
- 스터디 책: Hands-On Entity Resolution
- 깃헙: https://github.com/mshearer0/HandsOnEntityResolution
Entity Resolution을 진행할 때, 데이터 안에 민감한 정보가 있는 경우가 발생할 수 있다. 이때 활용가능한 기법이 PSI(Private Set Interaction)인데, PSI는 두 데이터셋 사이에서 교집합을 식별하되, 교집합에 속하지 않는 요소는 공개하지 않는 암호화 기법이다. 실제로 금융기관에서 다른 기관에 공통 고객이 있는지 확인하고 싶을 때, 공통된 개인들의 정보만 공개하고 그 외의 고객들은 공개하지 않을 때 사용할 수 있다.
PSI는 일반적으로 일방향으로 적용된다. 즉, 매칭을 하는 한 쪽에서만 교집합의 정보를 식별할 수 있어 보안상의 이점을 갖게 되는 것이다.
How PSI Works
PSI가 수행되는 가장 간단한 방법은 서버가 자신의 전체 데이터셋을 클라이언트에게 전송하고, 클라이언트가 매칭 과정을 진행해서 교집합을 확인하는 것이다. 그러나 서버 데이터가 너무 크거나 전체 데이터를 공개하고 싶지 않은 경우에는 이 방법을 사용할 수 없다.
대안으로 제시되는 방법은 naive PSI로, 양측이 동일한 매핑(해시)함수를 각자 데이터에 적용해서 변환된 값을 기반으로 교집합을 도출하는 방식이다. 일반적으로 흔히 사용되는 함수는 Crytographic Hash Functions로, SHA-256과 같은 해시 알고리즘이며, 임의의 이진 문자열을 고정 크기(256비트)의 digest로 변환한다.
한편, 해시 함수의 한계점으로는 보안상 문제가 발생할 수 있다는건데, 만약 악의적인 클라이언트가 미리 방대한 원본-해시값 테이블(rainbow table)을 준비한뒤, 서버에서 받은 해시값들을 이 테이블을 통해 원본 데이터를 역추적 할 수 있다는 것이다. 따라서 보다 강력한 암호화 해시 함수가 필요하며,
교안에서는 발전된 PSI 기술로 ECDH(Elliptic Curve Diffie-Hellman) 프로토콜을 예시로 제시한다.
PSI Protocol Based on ECDH
basic PSI 프로토콜은 다음과 같이 작동된다. 이때 사용하는 commutative encryption(교환 암호화)은 두개의 서로 다른 키로 이중 암호화했을 때, 키를 사용하는 순서와 관계 없이 올바르게 복호화할 수 있는 암호화 방식을 의미한다. 다음 예시를 통해서 알아보자.
- 클라이언트가 자신의 데이터를 commutative encryption scheme을 활용해서 암호화한다. 예를 들어, 클라이언트가 {'Apple', 'Orange', 'Banana'}라는 값을 갖고 있을 때, 이를 각각
Encrypt_A('Apple'),Encrypt_A('Orange'),Encrypt_A('Banana')함수를 통해서 C1, C2, C3로 변환하는 것을 의미한다. - 클라이언트는 암호화된 요소들을 서버에 전송한다. C1, C2, C3를 보낸다는 의미이다.
- 서버에서는 받은 값들을 추가 암호화해서 반송한다. 예를 들어, 서버는
Encrypt_B(C1),Encrypt_B(C2),Encrypt_B(C3)와 같이 암호화해서 BC1, BC2, BC3를 만들어서 클라이언트에게 다시 보낸다. - 클라이언트는 받은 BC1, BC2, BC3를 통해서 교환 암호화의 특성을 파악하고,
Decrypt_A(BC1),Decrypt_A(BC2),Decrypt_A(BC3)를 통해서 B1, B2, B3를 도출한다. - 서버는 자신의 전체 데이터셋을 같은 키로 암호화해서 전송한다. 서버가 기존에 {'Apple', 'Orange', 'Strawberry', 'Kiwi'}라는 값을 가졌을 때, 이를 B1, B2, B4, B5로 암호화하는 것이다. 이제 암호한 값을 클라이언트에게 전송한다.
- 클라이언트는 교집합을 발견할 수 있다. 이때의 교집합은 B1, B2이다.
이때 5단계에서 모든 서버의 암호화한 데이터를 전송하는 과정은 비효율적일 수 있다. 따라서 인코딩 기법을 사용하여 오탐지 비율이 높아지지만, 데이터 전송량을 획기적으로 줄일 수 있으며, 이때 사용하는 두가지 주요 기법은 Bloom Filters와 GCSs(Golomb-Coded Sets) 이다.
1️⃣ Bloom Filters
Bloom Filters는 데이터 요소가 집합에 존재하는지를 매우 효율적으로 저장하고 확인할 수 있는 확률적 데이터 구조이다. 초기에는 모든 비트가 0으로 초기화된 배열로 구성되며, 요소를 추가할 때에는 여러 해시를 함수를 통해서 출력된 결과를 필터의 비트 위치에 매핑하여 해당 비트 위치를 1로 설정한다. 이후 요소의 추가 결과를 확인하려면 그 요소의 모든 특징이 필터에 기록되었는지 확인하면 되는데, 최종 결과가 하나라도 0이면 확실히 존재하지 않는다는 것을 알 수 있고(이전의 기록과 겹치지 않는다는 의미이므로) 모두 1이라면 존재할 수도 있는 가능성이 있다는 것을 의미한다. 그러나 모두 1이라도 존재하지 않을 수도 있으므로(이전의 요소들과 부분적으로 모두 일치한 경우일 수도 있으므로) 거짓 양성의 가능성이 생긴다.

위 수식을 살펴보면, fpr은 false positive rate(거짓양성률)로, 낮을 수록 더 정확하지만 큰 필터가 필요하고, max_elements는 클라이언트와 서버의 데이터셋의 최대 요소 수를 의미한다. 즉, 원하는 거짓 양성률을 달성하기 위한 최대 비트수를 계산하는 공식인데, fpr이 0.01이고 max_elements가 백만개라면, 백만개 요소를 1%의 오류률로 저장하려면 약 19KB가 필요하다는 결론을 도출할 수 있다.
즉, bloom filters를 사용하면 클라이언트가 처리하기 용이한 크기로 감소되어 메모리를 절약할 수 있으며, 빠른 속도로 교집합을 확인할 수 있다는 장점이 있으며, 한편으로는 거짓 양성이 발생할 가능성과 약간의 복잡성이 증가할 수 있다는 한계가 있다.
Bloom filter example
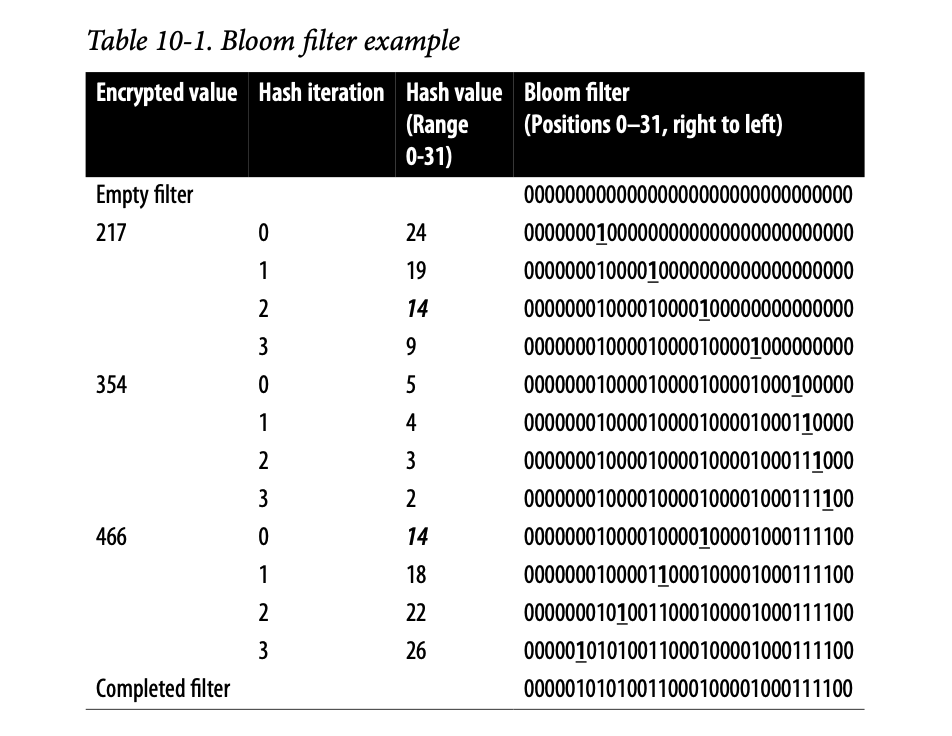
이제 예시를 통해서 다시 확인해보자. 32비트 길이의 bloom filters가 있고, 각 값마다 4개의 해시값을 생성한다고 했을 때 다음과 같이 해시 계산이 된다.
Hash1 = SHA256(Encrypted_value prefixed by "1") % 32
Hash2 = SHA256(Encrypted_value prefixed by "2") % 32
Hash_Value = (Hash1 + Iteration_number × Hash2) % 32이때 아래 표와 같이 빈 필터일 때는 전체가 0이지만, 값 217, 354, 466이 추가될 때마다 해시값이 해당 위치에 표시된다. 이때 값이 충돌되는 경우가 있는데, 예를 들어, 217의 세번째 해시값과 466의 첫번째 해시값운 모두 14로 동일하다. 그러나 해시를 4번 반복하여 최종값을 계산하므로, 이 둘은 구분이 가능해진다.
2️⃣ Golomb-Coded Sets
GCS(Golomb-coded sets)는 Bloom filters와 같이 확률적으로 데이터셋의 존재 여부를 확인할 수 있도록 인코딩하는 방법이며, 효율적이라는 특징이 있다. GSC는 다음과 같은 과정으로 수행된다.
1. 해시값 생성
- 범위:
Hash_range = max_elements / fpr - max_elements가 1000이고 fpr이 0.01일때 해시값은 0~100000 사이의 값을 갖는다.
2. 정렬
- 해시값들을 오름차순으로 정렬한다.
3. 분할자 계산
-
GCS_divisor_power_of_2 = max(0, round(-log₂(-log₂(1.0 - prob)))),prob = avg / (last_element + 1)
큰 숫자를 두 부분으로 나눠서 압축률을 높이는 방법이다. 분할자가 2의 거듭제곱인 경우를 Rice encoding이라고 하며, 다음 예시를 통해 이해할 수 있다.avg = number_elements_in_ascending_list = 4 last_element = 89,456 prob = avg / (last_element + 1) = 4 / (89,456 + 1) = 4 / 89,457 ≈ 0.0000447 GCS_divisor = max(0, round(-log₂(-log₂(1.0 - prob)))) 1.0 - prob = 1.0 - 0.0000447 = 0.9999553 log₂(0.9999553) ≈ -0.0000644 -log₂(-0.0000644) ≈ -(-14.0) = 14.0 round(14.0) = 14 GCS_divisor = 14이 경우 2^14 = 16384를 분할자로 사용한다.
4. 차이값 계산
- 다음은 차이값을 계산하는 단계로, 해시값들을 차례로 빼서 차이값을 구한다. 만약 해시값이 동일해서 0이 나오는 경우, 0은 제거한다(정보가 없으므로). 이 차이값들을 '델타 해시값'이라고 한다.
- 이러한 델타 해시값들을 이전에 계산된 GCS 분할자의 2제곱으로 나눕니다. 위 예시에 따르면 2^14인 16384로 델타값을 나눈다는 의미이다.
5. 인코딩
-
위에서 나눈 값의 몫과 나머지를 기반으로 인코딩을 실시한다. 몫은 단항코딩(0과1로만 표현하는 것)으로 표현하고, 나머지는 이진법으로 표현하되, 최대 길이를 분할자와 동일한 비트로 나타내어 나머지는 0으로 패딩을 진행한다. 예를 들어 100을 이진법으로 표현하면 1100100인데, 14비트로 표현하면 앞에 0을 추가해서 맞춰준다는 의미이다.
델타 8,132: - 몫 0 → "1" - 나머지 8,132 → "01111111000100" - 결합: "1" + "01111111000100" = "101111111000100" 델타 27,657: - 몫 1 → "01" - 나머지 11,273 → "10110000001001" - 결합: "01" + "10110000001001" = "0110110000001001" 델타 46,565: - 몫 2 → "001" - 나머지 13,797 → "11010111100101" - 결합: "001" + "11010111100101" = "00111010111100101" -
최종적으로 몫과 나머지 인코딩 결과를 결합해서 표현한다. 전체를 다 더하면 총 48비트가 나오는데, 기존의 방식으로 하면 32비트*3 만큼의 크기이므로 이것보다 훨씬 효율적인 공간 활용이 가능하다.
GCS는 효율적인 압출을 통해서 빠른 검색이 가능하고 해시 충돌로 인한 False Positive(없는데 있다고 하는 경우는 가능하지만, False Negative(있는데 없다고 하는 경우)는 논리적으로 발생할 수 없다는 특징이 있다.
