📕 Keras
✍ keras
import numpy as np
from numpy import genfromtxt # 텍스트 파일에서 데이터를 배열로 생성해줌.
data = genfromtxt('../Computer-Vision-with-Python/DATA/bank_note_data.txt', delimiter=',') # delimiter : ,로 나누어져서 배열생성됨.
labels = data[:, 4]
features = data[:,0:4]
X = features
y = labels
from sklearn.model_selection import train_test_split # 이걸 사용하면 train set과 test set 나눌수 있음.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42) # 33퍼는 test set으로 들어감.
from sklearn.preprocessing import MinMaxScaler # 모든 데이터의 feature들이 특정 범위로 bound시킬 수 있음. -> 정규화가 가능
scaler_object = MinMaxScaler()
scaler_object.fit(X_train) # 이 과정을 통해 X_train의 최소 값과 최대 값을 찾을 수 있다.
scaled_X_train = scaler_object.transform(X_train)
scaled_X_test = scaler_object.transform(X_test) # 모든 데이터를 학습 시키지 않는 이유는 overfit 방지
from keras.models import Sequential # 이것들을 이용해서 CNN생성
from keras.layers import Dense
model = Sequential()
model.add(Dense(4, input_dim=4, activation='relu')) # feature의 개수, activation function. 이거는 input layer
model.add(Dense(8, activation='relu')) # 이거는 hidden layer
model.add(Dense(1, activation='sigmoid')) # output layer
# 모델을 컴파일하는 과정. 학습 방식에 대한 환경설정.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# epochs : 모든 데이터의 학습 횟수
# verbose : 손실 변수, 손실 값을 나타내줌.
model.fit(scaled_X_train, y_train, epochs=50, verbose=2)
model.predict_classes(scaled_X_test) # 위 함수를 사용하면 X test에 대해 예측 클래스를 뱉음
from sklearn.metrics import confusion_matrix, classification_report # 모델의 결과를 보여주기 위해 가져옴
predictions = model.predict_classes(scaled_X_test)
print(classification_report(y_test, predictions))💻 결과

📗 CNN
✍ MNIST
from keras.datasets import mnist
import matplotlib.pyplot as plt
%matplotlib inline
(x_train, y_train), (x_test, y_test) = mnist.load_data()
single_image = x_train[0]
plt.imshow(single_image, cmap='gray_r') # 검정 하양 반전
from keras.utils.np_utils import to_categorical # one hot encoding을 하기 위함
y_cat_test = to_categorical(y_test, 10) # class의 개수 10개
y_cat_train = to_categorical(y_train, 10)
x_train = x_train / x_train.max() # 수동으로 정규화 하는 방법
x_test = x_test / x_test.max()
x_train = x_train.reshape(60000, 28, 28, 1) # 채널의 차원을 늘려줌
x_test = x_test.reshape(10000, 28, 28, 1)
from keras.models import Sequential
from keras.layers import Dense, Conv2D, MaxPool2D, Flatten # Flatten은 2차원을 1차원으로 바꾸어줌
model = Sequential()
# Convolutional Layer
# 필터의 수는 간단하면 32가 낫다. 커널 사이즈는 보통 3x3 or 4x4
model.add(Conv2D(filters=32, kernel_size=(4,4), input_shape=(28,28,1), activation='relu'))
# Pooling Layer
model.add(MaxPool2D(pool_size=(2,2)))
# 2D -> 1D
model.add(Flatten())
# Dense Layer
model.add(Dense(128, activation='relu')) # Hidden layer
model.add(Dense(10, activation='softmax')) # 이거는 클래스 분류
model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
model.summary()
model.fit(x_train, y_cat_train, epochs=2)
model.evaluate(x_test, y_cat_test)
from sklearn.metrics import classification_report
predictions = model.predict_classes(x_test)
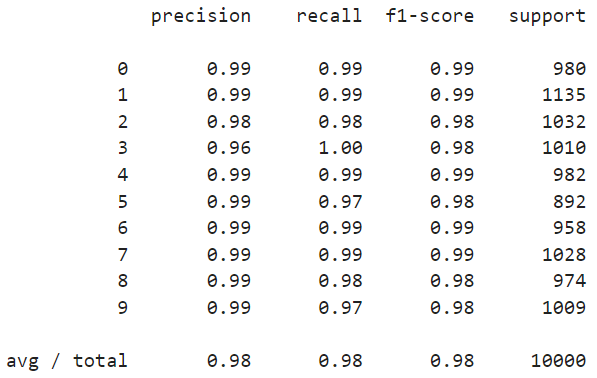
print(classification_report(y_test, predictions))
💻 결과
✍ CIFAR-10
from keras.datasets import cifar10
import matplotlib.pyplot as plt
%matplotlib inline
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train = x_train / x_train.max()
x_test = x_test / x_test.max()
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense, Conv2D, MaxPool2D, Flatten
y_cat_train = to_categorical(y_train, 10)
y_cat_test = to_categorical(y_test,10)
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(4,4), input_shape=(32,32,3), activation='relu'))
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Conv2D(filters=32, kernel_size=(4,4), input_shape=(32,32,3), activation='relu'))
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
model.fit(x_train, y_cat_train, verbose=1, epochs=10)
model.evaluate(x_test, y_cat_test)
from sklearn.metrics import classification_report
predictions = model.predict_classes(x_test)
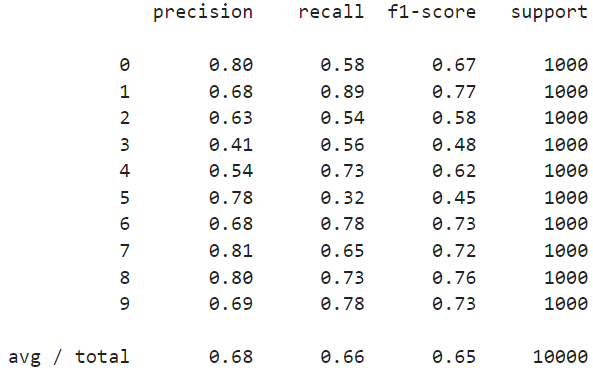
print(classification_report(y_test, predictions))
💻 결과

Vancouver