
들어가기 전,
-
전동 스쿠터 사용자들은 왜 2-3달 후 이탈할까? 자주 사용하는 사람은 스쿠터를 구매해버림
-
돈을 사용하는 사람이 어떤 사람이고, 어떤 특성을 갖고 있는가, 재방문/이탈 하는가? 이런 것에대한 호기심을 갖고 있는 것이 중요함
-
Troubleshooting calls and churn
- 서비스 관련 불만을 말하는 사람의 이탈률은 어떨까?
오히려 더 길게감. - 하지만 불만을 말하는 사람의 말만 더 들으면 안됨. (Survivor Bais & Confirmation Bias)
- 서비스 관련 불만을 말하는 사람의 이탈률은 어떨까?
-
우리가 데이터를 보는 편견이 있을 수 있다. 여러 각도로 봐야함
1. What is Data Engineering?
- Different Roles
- 데이터 웨어하우스 관리
- 파이프라인 작성
(Data Pipeline == ETL == Data Job == DAG_in airflow) - 파이프라인의 타입
- batch process(airflow) vs realtime process(spark, kafka, kinesis)
- data Generation의 summary (DBT - Analytics Engineer)
- 유저 행동데이터를 모음
- Skillset
- SQL : Hive, Presto, SparkSQL
- Python, Scala, Java
- ETL/ELT : Airflow
- large scale computing platform : Spark/YARN
- cloud Computong
- container Technology : K8S, Docker
- knowledge : ML, A/B test, Statistics
2. Data warehouse Deep Dive
-
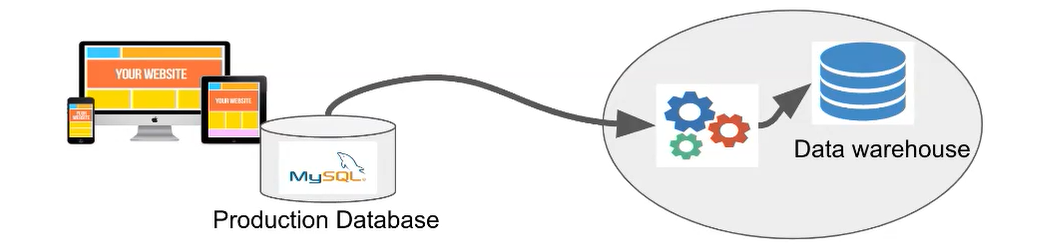
Data warehouse = a separate SQL DB
- 아직까지 SQL이 데이터를 다루기 가장 좋은 언어임(스키마 디자인 능력이 중요)
- 따라서 상황에 맞는 가장 좋은 옵션을 찾아야함
- Production database는 DW에 들어가지 않음
- 어떤 행동을 하면 Production DB에 넣거나 뱉음. -> 속도가 빨라야함 처리속도 중요!(-> 벡엔드가 관리)
- DW는 내부 직원이 사용하니 처리 속도가 중요하지 않음. 처리 양이 더 중요함.
- Production DB 는 OLAP(OnLine Analystical Processign, vs OLTP(OnLine Transaction Processing)
-
중앙 데이터 스토리지!
- 1) 다른 소스에서 온 raw data들을 모은 DB(ETL)
- 2) raw data를 서머리한 DB (ELT)
- Fixed Cost options VS Variable Cost Option
- 고정비용 : 매달 내는 것 (Redshift, on-premise DW)
- 가변비용 : 사용하는 만큼 지불 (BigQuery, Snowflake) -> 처리할 수 있는 용량이 훨씬 큼, 비용 예측이 어려움 책임이 따른다...
3. Redshift Introduction
-
Scalable SQL Engine(DW) in AWS
- up to 2TB of data in cluster of servers
- still OLAP
: 데이터 처리속도 빠르지 않고 크기에 신경을 쓴 것 - columnar storage
: 저장할 때 컬럼으로 나눠 저장함 -> scalable은 대부분 columnale - support Bulk-update
: data file을 던져 적재함으로 빠르게 적재할 수 있음 - Fixed Capacity SQL engine
- Dosen't guatantee primaty key uniqueness!
: SQL의 PK를 지정해서 유니크한 값을 넣게 되는데, DW는 아무리 특정키를 PK로 지정해도 그게 유니크한지 보장하지 않음 -> DE, DA의 책임이다..!!!
(Redshift, BigQuery, Snowflake, SPARK 포함. 보장하는 순간 DW의 속도가 확 느려진다) - PostfresQL 8.x ver 과 호환

- Supported Data Type in RedShift

- RedShift Options and Pricing
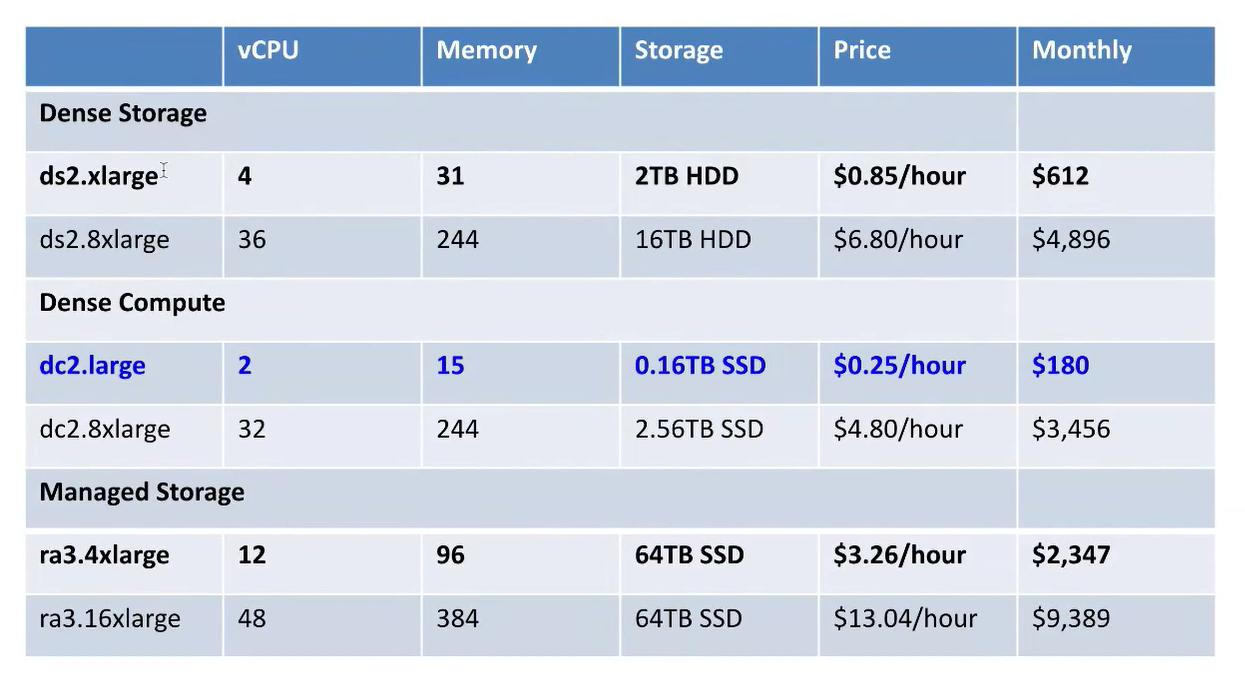
블라인드도 이정도면 사용 가능
사용하다 모자라면 계속 추가할 수 있음
-
Optimization can be tricky
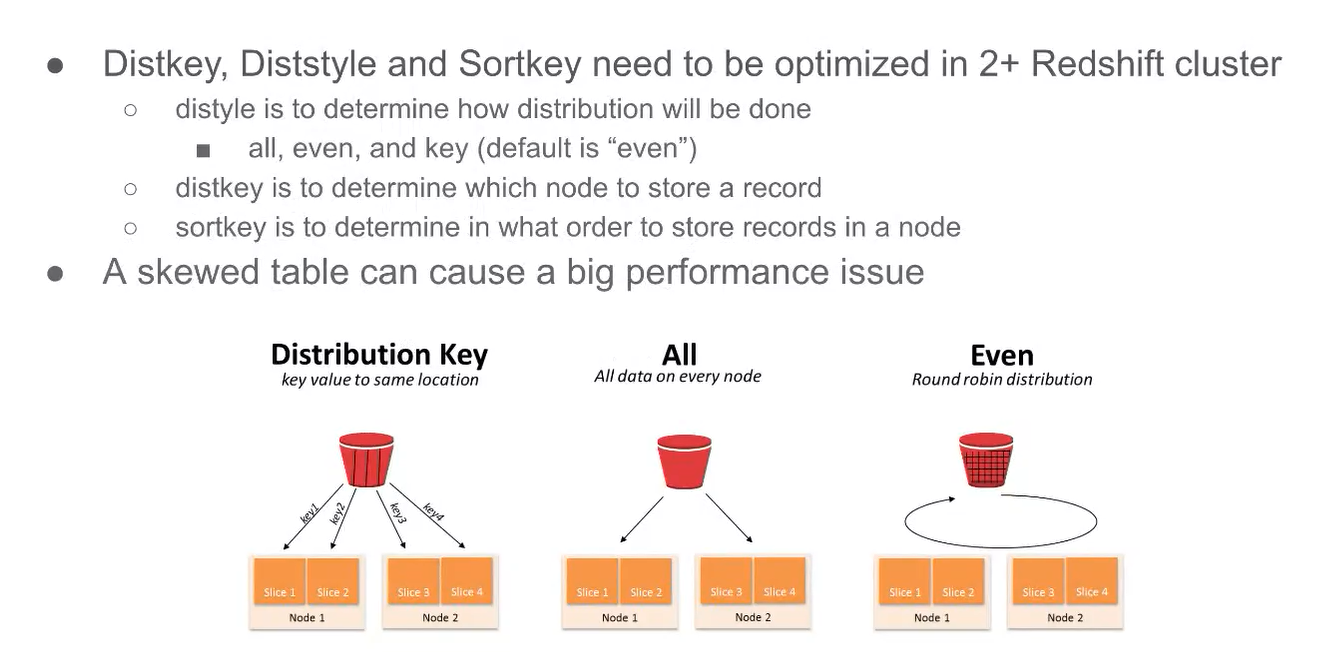
데이터들이 노드에 저장될 때 레포가 균등하게 안가고 한 노드에 많은 양의 데이터가 저장될 수 있음.
JOIN 할 때 한 노드에 로드가 많이 감으로(이게 병목현상인가?) 분산 처리가 안되고 속도가 느려지는 경우가 있음. -
이게 치명적인 단점임. 어떤 스케일을 넘어가면 빅쿼리, 스노우플레이크가 더 좋은 옵션이 될 수 있음
-
AWS 서비스와 연동이 편함
-
How to Extend RedShift Functionality?
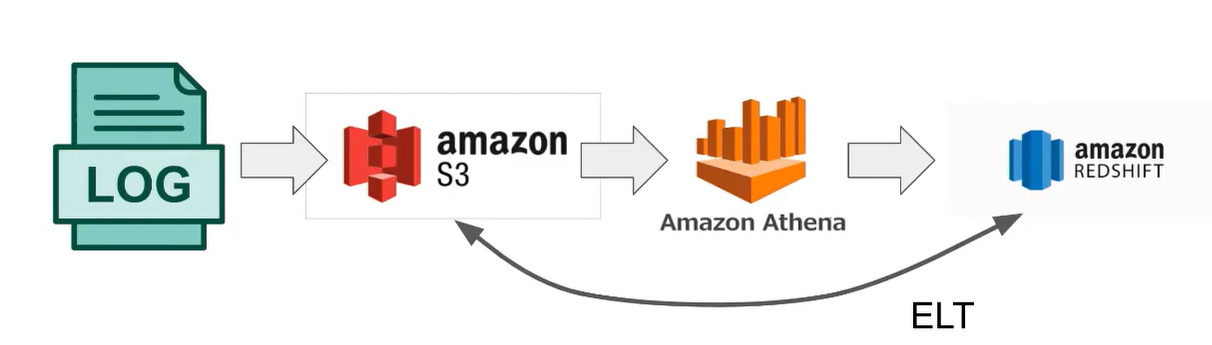
- Python based UDF(User Defined Function) support
- Caching 지원
- Athena(오픈소스 프레스토를 서비스화한 것)
: redshift는 정재된 데이터를 저장하는 건데, log file은 크기도 크고 정보도 비구조 semi structure이라 athena를 써서 비구조를 요약해서 내가 필요한 부분만 뽑아서 redshift에 저장한다.
-
Bulk update Sequence - Copy SQL
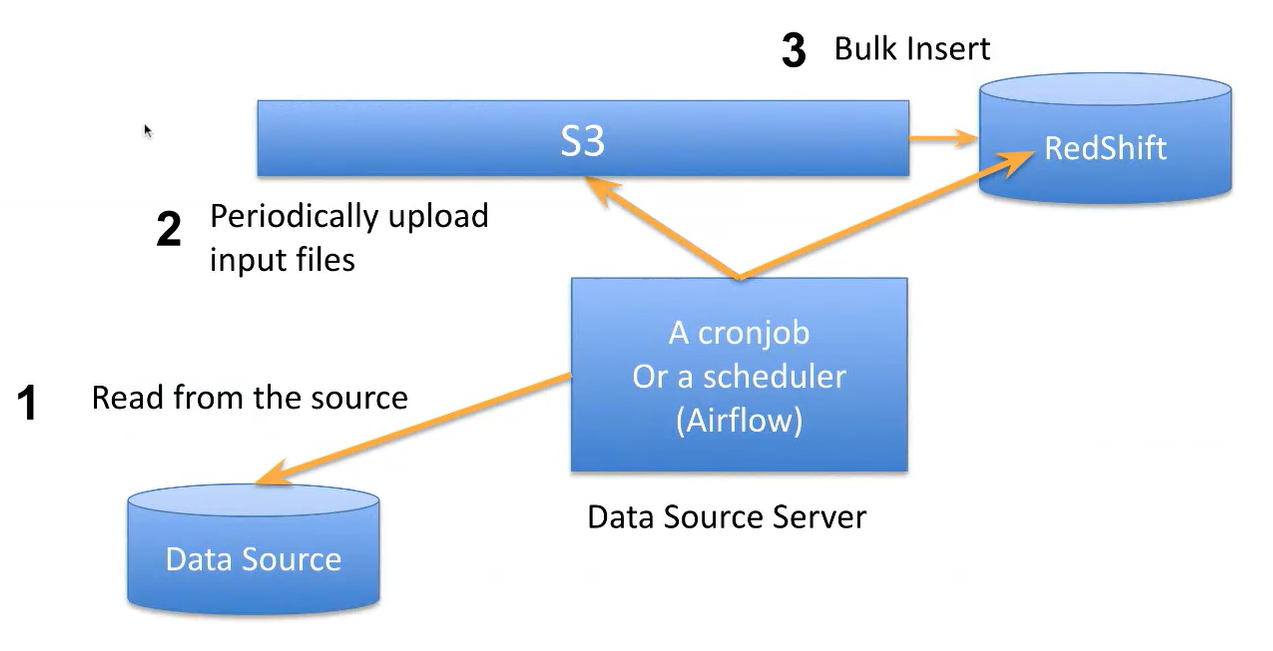
- insert into 로 해서 데이터를 적재하는데, 1개씩하다보면 시간이 다간다~
- source에서 하나의 파일로 만든다음 S3에 저장하고, 그걸 COPY SQL을 통해 RedShift 에 한번에 넣음
- 이렇게 가다보니 PK 체크를 할 수가 없다. 속도 저하의 원인
4. How to Access Redshift
5. Data Management Best Practices
6. Launch Redshift Cluster
7. Lab Sesstion and Assignment
느낀점
- 요즘 BigQuery를 사용하는 회사들이 늘어나는 추세인 것 같아 관심이 많았다. 처리 용량이 큰 건 분명 매력적인 사항이지만, 사용하는 만큼 비용을 낸다는게 아직 입문자의 입장에서는 부담스럽게 느껴진다.
- 또한 Udemy같은 회사도 4~5000억 할 때까지 Redshift를 사용했다고 하니 우선은 Redshift를 사용하며 쿼리날리는 것에 익숙해지고 나중에 BigQuery로 넘어가는것이 좋을 것 같다.

차보의 Data Engineer 도전기♥ (근데 기록을 곁들인)