실제 어플리케이션을 AWS 환경(t3a.small)에 배포해보면서 부하테스트가 하고 싶어졌다. 그리하여 k6와 CloudWatch를 이용하여 간단하게 아래 API에 대하여 성능 테스트를 해보았다.
(실제로 모든 테이블 100만건 넣고 테스트)
<해당 API>
@GetMapping("/gatherings")
public ResponseEntity<TotalGatheringsResponse> gatherings(@RequestParam(defaultValue = "") String title,
@Username String username){
TotalGatheringsResponse totalGatheringsResponse = gatheringService.gatherings(username, title);
return new ResponseEntity<>(totalGatheringsResponse, HttpStatus.OK);
}<해당 Service Logic>
public TotalGatheringsResponse gatherings(String username, String title) {
userRepository.findByUsername(username).orElseThrow(()->new NotFoundUserException("no exist User!!"));
List<EntireGatheringsQuery> entireGatheringsQueries = gatheringRepository.gatherings(title);
List<GatheringsQuery> gatherings = toGatheringQueriesList(entireGatheringsQueries);
List<TotalGatheringsElement> totalGatheringsElements = toGatheringsResponseList(gatherings);
Map<String, CategoryTotalGatherings> map = categorizeByCategory(totalGatheringsElements);
return createTotalGatherings(map);
}<해당 Repository Query>
@Query(value = "select id,title,content,registerDate,category,createdBy,url,count from ( " +
" select g.id as id, g.title as title, g.content as content, g.register_date as registerDate, ca.name as category, " +
" cr.username as createdBy, im.url as url, g.count as count, " +
" row_number() over (partition by g.category_id order by g.count desc) as rownum " +
" from gathering g " +
" left join category ca on g.category_id = ca.id " +
" left join user cr on g.user_id = cr.id " +
" left join image im on g.image_id = im.id " +
" where g.title like concat('%', :title, '%') " +
") as subquery " +
"where rownum between 1 and 9", nativeQuery = true)
List<EntireGatheringsQuery> gatherings(@Param("title") String title);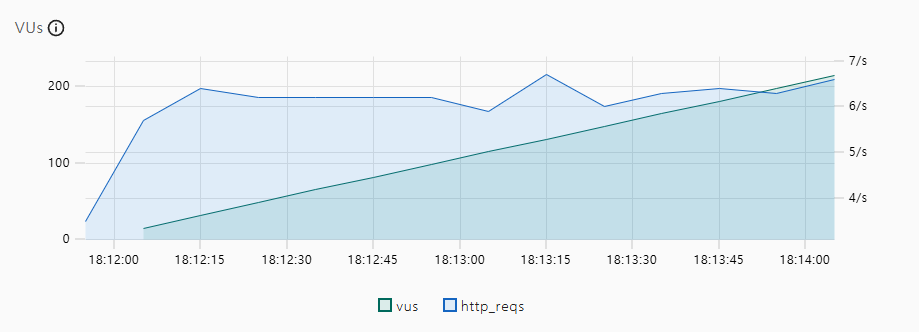
다음과 같이 보면 TPS가 100도 안나오는걸 확인할 수 있다.
데이터베이스는 Mysql RDS를 사용하였고 CloudWatch를 통하여 메모리 및 CPU를 측정해 본 결과, CPU를 99% 소모하고 있는것을 확인하였다.
성능이 안나오는 이유를 확인하기 위해 옵티마이저의 전략을 확인해 봤는데, innerjoin에서 시간이 매우 오래 걸린다는 것을 확인하였다
즉, rownumber을 처리하는 과정에서 g.category_id와 g.count를 처리하는데 인덱스가 안걸려 있기 때문에 full table scan을 하게 된것이다.
따라서 다음과 같은 쿼리문을 통하여 인덱스를 추가하였다
create index category_count on gathering(category_id,count)index를 적용한 이후에 성능이 많이 개선되었다
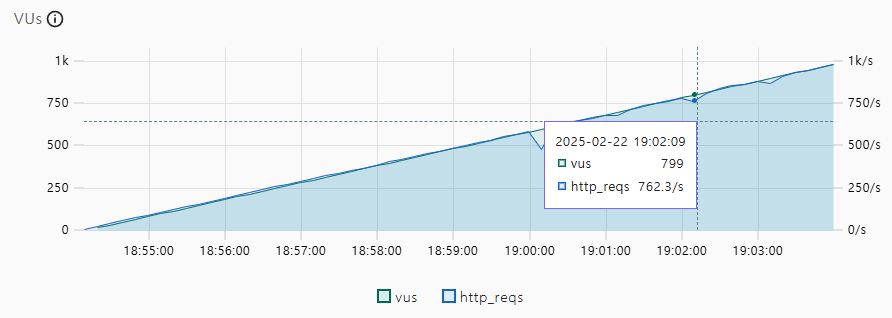
다음 사진을 보면 1000TPS까지 무난히 가능한 걸로 보인다

성장을 지향하는 개발자