
1. 과정소개
1주차 : 데이터팀의 역할과 Redshift 소개 - SQL
2주차 : SQL for DataEngineer - SQL
3주차 : ETL/Airflow 소개 -Python, SQL
4주차 : Airflow Deepdive -Python, SQL
5주차 : Airflow Deepdive2 -Python, SQL
6주차 : Productionizing Airflow -Python, SQL
7주차 : 과정 정리 및 커리어 톡
부록 : Superset과 고급 Airflow 기능과 Redshift 설치방법
2. 요즘 커리어란?
- 커리어를 바라보는 관점
- 많이 듣는 질문들
- 요즘 무엇이 뜨는가
- 미래를 대비하려면 무엇을 준비해야하는가
- 커리어가 고착된 것 같은데, 무엇을 할지 모르겠다 (좋은 커리어를 쌓은 사람들)
- 👉 선행학습(불안감을 공부로 해소하려고함) , 불안감
- 전문성을 쌓는 것(깊게 파고드는 것)이 나의 커리어를 보장해준다고 생각하지 않음
- 변화를 두려워하지 않고, 지금 나에게 필요한것을 학습해서 할 수 있다는 자신감
- 이젠 커리어의 업다운이 심할 것.
- 내가 가진 것과 변화의 기회를 바꿔야함
- 작은 실패를 하면서 배워 후반부에 재밌게 살 수 있을 것
- 배움의 전형적인 패턴
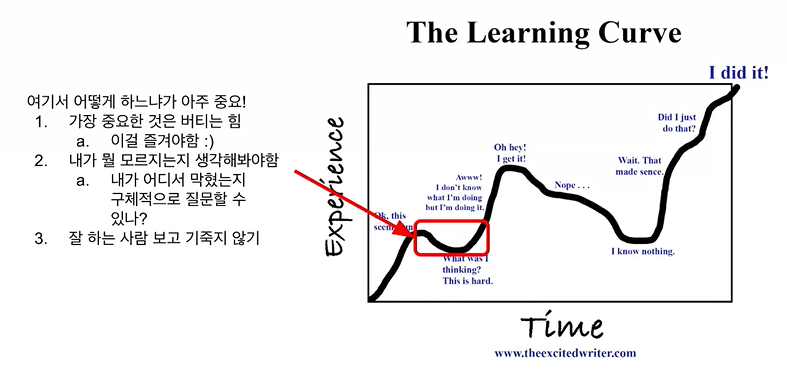
- 시간이 지나면서 배운다는 느낌이 있음. 그러다 배움의 정체기가 있는데, 그때 어떻게 지나가느냐가 중요함.
- 모든 배움에는 정체기가 있다. 이것을 나의 Fit의 문제로 생각하면 할 수 있는게 없다.
- 버티는 힘이 중요함. 그 과정 중 내가 모르는게 뭔지 아는게 중요함. 계속 질문!
- 빠르게 따라가는 사람 : 이미 일하고 있는 사람. 당연히 빠르고 처음하는 사람은 늦을 수 밖에 없다. 비교하지 말자.
- 이젠 Agile의 시대. 어디서 시작하는지 그렇게 중요하지 않다. 빨리 시작해서 일을 통해 배우고, 좋은 곳으로 이동하고. 취준하는데 너무 오랜 시간을 들이지 말자. 취업준비와 면접을 병행하는게 가장 좋다.
3. Goals of Data Organization
Data flow
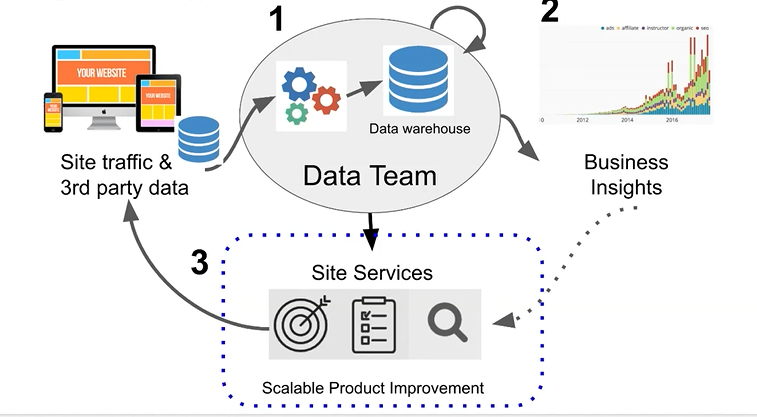
회원가입, 구매, 광고 등 사이트에서 data가 쌓임
- 1️⃣ 데이터 팀이 할 일
1) 내/외부 data를 수집해서 정재한 후 저장소(Data warehouse)에 적재함(= ETL, data pipeline) - 데이터 분석을 위한 DB
2) ETL의 수도 증가함에 따라 관리할 필요가 있음 (dependency가 잡히는데 10개가 넘으면 운영이 필요해짐 -> Airflow)
3) db로 Redshift, ETL은 Airflow 사용해볼 예정 -> 그 과정에서 SQL, Python이 기본기술로 사용됨.
=> DE가 하는 일은, DW구축, ETL작성해서 DW에 DA을 위한 내외부 정보를 읽어 적재하는 것(기본). - 2️⃣ 그 이후, DA가 투입되어 DW에 적재된 데이터를 조합해서 시각화, 인사이트를 도출 (= ELT)
- 3️⃣ DS가 투입되서 추천시스템이나 챗봇 같이 프로덕트를 고도화시킴. 앞의 1,2가 없으면 엉뚱한 일을 하게될수있음
- 성능 확인을 위한 A/B test 등을 통해 지표화 함
Vision of Data Organization(1)
- Build Leverage for the company through Trustworthy Data
- Leverage : data는 약간 서포트 조직에 가깝다. 본업은 아니지만 중요한 부가가치를 만든다.
- 데이터로 직접 매출 혹은 차별성이 만들어지는 것을 보여주는 것이 중요하다. 연결고리를 찾아서 객관화 시키고 사람들에게 설명시키는가가 중요
Vision of Data Organization(2)
-
Providing high quality data in timely fashion so that
-
data informed decisions VS data driven decisions
- data driven decisions : 데이터가 하라는 데로 결정
- data informed decisions : 데이터 참고 결정
- 어느쪽으로 가는 것이 우리 회사가 원하는 쪽이라는 것을 보여줌(데이터분석가)
-
data culture within your company is very critical
- 데이터를 통한 선택, 선택에 의한 결과를 어떤 데이터로 볼 것인지 등
-
-
데이터는 과거의 기록임. 항상 미래에 과거의 일이 반복되는 것이 아님(Ex. COVID19). 이럴때 data driven decisions은 의미가 없다 => 모든 경우에 data driven decisions 을 할 필요는 없다. 혁신, 창조의 경우엔 과거 데이터는 필요가 없다. -> 리더의 뚝심도 필요함
Vision of Data Organization(3)
- 고품질 데이터에서 패턴을 찾아 서비스 기능 개선(Garbage in Garbage out)
- ML을 통해 사용자의 서비스 경험 개선 (Ex. 추천, 검색기능)
- ML을 통해 운영비용 줄이기 (Ex. 공정과정에서 오동작 기기 예측)
4. Participants of Data Organization
-
Data Team
- Data Engineer
- Data Analyst
- Data Scientist
More, Analystics engineer : DE + DA, ML Engineer : DE + DS, MLOps, Privacy Engineer,...
-
Data Scientist (Product Science)
- 알고리즘을 통한 고객 경험 향상(모델 설계, 코딩능력)
- 석사 필
- Skill set : 딥러닝 지식, 파이썬, 스파크, SQL, Hive, R/SAS/Matlab,...
-
Data Analyst (Decision Science)
- 데이터를 시각화, 대쉬보드를 만들고 인사이트 도출
- 회사 도메인을 학습하고 내부의 문제에대한 결정을 냄
- Skill set : 파이썬, 스파크, SQL, Hive, R/SAS/Matlab,...
- 매일 질문에 답하다보면 재미가 없다아
- 속한 팀에 따라 커리어 패스가 혼란하게 됨
-
✨Data Engineer
- data warehouse( vs Data lake)
- Large scale의 DB 매니징 : Redshift(AWS), BigQuery(Google), Snowflake(Azure)
- Data pipeline 구축, 관리 (ETL)
- 3rd party SaaS ETL : FiveTran, StitchData, Segment
- Cloud is the choice (AWS를 많이 쓰지만, Google Cloud in particular)
- Data tools
- 기본지식은 Python, SQL 이 필수
- API, Web service 만들기도함
- data warehouse( vs Data lake)
5. Various forms of Data Organization Structure
- 한팀으로 묶여 있고, 다른 팀에서 요청을 하는 것이 가장 이상적이지만,,,, 쪼개서 각 현업팀으로 분산됨
- DE만 남고 DA, DS가 떨어지는 경우가 많음...
- 하이브리드된 형태가 제일 좋음
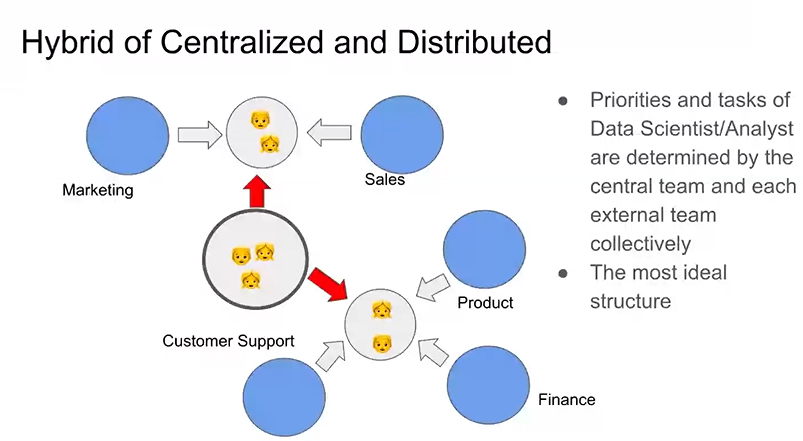
- 면접시 "데이터 팀의 조직 구조가 어떻게 되는가?" 확인하면 좋음
6. Case study
- Setting up Marketing Attribution Pipeline at tulip
- 마케팅을 pipeline으로 Data driven 하게 하면 바로 결과가 나온다. 어디에 마케팅 ad를 올리면 어떤 결과가 나오는지...
- 많은 경우 스타트업에서 하는 일들
- How to Detect Fraud Payments at Udemy?

- 훔친 credit card로 결제하는지 미리 확인. customer 팀으로 오니까 관련 프로세스를 확인하고 훈련데이터를 쌓아서 미리 예측하게 함
- Personalizing Weight Alerts at a Helth Startup

- 50% 정도의 정확도만 되도 됨. 아플 것 같은 사람에게 서비스를 제공하고 예방하는 것에 집중하도록 서비스를 만듬
- Personalizing Recommendation at Udemy
- 어떤 것을 추천해주고, 어떤 변화가 일어나는지 확인
- 사람의 필요성이 달라지고 data패턴이 변하니까 계속 모델을 유지보수해줘야함. 이걸 자동화하는게 MLOps
7. Lessons Learned
- Data가 비지니스 결과를 이끈다(데이터와 매출의 연결고리를 만들어야함)
- 데이터와 관련된 비용이 높다
- 만약 비지니스
- 인프라가 먼저 만들어져야한다. 작게 시작해서 필요할 때 키우면 됨. 분석과 데엔은 동시에 할 수 있는 사람을 뽑을 수 있으면 초기 스타트업에 가장 좋음
- 데이터 품질이 중요하다. (어떻게 확인할까)
- 지표가 먼저다. (일이 갖는 가치가 무엇이고, 어떻게 수치화 할 수 있을까? 어떤 지표가 개선되고 어떻게 시각화될까)
- 간단한 솔루션이 가장 좋은 솔루션이다. iteration 몇바퀴 돈다는 생각으로, 가장 쉽게 한번, 이후 고도화해서 한번 더,,, keep iteration in mind!
느낀점
- 역시 중요한건 꺾이지 않는 마음! 근 9개월간 프로그래밍을 하며 제일 많이 느낀게 '나는 왜 이렇게 못할까...'하는 것이었다. 항상 나보다 잘하는 사람들(중고신입)을 보며 스스로를 채찍질하곤 했는데, 처음하면 버벅이는게 당연한걸!! (물론 하면서 그 사람들한테 이만큼 빼먹어야지~~ 하는 마음으로 열심히하는 긍정효과도 있었지만ㅋㅋ) 이젠 나의 과거를 보며 나에게 더 집중해야겠다.
- 또한 여러 실습을 진행하면서 내가 지금 모르는게 뭐고 어떤 부분에서 계속 막히는지를 파악하며 빠르게 뚫고 나가야겠다
- 그리고 취업준비가 길어지면서 좀 더 공부하고, 좀 더 채우고 지원하자,, 하면서 머뭇거렸는데,, 적어도 1월달엔 정리해서 2월부턴 계속 지원을 해야겠다 생각이 든다. 역시 성장하는건 일을 통해 배우는게 제일 크니까!!!
- 내용도 그동안 '빅데이터를 지탱하는 기술', 강의들, 블로그들을 보며 대략적으로 알고 있던 부분들이 쭉 정리되어 앞으로가 기대된다
- 가보자고!!!!!!!!!!!!!

차보의 Data Engineer 도전기♥ (근데 기록을 곁들인)