[논문리뷰] A survey on Named Entity Recognition — datasets, tools, and methodologies
Paper Review

1. Introduction
Named Entity Recognition(이하 NER)은 자연어 텍스트에서 엔티티를 인식하고, 해당 엔티티의 타입을 분류하는 작업을 의미한다. NER은 텍스트 데이터를 활용하는데 다양하게 활용될 수 있으며, 다음과 같은 분야에서 응용되어 왔다.
- Social media에서 매일 생성되는 수많은 텍스트 데이터에서 감성 분석과 같은 기법을 통해 인사이트 찾기
- Domain-specific NER: Biomedical 분야같이 전문 지식이 필요한 분야의 구조화되지 않은 데이터에서 필요한 정보 찾기
- 텍스트 문서에서 중요한 정보를 검색할 때
- 의미론적 annotation을 통해 문서에 관련 아이디어를 태깅하는 작업
- 기계 번역에서 텍스트를 자동으로 번경할 때
- QA 시스템에서 활용 가능
- 간단한 절차로 진행할 수 있는 텍스트 요약
본 연구에서는 NER 기법을 규칙(룰) 기반, 지도식 기반, 비지도식 기반의 접근법으로 구분하여 알아보고, NER에 사용할 수 있는 데이터셋과 도구 등을 정리한다. 또한 biomedical, social media, general 등 다양한 영역에서 초기에 제안된 기법부터 최신 기법까지 자세히 다루고 있다.
2. Definition
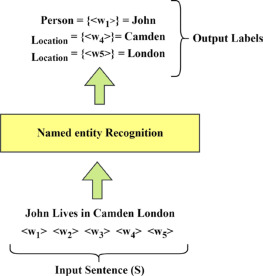
NER은 텍스트에 있는 수많은 부분(segments)을 인식하고, 사전에 정의된 카테고리에 맞게 분류하는 과정이다. 이때 카테고리는 'Person', 'Organization', 'Region' 등과 같은 분류를 말하고, 다음 그림과 텍스트의 각 부분에 태킹하는 것을 의미한다.
3. Dataset
NER을 수행하기 위한 모델을 만들고 평가하기 위해서는 사전에 구축된 데이터셋이 필요하다. 다음은 온라인에서 구할 수 있는 대표적인 annotation 데이터셋들이다.
| Index | Dataset | Description | Category |
|---|---|---|---|
| 1 | CoNll datasets | - CoNLL-2002는 네덜란드어와 스페인어로 나뉘며, 4개의 범주로 구성됨 - CoNLL-2003은 독일어와 영어를 포함하며, 주석이 없는 대용량 데이터를 학습 과정에서 활용하는 방법을 찾이 포함됨 | people, organizations, places, etc |
| 2 | WNUT-2017 | - 노이즈가 많은 소셜미디어 데이터(Twitter, Reddit, Stact Exchange, Youtube 등의 댓글)를 활용하여 실제 환경의 적용성을 높임 - 텍스트 길이를 140 단어 이상의 글들만 포함하여 독특한 문체와 특성을 반영하고자 함 | location, product, corporation, person, creative work, group |
| 3 | OntoNotes | - 아랍어, 영어, 중국어를 포함하고 웹블로그, 토크쇼 방송, 뉴스 등의 데이터로 구성됨 - 약 290만의 대용량 텍스트 말뭉치의 구조적 정보(술어 구조, 구문론)와 의미론적 정보를 태깅하는 것을 목적으로 함 | - |
| 4 | NCBI disease corpus | - 의료분야의 도메인 특화 데이터셋 - OMIM, MeSH와 같은 표준 의료 용어 체계를 활용하여 정확한 질병 개체명을 인식 | 약 790개의 서로 다른 질병 카테고리로 분류 |
| 5 | BioCreative V chemical disease relation | - 화학물질과 질병관련 논문 데이터를 PubMed에서 1500편을 활용 | - |
| 6 | Genia corpus | - 분자생물학 분야의 텍스트 마이닝을 위해 개발된 데이터로, PubMed에서 3개의 MeSH 용어를 사용해서 검색된 논문의 초록을 사용 - 다양한 언어적, 의미적으로 다층적 구조로 주석 작업을 진행함 | - |
| 7 | Wikipedia dataset | - WikiGold는 영어 위키피디아에서 39000개 단어를 수동으로 주석 WikiCoref는 영어 위키피디아에서 추출한 말뭉치를 조응(anaphoric)관계로 태깅. OntoNotes와 유사한 구조 - HYENA는 무작위로 선택된 50000개의 위키피티아에서 약 백만개의 개체를 태깅 | - |
이외에도 BC4CHEMD, JNLPBA, BC2GM 등의 데이터셋들이 존재한다.
4. Tools used for NER
| Index | Tools | Description |
|---|---|---|
| 1 | SpaCy | Python 패키지. 72개 이상의 언어를 지원하고, BERT와 같은 transformer를 활용한 멀티태스크 학습을 지원하며 TensorFlow, PyTorch 등의 라이브러리에서 커스텀 모델을 지원함 |
| 2 | Natural Language Tool Kit (NLTK) | Python 패키지. 연구와 교육 분야에서 활발하게 사용되며, 구문분석, 분류, 태깅, 토큰화 등의 작업에서 활용 가능 |
| 3 | Apache openNLP | 자연어 텍스트 처리를 위한 머신러닝 기반 도구. 문장 분할, 토큰화, 품사 태깅, 개체명 추출 등의 기능을 지원하며, Name Finder를 통해 개체명과 숫자를 인식함 |
| 4 | Tensorflow | Google에서 개발한 딥러닝, 머신러닝 라이브러리로, Python, C++, CUDA로 개발됨. 텍스트 데이터 대신 숫자나 원-핫 인코딩 인풋을 받음. Google 번역이나 텍스트 요약, NER 등에 활용됨 |
| 5 | Pytorch | Facebook에서 개발된 Python 기반 오픈소스 딥러닝 패키지. 이미지 인식이나 언어처리에 주로 활용되며 연구, 산업 기반에서 활발하게 사용됨 |
이외에도 LingPipe, AllenNLP, IBM Watson, Intellexer, ParallelDots, Dandelion API 등의 도구들이 존재한다.
5. Evaluation
Grishman and Sundheim (1996)은 두개의 평가 기준을 제시했는데, 우선 Type은 개체의 경계와 관계 없이(어디까지의 하나의 엔티티로 분류했는지는 고려하지 않는다는 의미) 예측된 레이블이 정확한지를 특정하고, Text는 레이블과는 관계없이 예측된 개체의 경계가 정확한지를 측정한다. 또한 각 카테고리별로 Precision은 시스템이 예측한 엔티티 중 정확히 예측된 비율을 나타내고, Recall은 인간이 태깅한 전체 엔티티 중 시스템이 정확하게 예측한 비율을 의미하며, 이를 통해 F1-Score을 도출한다.
추가로 exact match(예측값이 완전히 일치할 때 정답으로 간주), Relexed F1(예측된 엔티티의 일부라도 정확히 인식됐을 때 정답으로 간주), Strict F1(예측된 엔티티의 시작점과 끝점이 정확하게 일치하는 경우 정답으로 간주) 등과 같은 평가 지표들도 존재한다.
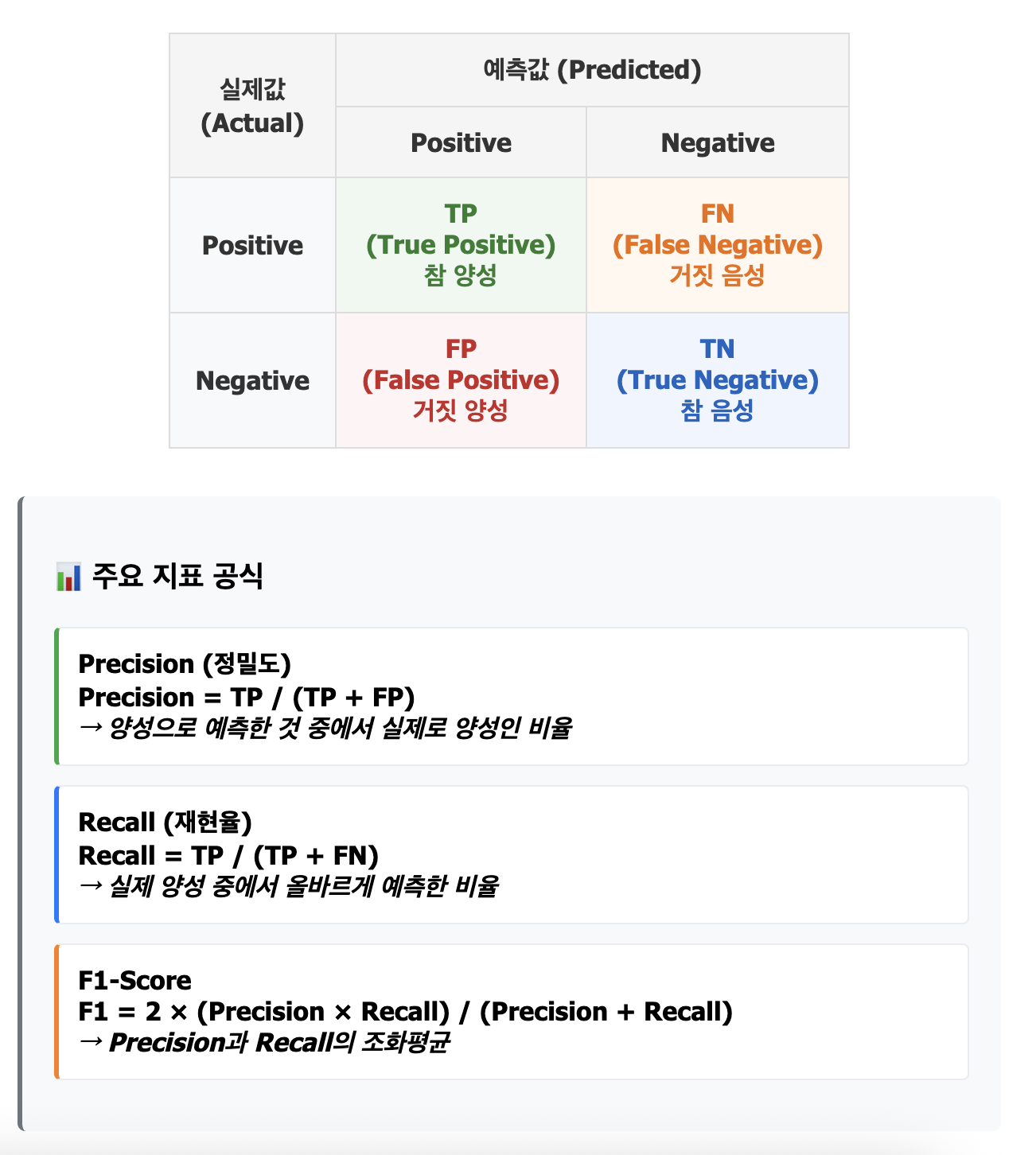
수학적으로 평가 지표를 계산할 때는 True Positive, True Negative, False Positive, False Negative 비율을 계산하여 평가를 진행하며 개별 지표의 의미는 다음과 같다.
- TP (True Positive): NER 시스템이 제공하지만 실제 데이터에는 존재하는 개체
- TN (True Negative): NER 시스템이 제공하지 않고 실제 데이터에는 존재하지 않는 개체
- FP (False Positive): NER 시스템이 제공하지만 실제 데이터에는 존재하지 않는 개체
- FN (False Negative): NER 시스템이 제공하지 않지만 실제 데이터에는 존재하는 개체
Confusion Matrix
** Claude로 생성
6. NER using rule based approach
규칙(룰) 기반의 NER은 언어, 구문-어휘적 특징과 도메인 전문지식을 바탕으로 구축된 특정한 규칙들의 집합으로 구성된다. 규칙들은 특정 도메인에만 제한되기 때문에 일반화하여 사용할 수 없으며, 규칙을 설계하는데 인간의 개입과 높은 프로그래밍 능력이 필요하지만, 한편으로는 특정 도메인에 특화되어 더 정확하고 효율적인 성능을 보인다는 특징이 있다.
규칙은 정규표현식을 활용하여 구축할 수 있는데, 복잡한 문자열 매칭과 패턴을 발견하여 개체를 판단하는 방식이다. 예를 들어, 약물정보가 저장된 DB에서 약물명들에서 자주 나타나는 접미사를 통해 유사성을 계산하는 등의 적용이 가능하다. 또한 식품(dietary) 정보를 추출하는 예시도 있는데, 우선 언급된 엔티티를 식별한 뒤 이 중에서 카테고리를 선택하는 과정으로 진행된다고 한다. Sari et al. (2010)은 규칙 기반과 지도, 비지도 알고리즘을 결합한 2단계 프로세스를 제안했는데, 우선 규칙 기반으로 초기 데이터를 추출한 뒤, 알고리즘으로 추가 분류하는 방식이다. 이때 규칙 기반 파트는 Stanford POS 태거와 문서 파서, 그리고 패턴을 통해서 추출하고, 이후 semi-supervised 모델을 통해서 DATE, LOCATION 등과 같은 카테고리를 분류한다.
규칙 기반 NER을 적용한 대표적인 시스템들은 다음과 같다.
- FATUS(1993): 포괄적인 텍스트 해석보다는 정보 추출 작업에 적합함. 즉, 텍스트의 일부만 중요한 정보일 때 스캐닝을 통해서 사전에 정의된 표현에 매칭하는데 사용할 수 있음
- LaSIE(1998): 대규모 정보 추출 시스템으로 다양한 도메인에서 활용됨
- LTG(1998): 텍스트 주석, 데이터 수집 도구 등 다양한 기능을 제공함
- FACILE(1998): 독일어, 영어, 스페인어, 이탈리아어 등 여러 언어로 텍스트를 분류함
정리하면, 규칙 기반 NER 접근 방식은 높은 정확도를 갖는다는 장점이 있지만, 특정 도메인에 특화된다는 특징으로 인해 일반화의 한계가 있고, 전문적인 규칙 개발 능력이 필요하다는 한계가 있다.
7. NER using unsupervised learning
비지도학습 기반의 NER은 라벨링되지 않은 데이터를 활용하여 학습한 모델을 사용하며, 일반적으로 연관성과 클러스터링으로 접근할 수 있다.
Liu & Zhou (2013)는 소셜 네트워크 데이터의 노이즈가 많고 짧은 트윗의 문제를 해결하기 위해 우선 linear Conditional Random Fields 모델을 사용해서 모든 트윗을 사전 클러스터링 하고, 각 클러스터에 대해서 현재 단어 혹은 유사한 라벨을 고려하는 개선된 랜덤 필드 모델(linear Conditional Random Firelds model)을 사용하여 라벨을 미세조정하여 부여한다.
✅ CRF(Conditional Random Fields) model 이란?
CRF(Conditional Random Field)는 머신러닝에서 시퀀스 데이터를 모델링하기 위해 사용되는 확률적 모델로, 주로 자연어 처리 분야에서 개체명 인식(NER)과 같은 태깅 작업에 활용된다. CRF의 핵심 특징은 개별 단어를 독립적으로 분류하는 것이 아니라, 전체 문장의 모든 단어에 대한 태그 조합을 동시에 고려하여 가장 합리적인 태그 시퀀스를 찾는다는 점이다. 예를 들어, '김철수는 서울에 산다'라는 문장에서 CRF는 [김철수→사람, 는→개체X, 서울→장소, 에→개체X, 산다→개체X]과 같은 수많은 가능한 태그 조합들을 생성하고, 각 조합에 대해 단어 특성(김철수의 이름 패턴, 서울의 지명 특성), 태그 전이 확률(사람 태그 다음 O 태그(개체X)의 자연스러움), 문맥 정보(조사 '는' 앞의 사람 개체, '에 산다' 앞의 장소 개체) 등을 종합하여 점수를 계산한 후, 가장 높은 점수를 받은 태그 시퀀스를 최종 결과로 선택함으로써 개별 단어 분류 방법보다 훨씬 정확하고 일관성 있는 개체명 인식 결과를 제공한다.
Zhang & Elhadad (2013)은 biomedical 분야에서 미리 라벨을 붙이거나 규칙을 부여해서 엔티티를 파악하는 방식이 아닌 자주 나타나는 의학 용어들을 정의하거나, 단어들의 기본적인 문법적 관계, 출현 빈도와 패턴들을 기반으로 한다. 이는 특정 분야에 특화된 방식이 아니기 때문에 다른 분야에서도 그대로 사용할 수 있다는 장점이 있다.
Peng et al. (2021)은 도메인 의존성 문제에 초점을 맞춰서 교차 도메인에서 적용할 수 있는 비지도 NER 모델을 제안했다. 이 모델은 적대적 훈련(adverarial tranining)을 통해 진행되는데, 이는 서로 다른 도메인 간의 분포 차이를 줄이는 훈련방식을 의미한다. 예를 들어, 의료 도메인의 데이터로만 학습된 모델에서는 'Dr. Kim'이라는 텍스트에서 'Kim'이 의사라는 것을 잘 인식하겠지만, 뉴스 도메인의 데이터로만 학습된 모델에서는 Kim을 의사로 인식하지 못한다. 따라서 텍스트의 도메인의 구분을 모호하게 만들어서 도메인에 관계 없이 공통적으로 이름 패턴을 인식하게 만들고, 이를 통해 특정 도메인에서 훈련된 모델이 다른 도메인의 텍스트에서도 개체를 정확하게 인식할 수 있다.
Dutta & Gupta (2022)는 데이터의 노이즈가 NER에 미치는 영향을 조사하였다. 우선 NER operating 시스템을 통해 맥락 기반의 특징을 포함한 개체명들을 수집하고, 식별된 개체들의 단어 길이, 출현빈도, 문맥정보 등의 다양한 특징들을 추출한다. 이후 비지도 학습 알고리즘인 KDE(Kernel Density Estimation)을 통해 개체들의 중요도 순위를 결정한다.
비지도 학습 기법은 많은 리소스가 소요되는 라벨링 작업이 없어도 모델을 구축할 수 있다는 장점을 갖지만, gold standard, 즉 정답이 없기 때문에 기존의 accuracy나 F-score와 같은 매트릭을 사용한 평가는 불가능하다는 한계가 있다.
8. NER using supervised learning
지도학습 기반 NER은 라벨링된 데이터를 활용하여 모델을 학습하고, 이 모델로 예측이나 분류 작업을 수행하는 기법이다. 지도학습 기반 NER에서 가장 중요한 건 적절한 학습 알고리즘을 선택하는 것이다. 대표적인 학습 알고리즘 예시로는 HMM(Hidden Markov Model), CRF(Conditional Random Field), SVM(Support Vector Machine) 등이 있다.
우선 HMM을 활용한 연구 사례로는 biomedical 분야에서 이전 시퀀스의 상태와 관측된 정보인 형태, 핵심 명사 트리거, 맞춤법, 품사 등을 활용하여 개체명 태그(이게 hidden! 텍스트에서 실제로 명시되어 있지 않으므로)를 예측하는 작업이 존재한다.
✅ HMM(Hidden Markov Model)이란?
HMM(Hidden Markov Model)은 시간에 따라 변화하는 시스템을 모델링하는 확률적 모델로, 관찰 가능한 출력 시퀀스를 통해 숨겨진 상태 시퀀스를 추론하는 데 사용된다. HMM의 핵심 가정은 현재 상태가 오직 이전 상태에만 의존한다는 마르코프 가정과, 현재 관찰값이 오직 현재 상태에만 의존한다는 출력 독립 가정이다. 예를 들어, 날씨 예측에서 실제 날씨(맑음/흐림)는 숨겨진 상태이고 우리가 관찰하는 것(우산 사용 여부)은 출력이라고 할 때, HMM은 어제가 맑았다면 오늘도 맑을 확률이 0.8이고(상태 전이 확률), 맑은 날에 우산을 사용할 확률이 0.1이라는(출력 확률) 식으로 모델링하여, 연속된 우산 사용 패턴을 보고 실제 날씨 상태 시퀀스를 추론한다. 자연어 처리에서는 품사 태깅에 활용되어 단어는 관찰 가능한 출력이고 품사는 숨겨진 상태로 모델링하지만, 각 단어가 독립적으로 생성된다고 가정하는 한계가 있어 복잡한 문맥이나 다양한 특성을 고려하기 어려우며, 이러한 제약을 해결하기 위해 전역 최적화와 유연한 특성 결합이 가능한 CRF가 개발되었다.
- 참고1, claude
CRF을 적용한 사례로는 마라티어(Marathi language; 인도의 마하라슈트라주의 공용어인데 형태학적으로 복잡하다고 함) 기반의 ML 통계적 NER 시스템이 있는데, 순서대로 이전 시퀀스의 상태만 고려한 HMM과 달리, 문장 전체를 고려한 조건부 랜덤 필드를 사용한다는 특징을 갖는다.
SVM을 NER에 활용한 방법으로는 우선 개체의 경계를 식별하여(경계를 분류하는 직선 또는 경계면) 식별할 개체인지 아닌지 binary로 판단하여 불균형 문제를 해결하고(태그가 여러개일 경우 자주 등장하는 것과 그렇지 않은 클래스 간의 불균형 문제가 있음), 식별할 개체 중에서 다시 의미적으로 분류를 한다. 이는 온톨로지 기반 계층적 의미 분류 접근법을 활용하여 복잡도를 낮추고 성능을 향상시켰다고 한다.
마지막으로, 앙상블 방법은 '각 분류기의 예측 정확도는 출력 클래스에 따라 다르다'는 가설을 기반으로 한다. 분류기별로 가장 잘하는 클래스만 투표(vote)하는 binary vote-based ensemble 기법이나, 각 분류기가 모든 클래스에 투표하되, 신뢰도에 따라 가중치를 부여하는 real vote-based ensemble 기법 등이 있다. 해당 연구(Saha and Ekbal, 2013)에서는 7가지 모델을 사용하여 다양한 모델을 테스트 하고 있으며, 언어나 도메인별로 접근하지 않고 일반적인 통계적 특징이나 패턴을 활용한다.
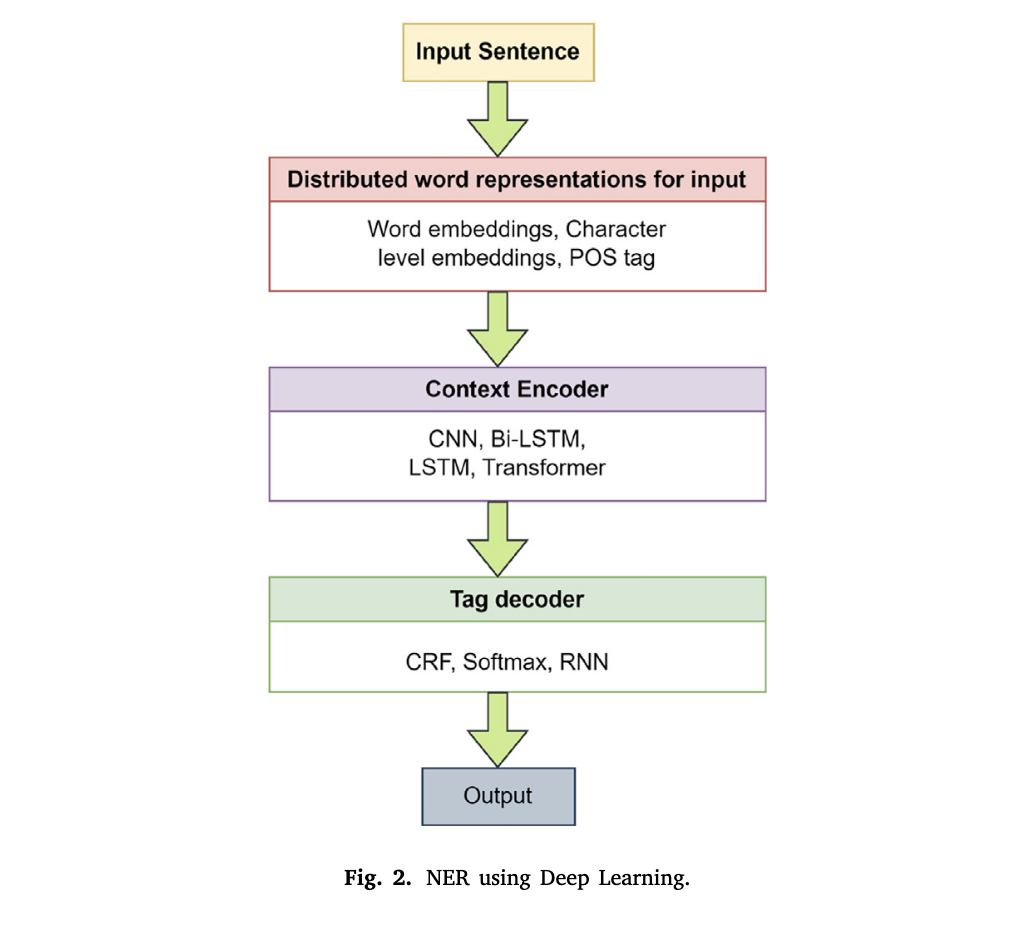
위 그림은 딥러닝을 활용한 NER의 프로세스를 나타낸다. NER 작업을 딥러닝을 통해 수행하는 방식은 Collovert and Weston(2008)이 처음 시도하였는데, 텍스트에서 의미론적인 역할을 라벨링하거나, 음성 태깅이나 청킹 등의 작업에 합성곱 신경망(convolutional network) 구조를 적용하였다. 간단히 이해해보면, 자연어 텍스트 input이 들어왔을 때 이를 벡터 등의 숫자로 변환하는 임베딩 작업을 진행하고, 이후 이 숫자 형식의 input을 CNN, LSTM, Transformer 등의 모델을 활용해 문맥(context) 의미를 반영한다. 이후 CRF, Softmax, RNN은 각 단어의 Tag를 붙여주는 모델로 앞서 반영된 문맥을 기반으로 태그를 부여한다. 이때의 태그는 일반적으로 개체명을 의미한다.
다음 내용은 NLP에서 사용되는 다양한 기본적인 딥러닝 아키텍쳐에 대해서 소개한다.
아래 내용에서는 굉장히 많은 선행 연구들을 소개하고, 이를 이해하기 위해서는 딥러닝의 기본적인 개념에 대한 이해가 선행되어야 하는 것 같다. 이전에 Neural Network에 대해서 쭉 정리한 포스트가 있으니, 참고하시길!
(1) Text representation
텍스트 표현 방법은 자연어를 숫자, 즉 인덱스로 나타내는 방법을 의미한다. 일반적으로 사용되는 방법은 One-Hot encoding, Count Vectorizer(등장 빈도 기반), TF-IDF(용어빈도*역문헌빈도; 문서k에서 등장하는 단어의 빈도*단어W를 포함하는 문서의 빈도), Word2Vec(대규모 말뭉치를 활용하여 맥락을 반영한 벡터 도출), Skip gram(하나의 중심 단어를 입력으로 받아서 주변 맥락 단어들을 예측하는 방식), CBOW(주변 단어들을 입력으로 받아서 중심단어를 예측하는 방식) 등이 있다.
(2) Convolutional Neural Networks
CNN은 임베딩된 입력 데이터를 지정한 window size 기준으로 합성곱 필터를 만들고, 가중치 행렬을 통해 합성곱 연산을 수행한다. 이후 도출된 결과를 검토해서 의미있는 패턴을 찾아내서 개체명을 인식한다.
CNN은 일반적으로 이미지 처리에서 많이 사용되는데(근처 픽셀은 의미있는 정보일 가능성이 높기 때문에), NER에서 활용한 연구 사례는 다음과 같다.
- Cho et al.(2020): biomedical 분야에서 문자, 단어 수준의 CNN과 BiLSTM을 결합하여 지역적 특성과 순차적 특성을 동시에 활용하고자 시도한 연구
- Zhang et al.(2022): BiLSTM과 확장된 CNN(Dilated CNN)을 사용하여 시퀀스 정보를 처리하며 대용량 데이터를 효율적으로 기록하고 관리함
- Wang et al.(2020): ASTRAL(Adverarial Trained LSTM-CNN)는 gated CNN(선택적으로 특성을 통과시켜서 특성 추출의 정확도를 높임)과 LSTM을 사용하여 모델의 일반화 능력을 향상 시킴
- Chang and Han(2023): BiLSTM은 여러 문장을 동시에 식별할 수 없어서 문장 간 연결 관계를 파악하기 어려워서 3D CNN을 도입. 문장 내부의 특성을 추출하고 문장 간 순차적 연결 관계를 파악할 수 있음
- Na et al.(2019): 한국어 NER을 수행할 때 빈번하게 발생하는 OOV(Out of Vocabulary)문제를 해결하기 위해 하이브리드 표현 방식을 개발. 입력문자 벡터를 병렬적으로 LSTM과 ConvNet에 넣어서 각각 형태소 벡터를 생성한 뒤, 두 벡터를 연결하여 순차적 처리와 지역적 패턴 포착을 둘 다 이루고자 함
- Zhou et al.(2020b): 의약품 패키지의 텍스트를 OCR을 통해서 추출한 뒤 Seq2Seq모델을 통해서 데이터를 정제하고, CNN을 통해 의미있는 패턴을 추출. 이후 마지막 레이어에서는 텍스트에서 완전히 문장을 식별하고 완성도를 판단함
(3) Recurrent Neural Networks
RNN은 내부 메모리를 사용하여 긴 입력 데이터를 저장하는 신경망으로, 순차적 데이터 처리에 특화된다. 앞서 자주 언급됐던 LSTM은 RNN의 장기 의존성 문제를 해결하기 위해 제안된 기법으로, 논문에서는 수식도 설명하고 있지만 이 부분은 건너뛰고 RNN 계산에서 추가로 설명해보겠다. RNN에서는 은닉층의 활성화 함수를 통해 나온 값을 다음 계산의 입력으로 보내는 순환구조를 갖는데, 이때 LSTM은 은닉층에 Cell-state와 Gate 개념을 추가한 것이다. Gate는 다시 Input gate, Forget gate, Output gate로 구성되는데, 이 부분에서 각각 어떤 정보를 기억하고 잊을지, Cell-state에 업데이트하여 최종 출력값으로 보낼지를 결정한다. 한편, BiLSTM은 한 방향으로 처리하는 LSTM과 달리, 입력 텍스트를 양방향으로 처리하여 앞뒤 맥락을 모두 고려한다는 특징을 갖는다.
RNN 계열의 모델을 활용한 연구 사례들을 쭉 설명하고 있는데, 이 부분은 패스 하겠다. 발전 순서만 간단하게 정리하면 다음과 같다.
기본 RNN→LSTM→Bi-LSTM→Bi-LSTM + CRF→Attention→Transformer
LSTM의 한계점으로는 긴 문장을 처리하는 경우, 하나의 잠재 벡터(latent vector)로는 전체 문구 의미를 완전히 포착하지 못할 수 있다. 따라서 앞쪽의 정보가 손실되지 않도록 개별 단어가 벡터로 표현되어야 하며, 이를 해결하기 위해 Attention 매커니즘이 제안되었다.
(4) Transfer learning
전이학습은 상대적으로 적은 데이터셋을 가지고 있을 때 사용할 수 있는 방법으로, 특히 언어모델은 Pre-training을 통한 전이학습에 자주 활용된다. 대규모 데이터로 사전 학습된 Elmo, BERT와 같은 모델은 텍스트 분류나 감정 탐지, 개체명 인식, 요약 등과 같은 자연어 처리 태스크에서 사용할 수 있다.
트랜스포머 아키텍쳐는 각 출력 요소가 입력 요소와 연결되고, 그들 간의 가중치가 상관 관계에 따라 동적으로 결정되는 딥러닝 모델이다. 아래 아키텍쳐는 Transformer 구조를 간단하게 표현한 그림으로, Seq2Seq 모델 처럼 인코더-디코더 구조를 따른다.
인코더 부분에서는 입력 시퀀스가 들어온 뒤, Positional encoding에서는 입력에 위치 정보를 추가한다. 이후 입력으로 부터 Keys, Quries, Values 세 가지 벡터를 생성하고, Attention 레이어를 통해 입력 시퀀스의 각 부분들의 관련성을 계산한다. 이후 Feed Forward로 들어가서 입력층, 은닉층, 출력층을 지나면 가중치와 편향이 부여된다. 이미지에는 표현되어 있지 않지만, 잔차 연결(Residual Connection)과 레이어 정규화(Layer Normalization)을 통해 반복되는 연산을 진행해도 정보가 소실되거나 확대되지 않도록 새로운 활성화 값을 통해 연산을 진행하며, 학습 속도와 안정성을 확보할 수 있다.
디코더 부분에서는 인코더의 마지막 출력값을 받아서 목표 시퀀스를 오른쪽으로 한칸씩 이동(Shifted)한 입력을 넣고 인코더와 같이 위치 정보를 추가한다. 이후 Masked Attention은 인토더에서 전체 문장 행렬을 받아서 현재 시점의 단어를 예측할 때 이래 시점의 단어까지 참고하는 현상을 방지하기 위해 현재 이후의 값들은 가중치에 반영되지 않도록 마스킹을 해준다.
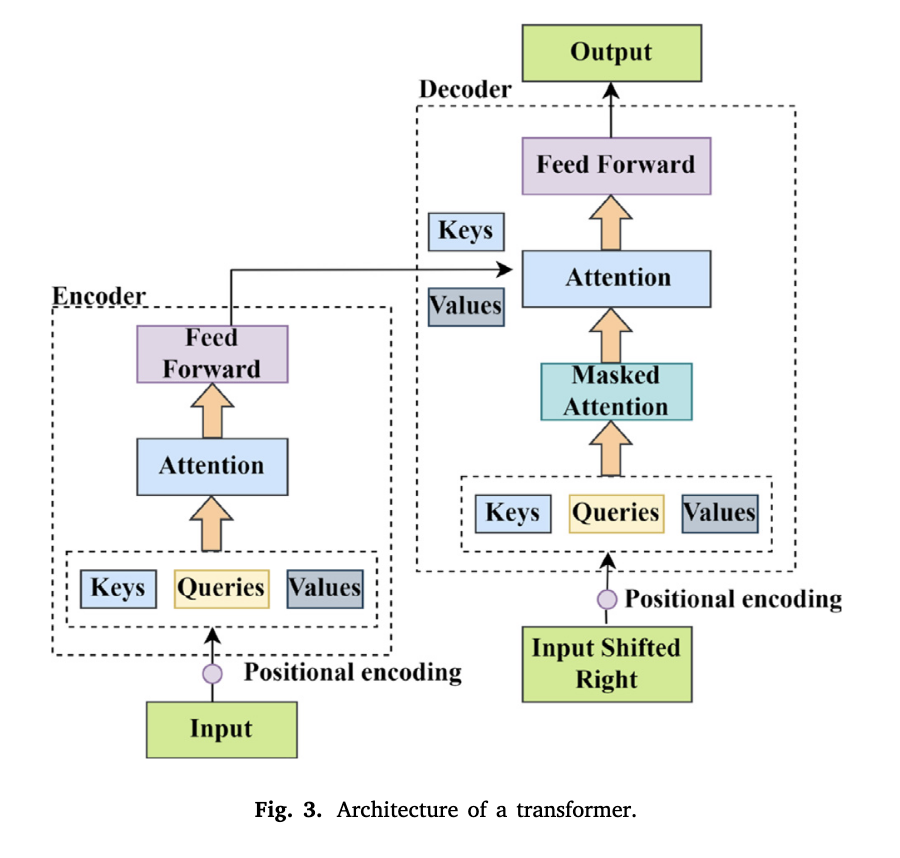
간단하게 정리하면, 인코더에서는 입력 시퀀스를 받아 각 위치의 맥락과 표현을 생성하고, 디코더에서는 인코더의 출력과 이전에 생성된 토큰들을 참조하여 다음 토큰을 예측하고 최종적으로 출력값을 생성하는 것이다.
Transformer는 RNN계열의 방법과 달리 모든 순차적으로 처리하지 않고 모든 위치를 동시에 처리할 수 있어 훈련 속도가 빠르고, 멀리 떨어진 토큰들 간의 관계를 포착할 수 있다는 장점이 있다. 반면, 전이 과정에서 잘못된 분류나 특정 도메인에 특화된 정보만 포함하여 오히려 성능이 저하되거나 편향이 증폭될 가능성도 존재한다.
9. Challenges
- Data Annotations: 지도학습 기반, 특히 딥러닝 기반의 NER은 대량의 주석된 데이터가 필요한데, 여전히 이 데이터를 구축하는데는 많은 시간과 비용이 소요됨. 또한 다국어로 NER 태깅을 하기 위해서는 충분한 언어학적 지식이 필요하다는 한계도 있음
- Complex Biomedical Texts: 복잡한 biomedical 분야에서 개체를 명확하게 인식하고 분류하는 것은 어려움. 약어와 acronym 등이 혼용되어 있다는 특징도 있음
- Ambiguity in language: 자연어 단어는 여러 해석이 가능해서 명확한 판단이 어려운 경우가 있음
- Informal texts: 댓글, 트윗 등에 있는 텍스트 중에는 비속어나 약어 등이 빈번해서 해석에 어려움이 있고, 일반적인 문장 구조와 차이가 있어 태깅의 어려움이 있음
- Multilingual NER: 웹 상의 언어는 다양성이 커졌고, 현재 영어 위주로 개발된 자연어처리 기법을 범용적으로 적용하는 것에 한계가 있음
- Domain Adaptation: 도메인에 따라서 개체의 의미가 달라질 수 있음(e.g. 'orange'는 오렌지 과일일수도, 색깔일수도)
- Named entity linking: 하나의 개체가 서로 다른 의미를 가지며, 한 문서 내에서도 다른 의미일 수 있음(e.g 'Barcelona'는 축구팀과 도시 모두를 지칭할 수 있음)
- Entity co-reference resolution: 텍스트에서 언급된 개체들이 실제로 동일한 개체를 지칭하는지 판단하는 부분이 필요함
- Handling noise and misspelled text: OCR을 통해서 텍스트 데이터를 수집했을 때 오타나 잘못 감지된 부분이 있거나 노이즈가 많은 경우
10. Future directions
- Hybrid Models: 각 모델이나 접근법을 결합하는 방법(e.g. CNN+RNN)
- Zero-shot Corss-lingual NER: 명시적으로 훈련되지 않은 모델을 활용해서 제로샷으로 NER을 수행하는 것. 성능의 제한이 있을 수 있지만 새로운 데이터 생성이나 훈련 과정이 필요없다는 장점이 있음
- Neural Network 모델과 새로운 기술의 결합: 문맥에 따른 단어의 의미를 반영하는 ELMo, BERT와 같은 모델들을 활용해서 세부적인 태스크들에서 쉽게 교체, 적용하여 다양한 용도로 활용할 수 있음(다음 Transfer Learning과도 연결됨)
- Transfer Learning: 비교적 적은 데이터 세트가 있을 때, 사전에 훈련된 모델을 사용하여 새로운 레이블 데이터를 최소한으로 사용할 수 있다.
