프로젝트 github : https://github.com/cattmerry/docker-hadoop
설치한 hadoop이 정상적으로 실행되는지 확인을 위해 테스트 진행.
hdfs에 파일을 저장하고 이 파일을 처리하는 mapreduce application을 yarn을 통해 배포하여 실행한다.
간단한 텍스트파일을 hdfs에 저장하고 이 파일의 word count를 세는 mapreduce application을 실행하여 결과를 확인해본다.
hadoop name node를 실행하고 있는 container에 명령을 실행해야한다. local에서 편하게 실행할 수 있도록 alias를 지정한다.
alias hadoop="docker exec namenode /opt/hadoop/bin/hadoop"
echo hadoophdfs에 test용 디렉토리를 생성하고 cli를 통해 디텍토리를 확인한다.
hadoop fs -mkdir -p /tmp/test/wordcount
hadoop fs -mkdir -p /tmp/test/wordcount_out
hadoop fs -ls /tmp/testname node의 web ui에서도 디렉토리를 확인할 수 있다.
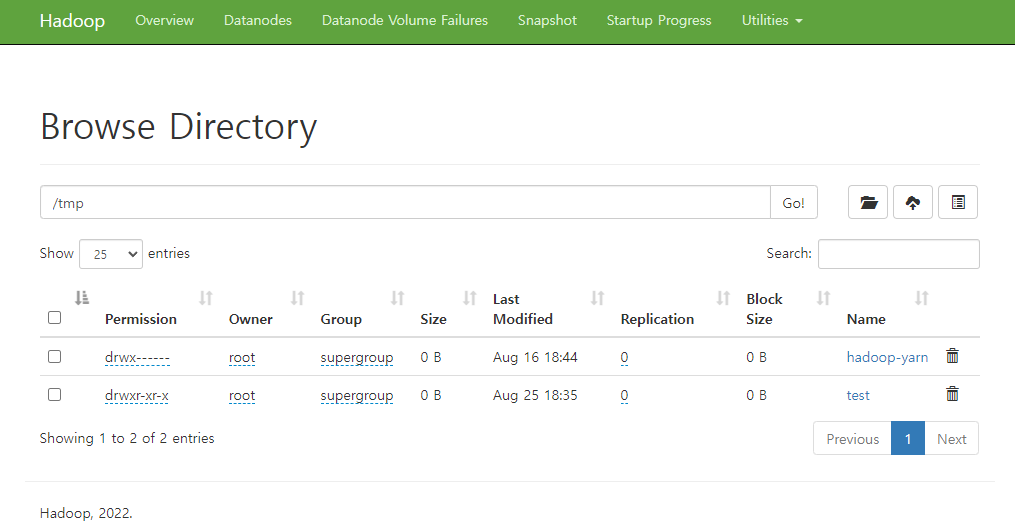
생성한 디렉토리에 test용 텍스트 파일을 저장한다.
간단하게 테스트를 위해 컨테이너 안에 있는 hadoop license.txt 파일을 hdfs의 /tmp/test 디렉토리에 저장한다.
원하는 파일을 넣고 싶다면 컨테이너 안에 파일이 존재해야 한다. 컨테이너에 파일을 copy하거나 bind mount를 통해 컨테이너내에서 파일을 인식할 수 있다.
hadoop fs -put /opt/hadoop/LICENSE.txt /tmp/test/wordcountmapreduce로 작성된 jar 파일을 실행한다. 타겟 디렉토리내의 파일들의 wordcount를 센 후 결과를 /tmp/test_out 디렉토리에 저장한다.
hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.4.jar wordcount /tmp/test/wordcount /tmp/test/wordcount_out정상적으로 실행된다면 yarn resource manager의 web ui를 통해 yarn위에서 mapreduce application이 돌아가고 있는 것을 확인할 수 있다.
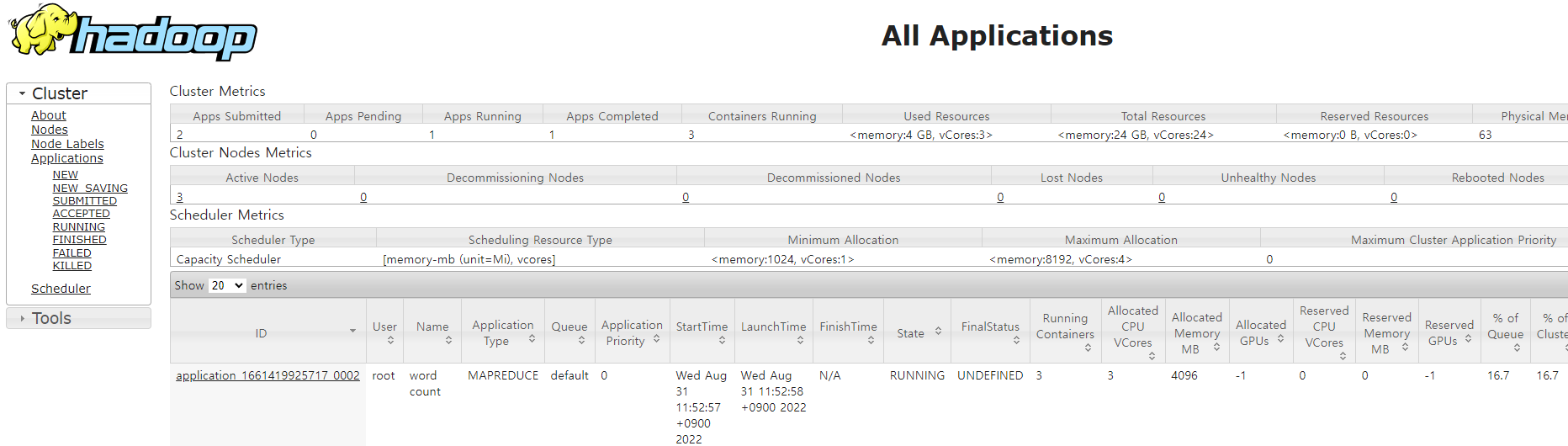
실행 결과를 확인한다.
hadoop fs -cat /tmp/test/wordcount_out/*
“Executable” 1
“Incompatible 3
“Initial 1
“Larger 2
“Licensable” 2
“License” 2
“Modifications” 2
“Original 1
“Participant”) 1
“Patent 2
“Secondary 1
“Source 2
“Your”) 2
“You” 4
“as 1
“commercial 3
“control” 2
...name node web ui 에서 생성된 결과 파일을 확인할 수 있다.
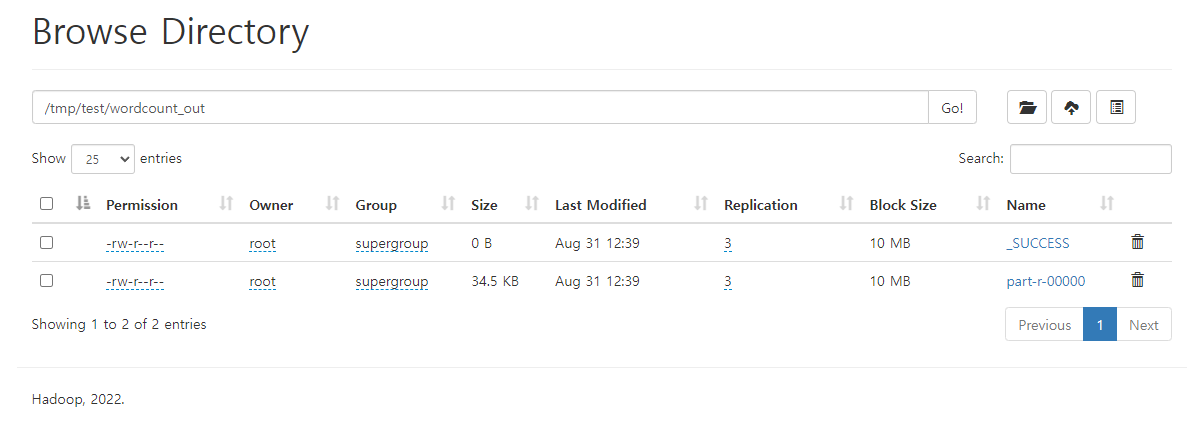
time line server에서 yarn history도 확인할 수 있다.

HDFS test
테스트에 활용할 parquet 파일들을 HDFS에 저장해보면서 어떤식으로 데이터가 저장되는지 알아본다.
Test data
https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page
공개적으로 제공되는 택시의 trip 데이터를 사용한다.
public S3에서 데이터를 다운로드할 수 있다. 2012년, 2013년 데이터를 모두 다운로드한다. ( 총 24개의 parquet 파일, 파일당 약 150~200mb )
zeppelin container와 bind mount되어있는 디렉토리에 다운로드해준다.
aws s3 cp "s3://nyc-tlc/trip data/" /home/ec2-user/testdata/ --recursive --exclude "*" --include "yellow_tripdata_2012*" --include "yellow_tripdata_2013*HDFS
bind mount되어 있기때문에 컨테이너내에서 파일을 인식할 수 있다. 이 파일들을 hdfs에 저장한다.
hadoop fs -put /testdata /tmp저장된 파일을 다음과 같이 확인할 수 있다.
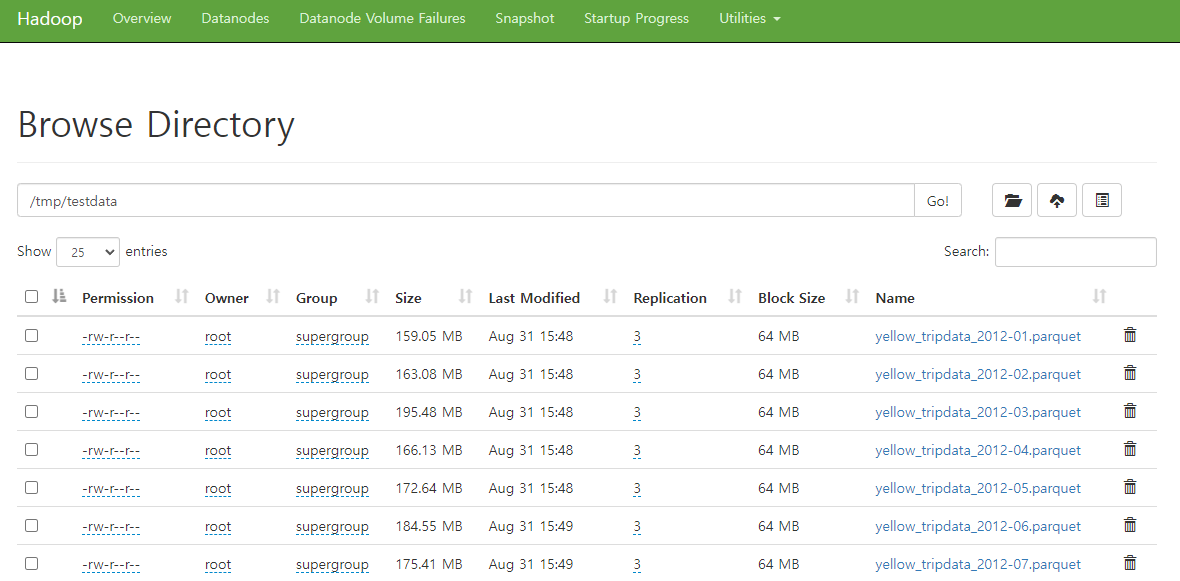
block size를 64mb로 지정해줬기때문에 각 파일들은 여러개의 블록으로 나눠진다. ( 3~4개 )
block size default 는 128mb이다. hadoop 2.x 대 에서는 64mb 였지만 하드웨어, 소프트웨어의 스펙 발전으로 점차 증가되고 있다. 아래의 URL에 block size가 64, 128mb인 이유에 대해 자세히 설명되어있다.
195mb 파일을 예로 들면, 각각의 크기가 64mb, 64mb, 64mb, 3mb 인 4개의 블록으로 나눠지게 된다.
나눠진 블록들을 3개로 복제한다. 결과적으로 총 12개의 block이 생성된다.
hadoop이 block을 replication하는 이유는 특정 데이터 노드의 장애가 발생시 무정지 대응을 가능하도록 하기 위해서다.복제 블록을 서로 다른 데이터 노드에 저장하게 되면 특정 노드에 문제가 생겨도 파일을 읽는데 문제가 없다.
이 12개의 블록은 data node에 고르게 분산되어 저장된다.
즉 hadoop에 데이터를 저장하기 위해선 저장할 데이터 크기의 3배의 용량이 있어야 한다.
실제 블록들이 어느 위치에 저장되어있는지 확인해보자.
예상했던 것처럼 4개의 블록이 3개의 복제본을 가지고 있고,
각 블록이 어느 data node(노드의 ip주소로 구분할 수 있음)에 저장되어 있는지 확인할 수 있다.
hadoop fsck /tmp/testdata/yellow_tripdata_2012-03.parquet -files -blocks -locations
WARNING: Use of this script to execute fsck is deprecated.
WARNING: Attempting to execute replacement "hdfs fsck" instead.
Connecting to namenode via http://namenode:9870/fsck?ugi=root&files=1&blocks=1&locations=1&path=%2Ftmp%2Ftestdata%2Fyellow_tripdata_2012-03.parquet
FSCK started by root (auth:SIMPLE) from /192.168.176.6 for path /tmp/testdata/yellow_tripdata_2012-03.parquet at Wed Aug 31 06:58:16 UTC 2022
/tmp/testdata/yellow_tripdata_2012-03.parquet 204978557 bytes, replicated: replication=3, 4 block(s): OK
0. BP-1753061581-192.168.0.2-1660117267827:blk_1073742645_1821 len=67108864 Live_repl=3 [DatanodeInfoWithStorage[192.168.176.2:9866,DS-d620f107-b1ab-4b33-bcb0-2cc1b35d7e89,DISK], DatanodeInfoWithStorage[192.168.176.8:9866,DS-36e28daf-2b35-4af0-8823-a3990f360721,DISK], DatanodeInfoWithStorage[192.168.176.4:9866,DS-a8901cd6-fc4e-4bd2-9ccd-b85124f8f478,DISK]]
1. BP-1753061581-192.168.0.2-1660117267827:blk_1073742646_1822 len=67108864 Live_repl=3 [DatanodeInfoWithStorage[192.168.176.2:9866,DS-d620f107-b1ab-4b33-bcb0-2cc1b35d7e89,DISK], DatanodeInfoWithStorage[192.168.176.4:9866,DS-a8901cd6-fc4e-4bd2-9ccd-b85124f8f478,DISK], DatanodeInfoWithStorage[192.168.176.8:9866,DS-36e28daf-2b35-4af0-8823-a3990f360721,DISK]]
2. BP-1753061581-192.168.0.2-1660117267827:blk_1073742647_1823 len=67108864 Live_repl=3 [DatanodeInfoWithStorage[192.168.176.8:9866,DS-36e28daf-2b35-4af0-8823-a3990f360721,DISK], DatanodeInfoWithStorage[192.168.176.4:9866,DS-a8901cd6-fc4e-4bd2-9ccd-b85124f8f478,DISK], DatanodeInfoWithStorage[192.168.176.2:9866,DS-d620f107-b1ab-4b33-bcb0-2cc1b35d7e89,DISK]]
3. BP-1753061581-192.168.0.2-1660117267827:blk_1073742648_1824 len=3651965 Live_repl=3 [DatanodeInfoWithStorage[192.168.176.4:9866,DS-a8901cd6-fc4e-4bd2-9ccd-b85124f8f478,DISK], DatanodeInfoWithStorage[192.168.176.2:9866,DS-d620f107-b1ab-4b33-bcb0-2cc1b35d7e89,DISK], DatanodeInfoWithStorage[192.168.176.8:9866,DS-36e28daf-2b35-4af0-8823-a3990f360721,DISK]]
Status: HEALTHY
Number of data-nodes: 3
Number of racks: 1
Total dirs: 0
Total symlinks: 0
Replicated Blocks:
Total size: 204978557 B
Total files: 1
Total blocks (validated): 4 (avg. block size 51244639 B)
Minimally replicated blocks: 4 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 3.0
Missing blocks: 0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Erasure Coded Block Groups:
Total size: 0 B
Total files: 0
Total block groups (validated): 0
Minimally erasure-coded block groups: 0
Over-erasure-coded block groups: 0
Under-erasure-coded block groups: 0
Unsatisfactory placement block groups: 0
Average block group size: 0.0
Missing block groups: 0
Corrupt block groups: 0
Missing internal blocks: 0
FSCK ended at Wed Aug 31 06:58:16 UTC 2022 in 4 milliseconds
The filesystem under path '/tmp/testdata/yellow_tripdata_2012-03.parquet' is HEALTHY특정 파일을 읽을때 블록으로 나눠져있기때문에 병렬로 빠르게 읽을 수 있다.
name node에서는 파일, 파일별 block에 대한 메타정보를 가지고 있다. ( dfs.namenode.name.dir = file:///opt/hadoop/dfs/name 이 경로에 메타데이터가 저장된다. )
이를 사용하여 사용자 입장에서는 block 단위로 접근할 필요가 없어진다.
Spark test
zeppelin 컨테이너에서 spark 테스트를 진행한다.
우선 spark가 정상적으로 실행되는지 확인하기 위해 컨테이너 내부로 들어가 spark shell을 실행해본다.
base 이미지 빌드시 env var를 지정해놨기때문에 바로 사용이 가능하다.
spark-shell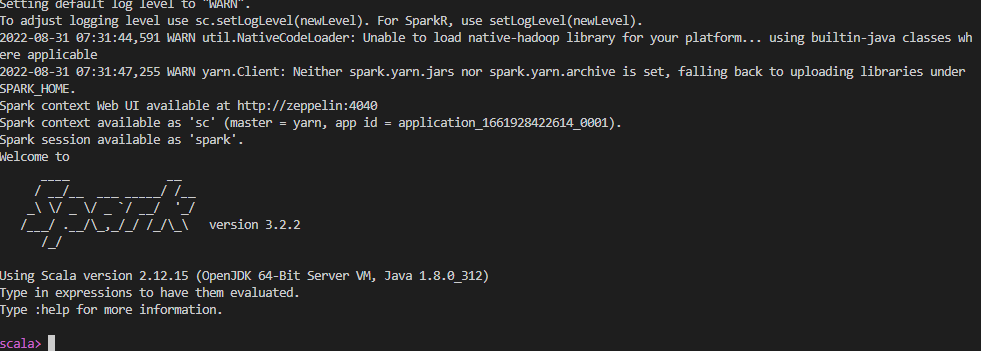
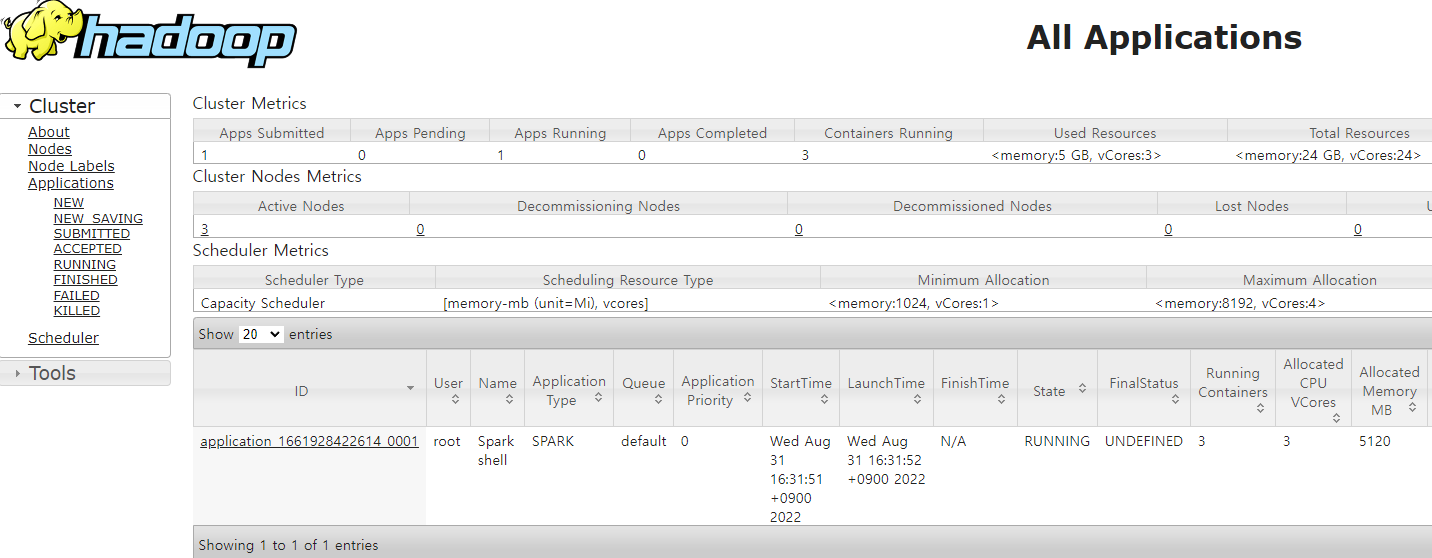
spark master 설정을 yarn으로 했기때문에 yarn client 모드로 실행된다. yarn 위에 spark application이 떠있는지 resource manager를 통해 확인해보자.
shell을 열었기 때문에 state가 running 상태로 떠있는 것을 볼 수 있다. shell을 종료하면 state가 finished로 바뀐다.
이번엔 pyspark를 실행해본다.
pyspark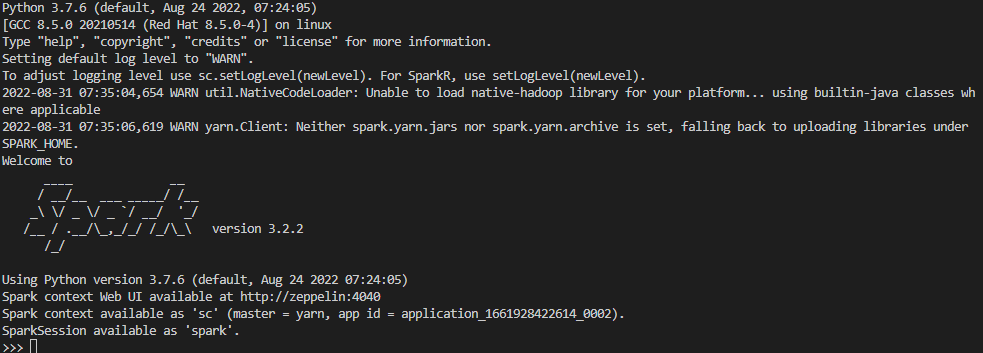
resource manager를 확인해보면 pyspark shell이 뜬 것을 볼 수 있다.
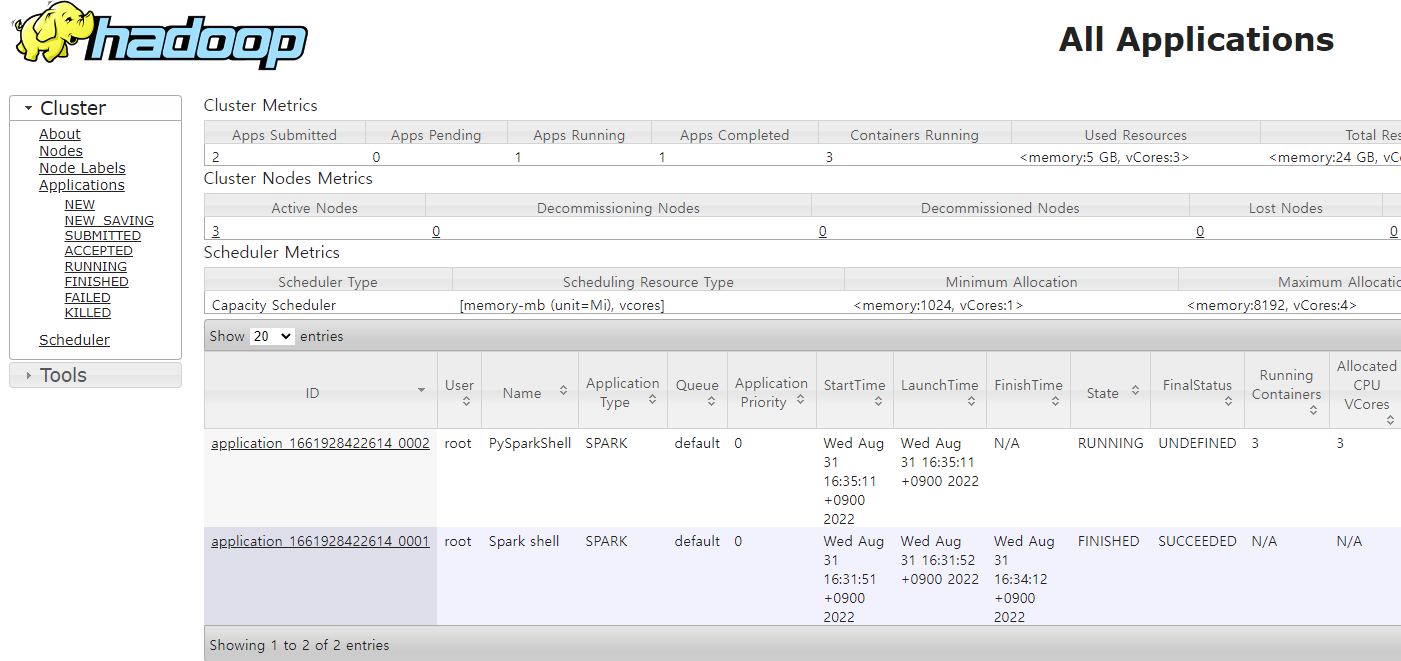
Spark on YARN
spark를 YARN 위에서 실행한다면 원하는 데이터가 저장된 HDFS 위에서 스파크가 돌아가게 되므로 매우 효율적이다.
spark에서 HDFS의 특정파일을 읽어오는 job이 있다고 가정하자.
그 파일이 여러 HDFS data node중 한곳에 저장되어 있다면 YARN은 spark app을 해당 data node로 보낸 후 실행한다.
즉 YARN은 실제 데이터와 데이터를 필요로 하는 application을 물리적으로 가깝게 만들어준다. ( 네트워크를 최대한 덜 타게 해줌 )
spark를 YARN 위에서 사용하는 방법은 크게 2가지가 있다.
Yarn Client mode
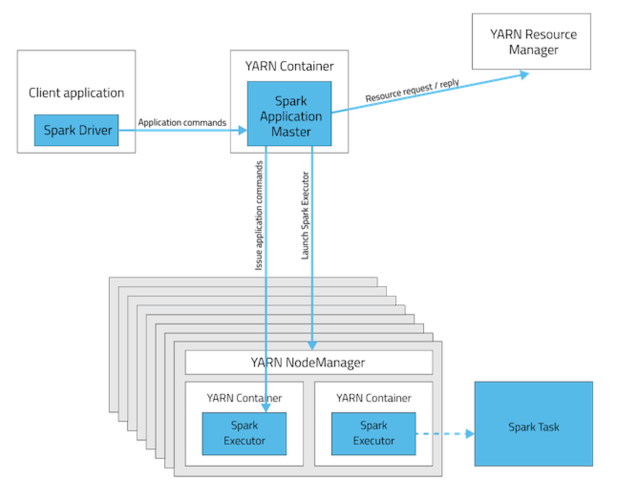
Client 서버에서 애플리케이션을 위한 Driver Program이 실행된다. client 서버에 실제 spark process가 뜨게 된다.
주로 대화형 개발에서의 디버깅용으로 사용하게 된다. 드라이버 프로그램의 출력을 직접 확인 가능.
이 경우 Application master는 단순히 Resource Manager에게 필요한 자원을 요청하는 역할만 한다.
Yarn cluster mode
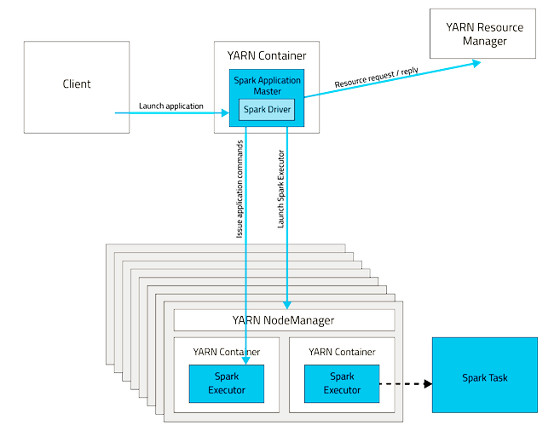
Yarn cluster의 Node manager(hadoop data node) 에 있는 yarn container(docker container 아님) 에서 spark driver가 실행되고 명령을 주고 받는다.
- Client가 Spark Application을 Resource Manager에게 제출
- Resource Manager는 NodeManager 중 하나를 선정해서 Application master(Driver)를 실행할 컨테이너를 할당하라고 지시
- NodeManager는 Application master(Driver)의 컨테이너를 시작
- Application master(Driver)는 Spark executor에 사용할 컨테이너들을 리소스 매니저에 추가로 요청
- Resource Manager가 리소스 할당을 ok 하면, Application master(Driver)는 Node Manger에게 컨테이너를 시작하라고 지시
- NodeManager는 Spark executor에서 사용할 컨테이너를 시작
- driver와 executor는 직접 통신하면서 Spark application을 수행한다.
Zeppelin
zeppelin에서 spark interpreter를 제공한다. interpreter 설정을 적절히 해준 후 사용하도록 한다.
spark.master는 zeppelin-env.sh 에서 미리 설정할 수 있지만 spark.submit.deploymode는 미리 설정할 수 없다.
spark.submit.deploymode = cluster or client
spark.app.name = zeppelin (자유롭게 설정, yarn 모니터링에서 name으로 출력된다. )
으로 설정해준다.
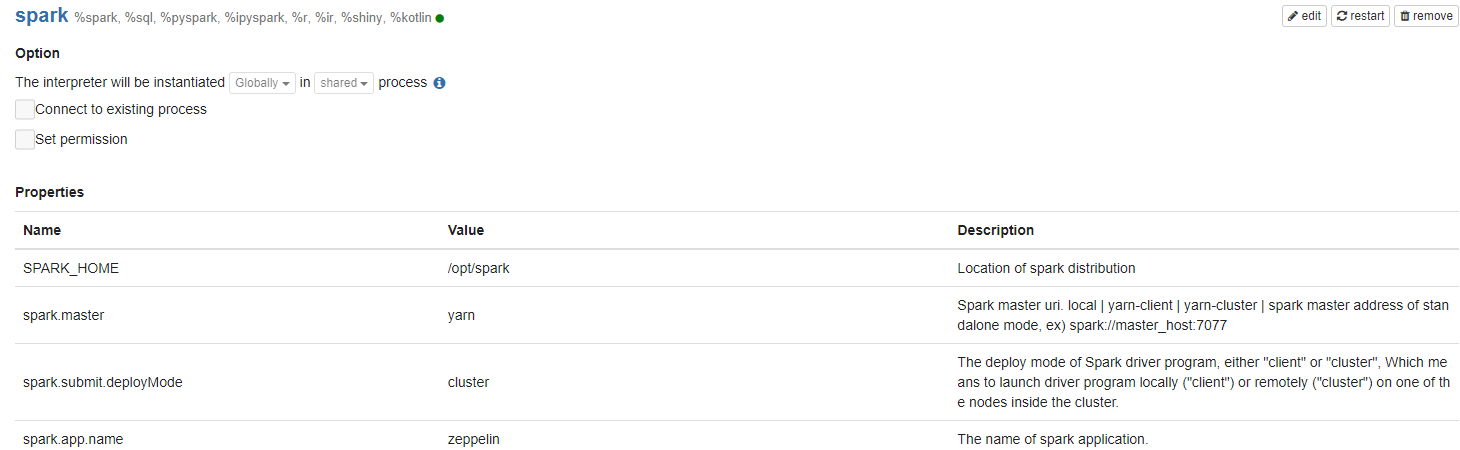
제대로 설정 되었다면 yarn container내에서 실행된 spark driver 프로그램의 spark session 객체를 call할 수 있다.

ession을 call하게 되면 yarn resource manager에서 application 정보를 확인할 수 있다.
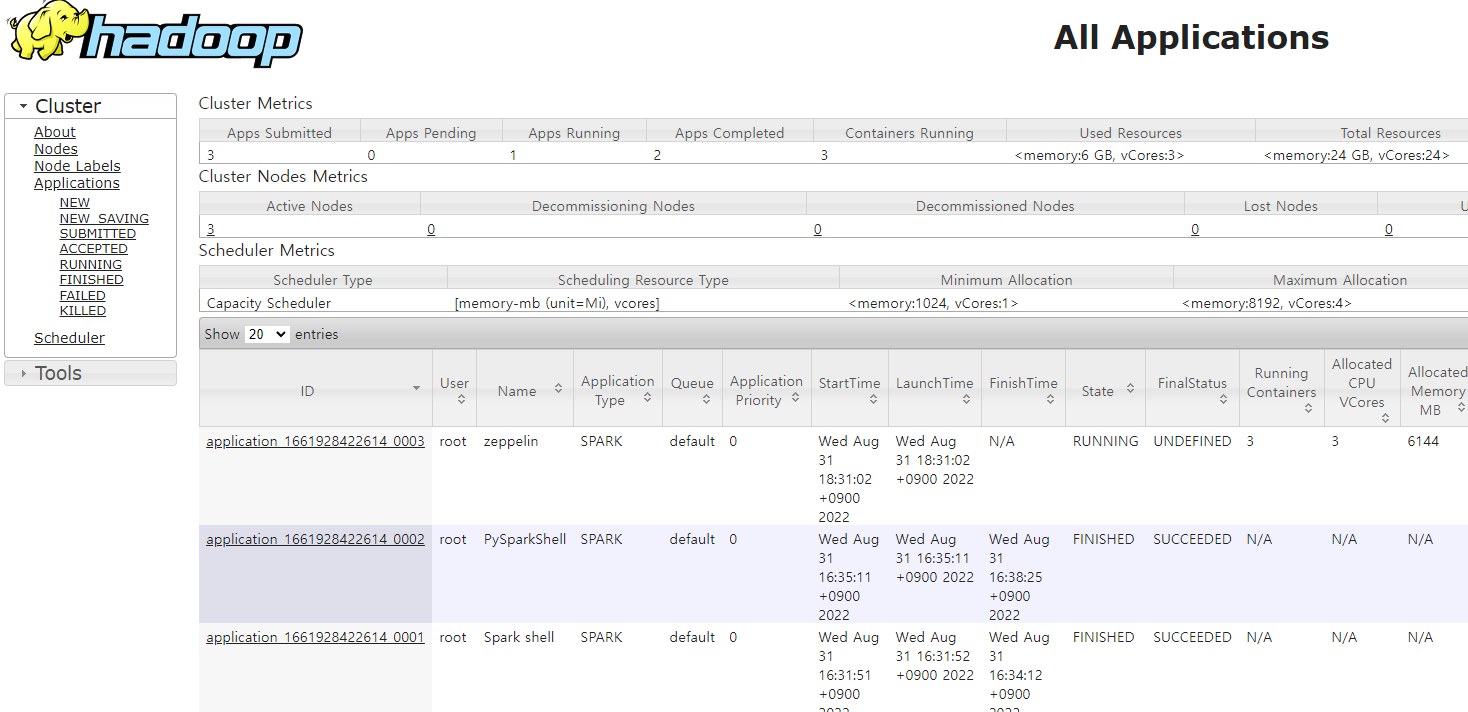
HDFS 데이터 처리
HDFS에 저장한 테스트 데이터를 불러와보자.
%pyspark
tripdata = spark.read.parquet("hdfs://namenode:9000/tmp/testdata/")10개의 row를 확인해본다.
%pyspark
tripdata.show(10)
+--------+--------------------+---------------------+---------------+-------------+----------+------------------+------------+------------+------------+-----------+-----+-------+----------+------------+---------------------+------------+--------------------+-----------+
|VendorID|tpep_pickup_datetime|tpep_dropoff_datetime|passenger_count|trip_distance|RatecodeID|store_and_fwd_flag|PULocationID|DOLocationID|payment_type|fare_amount|extra|mta_tax|tip_amount|tolls_amount|improvement_surcharge|total_amount|congestion_surcharge|airport_fee|
+--------+--------------------+---------------------+---------------+-------------+----------+------------------+------------+------------+------------+-----------+-----+-------+----------+------------+---------------------+------------+--------------------+-----------+
| 1| 2012-01-01 00:07:56| 2012-01-01 00:12:09| 1| 0.9| 1| N| 158| 231| 2| 4.9| 0.5| 0.5| 0.0| 0.0| 0.0| 5.9| null| null|
| 1| 2012-01-01 00:18:49| 2012-01-01 00:30:01| 1| 2.3| 1| N| 231| 164| 2| 8.5| 0.5| 0.5| 0.0| 0.0| 0.0| 9.5| null| null|
| 1| 2012-01-01 00:31:38| 2012-01-01 00:46:05| 1| 2.2| 1| N| 164| 148| 2| 9.3| 0.5| 0.5| 0.0| 0.0| 0.0| 10.3| null| null|
| 1| 2012-01-01 00:47:35| 2012-01-01 00:55:57| 4| 0.9| 1| N| 148| 107| 2| 5.3| 0.5| 0.5| 0.0| 0.0| 0.0| 6.3| null| null|
| 1| 2012-01-01 00:57:08| 2012-01-01 01:02:42| 3| 0.7| 1| N| 107| 107| 2| 4.5| 0.5| 0.5| 0.0| 0.0| 0.0| 5.5| null| null|
| 1| 2012-01-01 00:47:10| 2012-01-01 01:06:18| 1| 4.7| 1| N| 226| 239| 1| 14.9| 0.5| 0.5| 2.0| 0.0| 0.0| 17.9| null| null|
| 1| 2012-01-01 00:16:42| 2012-01-01 00:40:14| 1| 2.3| 1| N| 234| 237| 2| 12.9| 0.5| 0.5| 0.0| 0.0| 0.0| 13.9| null| null|
| 1| 2012-01-01 00:40:46| 2012-01-01 01:03:49| 1| 2.2| 1| N| 237| 68| 1| 12.9| 0.5| 0.5| 2.0| 0.0| 0.0| 15.9| null| null|
| 1| 2012-01-01 00:10:04| 2012-01-01 00:20:54| 1| 2.4| 1| N| 161| 263| 1| 8.9| 0.5| 0.5| 2.97| 0.0| 0.0| 12.87| null| null|
| 1| 2012-01-01 00:28:10| 2012-01-01 00:32:50| 1| 1.4| 1| N| 237| 236| 1| 5.3| 0.5| 0.5| 1.89| 0.0| 0.0| 8.19| null| null|
+--------+--------------------+---------------------+---------------+-------------+----------+------------------+------------+------------+------------+-----------+-----+-------+----------+------------+---------------------+------------+--------------------+-----------+
only showing top 10 rows데이터로 view를 만들어 spark sql를 사용한다.
%pyspark
tripdata.createOrReplaceTempView("trip")
%sql
select *
from trip
limit 10불러온 데이터를 집계 테이블로 만든 후 HDFS에 파티션을 나눠 parquet 형식으로 저장한다.
%pyspark
from pyspark.sql.functions import *
trip_df_0 = tripdata.select(
year("tpep_pickup_datetime").alias("year"),
month("tpep_pickup_datetime").alias("month"),
dayofmonth("tpep_pickup_datetime").alias("day"),
tripdata.PULocationID.alias("start_location"),
"trip_distance",
"passenger_count",
"total_amount",
)
trip_df_1 = trip_df_0.groupBy(
"year",
"month",
"day",
"start_location"
).avg(
"trip_distance",
"passenger_count",
"total_amount",
)\
.withColumnRenamed("avg(trip_distance)", "avg_distance") \
.withColumnRenamed("avg(passenger_count)", "avg_passenger_count") \
.withColumnRenamed("avg(total_amount)", "avg_amount")
trip_df_1.write.partitionBy("year", "month", "day").mode("overwrite").parquet("hdfs://namenode:9000/tmp/test_out/")새로 저장한 데이터를 불러온다.
%pyspark
summarydata = spark.read.parquet("hdfs://namenode:9000/tmp/test_out")
summarydata.show()name node web에서 확인할 수 있다.
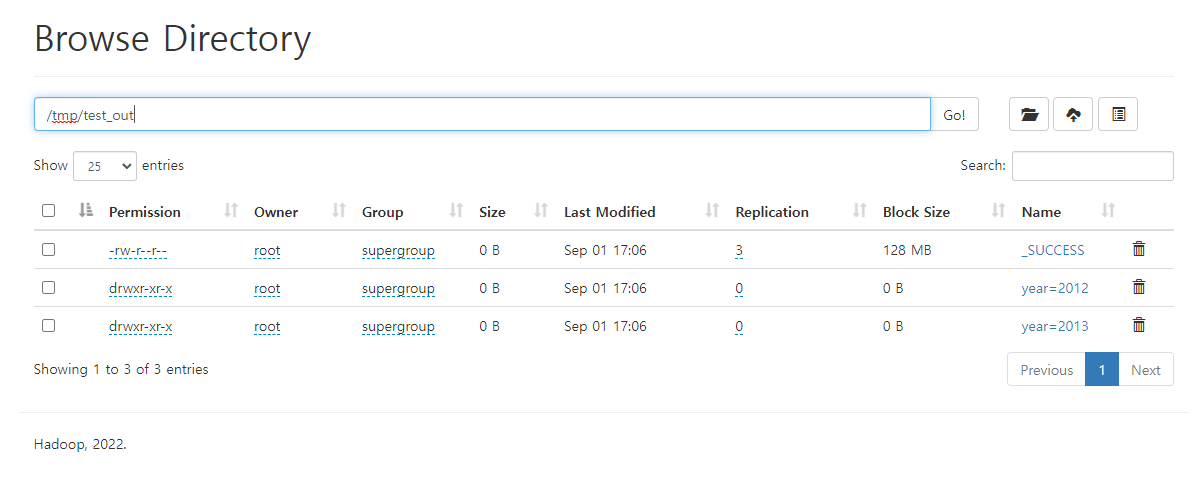
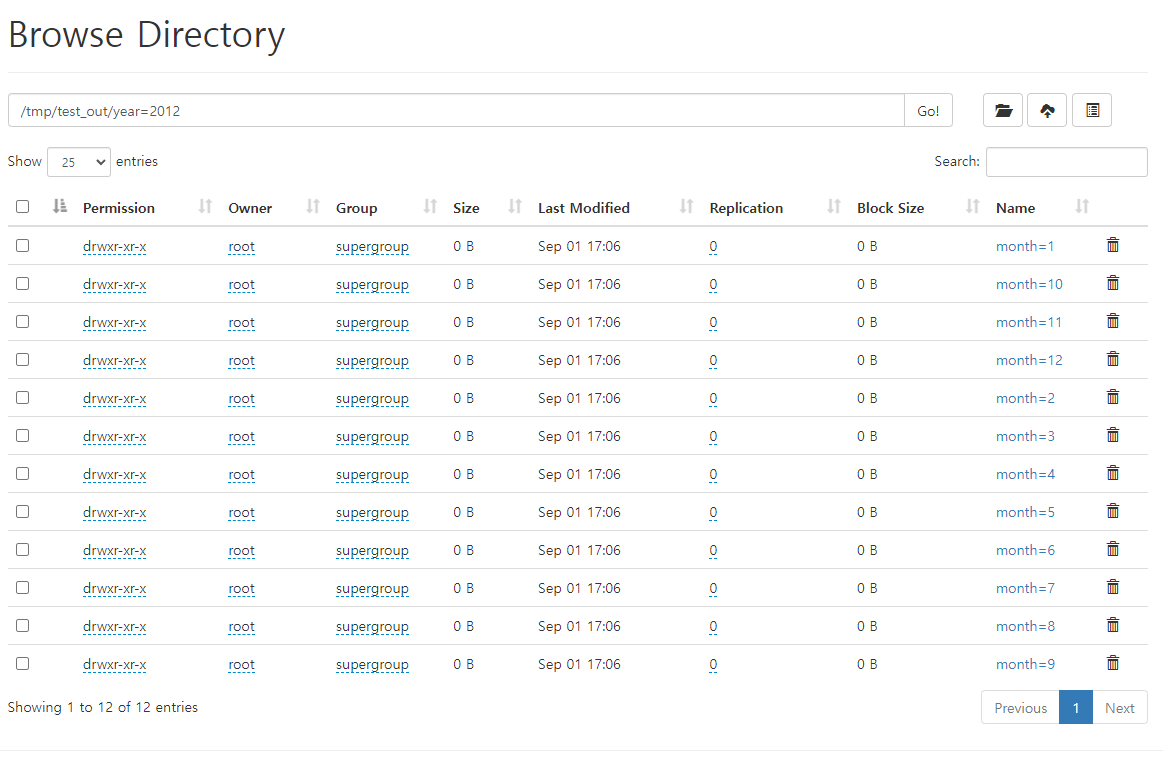
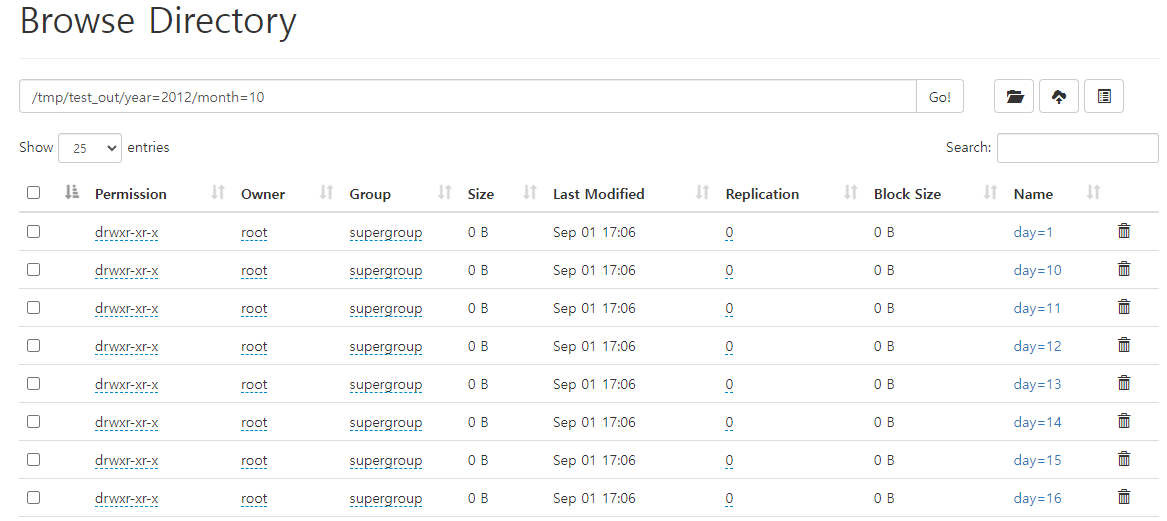
Spark submit
위에서 대화형 쉘로 처리했던 코드를 스크립트로 작성하고 YARN에 제출해보자.
먼저 스크립트 파일을 작성한다.
YARN에 제출할거고 관련 설정을 해줬기때문에 스크립트내에서 spark session conf를 설정해줄 필요는 없다.
from pyspark.sql.functions import *
from pyspark.sql import SparkSession
with SparkSession.builder.appName("yellow data summary").getOrCreate() as spark:
tripdata = spark.read.parquet("hdfs://namenode:9000/tmp/testdata/")
trip_df_0 = tripdata.select(
year("tpep_pickup_datetime").alias("year"),
month("tpep_pickup_datetime").alias("month"),
dayofmonth("tpep_pickup_datetime").alias("day"),
tripdata.PULocationID.alias("start_location"),
"trip_distance",
"passenger_count",
"total_amount",
)
trip_df_1 = trip_df_0.groupBy(
"year",
"month",
"day",
"start_location"
)\
.avg(
"trip_distance",
"passenger_count",
"total_amount",
)\
.withColumnRenamed("avg(trip_distance)", "avg_distance") \
.withColumnRenamed("avg(passenger_count)", "avg_passenger_count") \
.withColumnRenamed("avg(total_amount)", "avg_amount")
trip_df_1.write.partitionBy("year", "month", "day").mode("overwrite").parquet("hdfs://namenode:9000/tmp/test_out_2/")작성된 파일을 YARN에 cluster mode로 제출한다.
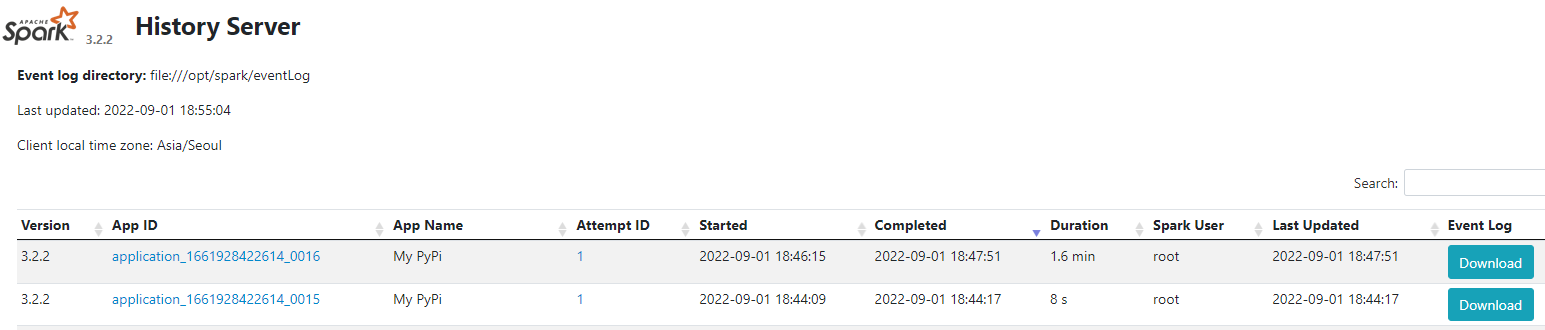
spark-submit --master yarn --deploy-mode cluster pyspark_test.pyyarn resource manager, yart timeline server, spark history server에서 각각 작업이 제대로 수행된 것을 확인할 수 있다.
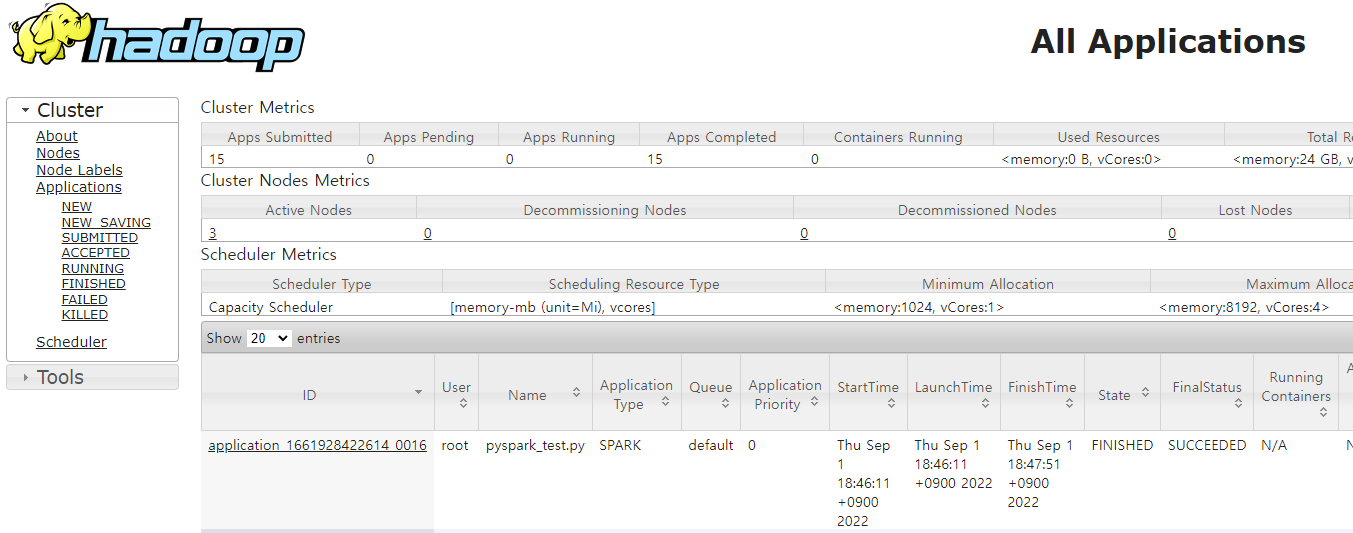


안녕하세요. 블로그가 큰 힘이 되고 있습니다.
한가지 문의드립니다.
spark.submit.deploymode = cluster or client 이걸 어디서 세팅할까요 ?
캡쳐에서 보여지는 spark 화면이 어디인지..