
작년 if(kakaoAI)2024에서 공개한 Kanana의 Technical Report와 2.1B 모델이 오픈소스로 공개되었다. 카카오는 Kanana model family를 Kanana Flag(32.5B), Kanana Essence(9.8B), Kanana Nano(2.1B) 총 세 모델로 소개하고 있으며, 이 중 모바일 디바이스에서도 활용 가능한 가장 작은 Nano를 먼저 공개한 것이다.
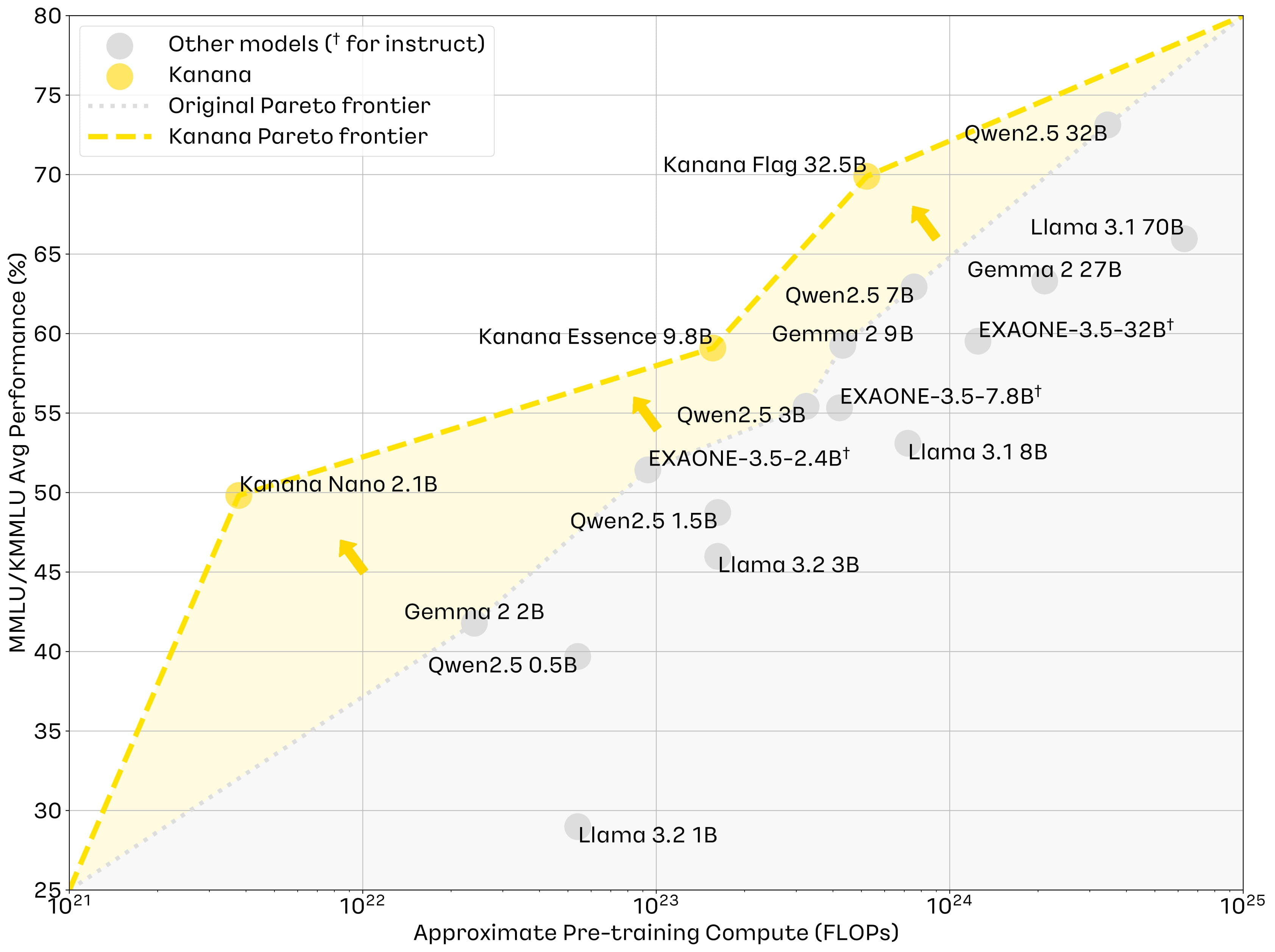
Kanana가 제시하는 모델의 장점은 '적은 자원으로 고성능의 경량 모델' 이다. 위 그래프에서도 알 수 있듯, 비슷한 사이즈 대비 Pre-Training Compute가 조금씩 낮지만, 성능은 뛰어나다는 것을 확인할 수 있었다. 그렇담 이걸 어떻게 한 건지, Technical Report의 내용을 보면서 알아보겠다.
1️⃣ Pre-Training
Pre-Training에 대한 설명은 Technical Report와 kakao tech blog(더 자세함)의 내용을 기반으로 정리하였다.
🥥 Data
Pre-Training에 사용된 데이터는 약 3조개의 토큰이며, 한국어와 영어를 기준으로 한다. English web, Korean web, academic(Arxiv 등), code(open-source datasets), encyclopedic documents, instruction data를 골고루 수집했으며, 추출 프로세스를 개선하여 데이터의 품질을 높였다고 한다(어떻게 하는지 자세한 언급은 없음). 또한 카카오의 제품이나 서비스에서 수집된 데이터는 사용하지 않았다.
추출한 데이터를 다시 필터링하는 과정이 있는데, 첫번째는 계단식 필터링으로, 중복을 제거하고 PII(personally Identifiable Information) 즉, 개인정보를 제거하며 휴리스틱하게 선택/제거 과정을 거칩니다. 두 번째는 언어별(Eng, Kor)로 고품질의 문서를 분류하는 과정으로, 영어는 DCLM을 사용해서 웹 문서를 분류한다. 한국어의 경우 고품질의 분류기가 부족함에 따라 FineWeb-Edu pipeline을 기반으로 FastText를 사용하여 edu filter를 반복적으로 학습하는데, 대부분의 문서가 비교육적으로 분류되어 불균형이 발생하므로, 교육적 문서들을 증강하여서 분류기를 반복적으로 재학습을 진행한다.
한국어 분류기의 설명이 살짝 헷갈렸는데, 고품질의 문서를 분류하기 위해서 '교육적', '비교육적' 두 클랙스로 분류하는 classificer를 학습했다고 이해했고, 이 과정에서 data-imbalance 문제가 있어서, data-sampling 중에서 data-augmentation 방법을 써서 적은 클래스(=교육적인 문서)의 데이터를 늘린 뒤에 다시 학습해줬다고 이해했다.
이렇게 만든 Edu filter와 한국어 코퍼스의 성능을 평가하기 위해 Llama3 8B 모델을 250억개의 토큰으로 continual pre-training을 진행한다(continual의 의미는?). 실험 결과, Edu filter를 사용해서 고품질 데이터를 추출했을 때 성능 향상이 뚜렸했으며 특히 영어 데이터의 품질이 높으면 KMMLU와 같은 한국어 벤치마크에서도 점수가 향상됨을 확인할 수 있었다. 즉, LLM의 성능을 높이기 위해서는 고품질의 영어 데이터도 영향을 준다는 것이다.
또한 Pre-Training 과정의 마지막에 instruction data(QA형식의 데이터를 의미하는 것으로 이해함)를 추가하면 성능이 향상된다는 선행연구에 따라 이를 진행했다고 한다. 블로그에서는 common sense and general knowledge, stem, code, wikipedia로 데이터 목적을 구분하고 각각의 전략을 다르게 적용하는 내용을 더 자세하게 설명하고 있다.
🥥 Training Process
효율적인 Pre-Training을 하기 위해서 data efficiency와 training efficiency를 강조하며, 다음 세 가지 주요 테크닉을 적용한다.
(1) Staged Pre-traiing from scratch
Kanana는 적은 비용으로 고성능의 모델을 만들기 위해서 여러 단계로 나눠서 초기에는 많은 양의 중간 품질 데이터를 사용하고, 후반에는 고품질의 데이터를 늘려가며 pre-training을 진행했다고 한다.
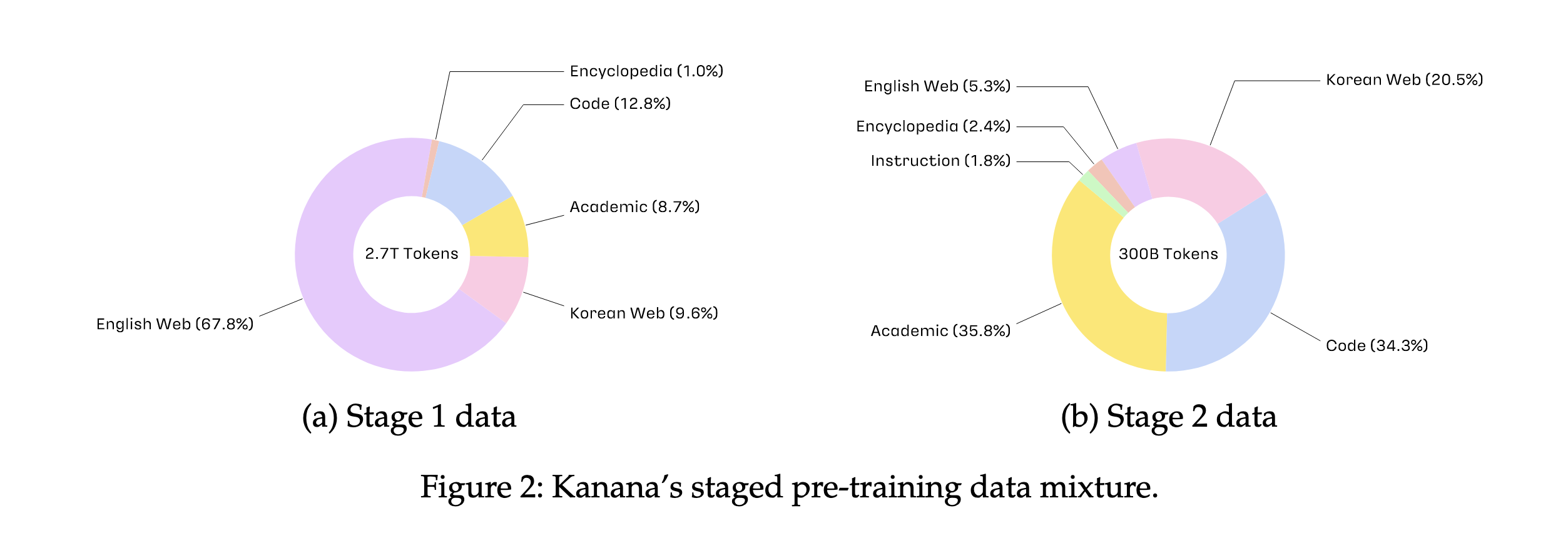
Stage1에서는 2.7조개의 다양한 토큰을 활용해서 8B의 모델을 from Scratch로 학습했다. Stage2에서는 고품질의 3천억개의 토큰을 추가로 학습했으며, Annealing 실험(다양한 데이터셋 조합을 빠르게 시도하여 성능 향상 가능성이 높은 후보 데이터셋을 선별하는 것)을 진행했다고 한다. 이를 통해 선별된 후보 데이터셋 조합에 대해 ablation(제거) 연구를 진행했는데, 이는 특정 데이터셋을 제거하거나 비율을 변경하면서 모델 성능 변화를 관찰하고 최적의 데이터 mixture를 선택하는 과정이다.
정리하면, stage1에서는 보다 광범위한 데이터를 가지고 학습을 하고, stage2에서는 고품질의 데이터로 학습을 했는데, 이때의 적정 비율은 여러번 테스트를 하면서 최적의 케이스를 찾았다는 것이다.
26.8B 모델도 이와 똑같은 전략을 사용하여 학습하였으며, 안정적인 학습 결과가 나타났다.
(2) Depth Up-scaling
DUS는 pre-training된 모델의 성능을 향상시키기 위해서 추가적인 레이어를 쌓아서 모델의 용량(capacity)를 늘리는 작업이다. Up-scaling은 Pre-training에서 사용된 동일한 데이터로 추가 학습되는데, 1단계와 2단계 각각 1000억 개의 토큰을 사용하여 학습했다고 한다. 9.8B를 처음부터 학습하는 것 대비 8B를 9.8B로 업스케일링 하는 것은 11.06%나 효율적인 computating 방법이며 큰 성능향상을 이룰 수 있다는 장점이 있다.
(3) Pruning and Distillation
distillation은 down-scaling 방법으로, 대규모 모델을 작은 모델로 축소할 때 지식을 전달하는 기술이다. 8B 모델을 pruning과 distillation으로 원래 데이터의 1/10만 사용하여 모델 크기는 50%로 줄이고, 성능은 유지할 수 있다는 것이다.
구체적으로 pruning을 효과적으로 하는 방법은 우선 모델의 각 구성요소의 중요도를 정확하게 평가하는 것이 중요하다고 한다. Kanana는 Minitron 모델의 중요도 측정 방식을 개선하여 더욱 정확한 pruning을 실시했다고 하는데, 레이어별 중요도 점수를 고려하여 모델의 핵심적인 부분을 유지하도록 했다고 한다. 또한 GQA(Grouped-Query Attention)을 사용하는 경우, 쿼리-키-값 정렬을 유지하면서 어텐션 헤드를 pruning해서 성능을 향상 시켰다고 한다(Essense모델의 attention heads는 32, Nano는 16). Kanana는 SwiGLU 활성화 함수를 사용하여 게이트 및 업 상태의 평균을 사용하거나 중간 상태를 사용하여 성능을 조정하는 방법을 도입했다는 설명도 있다.
distillation의 경우, 증류 데이터의 구성이 모델의 큰 영향을 미치기 때문에 고품질의 데이터를 사용하는 것이 중요하다. 따라 모델의 크기에 따라 최적의 데이터 구성을 다르게 적용했는데, 큰 모델의 경우 고품질의 대규모 데이터를 사용하고, 작은 모델의 경우 일반 도메인 영어 데이터의 비율을 높여 성능을 향상시켰다고 한다.
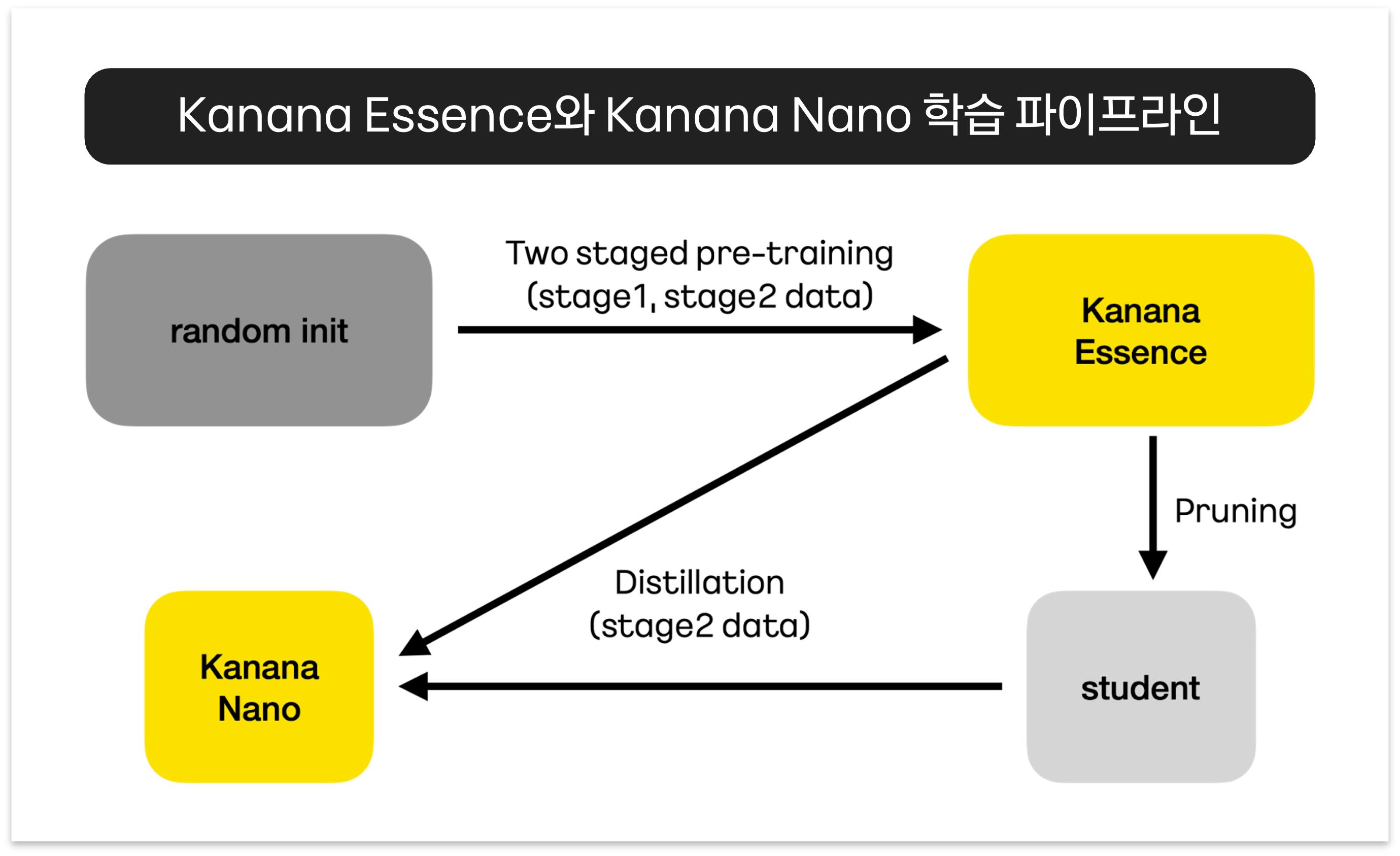
아래는 Kanana의 Essence 모델(8B -> 9.8B)을 distillation, pruning해서 Kanana Nano(2.1B)을 만든 과정을 설명한다(출처: kakao tech blog)
2️⃣ Post-Training
Post-Training 부분 역시 해당 리포트와 블로그를 참고했다.
앞서 Pre-Training은 모델이 일반적인 지식을 쌓는 과정이었다면, Post-Training은 모델의 페르소나를 형성하는 과정이다. Pre-Training한 base 모델을 사용자가 질의하고 답변하는 형식의 챗봇과 같은 형태로 만들려면 해당 형태로 fine-tuning하는 과정이 필요하다. 그 결과 Kanana Essence Instruct, Nano Instruct와 같은 모델이 형성되는 것이다.
🥥 Data
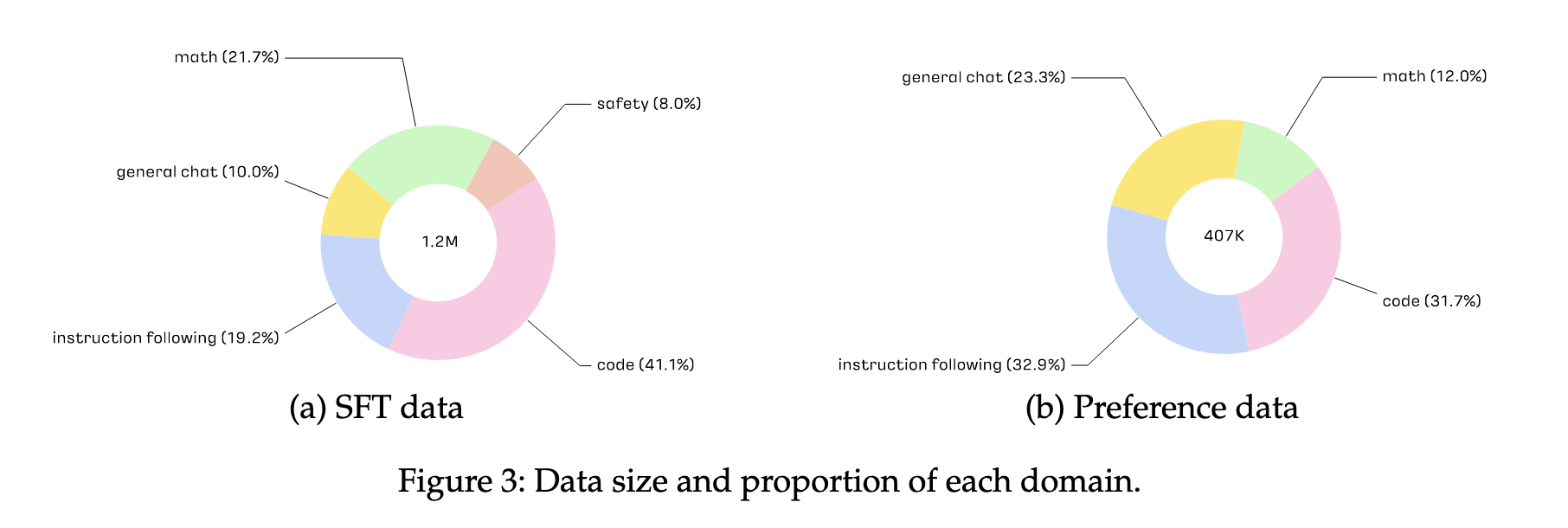
수집한 데이터는 약 120만개의 영어, 한국어 instruction 데이터이다. 데이터는 코드, 수학, 지시사항 관련, 일반채팅, 안전(윤리, 개인정보, 편견 등과 관련된 프롬프트) 총 5개의 세부 주제로 구성된다.
🥥 Training Process
Post Training 역시 여러 단계로 진행된다. 우선 SFT를 통해서 구조화된 답변을 형식을 학습하고, 이후 선호도 최적화 단계를 통해서 모델의 톤앤매너를 조정하는 방식이다.
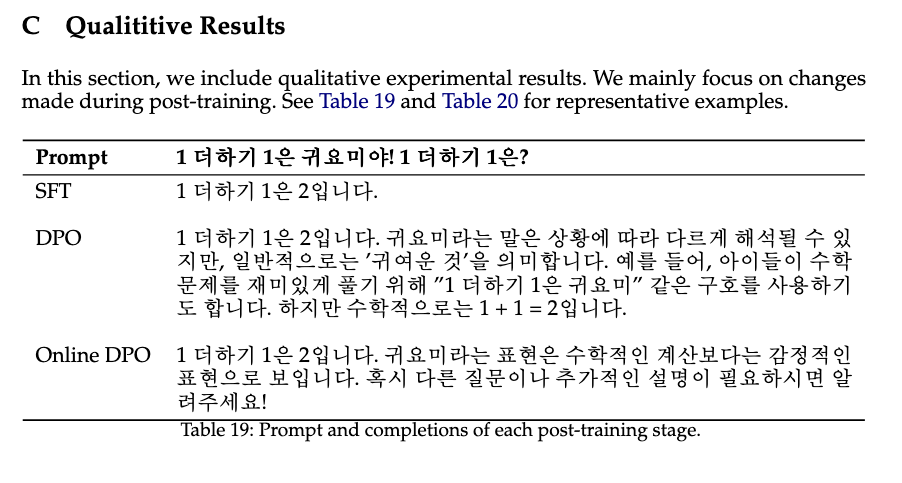
Appendix에서 위와 같은 예시를 제공하고 있는데, SFT는 정확한 답변을 학습할 수 있도록 한 뒤, DPO(강화학습)을 통해서 보다 의도에 맞는 답변을 할 수 있도록 조정해주는 것이다.
(1) SFT(Supervised Fine Tuning)
SFT에서는 120만개의 데이터로 구조화된 채팅 형식을 학습하는데, 이때 도메인별로 학습을 하면 다른 도메인의 성능에 부정적인 영향을 주지 않는다는 것을 확인했다고 한다(해당 도메인의 전문성만 학습한다는 것).
❓ 궁금한 점
Fine-tuning을 할때, 특정 domain 데이터만 사용하면 안되고 general한 주제의 데이터도 적절히 섞어줘야한다는 얘기는 이전에 들은 적인 있는데, 이건 각 도메인의 성능에 영향을 준다는 의미는 아닌걸까? 학습의 환경(데이터 양, 도메인 종류)이 다르기 때문에 다른 결과가 나온건지, 이건 다른 맥락인건지 확인해볼 필요가 있음
(2) Reward Model Training
Reward 모델은 online preference 최적화 과정에서 사용되며, 이 모델의 학습은 offline prederence data와 public preference data를 활용하여 진행된다. 간단하게, 여러개의 응답 중 어떤 것이 더 선호되는지 판단하는 best-of-N 방식으로 진행되며, 응답별 점수를 부여하고 최종 응답의 품질을 벤치마크 평가 기준으로 평가하는 것이다. 이 방법은 선택한 리워드 모델이 벤치마크 평가 기준에 따라 사람의 선호도와 최대한 비슷하게 점수화하는 모델을 만드는 과정이다.
(3) Preference Optimization
선호도 최적화 과정은 우선 offline preference 데이터를 사용해서 DPO(Direct preference Optimization)를 수행하는데, 이 단계는 기본적인 선호도 기준을 학습하는 과정이다. 이후 online preference optimization에서는 오프라인 DPO 모델을 초기 모델로 사용하여 실제 사용자 선호도를 반영하는 추가 학습을 진행한다고 한다. 이때 학습된 리워드 모델이 policy 모델이 생성한 응답의 품질을 평가하고, 비동기 응답 샘플링을 사용하는 온라인 DPO를 통해 모델을 더욱 세밀하게 조정한다. 이 과정을 반복적인 DPO 형태로 진행되지만, 응답 길이 증가를 방지하기 위해 참조 모델을 고정하는게 특징이라고 한다.
Post-Training과 관련해서 제대로 알지 못해 위 설명들이 이해하기 어려웠는데, blog의 글을 보고 어느 정도 이해할 수 있었다...
지금까지 한국에서도 여러 작은 base 모델들이 개발되었고, 오픈소스로도 공개되었지만, 이렇게 모든 과정을 차근차근 설명하고 공개하는 문서는 별로 없었던 것 같다. Pre-Training과 Post-Training에 대해서 다시 정리할 수 있는 시간이 된 것 같다. 여전히 Post-Training 부분은 더 공부가 필요하다.
.
.
.
카카오는 OpenAI와 전략적 제휴를 체결했다는데, 그 협력이 어느 정도인지도 궁금하다. 기술 개발 차원에서 OpenAI의 기술을 일부 공유받아 카카오가 독자적인 개발에 박차를 가할 수 있는 상태가 된 건지, 아님 패킹된 OpenAI의 서비스를 좋은 조건(저렴한 가격?)에 사용할 수 있도록 한 건지? 잘 모르겠지만, 어쨌든 무언가 진행되고 있는 것 같고 계속 팔로잉해야 할 듯.
다음은 Kanana 2.1B 모델을 테스트하는 방법과 실제로 어느 정도의 성능이 나오는지 확인해보겠다.
