
논문에 대한 완벽한 이해가 되지 않은 상태입니다. 이 글을 읽은 또다른 논문 리뷰어의 의견을 들려주시면 감사하겠습니다 :)
한줄 정리: LLM을 활용한 서로 다른 온톨로지의 자동 정렬(맵핑) 방법
'Accelerating knowledge graph and ontology engineering with large language models' 논문과 연결되는 내용이 있습니다.
'Accelerating knowledge graph and ontology engineering with large language models' 이 논문을 읽다가 Ontology alignment, 모듈화 부분이 도저히 이해되지 않아서 선행연구인 해당 논문으로 넘어와서 먼저 읽었다. 논문 전체를 꼼꼼하게 읽진 않았고, 필요한 내용만 부분적으로 발췌해서 읽고 이해했다.
1️⃣ Introduction
ontology matching이라고도 불리는 ontology alignment는 서로 다른 온톨로지를 매핑시키는 것을 의미한다. 이러한 연구의 대부분은 주소 동등성 관계를 파악하여 클래스간, 속성간의 1-1 매핑만 감지하도록 하며, 복잡한 매핑 관계를 파악하고 구조화하는 것은 매우 어려운 작업이다.
NLP의 발전과 LLM의 등장으로 인해 대부분 사람의 수작업으로 진행되던 ontology alignment 작업을 자동화하려는 시도들이 진행되고 있다. 그러나 일반적으로 온톨로지 두개를 프롬프트에 넣고 정렬하려고 하면 원하는 결과물이 나오지 않기 때문에, 본 연구에서는 온톨로지 모듈 형태의 풍부한 정보를 제공하고 여러 단계를 거쳐 최대한 정렬의 성능을 높이는 실험을 진행한 것이다.
2️⃣ Complex Alignment by Large Language Model
Ontology Modules
Semantic Web Community에서 'Modlues'라는 단어는 다양하게 해석될 수 있는데, 여기서는 MOMo(Modular Ontology Modeling) 방법론에서 사용되는 방식의 용어로 이해할 수 있다. 즉, 온톨로지의 특정 부분으로 주요 개념과 특징을 캡슐화하는데, 예를 들어 위치, 날짜, 조직 등에 대한 세부 정보를 포함한다.
모듈은 (1) 기술적 구성 요소로 관련 클래스와 그 상호 작용을 그룹화하는 온톨로지의 부분을 구분하는 역할과 (2) 도메인 전문가의 이해방식과 일치하는 방식으로 구분의 두 가지 역할을 한다.
이 부분이 잘 이해되지 않는다. Cluade를 통해서 보다 자세한 설명을 부탁했다.
모듈은 온톨로지의 일부분으로 하나의 핵심 개념과 그 개념에 관련된 주요 특징들을 포함하는 의미적으로 일관된 단위이다. 예를 들어, '사람모듈'은 사람이라는 핵심 개념과 사람의 특징(이름, 나이, 직업, 관계 등)을 포함한다. 각 모듈을 독립적으로 이해 가능한 '미니 온톨로지'처럼 작동할 수 있지만, 다른 모듈과 연결되어 전체 온톨로지를 구성한다.
모듈은 두 가지 역할을 수행하는데, 우선 기술적 구성요소로 온톨로지를 논리적으로 분할하고 그룹하며 다른 온톨로지에서 재사용할 수 있도록하는 역할이다. 두 번째는 도메인 전문가와 이해를 일치시키는 역할인데, 개념적 일관성을 통해 특정 도메인 전문가들이 사용하는 용어와 개념을 반영하여 자연스럽게 인식하도록 하는 역할이다.❓ SubGraph와는 어떻게 다를까? 특정 개념을 중심으로 n-hop까지의 subgraph를 구성하는 방법과 다른걸까?
🤩 다시 생각해보니, 이때 말하는 모듈이란 온톨로지 스키마에서 해당 클래스나 프로퍼티와 관련된 개념들을 의미하는 것 같다. 예를 들어Person이라는 클래스를 써서 'JY-is a-Person'과 'JY-hasParents-NAM' 이런식의 triples들이 있을 때, 이 두 JY를 alignment, 즉 매핑하기 위해서는is a나hasParents,Person,NAM등과 같은 관련된 개체나 클래스, 속성의 정의 등을 알면 성능이 향상될 수 있다.
이러한 모듈은 작업을 관리 가능한 세그먼트로 분류하여 온톨로지 모델링에 전략적으로 접근할 수 있도록 한다. 시작 부분에서는 개별 모듈에 초점을 맞춘 뒤, 전체를 연결하는 방식을 사용함으로써 복잡하고 큰 온톨로지를 응집력있게 관리할 수 있고 수정이 필요한 경우 개별 모듈을 수정, 교체하면 되므로 전체 시스템을 보다 편리하게 관리할 수 있다.
Design of the Prompting Process
해당 연구에서 alignment를 위해 사용한 온톨로지는 다음 두 가지이다.
- GBO(GeoLink Base Ontology)
- GMO(GeoLink Modular Ontology)
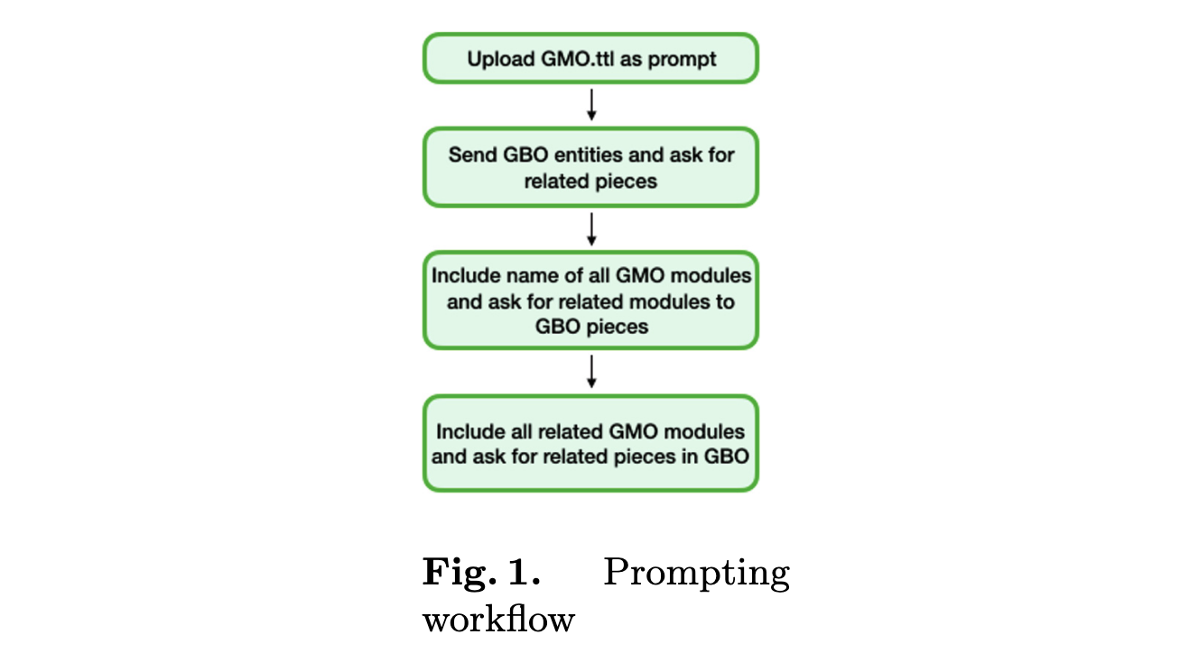
프롬프팅을 진행한 순서는 다음과 같다.
- GMO.ttl 파일 업로드
- GBO의 entity 리스트를 주고 관련있는 값들을 질문
- (2)의 결과가 만족스럽다면, 이후의 작업은 필요 없음
- GMO 모듈의 이름을 포함하고 GBO에서 관련있는 값들을 질문
- 모든 관련 GMO 모듈을 포함하고 GBO에서 관련있는 값들을 질문
3️⃣ Experiment and Evaluation
실험에 사용 모델은 GPT-4이다. 초기에 단순히 GBO.ttl 파일을 업로드 하고 추출한 관계를 GMO에서 관련 관계 탐색을 요청했는데, 이 결과는 충분하지 않았다고 한다. 따라서 모듈 정보를 포함한 프롬프트를 사용했고, 성능이 크게 향상되었다. 즉, zero-shot일 때는 필요한 요소의 10-20%만 인식할 수 있었지만, 모듈 정보를 제공했을 때는 약 95%가 성공적으로 식별되었다고 한다.
❓ 적절한 모듈 정보를 넣어준 방법이 궁금한데, 이 부분까지 자동화한 건지는 잘 모르겠다. 모듈의 생성 방법과 적절한 모듈을 넣어주는 방법은?
평가는 양적 평가를 진행했으며, recall과 precision 지표를 활용한다. recall은 총 예상 인스턴스 중 탐지된 GMO 관련 인스턴스의 비율로 계산하고, precision은 발견된 모든 인스턴스 중에서 올바르게 식별된 GMO 요소의 비율로 계산된다. 평가 결과, recall과 precision의 평균은 모두 0.67이고 중앙값은 각각 0.75, 0.8이다.
4️⃣ Discussion and Future Work
본 연구의 의의는 공유 인스턴스가 없어도 복잡한 정렬을 생성할 수 있는 최초의 접근법이라고 한다. 이때의 공유 인스턴스랑 서로 다른 온톨로지에서 동시에 등장하는 인스턴스를 의미한다. 즉, 동일한 인스턴스가 반드시 없어도 의미적으로 유사한 값을 판별해낼 수 있음을 의미하는 것 같다.
모듈을 통해서 자동화된 alignment의 성능을 상당히 향상시켰으나, 여전히 향후 연구에서는 Human-in-the-loop와 같은 인간이 개입하는 중간 단계를 고려할 수 있고 파인튜닝이나 심볼릭 데이터를 잘 이해하는 모델을 활용한다면 성능이 더욱 향상될 것을 기대할 수 있다고 언급한다.
.
.
.
neuro symbolic... 어렵다

그럼 그냥 온톨로지 스키마 파일(ttl)을 LLM에 주고 각각 의미 비슷한 것 끼리 매핑해달라고 한 것으로 이해하면 되는걸까..? 내 생각에는 프롬프팅에서 결국, GBO랑 GMO에 대한 디테일한 설명을 넣어줬을 것 같다는 생각입니다..