
대학원 수업 과제로 온톨로지, 지식그래프, LLM 융합 관점의 논문들을 서치하고, 연구동향을 파악해보았다. 포커스는 KGs를 구축하는 관점과 LLM의 한계점이나 성능 향상에 KGs를 활용하는 측면으로 접근했고, 위와 같은 상호 보완적 관계를 정리할 수 있었다. 보고서는 공유할만큼 잘 정리하진 못한듯하여 제외하고(다음에 좀더 다듬어서 포스트로 작성해보겠음), 작성 과정에서 검토한 논문들을 주제별로 정리하여 공유하려 한다. Ontology-driven Agents Architecture 부분은 다소 미흡한 점이 있다는 것을 유의해주길..!
.
.
.
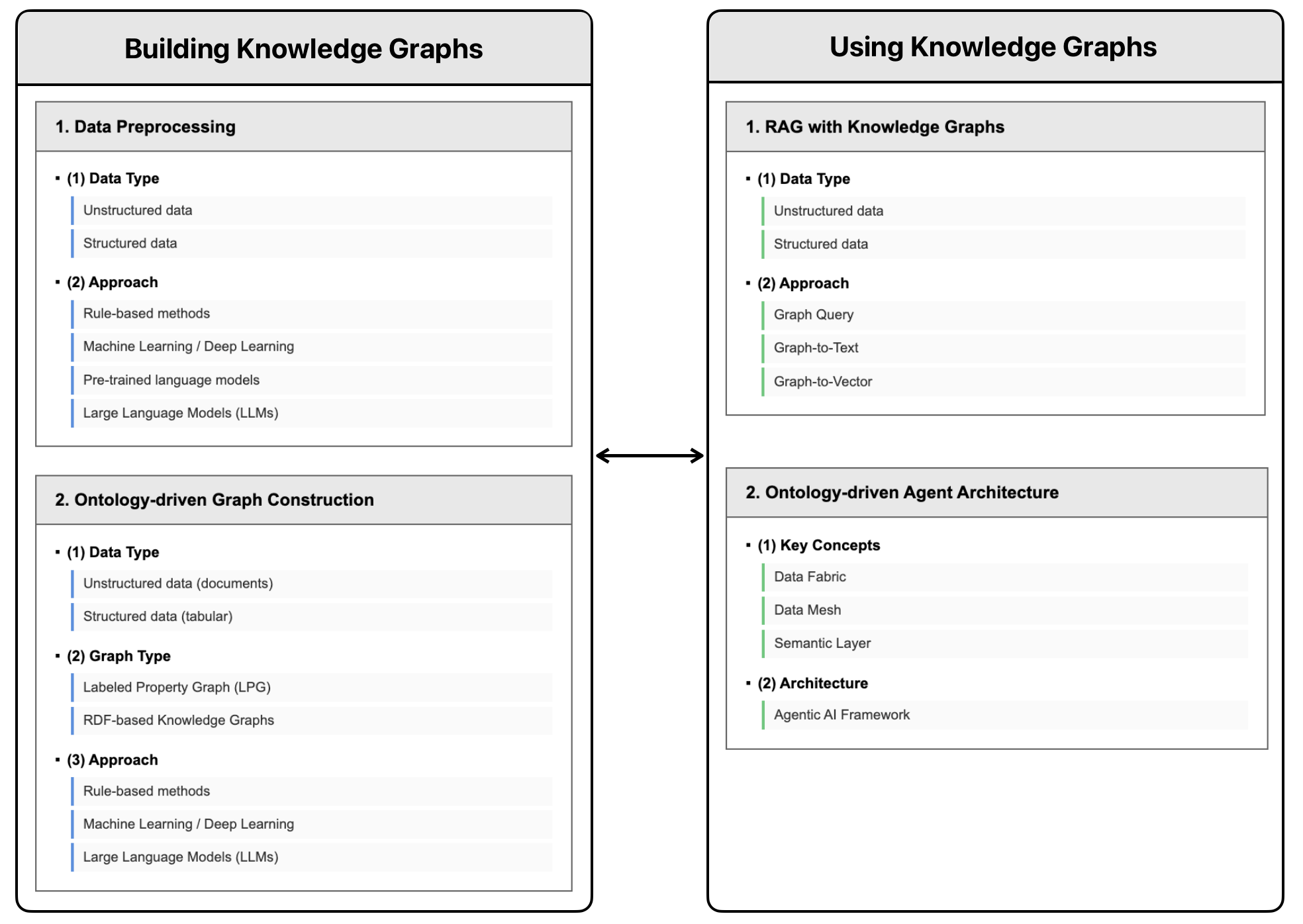
✅ Structure Overview
- Towards a definition of knowledge graphs(Ehrlinger, L., & Wöß, W., 2016)
- KGs의 정의를 논의한 논문
- Unifying large language models and knowledge graphs: A roadmap(Pan, S., Luo, L., Wang, Y., Chen, C., Wang, J., & Wu, X., 2024)
- KGs와 LLM을 함께 사용하는 융합 관점을 다룬 논문. 상호보완적 관계로 인식한다는 점에서 본인의 보고서와 같은 유사한 맥락을 가지고 있음
- Converting Property Graphs to RDF:A Preliminary Study of the Practical Impact of Different Mappings(Khayatbashi et al., 2022)
- LPG와 RDF 그래프를 구조적으로 비교한 논문
✅ Building KGs
Data Preprocessing
[Before LLM]
- Holoclean: Holistic data repairs with probabilistic inference(Rekatsinas, T., Chu, X., Ilyas, I. F., & Ré, C., 2017)
- 데이터 제약 조건과 통계적 특성을 활용한 확률적 모델링을 통해 오류를 자동으로 탐지하고 수정하는 'HoloClean' 모델을 제안한 논문
- New data preprocessing trends based on ensemble of multiple preprocessing techniques(Mishra, P., Biancolillo, A., Roger, J. M., Marini, F., & Rutledge, D. N., 2020))
- 다양한 통계 기반 전처리 기법을 결합하고, 최적의 조합을 탐색하기 위해 머신러닝을 결합한 접근을 시도한 논문
- Automated datapreprocessing for machine learning based analyses
- 특징 생성 및 샘플링 등 전처리 단계 전반을 자동화하는 머신러닝 기반 파이프라인을 제시한 논문
- Holodetect: Few-shot learning for error detection(Heidari, A., McGrath, J., Ilyas, I. F., & Rekatsinas, T., 2019)
- 소량의 라벨과 데이터 증강 기법을 결합하여 오류 탐지를 학습하는 딥러닝 기반 프레임워크를 소개한 논문
[After LLM]
-
- (프롬프트 기반 전처리) LLM이 컬럼 단위로 데이터 그룹핑, 오류 탐지, 검증, 수정을 반복하는 방식의 전처리 프레임워크를 제안한 논문. 약 5개 정도의 소량의 레이블만으로도 오류 패턴을 인식하도록 하고, 단계별로 오류를 탐지하고 수정하는 과정을 추가하여 기존의 규칙, ML 기반 방식보다 높은 정제 성능을 보였음
-
Large language models as data preprocessors(Zhang, H., Dong, Y., Xiao, C., &Oyamada, M., 2023)
- (프롬프트 기반 전처리) 레코드 단위로 각 튜플을 자연어 형식으로 변환하고, zero-shot, few-shot 등을 활용해 오류를 탐지하며 값을 보완하는 등의 전처리 작업을 수행했으며, 코드 없이 프롬프트만으로 다양한 데이터 품질 문제를 해결할 수 있다는 것을 실증한 논문
-
Cleanagent: Automating datastandardization with llm-based agents(Qi, D., Miao, Z., & Wang, J., 2024)
- (코드 기반 전처리) Multi-Agents 구조를 기반으로 테이블 내 컬럼 유형을 자동으로 분류하고, 사전에 정의한 파이썬 기반 전처리 함수를 호출하여 실행하는 'CleanAgent'를 제안한 논문. 사용자 개입을 최소화한 상태에서 주소, 날짜, 전화번호 등 다양한 유형의 데이터를 일관된 형식을 표준화할 수 있음
-
Data cleaning using largelanguage models(Zhang, S., Huang, Z., & Wu, E., 2025).
- (코드 기반 전처리) Cocoon 시스템을 통해 오류 유형 세분화, 각 오류에 대해 통계기반 탐지와 LLM기반 의미 분석, 수정의 단계를 거치고 중간 추론 과정에서 사람이 검토하는 human-in-the loop 구조를 사용한 논문 최종 정제는 SQL 쿼리를 통해 수행함으로써 LLM이 갖는 전처리의 유연성과 재현성, 추적성, 설명가능성을 동시에 확보했음
-
Jellyfish: A Large Language Model for Data Preprocessing(Zhang et al., 2024)
- 데이터 전처리를 위해 instruction tuning을 했다는데, instruction dataset을 가지고 fine-tuning을 했다는 것 같음. 데이터 전처리와 관련된 선행 연구 부분이 탄탄함
[LLM을 활용해서 비정형 텍스트를 학습데이터로 사용하려는 연구]
- Large Language Models as Advanced Data Preprocessors:Transforming Unstructured Text into Fine-Tuning Datasets(Vangeli, M., 2024)
- Are Large Language Models Good Data Preprocessors?(Meguellati, E., Pratama, N., Sadiq, S., & Demartini, G., 2025)
Ontology-driven Graph Construction
[LPG vs. RDF Graph]
-
- 지식그래프로의 변환은 데이터의 구조적, 의미적 특성을 그래프 형태로 모델링하는 과정으로 이해할 수 있으며, 이때 그래프의 형식에 따라 구체적인 방식을 구분할 수 있다는 내용을 언급한 논문
-
- BIM(Building Information Modeling) 데이터를 효과적으로 저장, 검색하기 위해 지식그래프를 도입하는 과정에서 두 가지 대표 그래프 모델인 LPG와 RDF 기반 그래프의 장단점을 비교, 평가한 논문. 연구에 따르면, LPG는 명시적 관계를 탐색하는 질의 수행에서 우수한 속도를 보였으며, Cypher 언어의 직관성에 따라 비전문가에게 접근성과 실용성이 높게 나타났음. 반면, RDF 기반 그래프는 데이터 정합성과 온톨로지 기반 추론에서는 강점을 보였으나, triple-indexing 구조(spo구조의 모든 조합별 인덱스를 생성하는 방법)와 OWA(Open World Assumption; 데이터에 없는 정보를 존재하지 않는게 아니라 알려지지 않은 것으로 간주하는 논리적 전제. 온톨로지 추론 시 추가적인 가능성을 고려해서 의미적 추론이 가능해지지만 계산 복잡도가 높아짐)으로 인해 대규모 그래프 모델에서는 상대적으로 높은 저장 비용과 느린 질의 성능을 보였음. 또한 RDF 기반 그래프는 의미적 일관성을 유지하면 복잡한 처리를 할수 있는 반면, LPG는 논리적 추론보다는 명시적 관계 탐색과 구조적 유연성에 최적화되어 있다는 특징이 있음
-
- LPG로 표현된 데이터를 RDF로 변환하기 위한 매핑 방식을 (1) RDF 기반 매핑과 (2) RDF-star 기반 매핑의 두 가지 접근을 비교한 논문. 전자는 엣지를 중간 노드로 변환하여 관계를 여러 트리플로 표현하는 방식으로, 표준 호환성이 높지만 트리플 수의 급증과 복잡한 조인으로 인해 질의효율성이 떨어지는 경향이 있었음. 반면 RDF-star 기반 매핑은 엣지를 인용된 트리플(quoted triple)로 표현하여 속성을 직접 부여함으로써 모델을 단순화하고 구조적 대응성을 향상시켰음. 실험 결과, 두 방식 모두 절대적 우위를 보이지 않았으나, RDF-star는 데이터 변환의 간결성과 엣지 속성 질의의 효율성 측면에서 유의미한 개선을 보여, RDF기반 그래프와 LPG 간 구조적 차이를 최소화하면서 RDF의 의미론적 표현력을 유지하는 통합 접근의 가능성을 제시했음
[Before LLM]
-
- 도메인 문서에서 개념 후보를 식별하고, 통계적 연관성과 그래프 탐색 규칙을 결합한 ‘GRAONTO 모델’을 통해 자동 온톨로지 구축을 시도한 논문
-
- 딥러닝 기반 정보추출 파이프라인을 중심으로, 사전 스키마 없이 비정형 텍스트로부터 엔티티와 관계를 추출하는 다양한 접근을 비교한 논문
-
A Comprehensive Survey on Automatic Knowledge Graph Construction(Zhong et al., 2023)
- 지식그래프 자동 구축에는 여전히 근본적인 한계가 존재하며, 이는 HACE(Heterogeneous, Autonomous, Complex, Evolving) 환경, 즉, 데이터의 이질성, 자율성, 복잡성, 지속적변화성에 기인한다고 지적했음. 또한 이러한 복합적 문제를 해결하기 위한 기술적 발전의 흐름을 지식 획득(KnowledgeAcquisition), 지식 정제(Knowledge Refinement), 지식 진화(Knowledge Evolution), 지식 응용(KnowledgeEvolution) 네 단계로 체계화했음
[After LLM]
-
- LLM을 활용한 TBox 수준의 스키마 설계를 다룬 연구. 모듈 기반 온톨로지 모델링(MOMo) 접근법을 바탕으로, 대규모 온톨로지를 개념 단위로 분할하여 LLM이 처리하기 용이한 구조로 재구성하는 방식을 제안하였음. 이를 통해 LLM이 온톨로지의 설계, 확장, 정렬 등의 작업을 모듈 단위로 수행하도록 하여 자동화 효율과 개념적 일관성을 동시에 확보할 수 있음을 보였음. 또한, 모듈화된 구조가 인간 전문가의 개입을 최소화하면서도 복잡한 도메인 온톨로지의 생성과 관리에 효과적임을 실험적으로 입증하였음.
-
- 프롬프트 기반의 자동 온톨로지 생성 프레임워크를 제안한 논문. LLM을 활용해 온톨로지 스키마(TBox)를 자동 구성하고, 품질을 정량적으로 평가하는 방법을 탐구하였다. 개념 정의, 계층 구조 설정, 관계 도출 등 온톨로지 구축 전 과정을 일련의 프롬프트 체인으로 설계하였으며, 생성된 온톨로지를 표준 온톨로지와의 정합도(consistency)와개념적 완전성(completeness) 기준으로 평가하였음. 실험 결과, LLM이 전문가 수준의 스키마 설계를 상당 부분 대체할 수 있음을 확인하였으며, 특히 도메인 텍스트에 기반한 지식 구조화 과정에서 높은 정확도를 보였음
[TBox + ABox까지 반자동으로 구축을 시도한 논문]
-
- LLM을 활용하여 (semi-)automatic하게 KG를 구축하는 방법
-
- 전통적으로 인간 전문가가 수행하던 온톨로지 설계와 그래프 구축과정을 LLM을 통해서 보완하고자 했는데, CQ(Competency Question)기반 접근을 통해 LLM이 도메인 요구사항을 식별하고 이를 바탕으로 온톨로지 스키마 구축을 수행하며, 전문가의 최소 개입으로도 지식그래프의 일관성과 완성도를 일정 수준 확보할 수있음을 보였음. 또한 이를 확장하여 LLM이 생성한 개념, 속성, 인스턴스 간 교차 정확도를 분석하여 ABox와 연계 자동화의 실현 가능성을 실증하였는데, 텍스트 기반 문서 데이터에서 엔티티를 추출해 그래프를 자동으로 채우는 과정을 통해 지식그래프 구축의 전 과정을 인간 전문가의 보조 역할 수준으로 자동화할 수 있음을 강조했음
✅ Using KGs
RAG with KGs
[GraphRAG Overall]
-
Retrieval-Augmented Generation with Graphs (GraphRAG) (Han et al., 2025)
-
- (RAG vs. GraphRAG) RAG와 GraphRAG를 체계적/정량적으로 비교하였으며, 이때 GraphRAG를 전통적 KG 기반의 GraphRAG와 그래프 커뮤니티 구조와 계층적요약을 활용하는 방식의 GraphRAG 계열로 구분하여 분석했음. 실험 결과, KG 기반 방식은 구조적 명확성이 있으나 정보 누락 시 성능 저하가 발생하는 반면, 커뮤니티 기반 GraphRAG는 전역 문맥, 개념적 연결성을 파악하고 복합 추론(multi-hop reasoning)을 수행하는데 특히 강점을 보였음. 반면, 세부 문장 단위 정보 회수나 단일 hop 질의에서는 기존 RAG가 더 뛰어났다. 결론적으로, 그래프 기반 접근은 RAG를 대체하는 기술이 아니라, RAG가 놓치기 쉬운 관계 정보나 전역 요약, 추론 능력을 보완하는 기술이며, 질의 유형에 따라 RAG와 GraphRAG을 선택하거나 통합하는 하이브리드 전략을 취할 수 있음
-
- Graph RAG와 관련된 서베이 논문. 구축된 지식그래프를 기반으로 적절한 정보를 검색하기 위한 구체적 전략은 크게 세 가지 범주로 구분함.
[GraphQuery]
-
PAROT: Translating natural language to SPARQL(Ochieng, P., 2020)
- PAROT 시스템을 통해 규칙 기반 구문 분석과 온톨로지 매핑을 통해 자연어 문장을 SPARQL 쿼리로 정형화했음
-
- 질의 분석, 엔티티, 관계 매핑, 후보 쿼리 생성 및 랭킹으로 구성된 모듈형 파이프라인을 설계하여 통계 기반 기법으로 성능을 개선했음
-
- 논문에서 제안한 SPARQLGEN은 별도의 학습 없이 LLM을 활용하기 위해 질문, 예시 쿼리, 그리고 해당 질의를 해결하는 데 필요한 서브그래프를 하나의 프롬프트에 결합하는 ‘One-Shot SPARQL’ 방식임
-
- 질의에 관련된 온톨로지(T-Box)와실제 인스턴스(A-Box)의 일부만을 선택해 LLM에 제공하고, 여러 후보 SPARQL을 생성 후 실행 결과를 비교하여 최적 쿼리를 선택하는 구조를 제안했음
-
- 1B 미만의 소형 언어모델을 미세조정하여 Text2SPARQL 과제를 수행할 수 있음을 보였으며, LLM에 비해 비용과 운영 측면에서 효율적인 대안을 제시했음
[Graph2Text]
-
From local to global: A graph rag approach to query-focused summarization(Edge et al., 2024)
- (GraphRAG 논문) 문서에서 엔티티와 관계를 추출하여 그래프 형태의 인덱스를 구축하고, 커뮤니티 탐지 알고리즘(Leiden 등)을 통해 의미적으로 밀접한 엔티티 집합을 그룹화한 뒤, 각 그룹 단위로 요약을 생성하고, 이를 질의 시 병렬적으로 활용하는 방식. 즉, 그래프 커뮤니티 단위에서 계층적 요약을 생성해 다단계 map-reduce 방식으로 글로벌 응답을 도출함으로써, 단순한 근접 텍스트 청크 검색을 넘어 데이터 전체의 주제 구조, 개념 연결성, 전역적 패턴을 추론할 수 있음. 실험 결과, GraphRAG는 기존 RAG 대비 대규모 텍스트 코퍼스에서 보다 포괄적이고 다양한 응답을 제공하여 전역적 의미 파악과 복합 질의 처리에서 우수한 성능을 보였으며, 특히 반복 질의가 수행되는 환경에서 계산 자원을 절약하면서도 높은 정보 포괄성을 유지할 수 있었음
-
- (LightRAG 논문) MS의 GraphRAG가 커뮤니티 기반 전역 요약을 통해 전통적 RAG의 전역 문맥 파악 한계를 개선하였으나, 대규모 그래프를 생성하기 위해서는 막대한 시간과 비용이 소요되며 업데이트가 어렵다는 문제가 있었음. LightRAG은 보다 경량화된 그래프 기반 RAG 프레임워크로, 문서에서 엔티티-관계를 추출해 지식 그래프를 구축한다는 공통점을 갖지만, 커뮤니티 요약 방식 대신 키-밸류 기반의 그래프 인덱싱과 이중 수준의 검색 전략을 활용함. 구체적으로, 특정 엔티티 중심의 세부 검색(low-level retrieval)과 광범위한 주제 개념 탐색(high-level retrieval)을 결합함으로써, 구조적 정보와 개념적 정보의 균형 잡힌 회수가 가능하도록 설계했음. 또한, 커뮤니티 전체를 재구성해야 하는 GraphRAG와 달리, LightRAG은 증분 업데이트를 지원하여 새로운 문서나 지식이 추가되었을 때 전체 그래프를 재생성할 필요가 없다는 점에서 비용 효율성과 실시간성을 확보했음. 실험 결과, 다양한 도메인에서 LightRAG은 기존 RAG뿐 아니라 GraphRAG 대비도 우수한 질적 응답을 보이며, 특히 복합 의미 이해, 전역문맥 수용, 응답 다양성, 업데이트 효율성 면에서 경쟁력을 입증했음.
[Graph2Vector]
- G-retriever: Retrieval-augmented generation for textual graph understanding and question answering(He, X., Tian, Y., Sun, Y., Chawla, N., Laurent, T., LeCun, Y., ... & Hooi,B., 2024)
- (G-Retriever 논문) 노드, 엣지, 속성 정보를 텍스트로 변환해 언어모델이 인식 가능한 형태로 재구성한 뒤, LLM을 이용해 그래프의 지역 구조를 이해하고 이를 기반으로 검색 및 응답 생성을 수행하는 기법을 제안했음. 특히, 그래프 주변 구조를 문장화하여 임베딩함으로써 그래프 파편을 효율적으로 비교할 수 있도록 하였으며, 질의와 유사한 의미 구조를 가진 서브그래프를 검색해 LLM이 참조하도록 설계했음. 이러한 방식은 그래프 쿼리 언어나 커뮤니티 요약 없이도 구조적 연결성을 유지한 상태로 의미 검색을 수행할 수 있다는 장점이 있음
- GRAG: Graph Retrieval-Augmented Generation(Hu et al., 2024)
- (GRAG 논문) 그래프의 k-hop 이웃 서브그래프를 LLM이 처리 가능한 시퀀스 형태로 변환한 뒤 임베딩하여 저장하고, 질의 시 해당 임베딩을 기반으로 관련 서브그래프를 검색하는 방식을 제안함. GRAG는 기존 RAG가 단순 벡터 검색에 의존하여 구조적 관계를 놓칠 수 있다는 문제를 지적하며, 그래프 구조 정보가 보존된 벡터 표현을 활용함으로써 multi-hop reasoning 및 관계 기반 추론 성능을 강화했음
Ontology-driven Agent Architecture
-
- 비구조 문서를 Property Graph로 자동 변환하는 상용 서비스
-
- 통계값이나 CSV 기반 테이블 데이터를 통합 지식 그래프 형태로 제공하는 대규모 공개 데이터 인프라로, 이를 기반으로 한 Data Gemma 프로젝트는 구조화 된 데이터를 LLM이 활용할 수 있도록 하는 방식을 제안함. 자연어 질의를 분석하여, 구조화된 데이터소스에 질의할지 결정한 뒤, LLM이 데이터를 임의로 추론하는 대신 데이터베이스 쿼리를 구성해 정확한 값을 반환하도록 하는 방식으로 구성되고, LLM이 비정형 텍스트뿐 아니라 구조화된 데이터와 지식그래프를 혼합적으로 활용할 수 있는 방법을 보여주며, 데이터 기반 질의 응답 환경에서 근거를 기반 응답함에 따라 신뢰성과 정확성을 확보하는 방향으로 연구가 확장되고 있음을 보여줌
-
Gartner - How Data Fabric Can Optimize Data Delivery
- Gartner의 Data Fabric, Data Mesh 관련 문서
-
SalesForce - The Agentic Enterprise - The IT Architecture for the AI-Powered Future
- Data Fabric, Mesh, Semantic Layer를 다룬 문서
-
Stardog - Agents Need Democratized Data Too
- Semantic Layer, data fabric을 다룬 문서
-
Ontotext - What Is a Semantic Layer?
- Semantic Layer를 다른 문서
