[논문리뷰] Don’t Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks
Paper Review

논문요약과 함께 필자의 의견이 포함되어 있습니다. 다양한 의견을 댓글에 남겨주세요 :)
최근 자주 언급되기도 하고 자극적인 제목이 눈에 띄는 CAG 논문을 읽어보았다. 핵심 내용은 기존 RAG의 단점인 긴 처리 시간, 시스템의 복잡성과 적합한 문서 선택의 오류 가능성 등의 한계를 질문 마다 검색을 새로 하지 않고 cache를 활용하는 CAG를 통해 극복할 수 있다는 것이다.
다 읽고 든 생각은, 분명 간단한 방법이고 장점이 있지만, 대용량 문서를 처리할 수 없다는 점에서 여전히 한계가 있다는 것이다. (제목의 Don't Do RAG 라고 말기에는 부족하지 않나...싶은 생각도)
Introduction
기존 RAG의 한계점
- 실시간 검색을 할 때 latency가 발생함
- 유사도 기반의 검색 과정에서 오류가 발생할 수 있으며, 답변의 품질에 직접적인 영향을 줌
- 시스템의 복잡성이 높고 유지 관리에 overhead가 추가됨
새로 제안하는 CAG의 특징
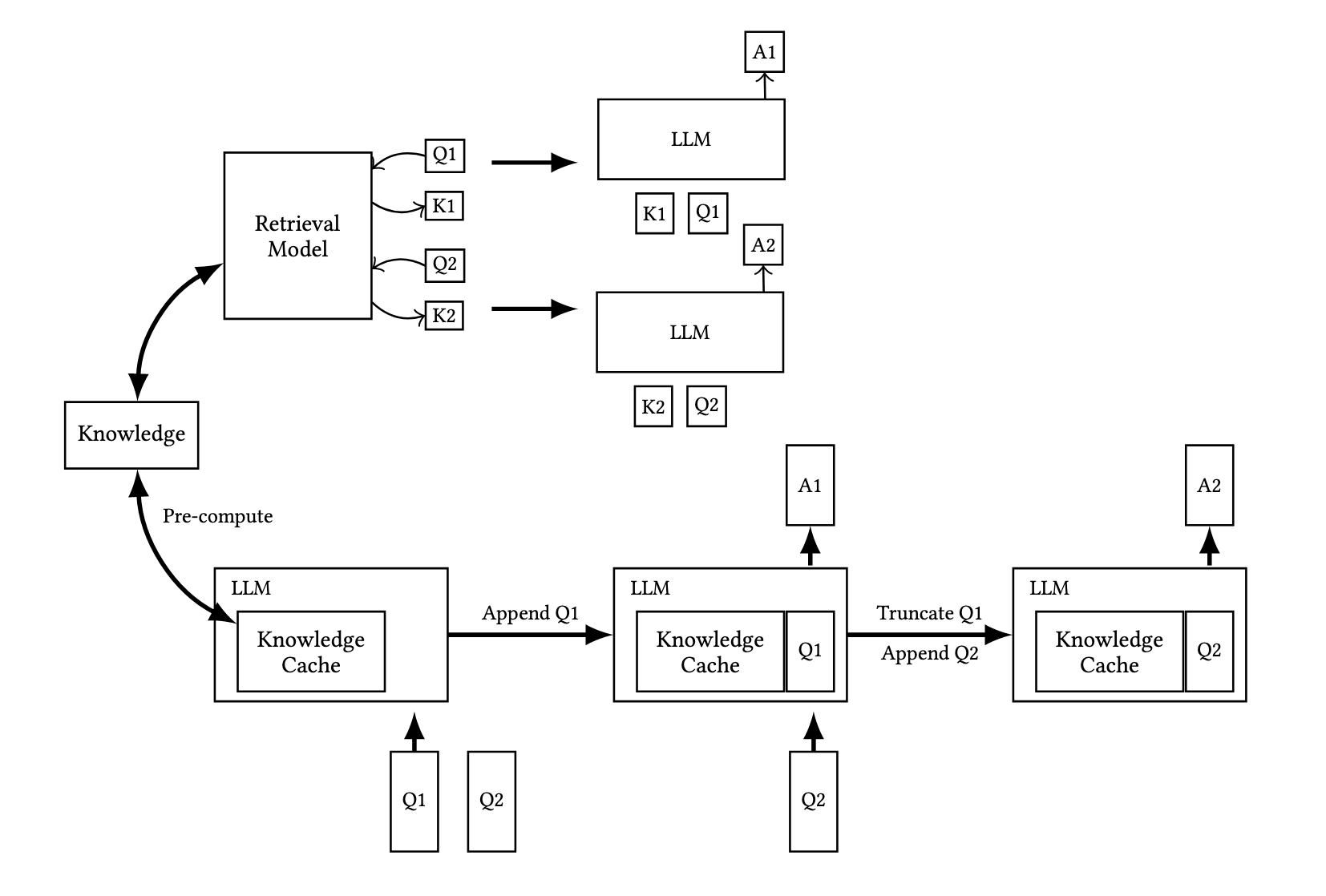
- 모든 관련된 문서와 LLM을 preloading하고 LLM의 추론 상태를 캡슐화하는 key-value cache를 미리 계산해둠 (? mehtod부분에서 더 자세한 설명이 나올테니 일단 넘어간다)
- latency를 줄이고 검색 오류를 완화하며 구조를 단순화할 수 있음 (? 왜 정확도가 높아지는지 잘 모르겠지만, 다음 설명에서 확인하겠음)
- 최근 LLM의 input context length가 매우 길기 때문에 (gpt-4o는 128000) 문서를 검색할 필요 없이 모델에 미리 로드해두기만 하고 사용할 수 있음
여기까지 읽었을 때 RAG와 CAG의 차이는 어떤 방식으로 참조하는 문서를 가져오는지의 차이라고 이해했다. RAG는 사전에 만든 data chunk 중에서 input과 가장 유사한 데이터만을 가져와서 답변 생성에 참조 데이터로 넣어주는 반면, CAG는 multi-turn retrieve라는 가정하에(필자의 생각임. multi-turn 이어야 이전에 넣어준 참조 데이터에 대한 정보를 기반으로 답변을 생성할 수 있을 것 같아서) 참조할 데이터를 전부 모델에 넣어두고, 이를 기반으로 답변을 생성하니 질문 마다 'retrieve'하는 과정이 생략되는 것이다. 이때 사전에 넣어주는 참조 데이터를 key-value cache 라고 표현하는 것으로 보았을 때, 단순히 문서 그대로를 넣어주는 방식은 아닌 것 같다.
Methodology
- 문서: D = {d1, d2, d3, ...}
- key-value: CKV
(1) External Knowledge Preloading
관련된 문서 D들을 전처리하고, 모델의 context window에 적합하도록 formatted한다. 여기서 말하는 포맷팅이 뭔지 모르겠다.
CKV - KV - Encode(D)
KV 캐시는 모델의 추론 상태를 캡슐화한 형태로 저장되며, 디스크나 메모리에 저장된다고 하는데, 여기서 캡슐화의 정확한 의미인지 잘 이해되지 않았으나 일반적인 의미와 같이 재사용을 위한 형태 정도로 이해했다(계산은 한번만 진행되며 비용도 한번만 발생) 또한 key-value 형태가 앞서 추측한 것과 달리, 특정한 형태로 변환하여 넣어주는 건 아닌 것 같다.
(2) Inference
추론을 할 때에는 CKV와 사용자의 질의 Q가 함께 로드되며 응답 R을 생성한다.
R = M(Q|CKV)
사전에 로드된 정보 D와 사용자 질의 Q를 결합한 통합 프롬프트 P = Concat(D, Q)는 외부 지식과 사용자의 질의를 통일된 방식으로 이해하도록 보장한다고 설명한다.
(3) Cache Reset
KV 캐시는 새로운 토큰 t1, t2, ...., tt가 순차적으로 추가되면 덧붙이는 방식으로 쌓이는데, 계속해서 쌓으면 성능이 저하되기 때문에 효율적으로 초기화 필요가 있다. 초기화 방법은 새로운 토큰(데이터)가 추가되었을 때 이전 데이터를 truncating(잘라내는) 방식으로 이루어진다고 한다.
CKVreset = Truncate(CKV, t1, t2, ...., tt)
이해가 안되는 부분이 여럿 존재했지만, 이 논문의 설명만으로는 알 수 없을 것 같아서 추가 자료를 검토중이다. (적용 코드 예제)
이 기법의 장점 3가지인 'Reduced Inferfence Time', 'Unified Context', 'Simplified Architecture' 중 두번째 부분은 주목할 만한데, MS의 Graph RAG에서 말하는 global 정보를 활용하는 이유와 상통하다고 생각했기 때문이다.
[Translated by Google Translator]
Preloading the entire knowledge collection into the LLM provides a holistic and coherent understanding of the documents, resulting in improved response quality and consistency across a wide range of tasks.
전체 지식 컬렉션을 LLM에 미리 로드하면 문서에 대한 전체적이고 일관된 이해가 제공되어 광범위한 작업 전반에 걸쳐 응답 품질과 일관성이 향상됩니다.
어떤 질문 중에는 특정 부분의 내용만 참고해서는 답변할 수 없는 경우가 있고, 문서 전반의 내용을 참조해야 할 수 있다. 기존의 RAG의 경우 전체 내용을 반영할 수 없다는 한계를 가지고 있으며 Graph RAG는 그 한계를 보완하기 위해 제안되었다. CAG 역시 문서의 특정 부분만 참고하지 않고 전체를 검토한다는 점에서 이러한 장점을 가질 수 있는 것이다.
(이 장점을 반대로 생각하면, CAG는 문서의 양이 많아졌을 때 부분적인, 세부적인 부분의 내용을 놓칠 가능성이 높다는 걸 의미하진 않을까?)
Experiments
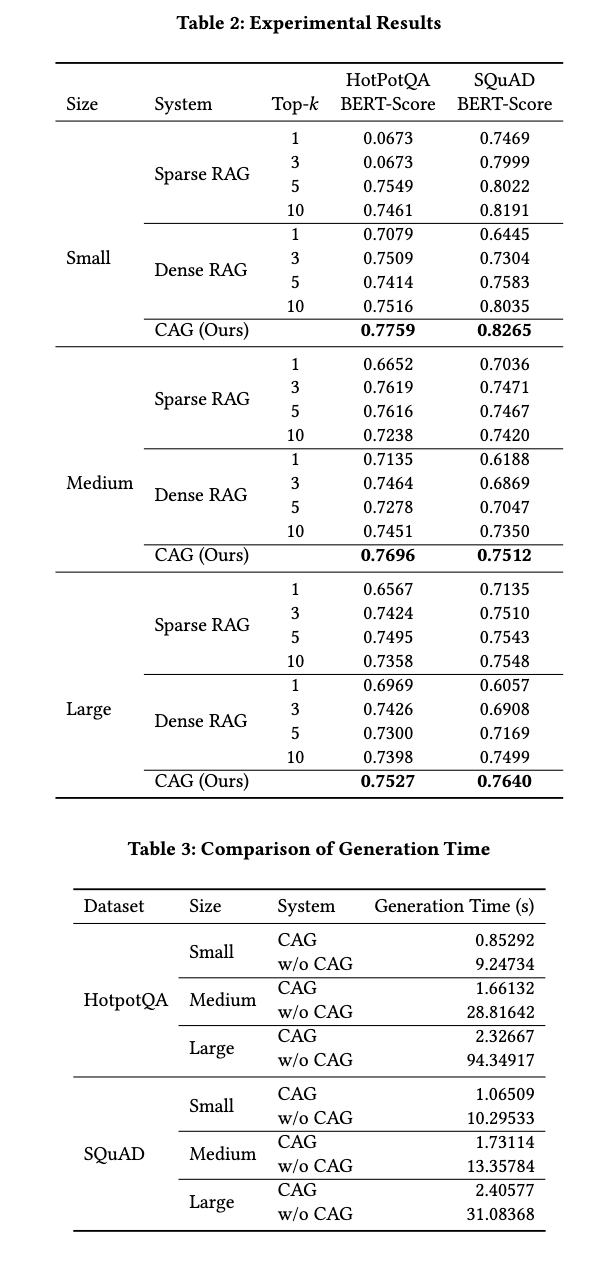
평가는 SQuAD와 HotPotQA 데이터 세트를 활용해서 진행했고, Llama Index framework의 두 가지 retriever(Sparse retrieval system의 BM25, Dense retrieval system의 OpenAI indexes)를 baseline으로 설정했다. 점수 계산은 BERTScore을 사용했다고 한다.
-
Sparse retrieval system
전통적인 정보 검색 기법이지만, 여전히 강력한 성능을 보여서 많이 사용된다. 이러한 기법들은 단어의 빈도와 문서 내 위치 등을 가중치로 계산하여 검색을 진행한다. BM25는 TF-IDF의 확장된 형태로, 단어 빈도와 역문헌빈도(TF-IDF)와 함께 문서의 길이를 정규화하고, 질의-문서 매칭을 최적화(단어의 등장 빈도와 질의 내 단어 중요도를 동시에 평가)하는 모델이다. 다만, 단어 간의 의미 관계를 고려하지 못하며 정확한 단어 일치(오타나 유의어, 변형어 등)에 의존한다는 한계가 있다. -
Dense retrieval system
단어의 의미와 문맥을 학습하고 활용하여 의미론적인 검색이 가능한 기법으로, 문자를 고차원의 벡터로 변환(임베딩)한 뒤 벡터 간의 유사도(cosine similarity, inner product 등)를 계산하는 방식이다. 최근 LLM을 활용한 RAG는 대부분 이 방식이 메인으로 활용되고 있다. 단어 자체 뿐만 아니라 문맥을 이해해서 유의어, 동의어 등을 처리할 수 있다는 장점을 갖지만, 고차원 벡터를 계산하는데 많은 자원(컴퓨팅 비용, API 비용 등)이 요구되고 복잡도가 높다는 한계를 갖는다.
최종 성능을 보면, top-k(k는 유사한 답의 개수)에 따라서 약간의 차이가 있지만, 대부분 CAG의 성능이 높다고 나온다. 소요 시간은 CAG가 월등히 적게 걸린다.
Conclusion
[Translated by Google Translator]
긴 컨텍스트 LLM이 발전함에 따라 기존 RAG 워크플로를 다시 생각해 볼 수 있는 강력한 사례를 제시합니다. 우리의 작업은 검색 대기 시간 제거를 강조하지만 사전 로드와 선택적 검색을 결합하는 하이브리드 접근 방식의 가능성이 있습니다. 예를 들어, 시스템은 기초 컨텍스트를 미리 로드하고 검색을 사용하여 극단적인 사례나 매우 구체적인 쿼리를 보강할 수 있습니다. 이는 사전 로드 효율성과 검색 유연성의 균형을 유지하여 컨텍스트 완전성과 적응성이 똑같이 중요한 시나리오에 적합합니다.
'~hybrid approaches that combine preloading with selective retireval~' 이 부분에서 CAG의 확장 가능성을 보여주는 것 같다. 개인적으로는 Text2SPARQL을 할 때, 활용해야하는 어휘 문서 전체를 넣어주고 싶은데, prompt engineering으로 적용하기에는 한 번의 질문에 처리해야 하는 input token 수가 너무 많아서 시간도, 비용도 많이 드는 문제가 있고 RAG로는 접근하기 어렵다는 문제가 있었다. 논문의 마지막에 언급되는 CAG의 preloading과 selective retrieval(정확히 어떻게 해야 할 지는 모르겠지만..)으로 접근하면 이 부분의 실마리를 조금 찾을 수도 있을 것 같다는 생각을 하며 마무리 해보겠다.
참고자료
