
카프카 중요요소 살펴보기
- Broker, Replication, ISR
- Replication(복제)
: 카프카 아키텍쳐의 핵심!
: 클러스터에서 서버의 장애가 생겼을 때, 가용성을 보장하는 가장 좋은 방법이 복제이기 때문!
Broker
- 카프카가 설치되어 있는 서버의 단위
- 보통 3개 이상의 Broker로 설정해서 사용하는 것을 권장!
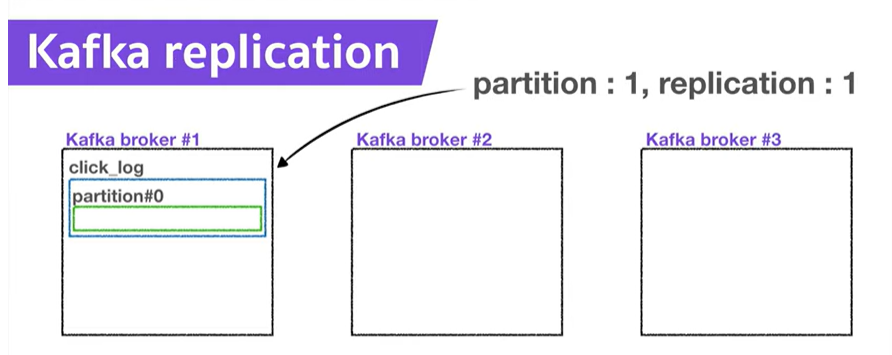
- Ex) 파티션이 1개이고, Replication이 1인 Topic이 존재하고 브로커가 3대라면, 브로커 3대중 1대에 해당 토픽의 정보(데이터)가 저장된다
Replication
- 파티션의 복제를 의미함!
- 만약 Replication이 1개하면, 파티션이 1개만 존재한다는 것
- 만약 Replication이 2개라면, 원본 1개 + Replication 1개. 총 2개가 존재함
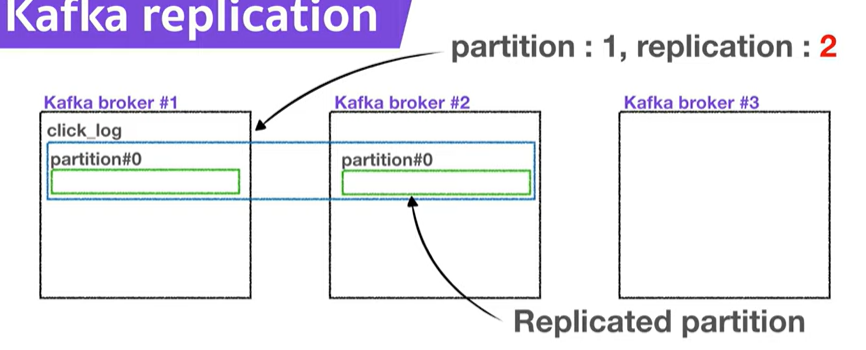
- 만약 Replication이 3개라면, 원본 1 + 복재 2 => 3개가 됨
다만 Broker의 갯수에 따라 Replication의 갯수가 제한됨
Broker가 3이면, Replication이 4개가 될 수 없다! (기본 통이 제한되어 있으니까) - 원본 1개의 파티션은 Leader partition, 나머지 Replication은 Follower partition이라고 함
ISR(In Sync Replica)
- Leader partition, Follower partition을 합쳐서 ISR이라고함
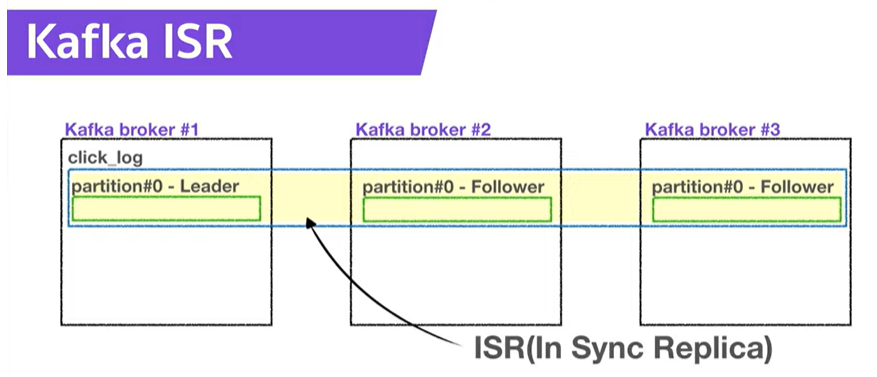
- 왜 Replication을 사용할까?
: 파티션의 고가용성을 위함. 만약 브로커가 3개고, 파티션1, Replication 1인 토픽이 존재한다면, 브로커가 사용불가하게되면 파티션 복구 불가됨.
-> Replication이 있으면 Follower Partition이 있어 복구 가능함
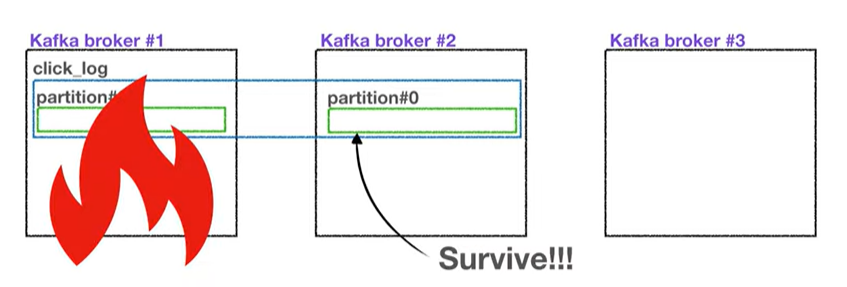
이때 남은 Follwer Partition이 leader partition이 됨
Leader partition, Follower partition의 역할 차이는?
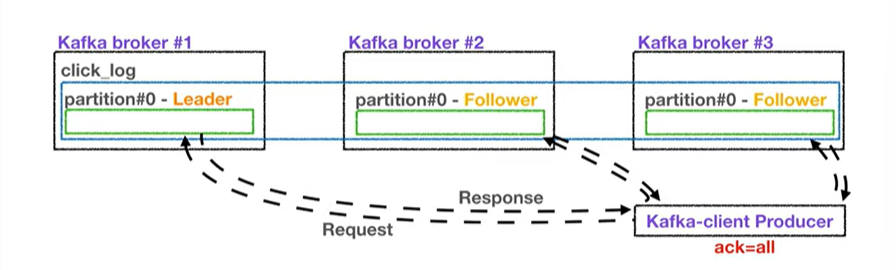
- 프로듀서가 토픽의 파티션에 데이터를 전달한다. 그때 전달받는 주체가 Leader partition임.
- 프로듀서에는 ack라는 상세 옵션이 있음 이를 통해 고가용성을 유지할 수 있음. 이게 파티션의 Replication과 연관이 있음
- ack는 0, 1, all 중 1개를 선택할 수 있음
1. ack = 0
- 프로듀서는 리더 파티션에 데이터를 넣지만, 응답값을 받지 않음 -> 정상적으로 전달 됐는지, 다른 파티션에 저장이 잘 됐는지 알 수 없음
속도는 빠르지만 데이터 유실 가능성이 잇음
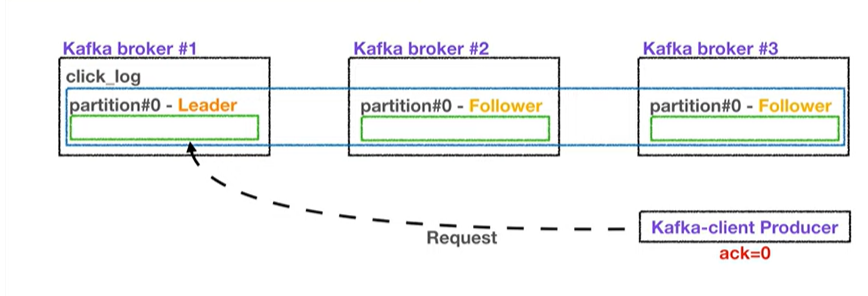
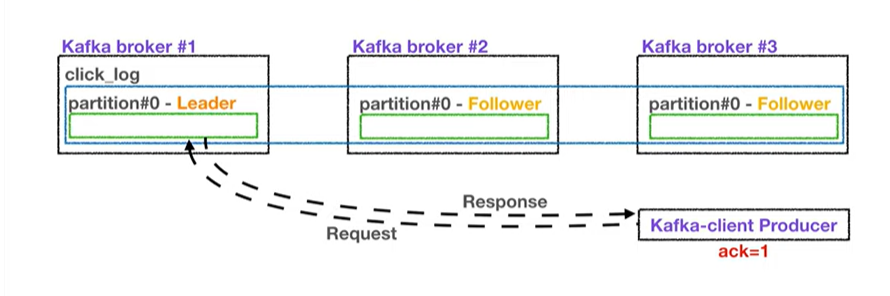
2. ack =1
- 리더 파티션에 넣고 응답값을 받아 잘 전달 됐는지는 확인 가능.
하지만 나머지 파티션에 복제되었는지는 알 수 없음.
리더에서 받고 브로커에 장애가 생기면 나머지 파티션에 전송되지 않아 데이터 유실 가능성 있음
3. ack = all
- 리더의 응답값 + 각 파티션에 저장이 됐는지 응답값을 받아 확인하는 절차를 거침. -> 데이터 유실은 막을 수 있음
- 하지만 확인하는 부분이 많아 속도가 현저히 느림
Replication Count
- Replication이 고가용성의 중요한 역할이면 많을 수록 좋은거 아닌가?
: 그만큼 브로커의 리소스 사용량도 증가함. -> 데이터량과 저장시간을 잘 생각해서 갯수를 정해야함.
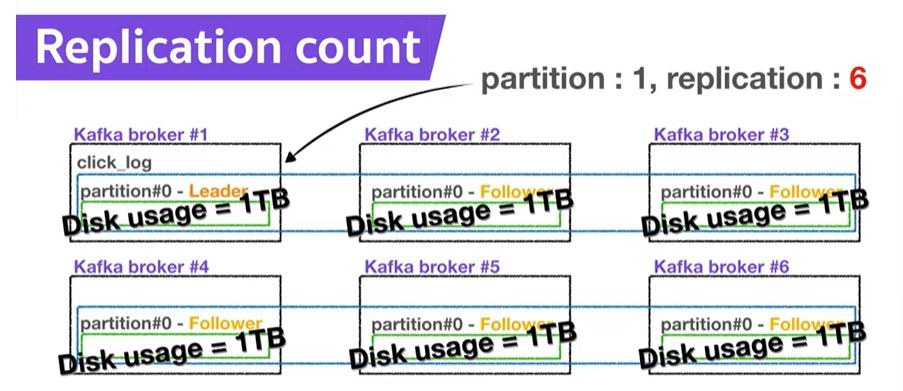
- 3개 이상의 브로커를 쓸 때, Replication을 3으로 설정하는 것을 추천!
서버의 이슈는 생각보다 자주 발생한다.
데이터 유실을 막기 위해 오늘의 핵심 요소가 중요함.
이렇게 고가용성을 잘 지원할 수 있기에 데이터 파이프라인에서 카프카가 더 중요해지고 있는 것 같음.

차보의 Data Engineer 도전기♥ (근데 기록을 곁들인)