
🚀 들어가기
배열 자료구조로 탐색을 진행하다보면 시간이 너무 오래 걸리는 경우가 있습니다. 배열의 시작부터 탐색해야 하니까요. 그럼 이런 생각이 들죠, '굳이 처음부터 찾아야하나?', '인덱스가 아니라 다른 값으로 데이터를 찾을 순 없나?'
어떻게 하면 빠르게 데이터를 찾을 수 있을까요?
✨ 해시 테이블
💡 개념
해시 테이블(Hash Table)은 시작부터 탐색해서 우리를 기다리게 하는 기존 배열의 단점을 극복했습니다. 배열에게 인덱스가 있다면 해시 테이블에는 키(Key)가 있는 것이죠. 키를 통해 데이터를 바로 받아올 수 있습니다.
해시 테이블은 키를 통해 바로 데이터를 받아올 수 있으므로 속도가 획기적으로 빨라집니다. 다만 보통 배열로 미리 해시 테이블의 크기만큼 생성 후에 사용하기 때문에 공간의 낭비가 있을 수 있습니다.
해시 테이블을 구현하기 위해서는 몇가지 용어를 알아야 합니다.
해시 테이블 또한 결국 배열로 구현되기 때문에 데이터가 놓여질 위치를 나타낼 인덱스가 필요합니다. 이렇게 인덱스를 만드는 과정을 해시(Hash) 라고 합니다. 키라는 임의의 값을 고정 길이의 또다른 값으로 변환시키는 것입니다.
또 이러한 해시라는 과정을 수행하는 함수를 해싱 함수(Hashing Function) 라고 합니다. 해싱 함수들의 예시는 아래에서 설명하겠습니다.
해시 값(Hash Value) 이란 임의의 값인 키를 해싱 함수로 변환한 값을 의미합니다. 이 해시 값이 인덱스로 동작하여 하나의 키를 통해 데이터를 바로 탐색할 수 있게 됩니다.
파이썬에서는 해시 테이블을 딕셔너리(Dictionary)라는 타입을 사용하여 이미 구현해 놓았습니다.
다음은 그림으로 해시 테이블을 설명해보겠습니다.
📗 설명
⏺️ 해시 테이블
먼저 키가 k로 주어졌다고 해보겠습니다. 키에 해당되는 데이터를 value라고 하겠습니다.
k를 해싱 함수 h(k)에 입력하면 해시를 수행하여 해시 값인 i가 출력됩니다. 즉 h(k) = i 가 되는 것이죠. 이 i 값을 인덱스로 사용하여 배열로 선언된 해시 테이블 ht의 i번째 위치에 value를 저장합니다.


저장된 value를 k를 통해 탐색해보겠습니다. value는 search_data라고 부르겠습니다.
value를 저장할 때와 동일하게 k를 h(k)에 대입하여 i를 구하고 ht의 i번째 위치에 접근하여 value를 구할 수 있습니다.


⏺️ 해시 테이블의 충돌
위에서 해싱 함수들을 설명하겠다고 했는데요, 해싱 함수의 종류는 많이 있습니다. 그 이유는 해시의 특성 때문입니다.
앞서 말했듯이 해시는 임의의 값을 고정된 또다른 값으로 변환시키는 과정입니다. 여기서 문제는 키에서 변형된 또다른 값, 즉 해시 값이 동일한 경우입니다.
예를 들어 네 개의 키 후보 a,b,c,d가 있다고 해보죠. 또 임의의 해싱 함수 h(k)가 있습니다. 해싱 함수의 결과가 다음과 같다면 어떻게 될까요?
- h(a) = 0
- h(b) = 1
- h(c) = 2
- h(d) = 0
두 개의 키, a와 d의 해시 값이 동일합니다. 이러한 문제를 충돌(Collision), 또는 해시 충돌(Hash Collision)이라고 합니다.

충돌 현상을 방지하기 위한 가장 단순한 방법은 좋은 해싱 함수를 사용하는 것입니다.
여러 키에서 동일한 해시 캆이 나오지 않도록 하는 해싱 함수를 사용하여 충돌을 방지할 수 있습니다.

여러 해싱 함수 중 가장 많이 사용되는 함수는 SHA-256이라는 함수입니다. 이 해싱 함수는 보안을 위한 알고리즘에 많이 사용됩니다.
⏺️ 해시 테이블의 충돌 방지 알고리즘
좋은 해싱 함수를 사용한다고 해서 충돌을 완전히 피할 수는 없습니다. 충돌을 방지하는 또다른 접근은 알고리즘을 적용하는 것입니다. 대표적인 알고리즘에는 Chaining 기법과 Linear Probing 기법이 있습니다.
먼저 Chaining 기법을 알아보겠습니다. Chaining 기법은 개방 해싱(Open Hashing)의 기법 중 하나로 해시 테이블 저장공간 외의 공간을 활용하는 기법입니다.
앞선 예시처럼 키 a와 b의 해시 값이 같아서 충돌이 벌어진 경우입니다.

Chaining 기법은 해시 테이블에 링크드 리스트를 접목시킵니다. 해시 테이블의 해시 값에 대응되는 위치에 데이터를 링크드 리스트 형식으로 저장합니다.
이 기법을 활용하여 해시 값이 충돌하여도 해시 값에 해당되는 링크드 리스트를 통해 데이터를 저장하고 탐색할 수 있습니다.
충돌이 벌어진 0의 위치에 해당하는 링크드 리스트에 d를 추가하여 저장합니다.

다음으로 Linear Probing 기법을 알아보겠습니다. Linear Probing 기법은 폐쇄 해싱(Close Hasjing) 기법 중 하나로 해시 테이블 저장공간 안에서 충돌 문제를 해결하는 기법입니다.
이전과 같은 예시를 사용하겠습니다.
Linear Probing 기법은 충돌이 일어났을 때 충돌이 일어난 해쉬 값의 다음 위치에서부터 탐색하여 빈공간이 있을 때 해당 공간에 저장하는 기법입니다.
키 a,d가 동일한 해시 값으로 인해 0에서 층돌이 벌어져 d의 value를 0에서 가장 가까운 빈공간인 3에 저장합니다.
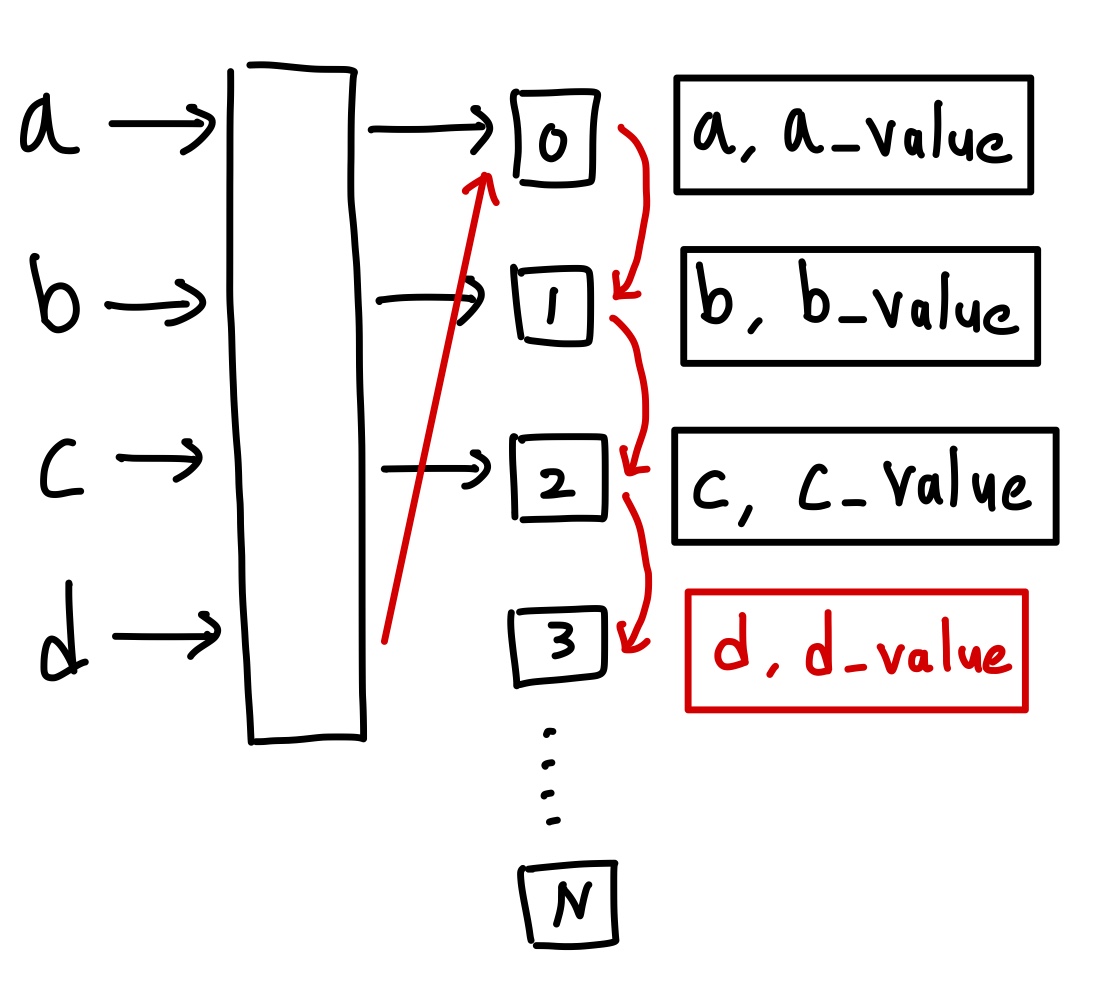
Linear Probing 기법은 해시 테이블 저장공간을 최대로 활용하는 장점이 있습니다. 하지만 일정 해시 값 근처에서 충돌이 반복되는 클러스터링(clustering) 문제가 발생할 수 있습니다. 또한 해시 테이블 저장공간이 충분해야 한다는 단점이 있습니다.
📝 파이썬으로 구현
⏺️ 해시 테이블
다음은 파이썬으로 해시 테이블을 구현해보겠습니다.
파이썬은 이미 딕셔너리 타입을 선언했기 때문에 먼저 딕셔너리를 사용하지 않은 해시 테이블을 구현하고 딕셔너리의 사용법을 설명해보겠습니다.
먼저 해시 테이블로 사용할 배열 리스트를 선언합니다. 길이는 10으로 설정하겠습니다.
hash_table = list([0 for _ in range(10)]) #[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]다음은 해시 함수를 구현해보겠습니다. 해시 함수는 다양하지만 본 예시에서는 간단한 해시 함수를 구현할건데요, 나눗셈범(division)을 사용해보겠습니다.
def hash_func(key):
return key % 5이제 key를 해시 함수에 입력하여 해시 값을 얻고 해시 테이블에 데이터를 저장하는 동작과 해시 테이블에서 데이터를 얻는 동작을 구현해보겠습니다.
class HashTable:
def __init__(self, length):
self.hash_table = list([0 for _ in range(length)])
def hash_func(self, key):
return key % 5
def save_data(self, data):
key = ord(data[0][0])
value = data[1]
hash_value = self.hash_func(key)
self.hash_table[hash_value] = value
def get_data(self, data):
key = ord(data[0])
hash_value = self.hash_func(key)
return self.hash_table[hash_value]
def show_table(self):
print(self.hash_table)
hash_table = HashTable(10)
data1 = ['Apple', 1000]
data2 = ['Banana', 2000]
data3 = ['Orange', 3000]
hash_table.save_data(data1)
hash_table.save_data(data2)
hash_table.save_data(data3)
hash_table.show_table() # [1000, 2000, 0, 0, 3000, 0, 0, 0, 0, 0]
print(data1[0], hash_table.get_data(data1[0])) # Apple 1000⏺️ 충돌 방지 기법
일반적인 해시 테이블의 구현은 완료했습니다. 다음은 충돌 현상을 방지한 Chaining 기법과 Linear Probing 기법을 구현해보겠습니다.
새로운 데이터 data4를 추가할 때 hash_func로 만들어진 해시 값이 1로 충돌이 발생합니다.
data2 = ['Banana', 2000] # ord('B') % 5 = 1
data4 = ['Lemon', 5000] # ord('L') % 5 = 1먼저 Chaining 기법입니다. 1에서의 충돌을 방지했습니다.
class HashTable:
def __init__(self, length):
self.hash_table = list([0 for _ in range(length)])
def hash_func(self, key):
return key % 5
def save_data(self, data):
key = ord(data[0][0])
value = data[1]
hash_value = self.hash_func(key)
if self.hash_table[hash_value] != 0:
for index in range(len(self.hash_table[hash_value])):
# 기존에 있는 값을 수정
if self.hash_table[hash_value][index][0] == key:
self.hash_table[hash_value][index][1] = value
self.hash_table[hash_value].append([key, value])
else:
self.hash_table[hash_value] = [[key, value]]
def get_data(self, data):
key = ord(data[0])
hash_value = self.hash_func(key)
if self.hash_table[hash_value] != 0:
for index in range(len(self.hash_table[hash_value])):
if self.hash_table[hash_value][index][0] == key:
return self.hash_table[hash_value][index][1]
return None
else:
return None
def show_table(self):
print(self.hash_table)
# 테스트 데이터
hash_table = HashTable(10)
data1 = ['Apple', 1000]
data2 = ['Banana', 2000]
data3 = ['Orange', 3000]
data4 = ['Lemon', 5000]
hash_table.save_data(data1)
hash_table.save_data(data2)
hash_table.save_data(data3)
hash_table.save_data(data4)
hash_table.show_table() # [[[65, 1000]], [[66, 2000], [76, 5000]], 0, 0, [[79, 3000]], 0, 0, 0, 0, 0]
# 데이터 검색
print(data2[0], hash_table.get_data(data2[0])) # Banana 2000
print(data4[0], hash_table.get_data(data4[0])) # Lemon 5000다음은 Linear Probing 기법입니다.
class HashTable:
def __init__(self, length):
self.hash_table = list([0 for _ in range(length)])
def hash_func(self, key):
return key % 5
def save_data(self, data):
key = ord(data[0][0])
value = data[1]
hash_value = self.hash_func(key)
if self.hash_table[hash_value] != 0:
for index in range(hash_value, len(self.hash_table)):
# 새로운 위치에 값 추가
if self.hash_table[index] == 0:
self.hash_table[index] = [key, value]
return
# 기존에 있는 값을 수정
elif self.hash_table[index][0] == key:
self.hash_table[index][1] = value
return
print('테이블이 모두 찼습니다.')
else:
self.hash_table[hash_value] = [key, value]
def get_data(self, data):
key = ord(data[0])
hash_value = self.hash_func(key)
if self.hash_table[hash_value] != 0:
for index in range(hash_value, len(self.hash_table)):
if self.hash_table[index] == 0:
return None
elif self.hash_table[index][0] == key:
return self.hash_table[index][1]
else:
return None
def show_table(self):
print(self.hash_table)
# 테스트 데이터
hash_table = HashTable(10)
data1 = ['Apple', 1000]
data2 = ['Banana', 2000]
data3 = ['Orange', 3000]
data4 = ['Lemon', 5000]
hash_table.save_data(data1)
hash_table.save_data(data2)
hash_table.save_data(data3)
hash_table.save_data(data4)
hash_table.show_table() # [[65, 1000], [66, 2000], [76, 5000], 0, [79, 3000], 0, 0, 0, 0, 0]
# 데이터 검색
print(data2[0], hash_table.get_data(data2[0])) # Banana 2000
print(data4[0], hash_table.get_data(data4[0])) # Lemon 5000⏺️ 딕셔너리
파이썬으로 구현한 해시 테이블과 두 가지 충돌 방지 기법을 알아보았습니다. 이제 파이썬에 내장되어 있는 딕셔너리 타입을 알아보겠습니다.
딕셔너리의 선언은 아래와 같은 두 가지 방법으로 가능합니다.
fruit_dict = dict()
fruit_dict = {}선언과 동시에 초기화도 할 수 있습니다. 왼쪽이 key, 오른쪽이 value입니다.
fruit_dict = {
'Apple' : 1000,
'Banana' : 2000,
'Orange' : 3000,
'Lemon' : 5000
}다음은 딕셔너리의 각종 동작입니다.
fruit_dict = {
'Apple' : 1000,
'Banana' : 2000,
'Orange' : 3000,
'Lemon' : 5000
}
# 키를 이용한 값 접근
print(fruit_dict["Apple"]) # 1000
# 새로운 키-값 쌍 추가
fruit_dict["Grapes"] = 4000
# "Apple" 키에 연결된 값을 업데이트
fruit_dict["Apple"] = 8000
# "Banana" 키에 연결된 키-값 쌍 삭제
del fruit_dict["Banana"]
# 딕셔너리에 키가 존재하는지 확인
if "Apple" in fruit_dict:
print("딕셔너리에 'Apple' 키가 존재합니다.")다음은 딕셔너리의 반복입니다.
# 키를 이용한 반복
for key in fruit_dict:
print(key)
# 값에 대한 반복
for value in fruit_dict.values():
print(value)
# 키-값 쌍에 대한 반복
for key, value in fruit_dict.items():
print(key, value)딕셔너리는 키와 관련된 특징이 있습니다. 먼저 딕셔너리의 키로는 변경 가능한 데이터 타입을 사용할 수 없습니다. 키는 불변 데이터 타입이어야 한다는 것이죠.
예를 들어 문자열, 숫자, 튜플은 딕셔너리의 키로 사용할 수 있지만 리스트는 변경 가능한 데이터 타입이기 때문에 키로 사용할 수 없습니다.
fruit_dict[["Mango","Melon"]] = 2000 # TypeError: unhashable type: 'list'
fruit_dict[("Mango","Melon")] = 2000또 딕셔너리는 존재하지 않는 키로 접근하면 KeyError가 발생합니다. 딕셔너리에 키로 접근해야 할 때 먼저 딕셔너리에 해당 키가 존재하는지 확인하여 에러 발생을 예방할 수 있습니다.
print(fruit_dict["Kiwi"]) # KeyError: 'Kiwi'
if 'Kiwi' in fruit_dict:
print(fruit_dict["Kiwi"])
else:
print('Kiwi가 존재하지 않습니다.') # Kiwi가 존재하지 않습니다.또는 딕셔너리의 get 함수를 사용할 수 있습니다.
print(fruit_dict.get("Kiwi")) # None
# default 값 설정 가능
print(fruit_dict.get("Kiwi",0)) # 0이밖에 DefaultDictionary라는 라이브러리를 사용하여 에러를 방지할 수 있습니다.
from collections import defaultdict
fruit_dict = defaultdict(int)
fruit_list = [('Apple',1000),('Banana',2000),('Orange', 3000),('Lemon', 5000)]
for fruit in fruit_list:
fruit_dict[fruit[0]] = fruit[1]
print(fruit_dict['Kiwi']) # 0🎁 관련 문제
