
ElasticSearch란?
Elasticsearch는 텍스트, 숫자, 위치 기반 정보, 정형 및 비정형 데이터 등 모든 유형의 데이터를 위한 무료 검색 및 분석 엔진으로 분산형과 개방형을 특징으로 합니다.
Elasticsearch는 Apache Lucene을 기반으로 구축되었으며, Elasticsearch N.V.(현재 명칭 Elastic)가 2010년에 최초로 출시했습니다.
간단한 REST API, 분산형 특징, 속도, 확장성으로 유명한 Elasticsearch는 데이터 수집, 보강, 저장, 분석, 시각화를 위한 무료 개방형 도구 모음인 Elastic Stack의 핵심 구성 요소입니다.
보통 ELK Stack(Elasticsearch, Logstash, Kibana의 머리글자)이라고 하는 Elastic Stack에는 이제 데이터를 Elasticsearch로 전송하기 위한 경량의 다양한 데이터 수집 에이전트인 Beats가 포함되어 있습니다.
- Elasticsearch 공식 페이지
설치
- 기본적으로 Linux기반에서 돌아가기때문에 가상환경을 통한 Ubuntu에서 진행했다.
Ubuntu에 설치하기
-
Elastic Public GPG 키 추가하기
$ curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - -
sources.list.d 폴더에 Elastic 소스리스트를 추가
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list -
apt update & install
sudo apt-get update && sudo apt-get install elasticsearch
or
sudo apt update👉sudo apt install elasticsearch
- 안되면 참고 블로그 : 설치 관련
Local에서 돌리기 위해 elasticsearch.yml 수정하기
-
elasticsearch.yml 파일 열기
sudo vi /etc/elasticsearch/elasticsearch.yml -
i버튼 눌러서 파일 수정하기
- #node.name: node-1의 #을 지워 활성화
- #network.host: 192.168.0.1 의 #을 지워 활성화 시킨 뒤 0.0.0.0으로 변경 (모든 host 선택)
- #discovery.seed_hosts: ["host1", "host2"]의 # 지우고 ["127.0.0.1"]로 수정
- #cluster.initail_master_nodes: ["node-1", "node-2"]의 # 지우고 node-1만 남김 (하나만 쓰니까)
- 수정이 끝났으니 esc키 눌러 insert 모드를 변경하고
:wq눌러 파일을 저장하고 나감
elasticsearch 자동 실행 저장, 작동 확인
-
sudo /bin/systemctl daemon-reload입력 (오류시 블로그 글 참고) -
sudo /bin/systemctl enable elasticsearch.service -
sudo /bin/systemctl start elasticsearch.service
이렇게 하면 앞으로 가상환경을 작동할 때마다 elasticsearch가 자동으로 실행됨 -
curl -XGET 127.0.0.1:9200을 입력해서 잘 작동하고 있는지 확인한다.
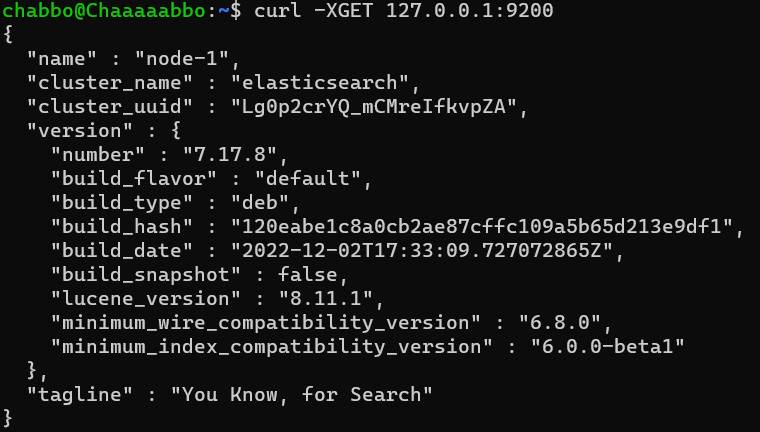
상기 화면이 뜨면 설치, 작동확인은 끝났다!
You know, for Search!
셰익스피어 전집으로 TEST
셰익스피어의 전집을 다운로드
- 어떤 식으로 넣을 건지 알려주는 mapping 파일을 다운받는다
wget http://media.sundog-soft.com/es7/shakes-mapping.json
- mapping file 내용
{
"mappings" : {
"properties" : {
"speaker" : {"type": "keyword" },
"play_name" : {"type": "keyword" },
"line_id" : { "type" : "integer" },
"speech_number" : { "type" : "integer" }
}
}
}
-
다운받은 mapping 파일을 elasticsearch에 넣어주기
curl -H "Content-Type: application/json" -XPUT 127.0.0.1:9200/shakespeare --data-binary @shakes-mapping.json -
셰익스피어 전집 다운로드
wget http://media.sundog-soft.com/es7/shakespeare_7.0.json -
다운받은 json 파일 elasticsearch에 넣어주기
curl -H "Content-Type: application/json" -XPOST '127.0.0.1:9200/shakespeare/_bulk' --data-binary @shakespeare_7.0.json
- 처리하는데 시간이 조금 걸린다. 이때 뒤에 누가 보면 매트릭스같은 멋진 모습을 보여줄 수 있다^_^
- 파일에서 문장 내용을 검색해보자.
json 요청을 넣어 검색 쿼리를 실행하자
### 쿼리검색 요청
curl -H "Content-Type: application/json" -XGET '127.0.0.1:9200/shakespeare/_search?pretty' -d '
{# 여기서부터 검색내용
"query" : {
"match_phrase" : {
"text_entry" : "to be or not to be"
}
}
}
'이렇게 넣어주면 아래와 같은 결과를 받아 볼 수 있다.
햄릿이 하는 대화임을 알 수 있죵!
{
"took" : 2424,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 13.889601,
"hits" : [
{
"_index" : "shakespeare",
"_type" : "_doc",
"_id" : "34229",
"_score" : 13.889601,
"_source" : {
"type" : "line",
"line_id" : 34230,
"play_name" : "Hamlet",
"speech_number" : 19,
"line_number" : "3.1.64",
"speaker" : "HAMLET",
"text_entry" : "To be, or not to be: that is the question:"
}
}
]
}
}이렇게 elasticsearch를 실행해보고 test를 진행해 봤다.
살짝 어떤 식으로 진행되는지 감은 잡았는데, 내 데이터를 가지고 어떤 식으로 mapping해야하는지는 더 강의를 보며 테스트해봐야할 것 같다.
