프로젝트 github : https://github.com/cattmerry/docker-hadoop
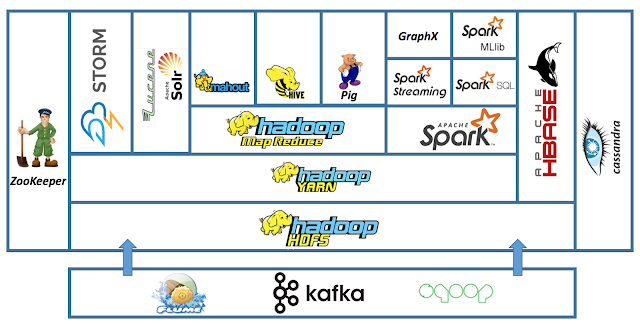
hadoop ecosystem을 docker container로 구축해보는 테스트를 진행해봤다. centos 이미지를 base로 단계별로 dockernize하여 필요한 이미지를 빌드하고 서비스별 컨테이너를 실행하도록 구성했다.
사용한 언어 및 프레임워크 버전은 다음과 같다.
java : 1.8.0
python : 3.7.6
hadoop : 3.2.4
spark : 3.2.2
zeppelin : 0.10.1
Base image build
먼저 각 서비스 실행을 위한 base image를 build한다. 아래의 순서로 이미지를 쌓아간다.
- 필요한 프로그래밍 언어 설치
- 필요한 프레임워크 설치
language-base image
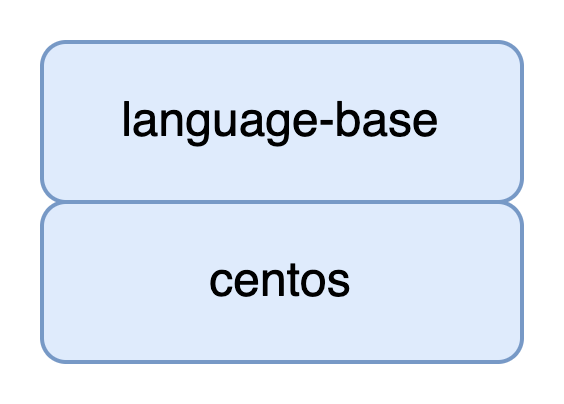
centos 이미지를 베이스로 필요한 프로그래밍 언어(java, python)를 설치한 이미지를 build한다.
hadoop과 spark 사용에는 java가 필요하며, pyspark를 사용하기 위해 python을 설치한다.
후에 서비스 가동시 필요한 환경변수들을 세팅해준다.
Dockerfile
FROM centos
RUN sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-*
RUN sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-*
RUN yum install -y wget
RUN yum -y groupinstall "Development Tools"
RUN yum -y install openssl-devel bzip2-devel libffi-devel
ENV PYTHON_VERSION=3.7.6
ENV PYTHON_URL=https://www.python.org/ftp/python/$PYTHON_VERSION/Python-$PYTHON_VERSION.tgz
# python install
RUN wget $PYTHON_URL
RUN tar -xvzf Python-$PYTHON_VERSION.tgz && rm Python-$PYTHON_VERSION.tgz
RUN /Python-$PYTHON_VERSION/configure --enable-optimizations
RUN make altinstall
RUN ln -s /usr/local/bin/python3.7 /usr/bin/python3
RUN ln -s /usr/local/bin/python3.7 /usr/bin/python
# java install
RUN yum install -y java-1.8.0-openjdk.x86_64
ENV JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-2.el8_5.x86_64/jreHadoop-base image
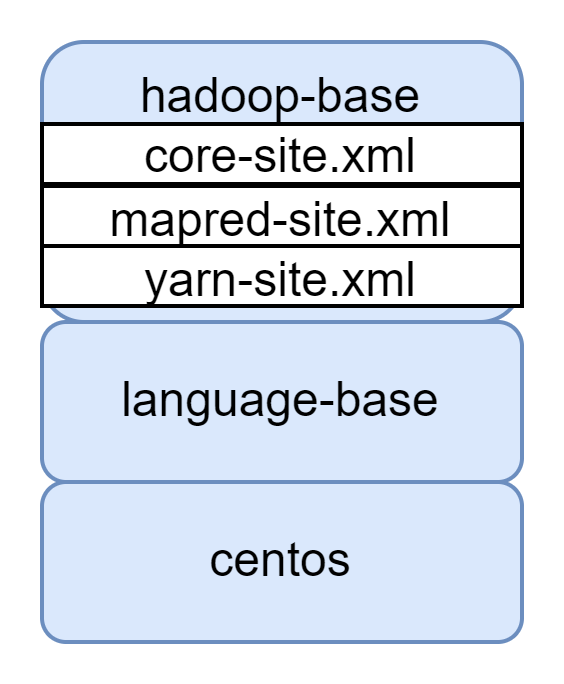
language-base image를 베이스로 Hadoop을 설치한 이미지를 build한다.
Hadoop, YARN, MapReduce 실행에 필요한 설정 파일들도 추가해준다.
Dockerfile
위에서 만든 Dockerfile을 직접 'language-base' 이름으로 image를 build했다.
직접 build한 이미지를 FROM에 명시하여 사용한다.
FROM language-base
ENV HADOOP_VERSION=3.2.4
ENV HADOOP_FILE_NAME=hadoop-$HADOOP_VERSION
ENV HADOOP_URL=https://dlcdn.apache.org/hadoop/common/hadoop-$HADOOP_VERSION/$HADOOP_FILE_NAME.tar.gz
# hadoop setting
RUN wget $HADOOP_URL
RUN tar -xvzf $HADOOP_FILE_NAME.tar.gz && rm $HADOOP_FILE_NAME.tar.gz
RUN mv $HADOOP_FILE_NAME /opt
RUN ln -s /opt/$HADOOP_FILE_NAME /opt/hadoop
ENV HADOOP_HOME=/opt/hadoop
RUN ln -s $HADOOP_HOME/etc/hadoop /etc/hadoop
ENV HADOOP_CONF_DIR=/etc/hadoop
RUN mkdir $HADOOP_HOME/dfs
RUN rm -rf $HADOOP_HOME/share/doc
RUN mkdir -p $HADOOP_HOME/yarn/timeline
# copy hadoop config file
ADD core-site.xml $HADOOP_CONF_DIR
ADD yarn-site.xml $HADOOP_CONF_DIR
ADD mapred-site.xml $HADOOP_CONF_DIR
ENV YARN_CONF_DIR=$HADOOP_CONF_DIR
ENV PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinHadoop configuration file
image에 추가할 Hadoop core, YARN, MapReduce 설정 파일을 작성한다.
core-site.xml
Hadoop의 core 설정 파일. file system의 주소를 명시해준다.
docker container의 host name을 'namenode'로 지정해줄 예정이기때문에 실제 IP 주소 대신 container에 사용할 host name을 사용하여 지정했다.
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:9000/</value>
<description>NameNode URI</description>
</property>
</configuration>yarn-site.xml
YARN 설정 파일. 크게 3가지 부분에 대해 설정했다.
- MapReduce를 사용할 경우 필요한 옵션
- YARN Resource Manager와 Node Manage에 대한 설정
- YARN Timeline Server 설정 (Timeline은 YARN의 history라고 생각하면 됨)
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>resourcemanager</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/hadoop/yarn/data</value>
</property>
<property>
<name>yarn.nodemanager.logs-dirs</name>
<value>/opt/hadoop/yarn/data</value>
</property>
<property>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.system-metrics-publisher.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.generic-application-history.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.leveldb-timeline-store.path</name>
<value>/opt/hadoop/yarn/timeline</value>
</property>
<property>
<name>yarn.timeline-service.hostname</name>
<value>yarntimelineserver</value>
</property>
</configuration>mapred-site.xml
MapReduce 설정 파일. MapReduce 애플리케이션을 YARN으로 돌리겠다는 옵션을 추가해준다.
이번 프로젝트에서는 Spark를 사용하겠지만 간단히 MR을 테스트해보기 위해 설정해준다.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>Spark-base image
위에서 build한 Hadoop-base image를 베이스로 Spark를 설치해주고 설정파일을 추가해준다.
Dockerfile
마찬가지로 위에서 만든 Hadoop-base Dockerfile을 직접 'hadoop-base' 이름으로 image를 build했다.
직접 build한 이미지를 FROM에 명시하여 사용한다.
FROM hadoop-base
ENV SPARK_VERSION=3.2.2
ENV SPARK_FILE_NAME=spark-$SPARK_VERSION-bin-hadoop3.2
ENV SAPRK_URL=https://dlcdn.apache.org/spark/spark-$SPARK_VERSION/$SPARK_FILE_NAME.tgz
# spark setting
RUN wget $SAPRK_URL
RUN tar -xvzf $SPARK_FILE_NAME.tgz && rm $SPARK_FILE_NAME.tgz
RUN mv $SPARK_FILE_NAME /opt
RUN ln -s /opt/$SPARK_FILE_NAME /opt/spark
ENV SPARK_HOME=/opt/spark
ENV PATH=$PATH:$SPARK_HOME/bin
# spark history log directory
RUN mkdir $SPARK_HOME/eventLog
# copy spark config file
ADD spark-defaults.conf $SPARK_HOME/confspark-defaults.conf
Spark를 YARN으로 돌리겠다는 설정과 Spark log를 쌓을 위치를 지정해준다.
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir file:///opt/spark/eventLog
spark.history.fs.logDirectory file:///opt/spark/eventLog
spark.hadoop.yarn.timeline-service.enabled false이번에 진행한 프로젝트에서는 spark.hadoop.yarn.timeline-service.enabled false 설정을 추가해줘야 한다.
yarn timeline 설정과 spark 설정과의 충돌이 있었다.
yarn-site.xml에 timeline 옵션을 추가하면 spark에서 에러가 발생했다. (구체적으로는 spark에서 서버의 env variable을 찾지 못하는 버그가 발생했다.)
spark 설정에서 위의 옵션을 줘 해결할 수 있었다.
해결에 참조한 글 : https://dhkdn9192.github.io/apache-spark/hdp-spark-upgrade/
최종 Base image
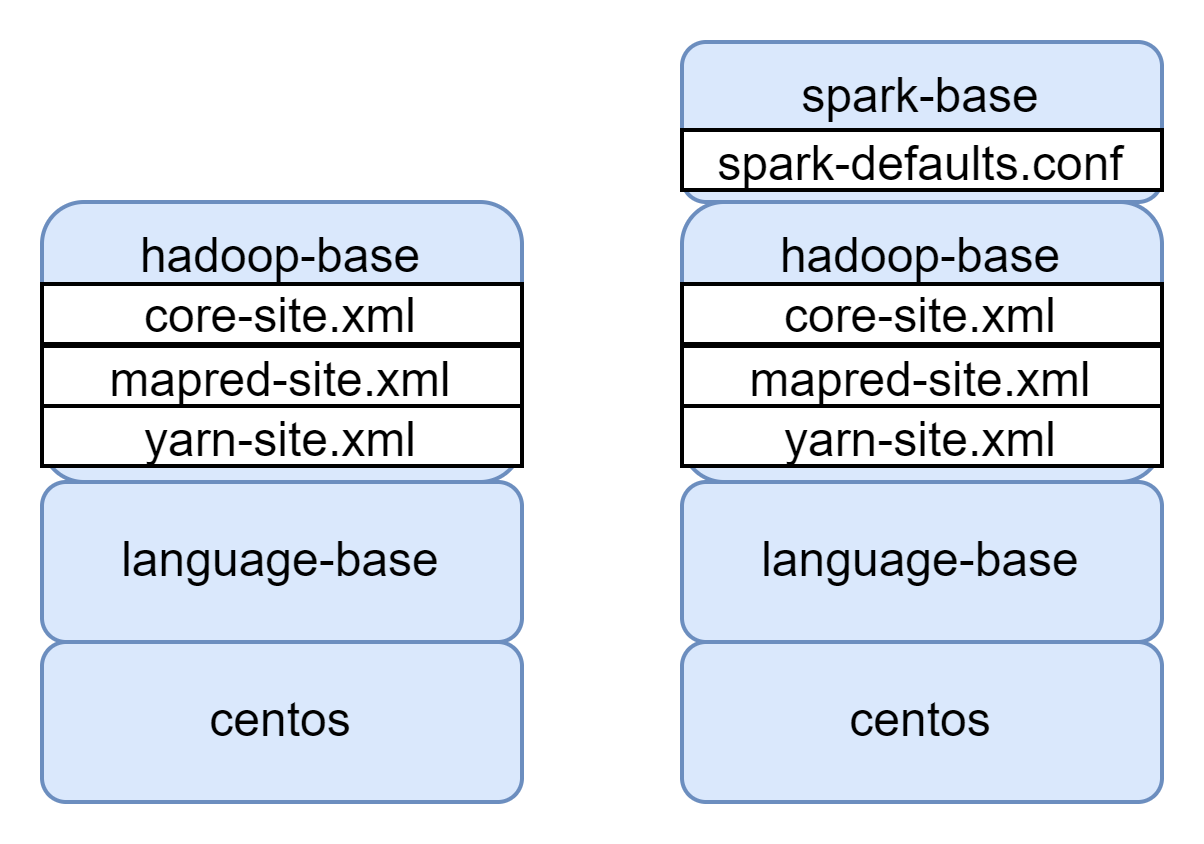
모든 서비스 Container에는 Hadoop이 필요하지만 Spark는 특정 Container에만 있으면 되기때문에 Container를 최대한 경량화하기 위해 나눴다.
최종적으로 만들어진 두개의 base 이미지를 기반으로 서비스별 Container를 생성할 것이다.
