
시편별 데이터를 추출해서 분포를 분석해야 하는 업무가 들어왔다!
내 목표는
| 시편1 | 시편2 | ... | 시편300 |
|---|---|---|---|
| 데이터1 | 데이터2 | ... | 데이터300 |
| 데이터1 | 데이터2 | ... | 데이터300 |
| 데이터1 | 데이터2 | ... | 데이터300 |
이런식으로 Dataframe을 만들어서 마지막에 df.describe()로 깔쌈하게 만들어보는것이다!
하지만 언제나 현실은 녹록치 않지...
제일 큰 문제는 시편에 들어있는 data의 갯수가 다르다는 것....ㅎㅎ.....
진행 순서
-
먼저 시편을 col으로 빼기 위해서 dictionary형태를 선택했다.
col을 list화해서 마지막에dataframe(list, column = columns)로 할 수도 있겠지만, 200여개가 되고, 2중 list로 넣기엔 시간이 오래걸릴 것 같아서 Dict로 진행했다.- 형태는 {"시편1" : [데이터1-1, 데이터1-2,...], "시편2" : [데이터2-1, 데이터2-2, ...], ...}가 된다.
{'100': [1339, 1351, 1367, 1201, 1337, 1318, 1361, 1353, 1316, 1387, 1373, 1364, 1382, 1364, 1310, 1422, 1375, 1227, 956, 1322, 956, 1399, 956, 1302, 1312, ... 1173, 1162, 1139, 990, 1268]}
- 형태는 {"시편1" : [데이터1-1, 데이터1-2,...], "시편2" : [데이터2-1, 데이터2-2, ...], ...}가 된다.
-
그리고 이제 dataframe으로 하면 되겠다! 싶었는데..!
temperature_df = pd.DataFrame(temp_dict)
temperature_df
>>> ValueError: All arrays must be of the same lengthdict의 value값의 길이가 동일해야 한다는 오류가 발생한다..(null값으로라도 채워줘...😞)
좀더 Error를 자세히 봐보자!

시리즈가 아닌 것이 들어간 dict를 섞으면 순서가 모호해질수도 있다는데,,, 흠,,,
- 이것저것 찾아본 결과 누락된 행때문에 발생한다는데, value에 있는 list값을 하나하나 dataframe에 넣으면서 시리즈가 아닌 데이터1과 df 이 충돌하는게 아닌가 하는 생각이 든다.
그리고 딱 생각해도 쭉쭉 df을 만들면서 넘어가는데, 이전 col으로 다시 돌아가서 null값을 넣는다는 개념도 이상하다...
🤔그래서 어떻게 해결했는데!?
-
Dataframe class를 보다가 from_dict를 발견해서 요걸로 요리조리 못할까~ 생각이 들어 검색을 진행하고
-
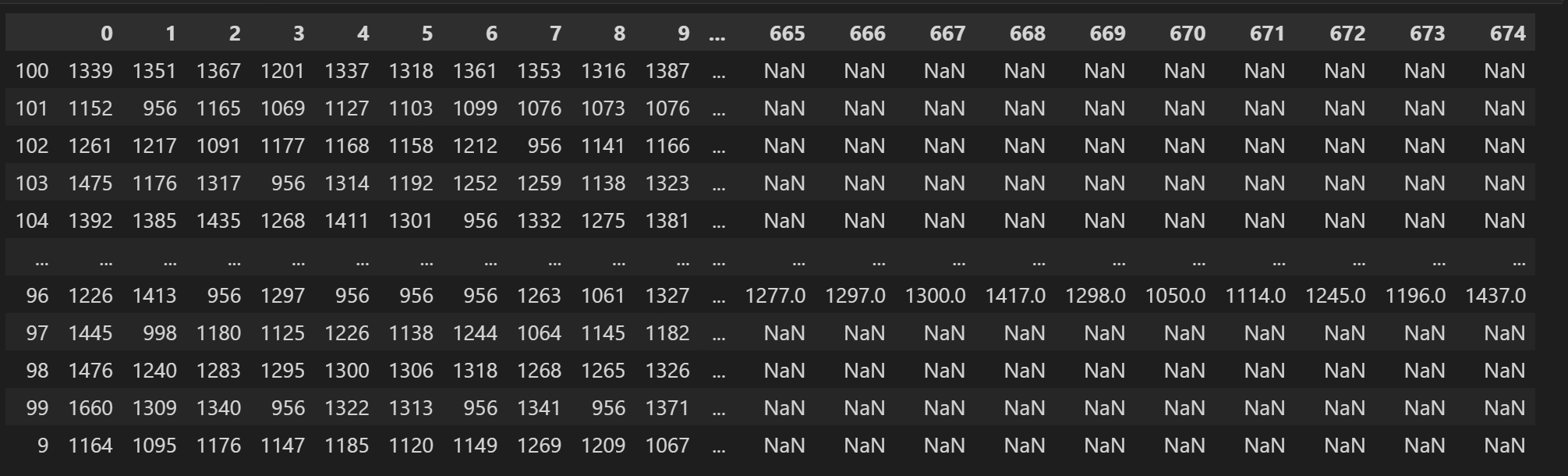
우선 만들어서 뒤집더라도 Dataframe으로 만들자! 가 되어서
temperature_df = pd.DataFrame.from_dict(temp_dict, orient='index')으로 만들어주면 이렇게 row와 col이 반대긴 하지만 row갯수가 맞지 않아 error를 발생시키진 않는다.
-
그럼 이제 이걸 반대로 뒤집어주면!?
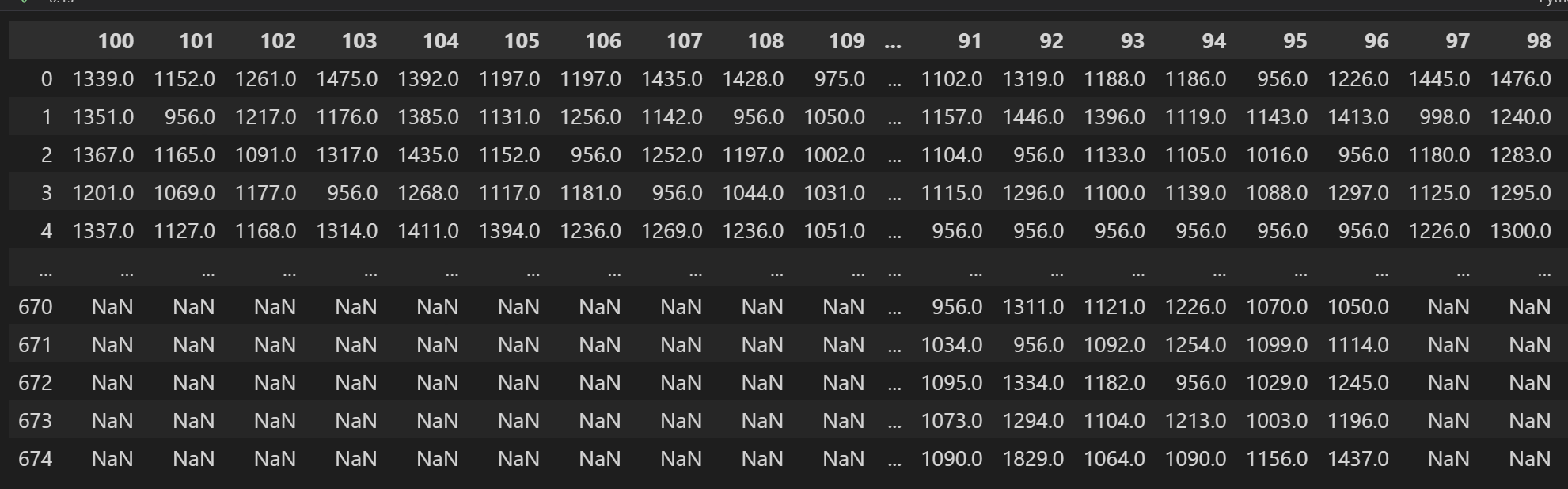
이렇게 원하는 형식으로 나오게 된다!
룰루!!!!!!!!!!! -
이상태에서 describe를 처리해주면
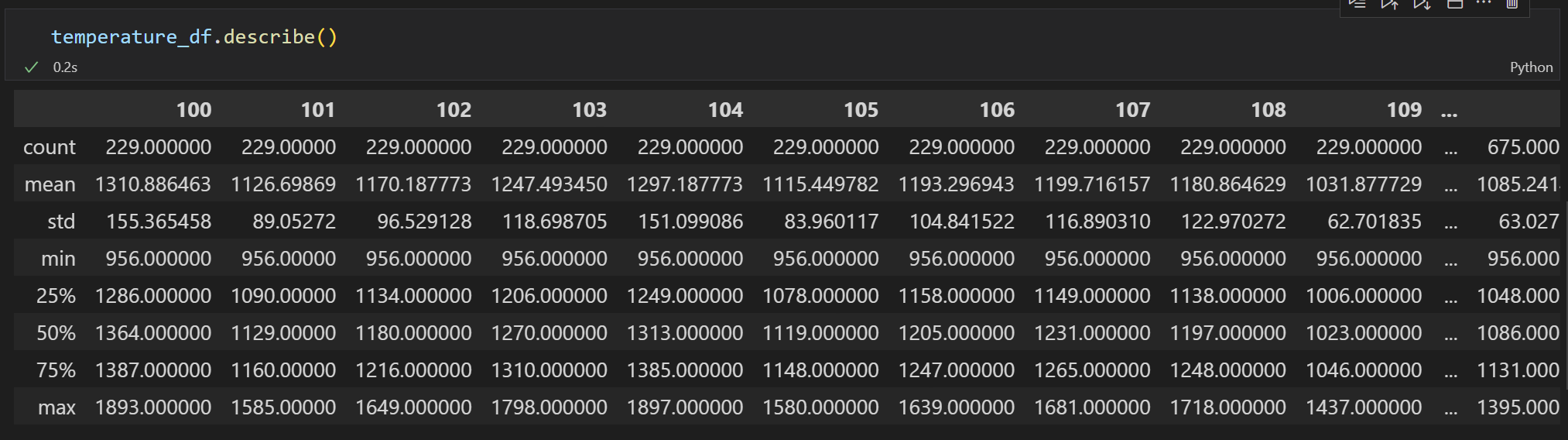
이렇게 시편당 데이터를 뽑아볼 수 있게 출력이 된다....(편-안)
Code 정리!
# 데이터 담을 dictionary 생성
temp_dict = {}
fail_list = []
for idx, sus_item in enumerate(sus_list):
item_temp_list = []
tem_dir = os.path.join(path, sus_item,'melt_temperature') # temp dir 생성
# temperature folder 없는 것 있음
try:
tem_files = os.listdir(tem_dir) # 한 폴더(시편) file list 생성
# json 파일 하나씩 열기
for tem_file in tem_files:
tem_file = os.path.join(tem_dir, tem_file)
with open(tem_file, 'r', encoding= 'utf-8-sig') as f:
json_data = json.load(f)
item_temp_list.append(int(json_data['max_temperature']))
temp_dict[sus_item.split('_')[0]] = item_temp_list
print(f'{sus_item} 시편 => 완료 ')
except Exception as e:
fail_list.append(sus_item)
print(f'{sus_item} 시편 => {e}\nmax_temperature folder 없음')
pass
print(f'dictionary 변환 안됨 ==> {fail_list}')
temperature_df = pd.DataFrame.from_dict(temp_dict, orient='index')
temperature_df = temperature_df.transpose()
temperature_df하면 완성!
이번 외에도 종종 사용하는데, 속도가 어떻게하면 빨라질지 또 생각해봐야할 것 같다!
참고 블로그
