
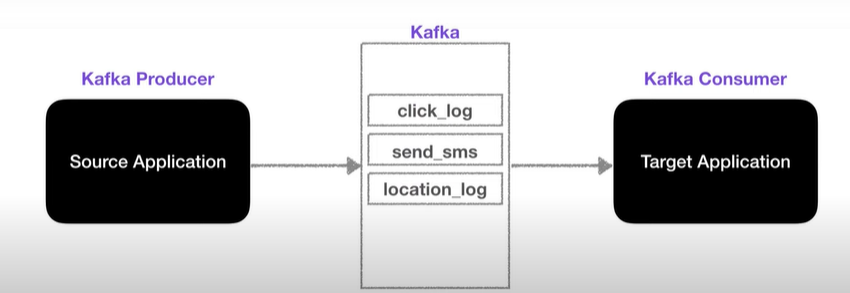
데이터가 들어가는 공간 = 토픽
일반적인 AMQP와는 다르게 동작함
카프카 토픽
-
여러개 생성 가능

-
DB의 테이블, 파일시스템의 폴더와 유사함
-
프로듀서가 data를 넣고, 컨슈머가 data를 가져감
-
목적에 따라 click_log, send_sms, 등 어떤 데이터인지 명확하게 기술하면 유지보수가 쉬워짐
카프카 토픽 내부
파티션 1개
- 하나의 토픽은 여러개의 파티션으로 구성될 수 있음
- 파티션은 0부터 시작. 데이터는 큐와같이 끝부터 쌓임.
- 컨슈머는 끝부터 가져감 (=Queue). 이때 가져가더라도 데이터는 삭제되지 않고 파티션에 그대로 남음

-> 새로운 컨슈머가 왔을 때 0부터 가져 갈 수 있음(다른 컨슈머 그룹, auto.offset.reset=earliest로 설정되어있어야함)

- 동일 데이터를 2번 처리 가능 -> 카프카 사용하는 중요 이유!
-> ex. 클릭로그 분석을 위해 elastic search, 저장을 위해 Hadoop에 각각 저장할 수 있음
파티션이 2개 이상
- 파티션에 보낼때 key값을 지정할 수 있음
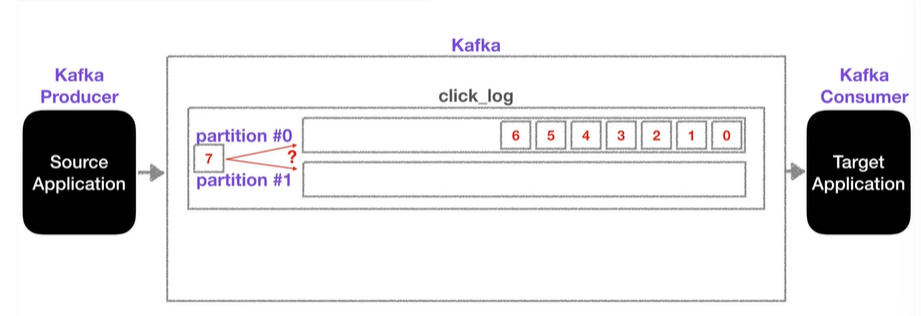
- Key가 Null이고, 기본 파티셔너로 사용할 경우
-> 라운드 로빈(Round Robin)으로 할당
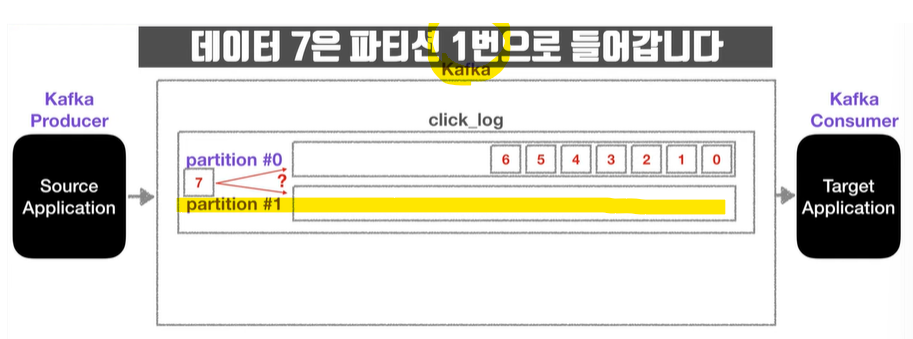

- key가 있고, 기본 파티셔너 사용할 경우
-> Key의 해쉬(hash)값을 구하고, 특정 파티션에 할당
파티션을 늘리는 경우
- 조심해야함. 파티션은 늘릴 수 있지만 줄일 수는 없기때문!
- 근데 왜 늘릴까?
파티션을 늘리면 컨슈머갯수를 늘려 데이터 처리를 분산시킬 수 있다. - 파티션의 데이터는 언제 삭제될까?
옵션으로 조절가능- log.retention.ms : 최대 보존시간,
- log.retention.byte : 최대 보존 크기 (Byte)

차보의 Data Engineer 도전기♥ (근데 기록을 곁들인)