

이 개발의 시작은 2024년 6월이다. RAG가 뜨기 시작함을 지나서 Langchain, LlamaIndex 등이 활발하게 사용되고 LangGraph가 소개되기 시작하던 시점이었던 것 같다. LLM, RAG 등 조금씩 공부하던 나에게 연구실 주제 기반의 특화 챗봇을 만들보라는 태스크가 주어졌고, 그렇게 몇 개월 간의 고군분투가 시작된 것이다.
사실 이 개발기는 현재 진행중이며, 지금은 ver2로 넘어가는 중이다. 작년 12월 정도 부터 지금 현재는 열심히 Agent를 활용한 코드를 테스트 중이다. ver2로 완전히 넘어가기 전에 ver1에 대한 마무리지어야 겠다는 생각에 늦었지만 이 글을 통해서 정리해보려 한다.
RAG 기반의 시스템을 만들 때는 여러가지 고려 사항이 있다. 데이터를 전처리해서 임베딩하고 벡터 데이터베이스에 저장하는 과정까지만 해도 수많은 고려 사항들이 있고, 저장 데이터를 어떻게 검색할 것인지(어떤 방법으로)와 관련된 테스트는 정말 수도 없이 많다. 마치 과거에 ML 모델을 학습시킬 때 Hyper-parameter를 찾는 방식이나, clustering을 할때 최적의 K를 찾기 위해서 elbow-method를 사용했던 것들이 기억났다. 결국은 굉장히 Heuristic한 방법이라는 것이다.
몇 개월 간 여러가지 테스트를 해보면서 얻은 것은 결국 '경험치'였다. PDF문서를 전처리 할 때 어떤 모듈을 써야 하는지, chunk size나 Overlap은 어느 정도가 적절하며 일반적인지 등 부터 시작해서 임베딩 모델은 이제 조금 비싸도 OpenAI의 text-embedding-3-large를 거의 고정해서 사용하는 것도 다양한 오픈소스 모델까지 테스트 해보고 난 뒤의 결론이다.
물론, 나보다 훨씬 훌륭하신 분들이 미리 테스트 해보고 정리한 문서들의 도움을 정말 많이 받았다. RAG를 공부하는 사람들 대부분(아마도 100% 확률로) 아래의 위키독스들을 참고하고 활용했을 것이라 생각한다.
그럼에도, 이 문서들의 내용을 실제로 다 테스트 해보고 최종 개발까지 해본 경험은 개인적으로 굉장히 많은 도움이 되었으며, 실시간으로 등장하는 새로운 기술들을 받아들이는데 어려움이 적어지고 있다는 걸 체감하고 있다. 올 초부터는 혼자 공부하던 내용들을 연구실 구성원들과 공유하며 같이 공부를 시작해나가려는데, 해줄 수 있는 말이 실제로 코드를 사용해보면 익히고, 개념적인 부분은 매일매일 tracking해나가야 한다는 말 밖에 해줄 수 없었지만, 정말 사실이다.
지금부터는 실용적인 이야기를 해보려 한다.
RAG를 처음 접했을 때부터 프레임워크는 langchian을 사용했고, DB는 ChromaDB 혹은 FAISS를 사용하고 있다. tracking은 langsmith를 통해서 진행하고 있고, Modular RAG를 적용한 뒤로부터는(현재 Agent도 마찬가지이다) langgraph를 적극적으로 사용하고 있다.
어디까지나 개인적인 경험을 바탕으로 작성한 내용이므로 참고용으로 봐주길 바란다.
| Type | Tools/Methods | Note |
|---|---|---|
| Framework | LangChain, LangGraph | - |
| Tracking | LangSmith | debugging 할 때 등 매우 유용하므로 가능한 모든 코드에 사용하는 편 |
| VectorDB | ChromaDB, FAISS | 문서의 양이 많을 땐 FAISS가 압도적인 성능을 보임 |
| Embedding model | OpenAI text-embedding-3-large | 아직까지 한글 문서를 임베딩 할 때 이것보다 성능 좋은, 단일 로컬에서 돌아가는 오픈 소스모델은 경험하지 못함 |
| LLM model | OpenAI gpt-4o, gpt-4o-mini | 이건 선택 사항 |
| Document Parser | Upstage Document Parser | 직접 개발해도 되고, 문서 양이 적은 경우 직접 형식을 맞춰줘도 되지만, 테이블, 이미지까지 처리되므로 이 API를 사용하는 것이 매우 편함. 다만 비쌈 |
| Splitter | LangChain RecursiveCharacterTextSplitter | Semantic Chunking도 테스트 해봤지만 성능이 일정하지 않았음 |
| Chunk, Overlap size | 600, 200 | 이건 정말 휴리스틱한 결과. 하지만 대부분 이정도 사이즈면 중간은 갔음. 베스트는 문서마다 다르니 여러번 테스트가 필요함 |
| Retrieval method | Chroma Vectorstore similarity_search_with_score | - |
| Groundness Checker | OpenAI gpt-4o or 4o-mini | Upstage에서 제공하는 Groundness checker가 있긴 하지만, 프롬프팅을 통해서 일반 모델을 활용해도 적당한 성능이 나옴 |
| Outer Tools: Search | TavilySearch | 한달에 1000건까지 무료로 사용할 수 있음. duckduckgo, SerpAPIWrapper 등 다른 툴들 테스트해봤지만 아직까지는 이 툴에 정착 중 |
이 중에서 retrieval 부분은 조금 더 언급할 필요가 있다. 참고로 본인은 langchain 문서가 0.1, 0.2일때를 기준으로 테스트 했는데, 지금은 0.3이니 약간의 차이는 있을 것이다.
검색 방식은 기본적으로 벡터 기반의 dense retriever인 similarity search, MMR 등이나 BM25와 같은 sparse retrieval를 사용할 수 있고, 이를 모두 사용하는 EnsembleRetriever가 제안되기도 한다. 또한 MultiVectorRetrieval과 같이 데이터셋을 DB에 저장할 때부터 chunk 사이즈를 다르게 해서 indexing 개념과 같이 작은 chunk를 먼저 찾고 큰 chunk를 찾는 방식이나 각 chunk의 summary를 미리 저장해두고 summary 기반으로 찾는 방법도 있다.
이것들을 전부 다 테스트해보고 내린 결론은, vanilla similarity search가 성능적, 속도적 측면에서 나쁘지 않다는 것이다. 우선 앞에서 언급한 MultiVectorRetrieval의 경우 개념적으로는 그럴싸한데, 실제로 해보면 그렇게 까지 많은 성능 향상이 있진 않았다. 또한 summary를 생성하는 과정에서 너무 많은 시간이 소요되기도 했다. Ensemble의 경우 많은 다른 예제에서 추천하고 있기도 하고, 성능도 좋았지만, BM25를 위해서 tokenizing을 하는데 또 시간이 소요되기도 했다. 물론 latency와 성능은 언제나 trade-off 관계이니, 각자 필요에 따라서 선택하면 되는 부분이다.
추가로, Reranker를 사용하지 않은 이유는 chunk가 많은 경우 계산량이 너무 많아서 속도가 느리고 대규모 데이터셋에는 사용하기 어렵다고 판단했기 때문이다.
실제 챗봇은 multi-turn 기능이 반드시 필요하기 때문에 이를 위해서 ChatMessageHistory(from langchain_community.chat_message_histories import ChatMessageHistory, StreamlitChatMessageHistory)부분을 추가해줬고, reset 부분은 frontend 부분에서 해결했다.
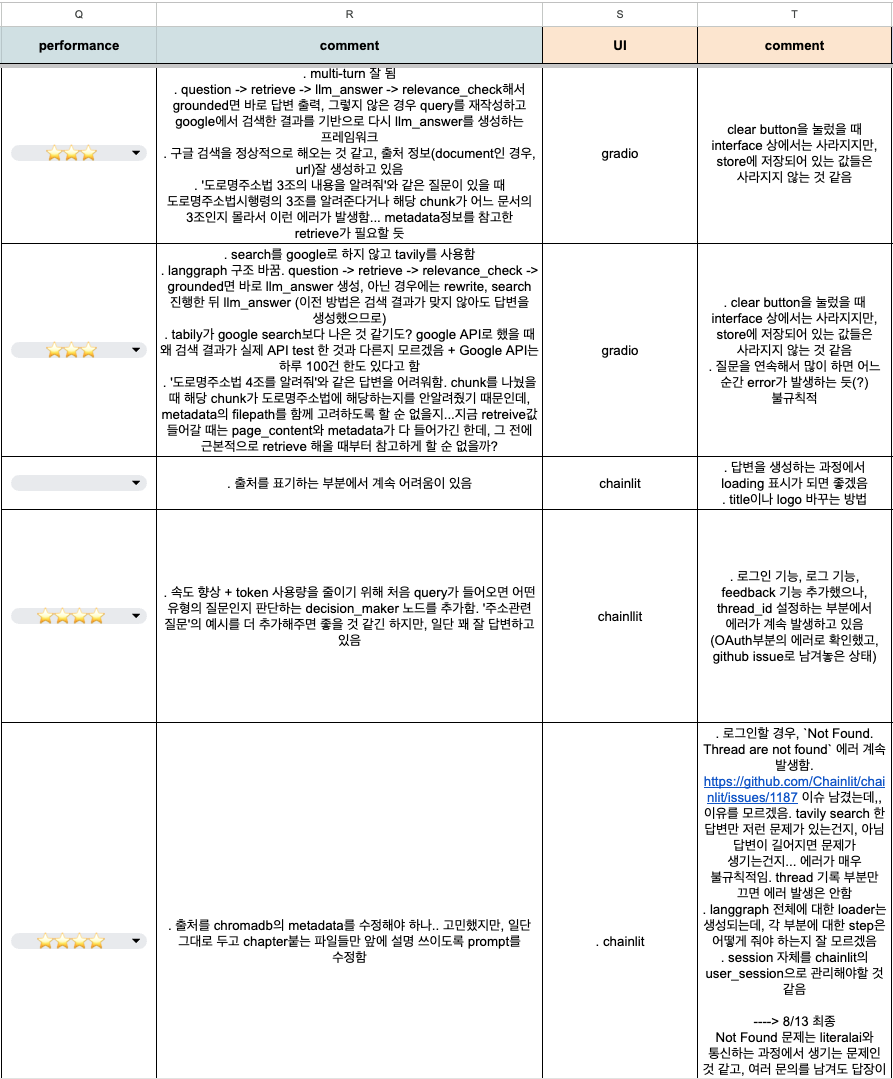
테스트 과정의 이슈와 진행사항은 위와 같이 스프레드 시트를 만들어서 관리해줬다. 테스트를 약 30번 넘게 했기 때문에 나중에는 정말 헷갈리므로 버전 관리를 잘 하는 것도 중요한 포인트 중 하나인 것 같다.
각 모듈을 구성하고 Modular RAG를 구성하는 단계에서부터 langgraph를 도입했다. GraphState로 Input들을 일괄적으로 관리하는게 편리하기도 했고 노드와 엣지로 연결하기 때문에 테스트 과정에서 엣지들을 자유롭게 옮길 수 있었다. 위 기록에서도 볼 수 있듯 구조를 바꿨다는 내용이 종종 등장한다. Router나 Verifier는 테스트를 하면서 성능이 안좋게 느껴지는 부분 중간 중간에 추가해줬고, 물론 약간의 latency와 비용 발생이 추가된다는 단점은 있었지만, 없는 것 보다 정확도는 훨씬 높아진다는 것을 확인했다.
최종 목표가 '챗봇 개발'이기 때문에 모델 개발 뿐만 아니라 frontend, backend 개발과 관련된 고려 요소도 있었다. 초기에는 테스트 목적성이 강해서 streamlit, gradio 등과 같이 python 기반의 개발 툴을 활용했는데, 배포용으로 사용하기에는 디자인적으로 예쁘지 않다던가 로그인 기능 등을 추가하기 어렵다는 문제가 있었다. 그러다 찾은 툴은 Chainlit으로, 챗봇 개발에는 최적화되었고 backend와 frontend를 따로 구성할 필요 없이 파이썬 기반이라 어렵지 않았지만, 이 역시 로그인과 기록을 남기기 위한 tracking 부분에서 문제가 있었다. 해당 부분은 literal ai와 통신을 하며 진행되는데, 깃헙 이슈에 여러 문의를 남겨도 해결 방법을 찾지 못했다.
결국, 원하는 모든 기능들을 구현하기 위해서는 from scratch로 개발을 해야겠다는 생각을 했다. 다행히 frontend쪽은 어느 정도 경험이 있었고, 통신할 API는 1개 정도 일 것 같고, Flask를 이전에 사용해 본 경험이 있었기 때문에(한..번..) 개발은 한 일 주일 내로 완성했던 것 같다.
- Frontend: Nuxt, tailwindcss
- Backend: Flask
마지막으로, 라이브러리들의 버전과 관련된 이슈를 언급해보려 한다. langchain, chromdb 등과 관련된 라이브러리들은 수시로 업데이트 되고, 호환성 문제 때문에 갑자기 되던게 안되기도 하고, 정말 요상한 에러들을 많이 접했다. 현재(25.01) 기준으로 다음과 같이 requirements.txt를 구성했을 때 충돌나는 에러는 없었다.
PyMuPDFb==1.24.6
PyMuPDF==1.24.7
openai==1.35.14
tiktoken==0.7.0
chromadb==0.5.0
langchain== 0.2.8
rank_bm25==0.2.2
gradio==4.38.1
kiwipiepy==0.18.0
pdfplumber==0.11.2
langchain_openai==0.1.16
python-dotenv==1.0.1
unstructured == 0.14.10
langgraph==0.1.8
streamlit==1.36.0
streamlit_feedback==0.1.3
langchain_teddynote==0.0.11
gradio == 4.38.1
langchain-openai == 0.1.16
langchain-community==0.2.7
langchain-text-splitters==0.2.2
langchain-google-genai == 1.0.7
langchain-google-vertexai ==1.0.7
duckduckgo_search == 6.2.5
chainlit == 1.1.400
tavily-python == 0.3.5
chainlit == 1.1.400
python-docx==1.1.2
Markdown==3.6
markdown-it-py==3.0.0자주 문제가 생기는 부분은 langchain-core와 chromdb의 버전이다. 아래와 같이 에러들도 기록해두는 편인데, 주로 reddit이나 stackoverflow에 'I have some issue...', 'Me too!!'x100 과 같은 글들을 잘 찾아보면 결국엔 누가 해결 방법을 알려주곤 했다. 본인이 가장 먼저 찾으면 공유해서 많은 사람들에게 하트를 받는 좋은 방법도 있다 😍

지금까지 설명한 개발 과정을 다음 세 단계로 구분해서 각각의 포스트를 작성하려 한다. 1.2와 1.3은 backend 쪽 구조는 거의 동일하다.
- ver1.1: Gradio 기반의 챗봇 개발
- ver1.2: Chainlit 기반의 챗봇 개발
- ver1.3: Nuxt 기반의 챗봇 개발
처음에 언급했 듯, 현재는 Agent를 추가한 모델을 테스트 해보고 있다. Agent추가 뿐만 아니라, 이전보다 데이터 전처리 부분을 훨씬 섬세하게 진행하려 하고, Router를 사용할 때 OutputParser를 적극적으로 사용해서 json 형식을 고정한 답변을 출력하도록 해서 오류를 줄이려고 한다. 이전에는 prompt를 한글로 작성했다면, 지금은 모든 prompt를 영어로 작성하고, 최대한 다른 좋은 예시들의 형식을 기반으로 사용하려고 하고 있기도 하다.
여전히 evaluation 부분에 대해서는 깊게 고민하고 있지 않지만, 서비스화된다면 이 부분을 가장 많이 고민할 것 같다.
갈 길이 멀다...ㅋㅋㅋ
