
- 스터디 책: Hands-On Entity Resolution
- 깃헙: https://github.com/mshearer0/HandsOnEntityResolution
🧩 Data Considerations
Unstructured Data
이 책에서는 주로 테이블 데이터와 같은 structured한 형식만 다뤘는데, 실제로는 비구조화된 데이터에서 개체를 추출해야 할 때도 있다. 이때 활용할 수 있는건 Python의 NLTK와 같은 NER 라이브러리인데, PERSON, ORGANIZATION, LOCATION과 같은 일반적인 타입은 추출할 수 있지만, 특정 도메인에 특화된 개체를 추출하는데는 한계가 있다.
Data Quality
지금까지는 데이터에 오류가 있거나 결측값이 있을 때 해당 레코드를 삭제하는 방식을 택했다. 그러나 실제로 데이터를 전처리 할 때는 전체 레코드를 삭제하는 대신 해당 속성을 무시하는, 즉 가중치를 0을 할당하는 방식을 적용할 수 있다. 또한 일부 오류에 대해서는 전처리를 해주는 작업도 매칭률을 높이는데 중요한 요소가 된다. 이를 위해 데이터의 완전성(completeness)과 유효성(validity) 검사를 활용할 수도 있다.
Temporal Equivalance
개체의 속성은 시간이 지남에 따라 변할 수 있다. 예를 들어, 결혼을 하면 성이 바뀔 수 있고, 나이는 매년 바뀌며, 전화번호와 이메일도 재발급받을 수 있다. 이는 당연한 이치이지만, 속성 매칭에서 종종 간과되는 부분이기 때문에 변동성이 잦은 속성에는 너무 큰 가중치를 두지 않아야 한다는 것을 기억해야 한다.
🧩 Attribute Comparison
Chapter3에서는 semantic기반과 phonetic기반의 유사도 기법을 제시했는데, 이는 모두 단일 토큰(단어)일 때 잘 적용되는 방식이다. 아래는 두개 이상의 단어 간의 매칭 방식에 대해서 설명한다.
Set Matching
단어 세트 간의 매칭은 Jaccard 인덱스와 같은 set 기반 기법을 활용하여 각각의 세트 간의 오버랩되는 정도를 측정하는 방식을 활용할 수 있다. 더 정교한 기법으로는 set기반과 수정 거리 테크닉을 결합한 Monge-Elkan 유사도 기법도 있다.
최근에는 문장 임베딩을 통해 문자열의 의미를 벡터로 변환하여 코사인 유사도와 같이 벡터 간의 각도를 기반으로 유사성을 판단하기도 한다. 한편, 벡터 기반의 접근법은 글자의 순서를 고려하지 않는다는 점에서 NBA와 NAB가 높은 유사성을 가질 수 있다는 특징이 있다.
Geocoding Location Matching
주소를 비교하는 또 다른 방법은 지오코딩을 통해 좌표를 비교하는 방식으로, 주소의 경위도를 추출하고 직선 거리를 계산하는 것이다. 이는 동일한 건물을 공유하거나 산업 단지 등과 같은 인접한 개체들이 있는 경우에는 오탐지(false positive)비율이 높아질 수 있다는 특징이 있다.
Aggregating Comparisons
속성을 비교하는데는 여러가지 기법을 사용할 수 있으며, 각자 고유의 장단점을 가지고 있으니 여러가지 테스트가 필요하다. 특히 여러 기법을 병렬적으로 사용하는 경우네는, Fellegi-Sunter 모델의 조건부 독립성 가정을 충족하지 않으므로 Splink와 같은 확률적 도구를 사용했을 때 제대로 작동하지 않을 수 있다고 한다. 따라서 이중 계산을 피하기 위해 각각 비교를 실시하고 통합 점수를 비교에 사용할 수 있다.
🧩 Post Processing
Chapter10에서는 쌍을 이룬 레코드들을 하나의 클러스터로 그룹화하는 방법을 다뤘는데 여전히 통합된 개체를 설명하기 위해 어떤 속성값을 사용할지 결정해야 하는 부분이 남았다. 예를 들어, Michael과 Micheal이라고 표기된 이름의 개체가 다른 속성들(e.g. 나이, 주소, 직업 등)까지 비교했을 때 동일한 개체로 판단된 경우, 하나의 클러스터로 묶을 수 있지만 최종적으로 Name에 표기할 때 Michael을 선택할 지, Micheal을 선택할지 정해야 한다는 의미이다. 이때 선택 기준은 데이터셋의 상대적 신뢰성과 우선순위에 따라 결정된다고 한다. 예시의 경우, 'ael'의 표기법이 더 일반적이기 때문에 Michael 을 선택할 수 있다.
이때 결정한 속성값은 데이터셋의 신뢰성과 우선순위에 따라 변경될 수 있다. 혹은 두 데이터셋의 다른 속성들을 참고해서 더 품질이 높은 데이터셋의 레이블을 선택할 수도 있다. 이러한 방식은 Bottom-up 접근의 계층 클러스터링으로, 단계별로 레코드들을 연결하여 클러스터를 만드는 방식이며, 반복적인 수행이 가능하지만 대용량 데이터셋에서는 상당한 연산 비용이 발생하고 최적의 솔루션이라는 보장을 할 순 없다는 특징이 있다.
🧩 Graphical Representation
속성 비교와 쌍별 매칭 분류를 마친 뒤에, entity resolution의 마지막 단계는 그래프 분석과 유사한 부분이 많다고 한다. 클러스터링 작업의 결과는 레코드를 의미하는 노드와 매칭되는 속성 엣지로 구성되어 표현되는데, 이를 통해 공통된 관계를 파악할 수 있다. 동일한 개체를 통합하는 작업을 진행하기 전에는 이 네트워크를 통해 잘못된 부분을 파악할 수 있고, 이후 동일한 개체를 파악한 뒤에는 단일 노드로 간단하게 표현할 수 있다. 실제로 구글은 5억개 이상의 entity와 35억개 이상의 사실 정보로 표현된 지식그래프를 통해 검새 결과를 통합하여 제시한다.
🧩 Real-Time Considerations
지금까지의 데이터는 특정 시점의 정적인 데이터를 배치로 처리하는 방식을 사용했는데, 만약 데이터에 업데이트된 정보가 있다면, 전체 작업을 처음부터 진행하는 비효율성이 존재한다. 실시간 처리는 새로운 데이터가 들어올 때마다 전체 클러스터를 다시 구성해야 해서 시간적 제약이 있으며, 재구성 과정이 복잡하다는 어려움이 있기 때문이다. 따라서 실시간으로 항상 최신 상태를 유지하려면 추가적인 기술적 고려사항들이 필요하다.
🧩 Performance Evaluation
entity resolution은 실제로 매칭되어야 하는데 매칭되지 않은 것과(underlinking) 서로 다른 객체인데 매칭된 경우(overlinking)을 파악하는 것으로 평가할 수 있다. 앞서 사용했던 precision, recall 등과 같은 평가 지표를 활용할 수도 있지만, 일반적으로는 정답 여부를 파악할 수 있는 공통 키나 정답 레이블이 없기 때문에 현실적이지 않은 방법일 수 있다. 소규모의 벤치마크 데이터셋을 통해서 전체 성능을 예측하기도 하지만, 이 역시 한계가 있다.
해당 파트에서는 entity resolution의 성능을 평가하기 위해 데이터를 라벨링하고 성능을 평가하는 두가지 기법에 대해서 설명한다.
1️⃣ Pairwise Approach
쌍별 접근법은 precision을 계산할 때, '매치됨'이라고 판단한 레코드에서 무작위로 몇 개 뽑은 뒤, 사람이 진짜 매칭되는 것인지 판단하여 비율을 계산할 수 있다. 예를 들어 100개의 매칭된 쌍을 뽑은 뒤 사람이 직접 판단해서 이 중 90개만 실제로 매칭된다면 precisiondmf 90%로 판단할 수 있는 것이다.
recall의 경우, 실제로 같은 개체인 경우에서 얼마나 매칭을 했는지를 판단해야 하기 때문에 보다 복잡하다. 예를 들어, 한 그룹에서 같은 사람인 쌍이 총 100개 있는데 시스템이 80개만 찾은 경우 80%라고 판단할 수 있지만, 같은 사람인 경우 100개를 찾기 위해서 탐색해야 하는 케이스는 훨씬 많아지기 때문이다.
2️⃣ Cluster-Based Approach
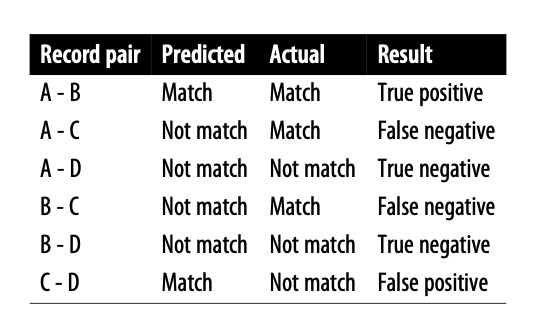
쌍별 접근법의 대안은 정답 클러스터를 수동으로 결정하는 방법이다. 예를 들어 A, B, C, D라는 사람이 있고 실제로는 (A, B, C)가 같은 사람이지만, 매칭 결과는 (A, B), (C, D)가 매칭되었다고 가정한다. 쌍별 비교를 했을 때, 6개의 매칭의 결과가 위 표와 같다고 했을 때, 3개는 맞췄고 3개는 틀렸다. 이 결과를 클러스터로 표현하면 아래 그림과 같다.
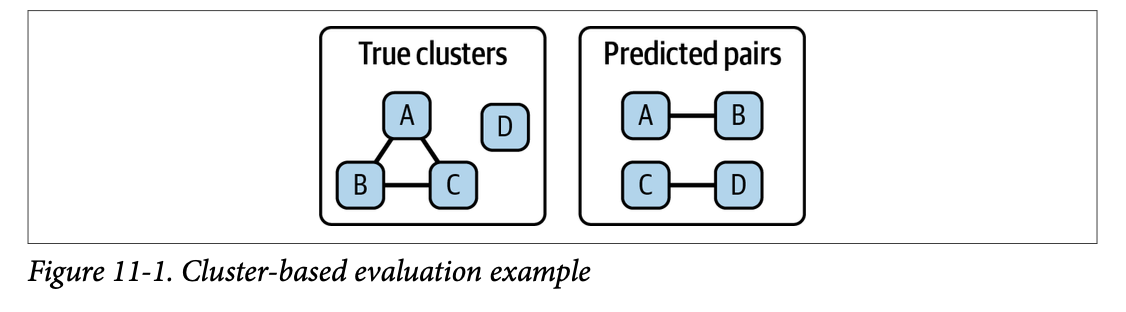
이 방법은 전체적인 성능을 정확하게 파악할 수 있다는 장점이 있지만, 모든 쌍을 사람이 직접 판단해야 해서 데이터가 큰 경우에는 사용하기 어렵다는 한계가 있다.
🧩 Future of Entity Resolution
Entity Resolution은 여러 출처의 정보들을 모아서 인사이트를 얻고 궁극적으로 더 나은 결정을 내리기 위한 수단으로써 사용될 수 있다. 잘못된 정보를 갖고 있거나, 부분적인 정보는 잘못된 결론을 내릴 위험이 있으며, 민감한 데이터가 이슈를 만들 수 있으므로, entity resolution을 통해 데이터를 연결해서 더 큰 그림을 볼 수 있도록 하고 불필요한 개인정보 공유를 막을 수 있다. 최근에는 ML뿐만 아니라 LLM을 통해서 개체들의 상호 연결 관계와 맥락을 파악할 수 있게 되었다. 또한 성능 평가와 최적화 기법들도 점차 발전하고 있으며, 앞으로 더욱 풍부한 결과물을 얻을 수 있는 가능성이 있다.
