CNN은 인간의 시신경을 모방한 모델로 주로 자연어처리, 이미지처리에 잘 활용된다는 특징이 있습니다. 이번 동아리 발표주제가 CNN이기도 하고 텍스트 분류에도 활용될 수 있기 때문에 CNN에 대해 한번 정리해 보겠습니다.
Neural Network의 한계
기존 neural network는 모든 입력벡터마다 가중치를 다르게 주어 학습을 진행했습니다. 이는 잘 정리된 데이터나, 1차원 데이터에선 좋은 성능을 내지만, 고차원 데이터, 특히 이미지나 영상 데이터에선 오히려 이 방식은 단점으로 드러납니다.
예를 들면 강아지 사진을 학습시켜, 새로운 사진이 주어졌을때 강아지를 분류하는 task에선

위 사진을 새로운 사진으로 주었을때 강아지로 분류할 것입니다.

하지만 강아지의 눈을 가린채 새로운 사진으로 준다면 기존 neural network에선 이 사진을 강아지로 분류하지 않을 가능성이 높습니다.
왜냐하면 2차원 데이터를 1차원으로 flatten 시키는 과정에서 데이터 손실이 발생하고, 2차원 데이터의 한 픽셀의 값이 달라졌기 때문에 일정 임계값까지 점수가 도달하지 않아 결국 강아지가 아니라는 결과를 내놓을 것입니다.
결국 기존의 neural network는 1차원 데이터만 효율적으로 다루기 때문에 데이터의 공간적 특성이 사라져버리는 한계가 존재합니다.
Convolution
CNN에 대해 자세히 알아보기 전에 Convolution(합성곱)에 대해 잠깐 알아보겠습니다.
Convolution의 정의는 아래와 같습니다.
연속:
이산:
정의를 살펴보면 두 함수 f,g에서 g함수를 y축을 기준으로 반전하고, 일정 보폭만큼 평행이동한 함수값과, f의 함수값을 곱한뒤 다 더한 값이 바로 convolution입니다.
CNN
CNN은 convolution을 모델 학습에 적용한 모델입니다. CNN의 구조를 살펴보면 그림과 같습니다.
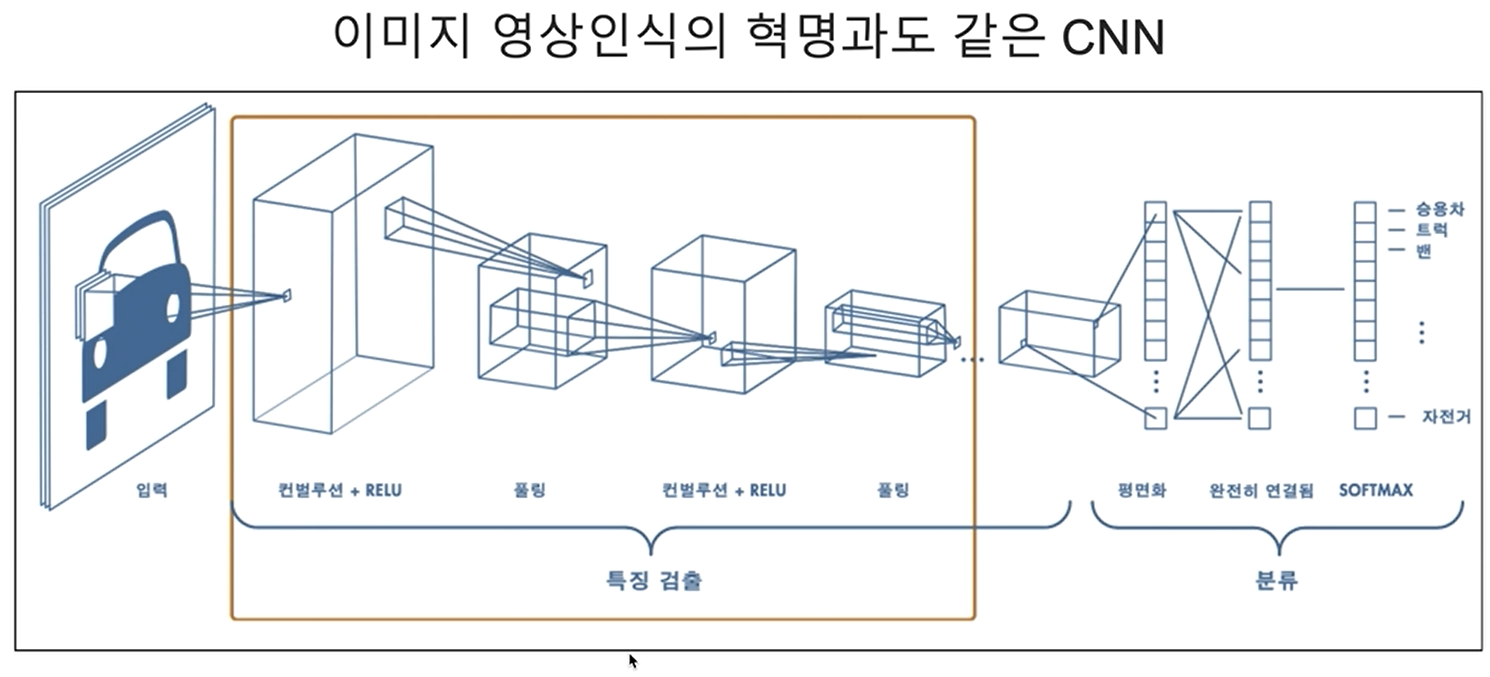
먼저 입력을 보면 이미지 데이터는 총 3장으로 되어있습니다. 이는 이미지 데이터의 특징입니다. 색을 표현하기 위해서 RGB값을 저장하게 되는데 red, green, blue 3가지의 정보가 담긴 채널이 각각 하나씩 총 3개가 존재합니다.
다른 특징으론 2차원 데이터를 1차원으로 축소시키지 않았습니다. 2차원 데이터를 그대로 받아 중요한 정보가 있는 지점만 학습하여 레이어를 쌓습니다.
컨벌루션 + RELU단계에선 2차원 데이터를 한번에 받는게 아니라 일정 영역에 있는 값만 입력으로 받는 것을 볼 수 있습니다. 이때 데이터를 받아오는 영역을 receptive field(수용영역)이라고 하고, 데이터를 받아올때 가중치를 정보다 담긴 부분을 필터 혹은 커널이라고 합니다.
CNN은 바로 이 filter(필터)를 학습하게 됩니다.
Convolutional Filter
필터는 우리가 학습시켜야할 목표입니다. 바로 이 부분이 앞서 우리가 살펴볼 합성곱이 활용되는 부분입니다.
먼저 필터가 어떻게 생겼는지에 대해 살펴보겠습니다.
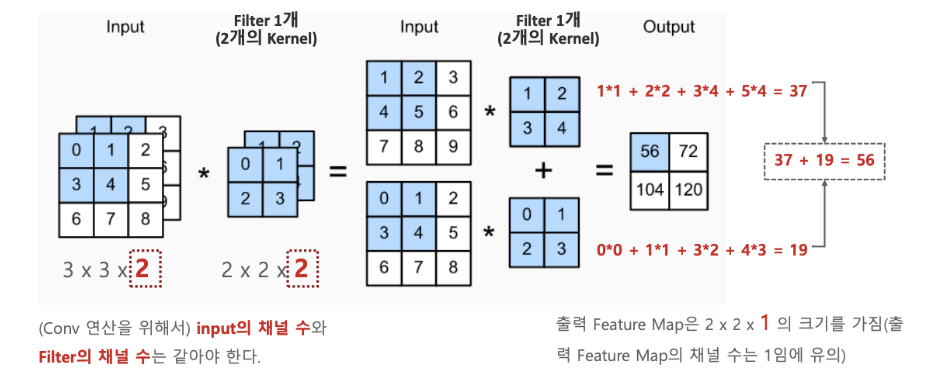
CNN에서 필터는 Input데이터의 채널의 개수만큼 있어야합니다. 만약 Input데이터가 28x28x3의 형태로 들어온다면 채널은 4x4x3의 사이즈를 가져야합니다.
이제 Input데이터가 어떻게 filter를 통과하는지 알아보겠습니다. 위에서 살펴본 Convolution의 정의를 살펴보겠습니다.
여기서 함수 f는 필터를 의미하고, 함수 g는 input데이터를 의미합니다.
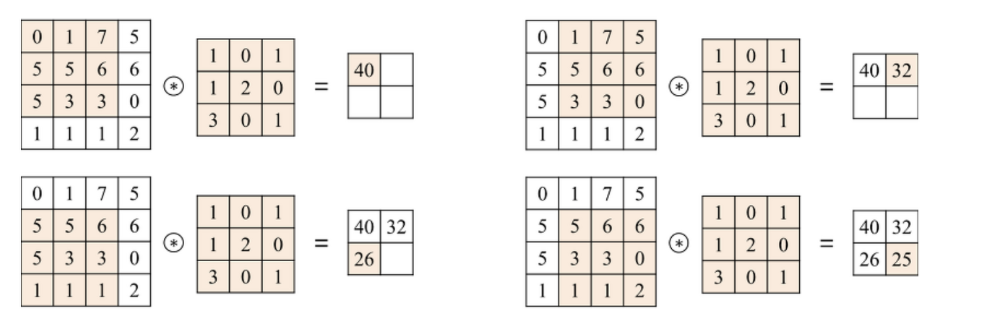
그림 왼쪽에 있는 행렬이 Input, 오른쪽에 있는 행렬이 filter를 의미하며 이 둘을 원소곱 한 뒤 다 더하는 방식으로 Convolution layer를 통과합니다. 즉 필터의 크기만큼 데이터를 읽고 하나의 스칼라가 통과한 행렬의 원소가 됩니다.
하지만 여기서 의아한 점이 있습니다. 원래 Convolution의 정의는 함수를 y축으로 반전하고 나서 두 결과값을 곱하여 더하는 것입니다. 하지만 실제로 Convolution layer에서는 대칭이동이 없습니다.
이는 CNN의 특징인 가중치 공유때문입니다. 가중치 공유란 하나의 커널이 뉴런의 볼륨을 stride하며 모든 커널이 동일한 가중치를 갖는다는 것을 의미합니다. 즉 filter에 존재하는 가중치는 Input데이터의 모든 값에 가중치로 사용됩니다. 이는 Input에서 들어온 정보를 계속 기억하게 하고, 중요하지 않은 정보는 기억하지 않게하기 위함입니다.
그래서 사실 CNN은 Convolution을 활용한다고 하기보단, Cross-correlation에 가깝습니다.
Cross-correlation =
이렇게 convolution layer를 통과하고 난 다음 활성화 함수 RELU를 지나 Pooling layer로 가게 됩니다. 이렇게 활성화 함수를 통과한 feature를 activation map이라고 합니다.
Pooling layer
이렇게 convolution layer를 통과하고 나면 Pooling layer를 통과하게 됩니다. Pooling layer란 이미지의 크기를 줄이고, 중요한 feature를 강조하는 부분입니다.
Pooling에는 총 3가지가 있습니다.
- Max Pooling
- Average Pooling
- Min Pooling
Max Pooling이란
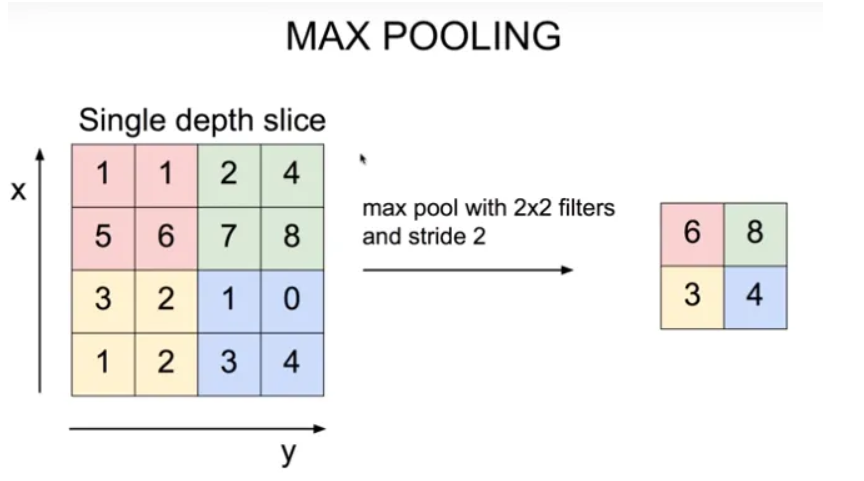
그림과 같이 activation map이 통과되고 난 뒤 선택된 영역에서 가장 큰 값을 해당 영역의 대표값으로 설정하는 것입니다.
Average Pooling은 해당 영역의 값의 평균을 대표값으로 사용하는 것이고, Min Pooling은 가장 작은 값을 대표값으로 사용하는 것입니다.
Pooling으로 이미지 크기를 줄이고, 중요한 정보만은 남겨, 학습속도를 올릴수 있습니다.
마무리
위와 같은 계층으로 여러 layer를 통과한 데이터는 이후 1차원으로 flatten되어 Fully connected로 이어지게 된 다음 각 task에 맞춰 활성화 함수를 지나게 됩니다.
정리하다 보니 몇가지 개념들이 빠졌는데 이후 NLP분야에서 CNN코드 정리할때 덧붙겠습니다.
