< Python Basics for Data Science >
1. Python Basics
2. Python Functions and Modules
3. Python Libraires

Numpy
: provides vectorization of mathematical operations on arrays and
matrices which significantly improves the performance

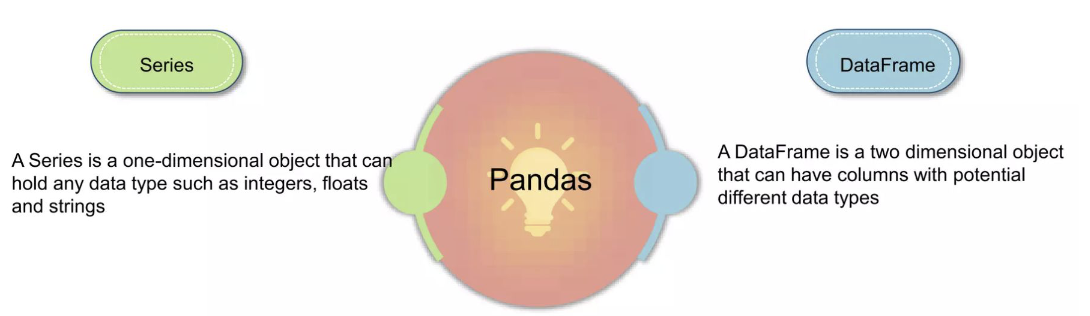
Pandas
: provides tools for data manipulation: reshaping, merging,
sorting, slicing, aggregation etc.






< Data Science and Machine Learning >
1. Data Science and Machine Learning
Data Science
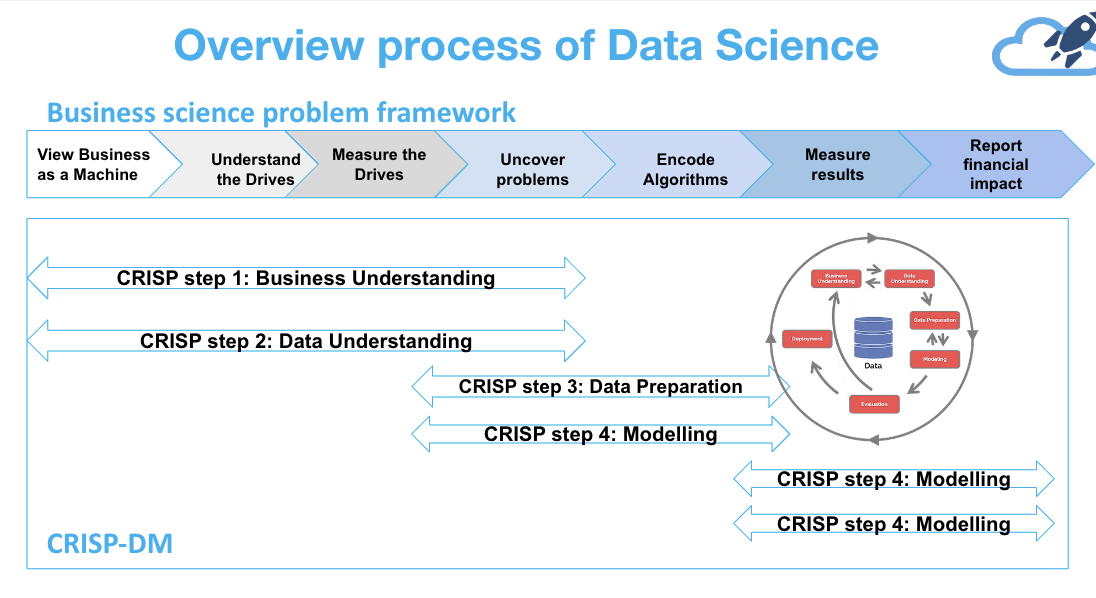
- Data Understanding & Data Acquisition
- Data Cleaning & Data Transformation
- Model Building
- Evaluation
- Deployment
-
Data Preparation
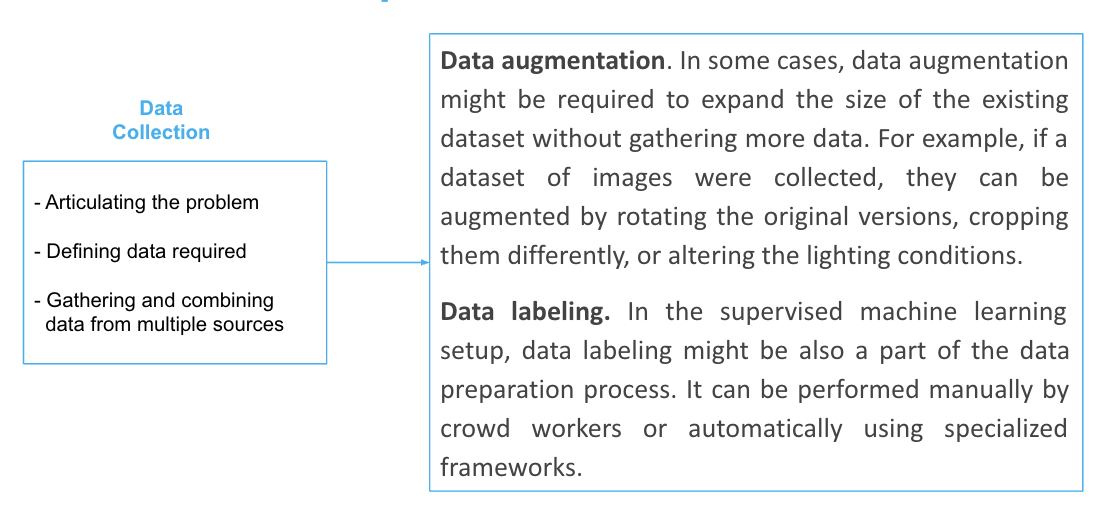
Data Collection
Data Processing
Missing and Repeated Values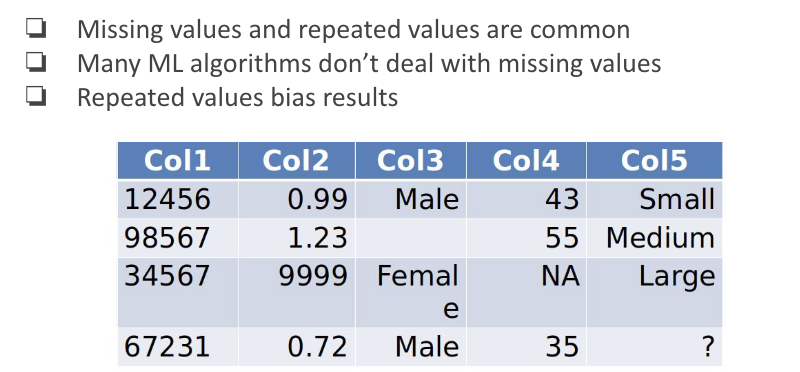
Outliers and Errors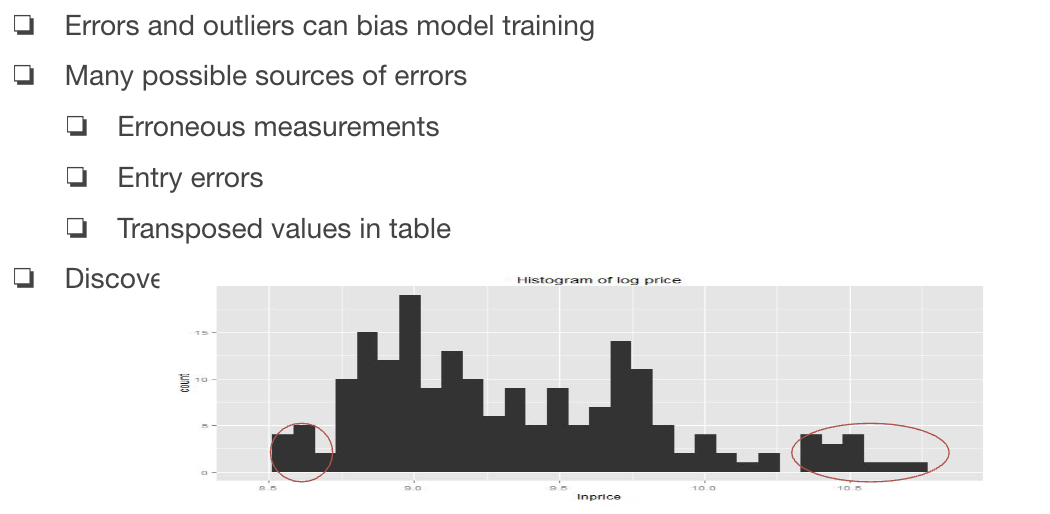
Data Preparation: Data Transformation
Scaling
-
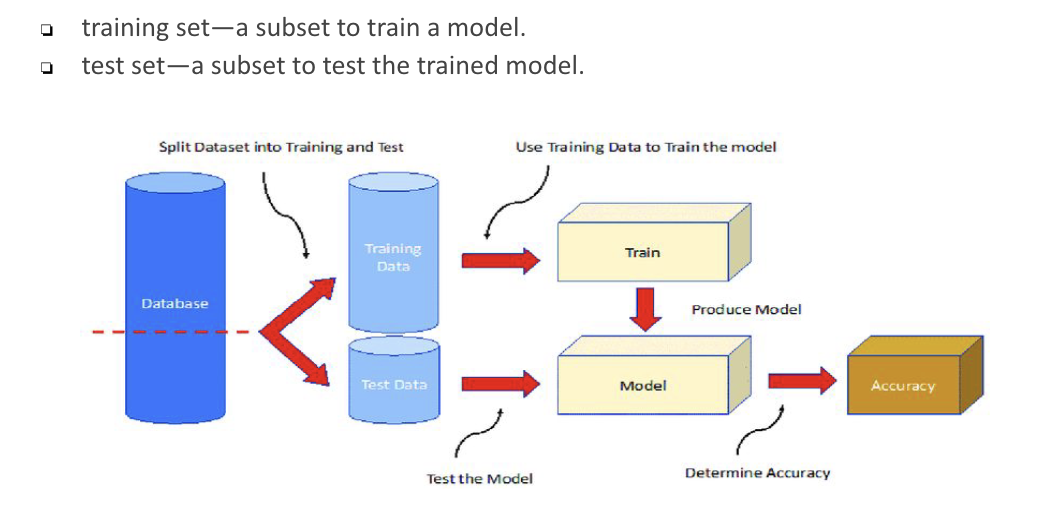
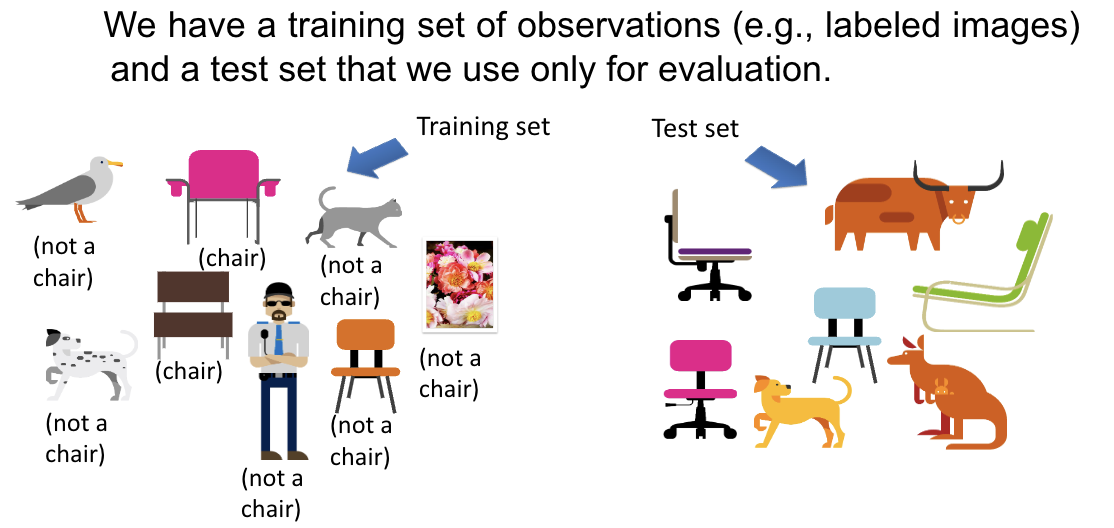
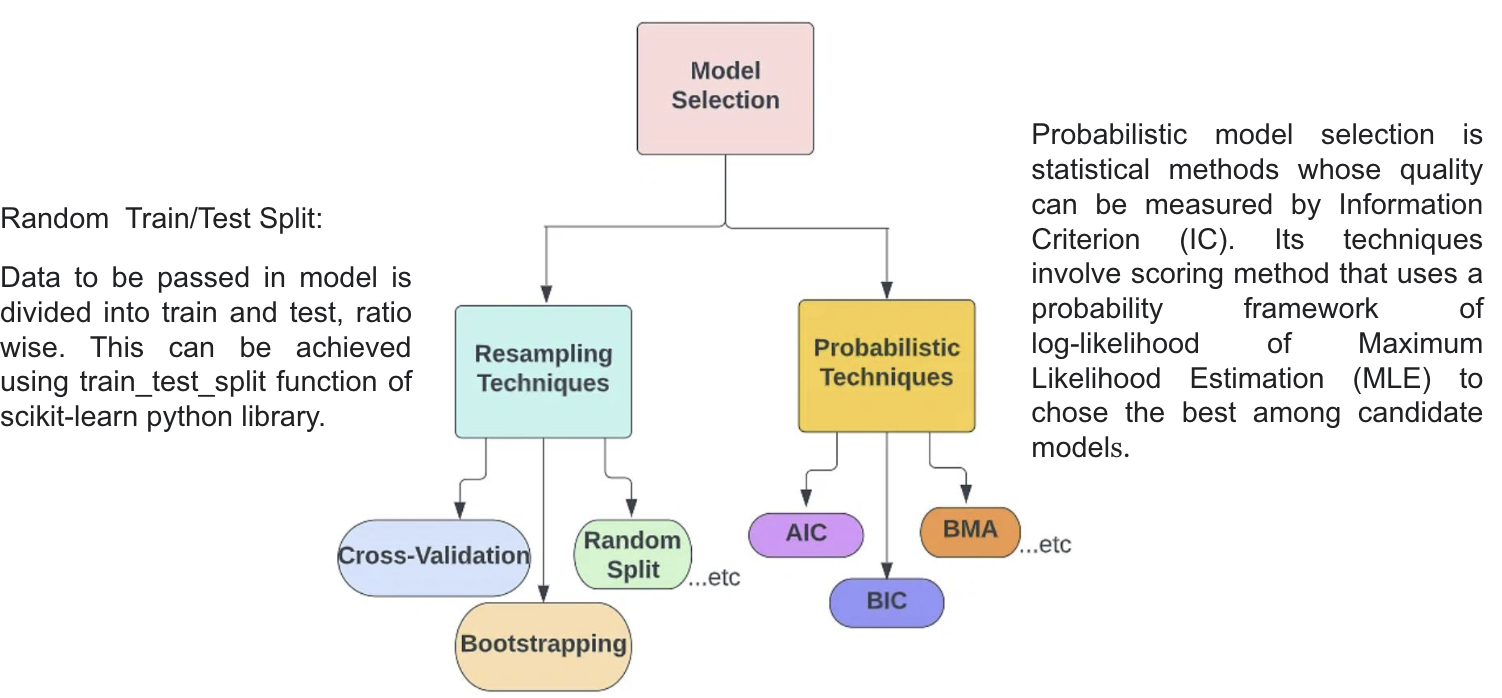
Training data and test data
Machine Learning
-
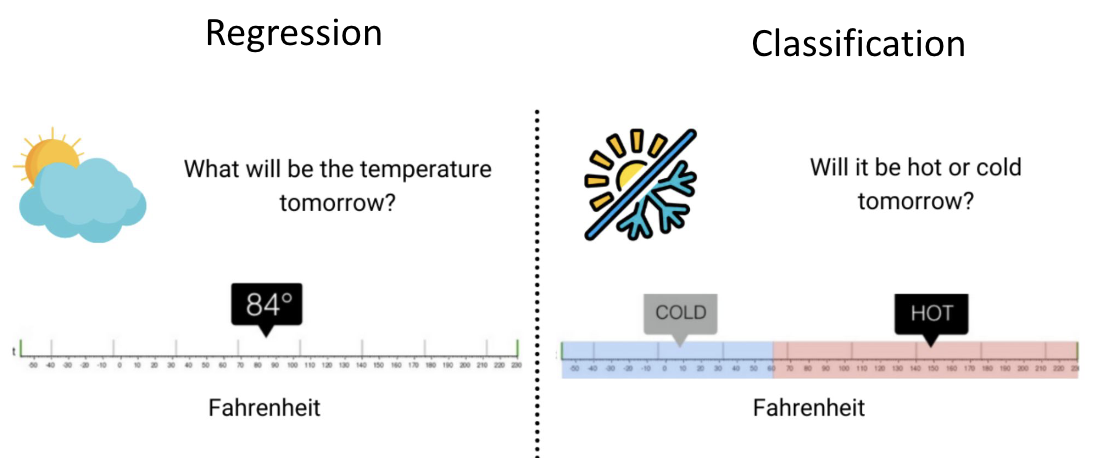
Classification: redict answers to Yes/No questions

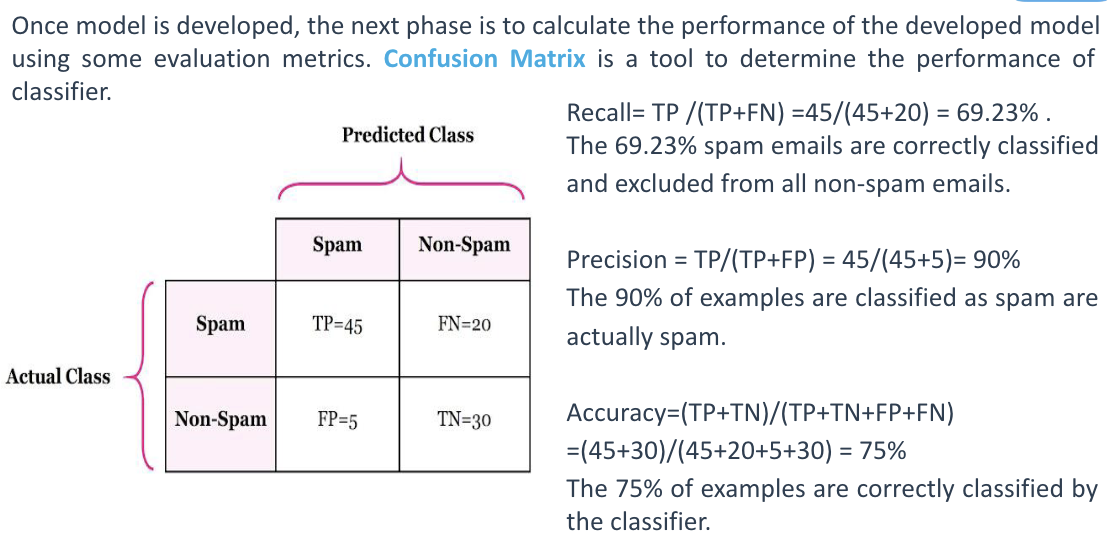
Evaluation of Classification
-
Regression: Predict real values
Linear Regression
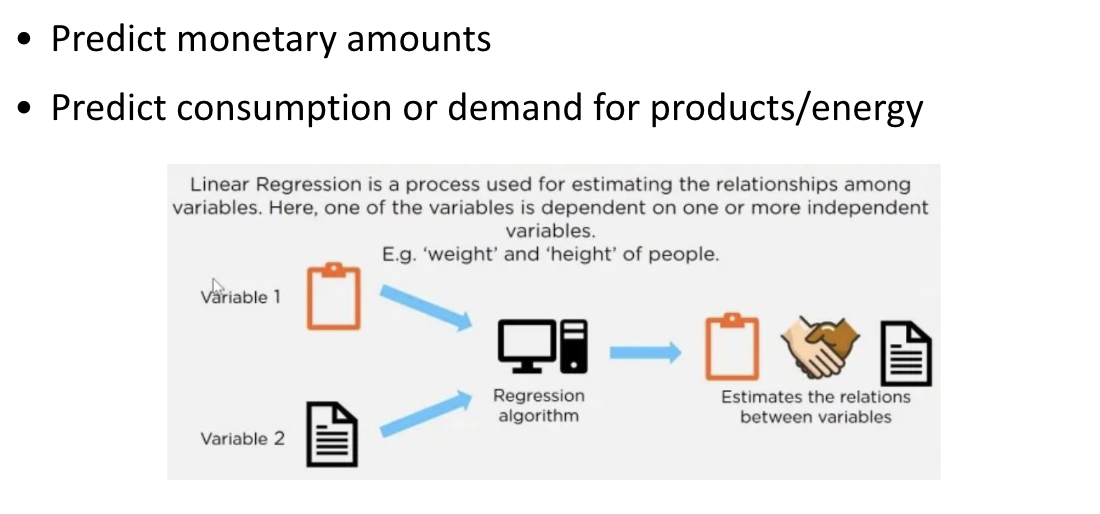
Evaluation of Regression
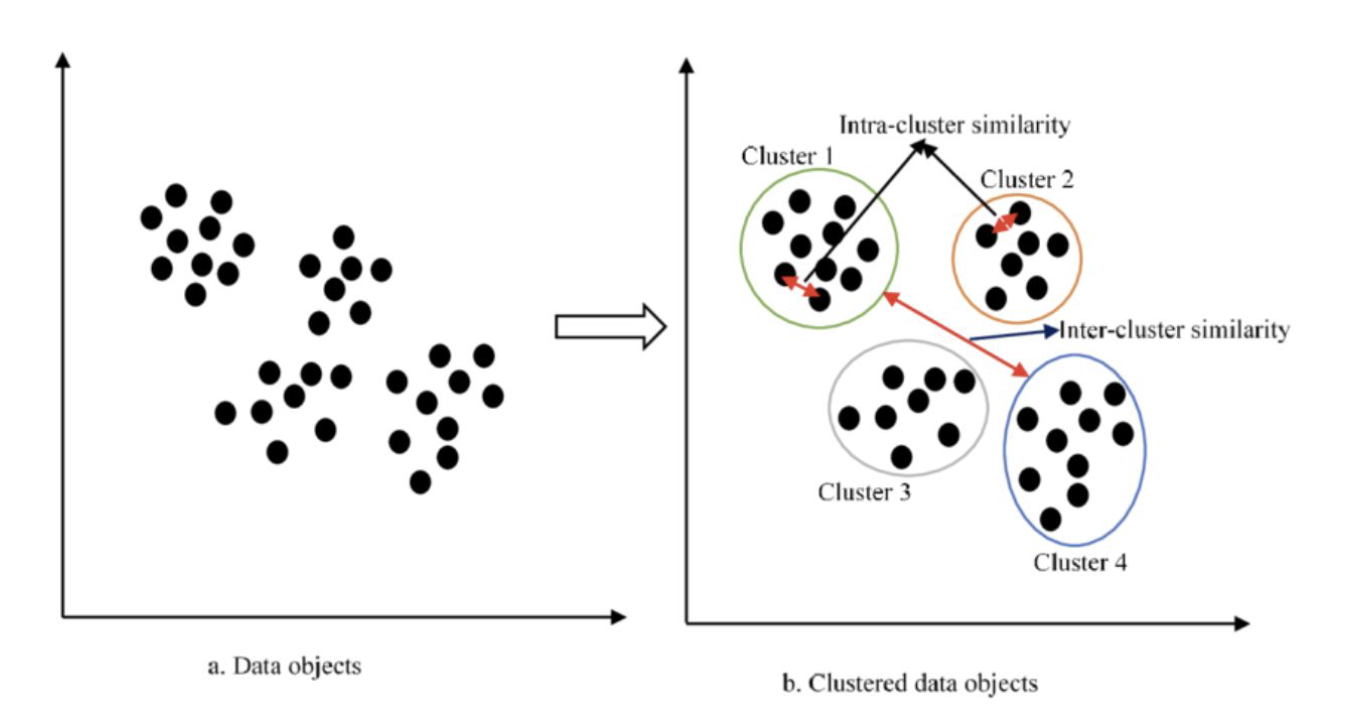
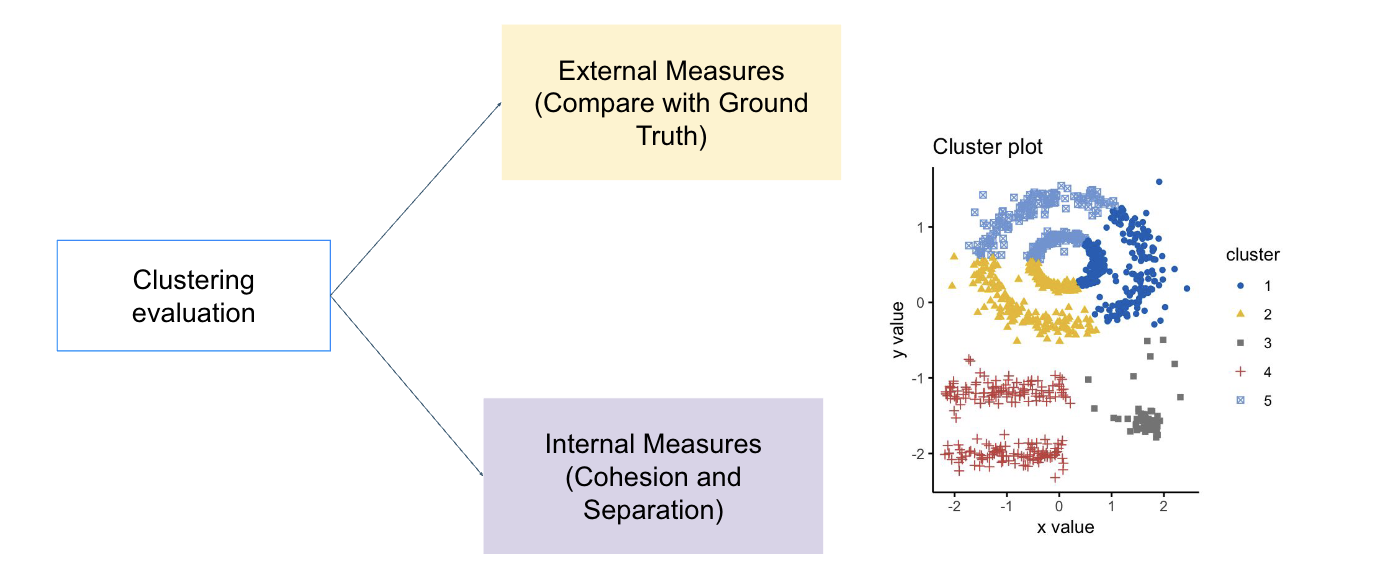
- Clustering: Find patterns of similar objects
- Supervised Learning
- Binary classification:
- Multiclass classification
- Multilabel classification


- Binary classification:
- Unsupervised learning ( Clustering )
-
Training, Validation and Test data
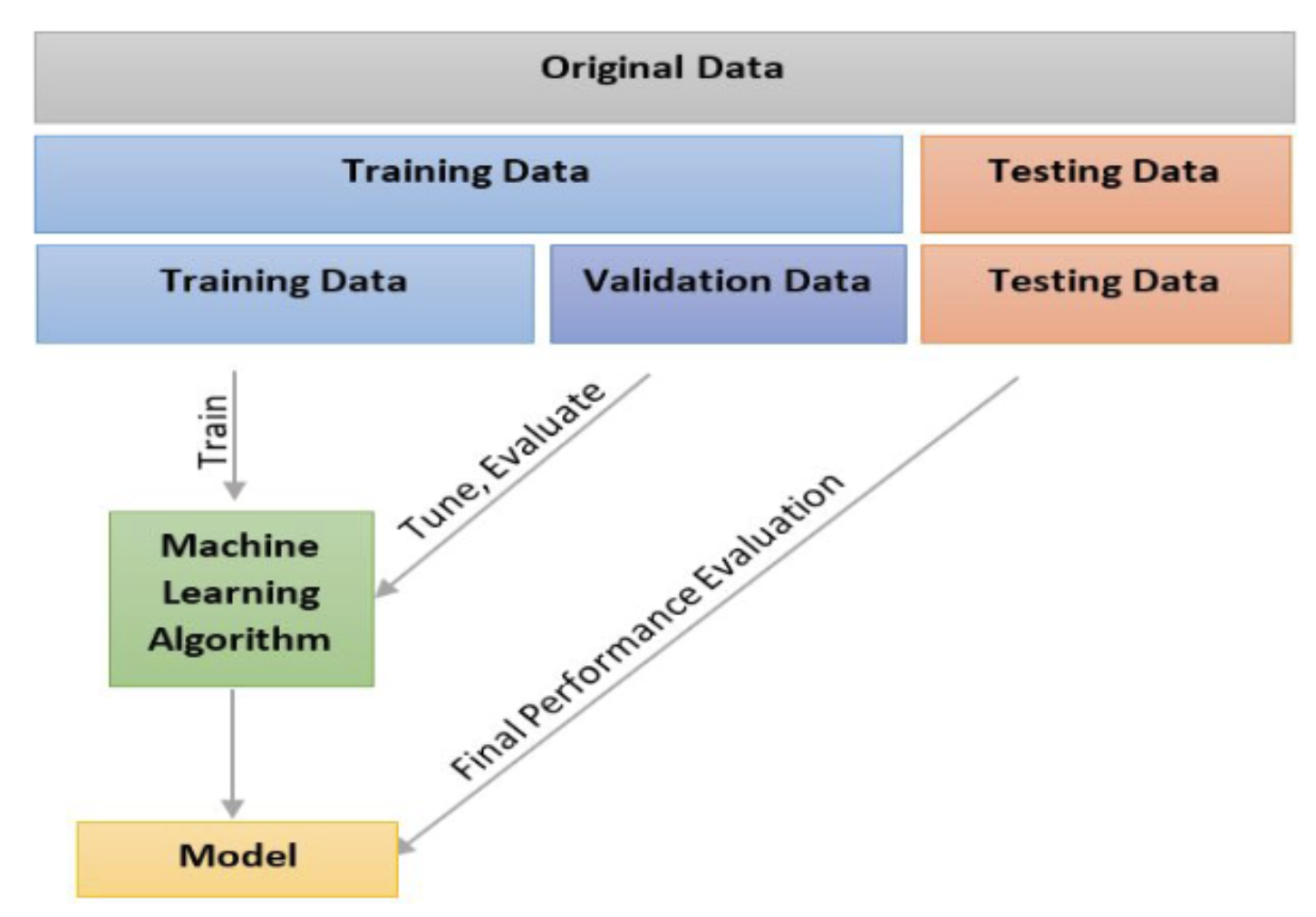
-
Cross Validation
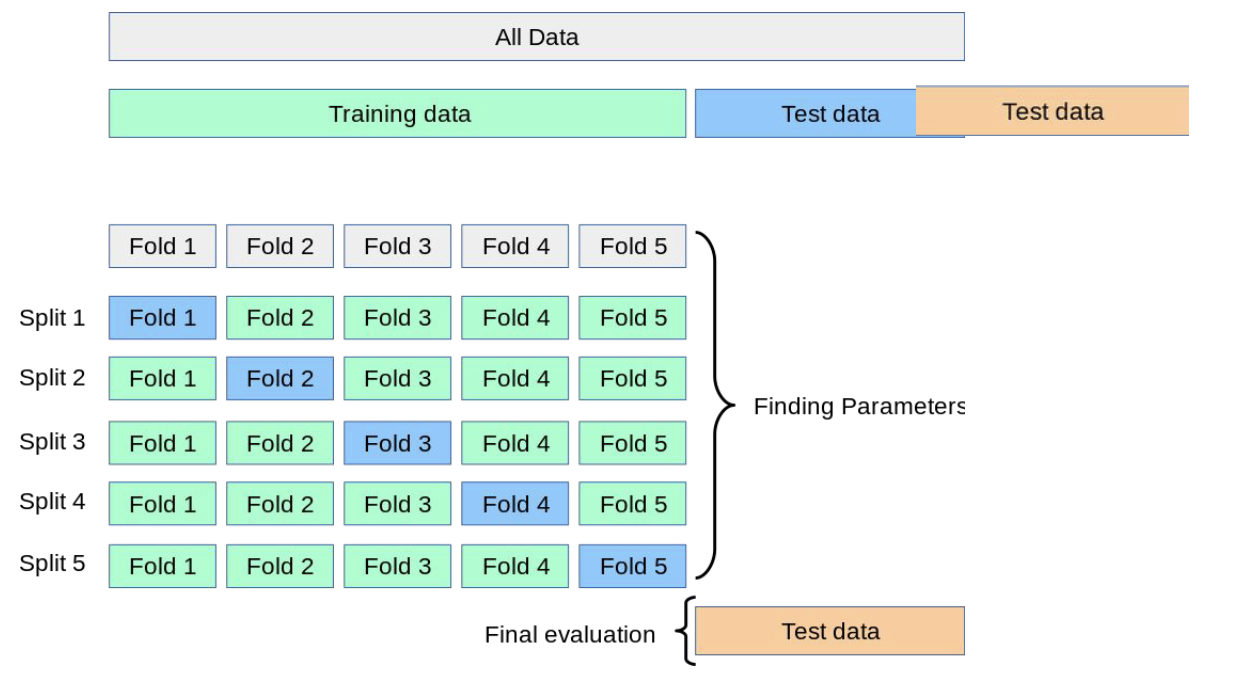
-
Overfitting
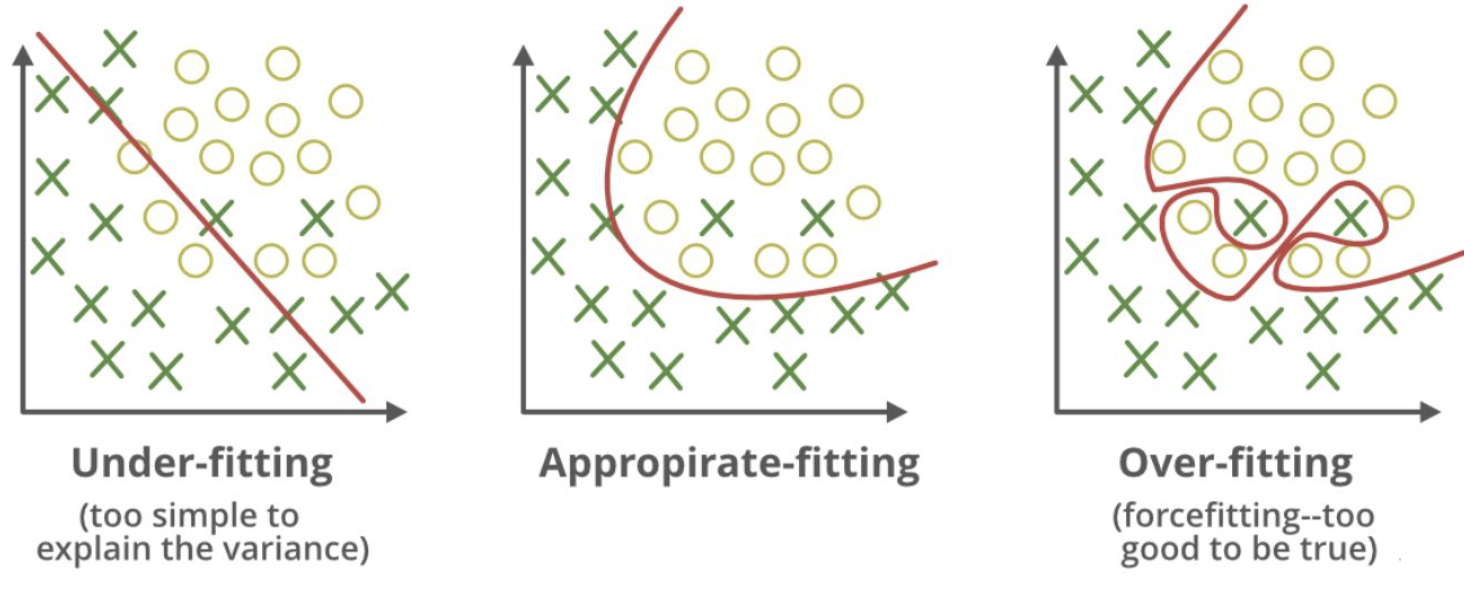
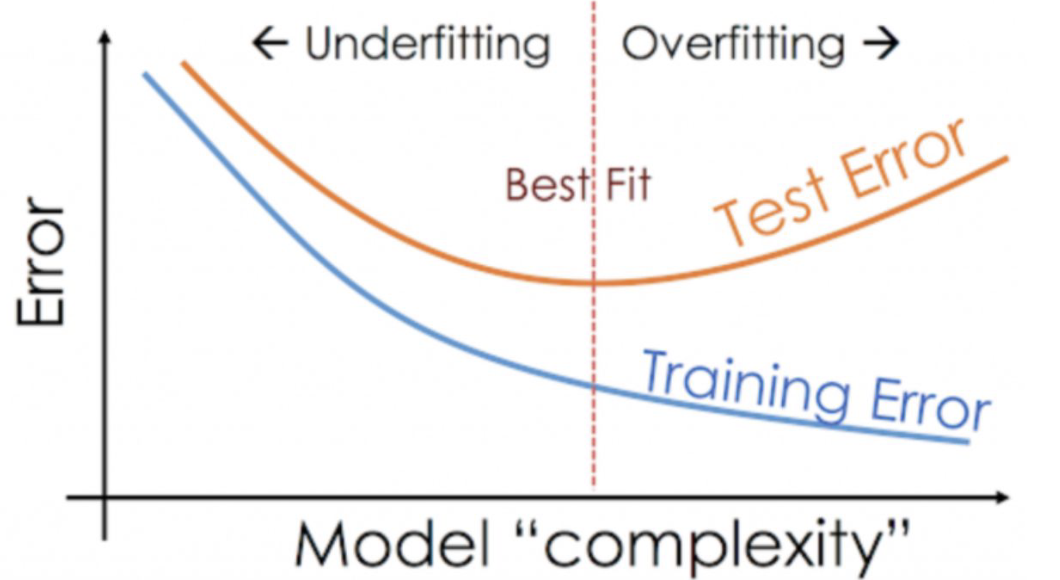
2. DATA PREPROCESSING FOR MACHINE LEARNING
3. MACHINE LEARNING MODELS
< Deep Learning for Computer Vision >
1 . Deep Learning for Computer Vision
Deep Learning
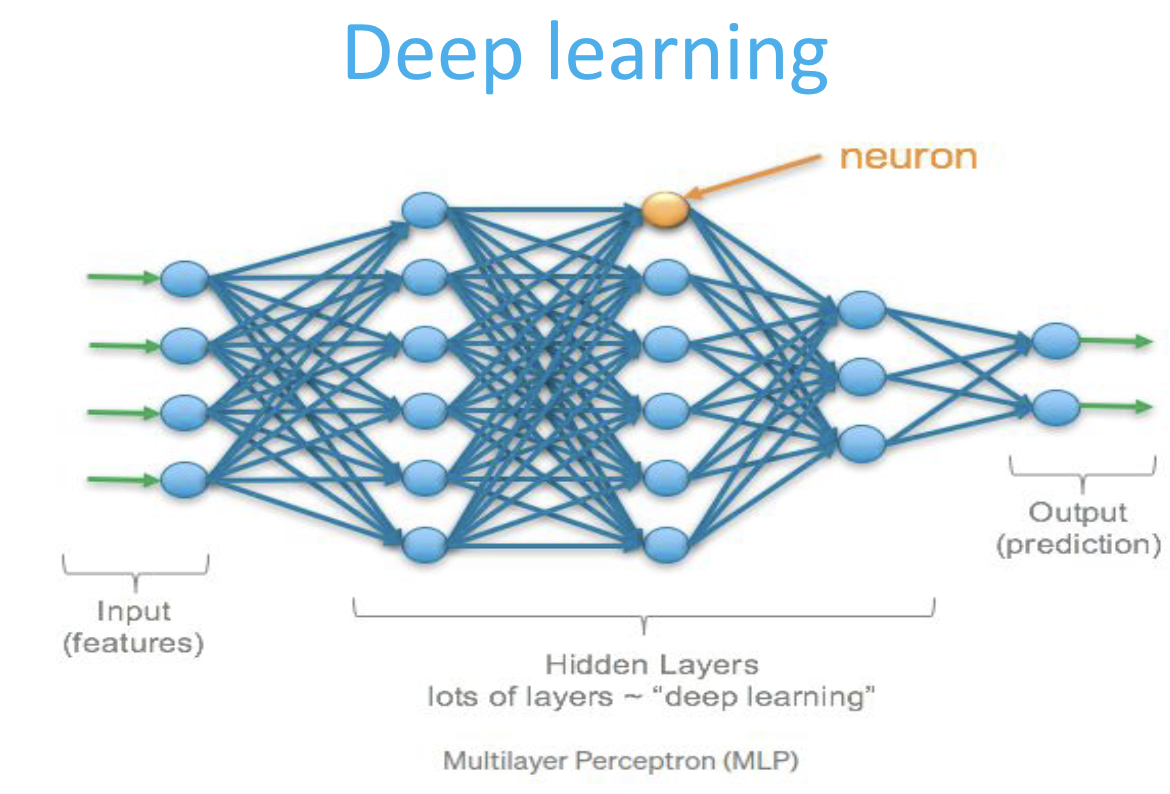
-
The Neuron
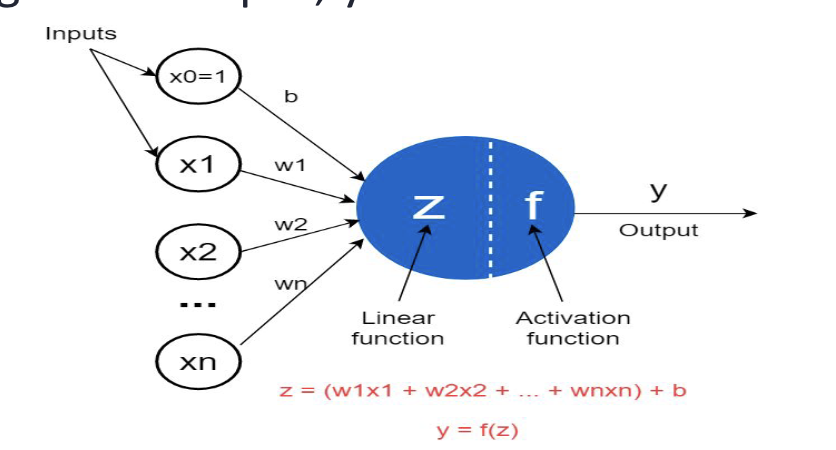

-
activation function
: 네트워크에 non- linear properties를 적용해주는 역할 -
Softmax Activation Function

-
Training Process
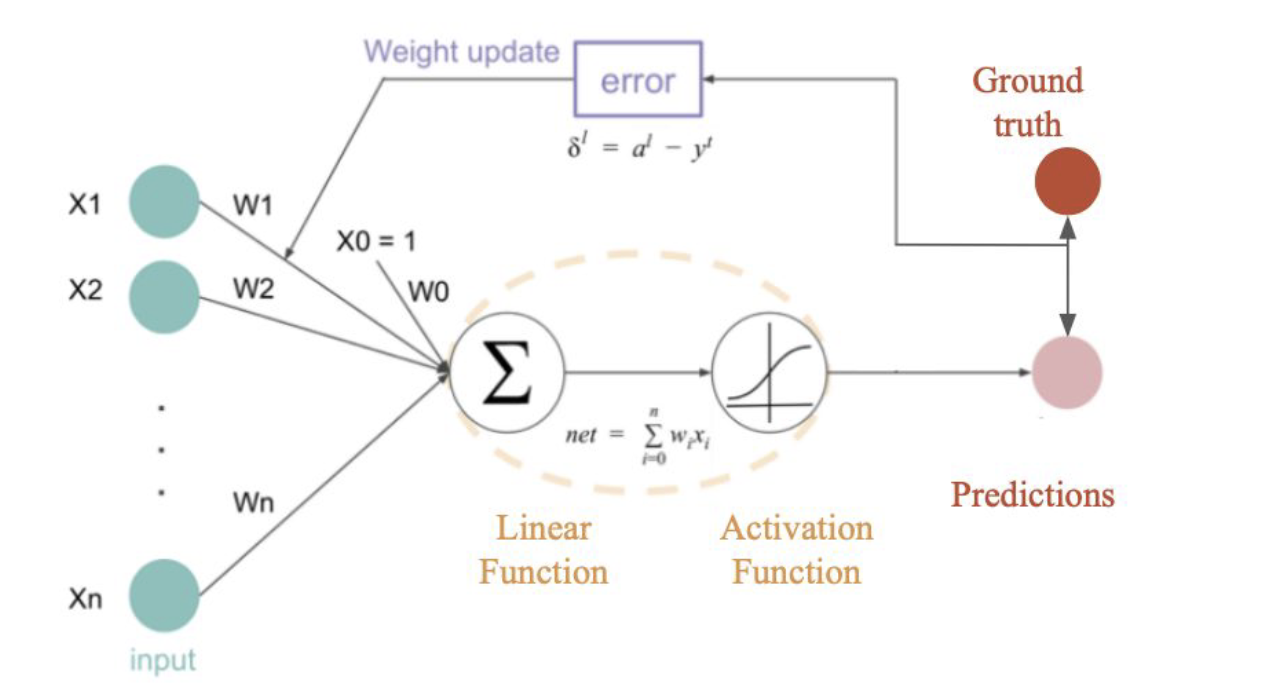
-
Loss Function ( Cost Function )
error를 measure하기 위해 사용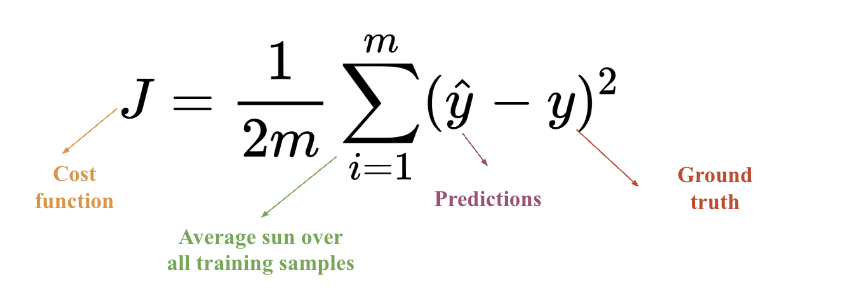
-
Gradient Descent
The Loss/Cost is used to calculate the gradients. And gradients are used to update the weights of the Neural network.
-
Training a Deep Learning Model

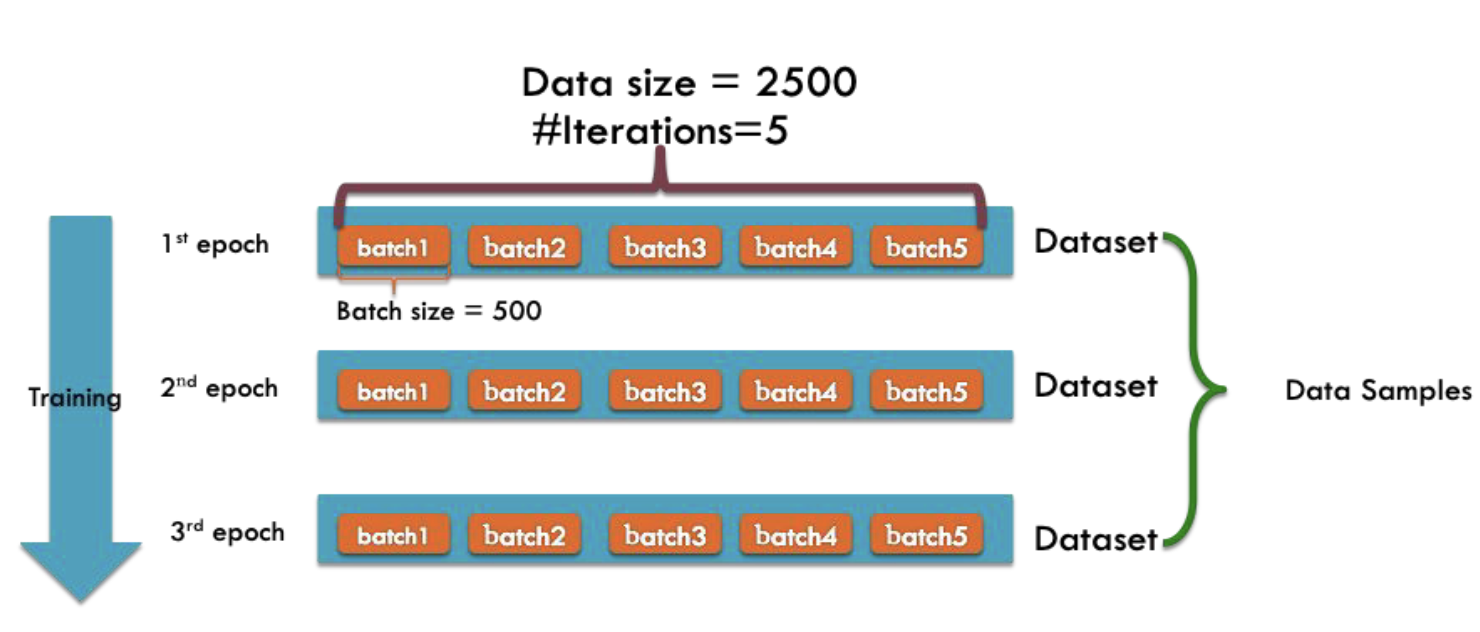
-
Transfer Learning
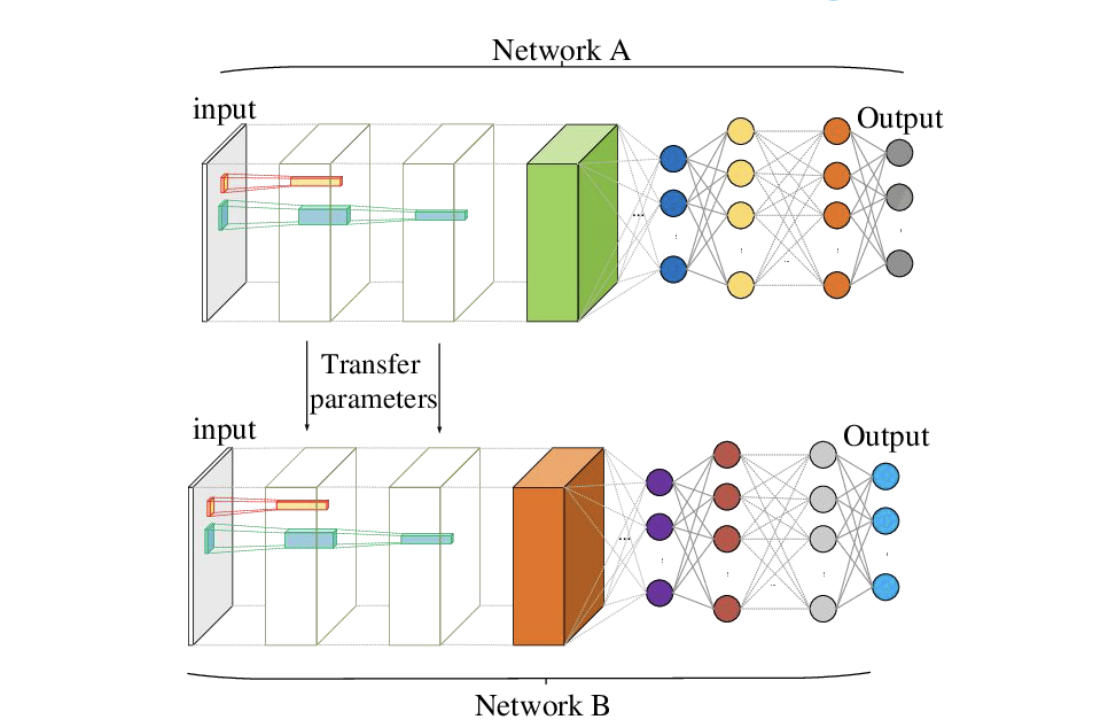
이미 학습된 모델의 지식을 다른 관련 작업에 적용하는 것을 의미. 많은 작업에서는 이러한 양의 데이터를 확보하기가 어렵거나 시간과 비용이 많이 드는 경우가 있습니다. 이때 Transfer learning은 유용한 방법이 될 수 있다 -
Fine-tuning
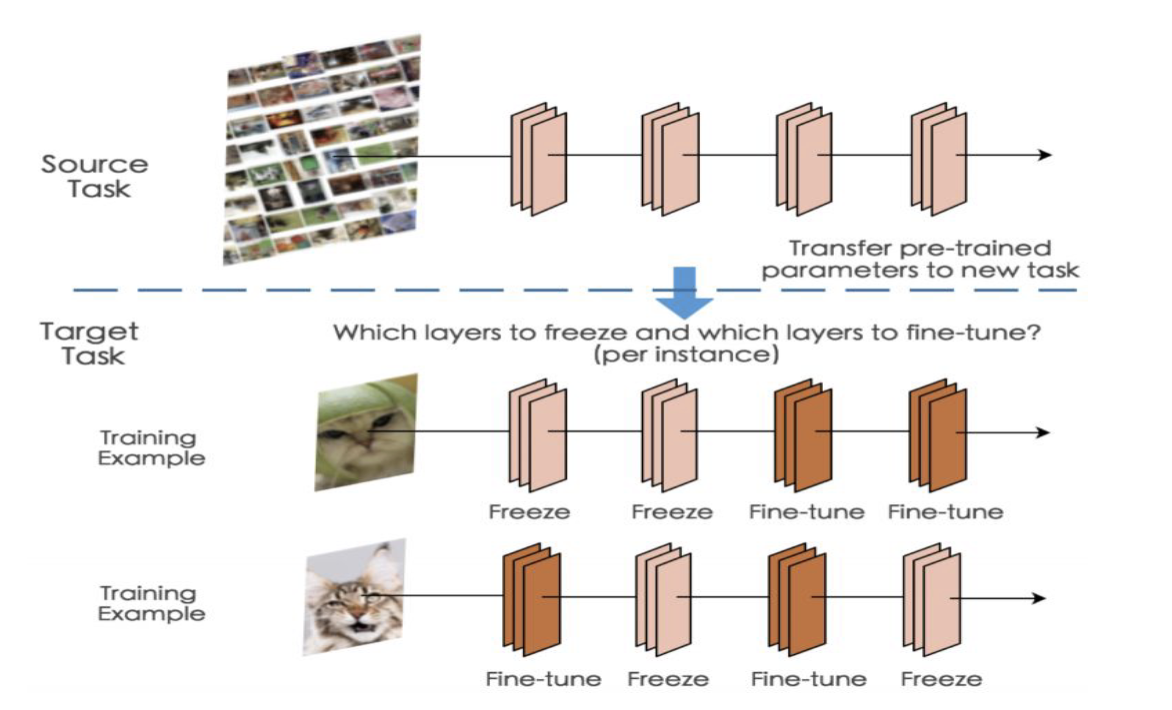
Fine-tuning은 전이 학습(transfer learning) 기법의 한 형태로, 사전 학습된 모델을 새로운 작업에 맞게 조정하는 과정을 말합니다. 이 과정에서는 사전 학습된 모델의 일부 레이어 또는 가중치를 동결(freeze)하고, 나머지 부분을 새로운 데이터셋으로 다시 학습시킵니다. Fine-tuning의 목적은 사전 학습된 모델이 이미 학습한 일반적인 특징을 유지하면서, 새로운 작업에 필요한 특징을 미세하게 조정하는 것이다.
freeze는 copy하는 것이고 fine-tuning은 regerate하는 것임.
Computer Vision
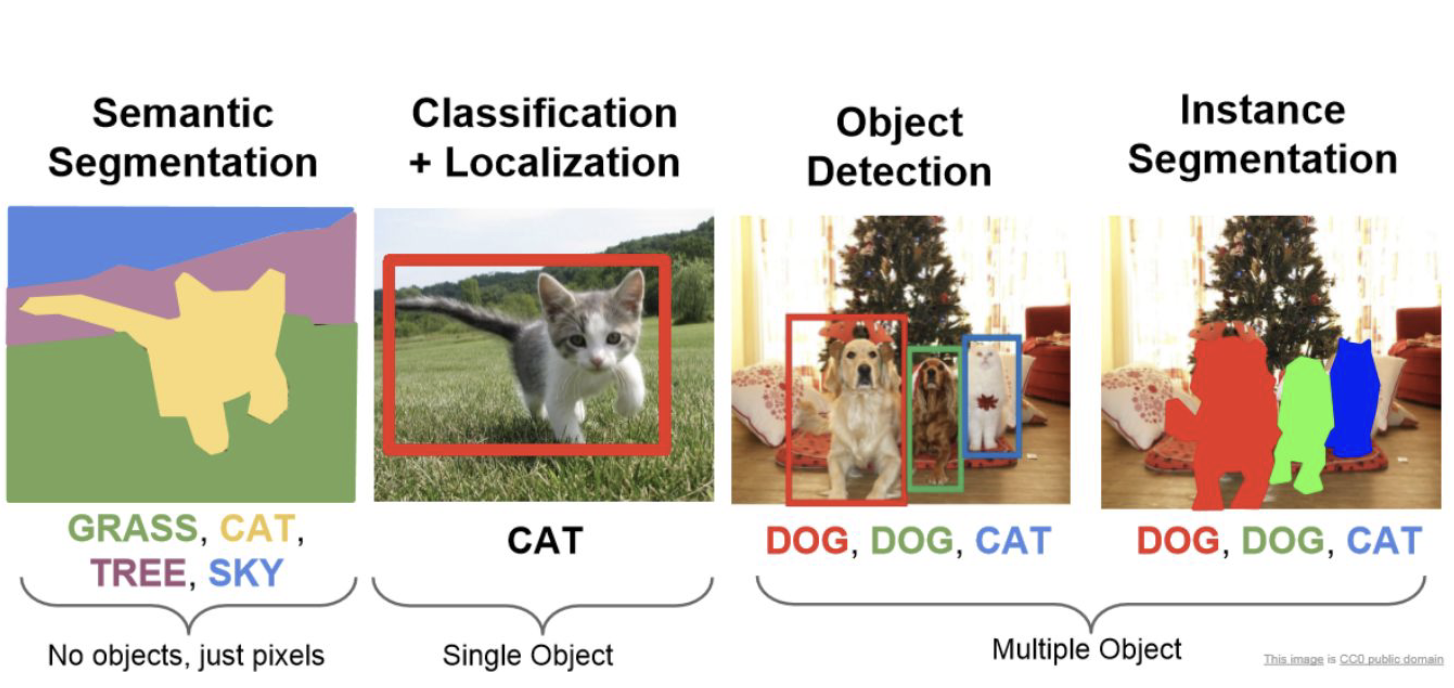
-
Image Classification
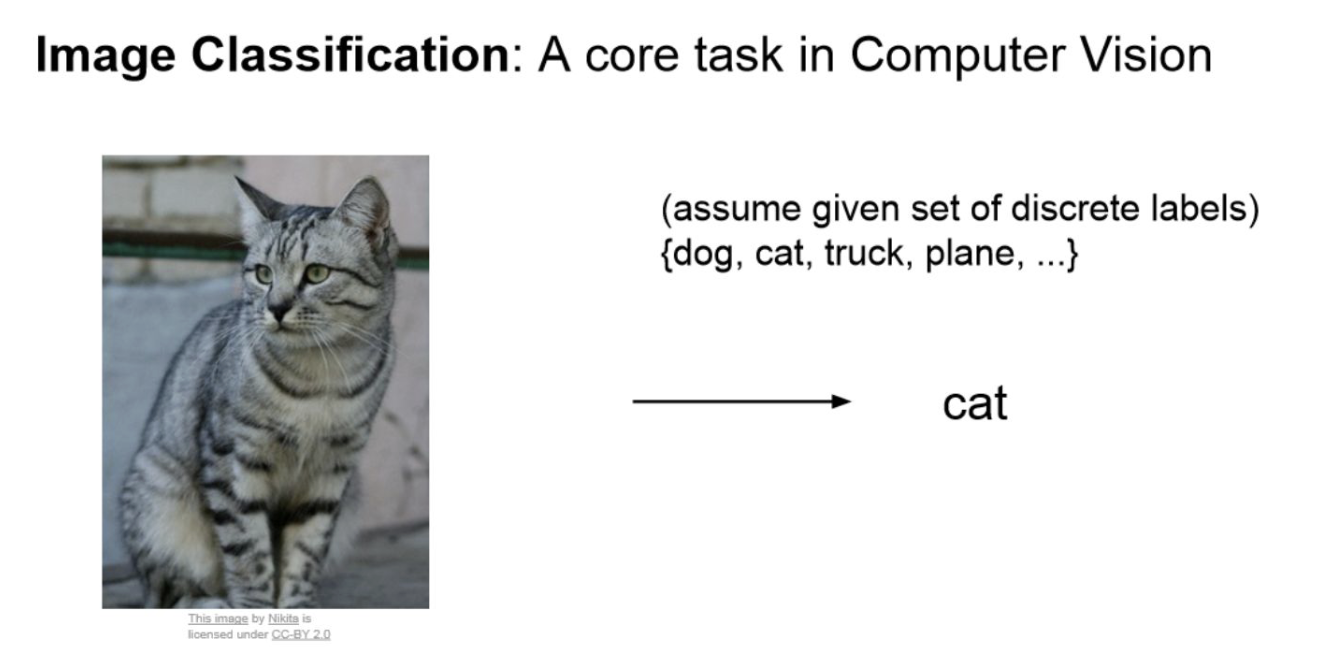

-
Object Detection
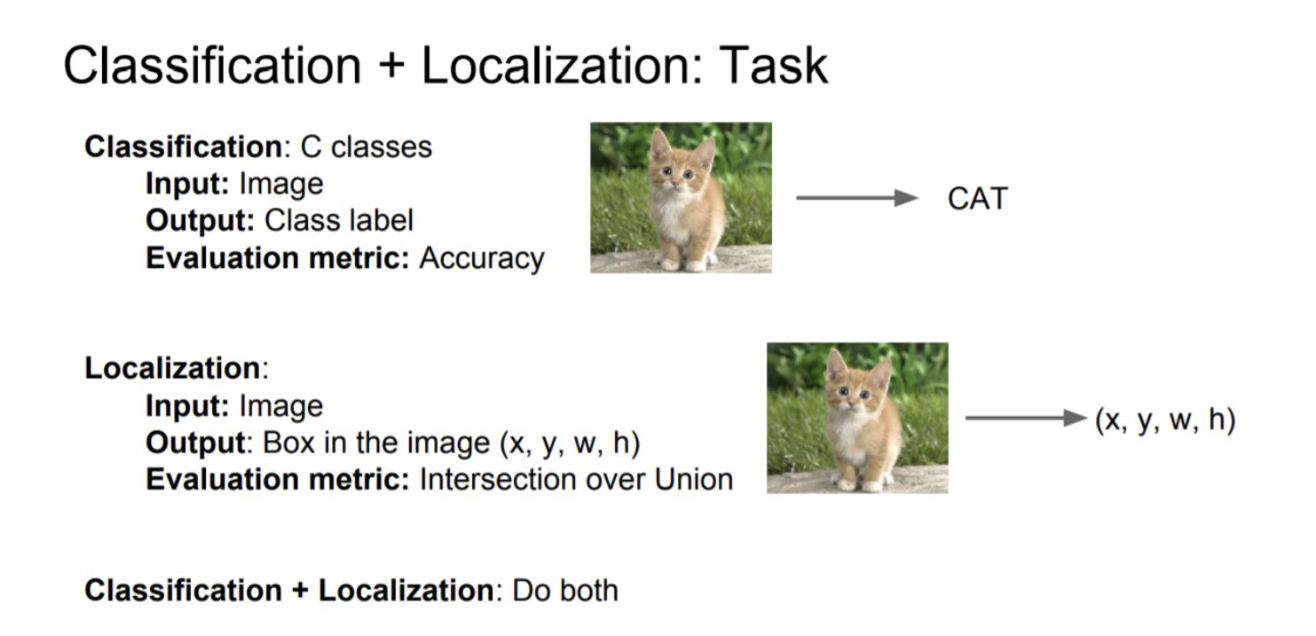
-
Semantic Segmentation
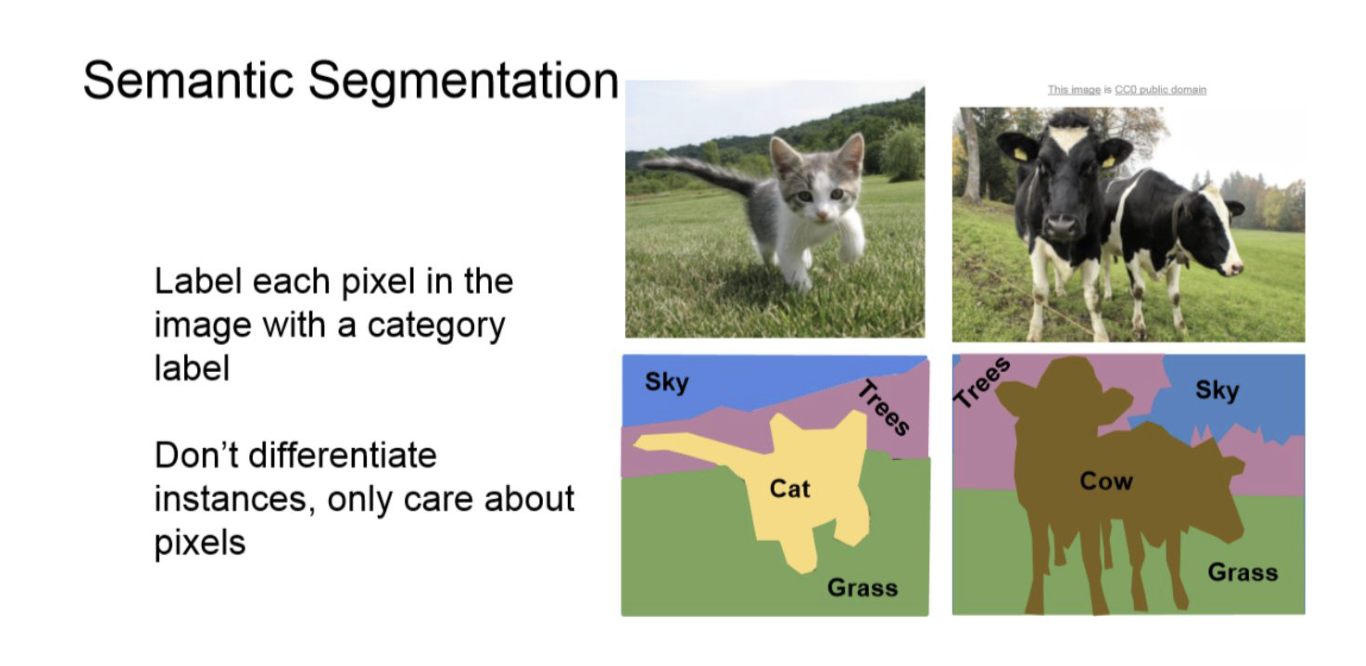
-
Instance Segmentation
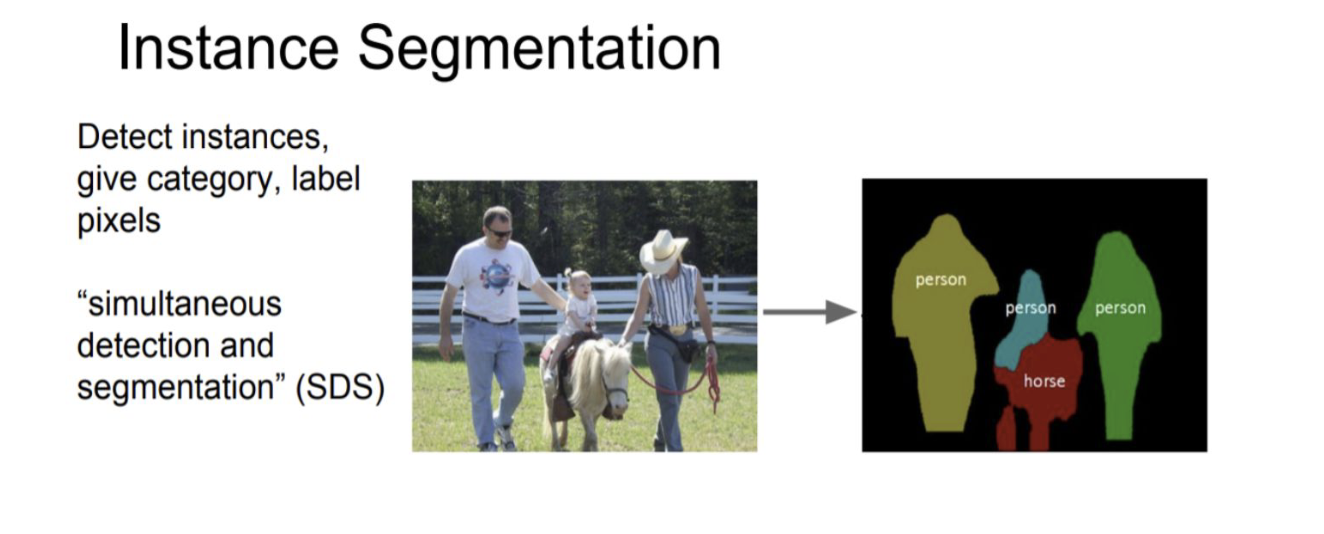
instance means object
CNN (Convolutional neural netwokrks)
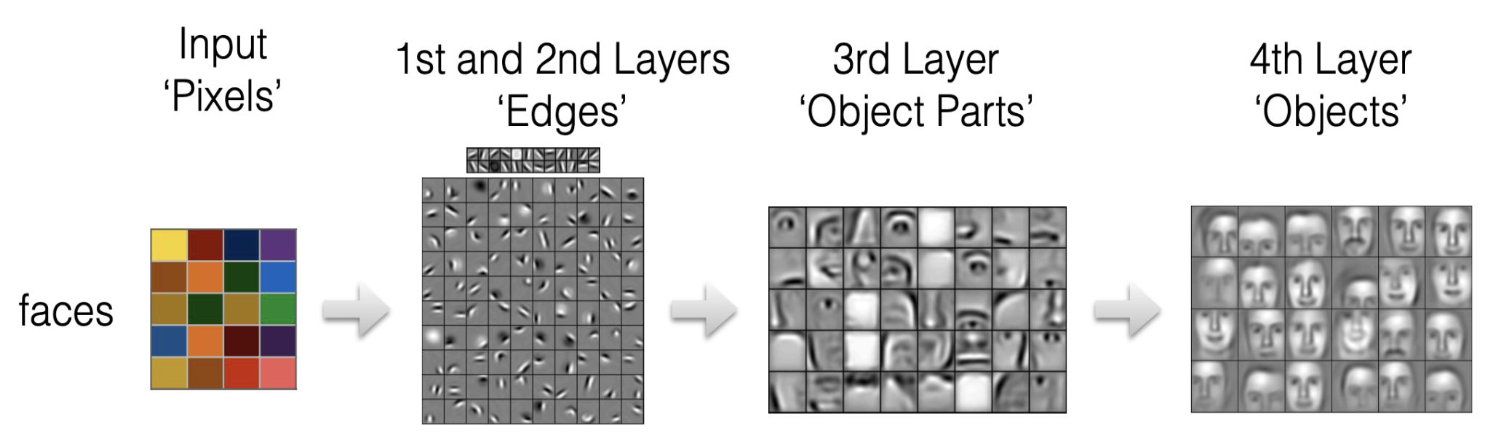
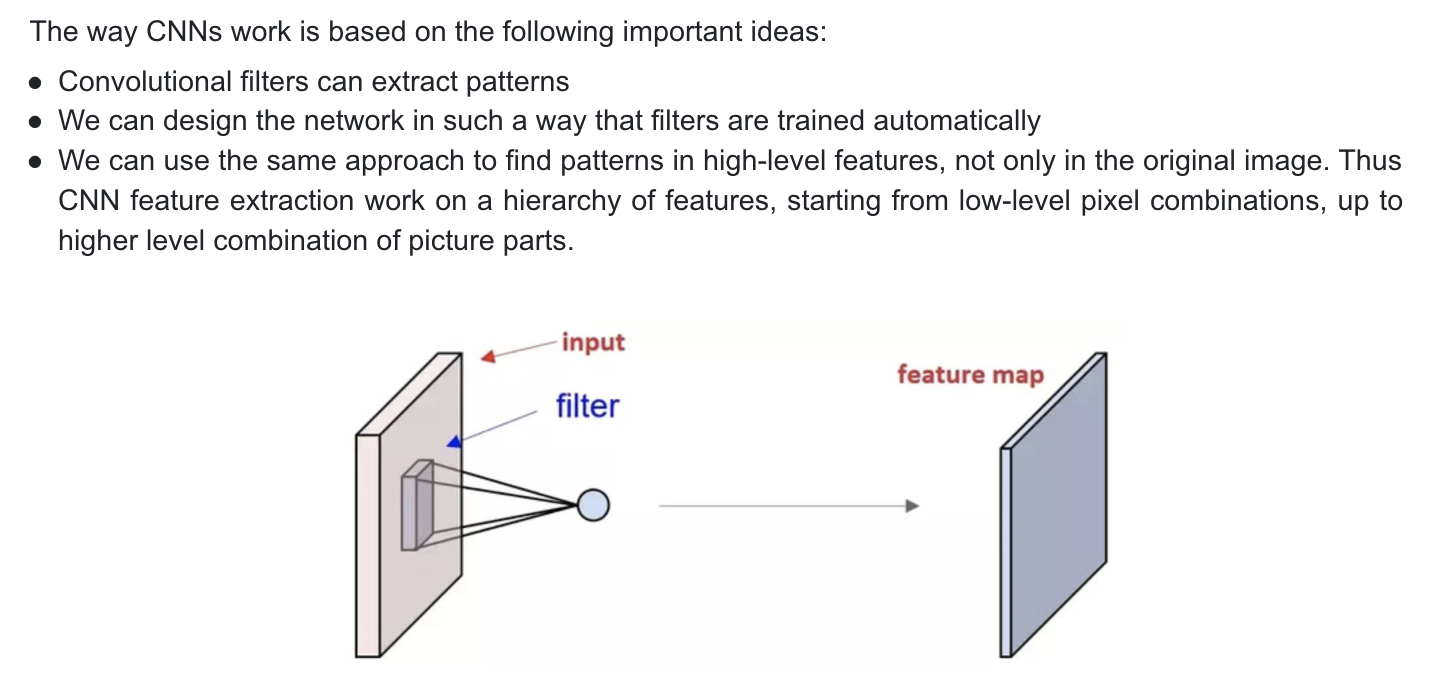
A convolutional layer applies a series of convolutional filters (also known as kernels) to the input data.
Each filter is a small matrix of weights that is convolved with the input data, performing a mathematical operation called convolution
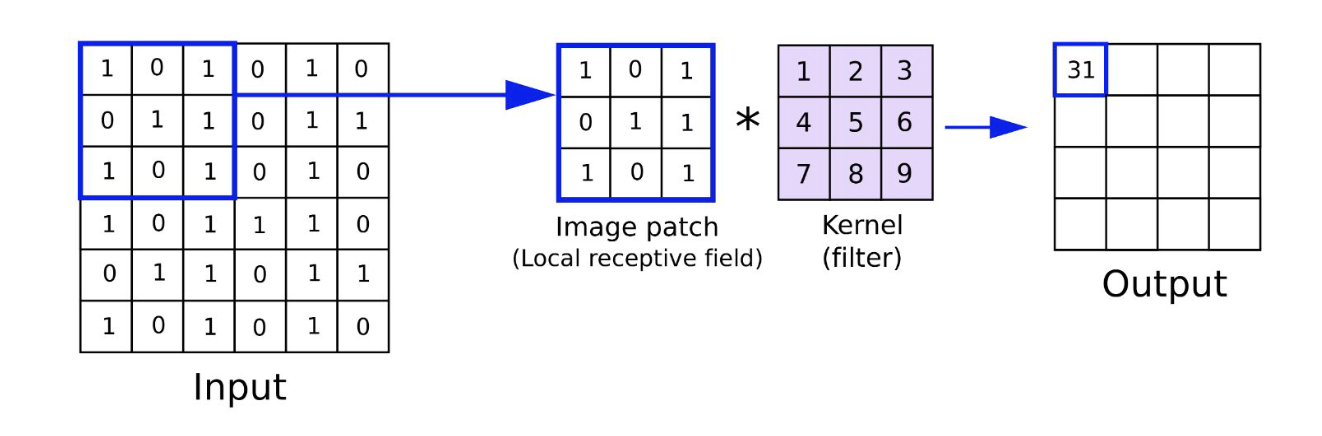
The Kernel
Conventionally, the first ConvLayer is responsible for capturing the Low-Level features such as edges, color, gradient orientation, etc. With added layers, the architecture adapts to the High-Level features as well, giving us a network that has a wholesome understanding of images in the dataset.
gray scale feature: 2 dimentional(width & height). 1 channel
RGB feature: 3 channel . Height X Width X Channel

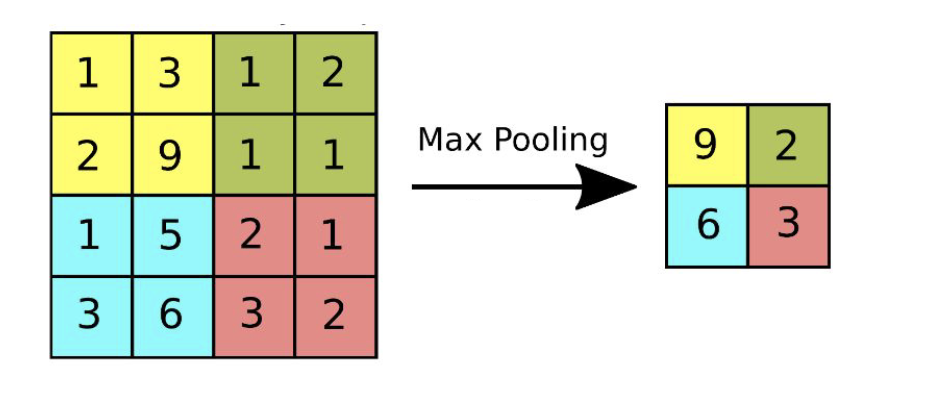
Pooling Layer
* dropout: to avoid overefitting, randomly abandon some neurons
Example of ConvNet
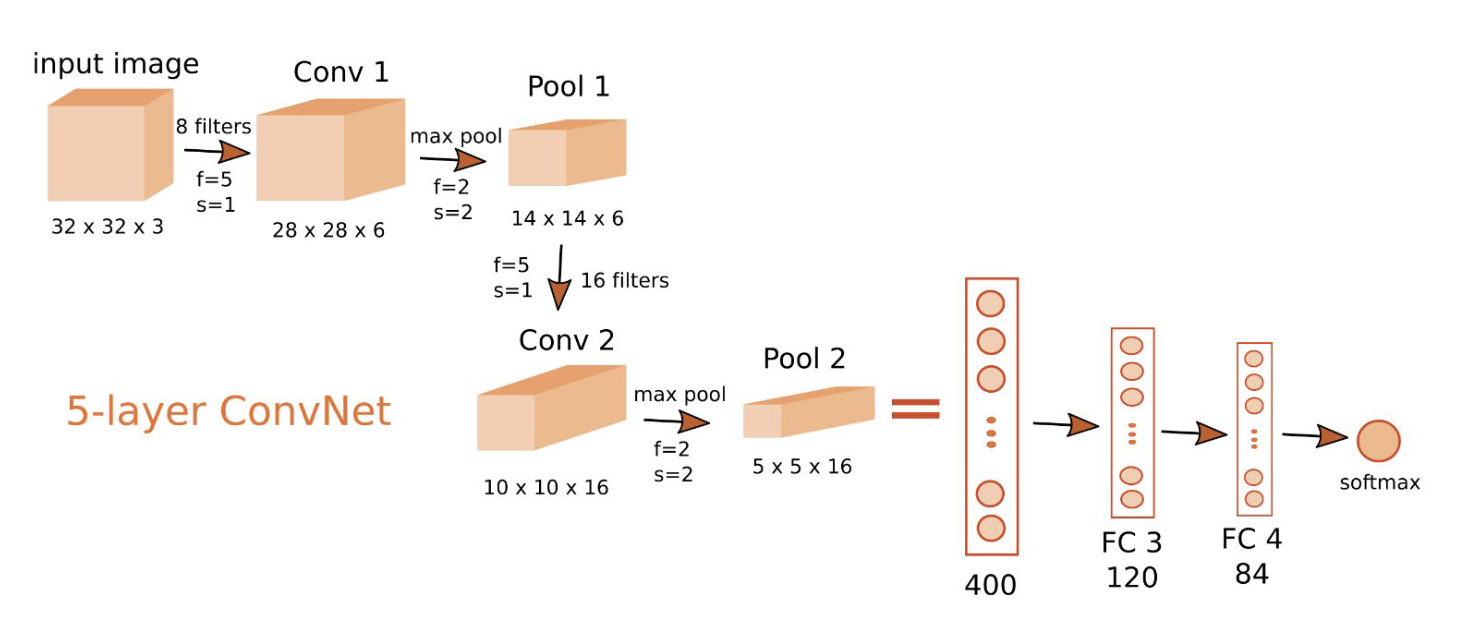
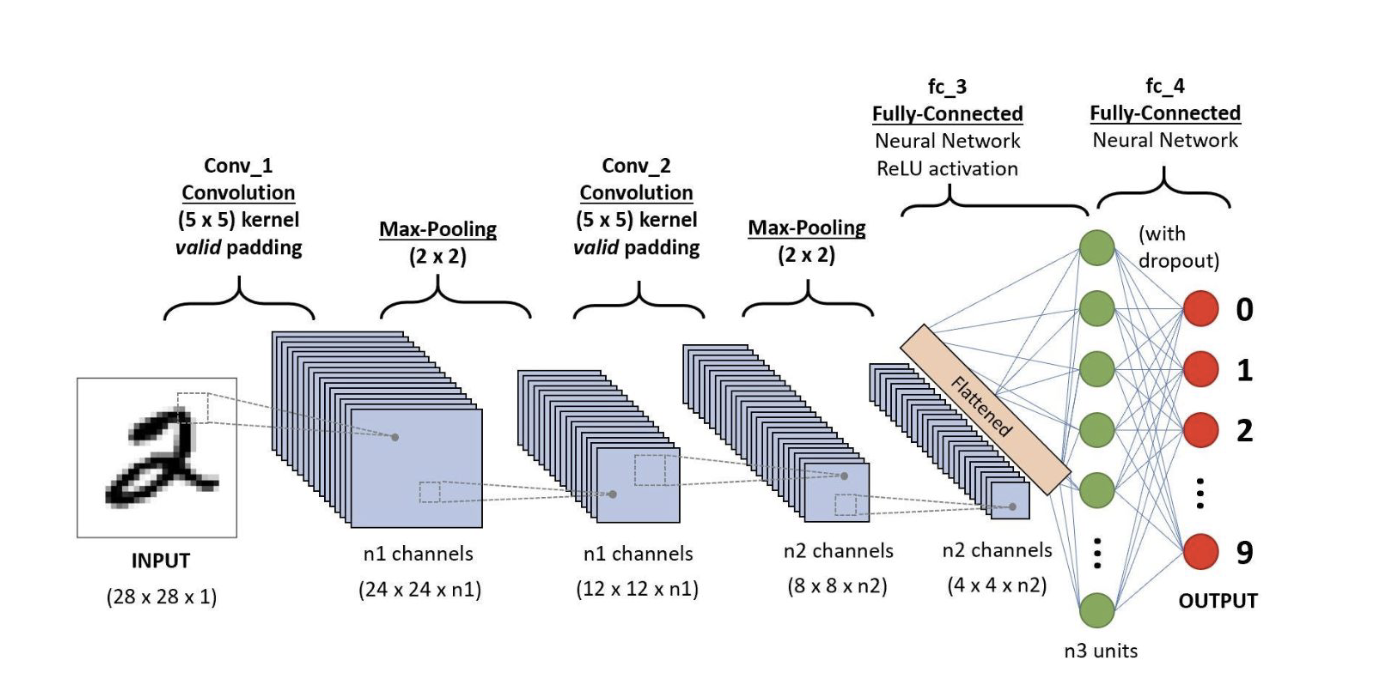
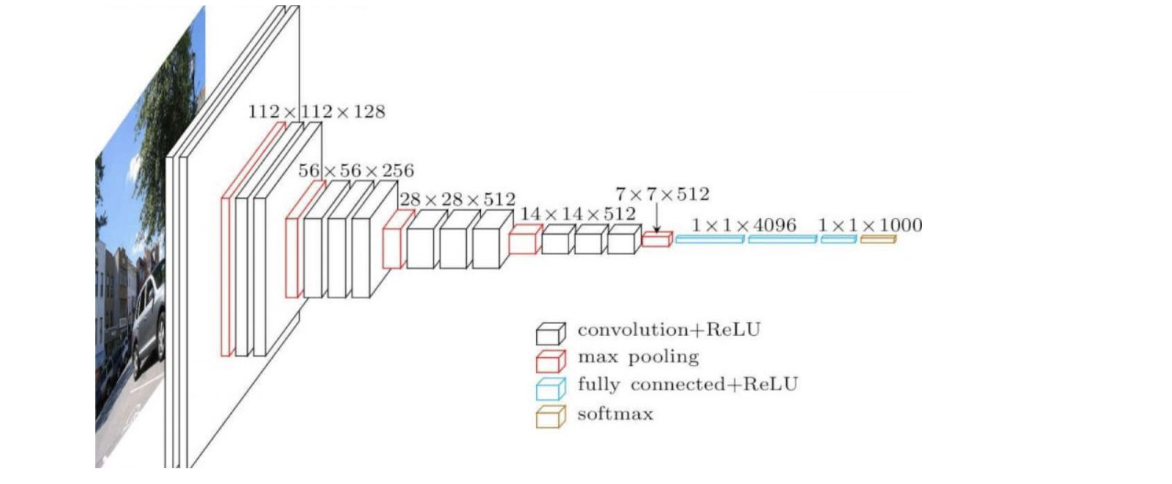
Pyramid architecture
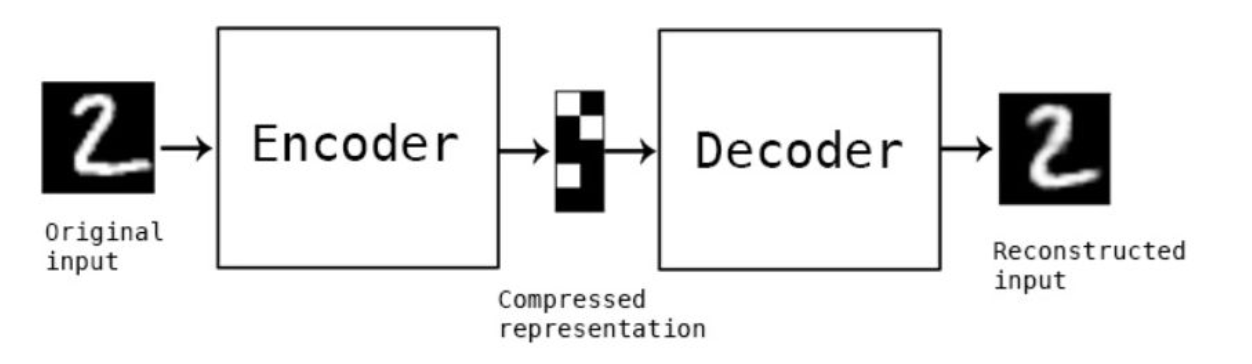
Autoencoder
When training CNNs, one of the problems is that we need a lot of labeled data. In the case of image classification, we need to separate images into different classes, which is a manual effort.
=> However, we might want to use raw (unlabeled) data for training CNN feature extractors, which is called self-supervised learning. Instead of labels, we will use training images as both network input and output.
=> The main idea of autoencoder is that we will have an encoder network that converts input image into some latent space (normally it is just a vector of some smaller size), then the decoder network, whose goal would be to reconstruct the original image.
OpenCV
: OpenCV is a powerful image processing library written in C++, which has become the de factostandard for image processing. It has a convenient Python interface.
-
Loading Images

-
Resizing Images
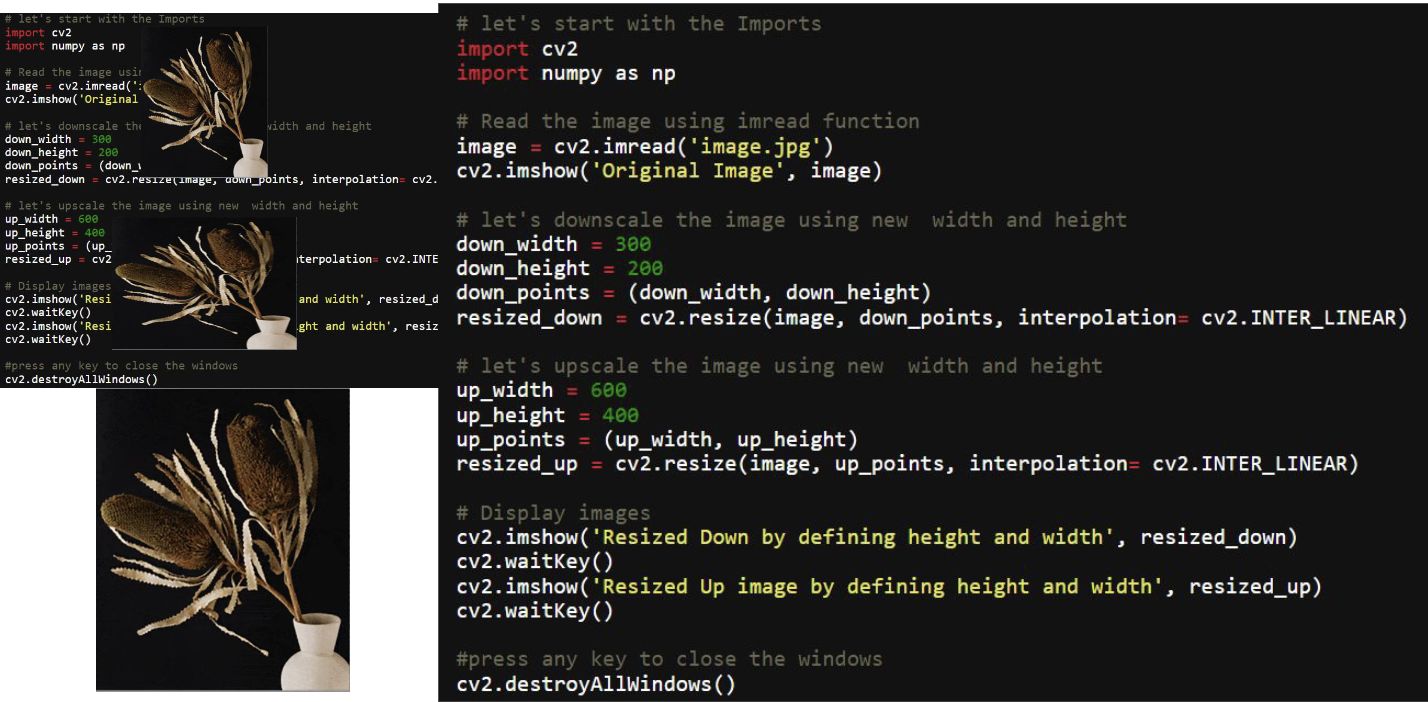
-
Cropping Images
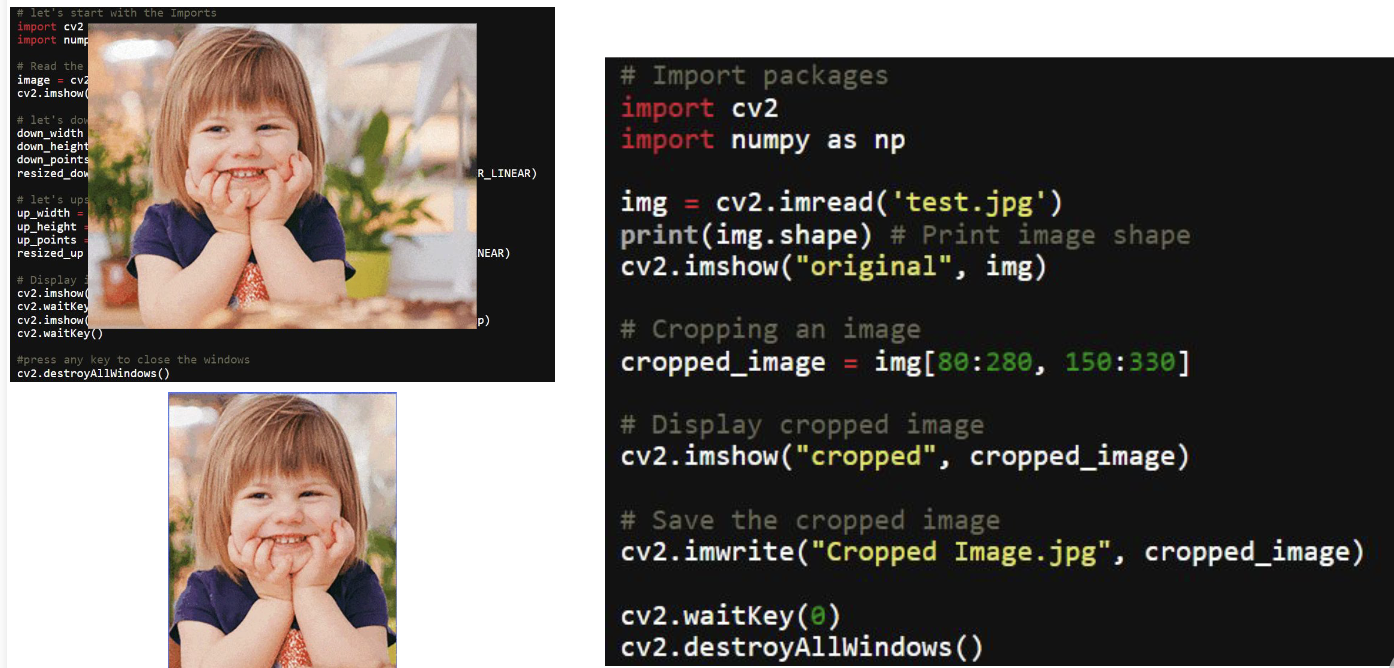
2 . ConvNet for image classification
< Generative AI for Computer Vision >
Generative AI
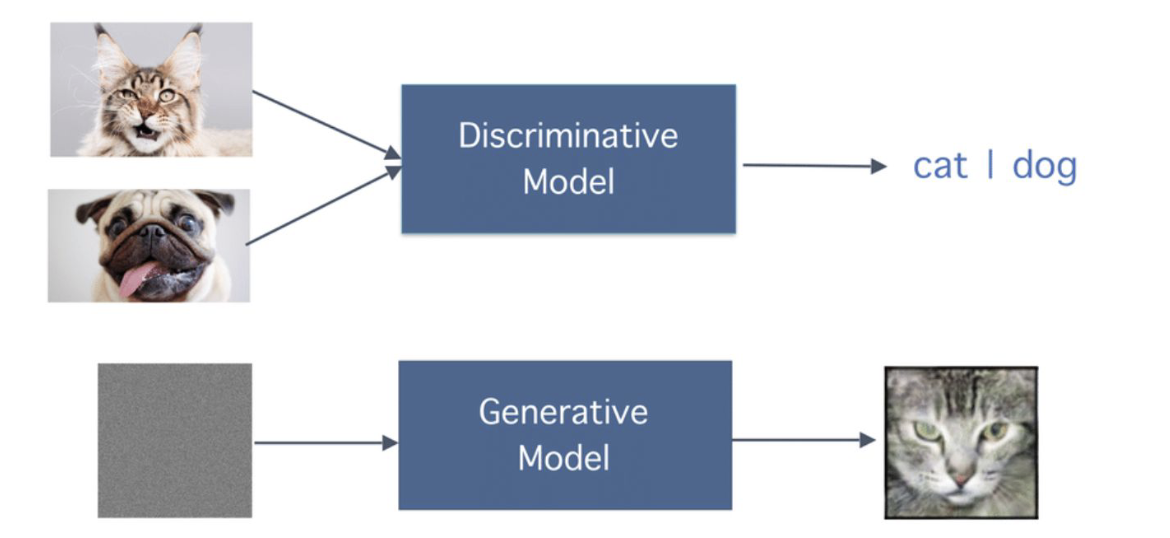
- Generative VS Discriminative
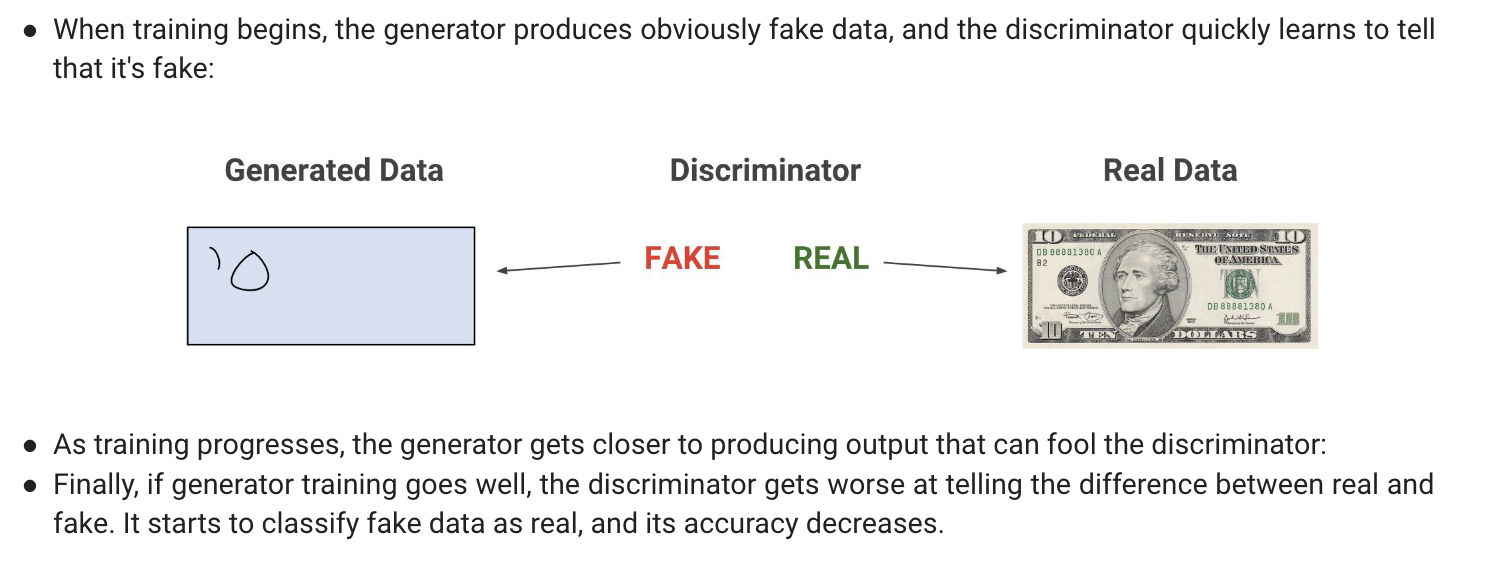
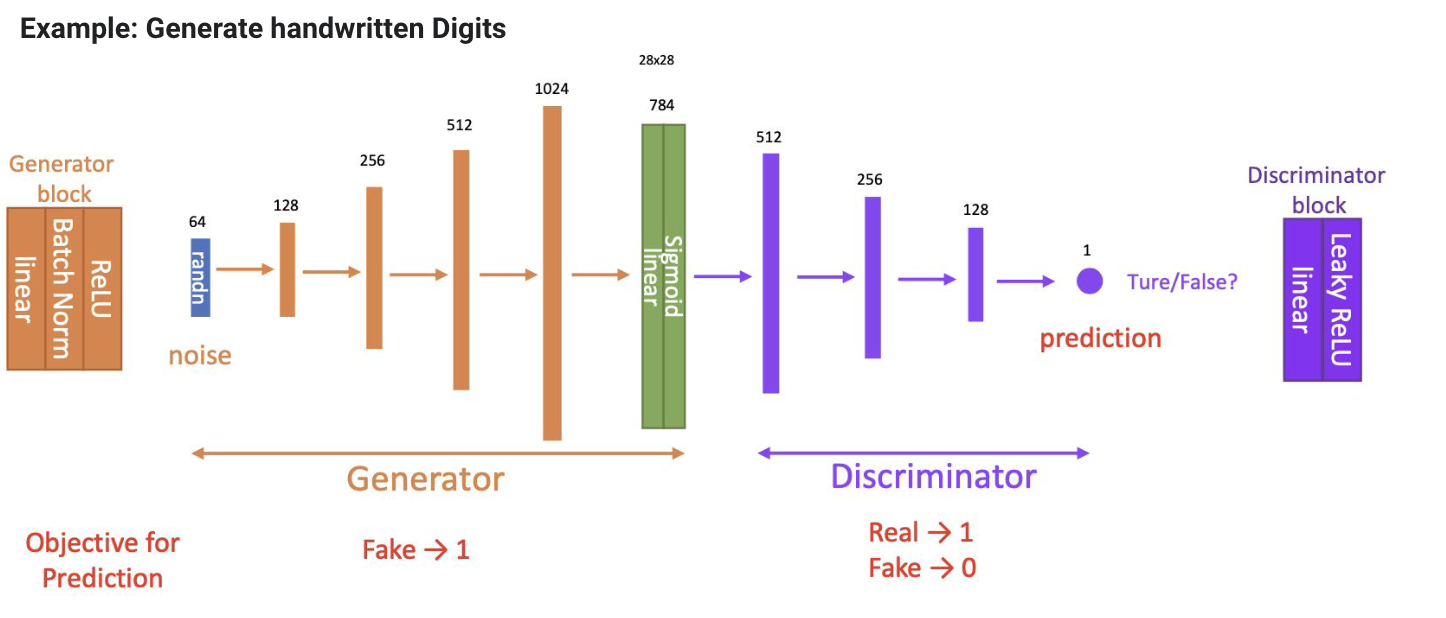
GAN (Generative Adversarial Network)


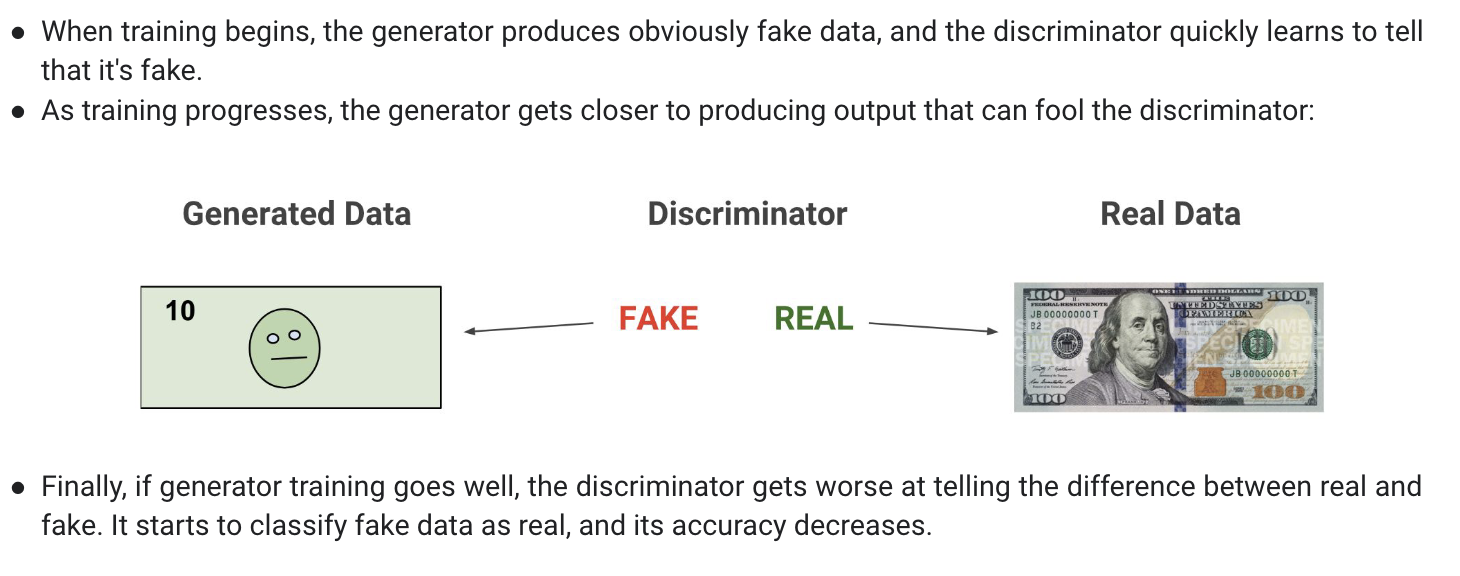 signal means the losss
signal means the losss
=> Discriminator : a classifier
=> Generator : Learning
-
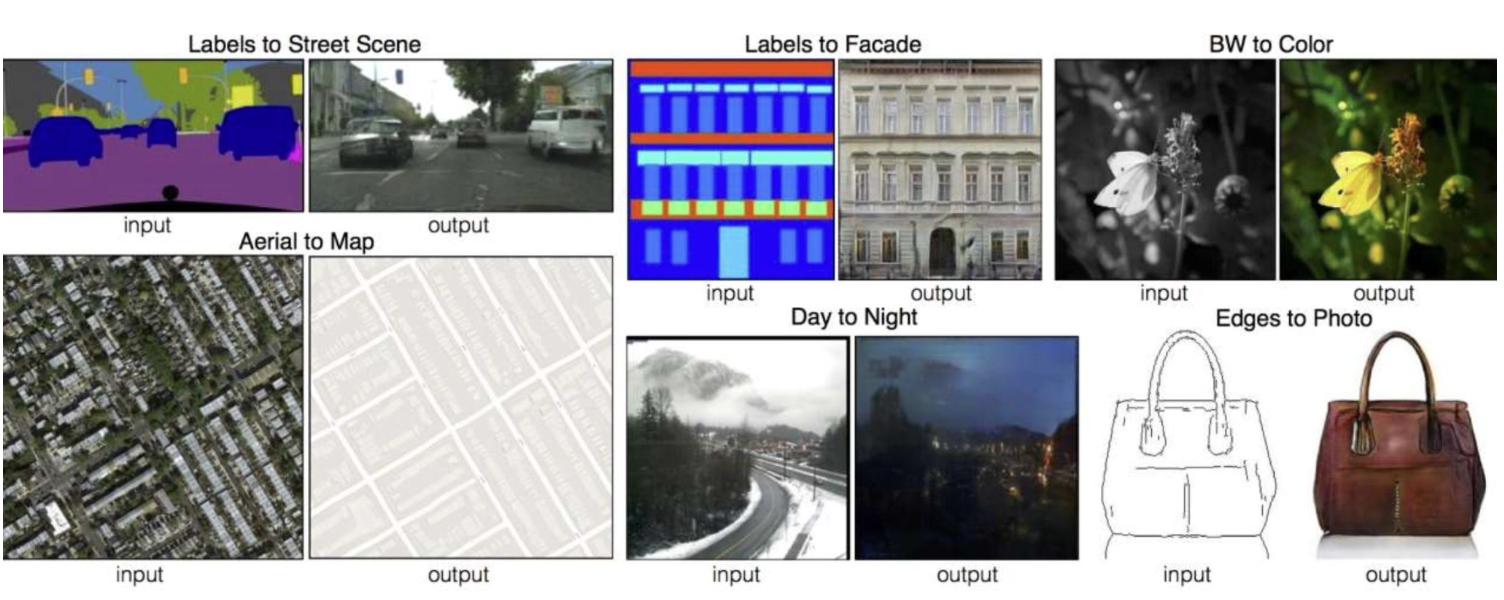
Image-to-Image
-
Head Models
-
Image Synthesis
$ -
Text-to-Image

-
Diffusion Model

-
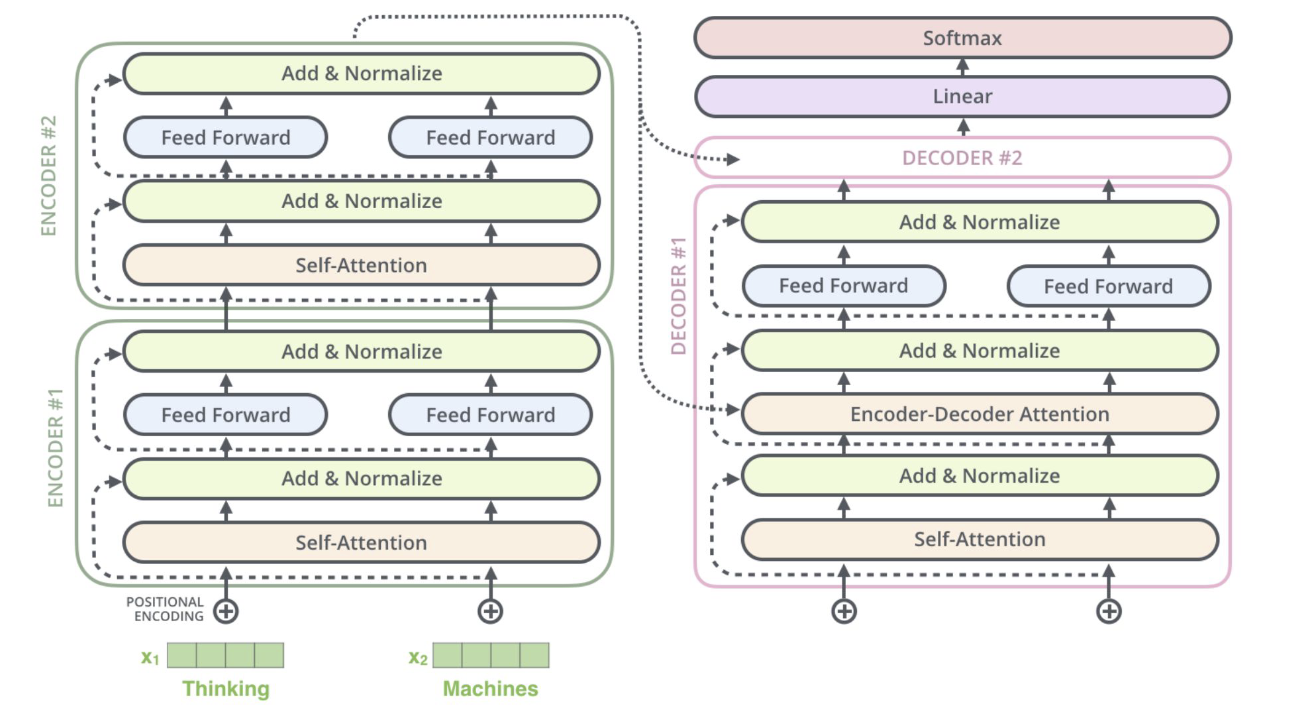
Transformer
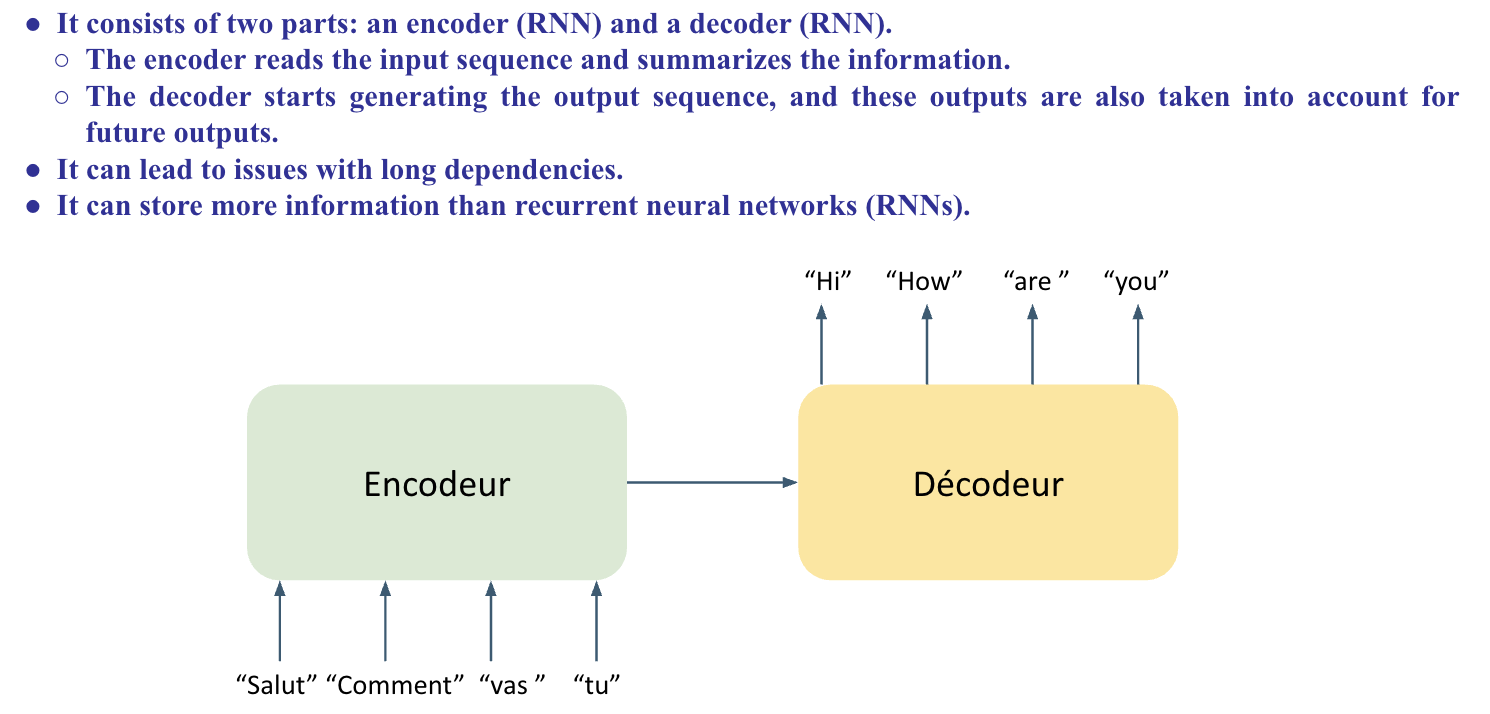
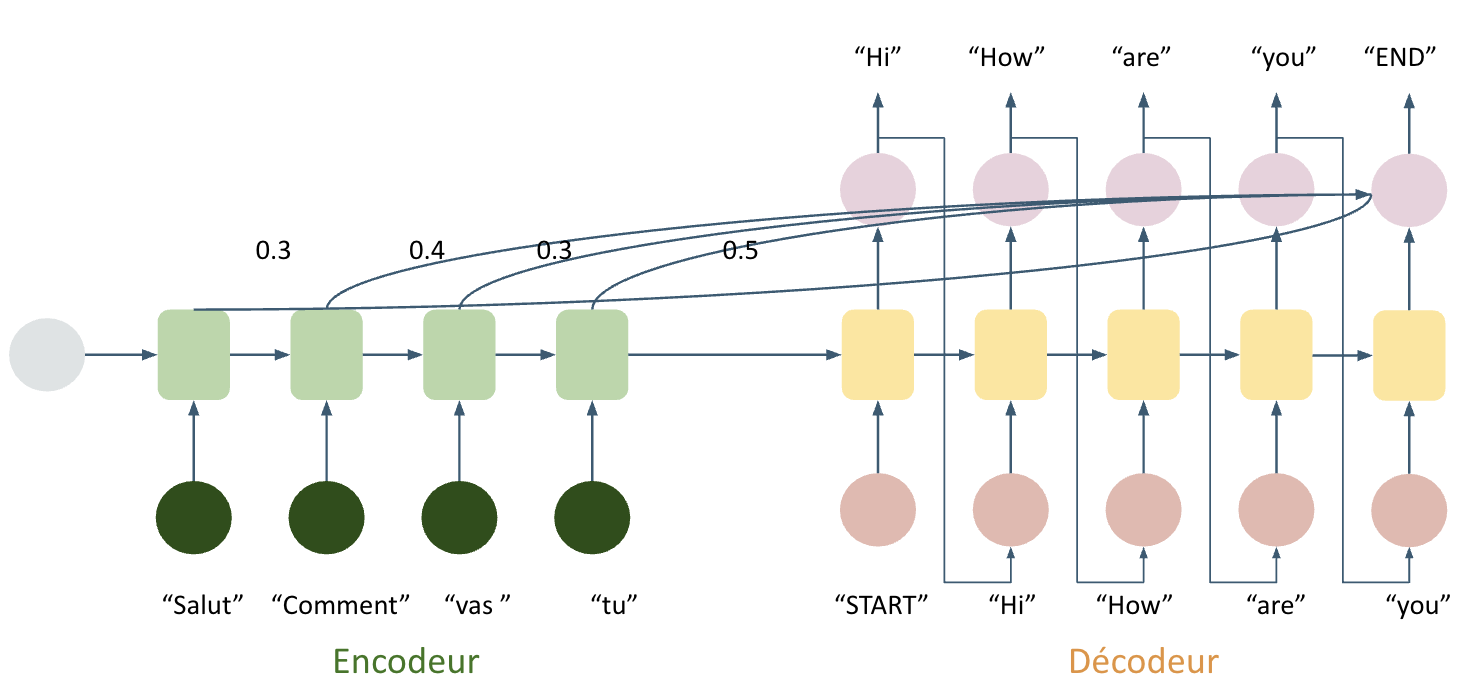
RNN (Recurrent Neural Network)
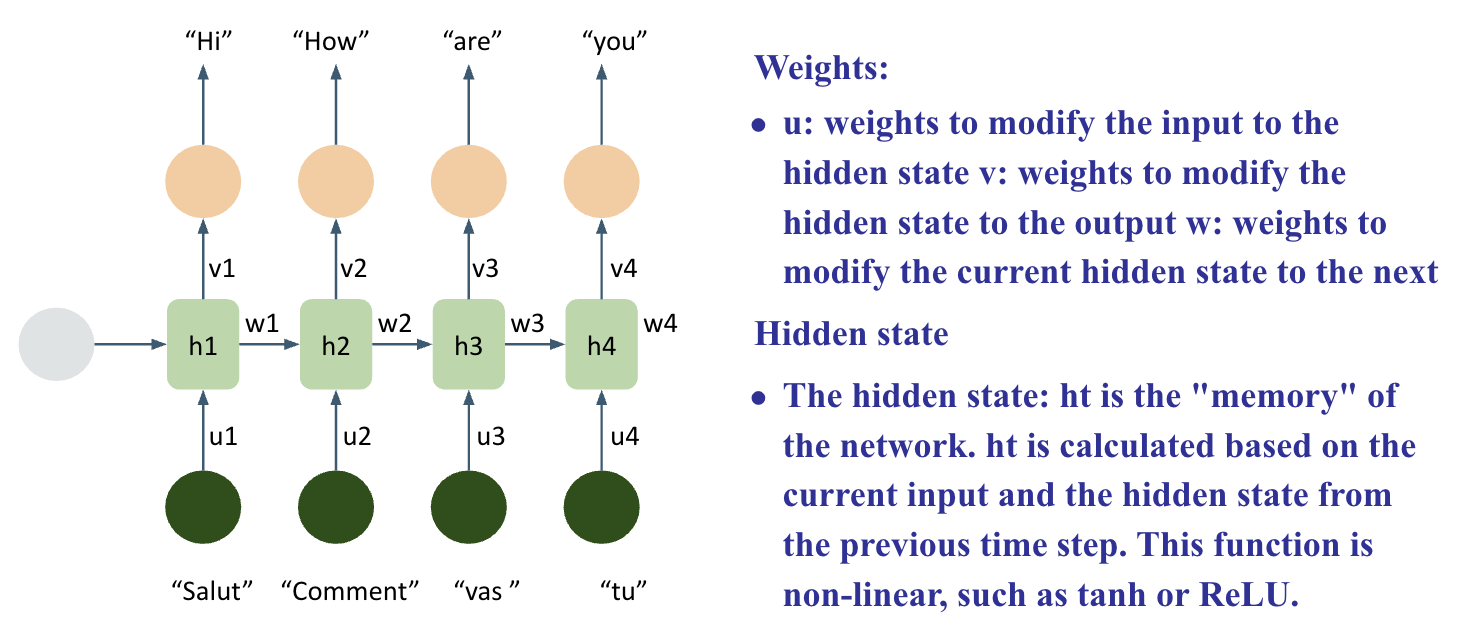
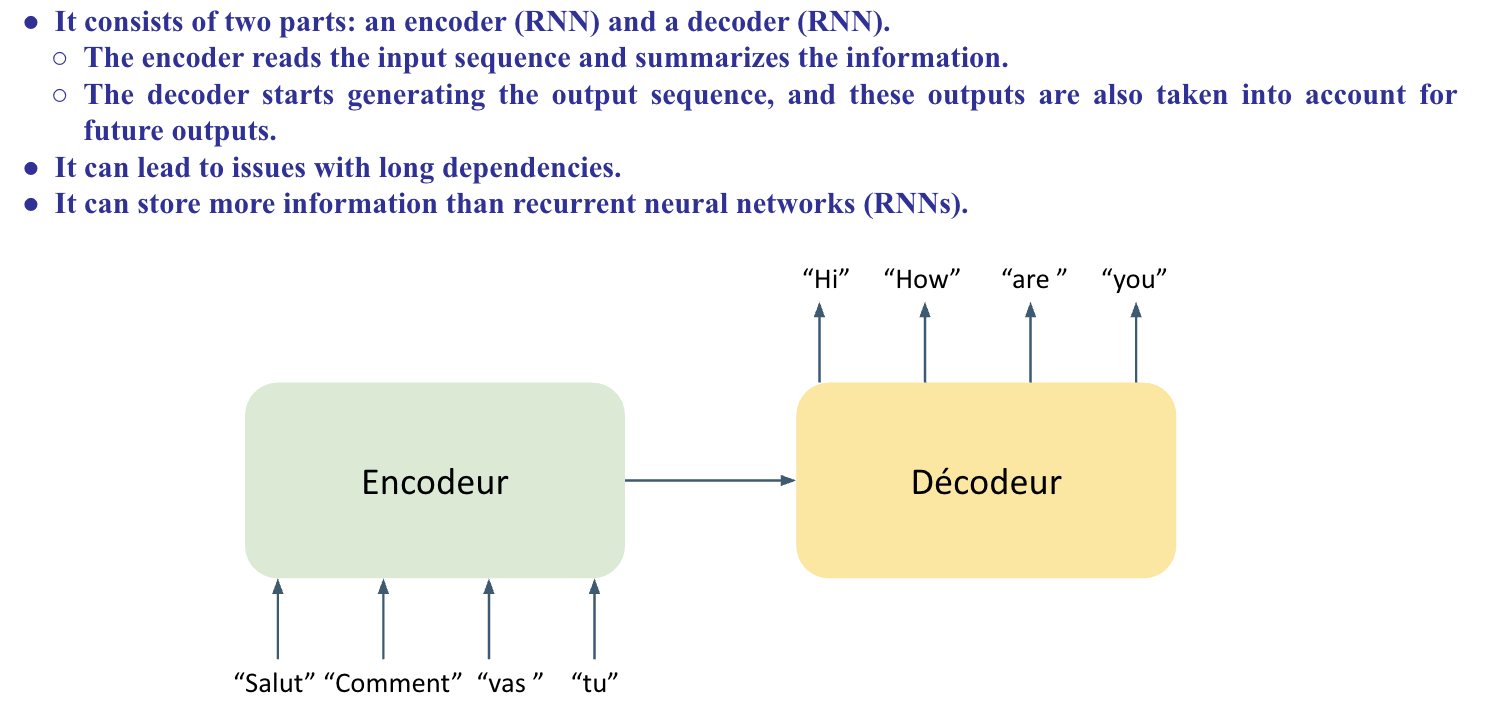
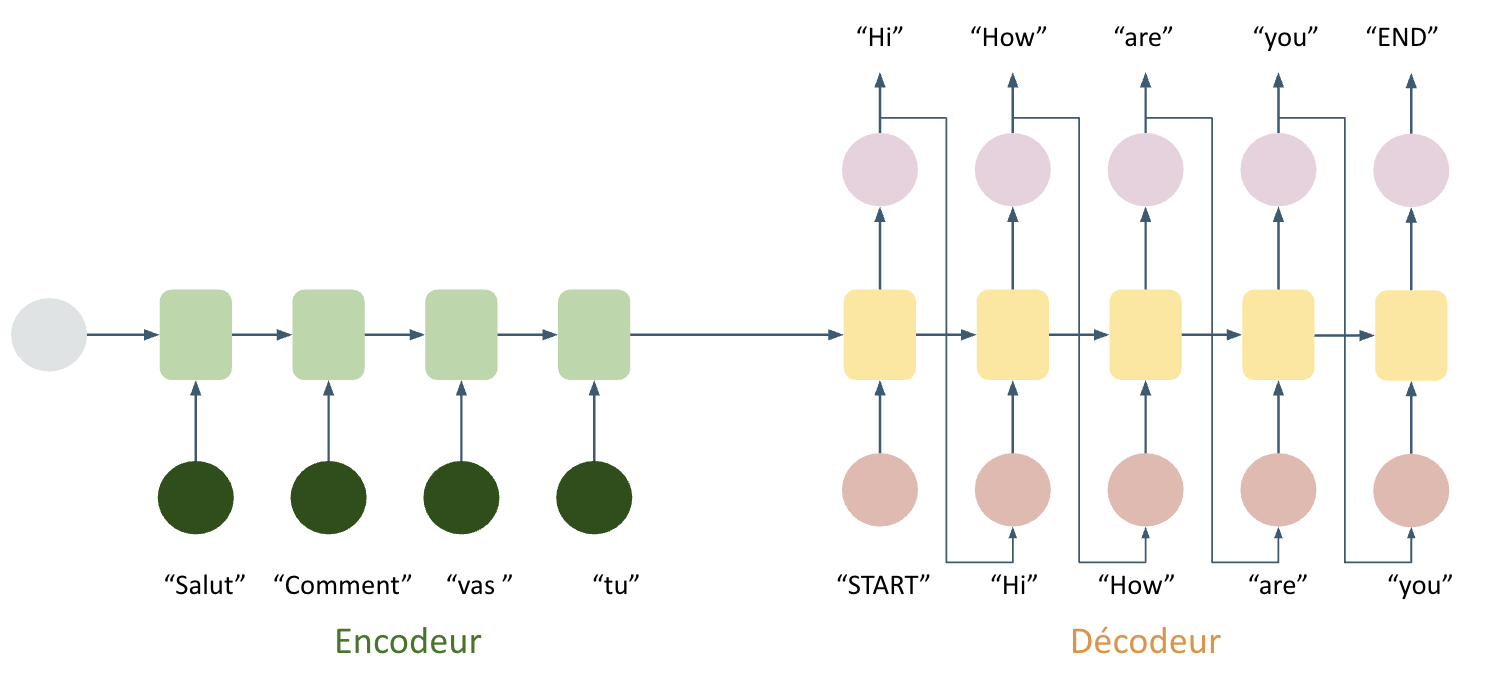
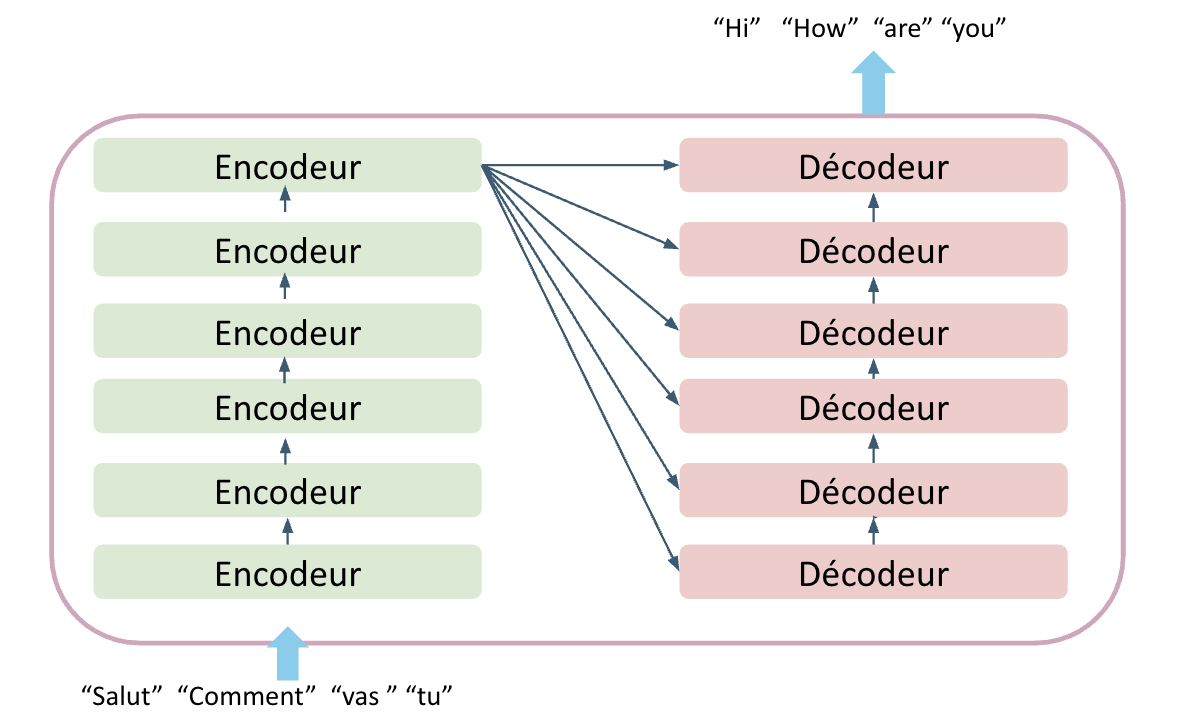
- Encoder-Decoder
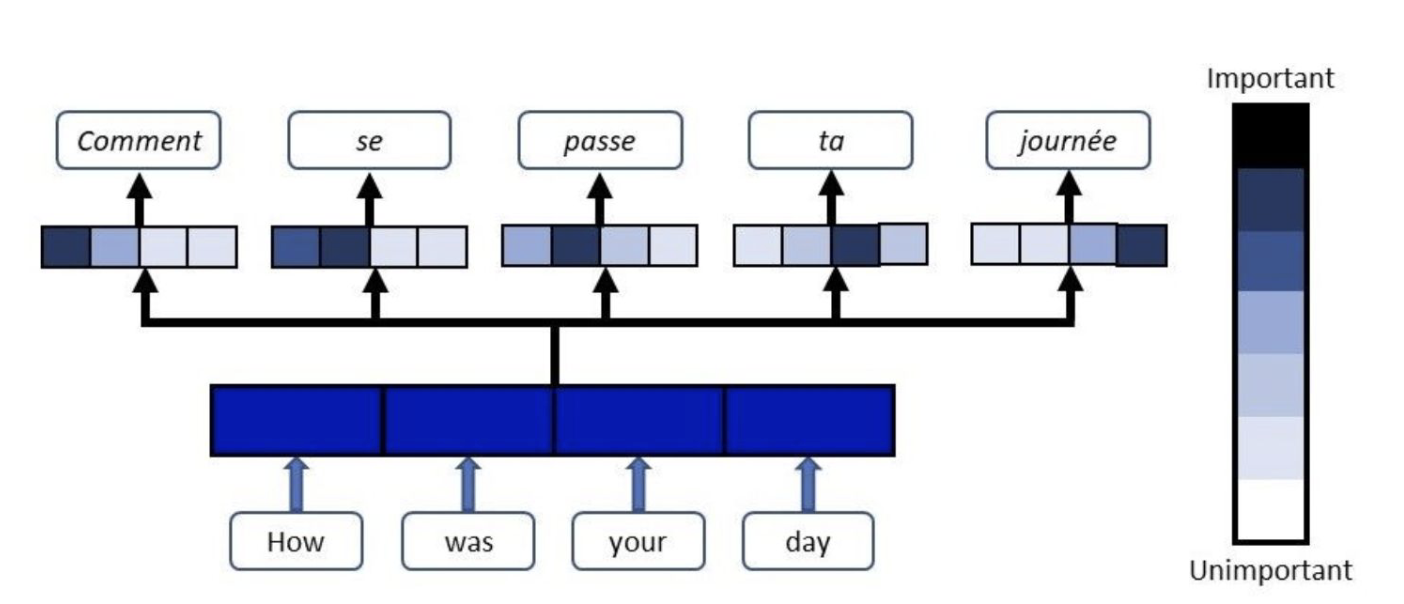
Attention
to decoder to flexibily use the most relevant parts of the input sequences
It combines weighted combinations of all the encoded input vectors, with the most relevant vectors being assigned the highest weights.
Attention provides a better measure of long-term dependencies and enables models to more efficiently memorize relevant information.
-
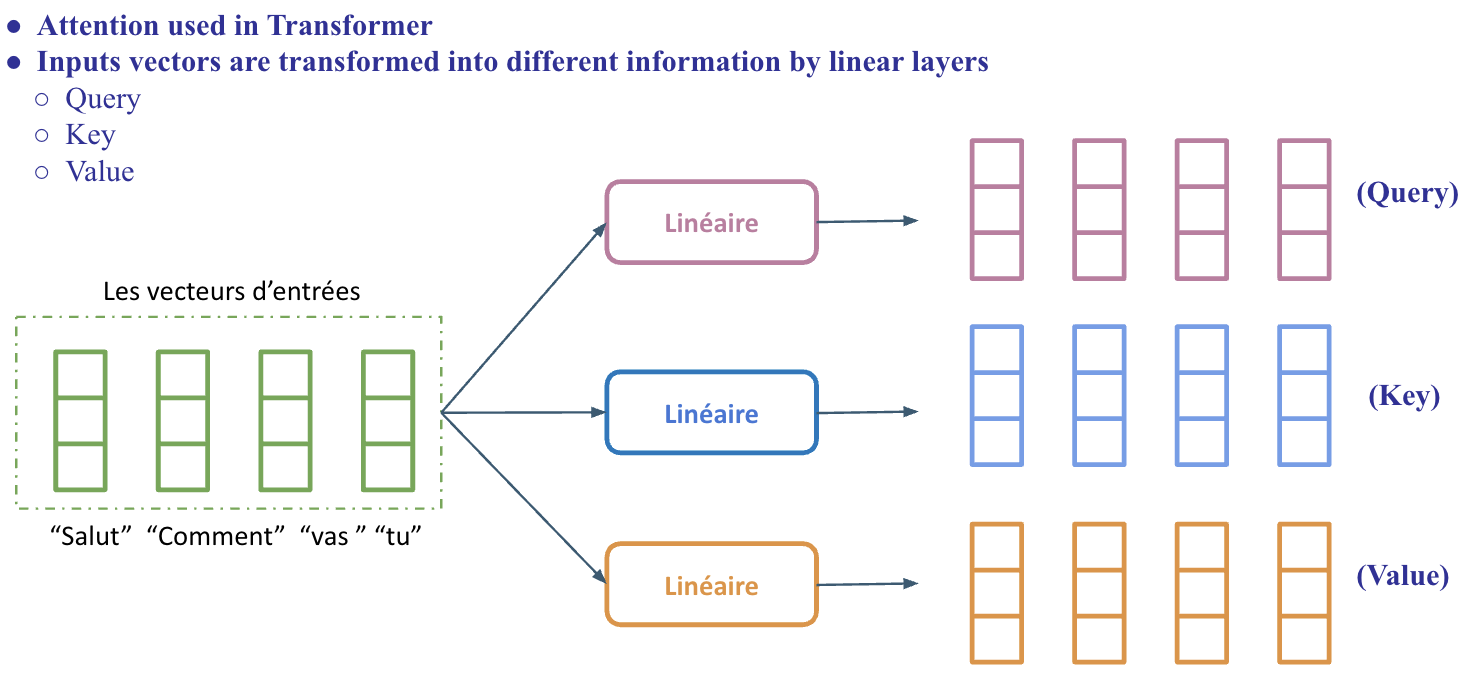
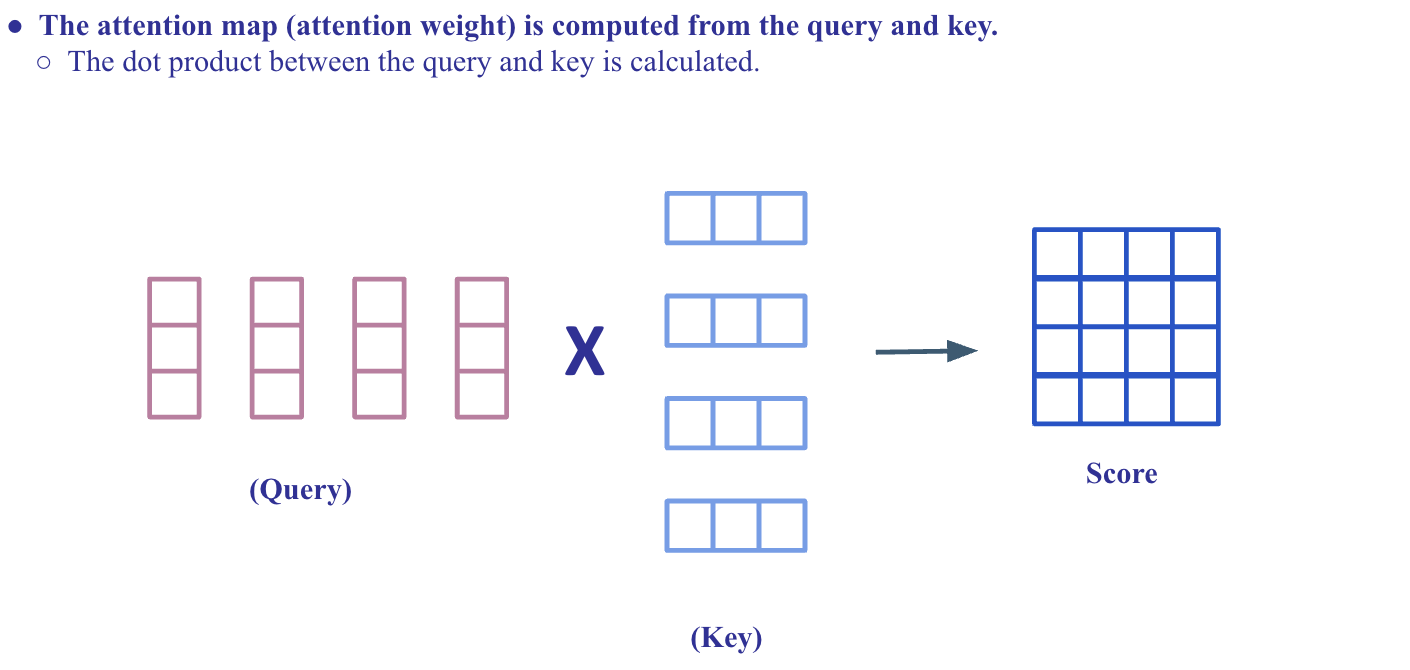
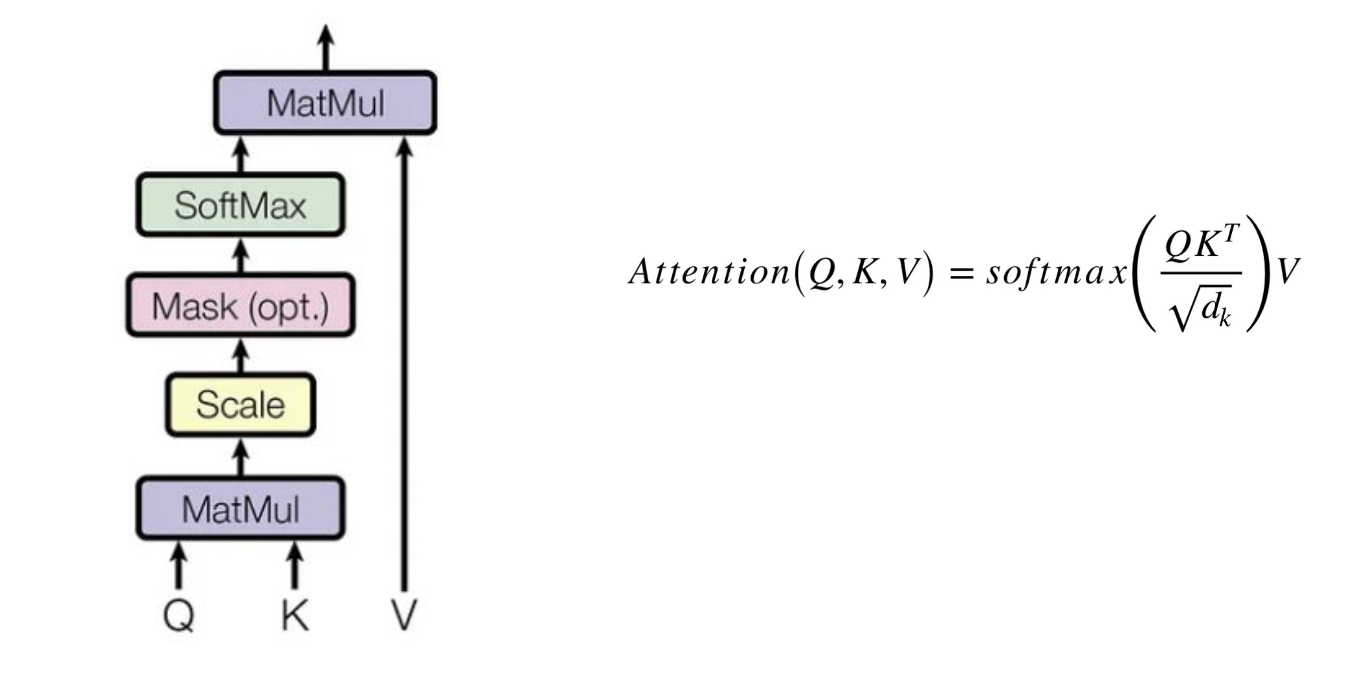
Scaled Dot-Product Attention
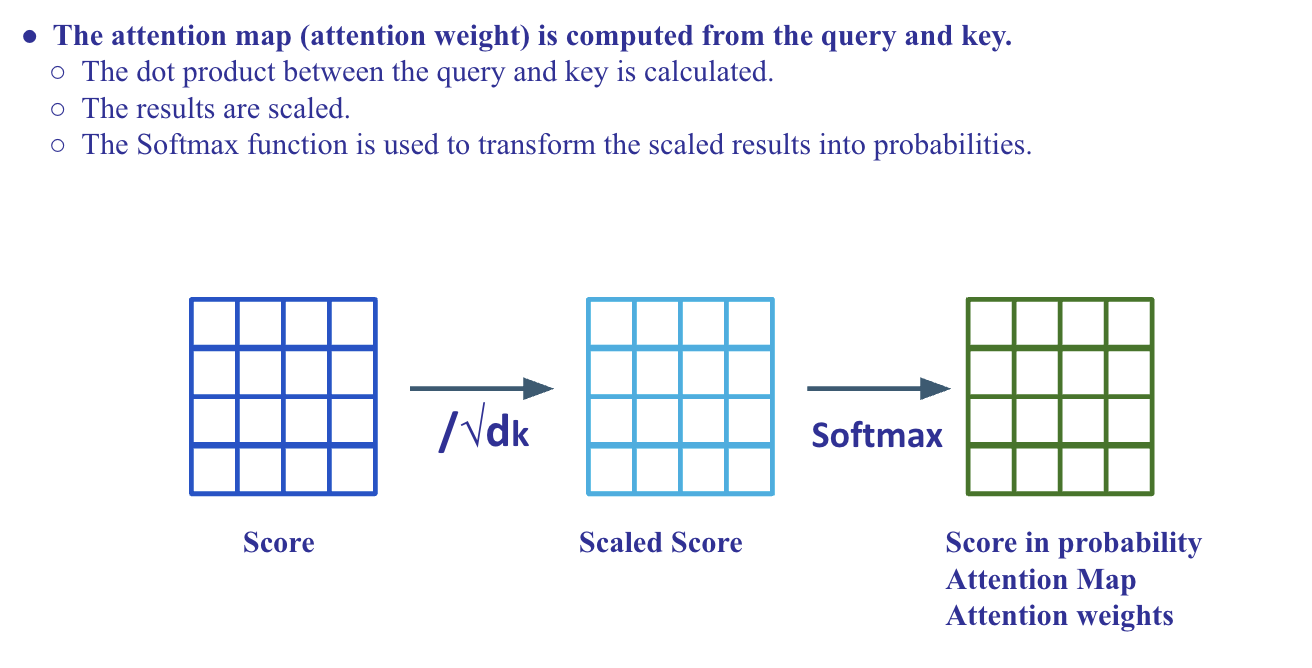
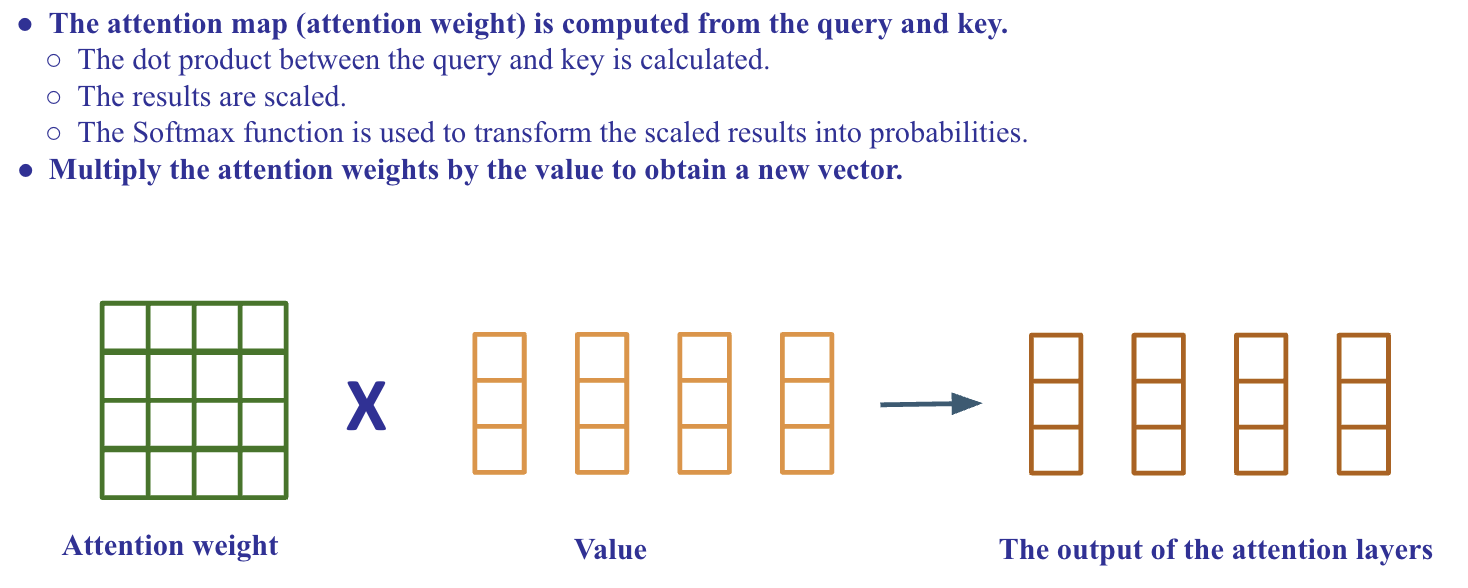
-
Self Dot-Product Attention
-
Self Attentio nand Cross Attention
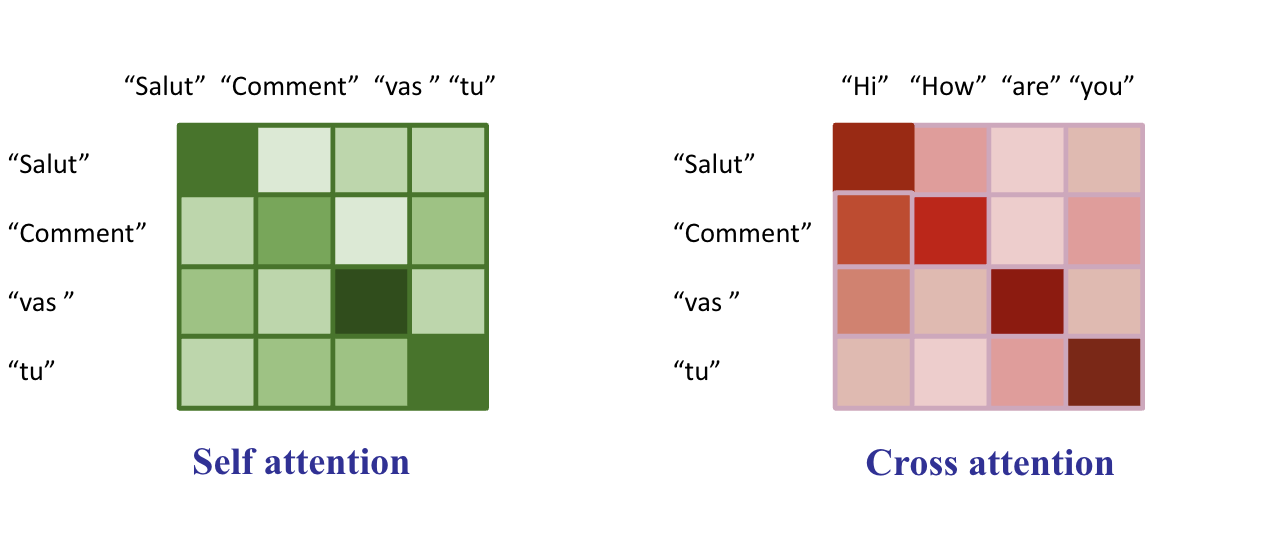
-
Multo-head attention
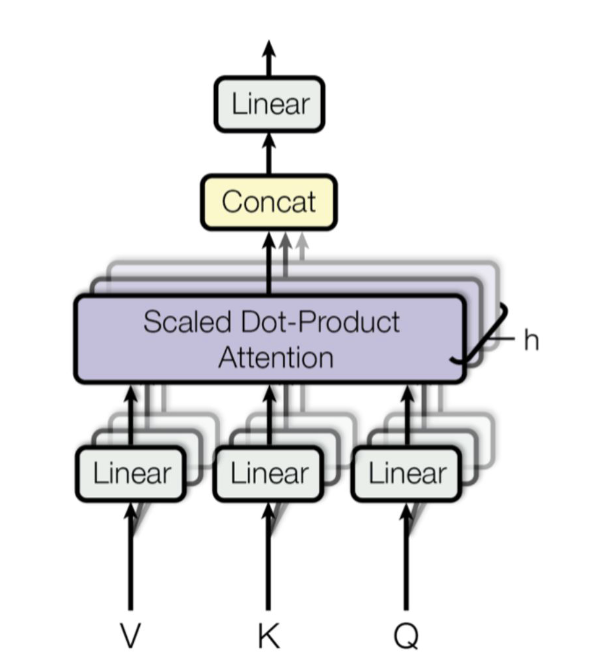
Transformer
cross attention은 encoder -> decoder 사이
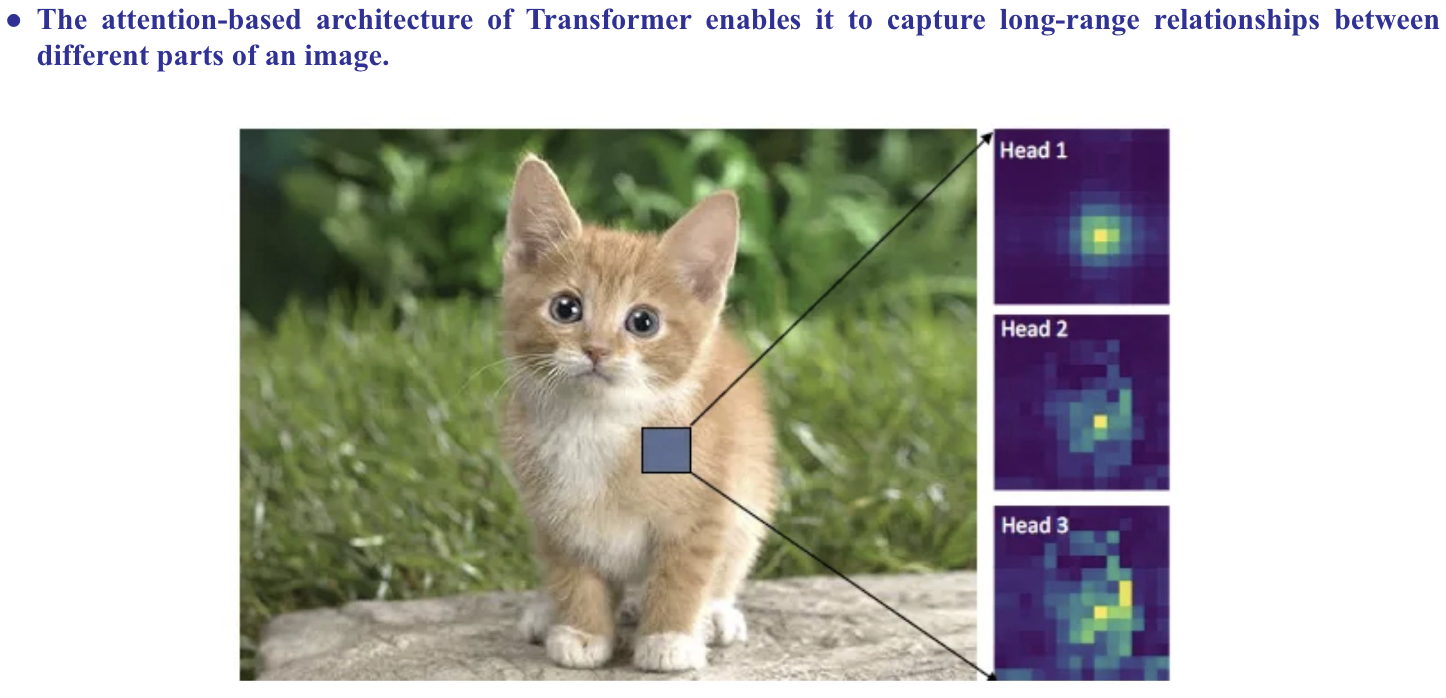
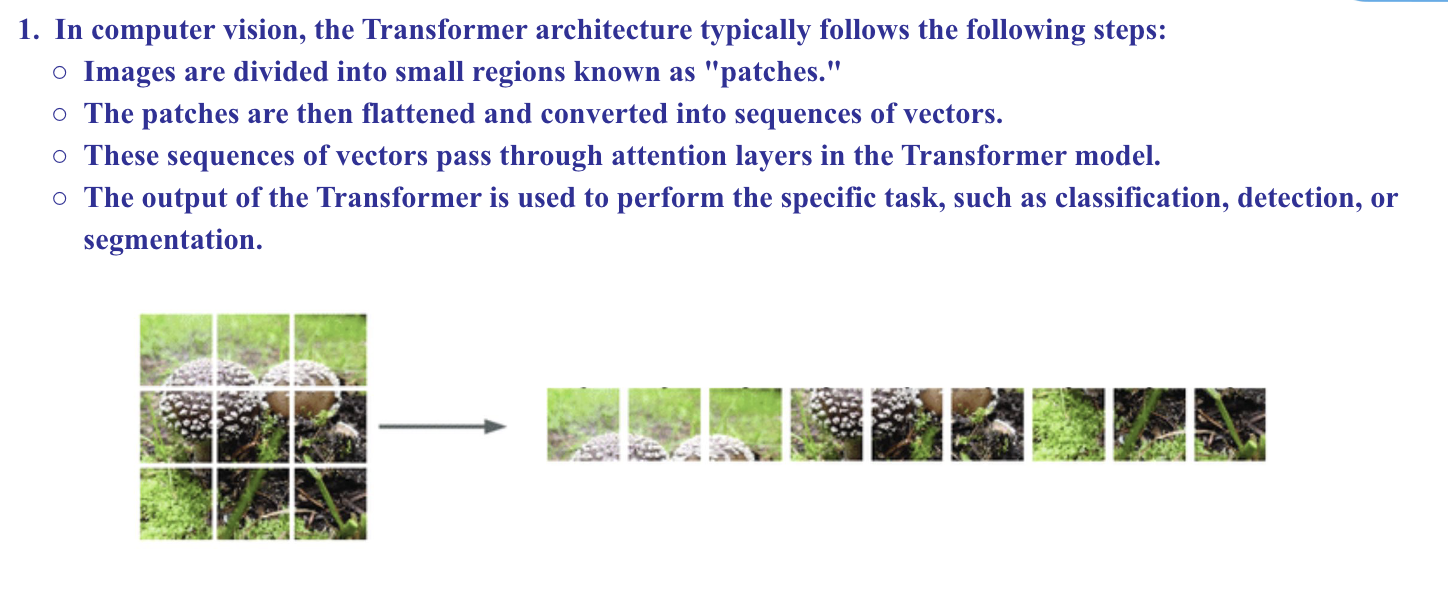
Vision Transformer (VIT)
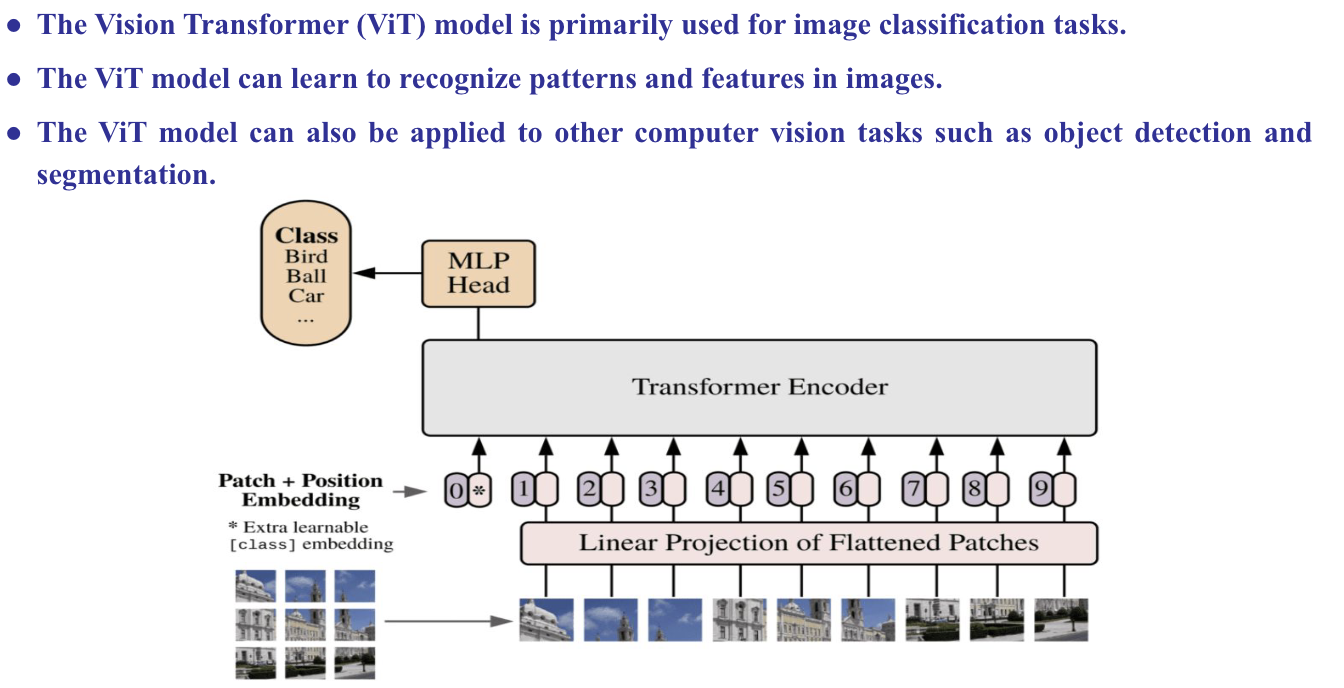
MLP: multi layer perception, fully connected
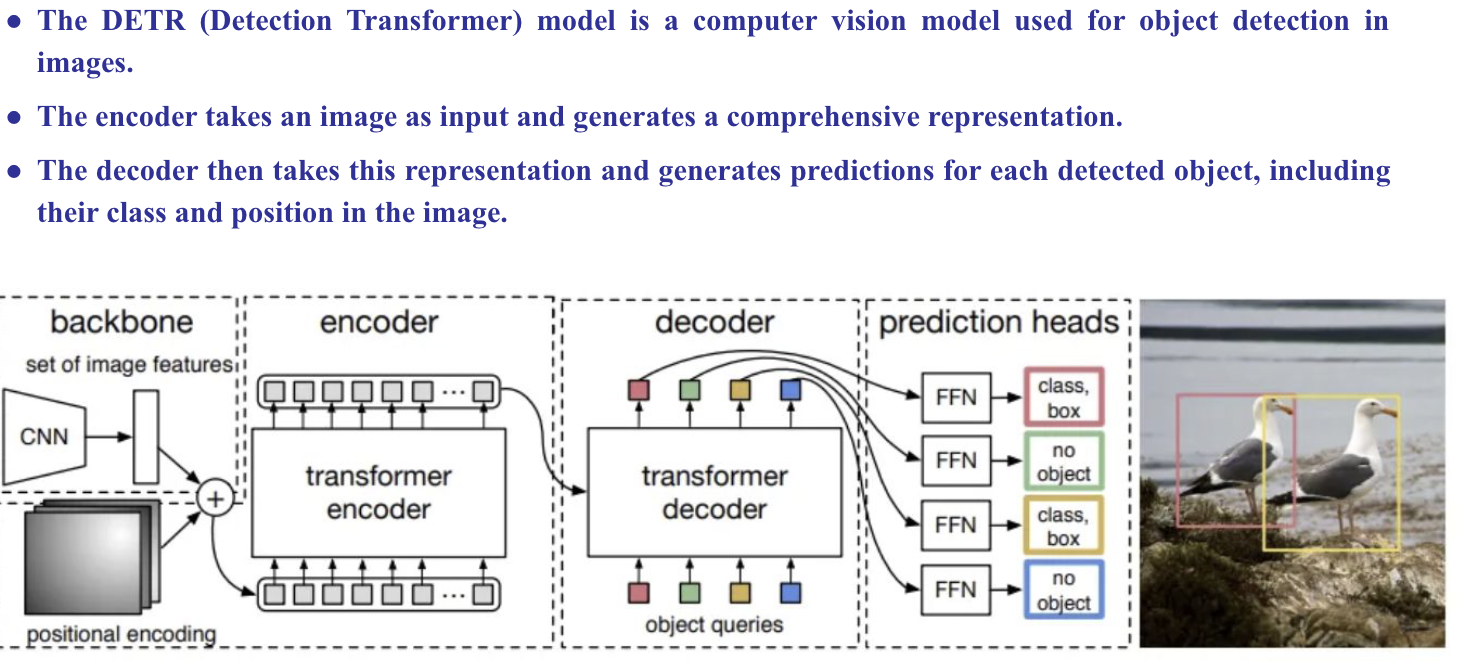
DETR (Dectection Transformer)
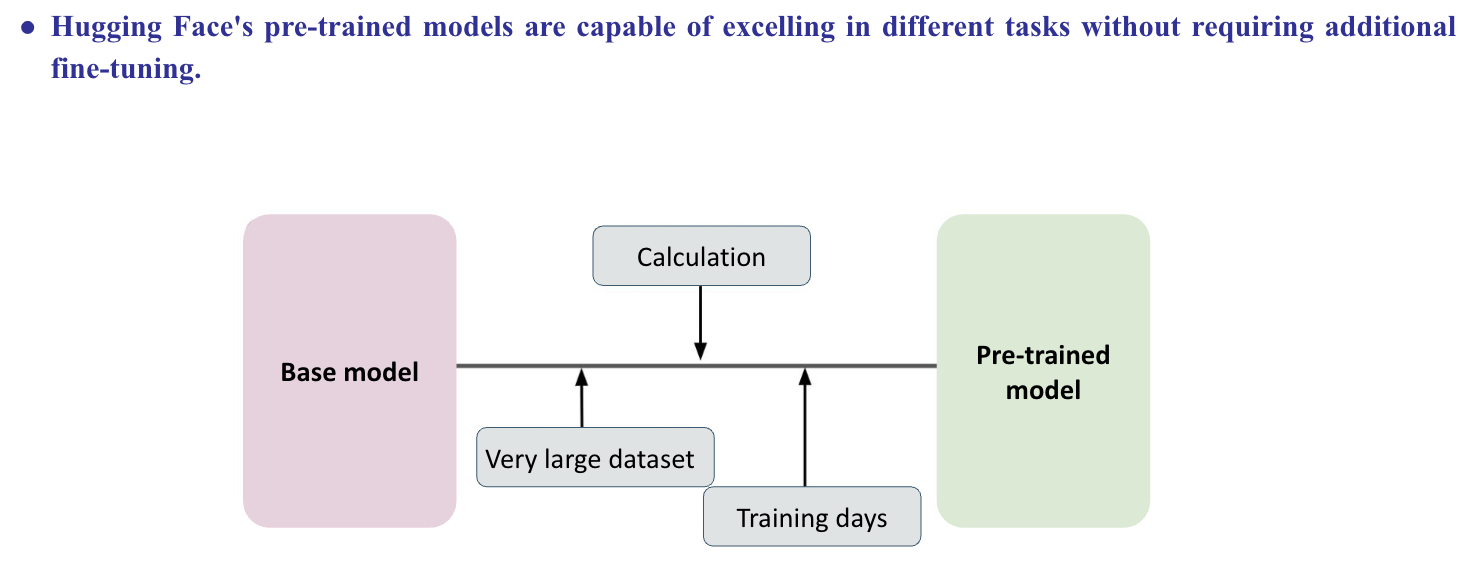
Hugging Face

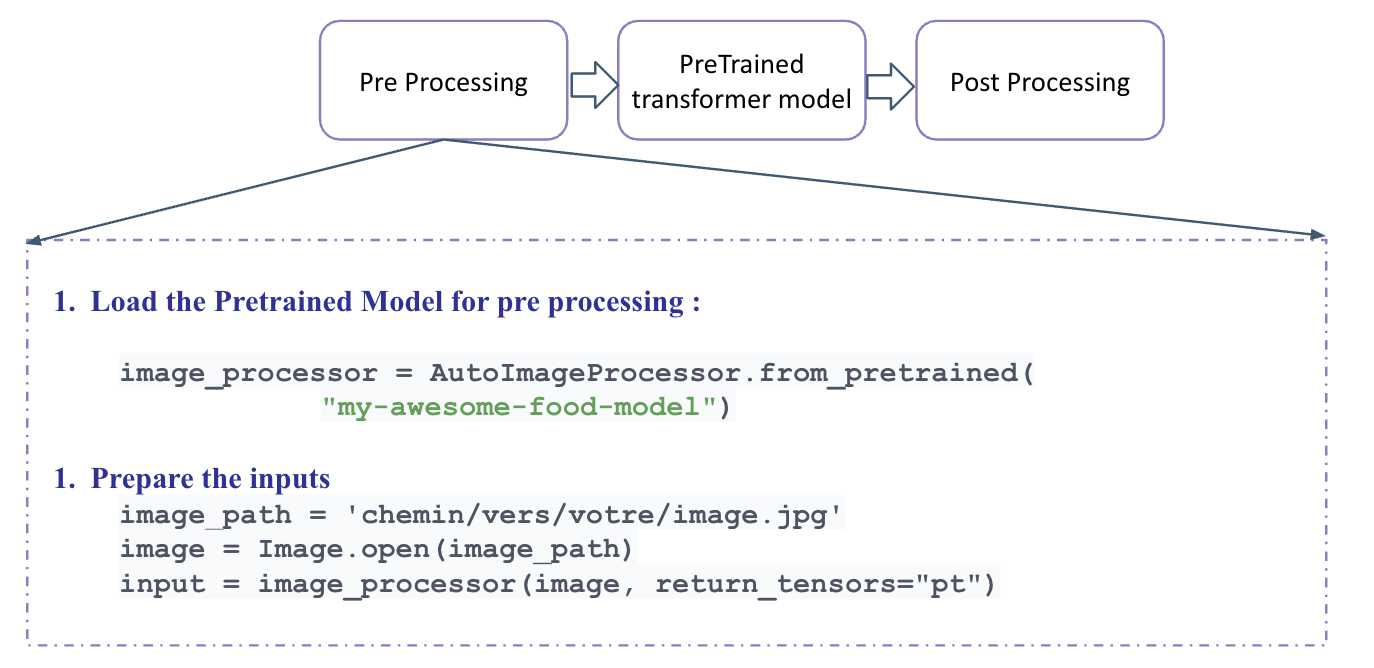
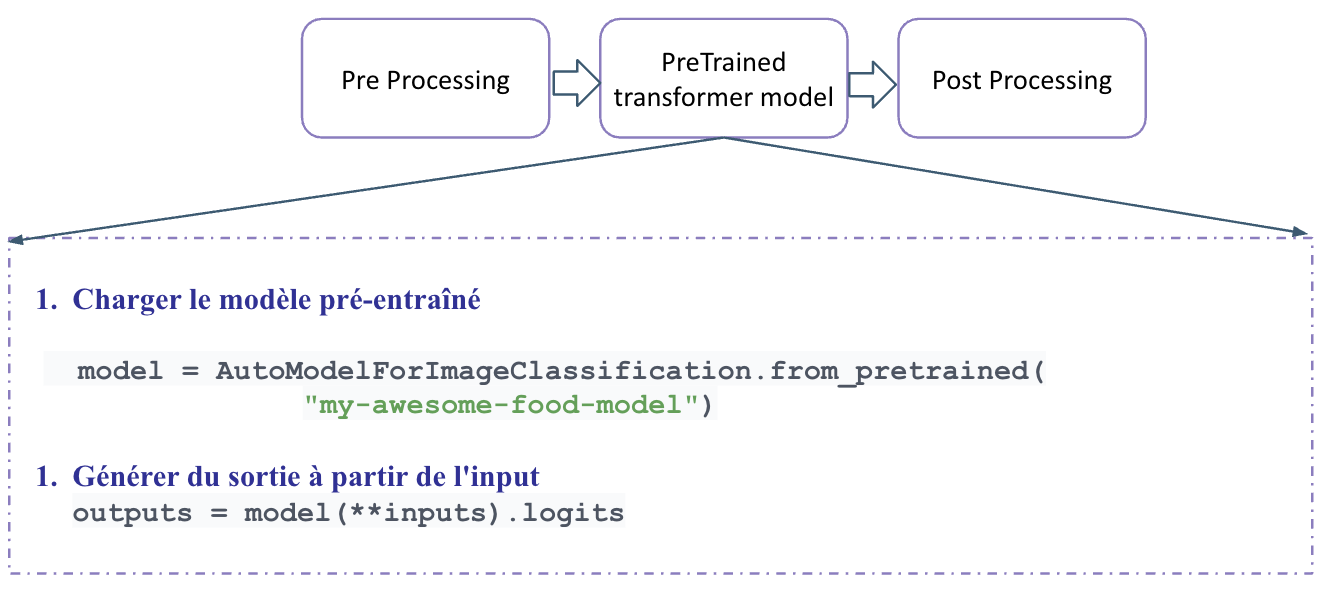
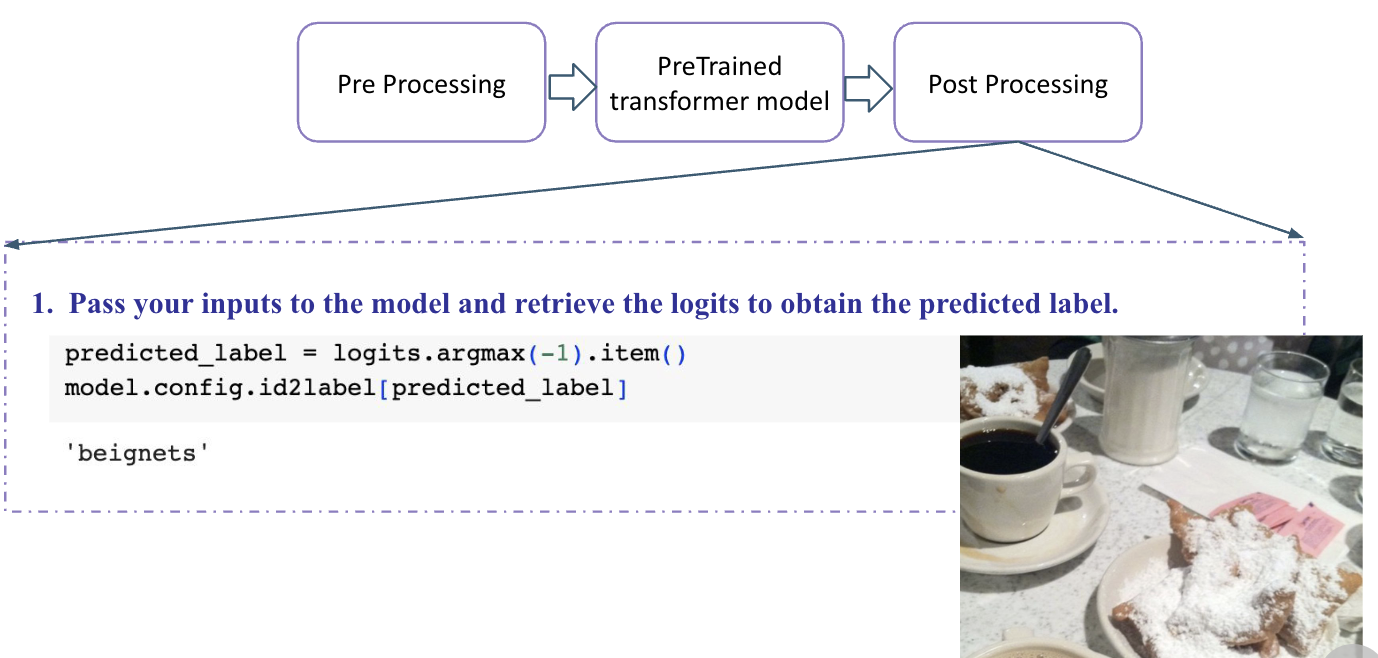
Stable Difusion for Image Generation
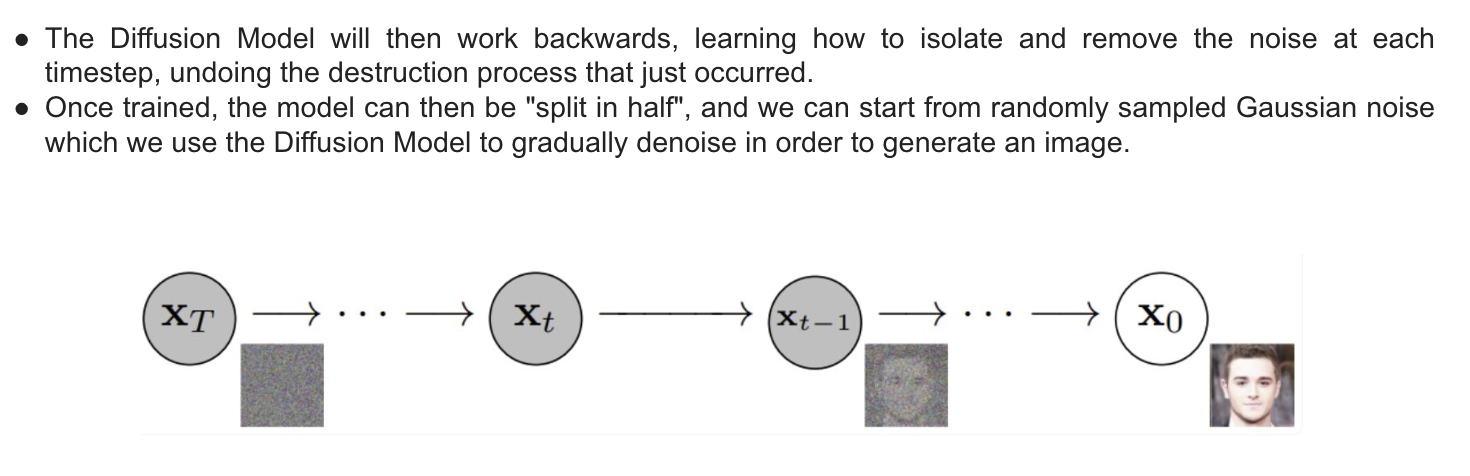
Diffusion Models

Stable Diffusion




-
Process
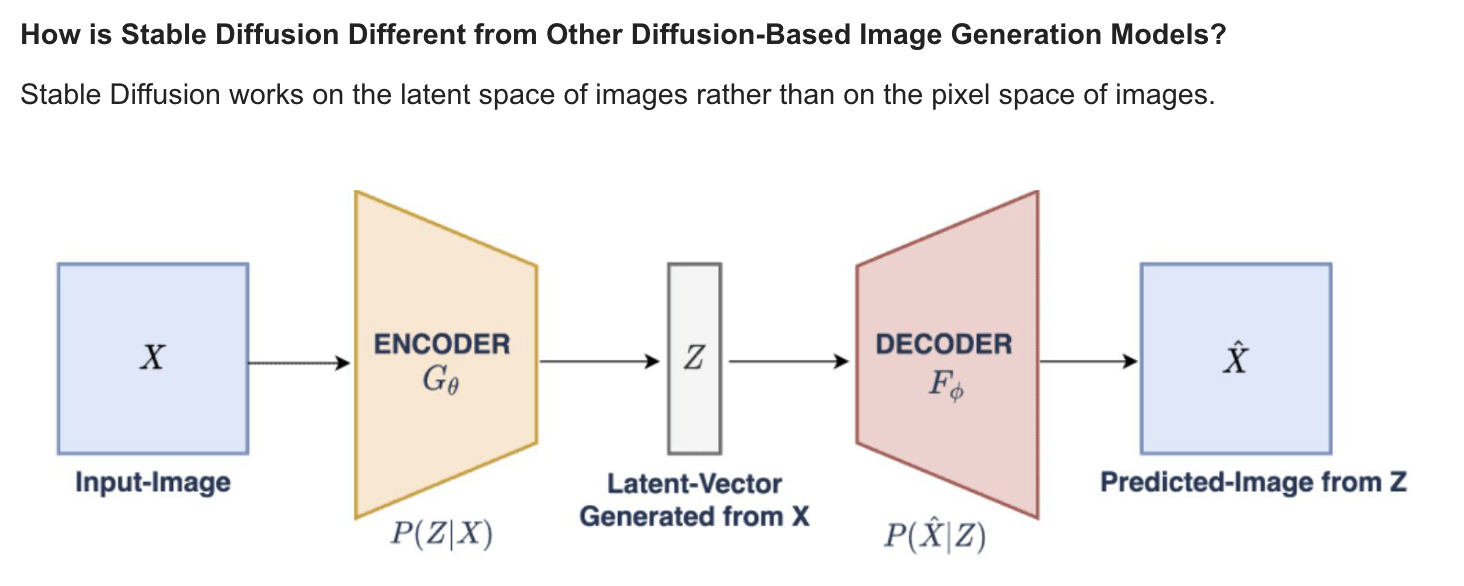
-
The Componet of Stable Diffusion
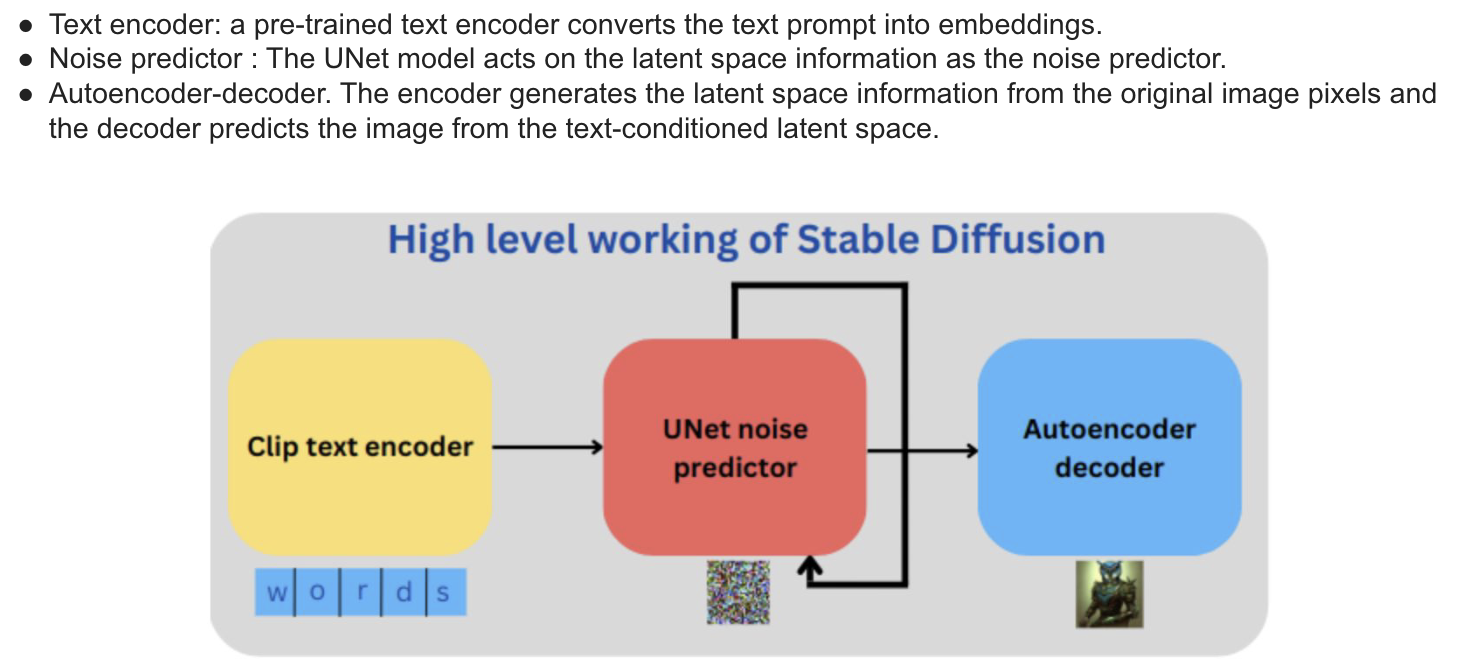
다른 모델들과 다르게 stabel diffusion은 latent space를 밖으로 꺼내서
-
Text encoder

-
The UNet Noise Predictor
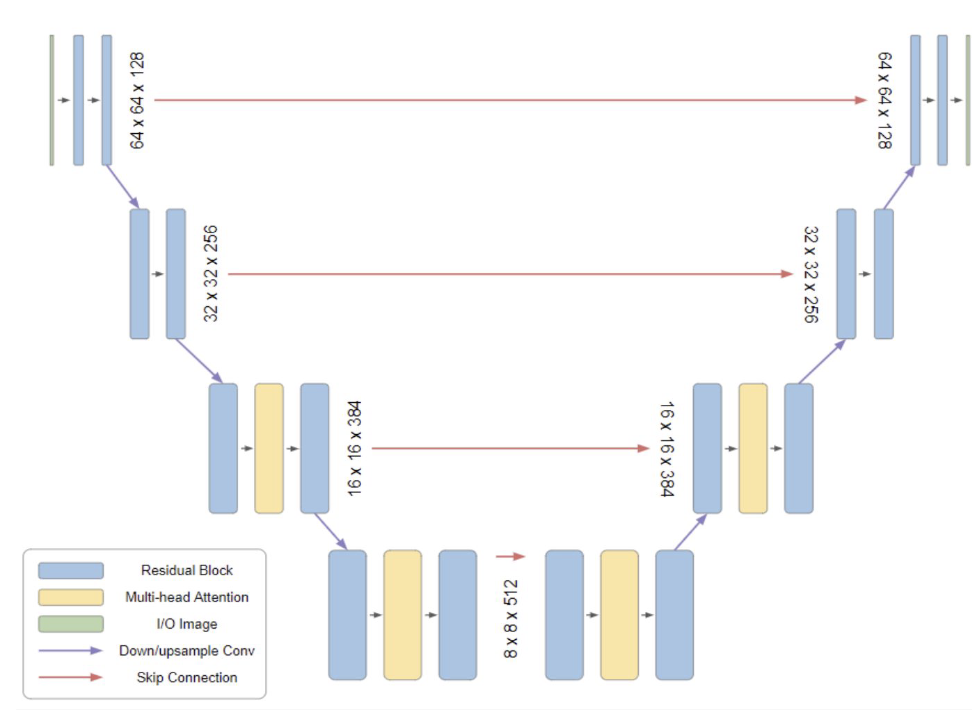
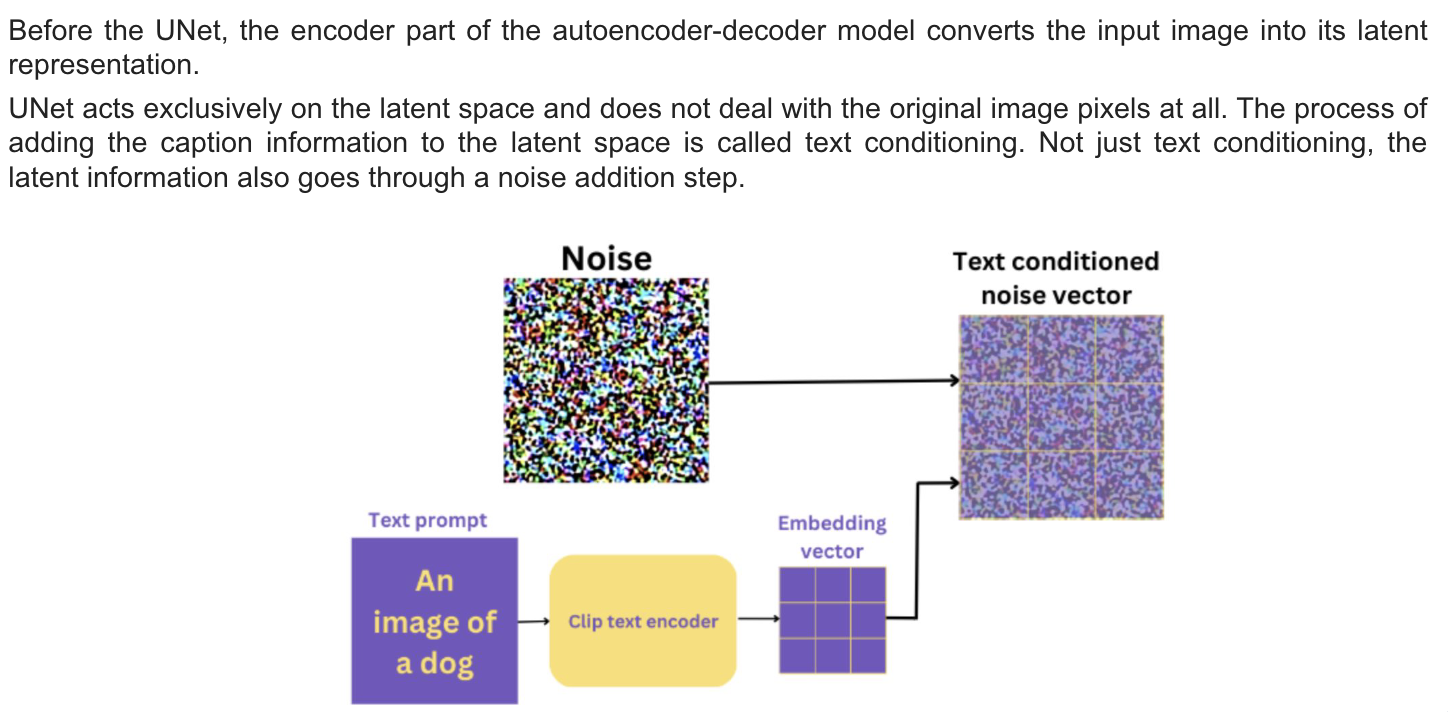
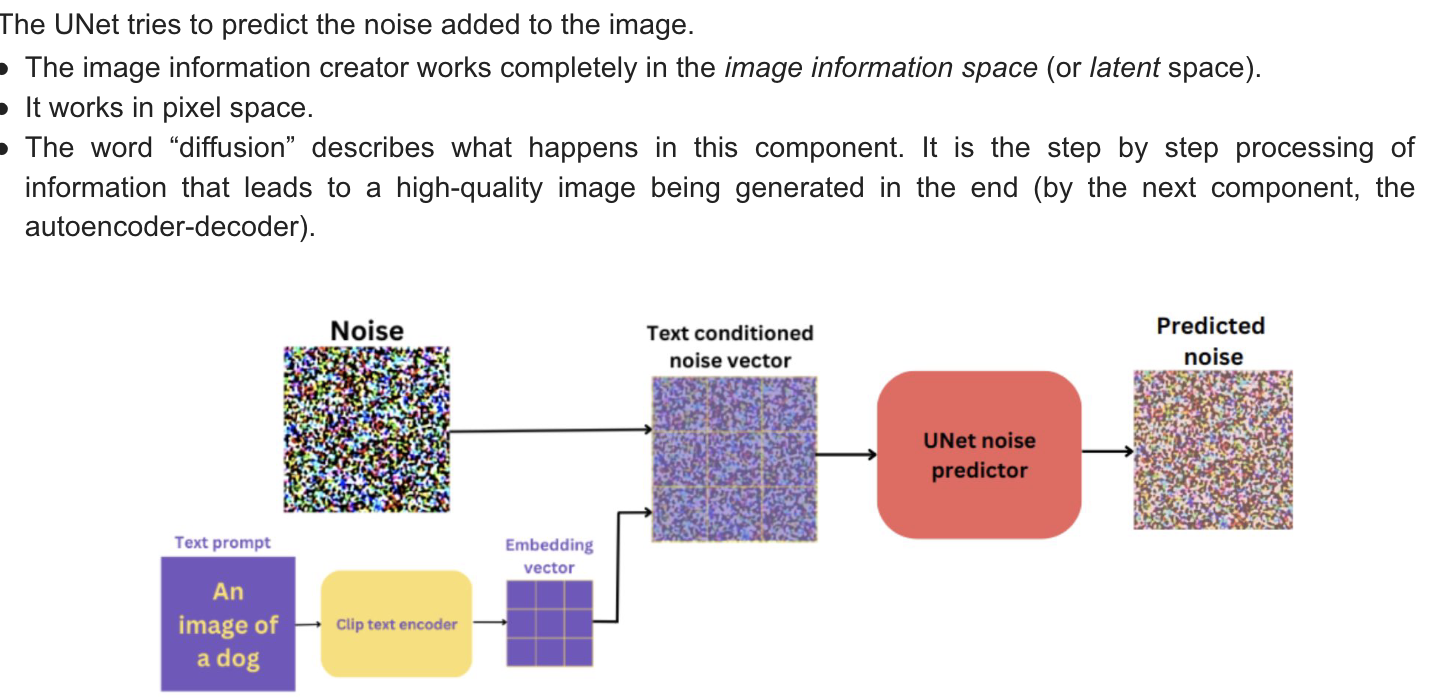
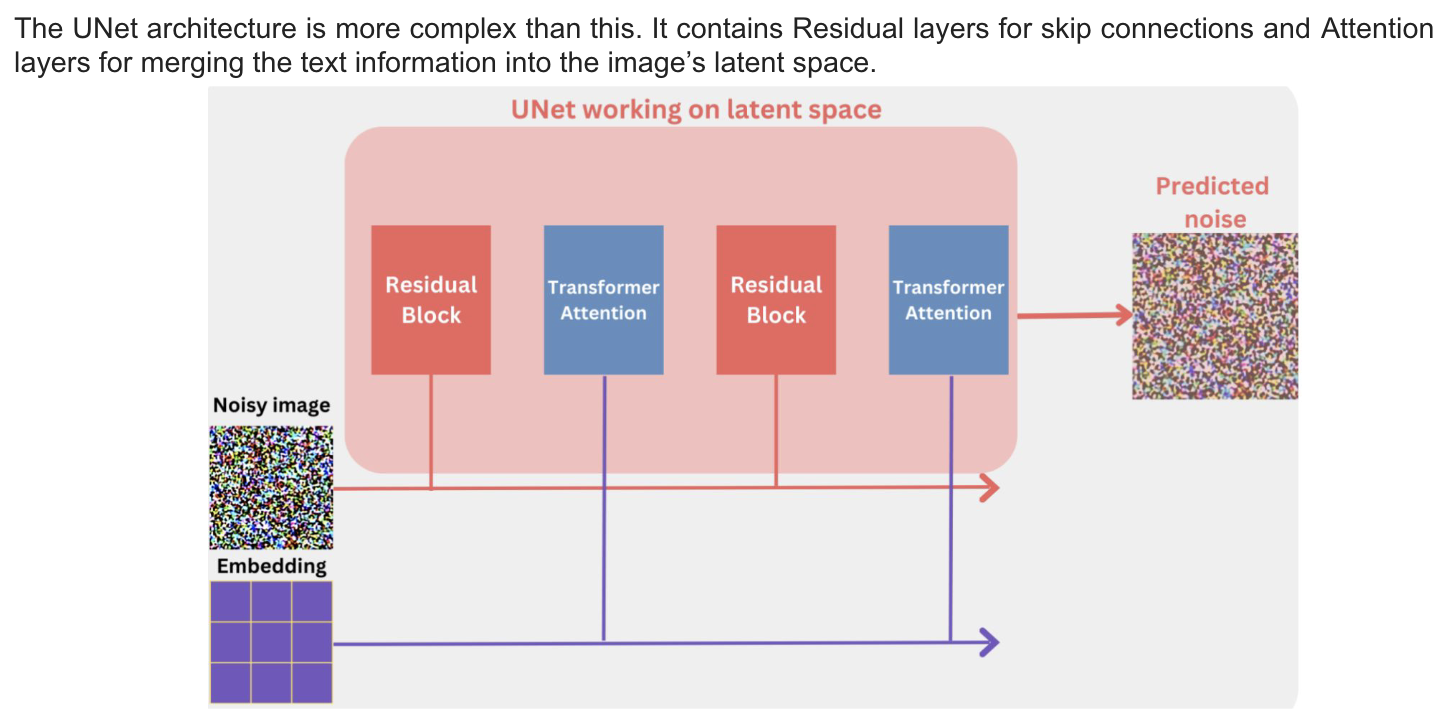
-
The Auto Enscoder-Decoder Model

-
Training Stable diffusion

-
Stable diffusion Inference
( Inference: 이미 모델을 가지고 있음. training을 이미 끝냄 )

-
What is Diffusionn Anyway?

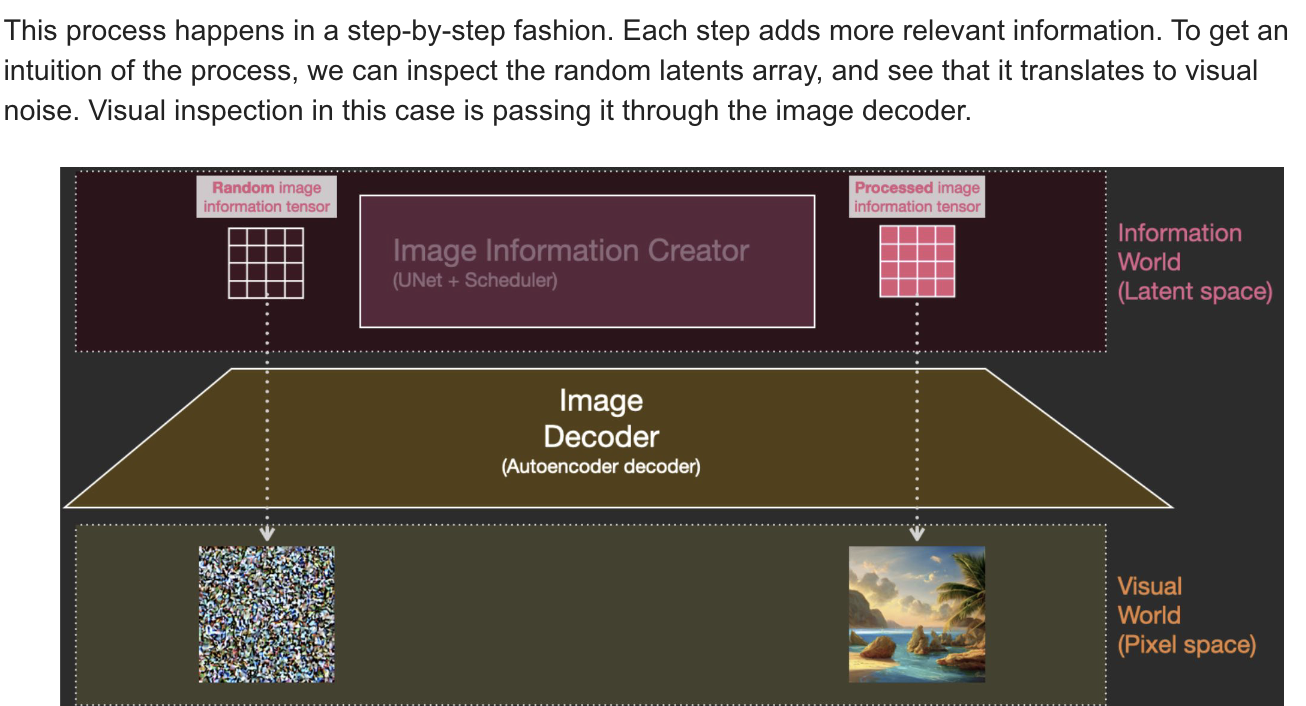
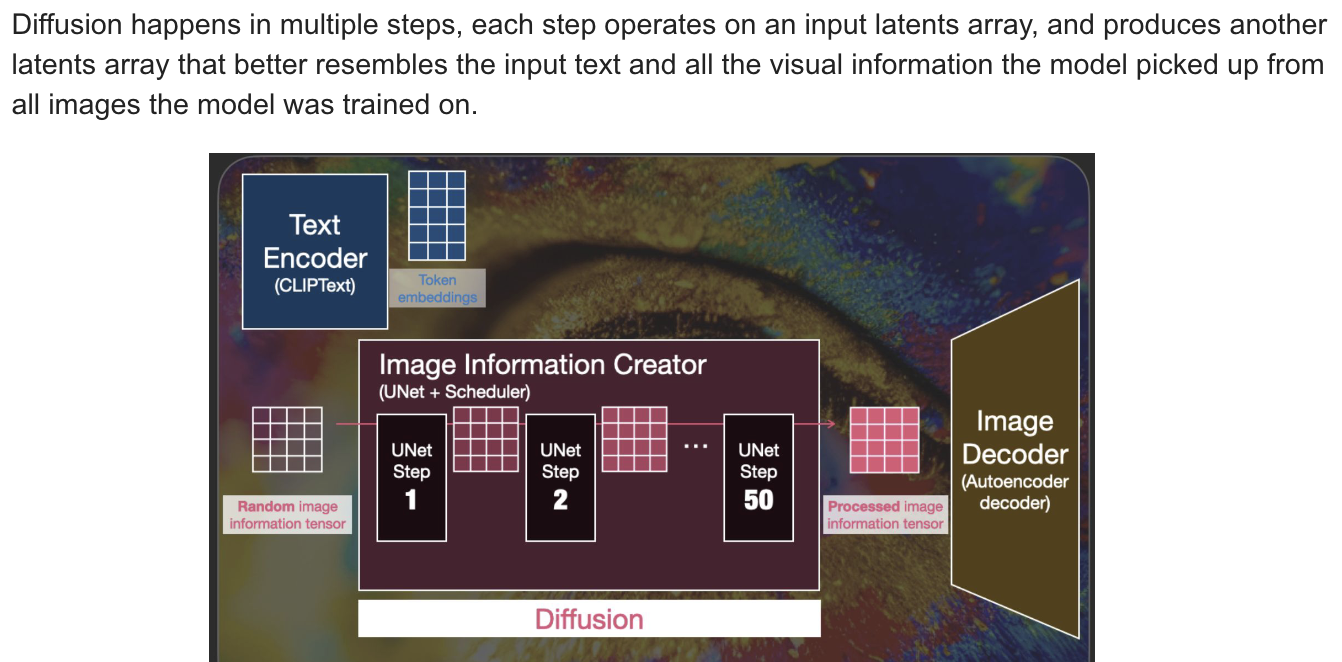
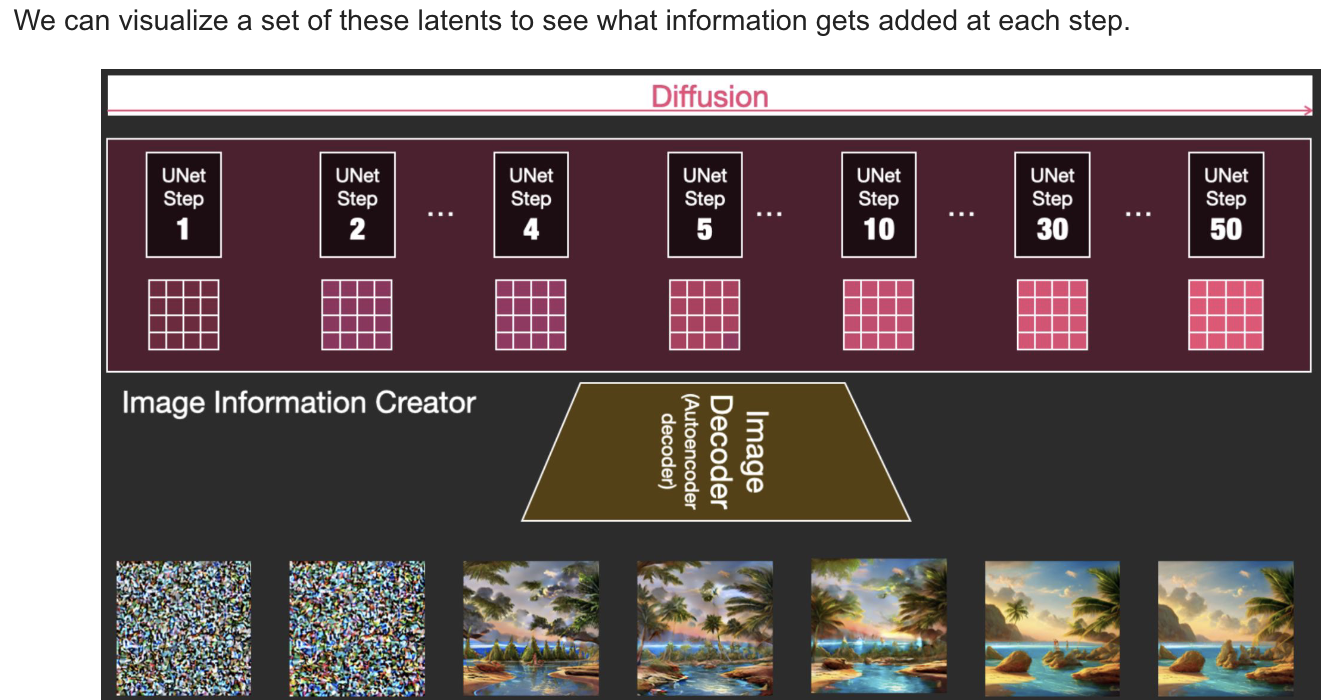
-
How diffusison works


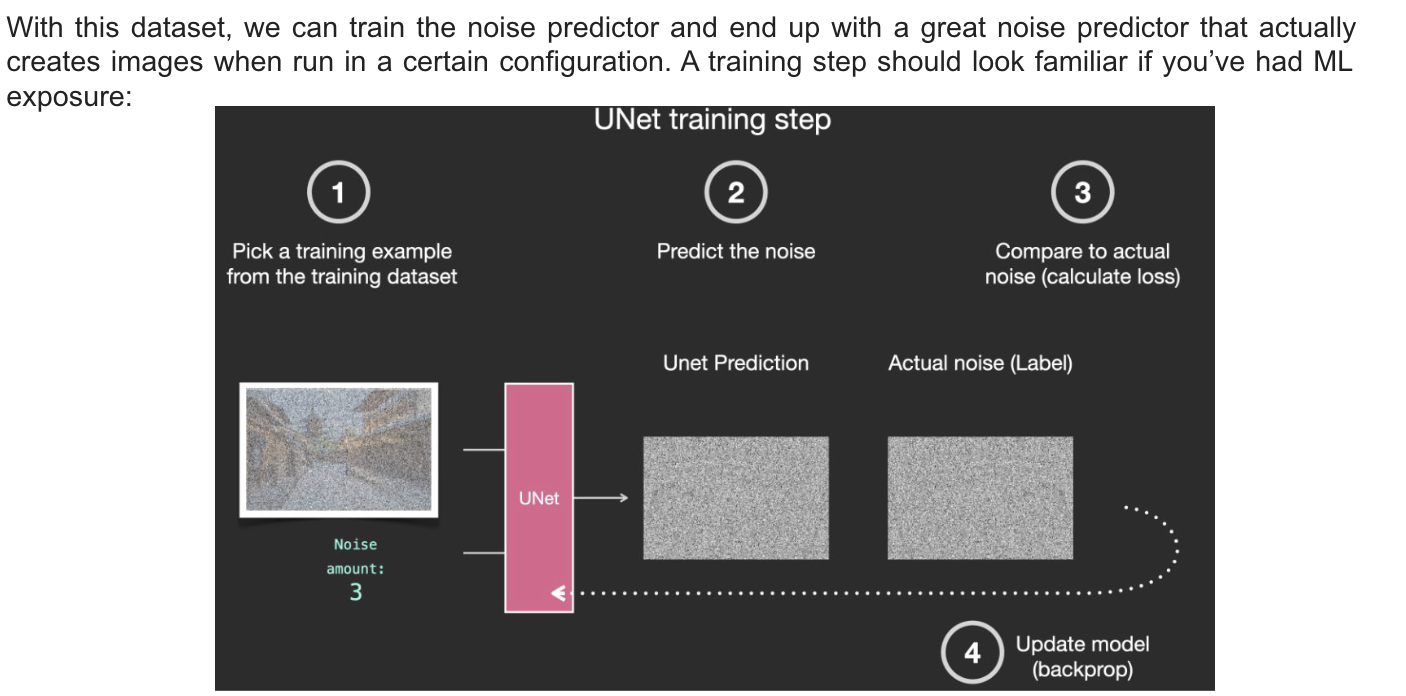
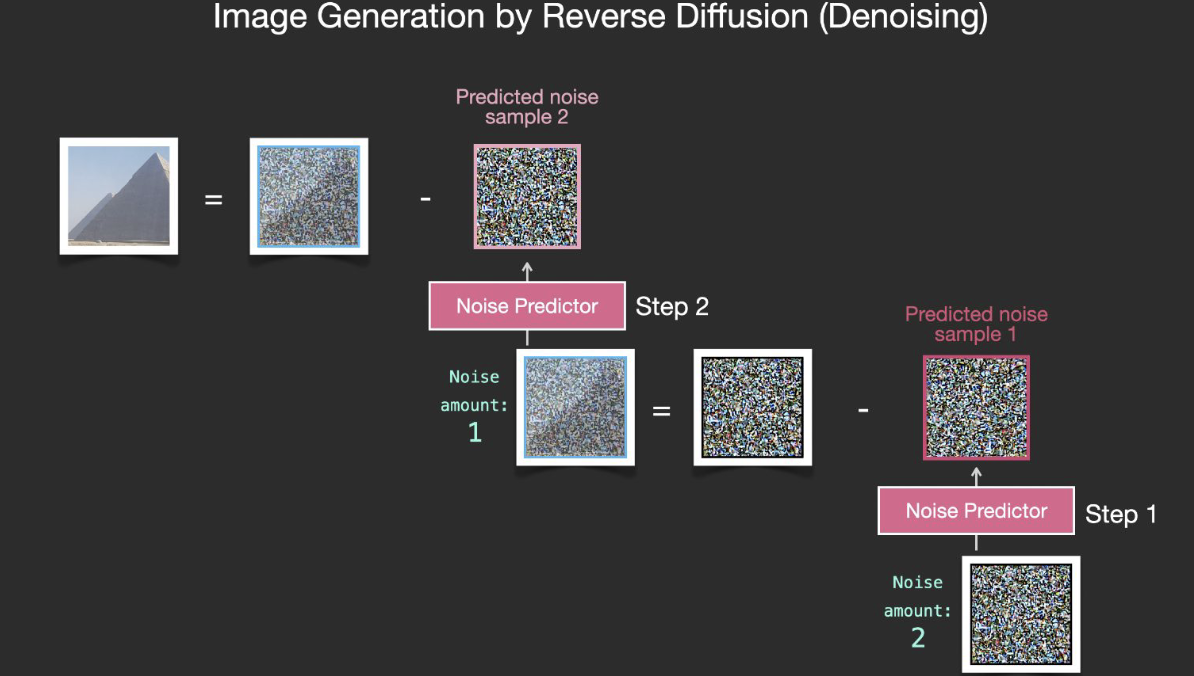
-
How to generate images

-
Generate images with text
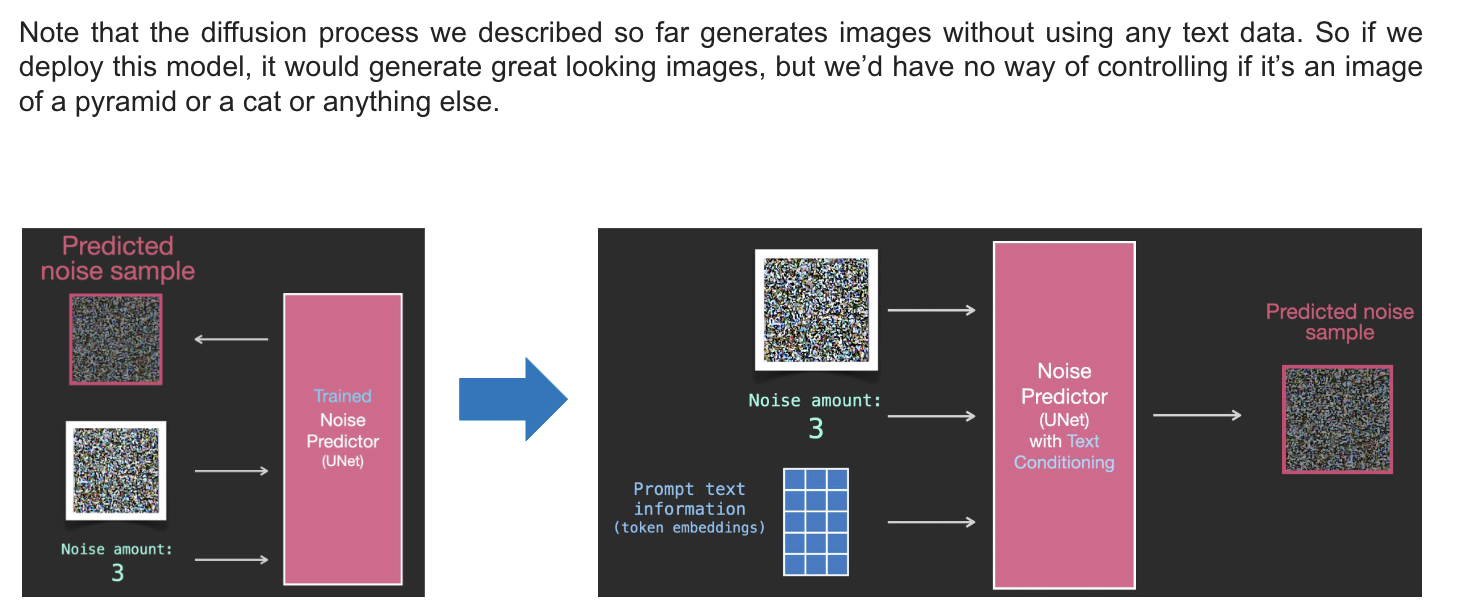
-
Prompts



-
LoRA models
: LoRA (Low-Rank Adaptation) is a training technique for fine-tuning Stable Diffusion models.

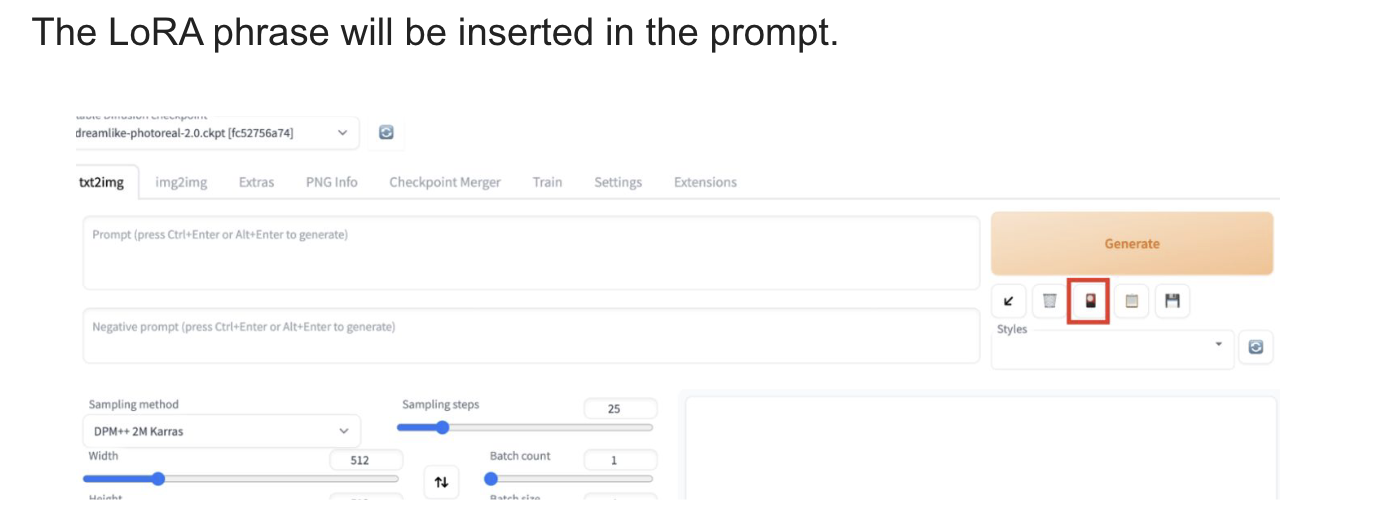
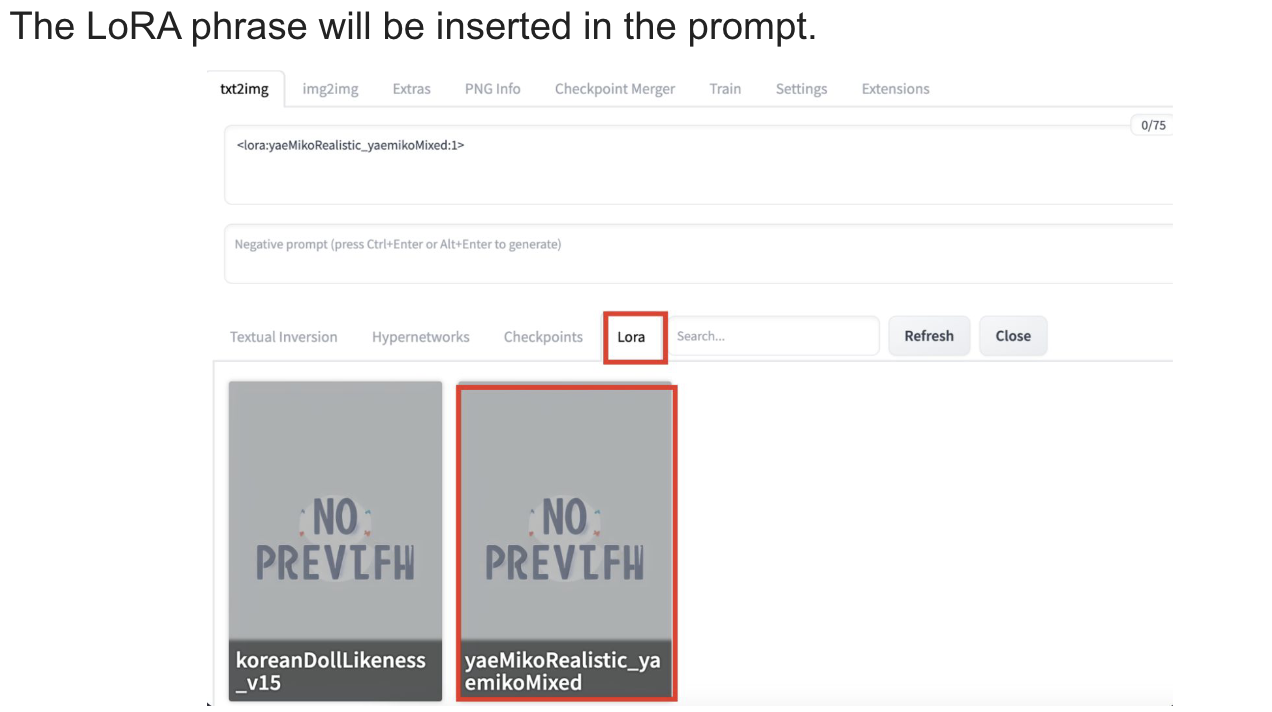
-
ControlNet
: ControlNet is a neural network model for controlling Stable Diffusion models. You can use ControlNet along with any Stable Diffusion models. With ControlNet, Stabel Diffusion users fianlly have a way to contrl where the subjects are and how they look with precision.
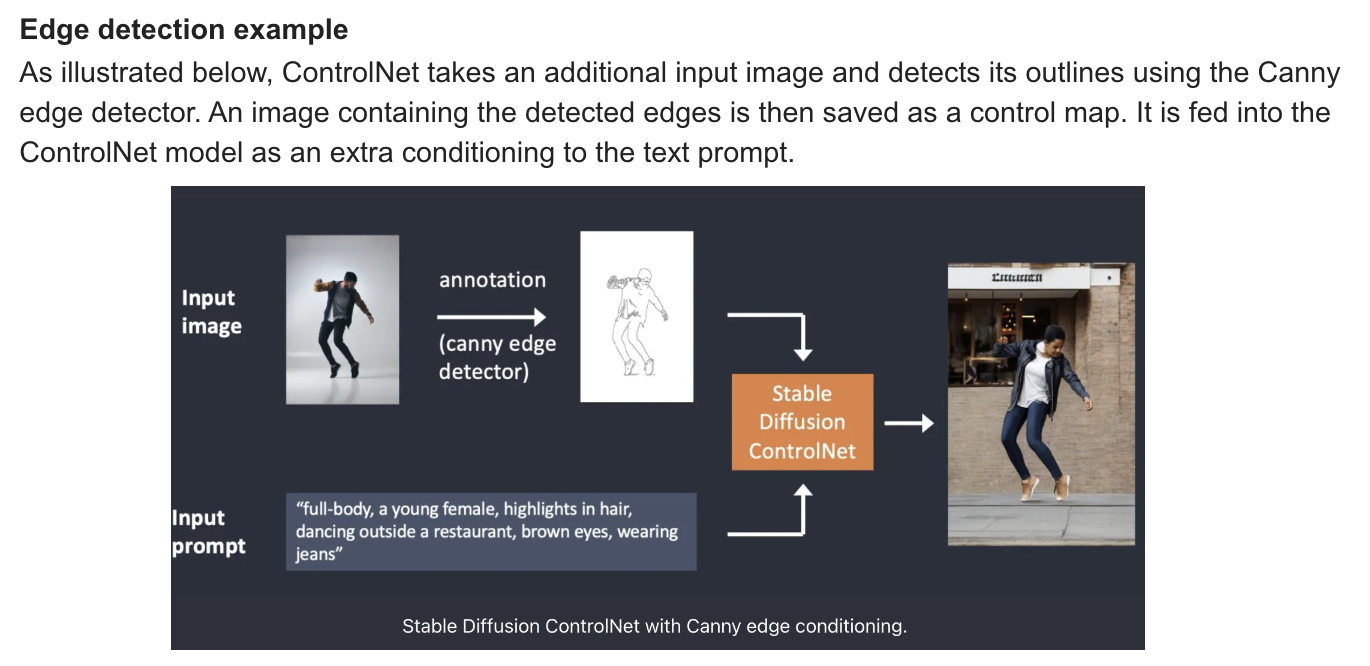 Canny: edge detector
Canny: edge detector
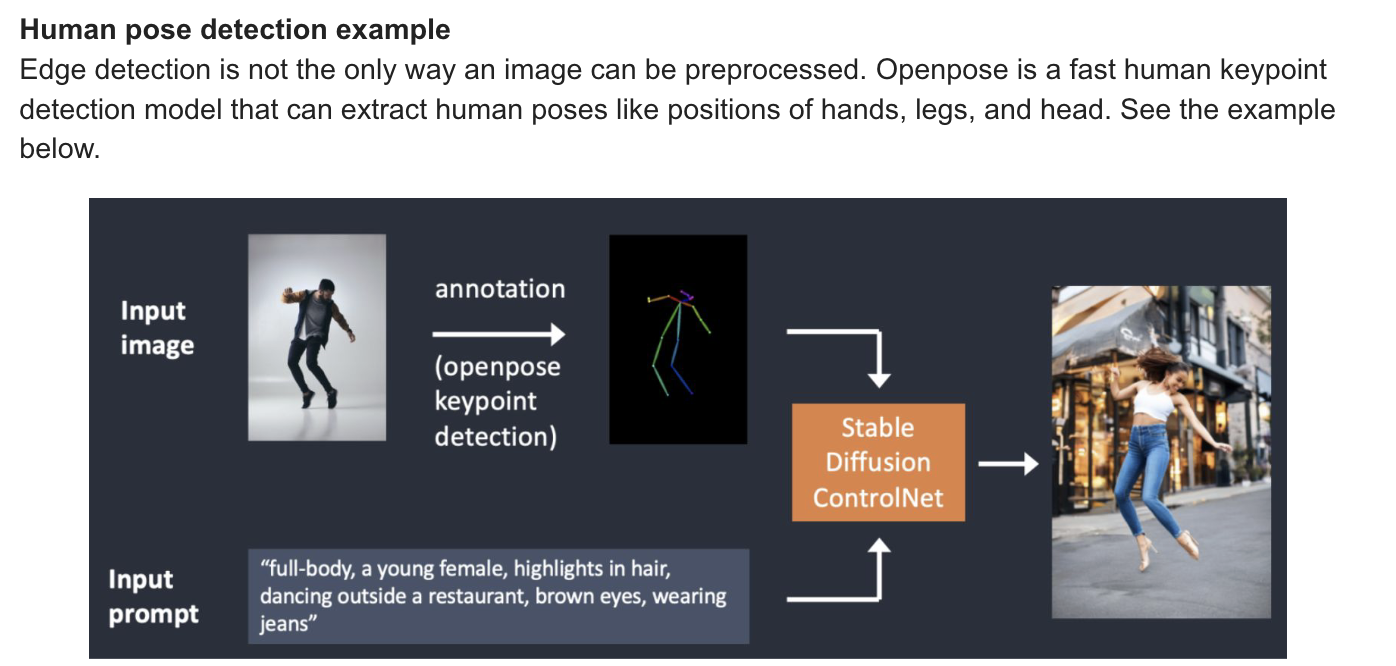
-
Stable Diffusion


stabel diffusion
github
AUTOMATIC1111
Text-to-image tab
- Generate Your Images Faster by Installing Stable Diffusion With Google Colab!
https://www.youtube.com/watch?v=uFNz4y8Ebz4&t=629s
-
Adding Models to Stable Diffusion: Colab & Locally
https://www.youtube.com/watch?v=vpdM9RqkSaM -
Intro to LoRA Models: What, Where, and How with Stable Diffusion
https://www.youtube.com/watch?v=ZHVdNeHZPdc -
Mastering ControlNet Scribble in Stable Diffusion: Transform Your Sketches into Stunning Images.
https://www.youtube.com/watch?v=u6wxGrqIX5Y -
Training (Fine-Tuning) Your Own Stable Diffusion Model Using Colab
https://www.youtube.com/watch?v=c6r25rT8DV0&t=1356s -
Training LoRA with Kohya (theory included!)
https://www.youtube.com/watch?v=xholR62Q2tY
Summary
- Data Science is the discovery of hidden patterns from raw data using various tools, skills, and techniques.
- If you want to answer a yes/no question, this is classification
- If you want to predict a numerical value, this is regression
- If you want to group observations into similar-looking groups, this is clustering
- If you want to recommend someone an item (e.g., book/movie/product) based on ratings data from customers, this is a recommender system
- Deep learning algorithms are constructed with connected layers.
deep learning” is coined for machine learning models built with many hidden layers: deep neural networks.- The structure of a Neuron: linear func, activation func
- By applying transfer learning to a new task, one can achieve significantly higher performance than training with only a small amount of data. Transfer learning is a machine learning approach where a pre-trained model's knowledge is leveraged to solve a new task, often requiring less data and training time.
- Fine-tuning is the process of taking a pre-trained model and continuing its training on a new task with a smaller learning rate to adapt the model's parameters specifically to the new data.transforming an architecture to suit a new purpose based on an existing learned model and finely adjusting the weight of an already learned model.
- Computer vision : image classification
- A Convolutional Neural Network (CNN)is a type of deep learning neural network commonly used for analyzing visual data, such as images or videos. A convolutional layer applies a series of convolutional filters (also known as kernels) to the input data.
Most of the CNNs used for image processing follow a so-called pyramid architecture.- Generative AI enables users to quickly generate new content based on a variety of inputs. Inputs and outputs to these models can include text, images, sounds, animation, 3D models, or other types of data.
- Discriminative models are primarily used for classification tasks, where the goal is to assign labels to new, unseen instances based on their features
- A Generative Adversarial Network (GAN) is a class of deep learning models where two neural networks, a generator and a discriminator, are pitted against each other in a competition,
- A Recurrent Neural Network (RNN) is a type of deep learning model that is capable of processing sequential data by utilizing internal memory to retain information and make decisions based on previous inputs.
- Attention is a mechanism in deep learning that allows a model to focus on specific parts of input data, assigning different weights to different elements, enabling better performance on tasks requiring context and long-range dependencies.
- The Transformer is a deep learning model architecture based on the attention mechanism, designed to process sequential data by leveraging self-attention layers, making it highly effective for tasks such as machine translation and natural language understanding.
- Vision Transformer (ViT) applies the transformer's self-attention mechanism to images by dividing them into patches and transforming them into sequences, allowing for effective image recognition and classification.
- DETR ( detection Transformer) el is a computer vision model used for object detection in images
- Hugging Face is a popular open-source library and platform that provides a wide range of natural language processing (NLP) models, tools, and resources
- Diffusion Models are a method of creating data that is similar to a set of training data. They train by destroying the training data through the addition of noise, and then learning to recover the data by reversing this noising process.
- stable Diffusion is a text-to-image AI model. It is trained on millions of image and text description pairs found on the internet.
Text encoder/ Unet noise predictor/ auto encoder-decoder model
Stable Diffusion works on the latent space of images rather than on the pixel space of images.- LoRA (Low-Rank Adaptation) is a training technique for fine-tuning Stable Diffusion models.
LoRA models are small Stable Diffusion models that apply tiny changes to standard checkpoint models.- ControlNet is a neural network model for controlling Stable Diffusion models.
Machine Learning Intermediate
Preliminary of machine learning
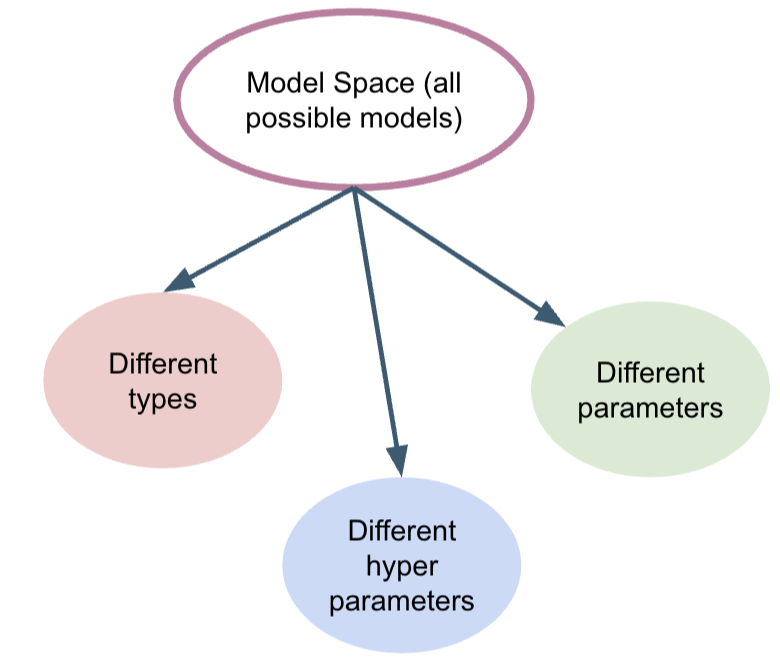
Modle Space
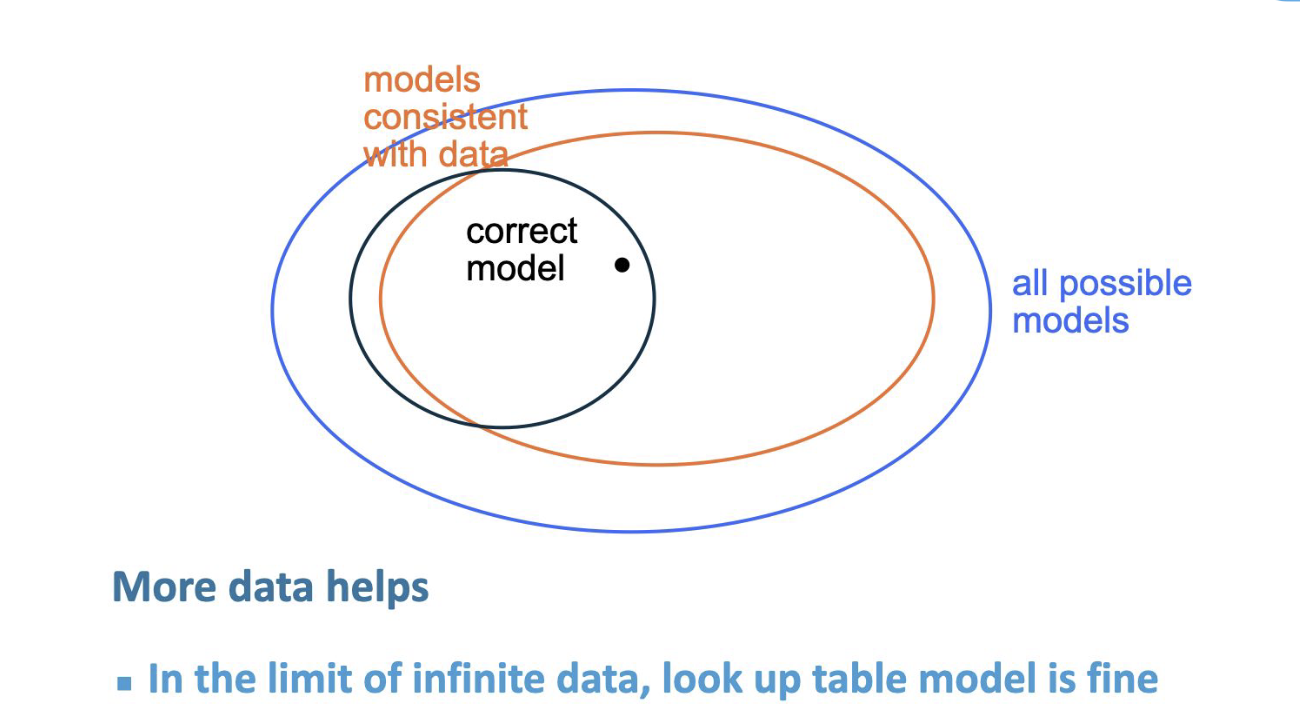
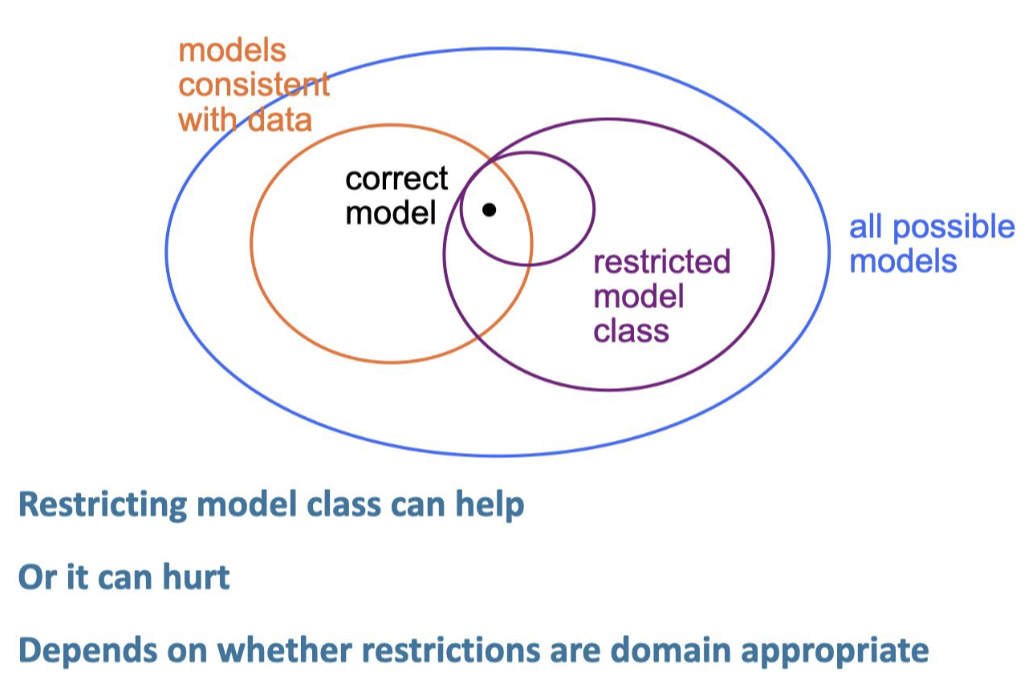
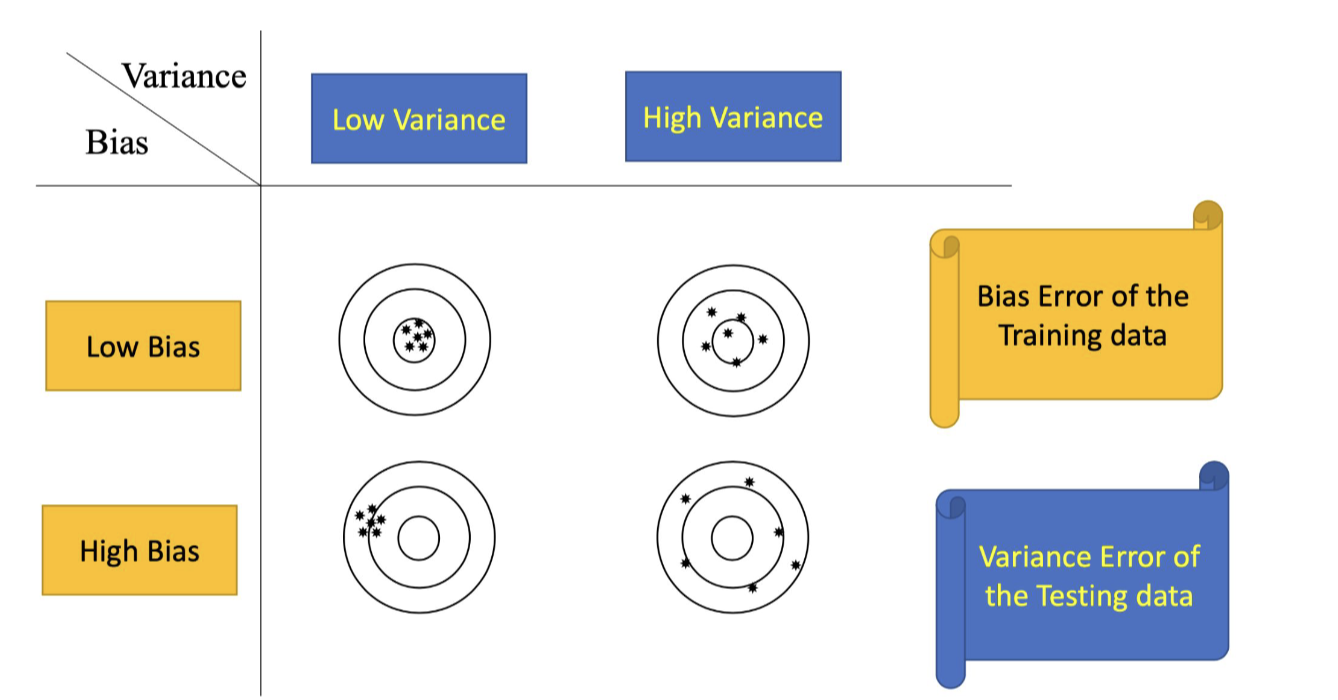
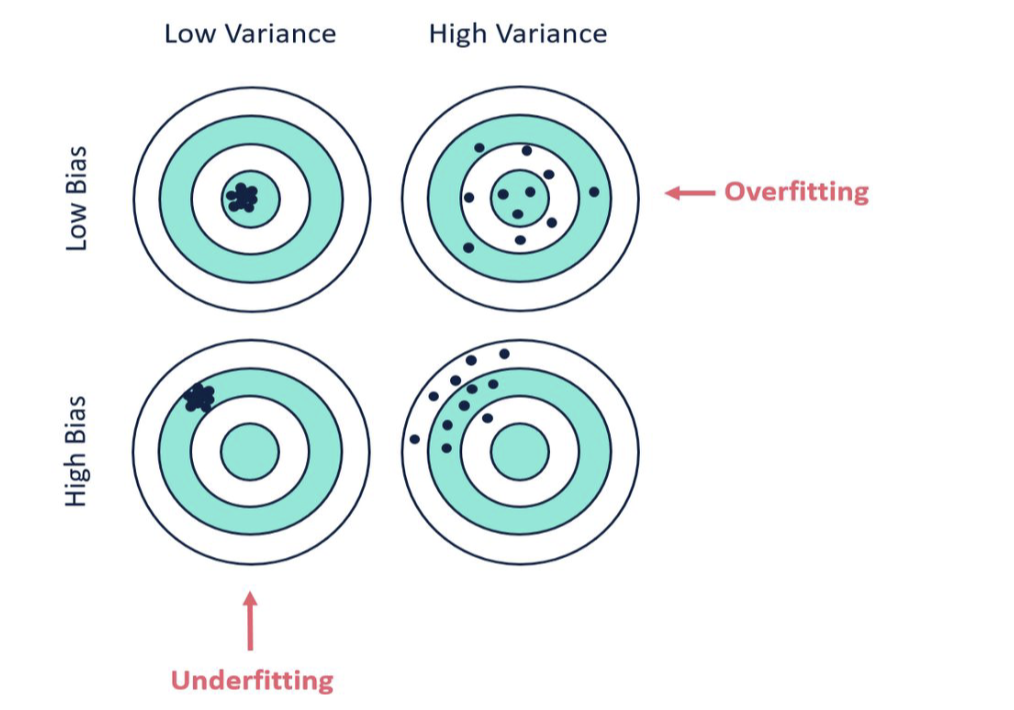
Biad and Variance
- Bias : is referring to the gap between predicted value of the data
and actual value of the data. - Variance : refers to the model's sensitivity to small fluctuations or noise in the traning data.


Feature Space
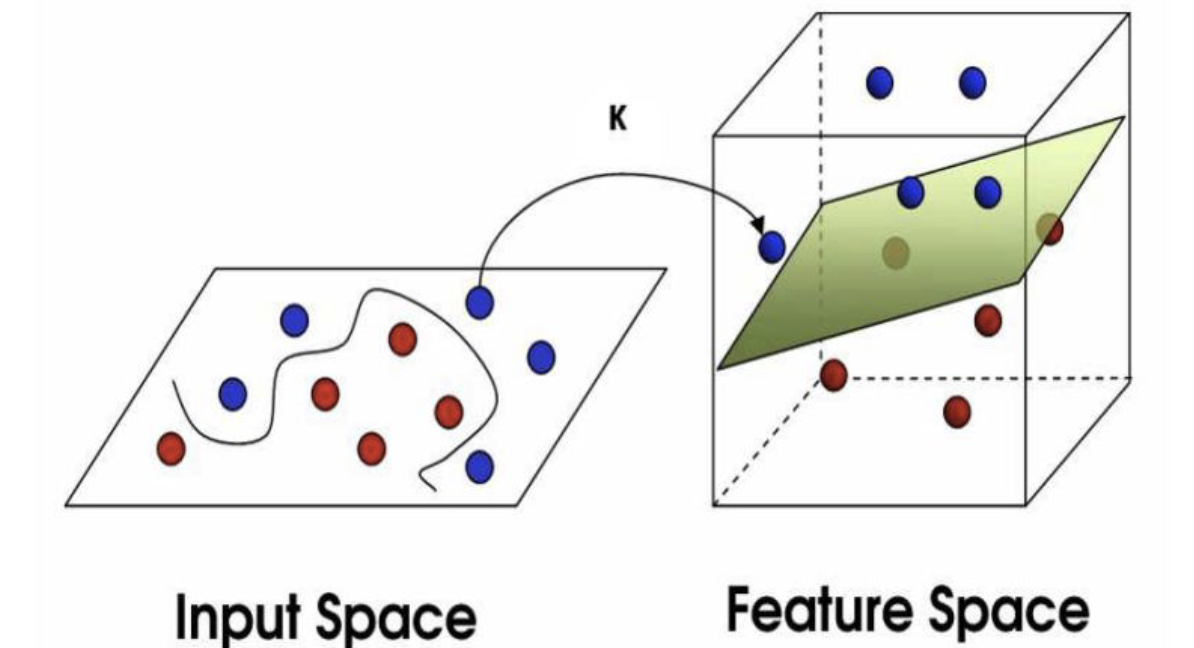
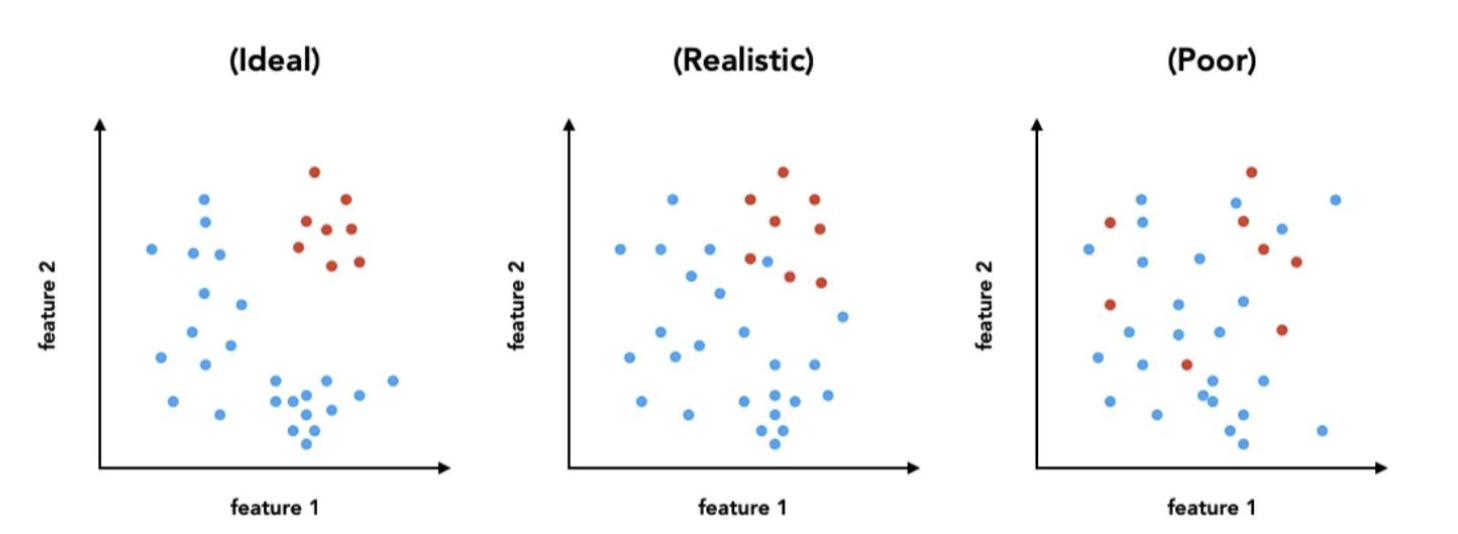
Decision Boundary
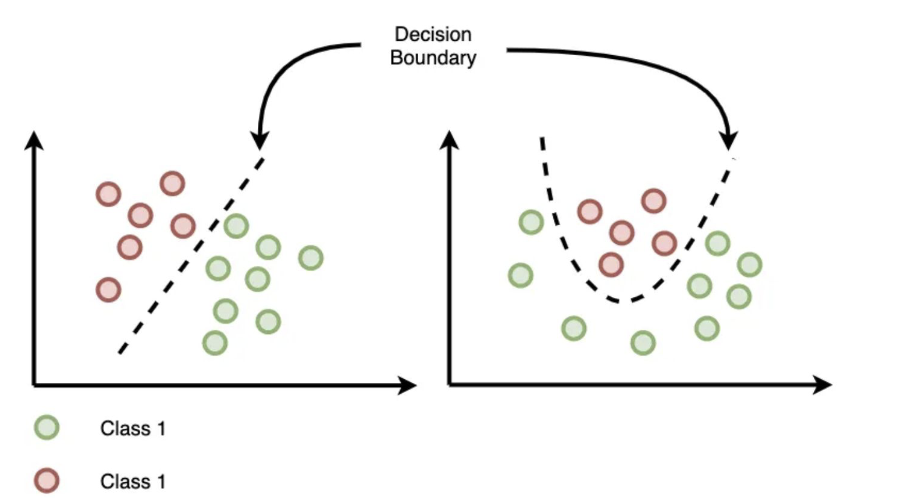
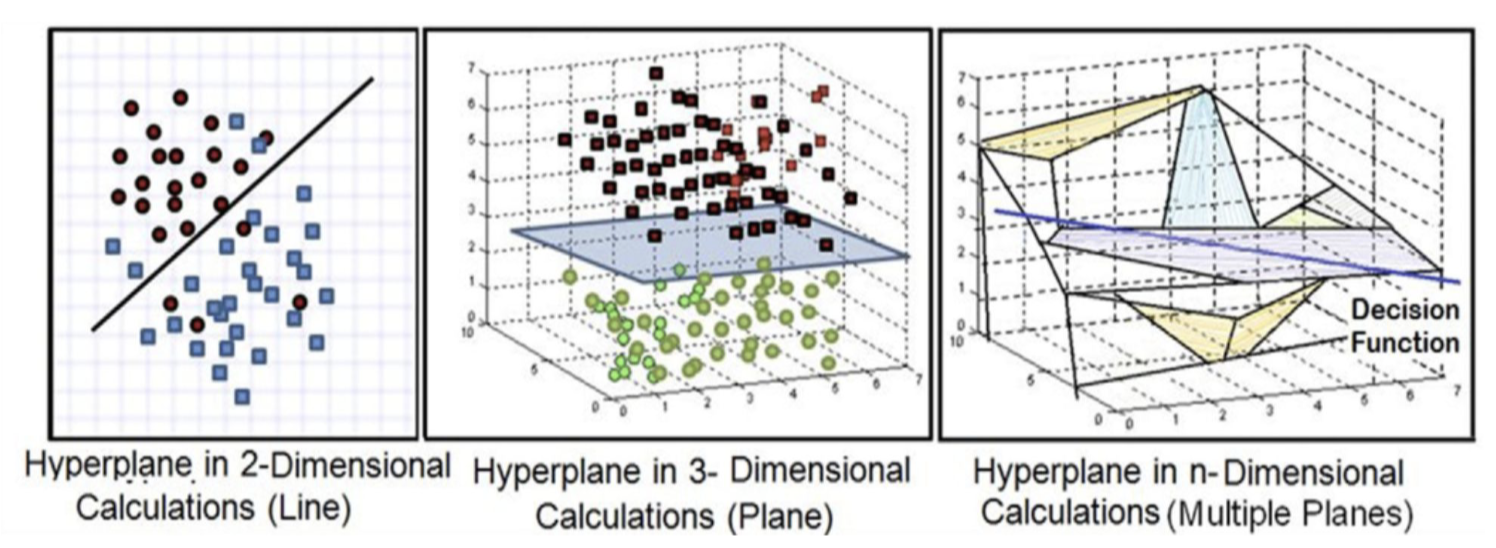
Linear seperabel and Non-linear seperable
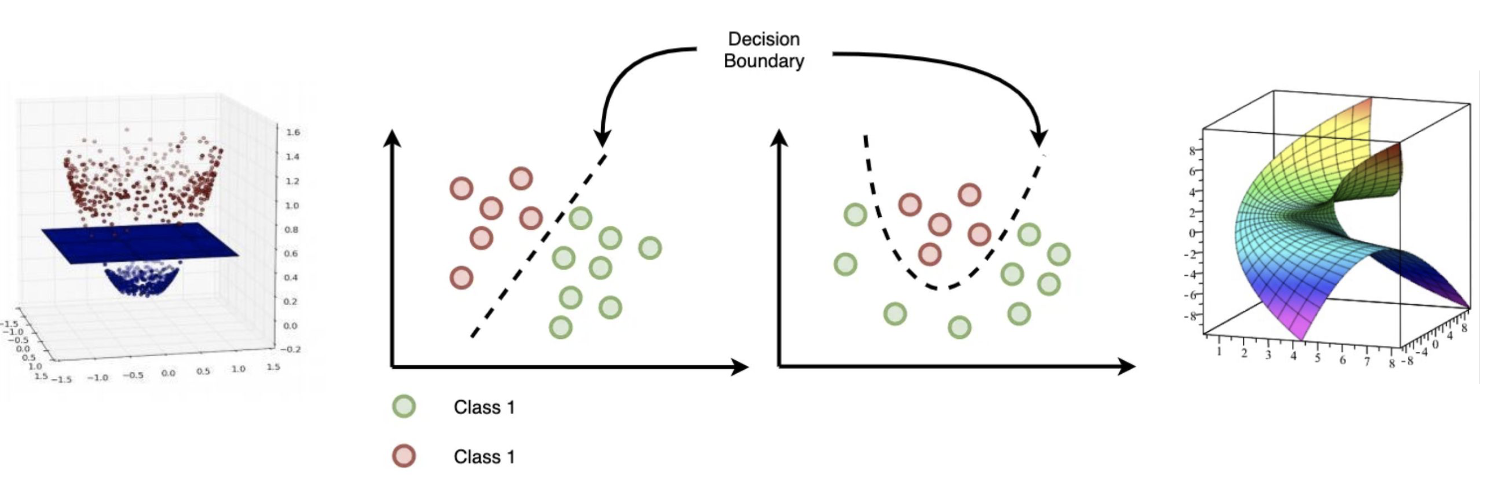
Model Genernality
Overfitting Underfitting

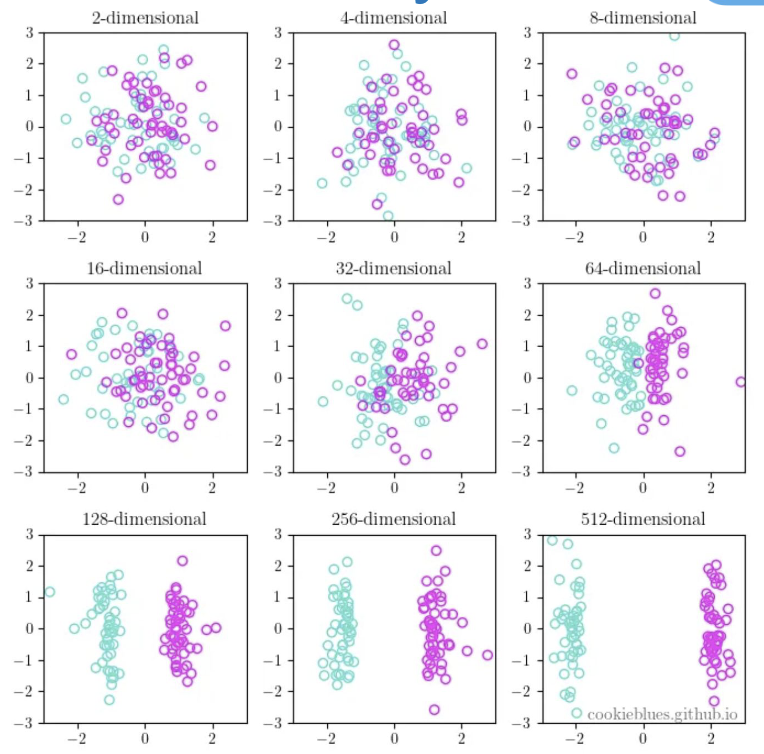
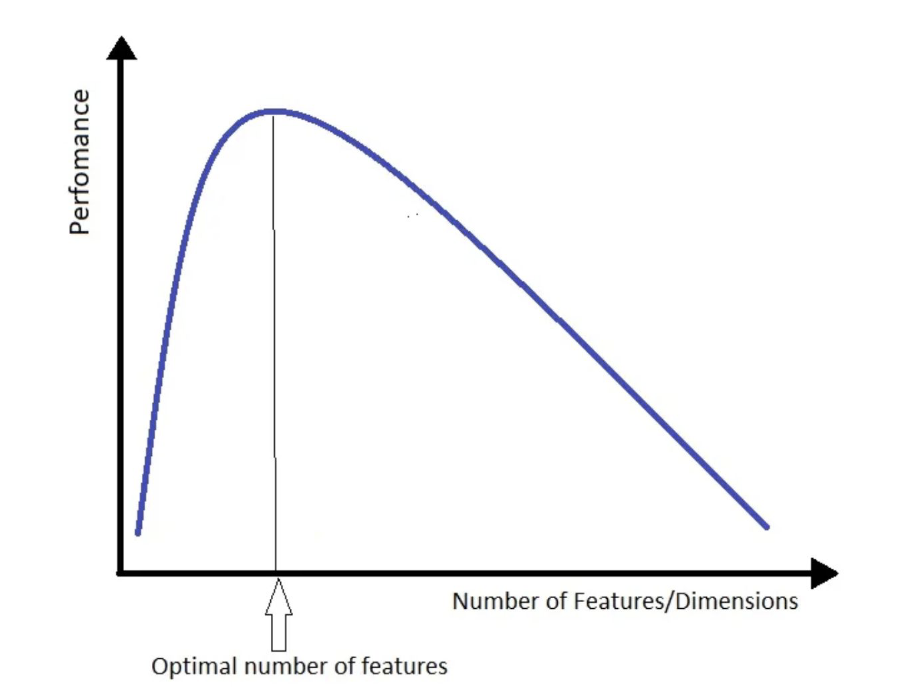
Cures of demensionality

Interpretability
Interpretability in machine learning refers to the ability to understand and explain how a machine learning model arrives at its predictions or decisions. It is an essential characteristic, especially in domains where decisions have significant
consequences, such as healthcare, finance, legal, and critical systems.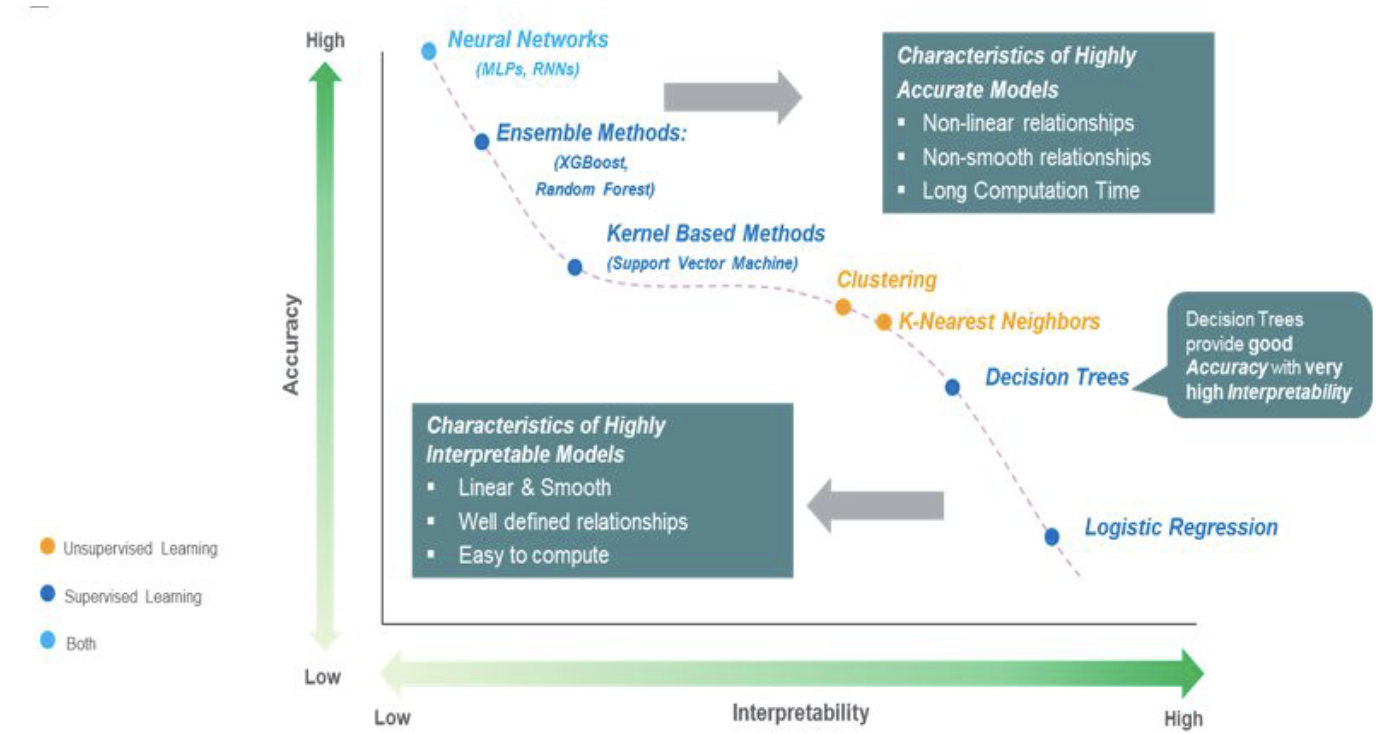
Probalistic perspecive


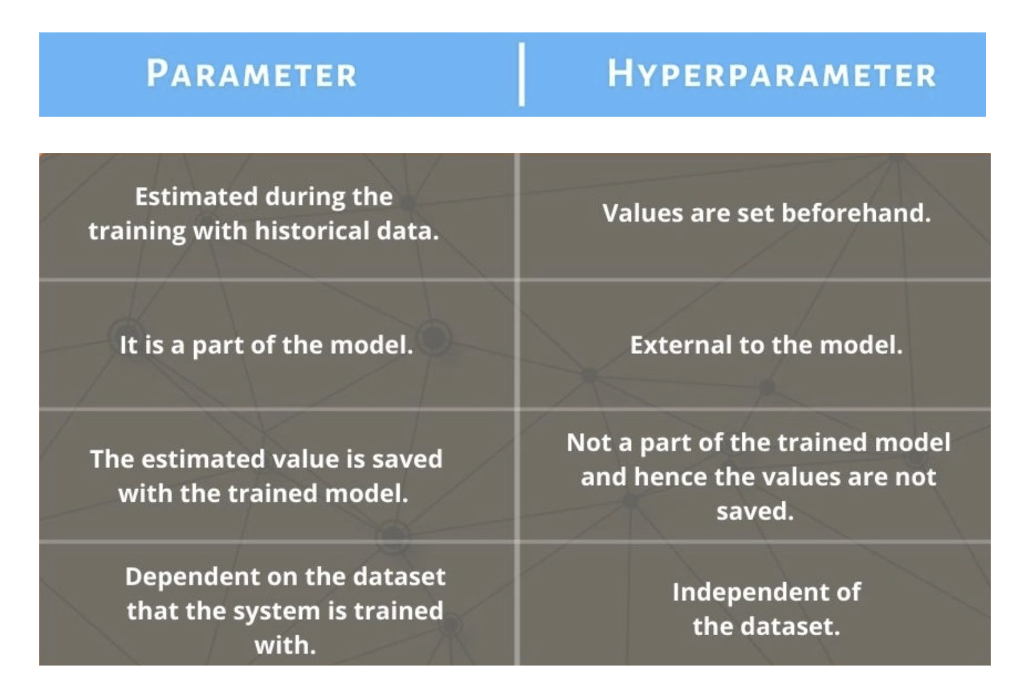
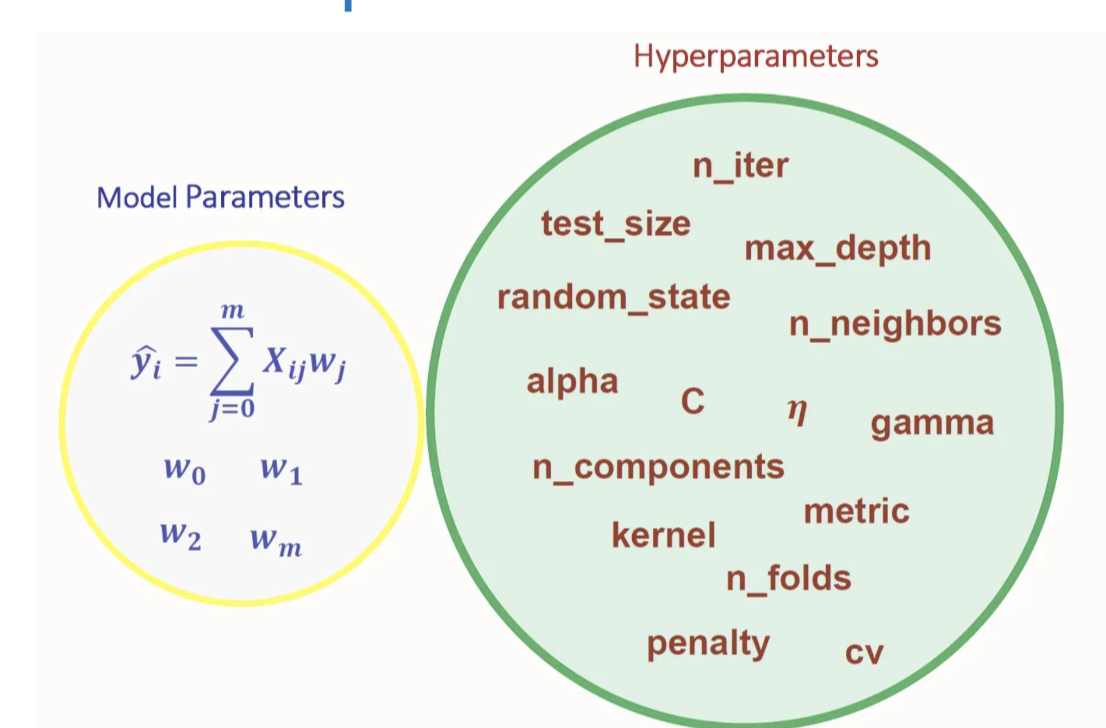
Parametric and Non-parametreic

Problaistic perspective

Optimization
Regularigation