프로젝트 github : https://github.com/cattmerry/docker-hadoop
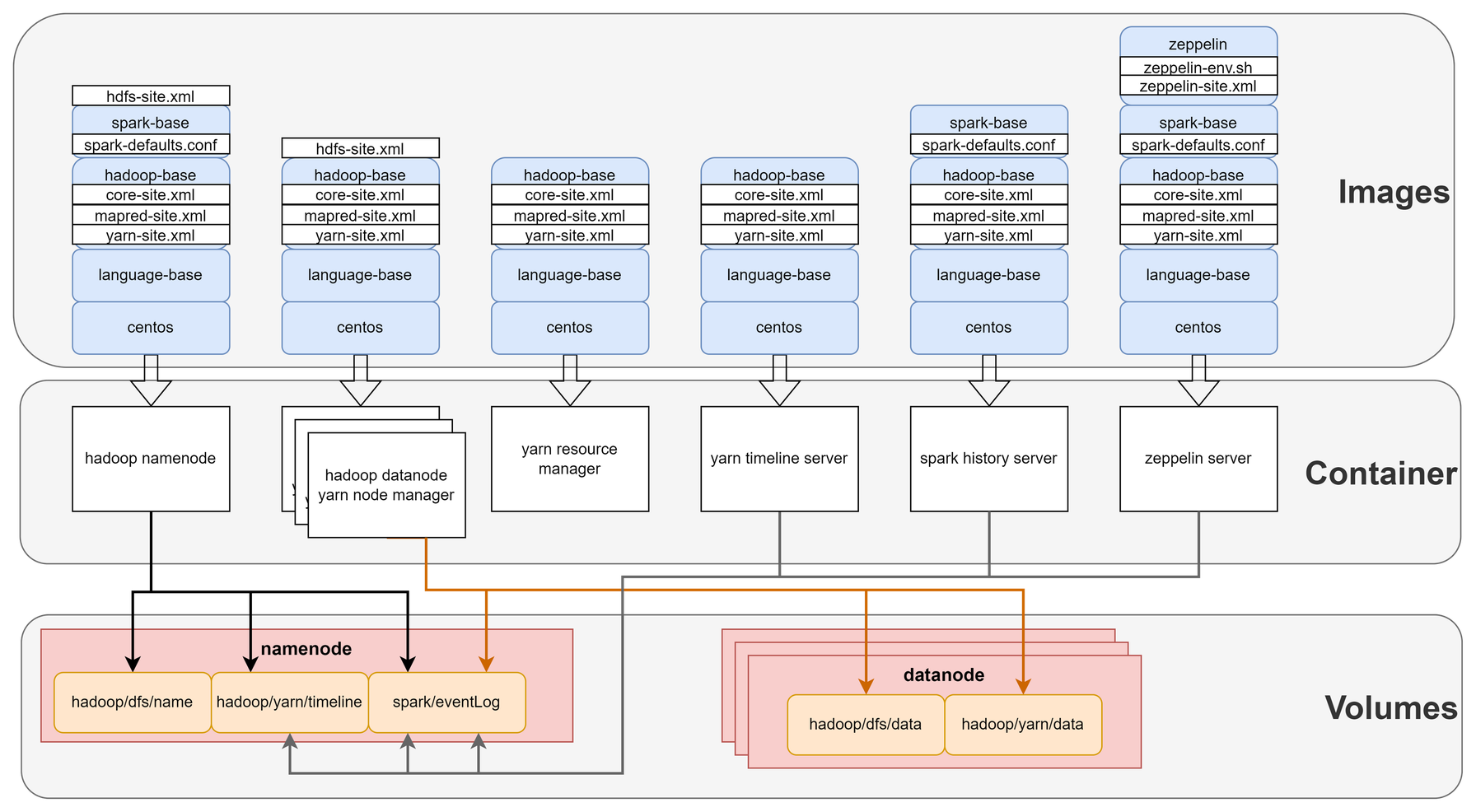
Container로 띄울 서비스들과 각 Container를 띄운 이미지, mount한 volume을 시각적으로 정리했다.
전 포스팅에서 build한 이미지를 기반으로 필요한 서비스들을 docker container로 띄운다.
volume 공유가 필요할 경우 docker 엔진에서 volume을 생성하고 필요한 container를 mount한다.
모든 container에는 Hadoop이 설치되어있고, Spark는 YARN 위에서 실행하기때문에 Spark를 실제로 실행할 container에만 설치되어있으면 된다. (Hadoop의 datanode에는 설치할 필요 없음)
모든 이미지에는 실행할 스크립트 파일을 추가해주고 Conatainer를 띄울때 이를 실행하는 구조로 build되었다.
Hadoop namenode
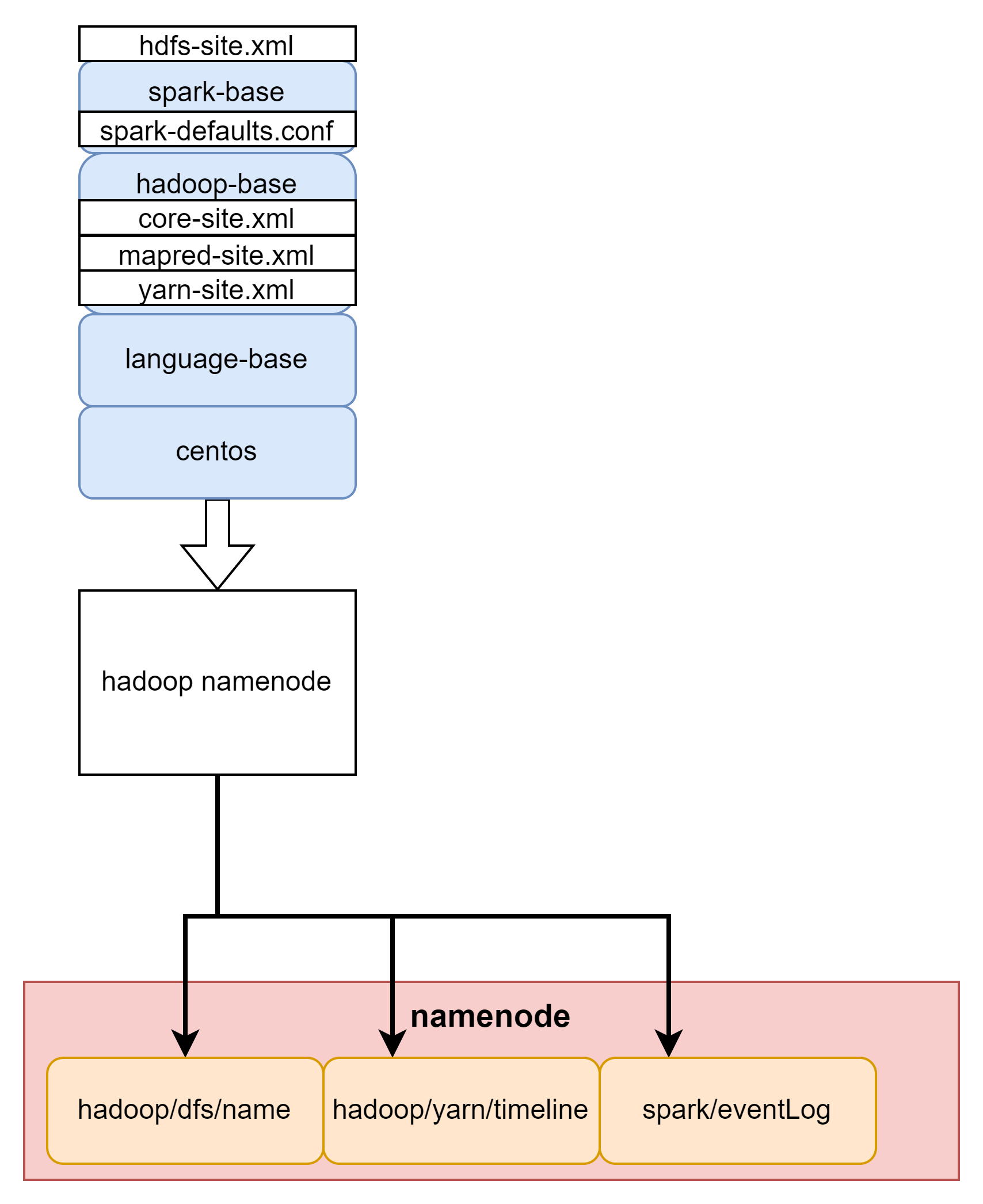
hadoop의 name node를 실행하는 Container다. Spark까지 설치한 base 이미지에 name node에 필요한 설정 파일을 추가해준다.
Dockerfile
FROM hadoop-spark-base
HEALTHCHECK CMD curl -f http://namenode:9870/ || exit 1
ADD hdfs-site.xml $HADOOP_CONF_DIR
# FsImage, EditLog 파일 경로
# FsImage : block replication 개수를 mapping 시켜놓은 정보
RUN mkdir $HADOOP_HOME/dfs/name
ADD start.sh /start.sh
RUN chmod a+x /start.sh
# 9000 : IPC port (namenode <> datanode 통신을 위한 포트)
# docker container간 통신만 하면 되기때문에 local port와 매핑해줄 필요 없음
# 9870 : NameNode HTTP web ui
EXPOSE 9000 9870
CMD ["/start.sh", "/opt/hadoop/dfs/name"]hdfs-site.xml
- name node의 데이터를 저장할 곳을 지정한다. hadoop File System, data node들의 메타데이터들이 저장된다.
- file bolck size를 지정한다. 테스트를 위해 64mb로 설정한다.(byte 단위로 표기하며 default size는 128mb 이다.)
Hadoop은 저장할 파일이 block size보다 클 경우 size만큼 데이터를 분할한다.
분할된 block들에서 총 3개의 복제본을 생성한 후 data node에 분할하여 저장한다.
복제본을 생성하는 이유는 장애에 대응하기 위함이다. 복제된 block들은 각각 다른 data node에 저장된다.
start.sh
namenode를 cli로 직접 실행하도록 스크립트를 작성한다.
추가적으로 디렉토리가 비어있는지에 대한 여부로 포맷 상태를 체크한다.
#!/bin/bash
# 네임스페이스 디렉토리를 입력받아서
NAME_DIR=$1
echo $NAME_DIR
# 비어있지 않다면 이미 포맷된 것이므로 건너뛰고
if [ "$(ls -A $NAME_DIR)" ]; then
echo "NameNode is already formatted."
# 비어있다면 포맷을 진행
else
echo "Format NameNode."
$HADOOP_HOME/bin/hdfs --config $HADOOP_CONF_DIR namenode -format
fi
# NameNode 기동
$HADOOP_HOME/bin/hdfs --config $HADOOP_CONF_DIR namenode
Hadoop Datanode & YARN node mamager
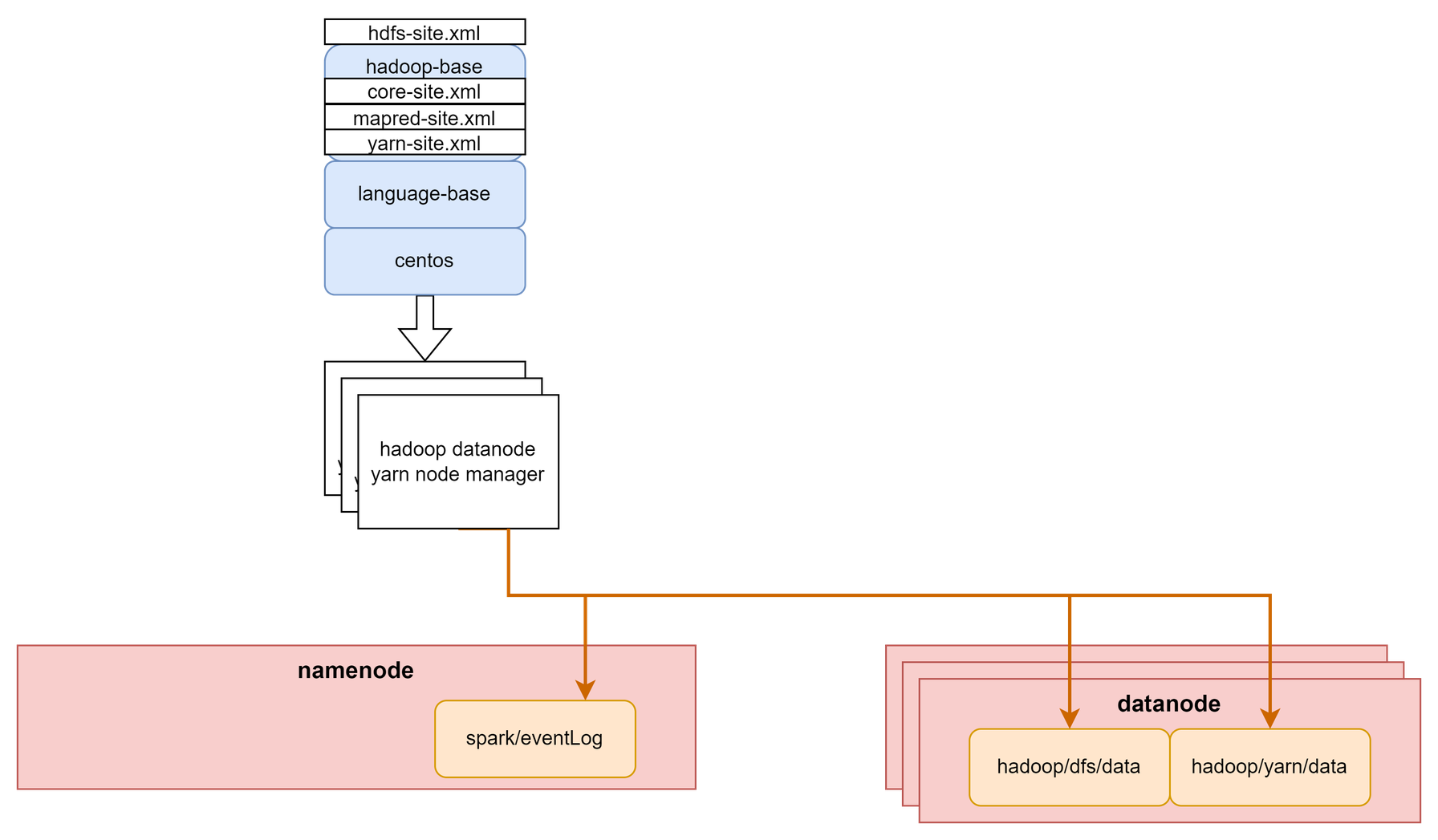
Hadoop의 datanode와 YARN의 node manager를 실행하는 Container다.
각 Hadoop datanode마다 YARN node manager가 실행되어야 한다.
Dockerfile
FROM hadoop-base
HEALTHCHECK CMD curl -f http://localhost:9864/ || exit 1
# copy config file
ADD hdfs-site.xml $HADOOP_CONF_DIR
# datanode data directory
RUN mkdir $HADOOP_HOME/dfs/data
# nodemamager data directory
RUN mkdir -p $HADOOP_HOME/yarn/data
# 9864 : datanode web UT port
# 9866 : The datanode server address and port for data transfer.
# 8042 : yarn nodemanager webapp address
# 8040 : arn.nodemanager.localizer.address
EXPOSE 9864 9866 8042
ADD start.sh /start.sh
RUN chmod a+x /start.sh
# Datanode에 spark 설치는 필요없지만 yarn container에서 spark app을 실행할때, spark job을 제출한 서버의 spark 설정을 따르게 된다.
# spark설정에서 eventlog 디렉토리를 설정해준 부분이 있는데, 이로 인해 datanode의 yarn container에서 실행되는 spark app 로그는 해당 서버에 남게 된다.
# dummy로 디렉토리를 만들어줘야 함
RUN mkdir -p /opt/spark/eventLog
CMD ["/start.sh"]hdfs-site.xml
Hadoop datanode의 설정파일.
Hadoop에서 실제 데이터를 저장할 디렉토리를 지정한다.
Hadoop namenode를 통한 데이터 저장은 block으로 분할 및 복제 후 datanode의 지정된 디렉토리에 저장된다.
<configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.datanode.use.datanode.hostname</name>
<value>true</value>
</property>
</configuration>start.sh
datanode와 node manager를 cli로 직접 실행하도록 스크립트를 작성한다.
#!/bin/sh
$HADOOP_HOME/bin/hdfs --config $HADOOP_CONF_DIR datanode &
$HADOOP_HOME/bin/yarn --config $YARN_CONF_DIR nodemanagerYARN Resource manager
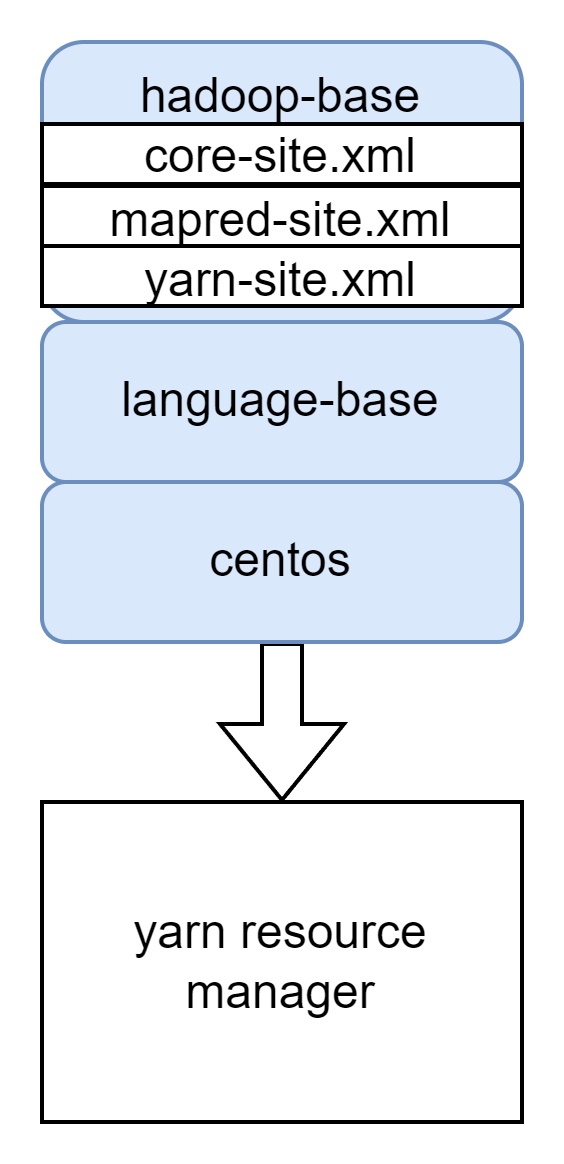
YARN resource manager를 실행하는 Container다.
Container를 띄울때 실행할 스크립트 파일을 추가해주고 이를 실행하도록 한다.
Dockerfile
본 Container에는 spark가 필요없다. 여기서 spark를 실행하지 않기 때문이다. 따라서 Hadoop만 설치된 base image를 사용한다.
FROM hadoop-base
HEALTHCHECK CMD curl -f http://resourcemanager:8088/ || exit 1
ADD start.sh /start.sh
RUN chmod a+x /start.sh
# 8088 : yarn resource manager Web UI
# 8030 : yarn scheduler interface
# 8032 : yarn resource manager IPC port
EXPOSE 8088 8032 8030
CMD ["/start.sh"]start.sh
cli로 직접 resource manager를 실행하는 스크립트를 작성한다.
#!/bin/bash
$HADOOP_HOME/bin/yarn --config $HADOOP_CONF_DIR resourcemanagerYARN Timeline Server
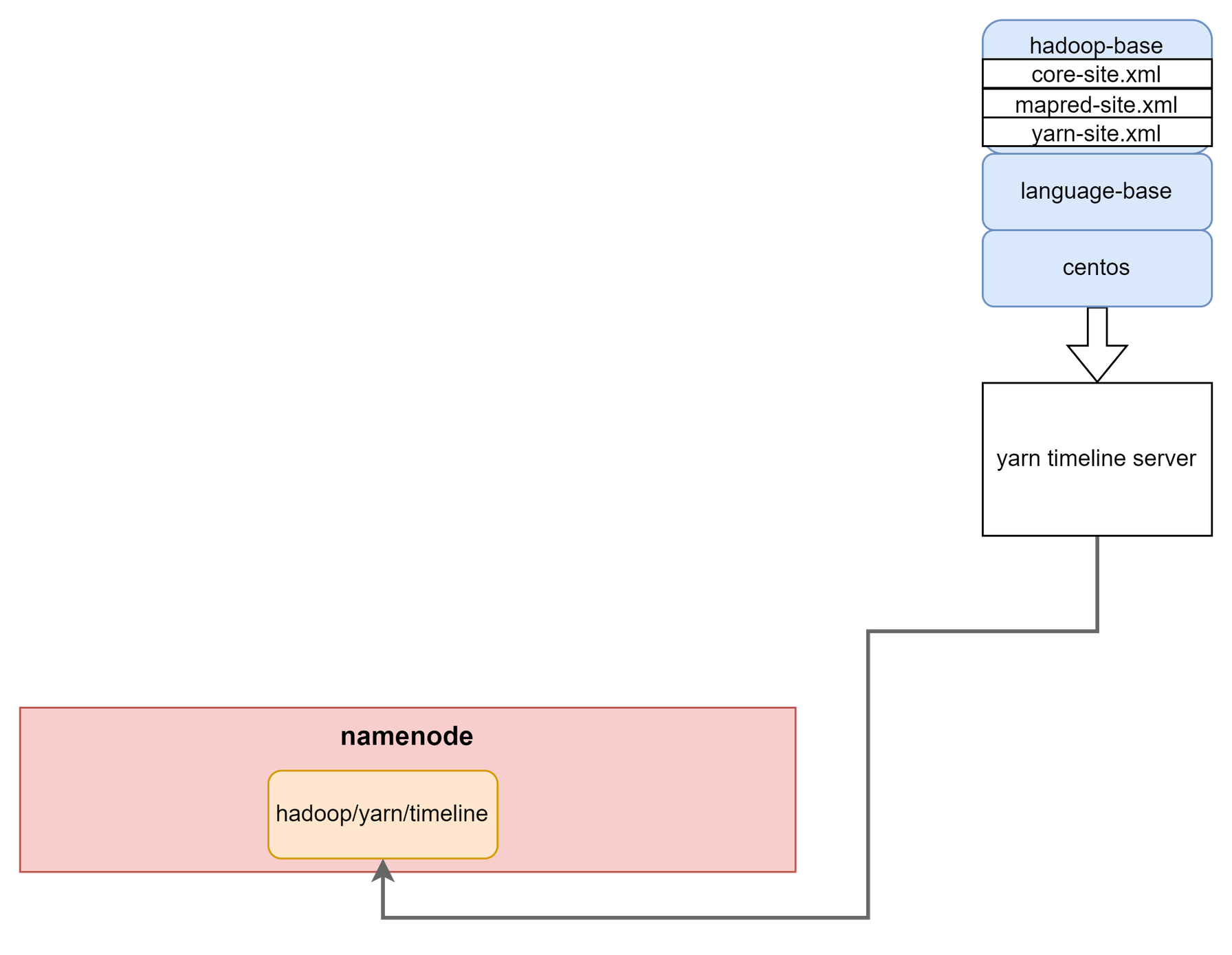
YARN 작업들의 history를 관리하는 timeline server를 실행하는 Container다.
설정에 따라 다른 Container에서 /yarn/timeline에 히스토리를 기록하고, 이 경로를 현재 Container에 mount하여 web에서 볼 수 있도록 구성한다.
Dockerfile
FROM hadoop-base
HEALTHCHECK CMD curl -f http://yarntimelineserver:8188/ || exit 1
ADD start.sh /start.sh
RUN chmod a+x /start.sh
# 8188 : yarn timeline web UI port
# 10200 : yarn timeline service port
EXPOSE 8188 10200
CMD ["/start.sh"]start.sh
cli로 직접 timeline server를 실행하는 스크립트를 작성한다.
#!/bin/bash
$HADOOP_HOME/bin/yarn --config $HADOOP_CONF_DIR timelineserverSpark history server
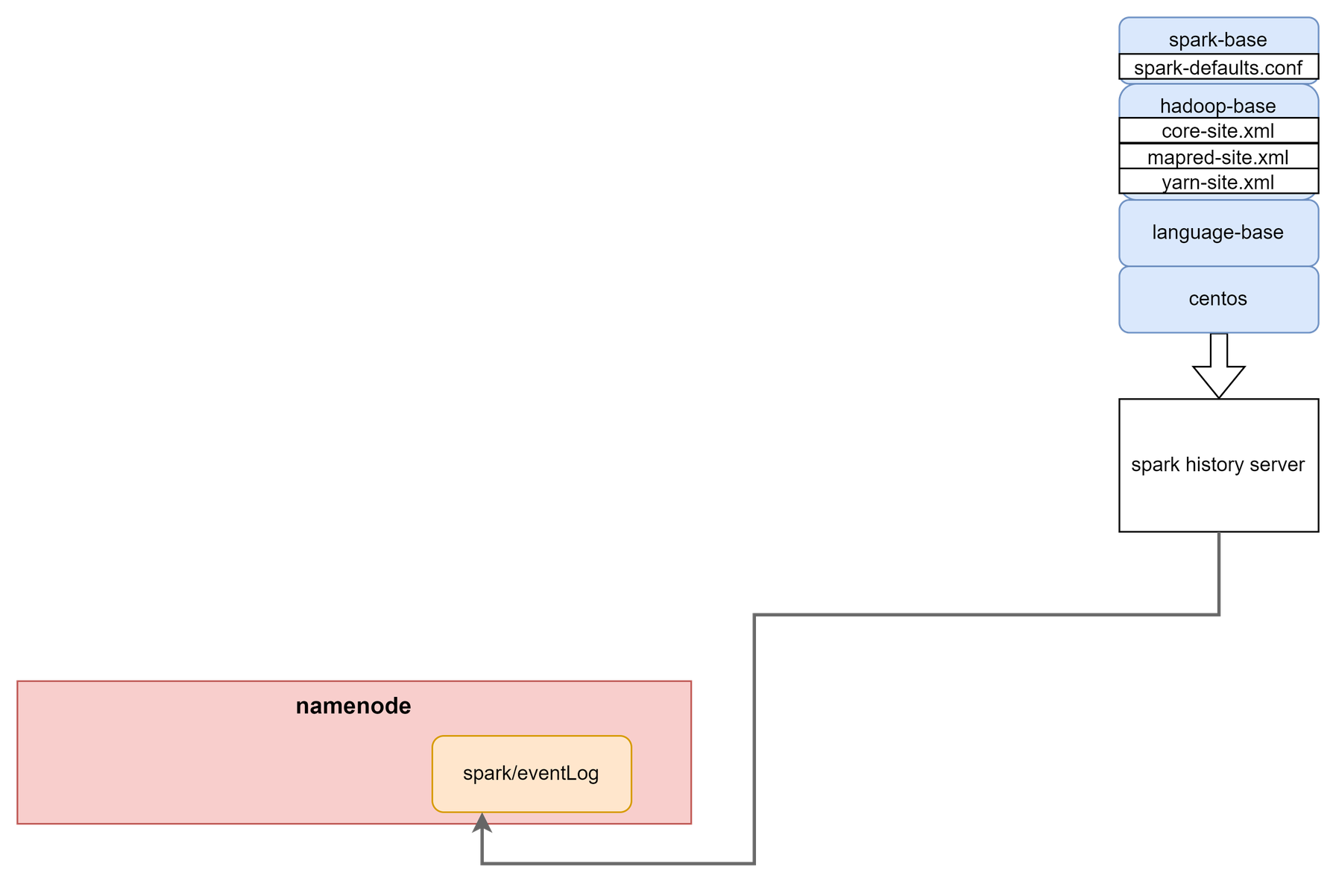
spark 작업들의 history를 보기 위한 web server를 실행하는 Container다.
설정에 따라 다른 Container에서 /spark/evnetLog에 히스토리를 기록하고, 이 경로를 현재 Container에 mount하여 web에서 볼 수 있도록 구성한다.
dockerfile
FROM hadoop-spark-base
HEALTHCHECK CMD curl -f http://localhost:18080/ || exit 1
# 18080 : spark history web UI port
EXPOSE 18080
COPY start.sh /start.sh
RUN chmod 700 /start.sh
CMD ["/start.sh"]start.sh
spark는 script를 통해 daemon형태로 실행하도록 되어있다. 따라서 위에 처럼 Container 실행시 start-history-server.sh만 실행하도록 하면 Conatiner가 즉시 다운된다. 약간의 트릭을 추가하여 Container가 계속 유지될 수 있도록 한다.(sleep infinity)
#!/bin/sh
echo "run"
/opt/spark/sbin/start-history-server.sh
echo "sleep -"
sleep infinityZeppelin
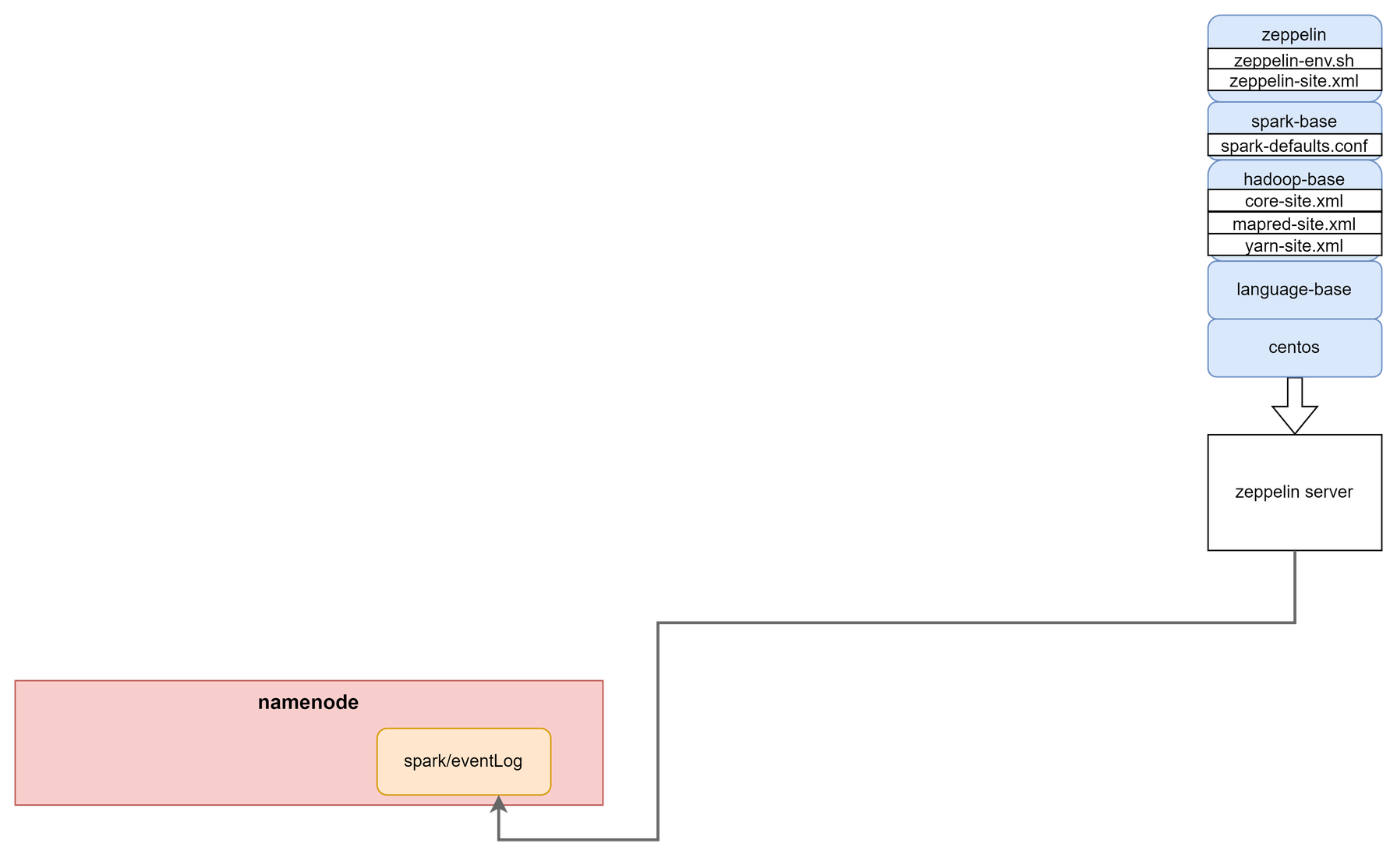
spark base image에 추가적으로 zeppelin을 설치하여 컨테이너를 실행한다.
현재 프로젝트의 spark version은 3.2이며, 이를 지원하는 zeppelin 버전은 0.9.0 이상이다.
Dockerfile
FROM hadoop-spark-base
HEALTHCHECK CMD curl -f http://localhost:8080/ || exit 1
# spark 3.2 support version (>=0.9.0)
ENV ZEPPELIN_VERSION=0.10.1
ENV ZEPPELIN_FILE_NAME=zeppelin-$ZEPPELIN_VERSION-bin-all
RUN wget https://dlcdn.apache.org/zeppelin/zeppelin-$ZEPPELIN_VERSION/$ZEPPELIN_FILE_NAME.tgz
RUN tar -xvzf $ZEPPELIN_FILE_NAME.tgz && rm $ZEPPELIN_FILE_NAME.tgz
ADD zeppelin-env.sh /$ZEPPELIN_FILE_NAME/conf
ADD zeppelin-site.xml /$ZEPPELIN_FILE_NAME/conf
ADD start.sh /start.sh
RUN chmod 700 /start.sh
# test용 data
RUN mkdir /testdata
# 8080 : zeppelin web UI port
EXPOSE 8080
CMD ["/start.sh"]start.sh
Zeppelin도 마찬가지로 script를 통해 daemon형태로 실행하도록 되어있다. 따라서 위처럼 트릭을 추가한다.
#!/bin/sh
echo "run"
/zeppelin-0.10.1-bin-all/bin/zeppelin-daemon.sh start
echo "sleep -"
sleep infinityzeppelin-env.sh
zeppelin에서 사용할 interpreter 설정을 미리 지정해준다. 여기서 미리 선언하지 않아도 web에서 바꿀 수 있다.
export ZEPPELIN_HOME=/zeppelin-0.10.1-bin-all
export PYSPARK_PYTHON=python3
export PYTHONPATH=python3
export SPARK_MASTER=yarnzeppelin-site.xml
zeppelin 설정 파일.
jobmanager는 zeppelin의 스크립트의 실행상태를 보여주는 기능이다.
기존에는 default로 켜져있었지만 서버 자원을 많이 먹는다는 이유로 버전이 올라가면서 default가 false로 변경되었다. 이번 프로젝트에서는 테스트를 위해 true로 바꿔준다.
<configuration>
<property>
<name>zeppelin.server.addr</name>
<value>0.0.0.0</value>
</property>
<property>
<name>zeppelin.server.port</name>
<value>8080</value>
</property>
<property>
<name>zeppelin.jobmanager.enable</name>
<value>true</value>
</property>
</configuration>Docker-compose
Container가 꽤 많기떄문에 Docker-compose로 한번에 관리할 수 있도록 구성하자.
docker-compose.yml
volume과 network를 생성해주고 각 서비스에 매핑해준다.
docker container끼리 네트워크를 묶어주고 host name을 설정 파일에서 사용한대로 지정해줘야한다.
Container내에서 실행되는 web을 local에서 접근할 수 있도록 서비스마다 필요한 port를 설정해준다.
version: "3.7"
x-datanode_base: &datanode_base
image: hadoop-datanode
networks:
- bridge
services:
namenode:
image: hadoop-namenode
container_name: namenode
hostname: namenode
ports:
- "9098:9870" # namenode web UI
volumes:
- namenode:/opt/hadoop/dfs/name # namenode data mount
- namenode:/opt/spark/eventLog # spark history log data mount
- namenode:/opt/hadoop/yarn/timeline # yarn timeline data mount
- /home/ec2-user/testdata:/testdata
networks:
- bridge
datanode01:
<<: *datanode_base
container_name: datanode01
hostname: datanode01
volumes:
- datanode01:/opt/hadoop/dfs/data
- datanode01:/opt/hadoop/yarn/data
- namenode:/opt/spark/eventLog
datanode02:
<<: *datanode_base
container_name: datanode02
hostname: datanode02
volumes:
- datanode02:/opt/hadoop/dfs/data
- datanode02:/opt/hadoop/yarn/data
- namenode:/opt/spark/eventLog
datanode03:
<<: *datanode_base
container_name: datanode03
hostname: datanode03
volumes:
- datanode03:/opt/hadoop/dfs/data
- datanode03:/opt/hadoop/yarn/data
- namenode:/opt/spark/eventLog
resourcemanager:
image: resourcemanager
container_name: resourcemanager
hostname: resourcemanager
ports:
- "9099:8088"
networks:
- bridge
yarntimelineserver:
image: yarn-timelineserver
container_name: yarntimelineserver
hostname: yarntimelineserver
ports:
- "9096:8188"
networks:
- bridge
volumes:
- namenode:/opt/hadoop/yarn/timeline
sparkhistoryserver:
image: spark-historyserver
container_name: sparkhistoryserver
hostname: sparkhistoryserver
ports:
- "9093:18080"
depends_on:
- namenode
- resourcemanager
volumes:
- namenode:/opt/spark/eventLog
networks:
- bridge
zeppelin:
image: zeppelin
container_name: zeppelin
hostname: zeppelin
ports:
- "9097:8080"
networks:
- bridge
volumes:
- namenode:/opt/spark/eventLog
- /env/hadoop-eco/hadoop/zeppelin/notebook:/zeppelin-0.10.1-bin-all/notebook
- /home/ec2-user/testdata:/testdata
volumes:
namenode:
datanode01:
datanode02:
datanode03:
networks:
bridge:image-build.sh
build할 이미지들이 많기때문에 스크립트로 작성하여 한번에 build할 수 있도록 하자.
#!/bin/bash
docker-compose down
docker build -t language-base ./languagebase
docker build -t hadoop-base ./hadoopbase
docker build -t hadoop-spark-base ./hadoopsparkbase
docker build -t hadoop-namenode ./namenode
docker build -t hadoop-datanode ./datanode
docker build -t resourcemanager ./hadoop/resourcemanager
docker build -t yarn-timelineserver ./hadoop/yarntimelineserver
docker build -t spark-historyserver ./hadoop/sparkhistoryserver
docker build -t zeppelin ./hadoop/zeppelin
docker-compose up -d정상적으로 실행되었다면 container들이 healthy하게 뜬 것을 확인할 수 있다.
Project Cluster 구조
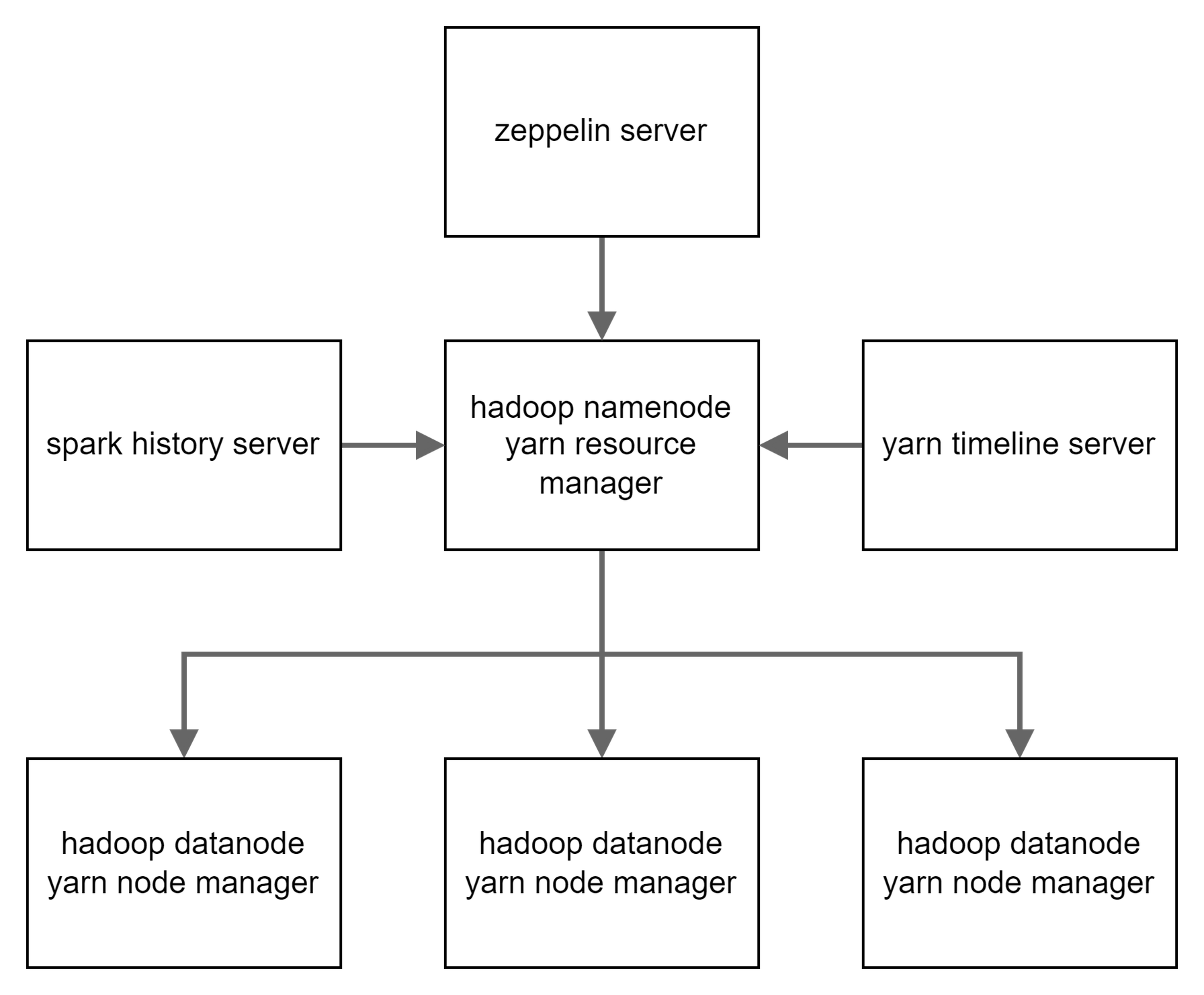
Container 구조와 별개로 실제 서비스사이의 관계를 표현했다. 테스트에서 사용할 client server는 zeppelin server(zeppelin container)다.
Web page
테스트에서 사용될 web page들이다.
local에서 매핑된 port로 접근할 수 있다.
- 0.0.0.0:9098 : hadoop namenode
- hadoop FS 의 전반적인 정보를 볼 수 있다.
- 0.0.0.0:9099 : YARN resource manager
- YARN cluster의 정보를 볼 수 있다. YARN cluster 위에서 돌아가는 application 정보를 확인할 수 있다.
- 0.0.0.0:9096 : YARN timeline server
- yarn cluster에서 실행된 application 히스토리를 볼 수 있다.
- 0.0.0.0:9093 : spark history server
- spark 애플리케이션 실행에 대한 히스토리를 볼 수 있다.
- 0.0.0.0:9097 : zeppelin
- spark code들을 작성하게될 zeppelin이다.


안녕하세요, 포스팅으로 많은 도움 받았습니다.
namenode 컨테이너에서 format을 계속 실패하는데, 문제 없으셨나요?
NAME_DIR에 leveldb-timeline-store.ldb파일이 존재하고 있어 format이 제대로
실행되지 않는것같습니다.
``
Re-format filesystem in Storage Directory root= /opt/hadoop/dfs/name; location= null ?: Invalid Input" 에러가 계속해서 출력됩니다.