0. concepts
-
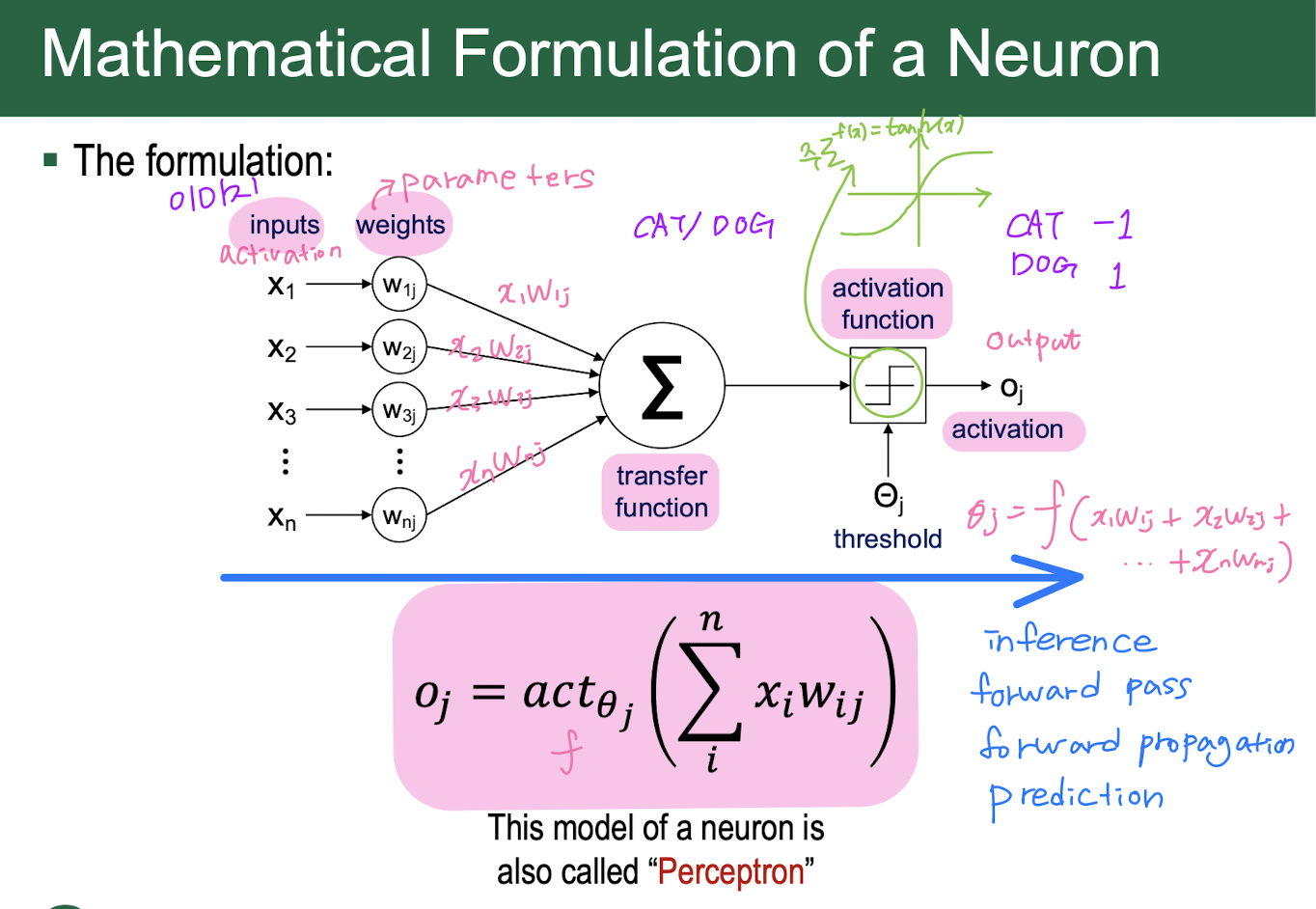
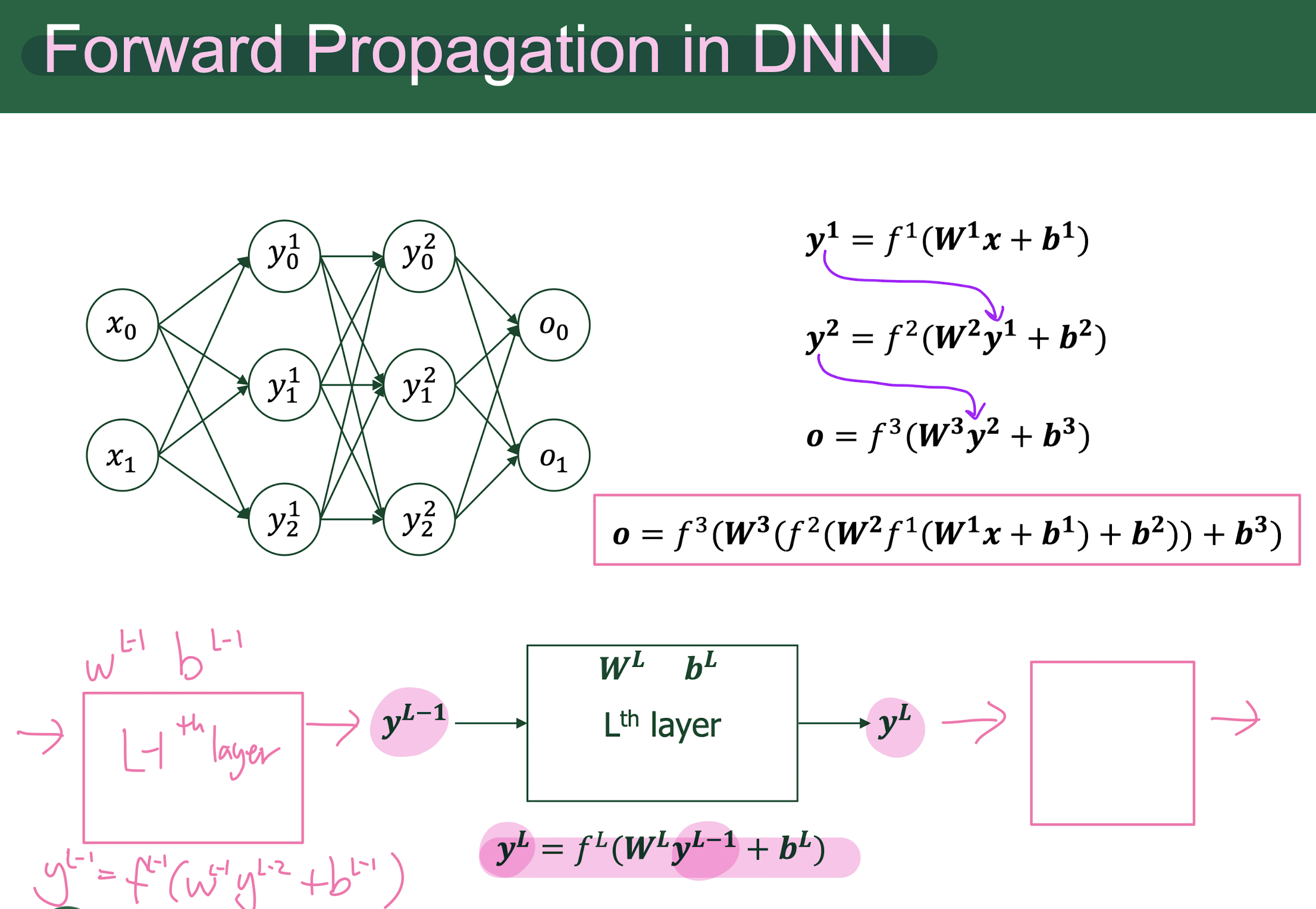
foward = inference = forward pass = forward propagation = prediction
-
output value = predict = inference
-
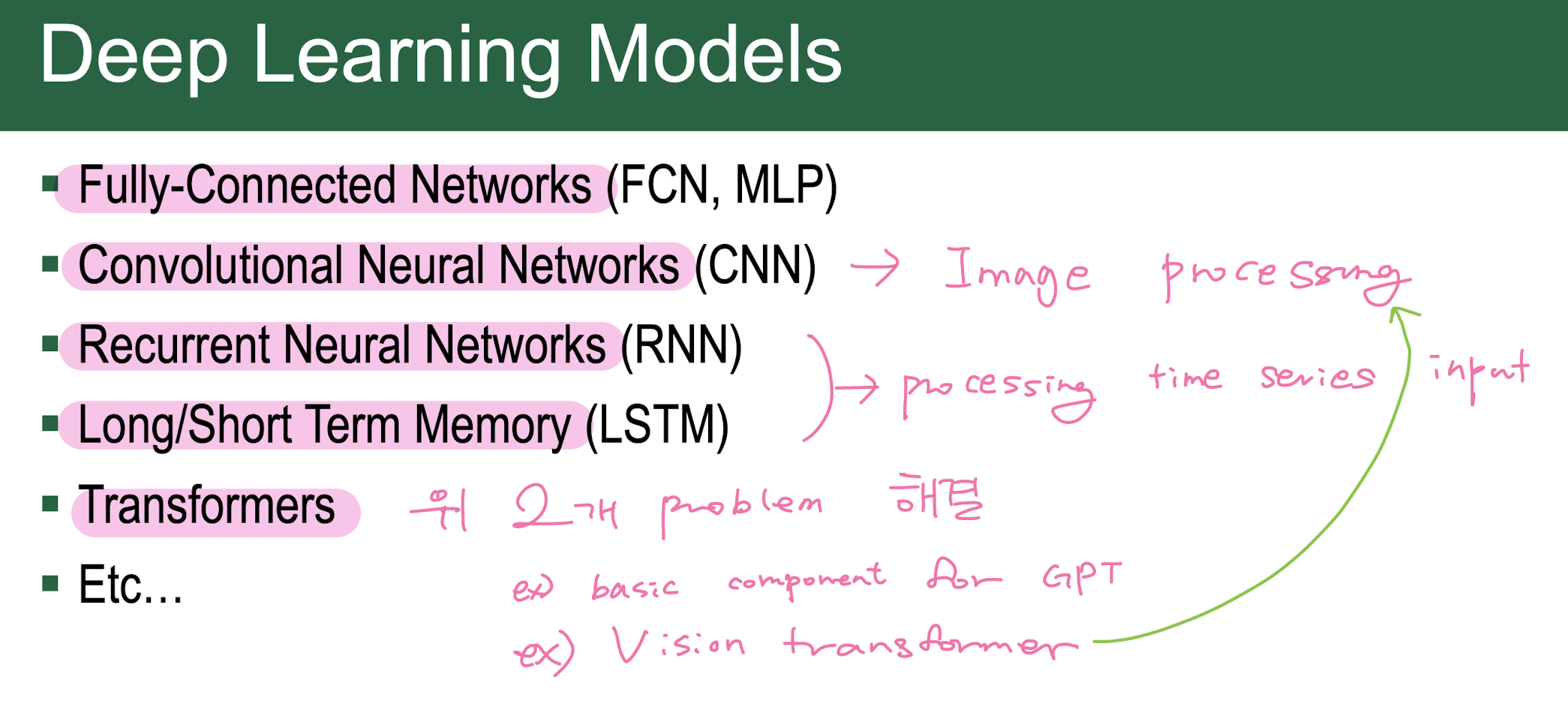
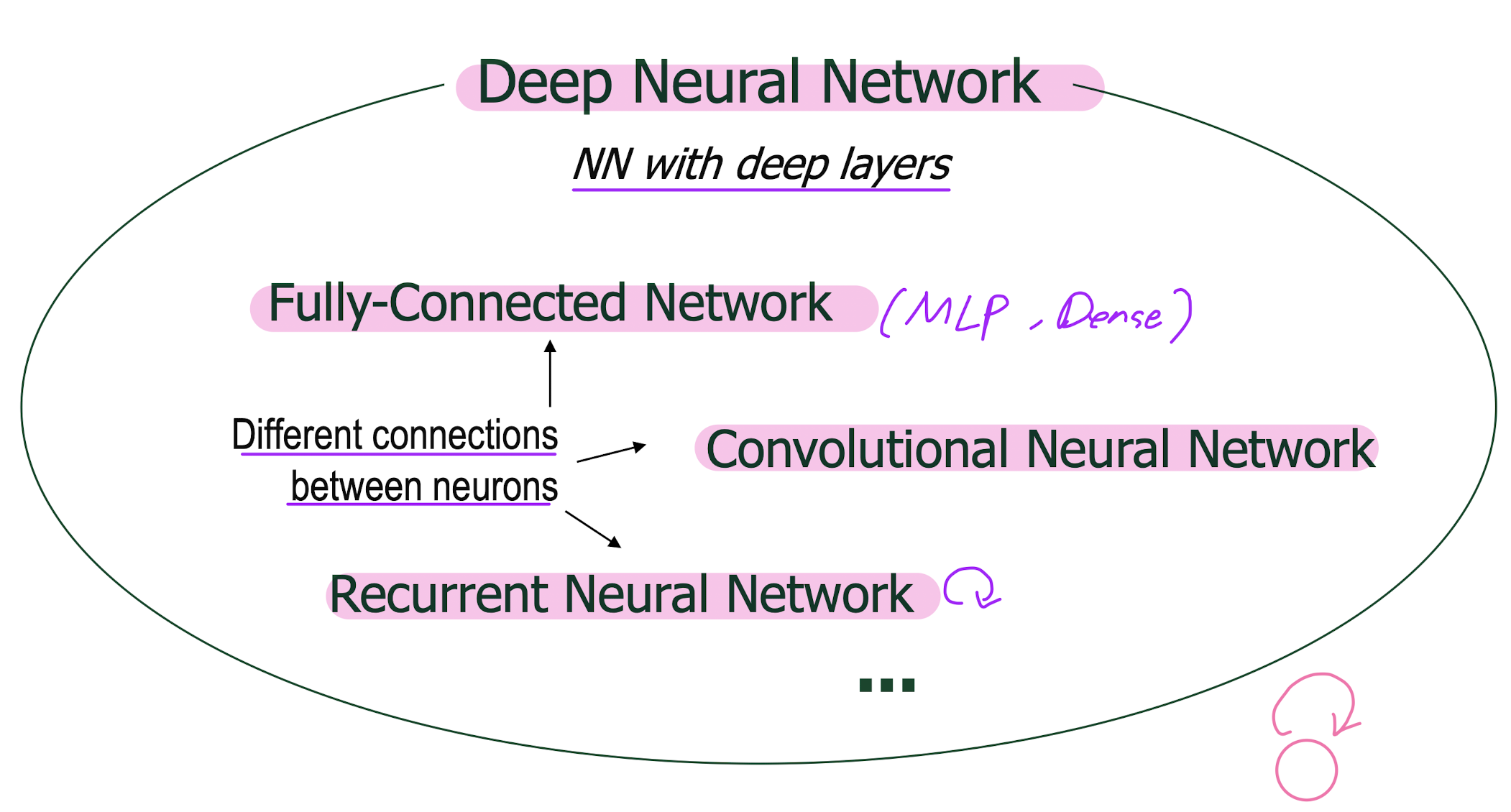
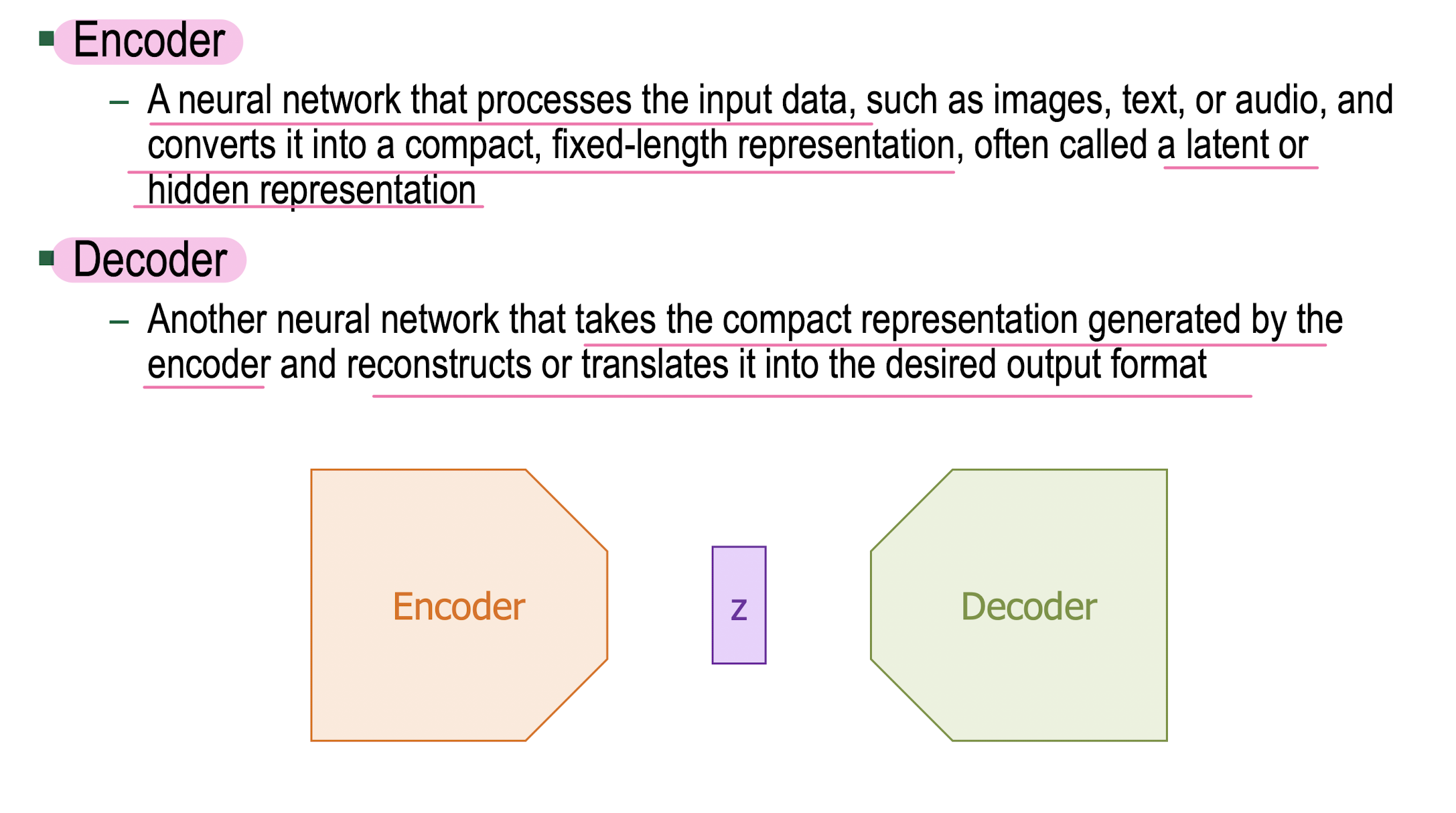
MLP(multi layer perceptron) = fully-connected network
-
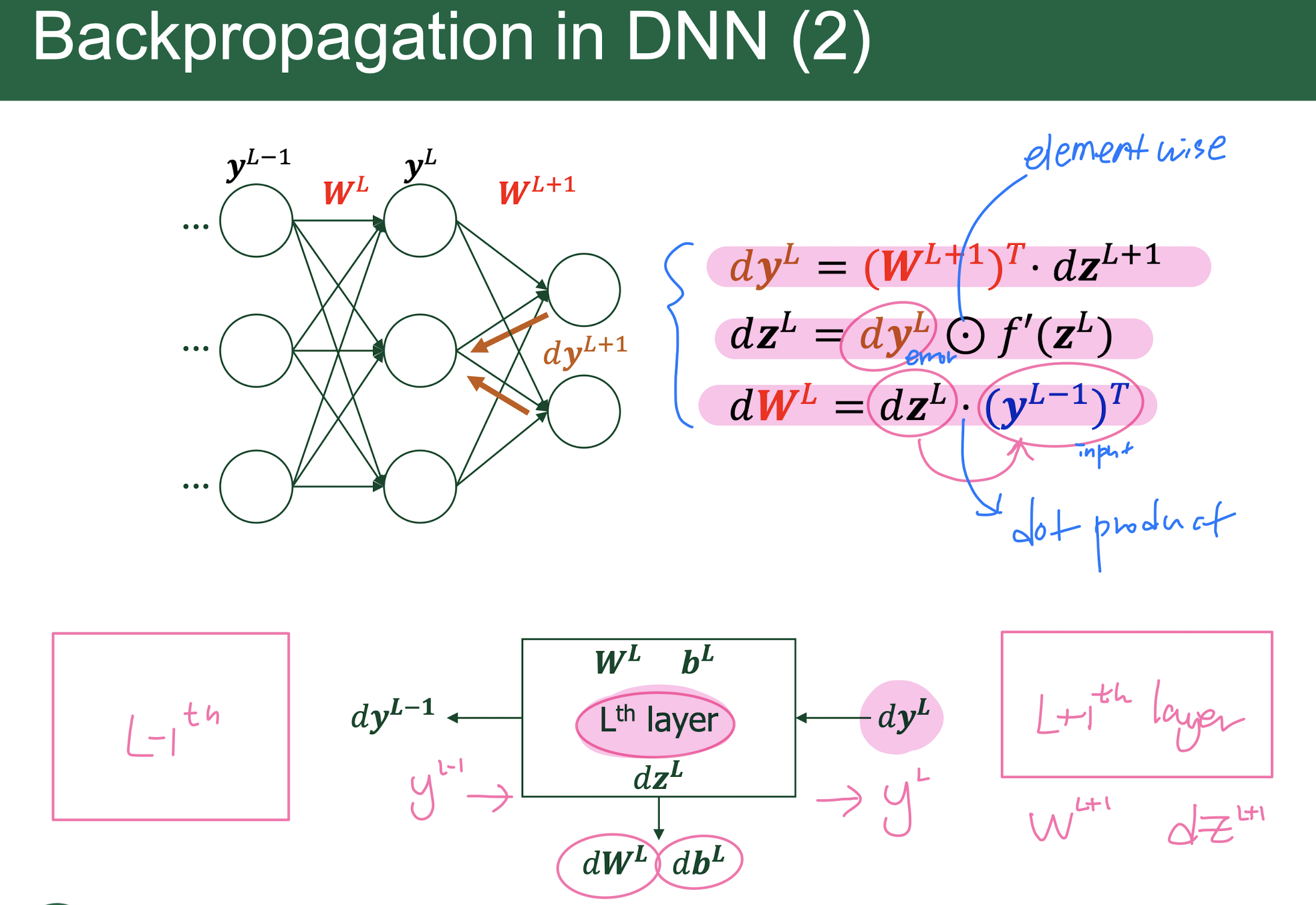
error = input gradient = activation gradient
-
n-layer perceptron = fully-connected network = dense network = feed forward network
-
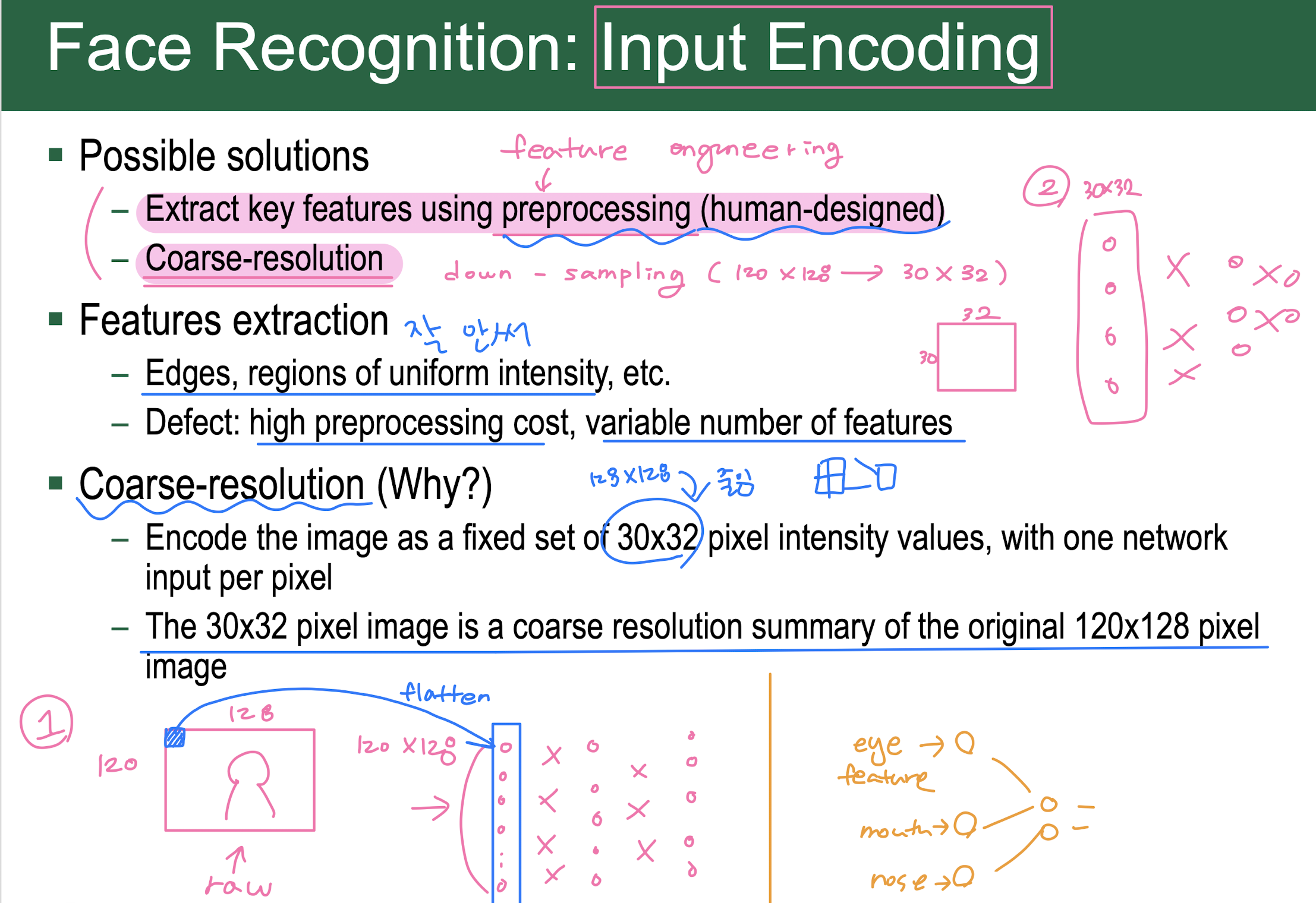
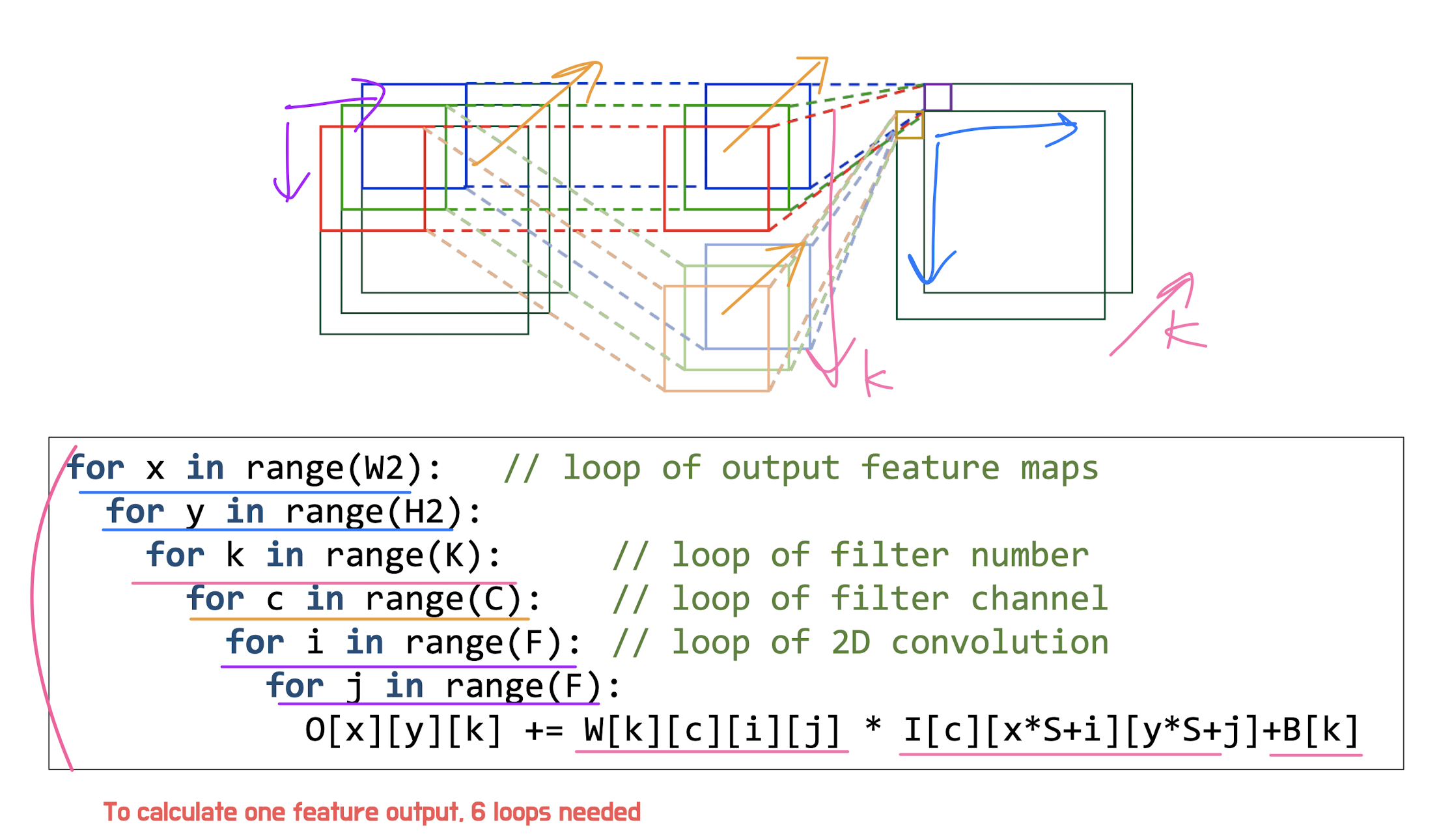
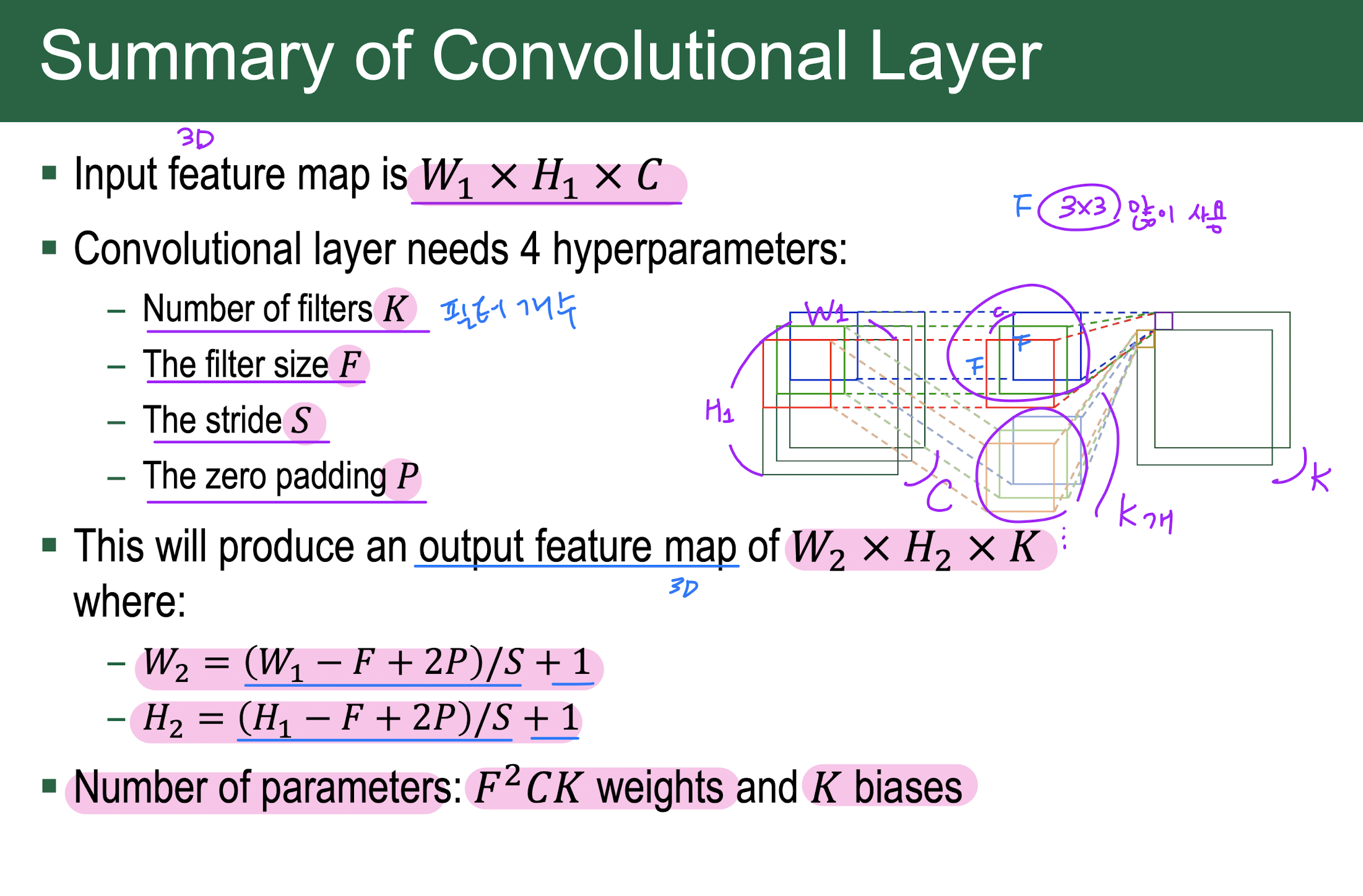
input image = input activation = input feature map
-
output image = output activation = output feature map
-
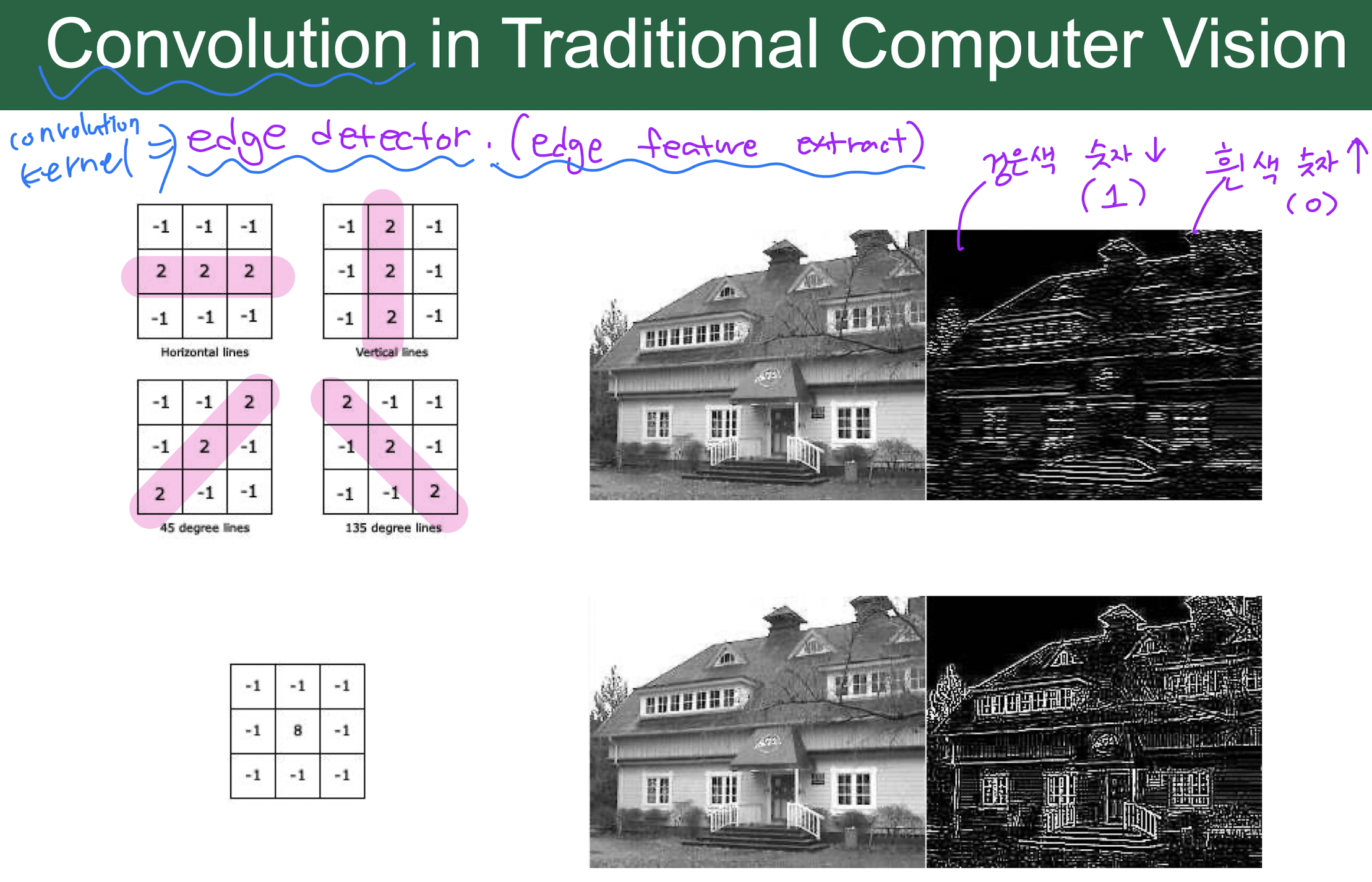
filter = kernel = weight
-
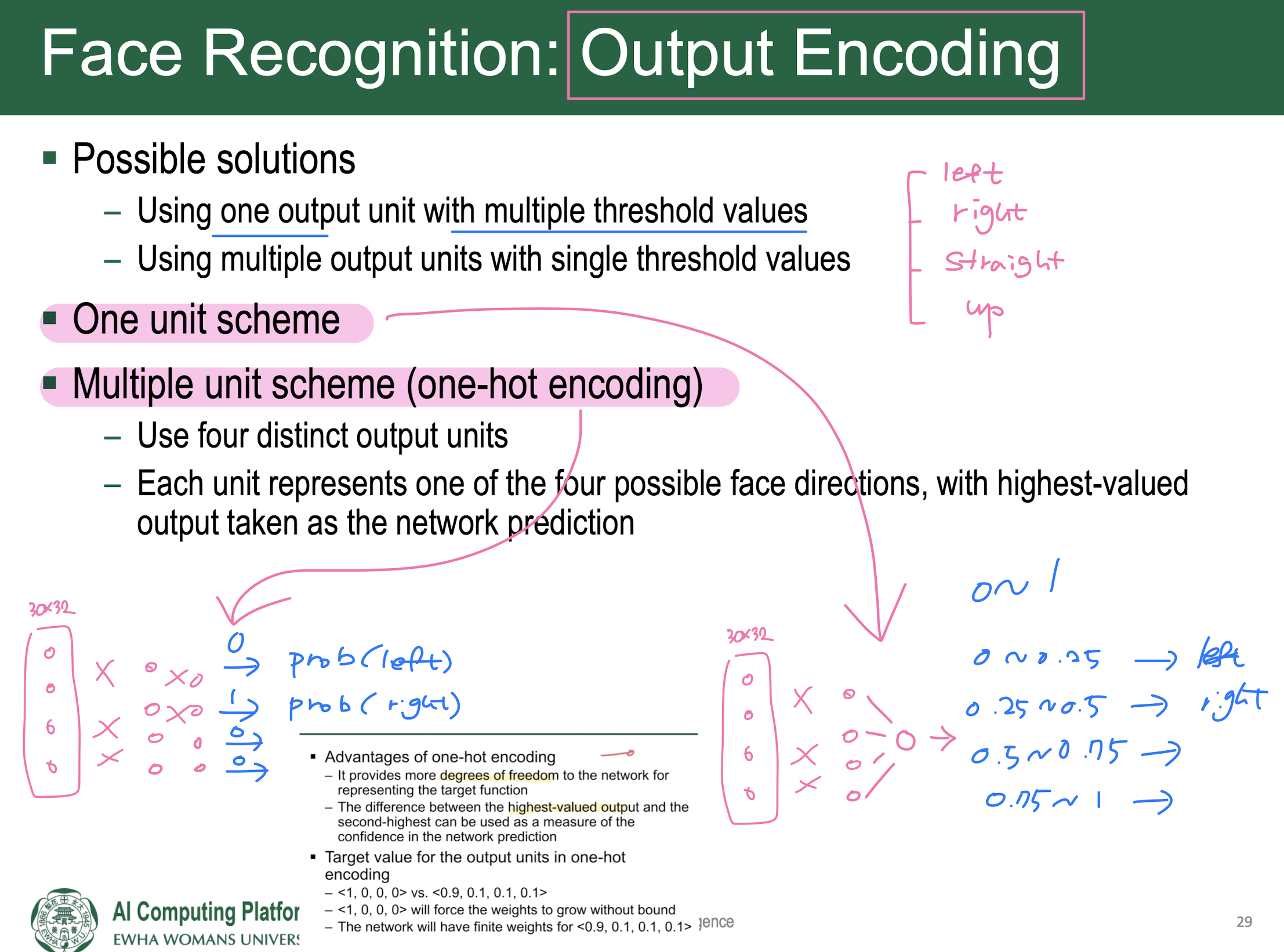
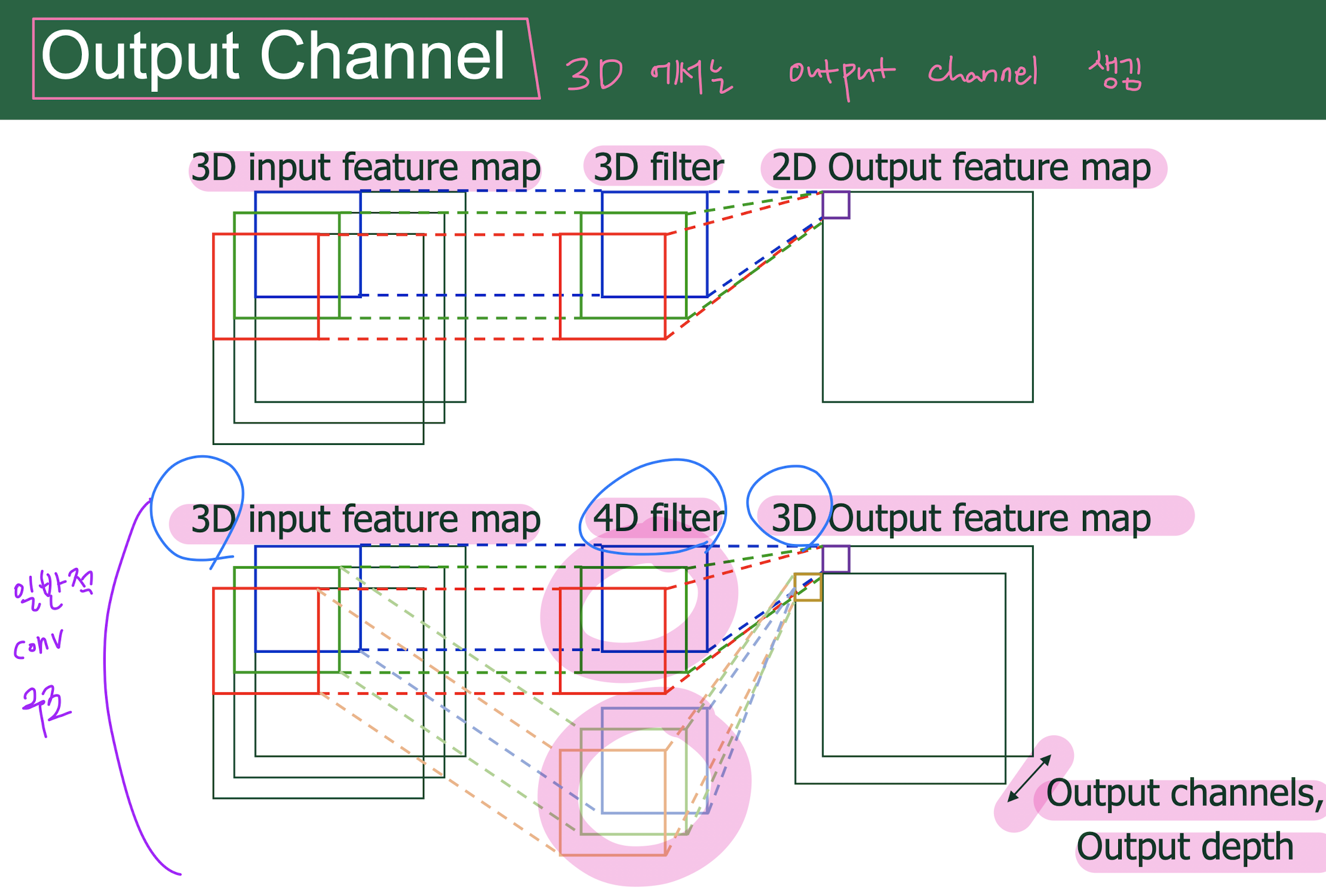
Output channels = Output depth
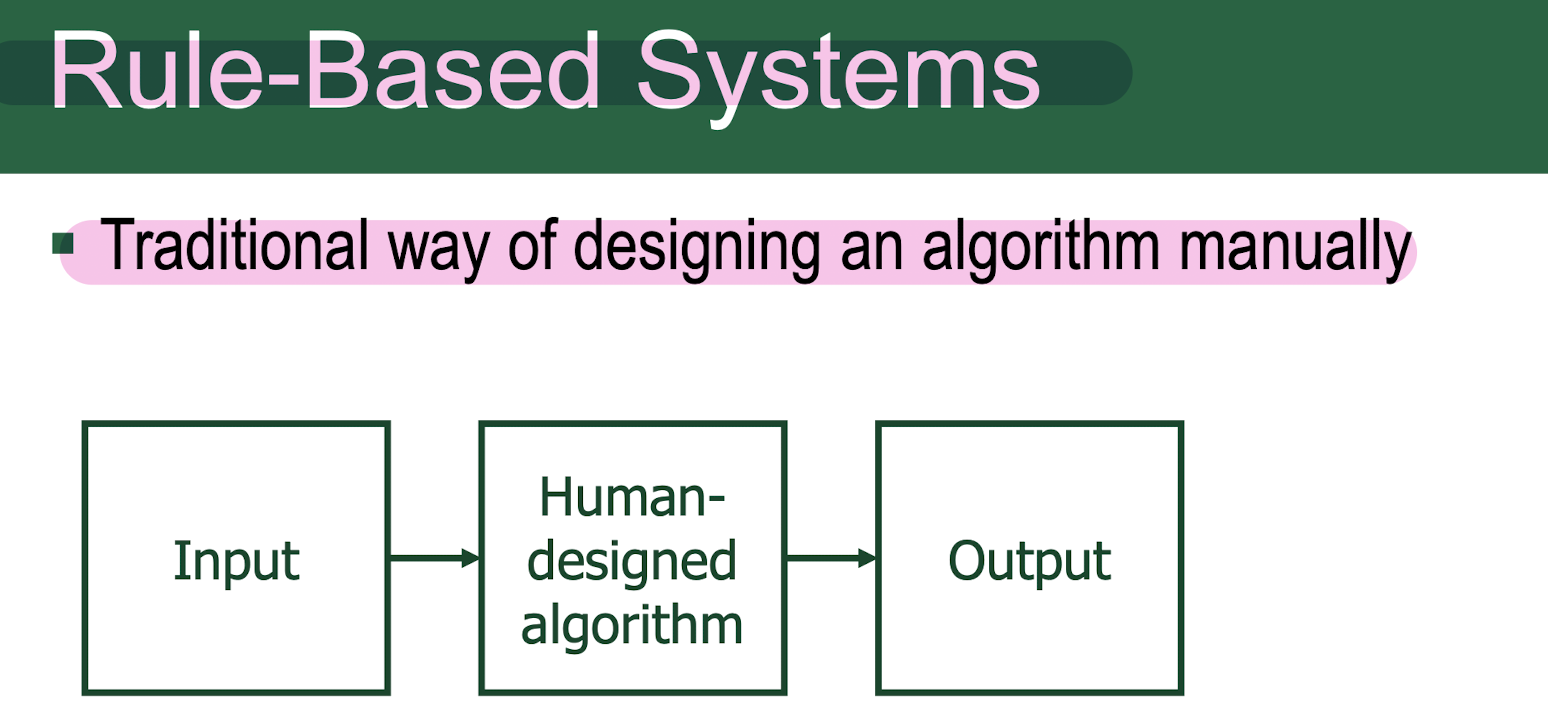
1. Traditional AI methods
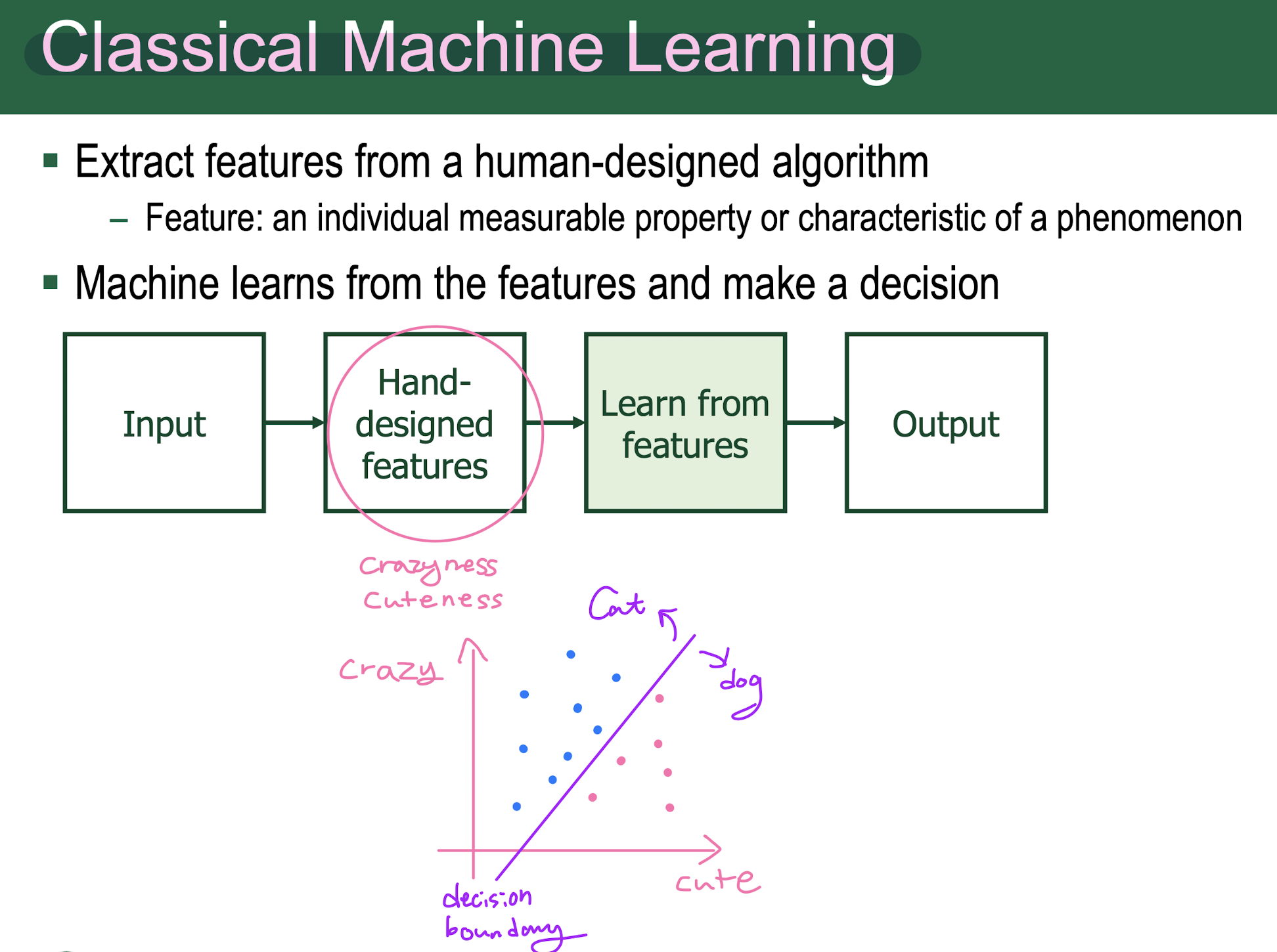
2. Mathematical Backgrounds
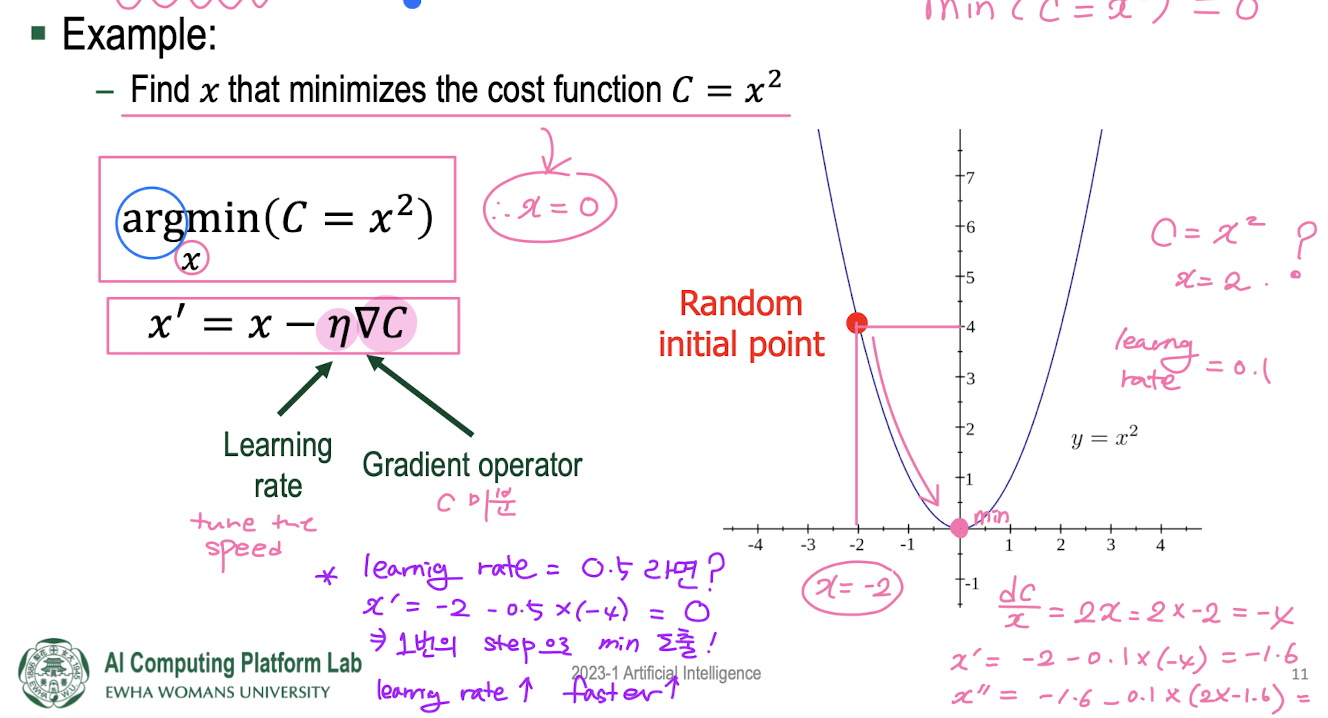
- gradient is a vector/matrix that points in the direction of the steepest increase in the function. The direction of greatest change of a function
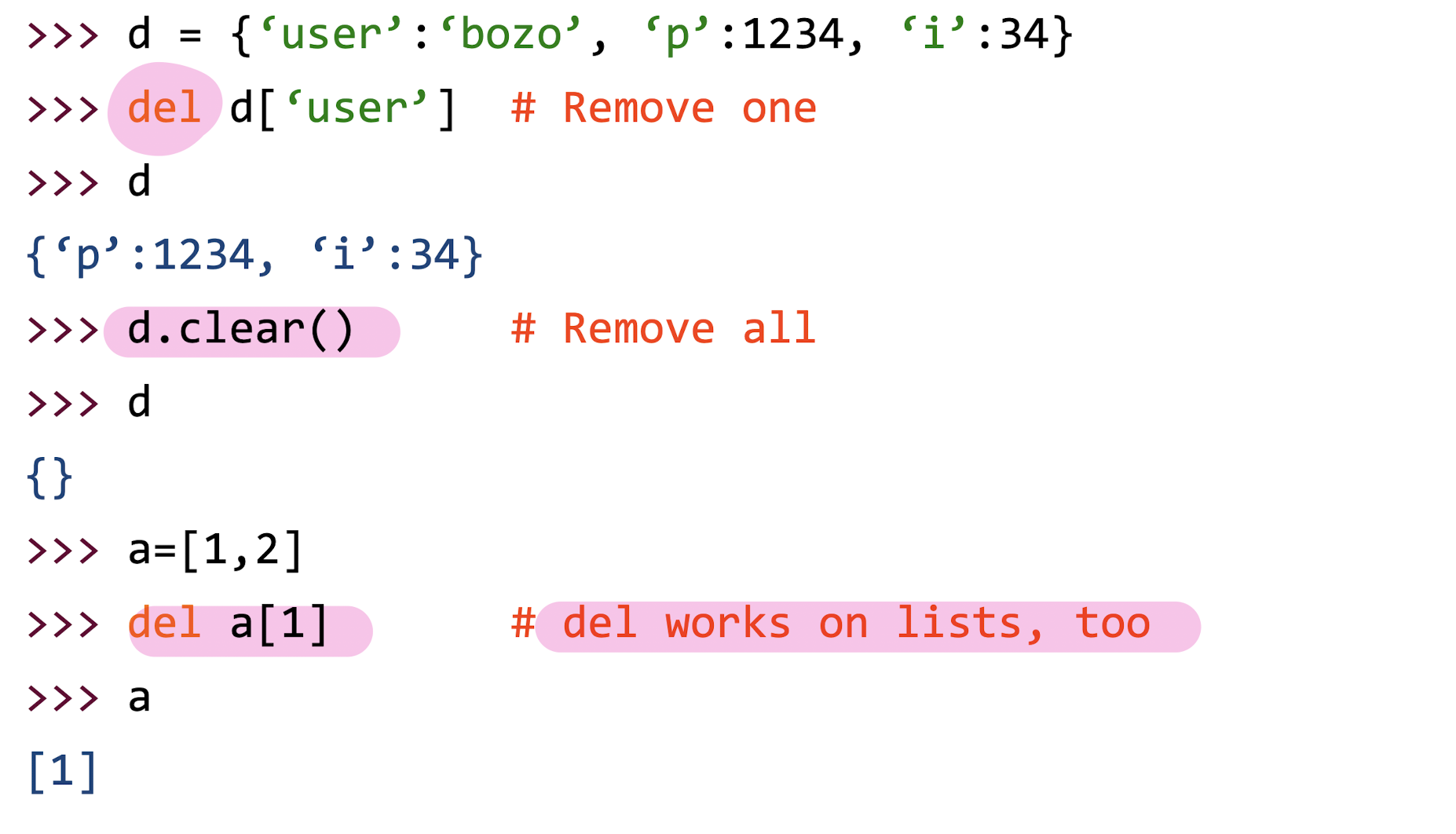
3. Python Backgrounds























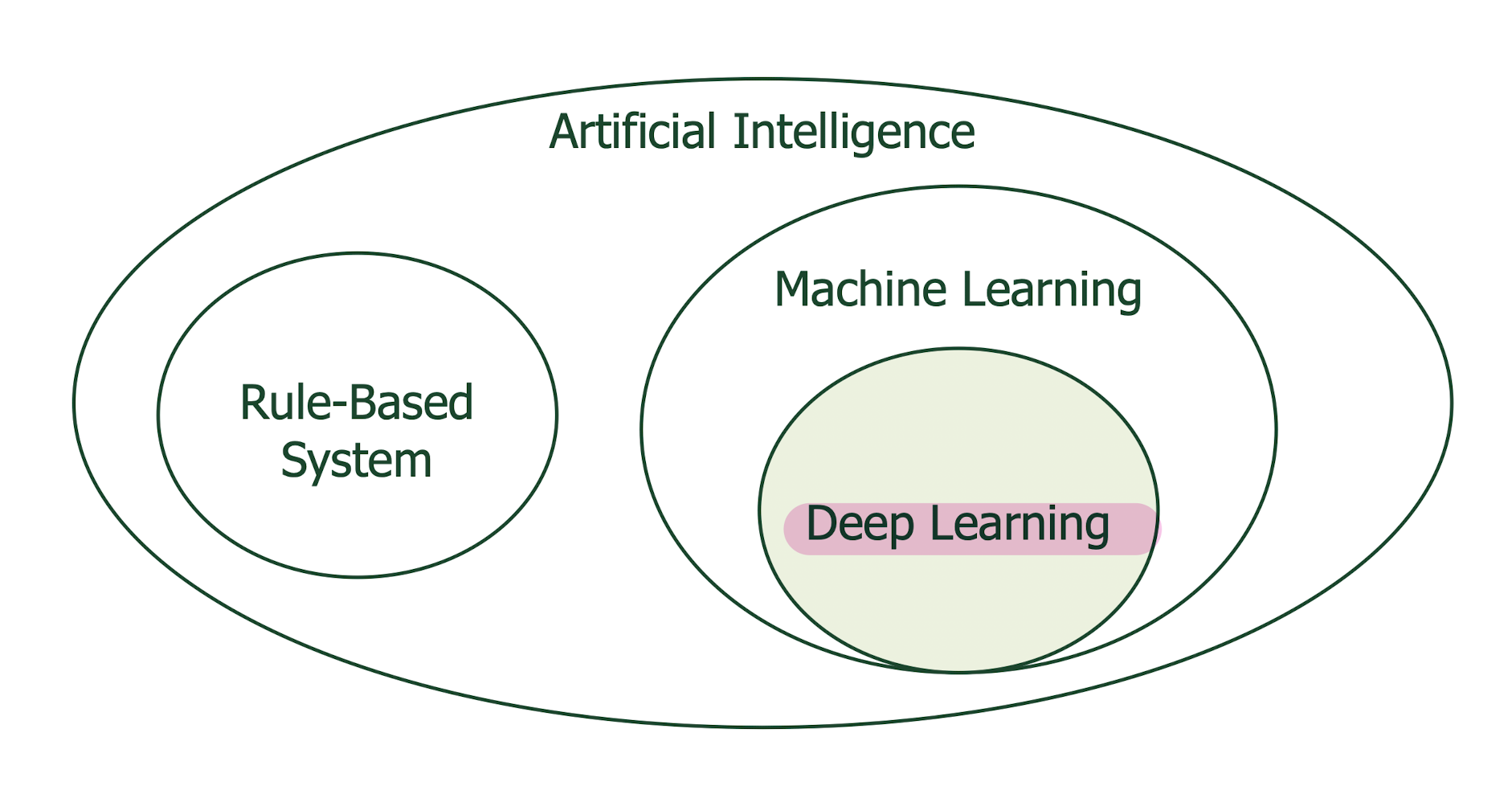
4. Introduction to Deep Learning


5. neural Network Basics
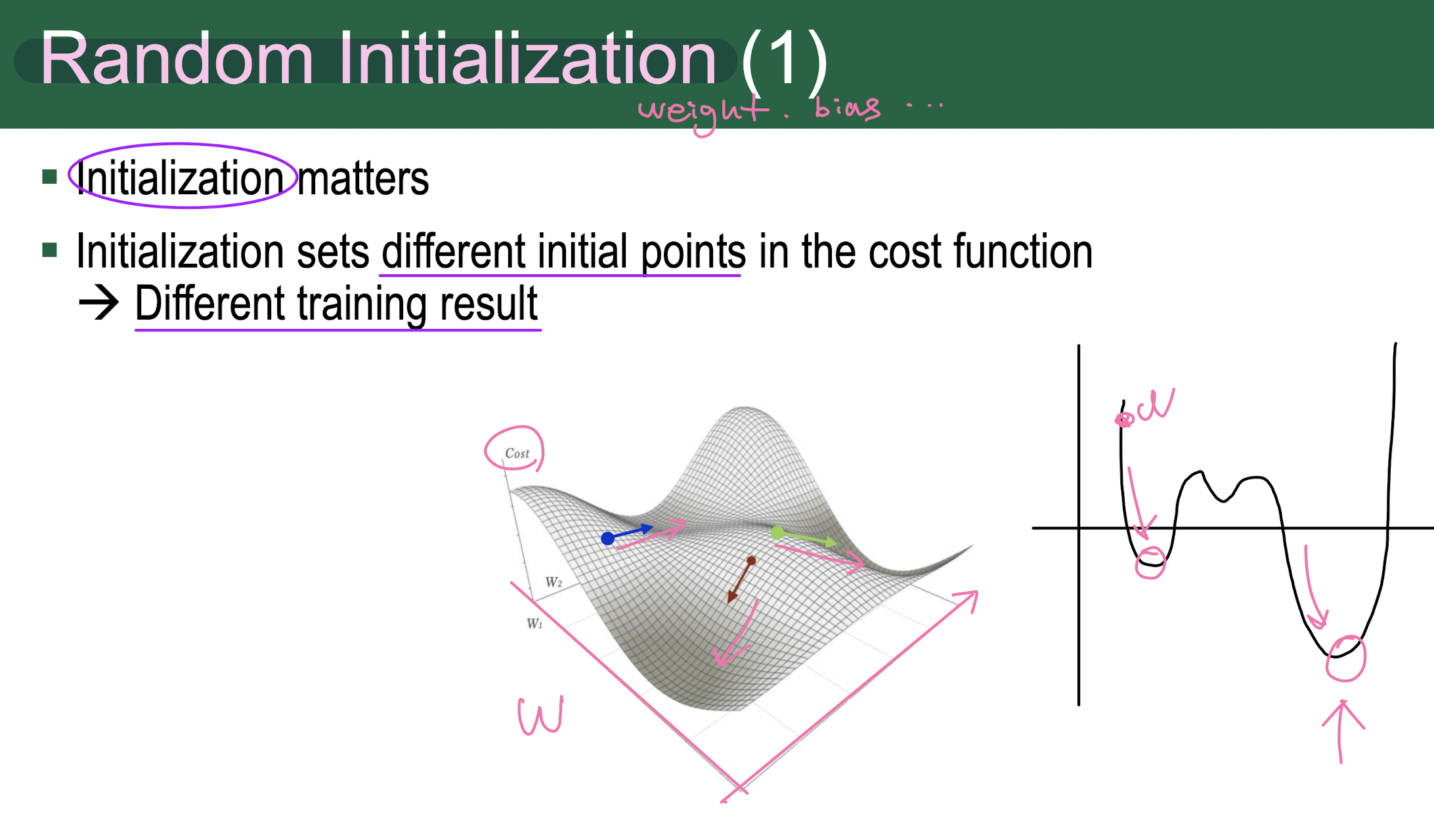
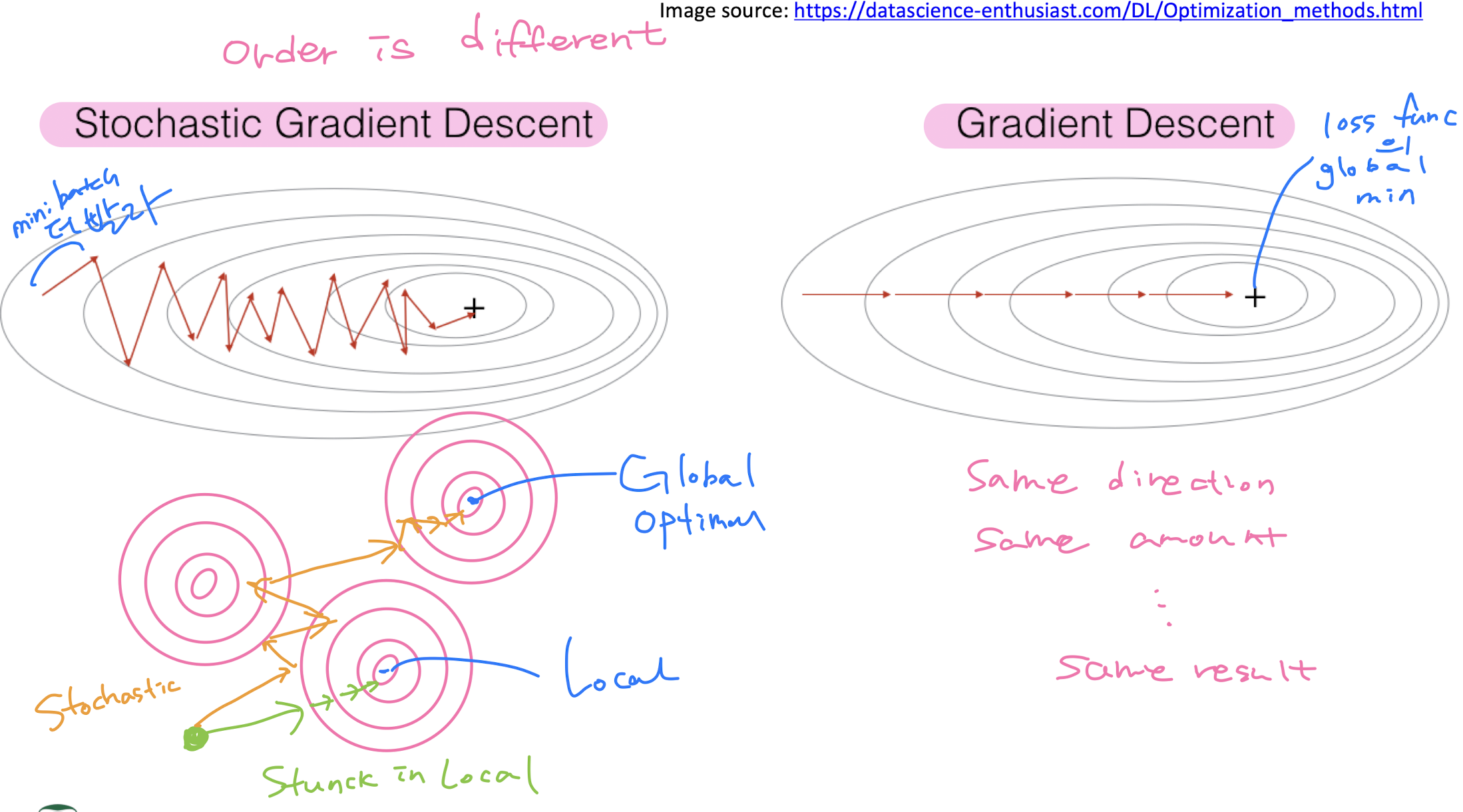
Gradient Descent
: A famous optimization algorithm to minimize a cost function by iteratively moving in the direction of steepest descent as mathematically defined by the negative gradient

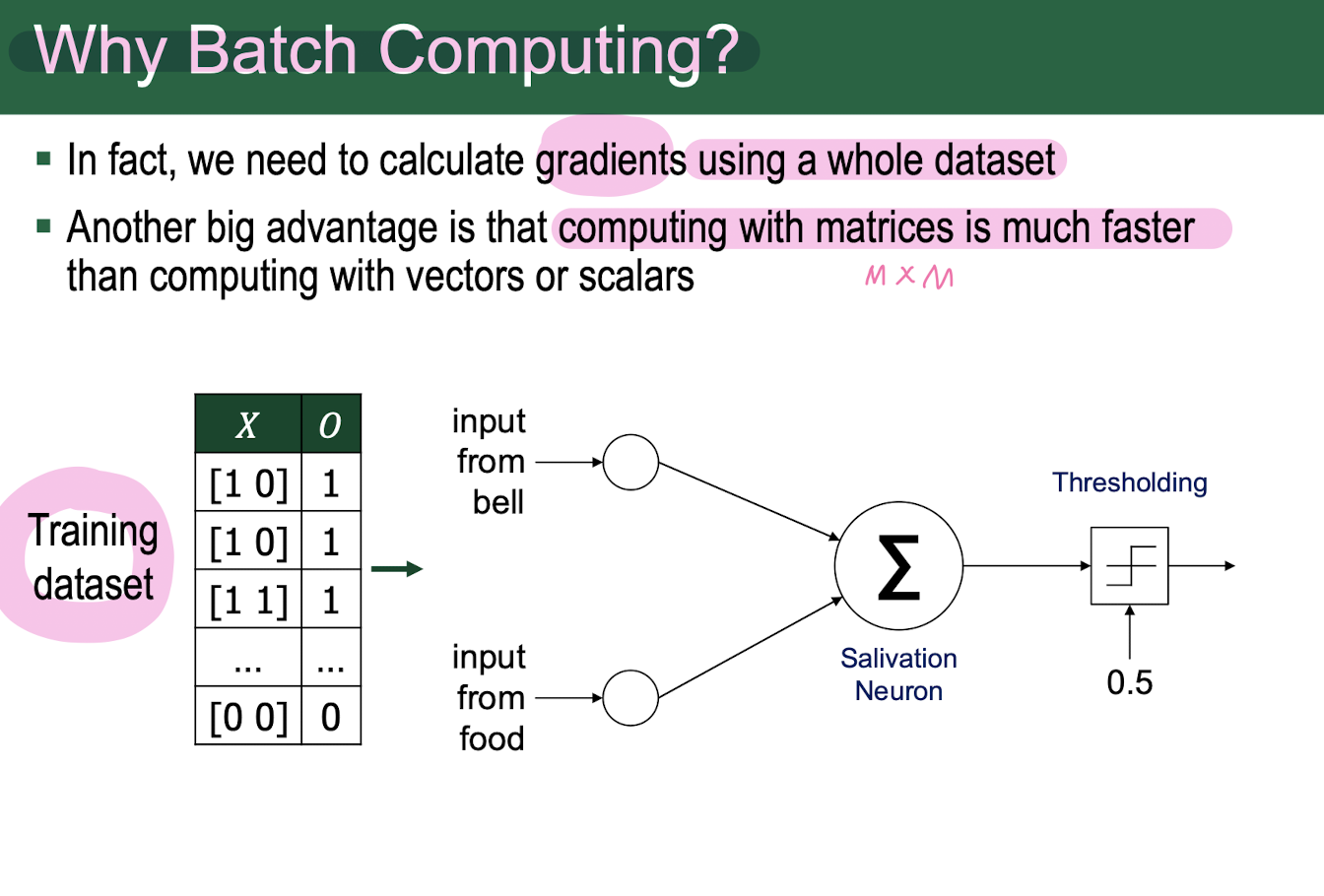
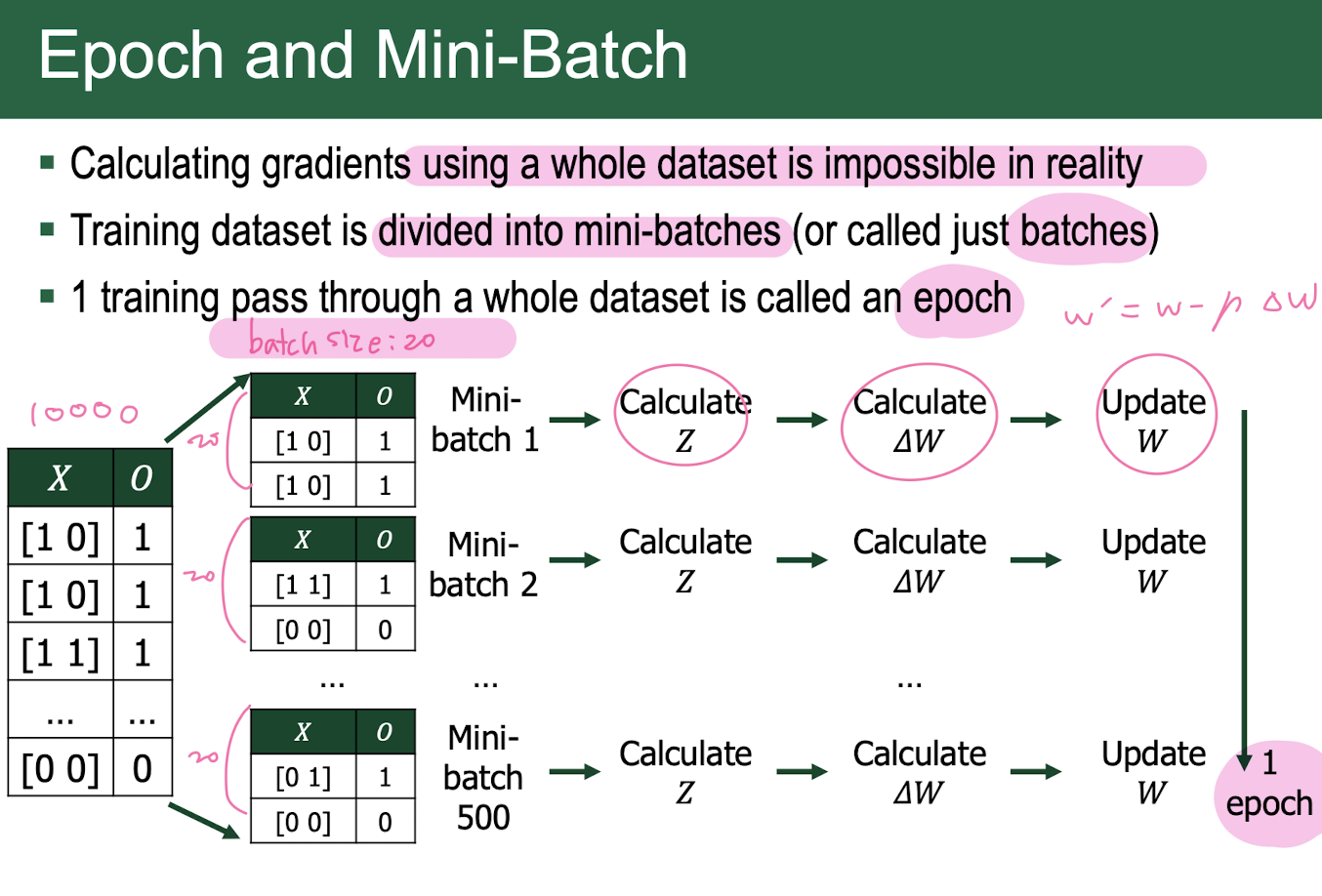
Batch
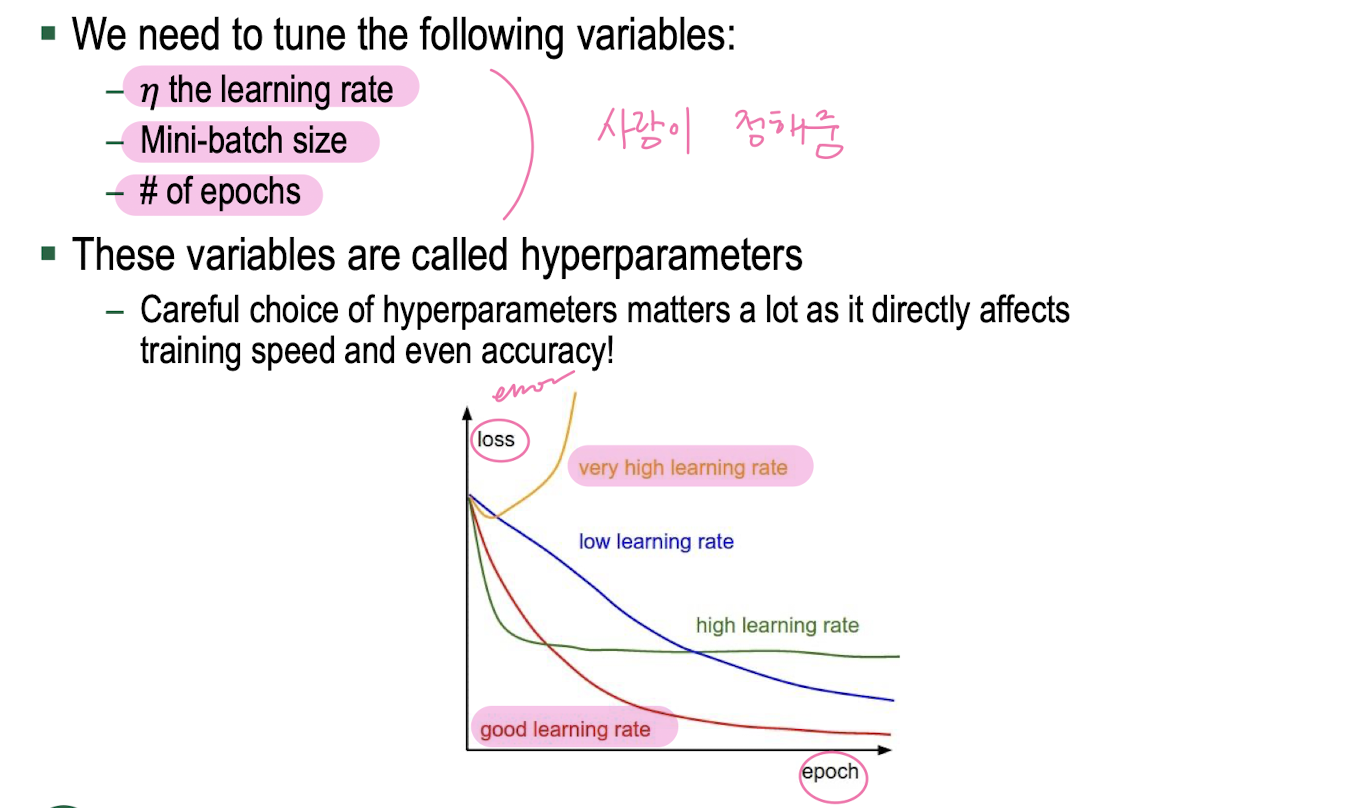
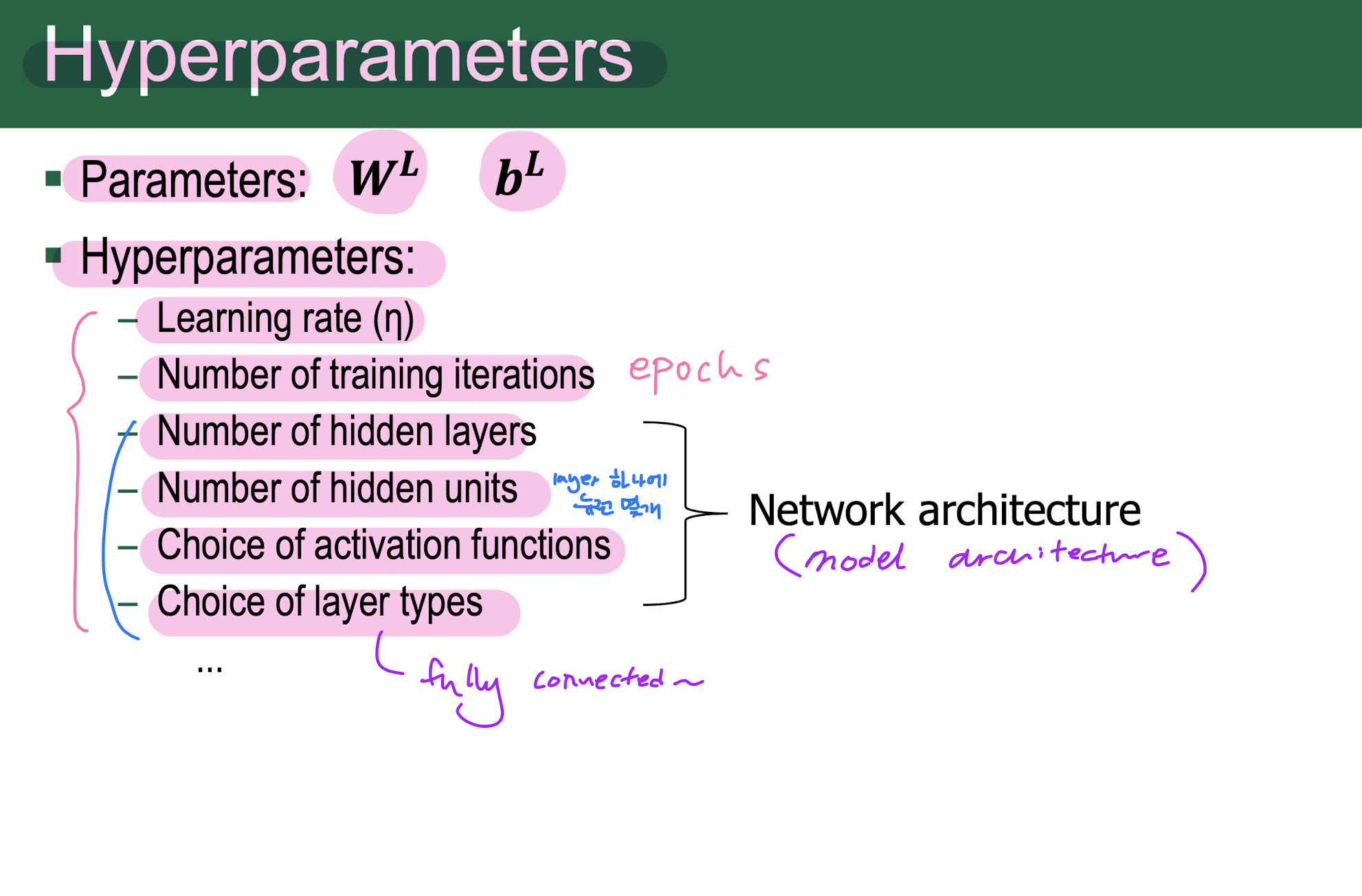
Hyperparameters
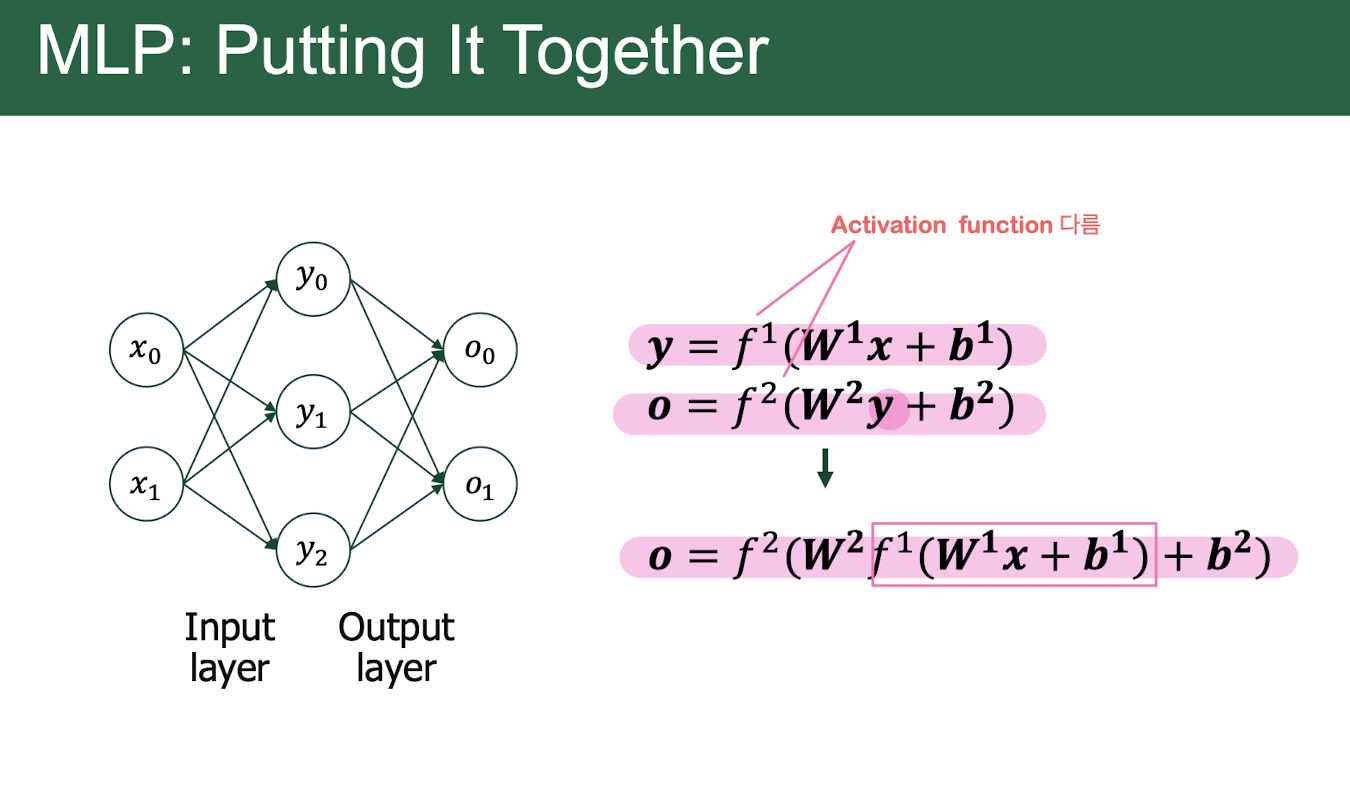
6. Multi-Layer Perceptron
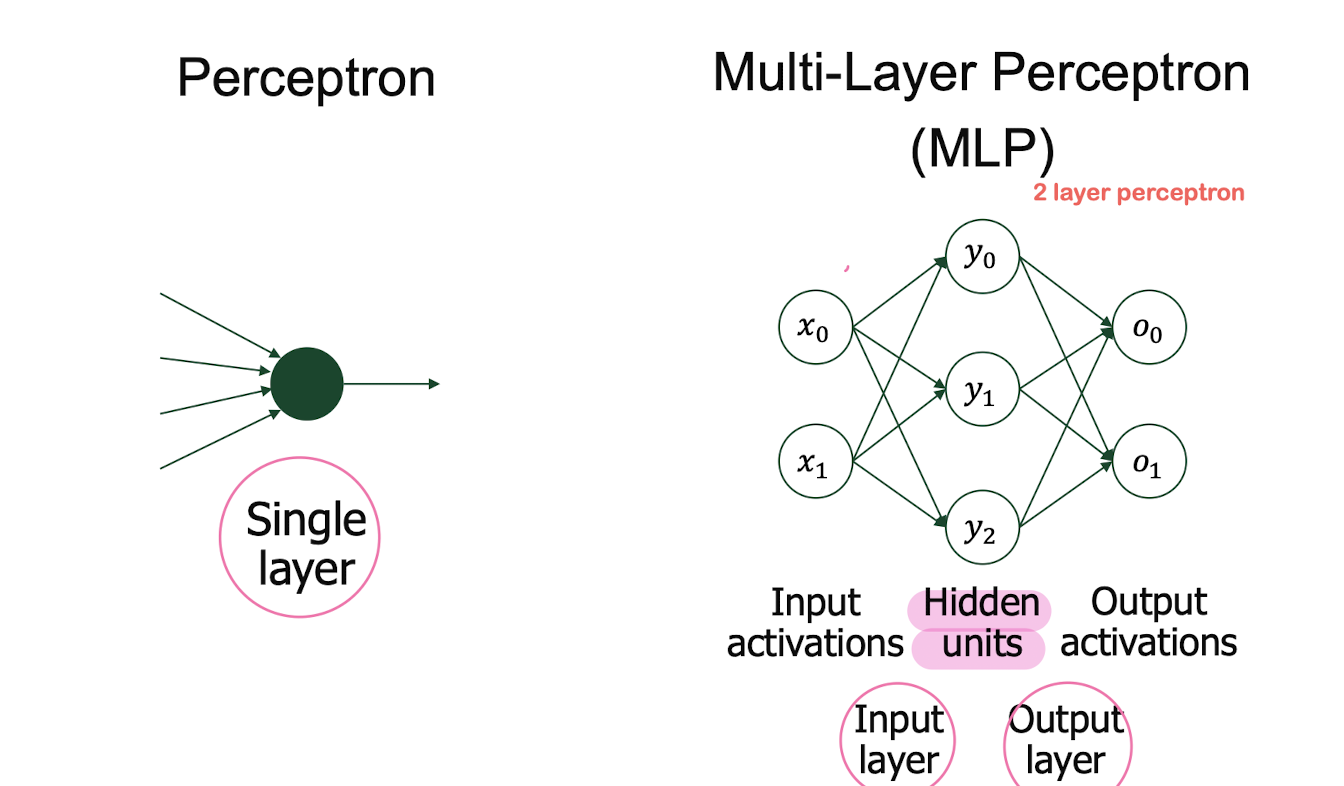
Multi-layer perceptron (MLP)
The need for mutiple layer (XOR problem)
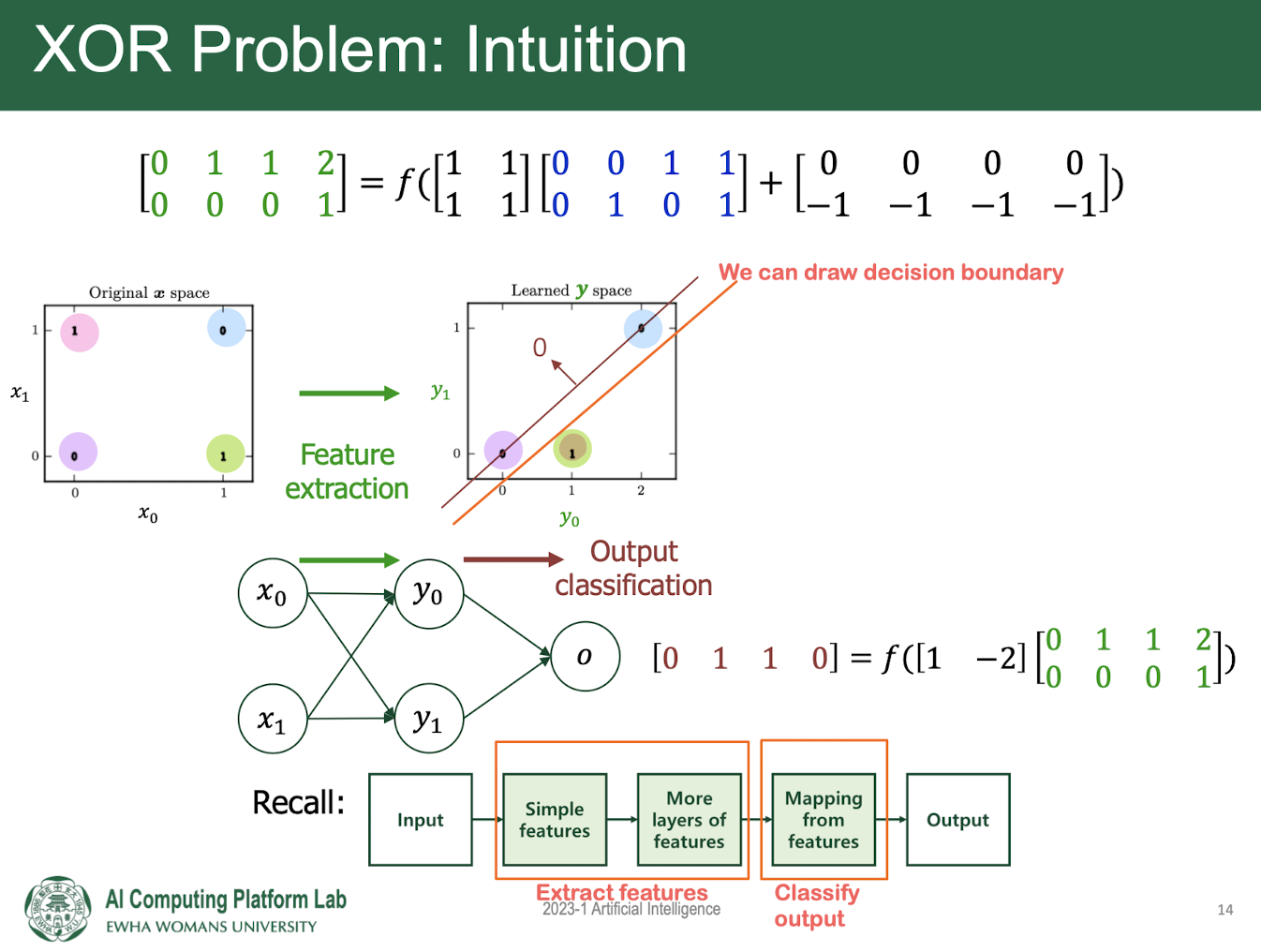
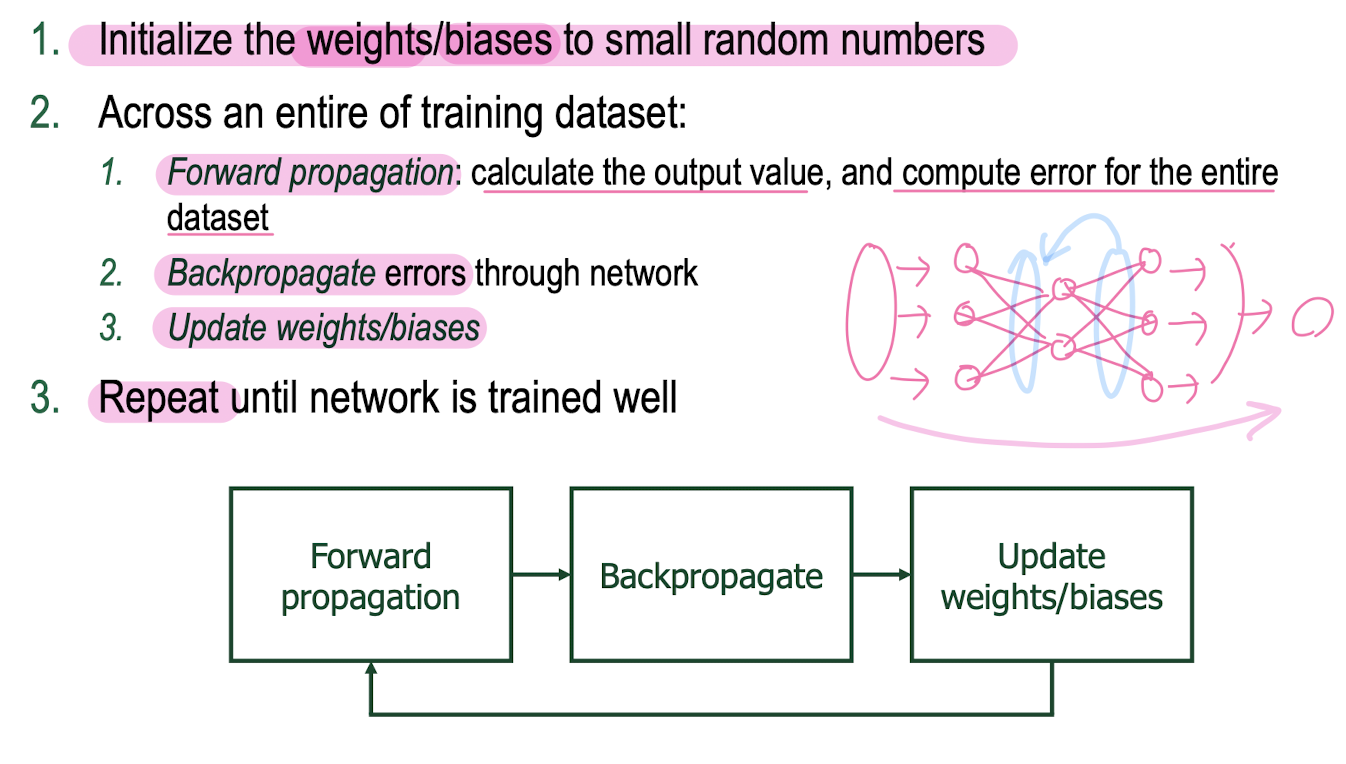
MLP: Training
: finding weight/bias matrices given training data to achieve our goal
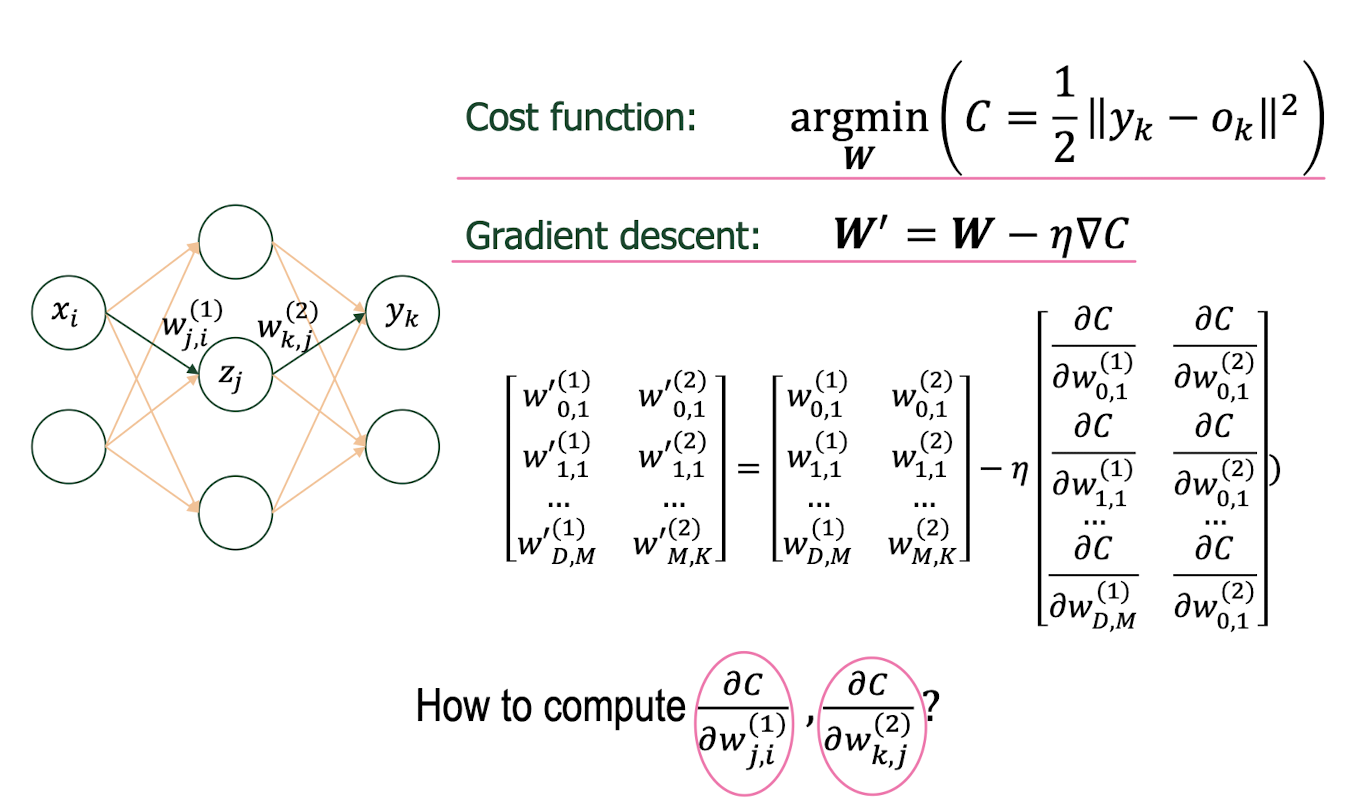
Gradient Descent: MLP



7. Deep Neural Networks



0으로 초기화 하면 안됨.
tanh, relU 는 weight가 0에서 영원히 멈추고,
sigmoid는 weight가 똑같이 업데이트 됨


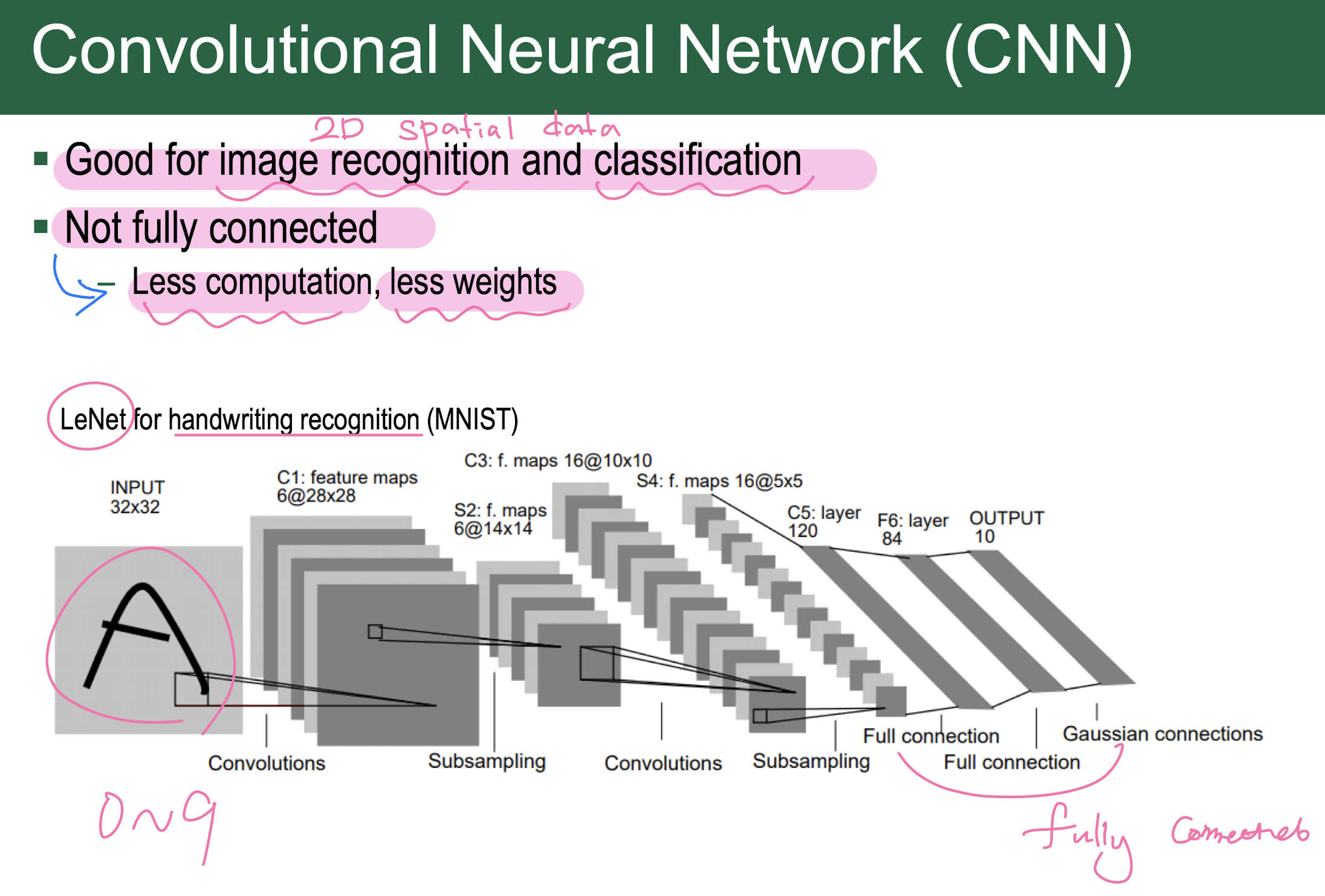
8. Convolutional Neural Network
Convolutional Neural Network (CNN)
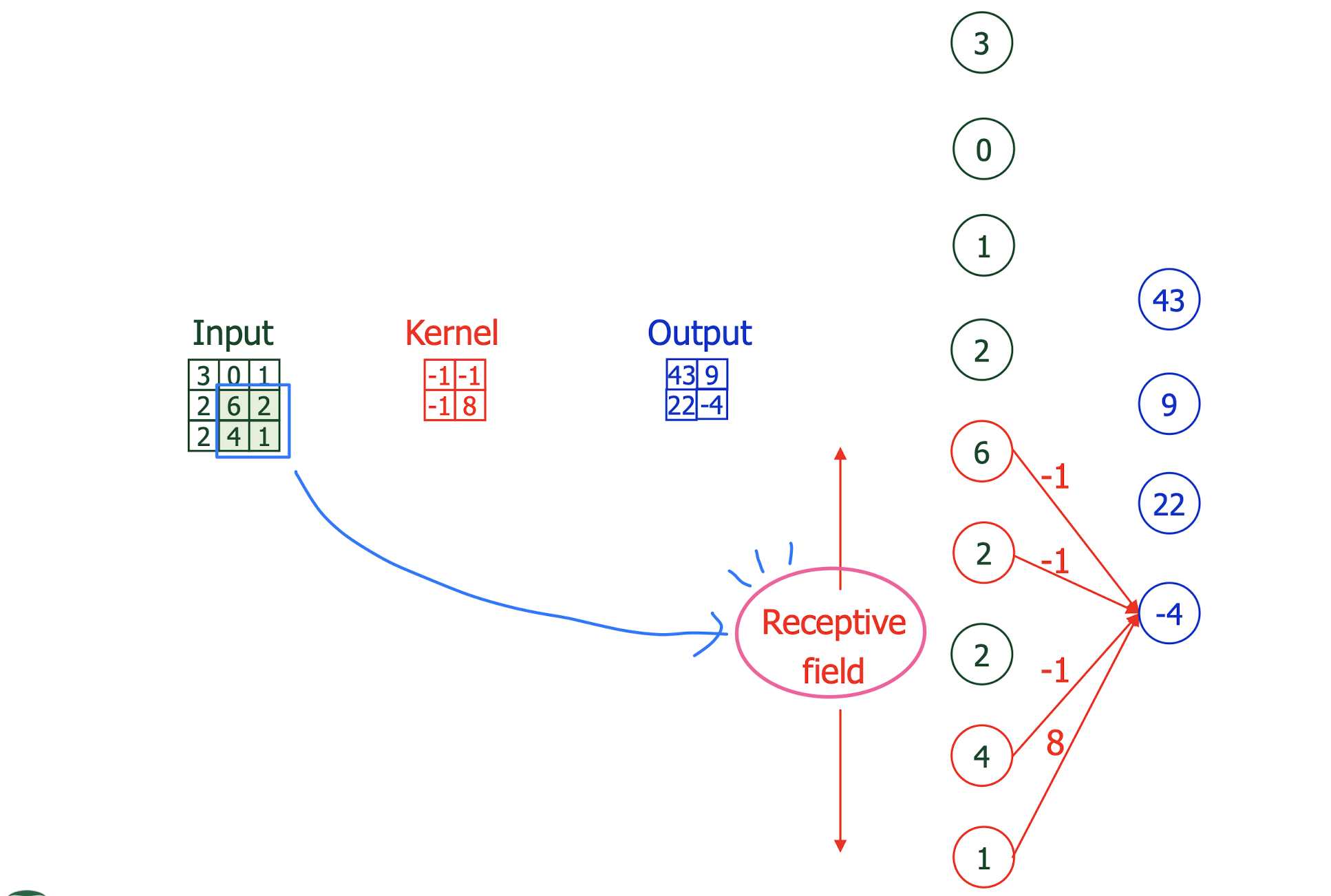
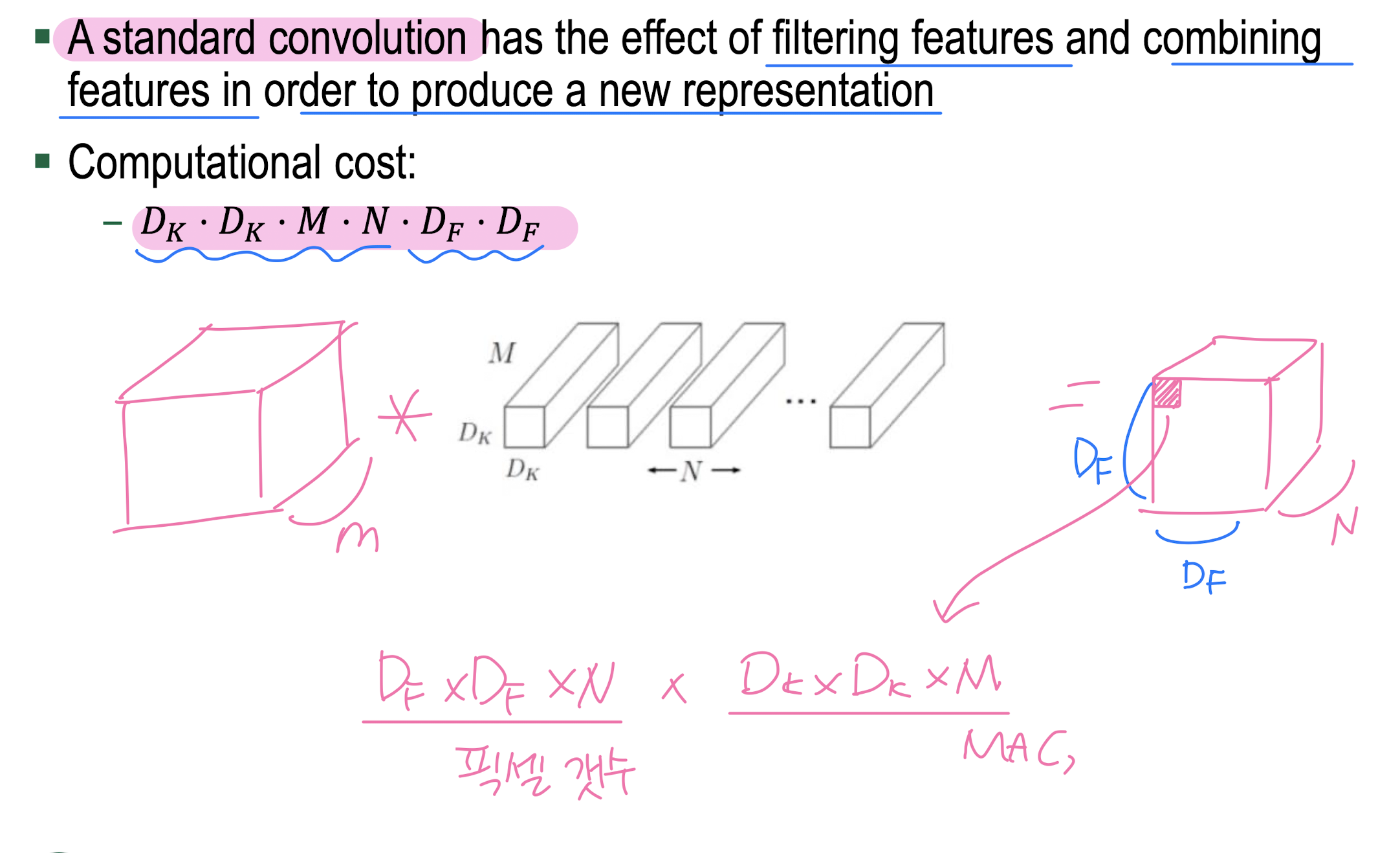
convolution (kernel)의 역할....>

CNN models
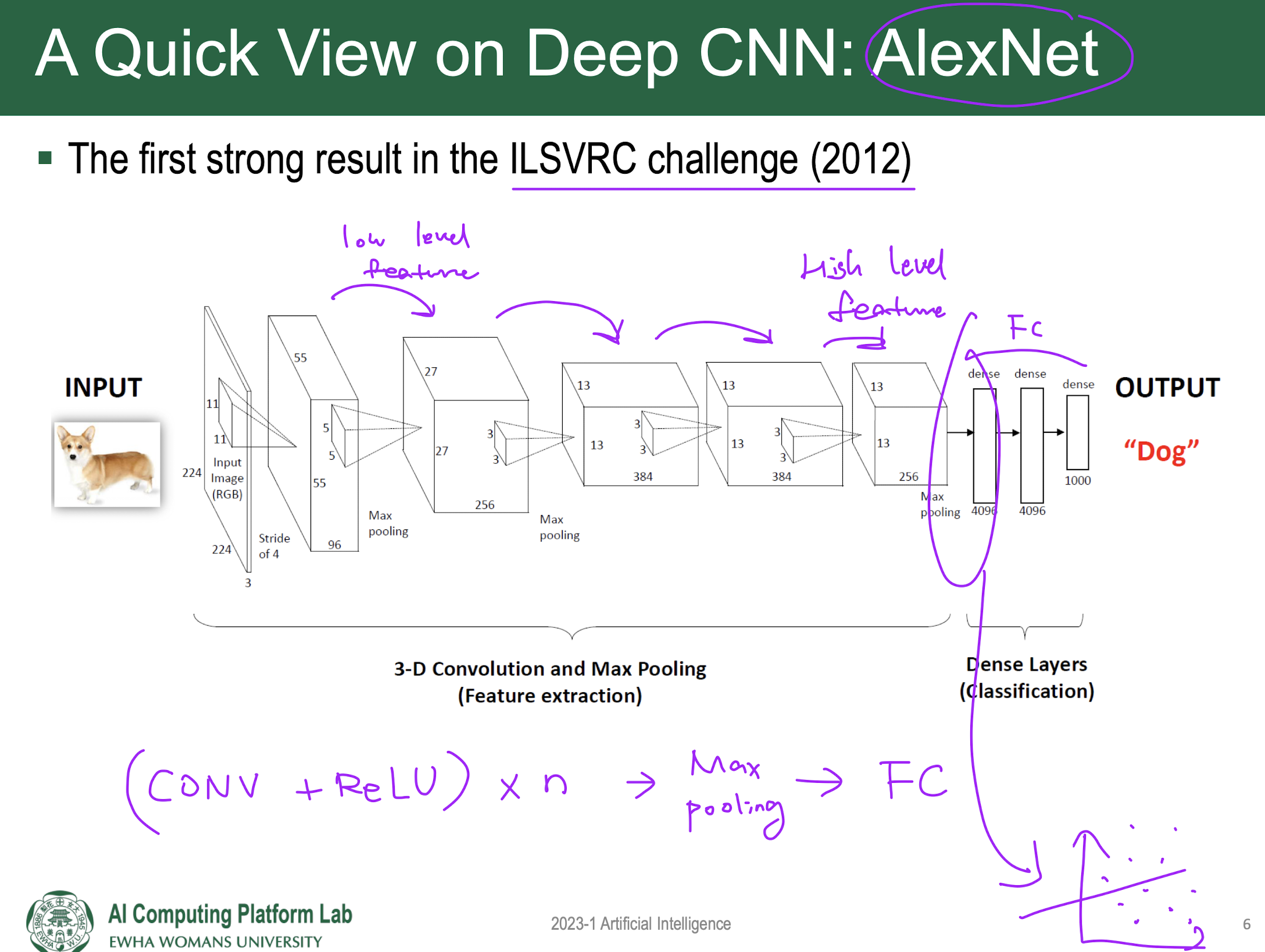
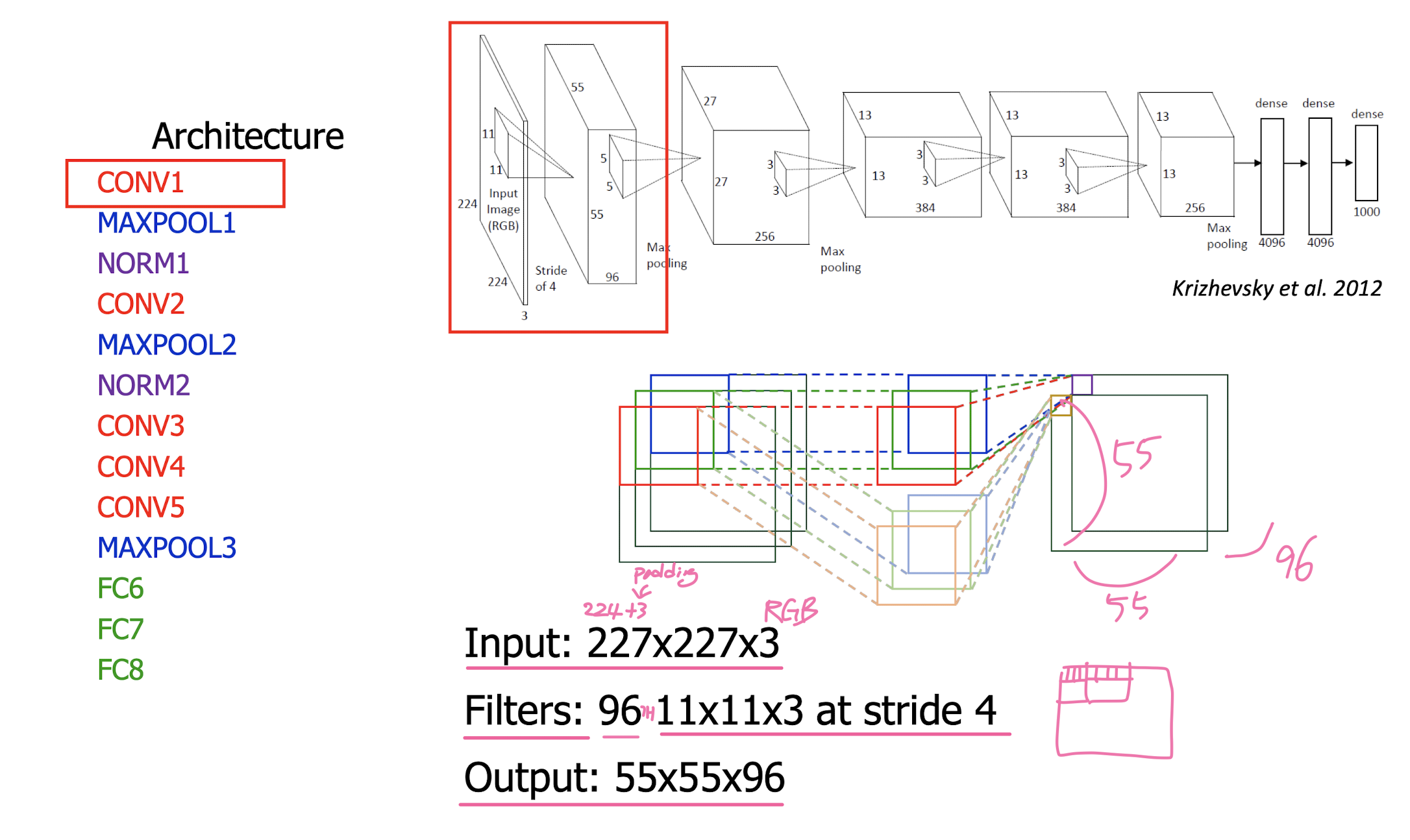
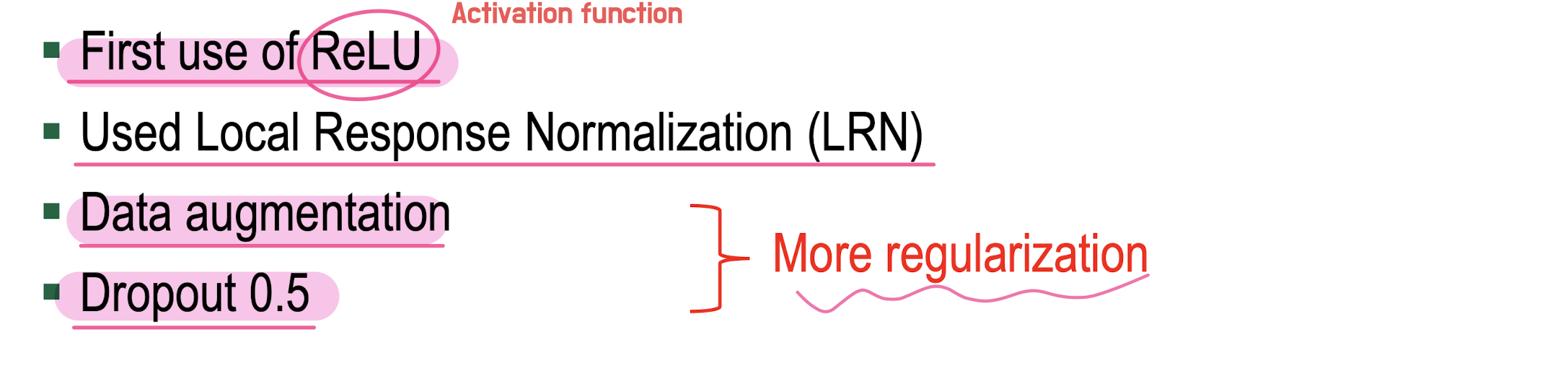
AlexNet

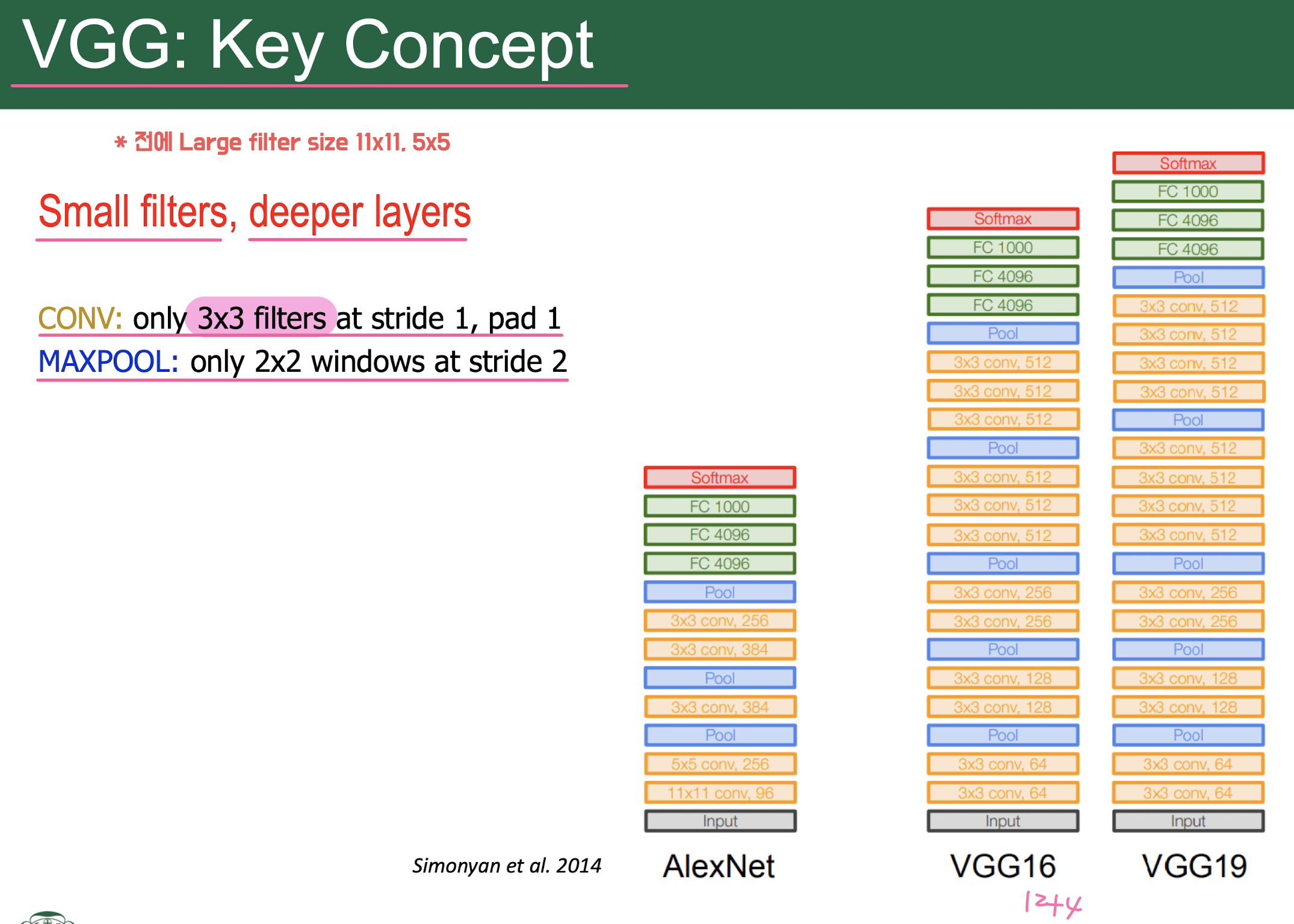
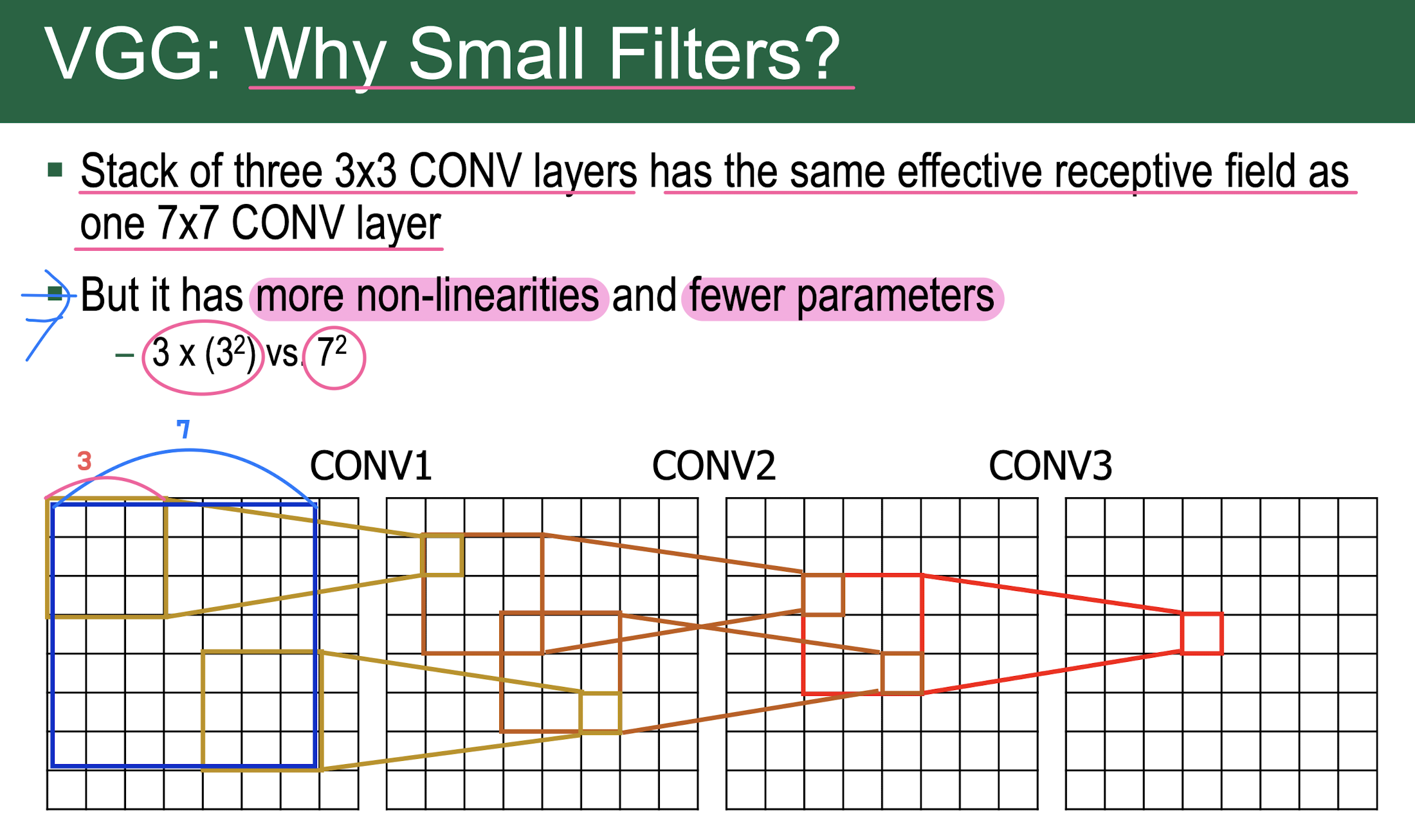
VGG
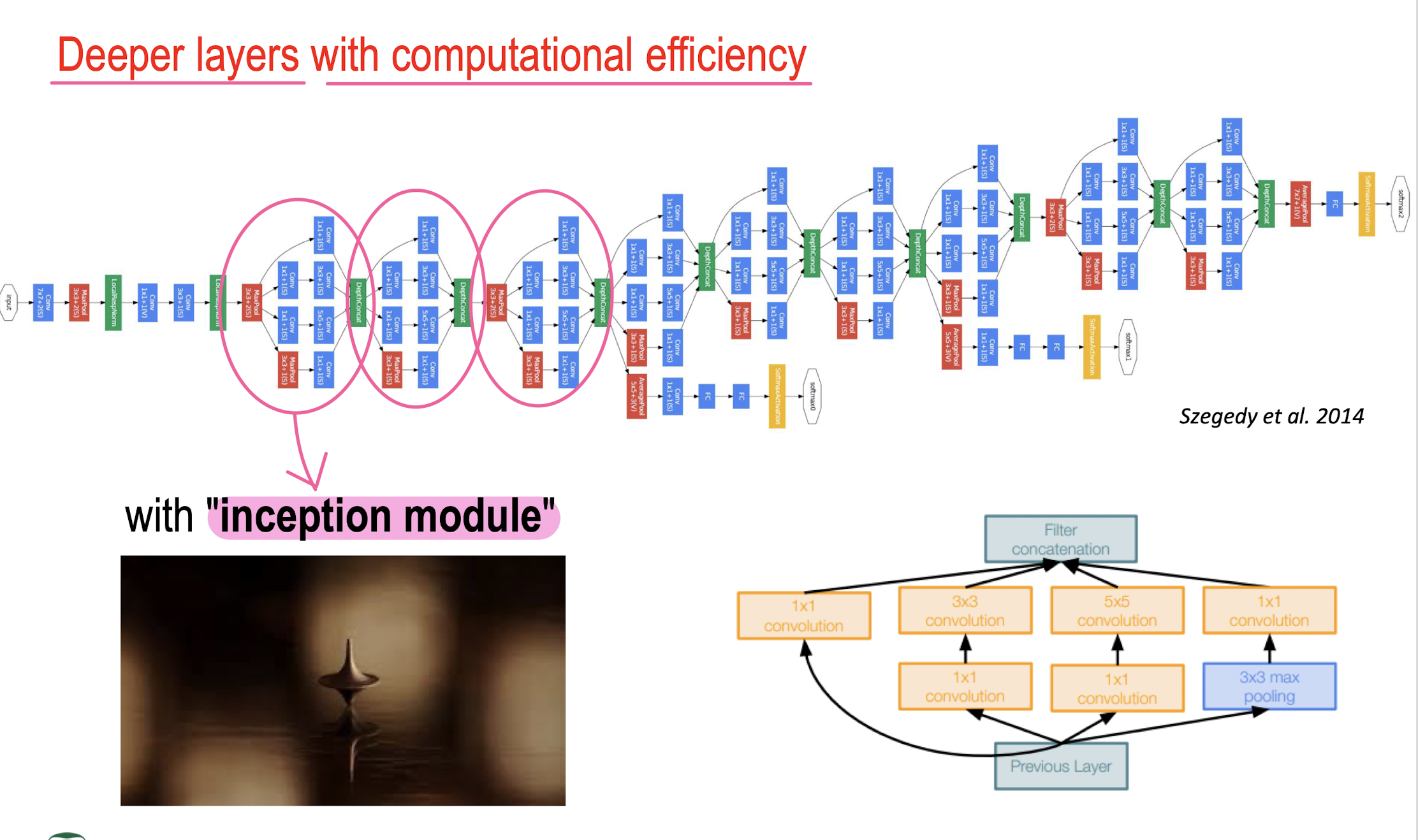
GoogLeNet – ResNet
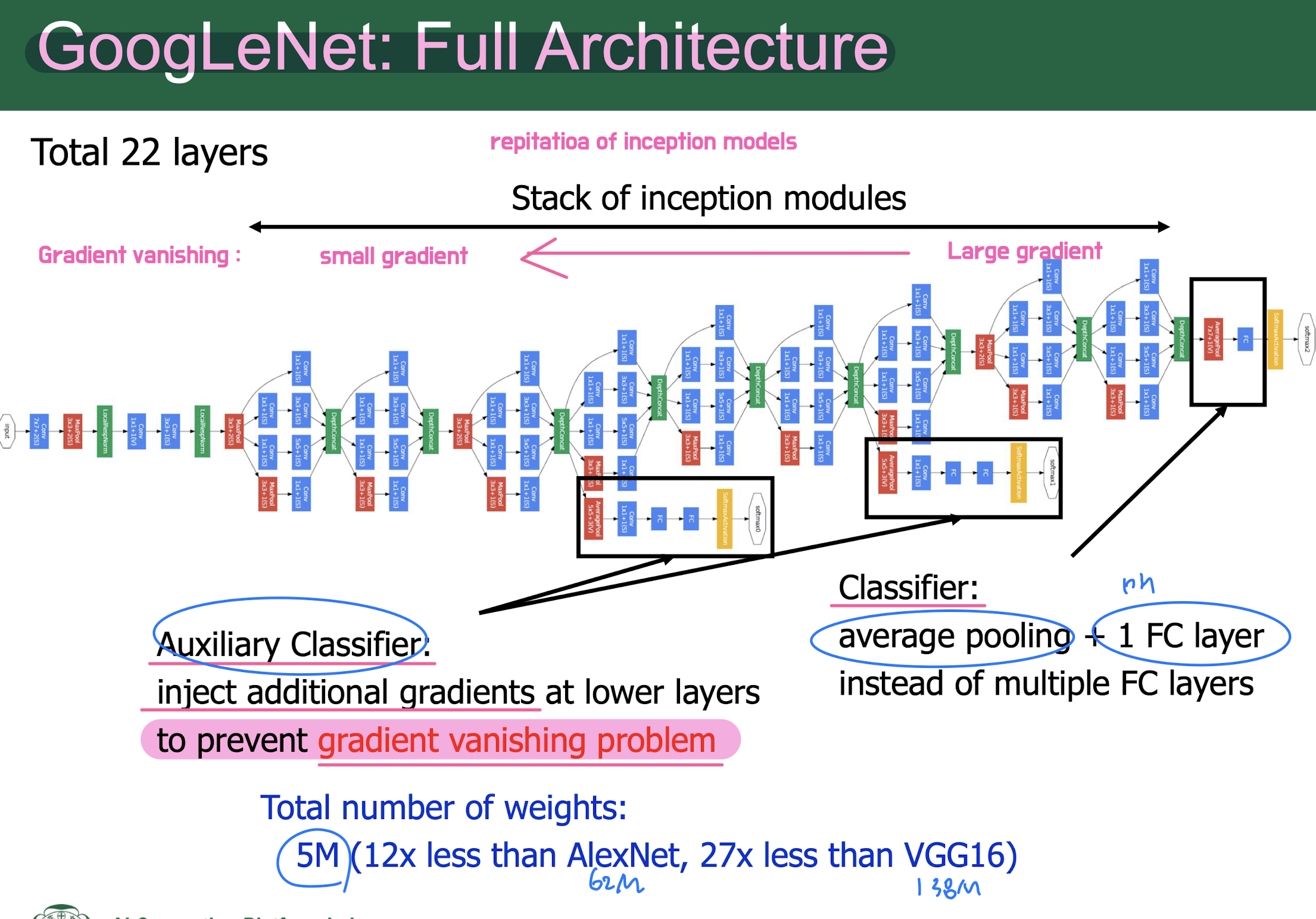
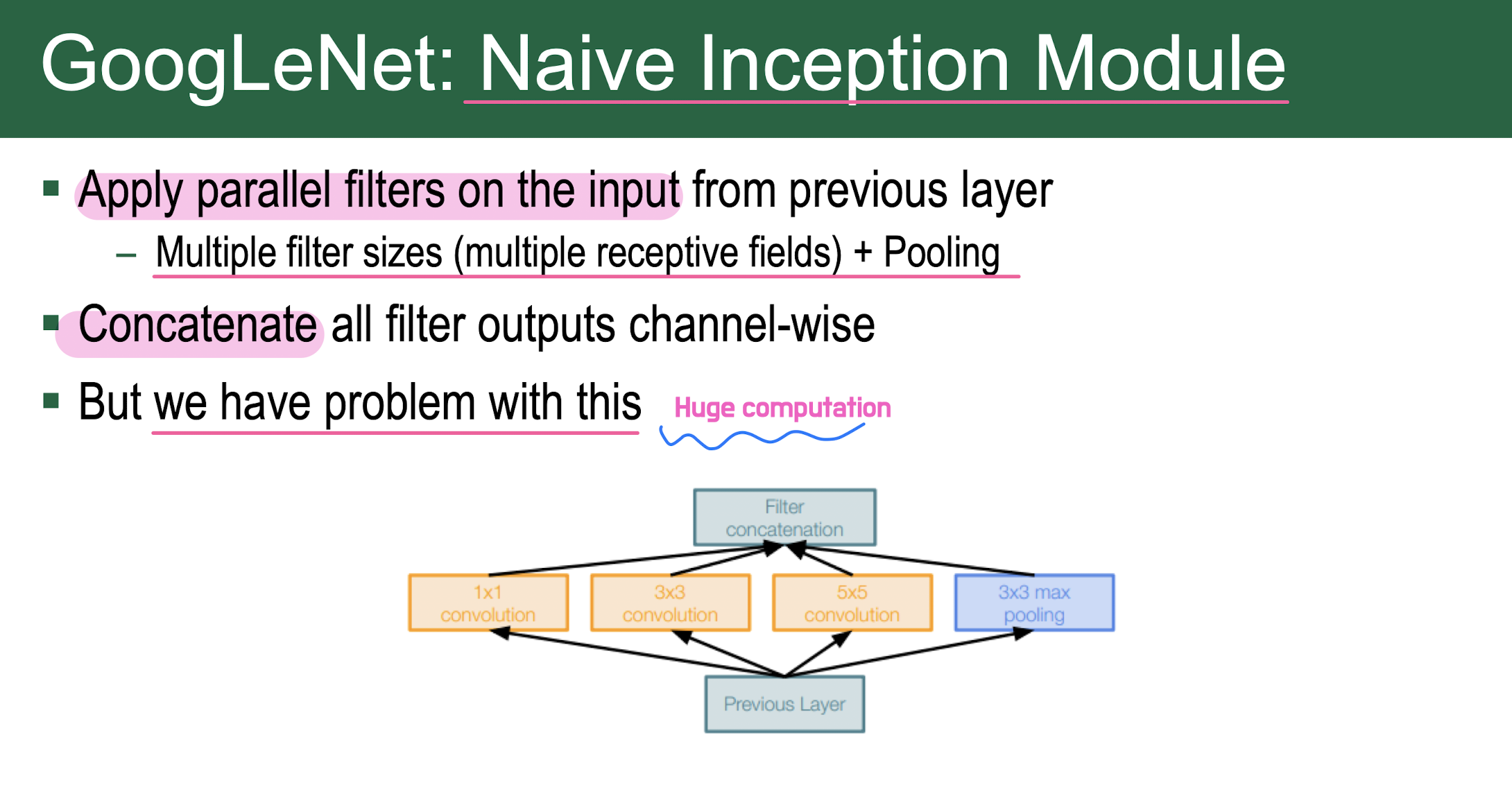
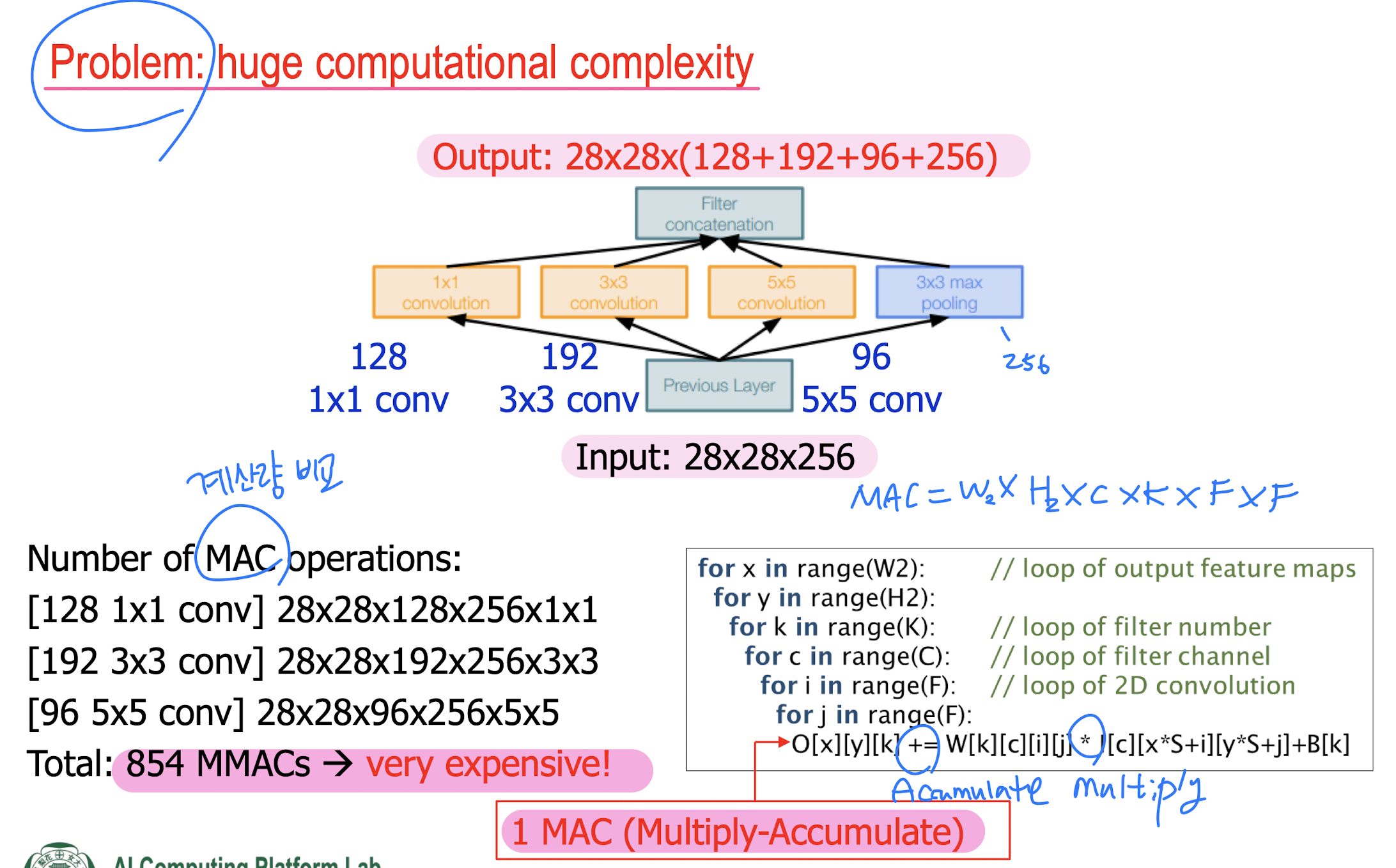
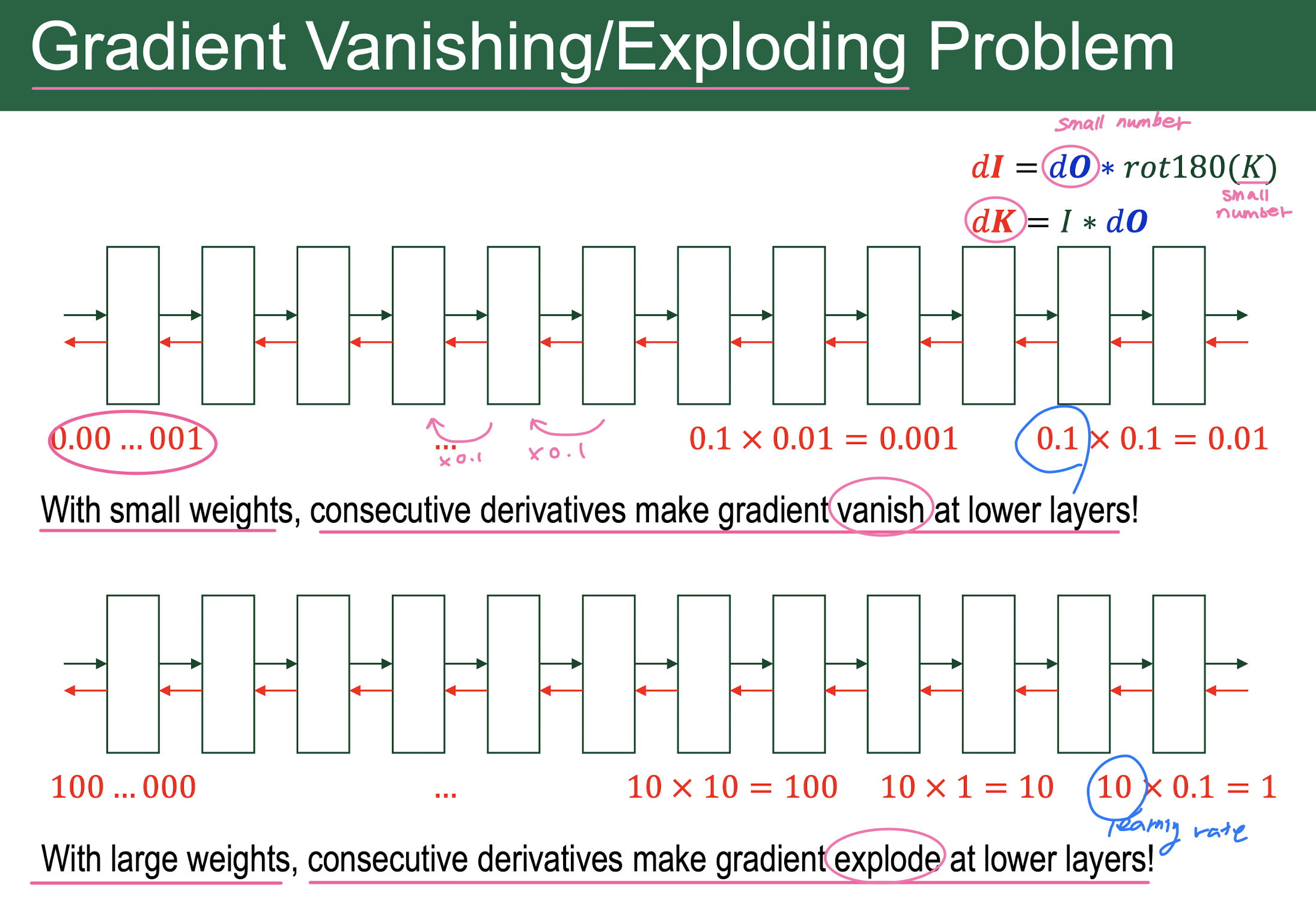
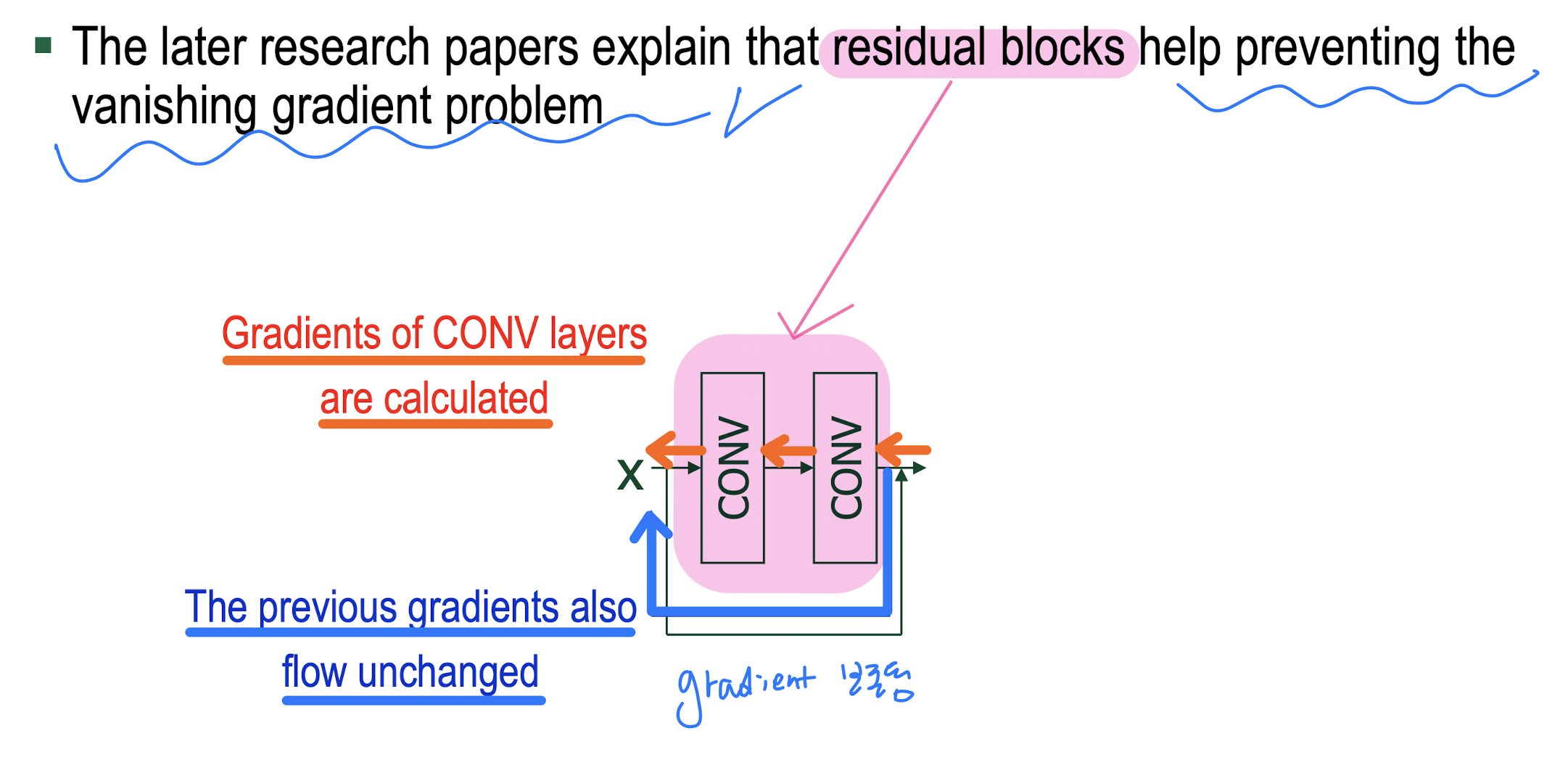
Gradient vanishing/exploding problem

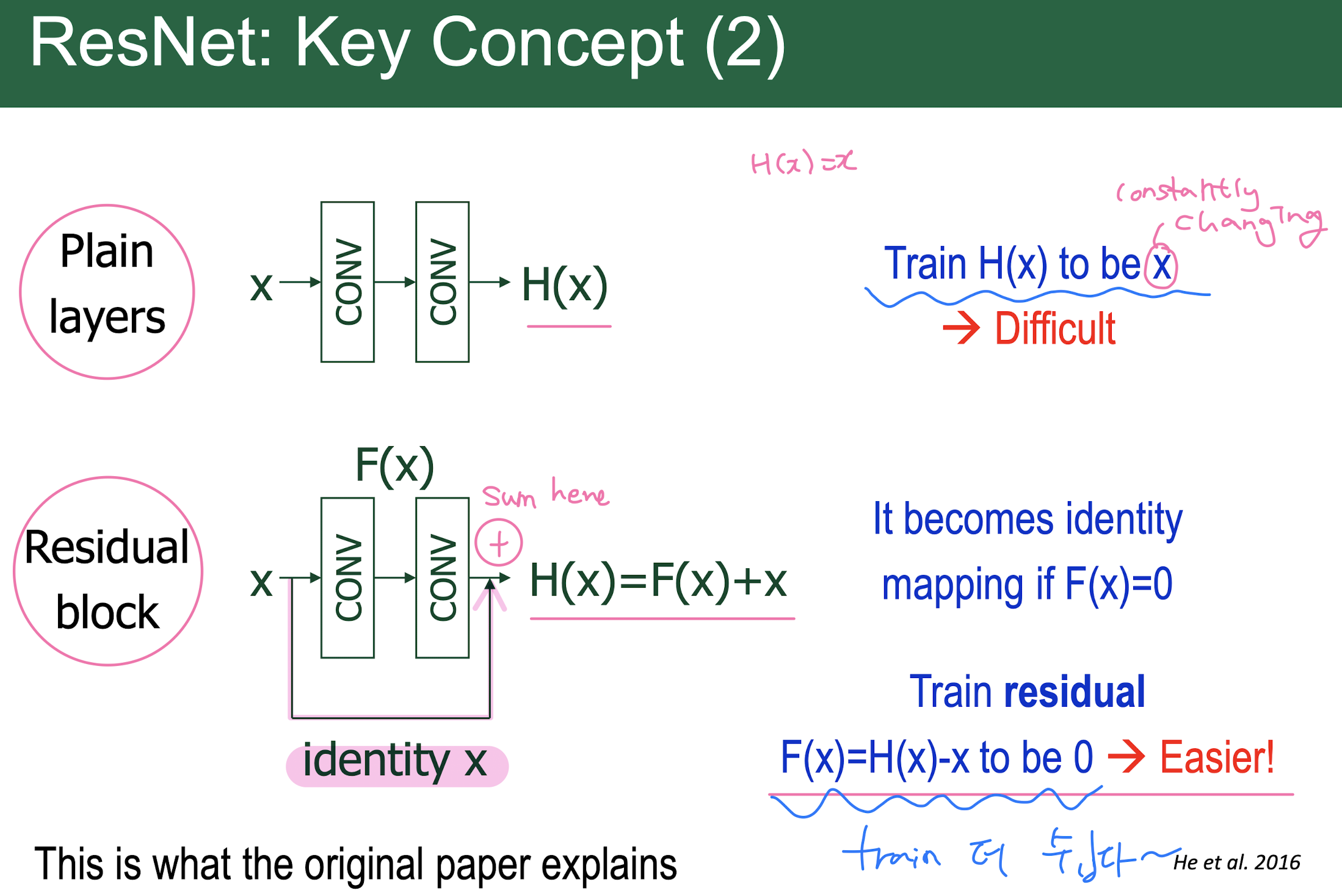
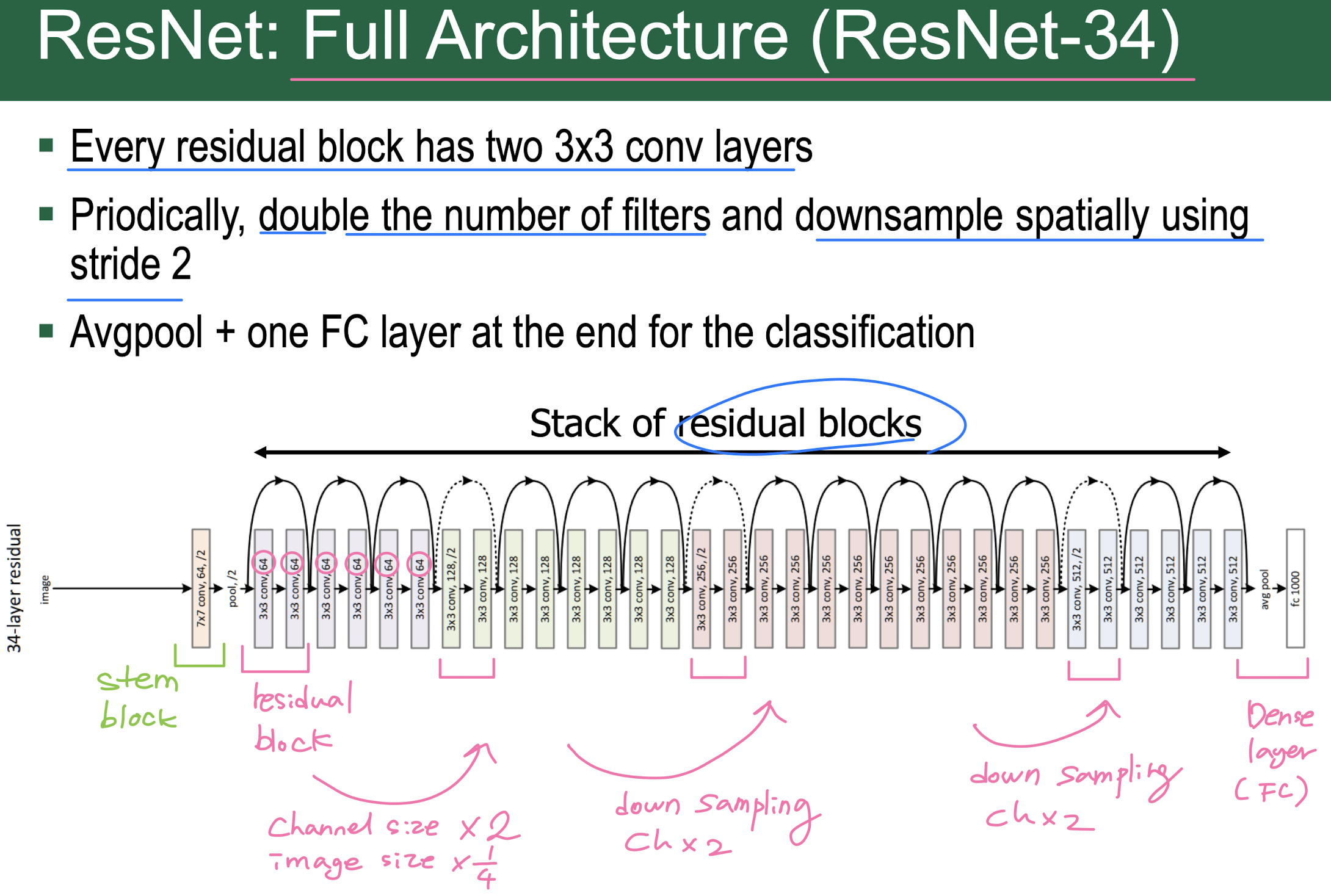
ResNet
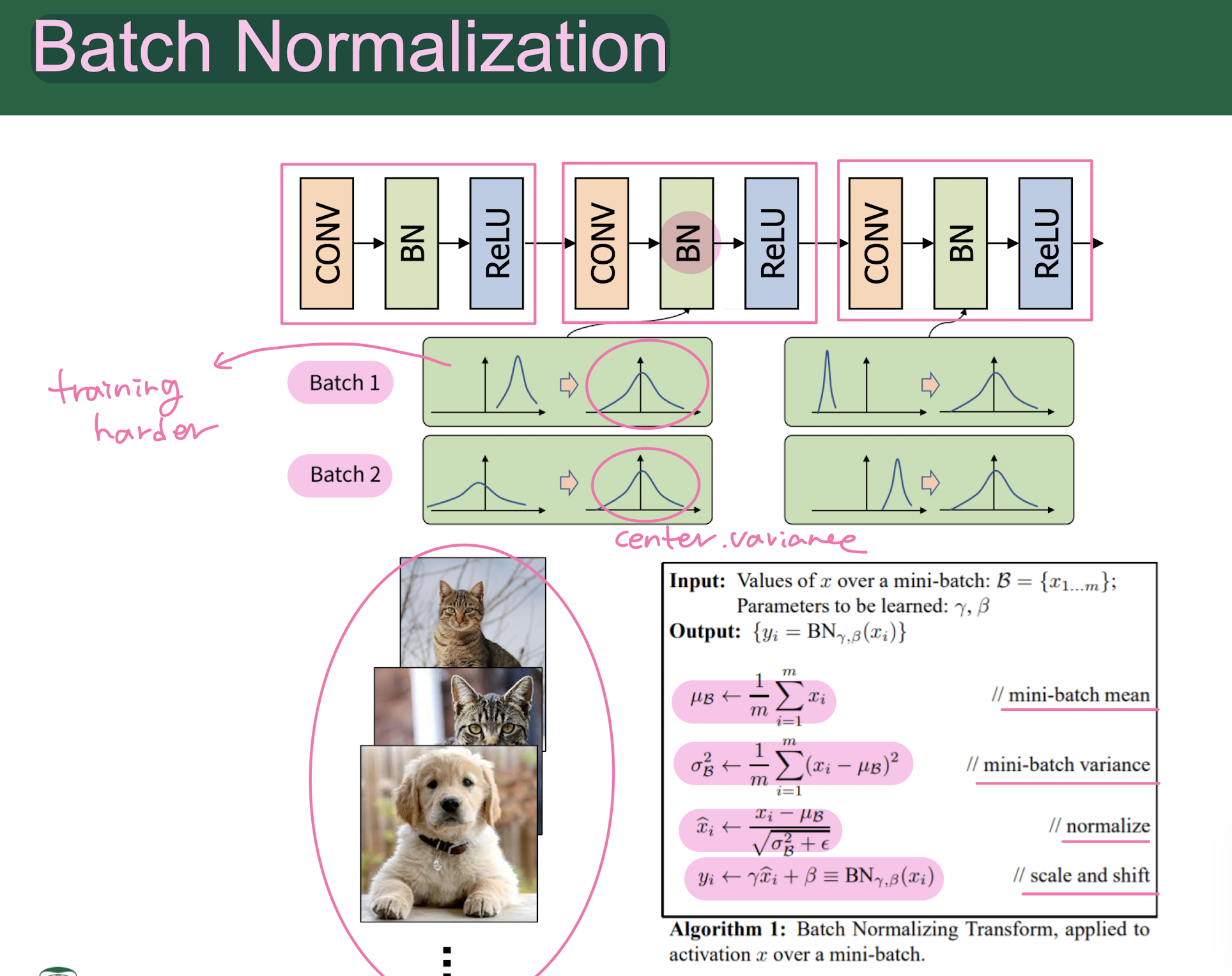
batch nomalization
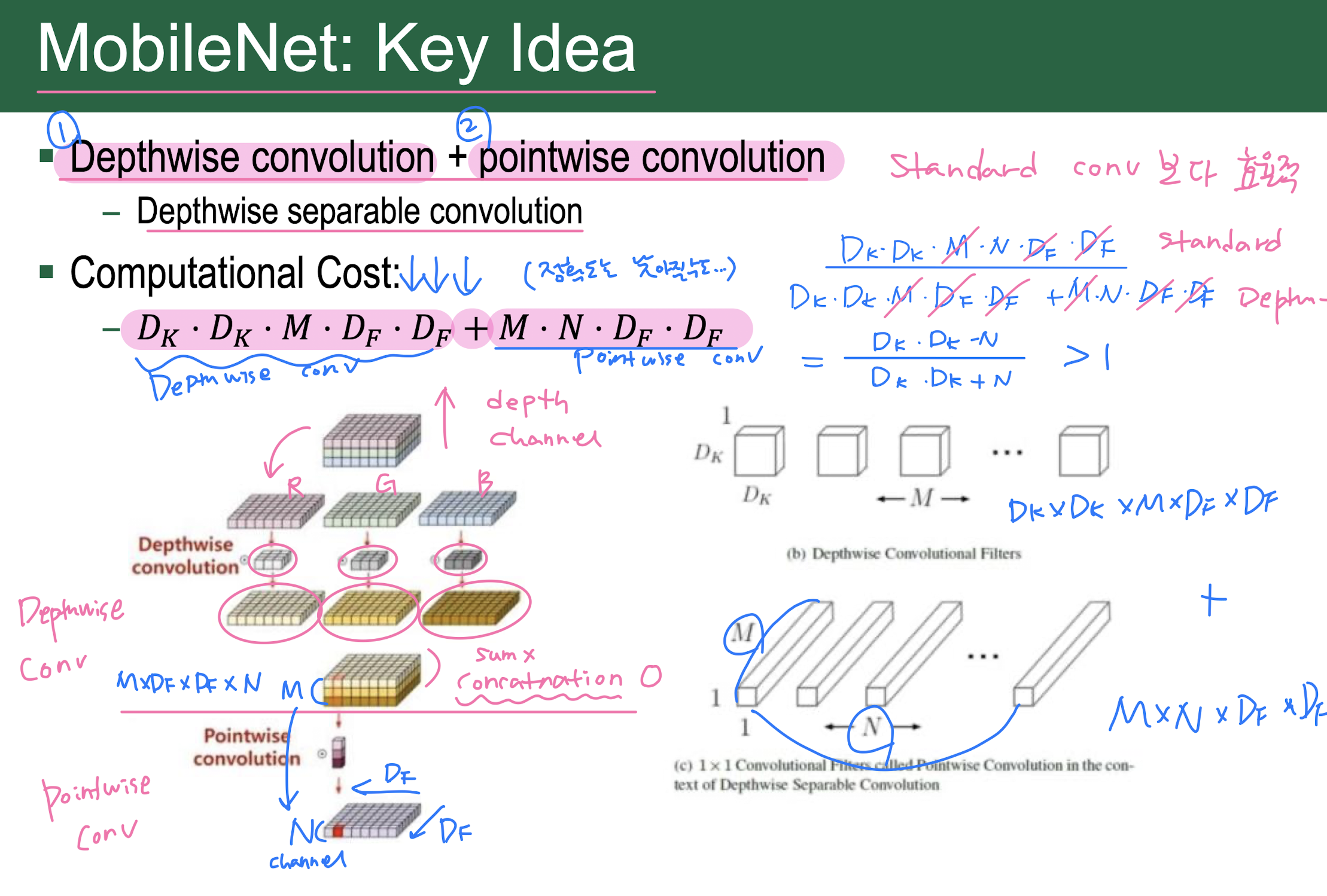
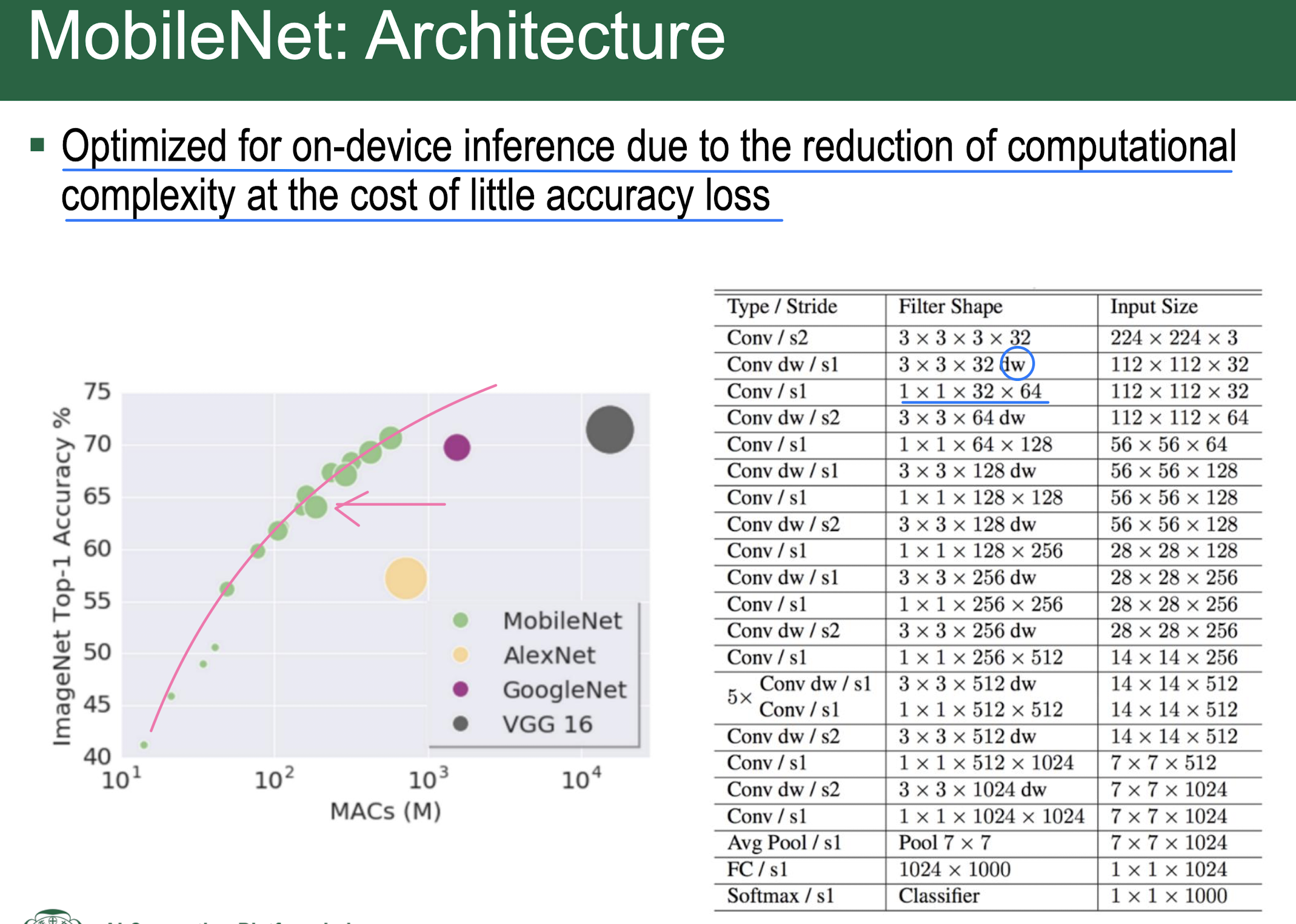
MobileNet
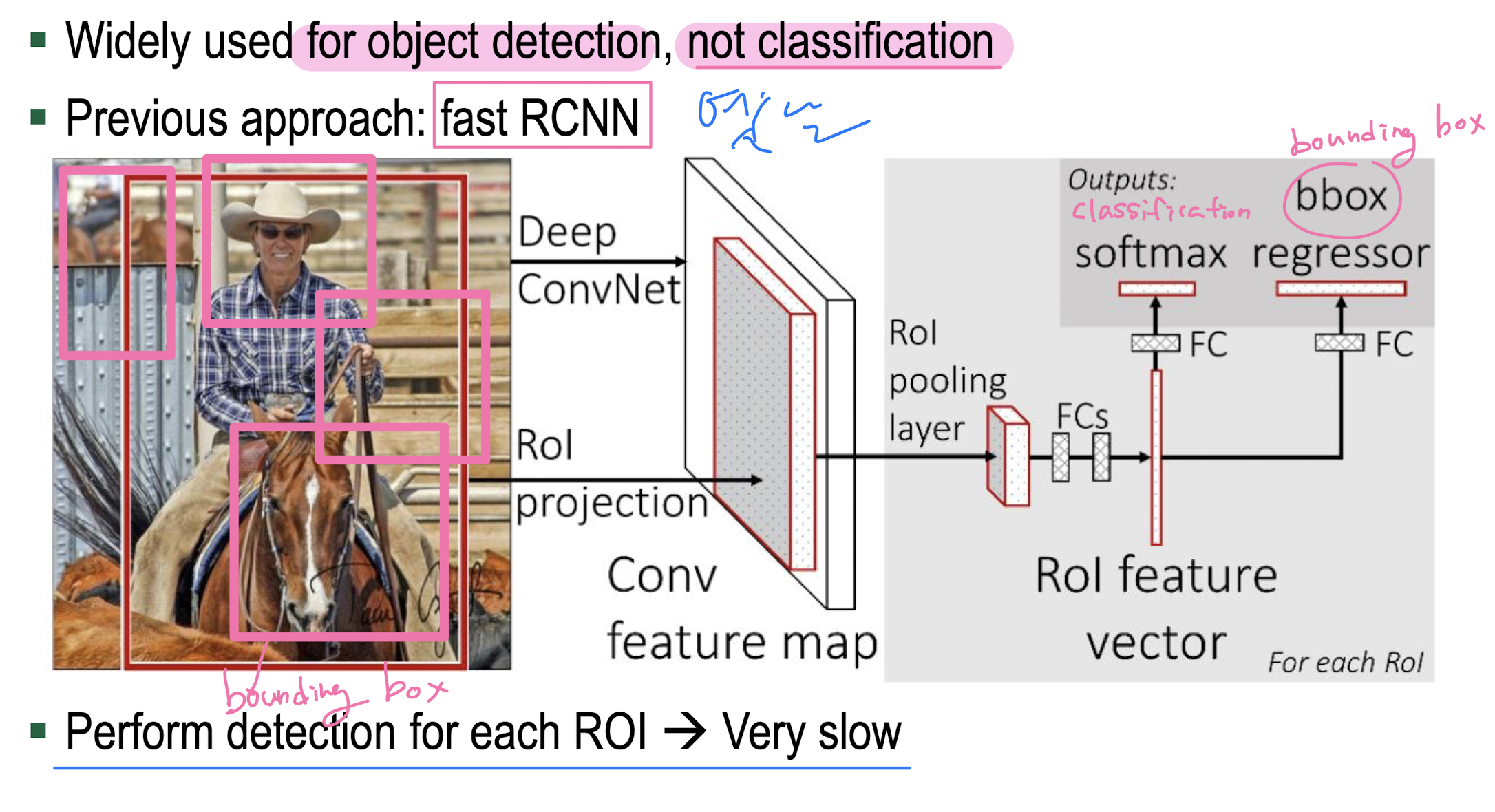
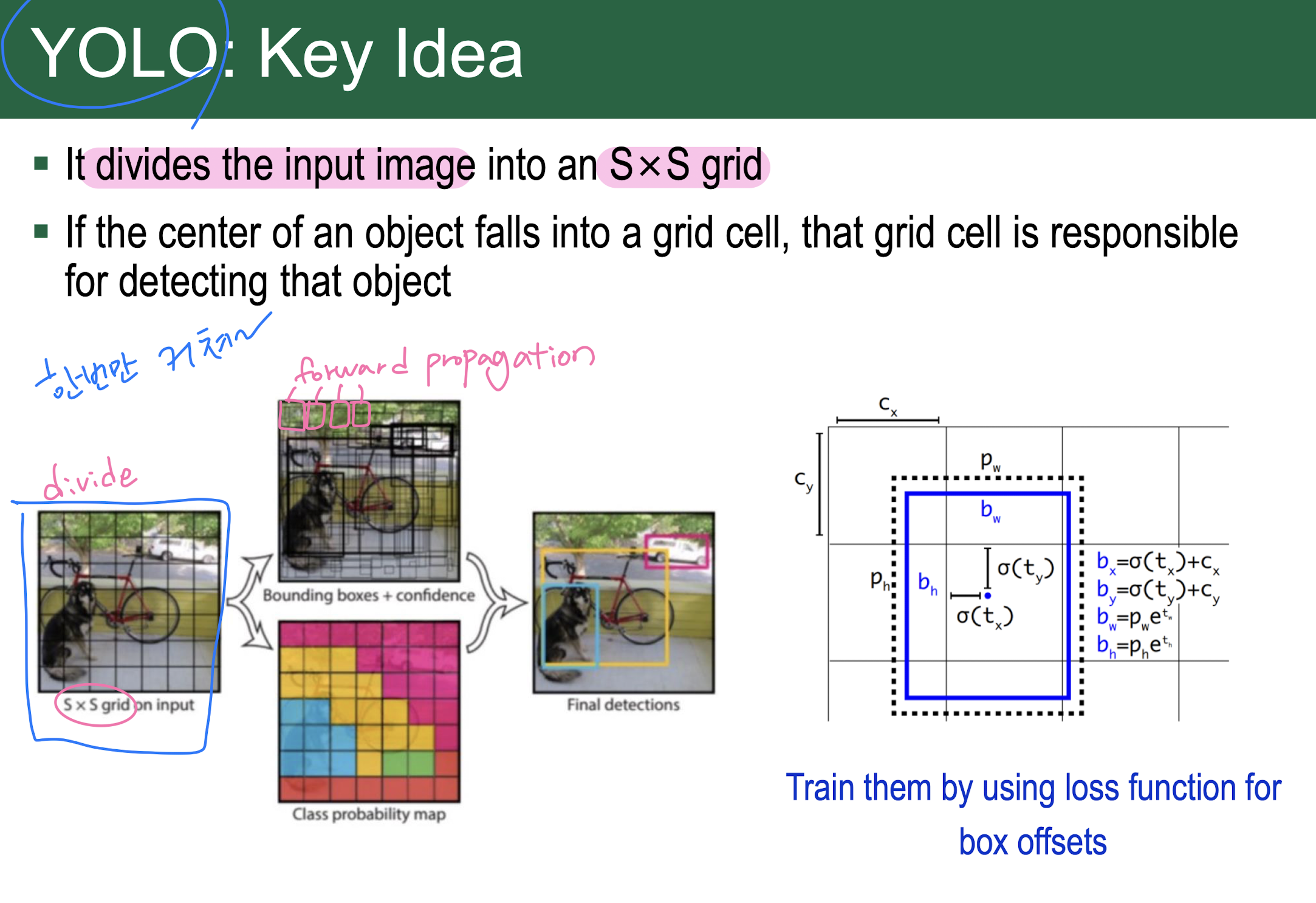
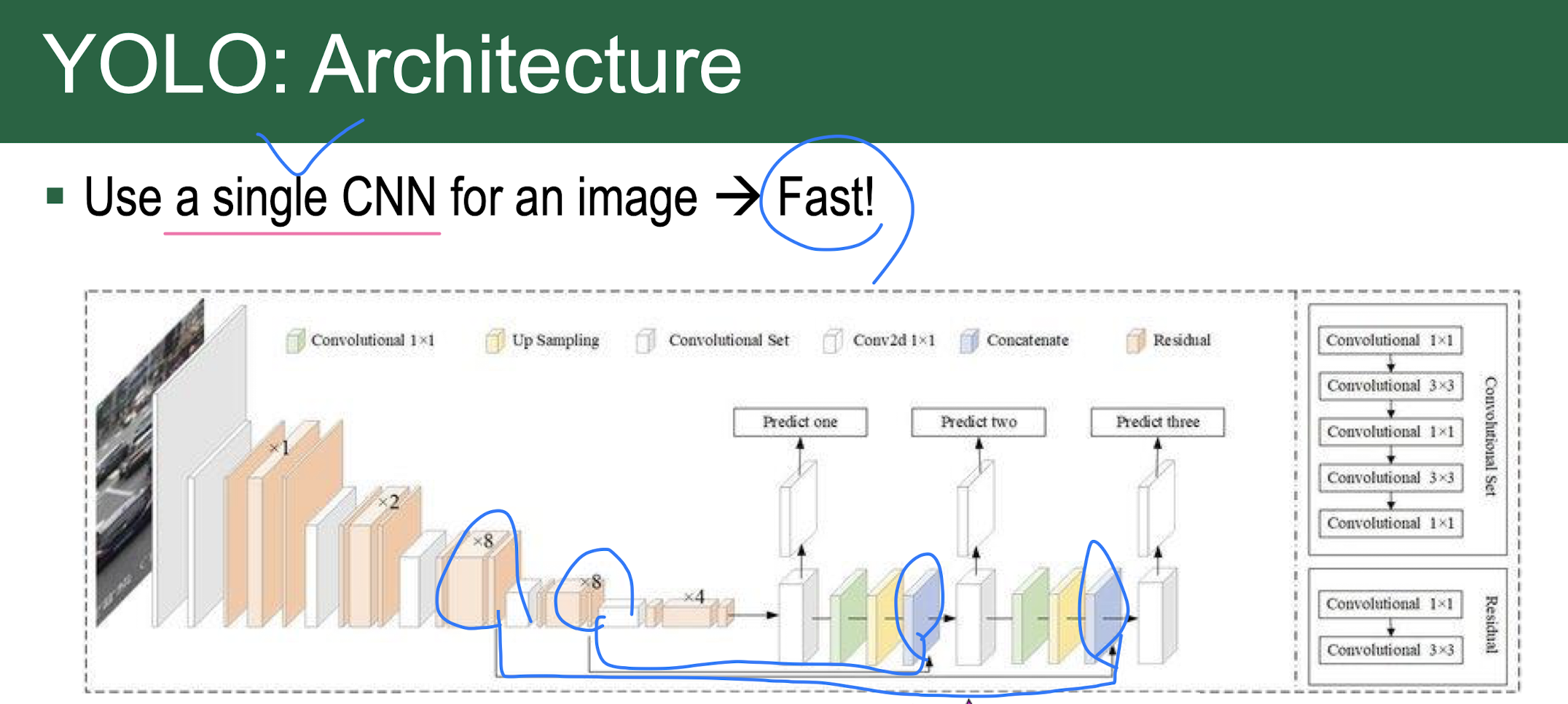
YOLO

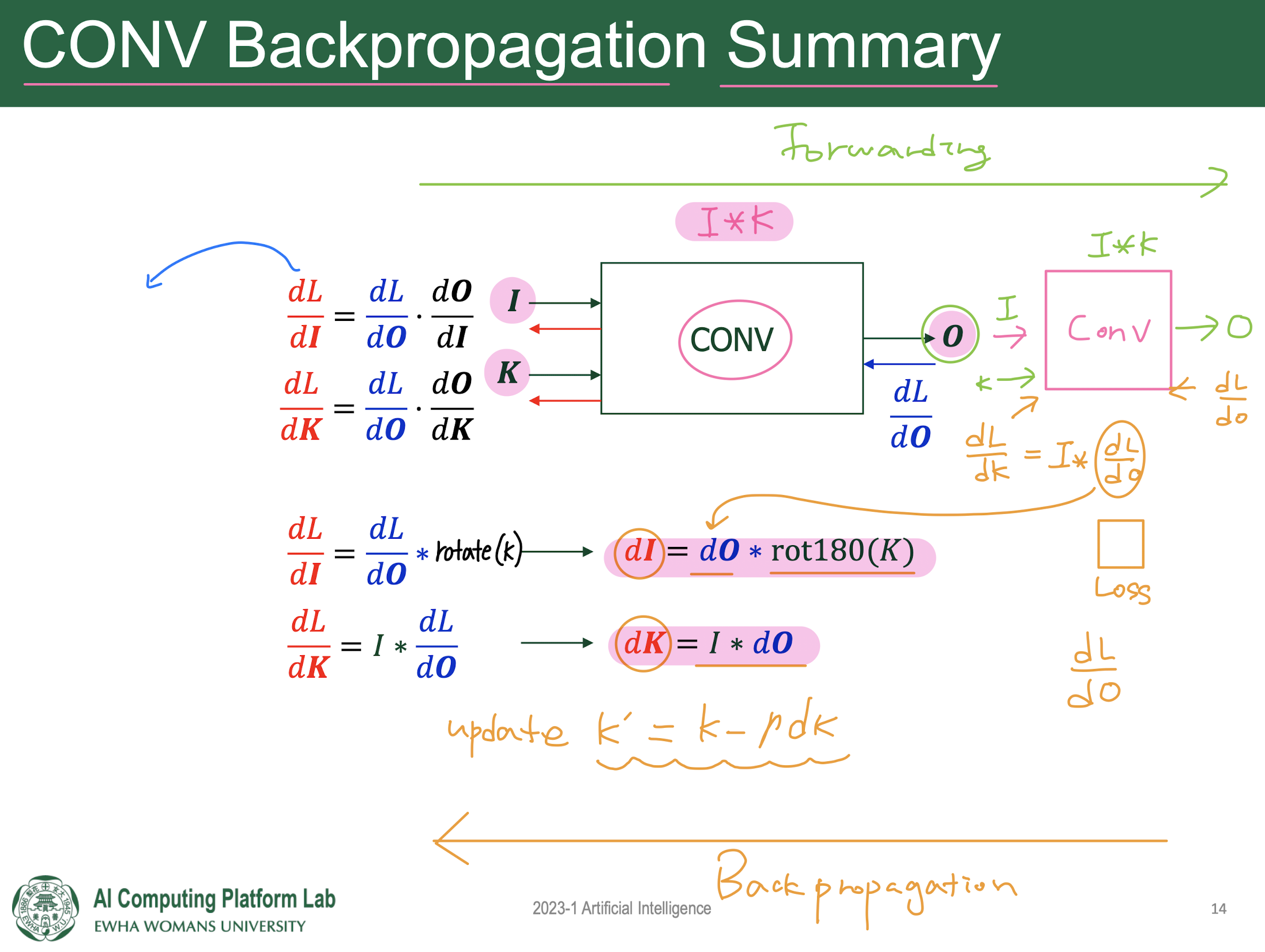
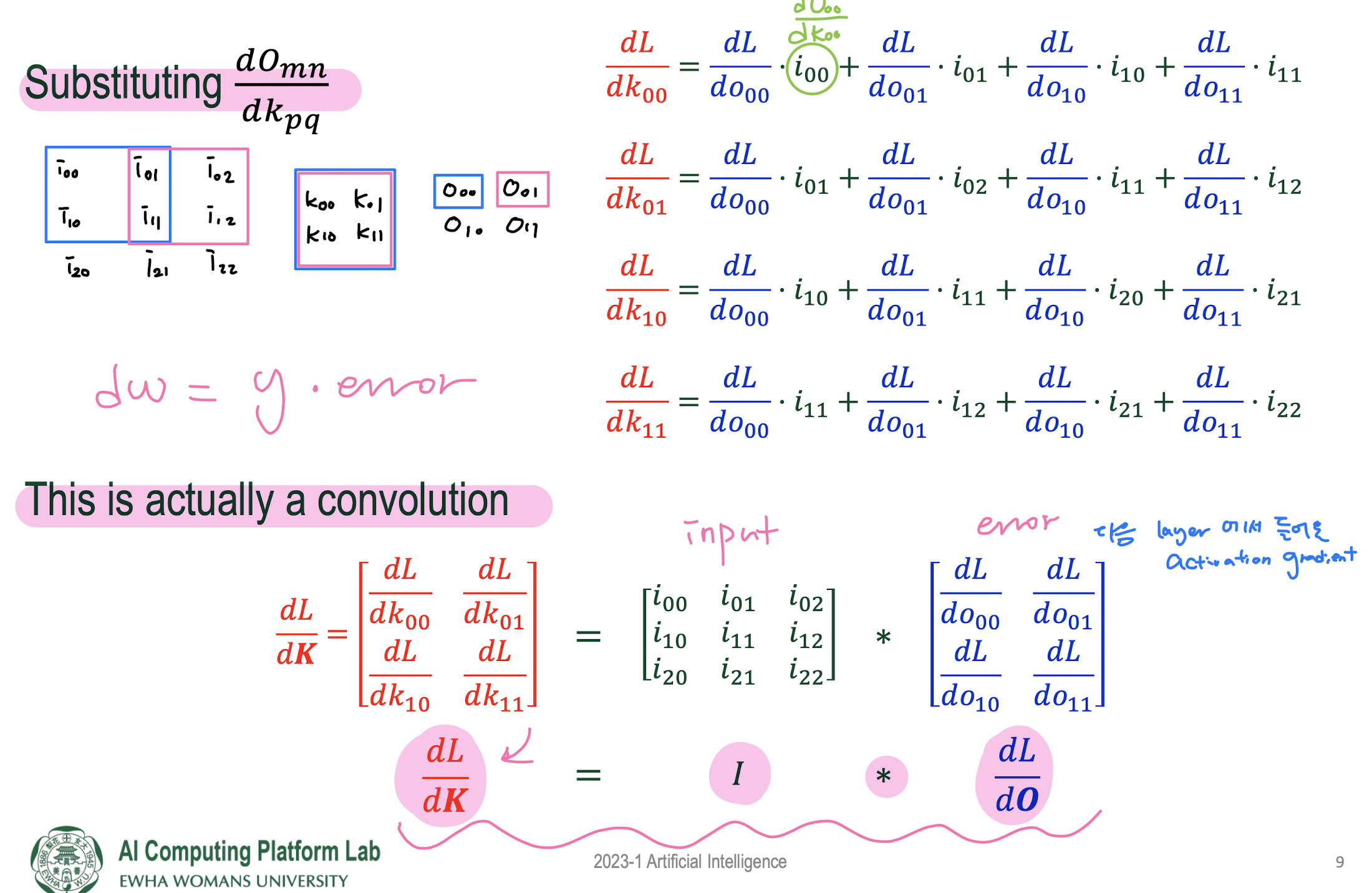
9. CONV Backpropagation
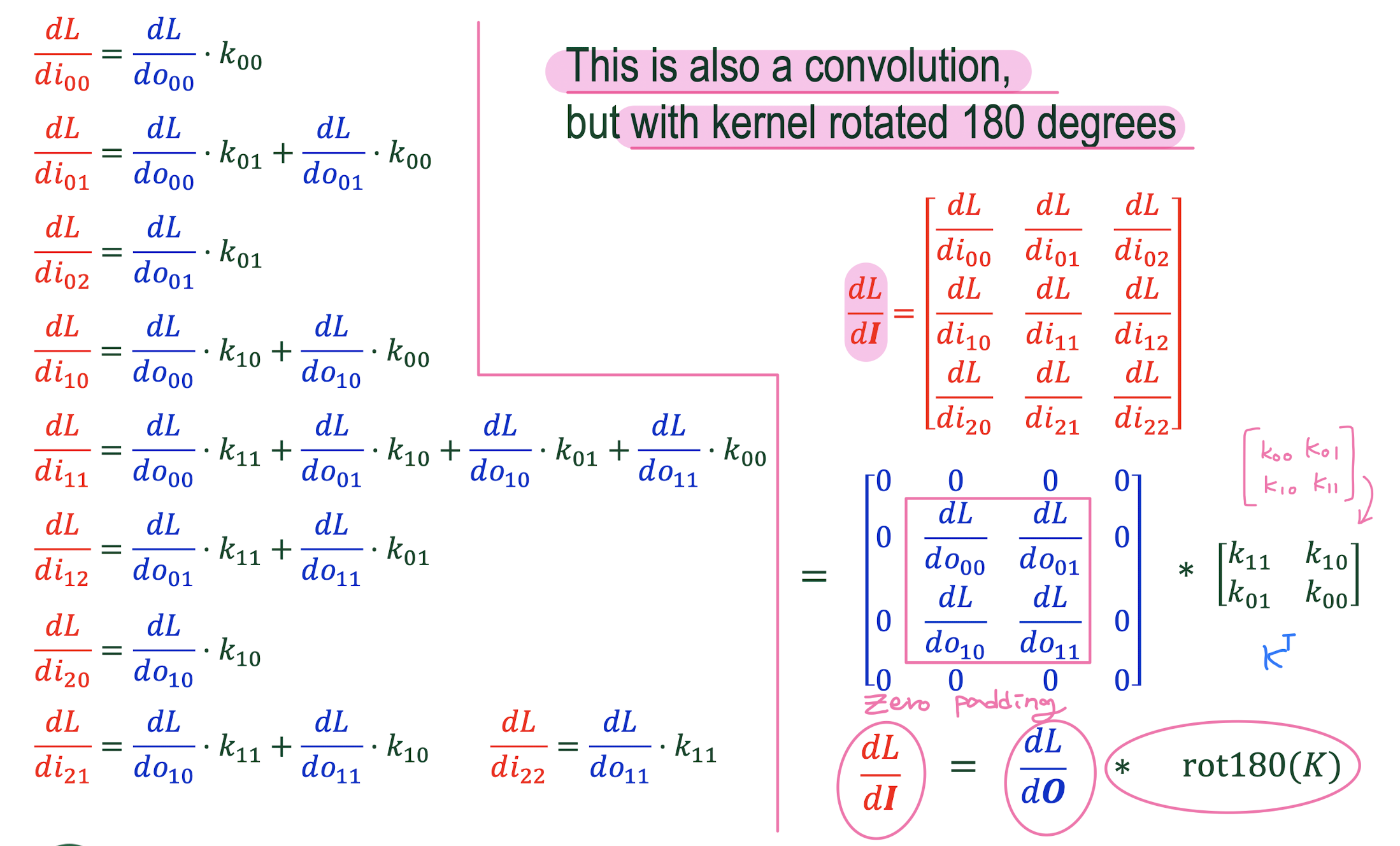
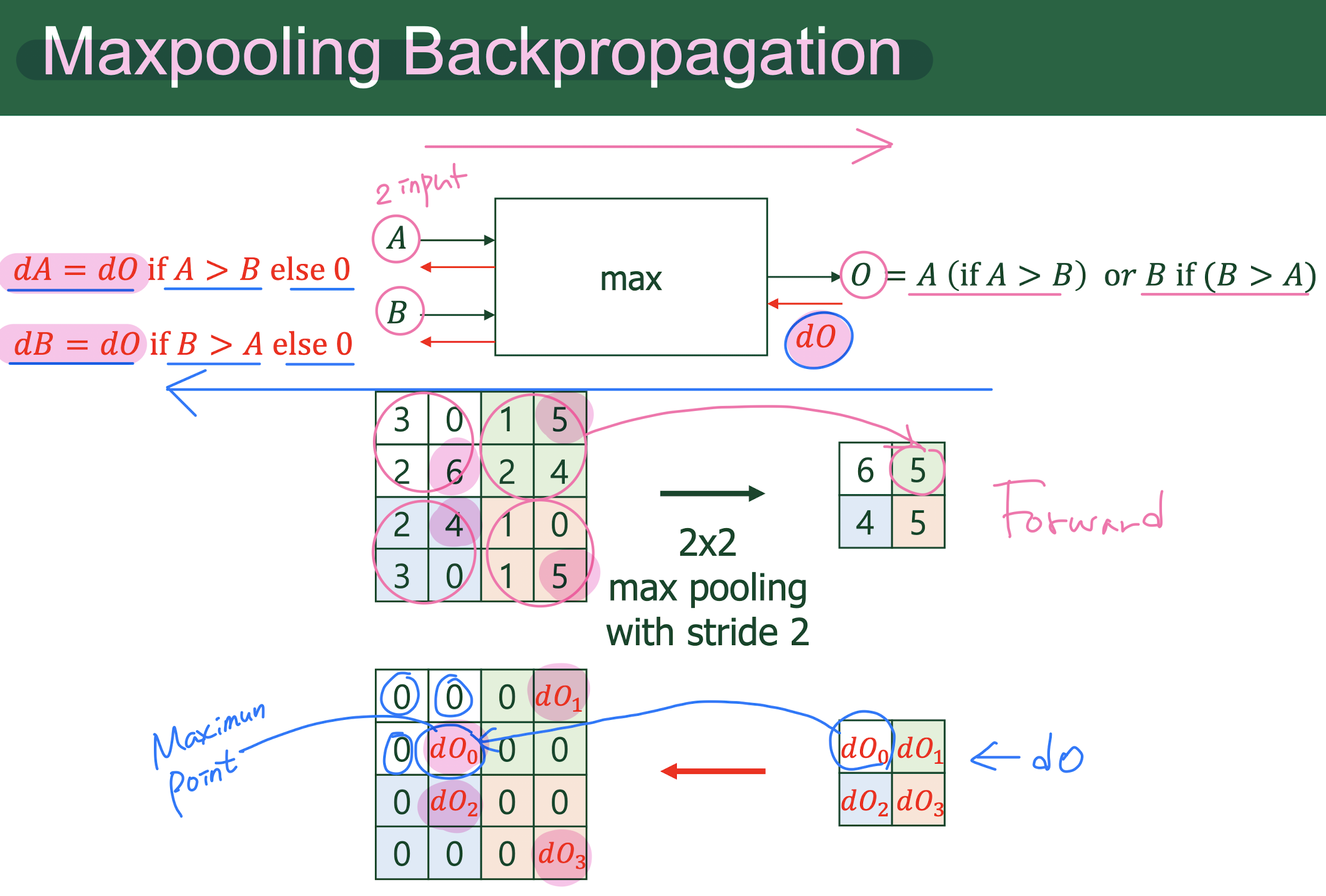


10. Regularization
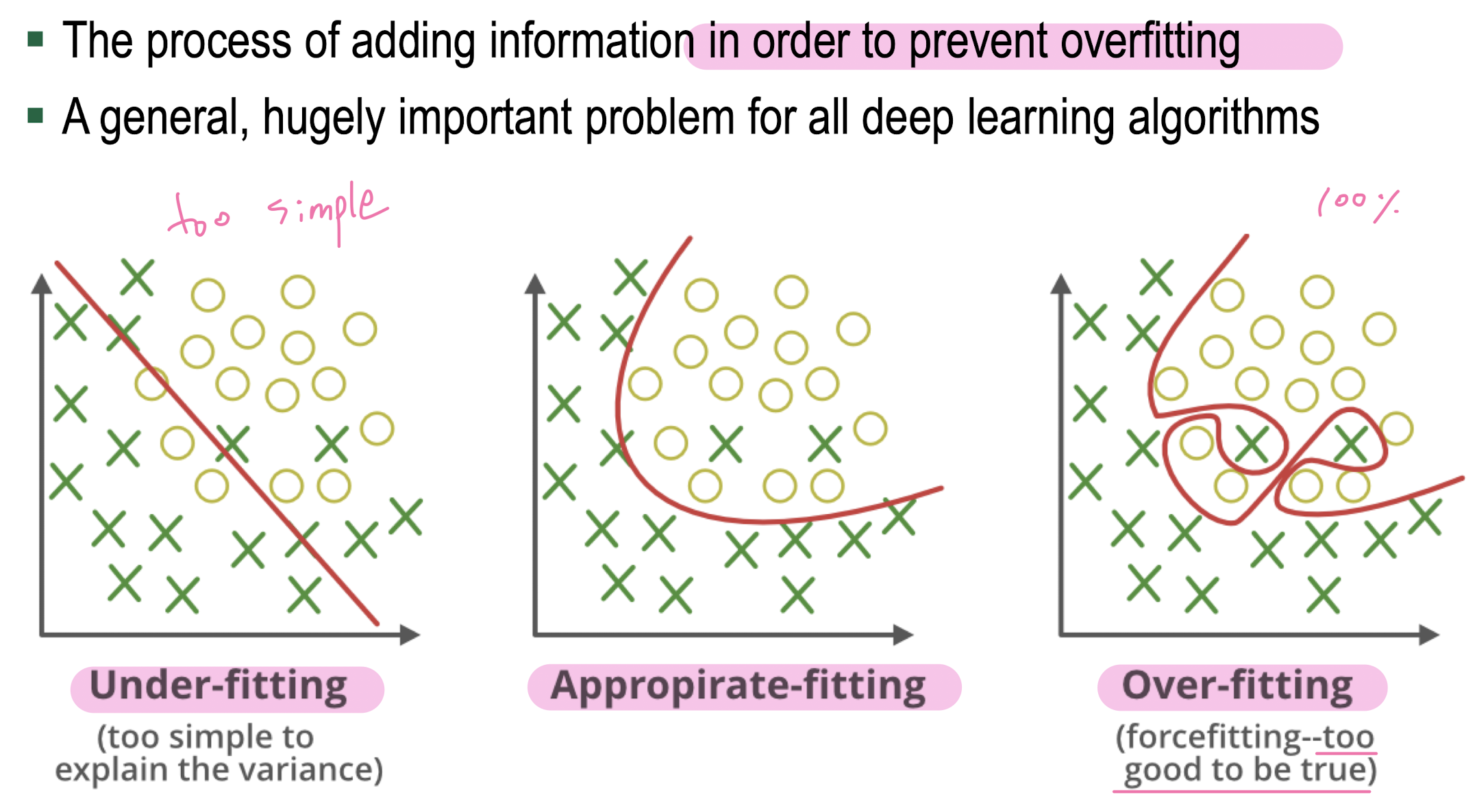
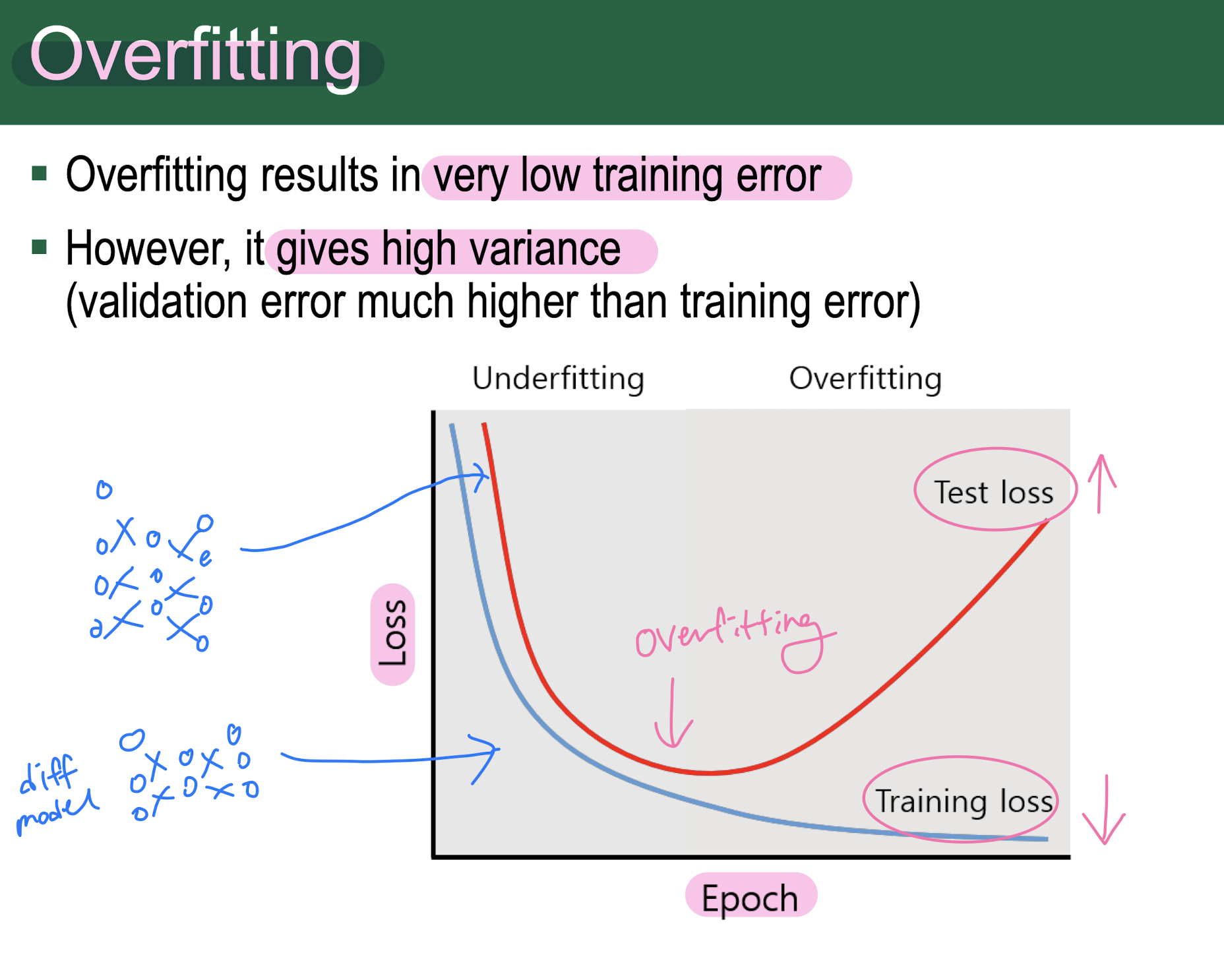
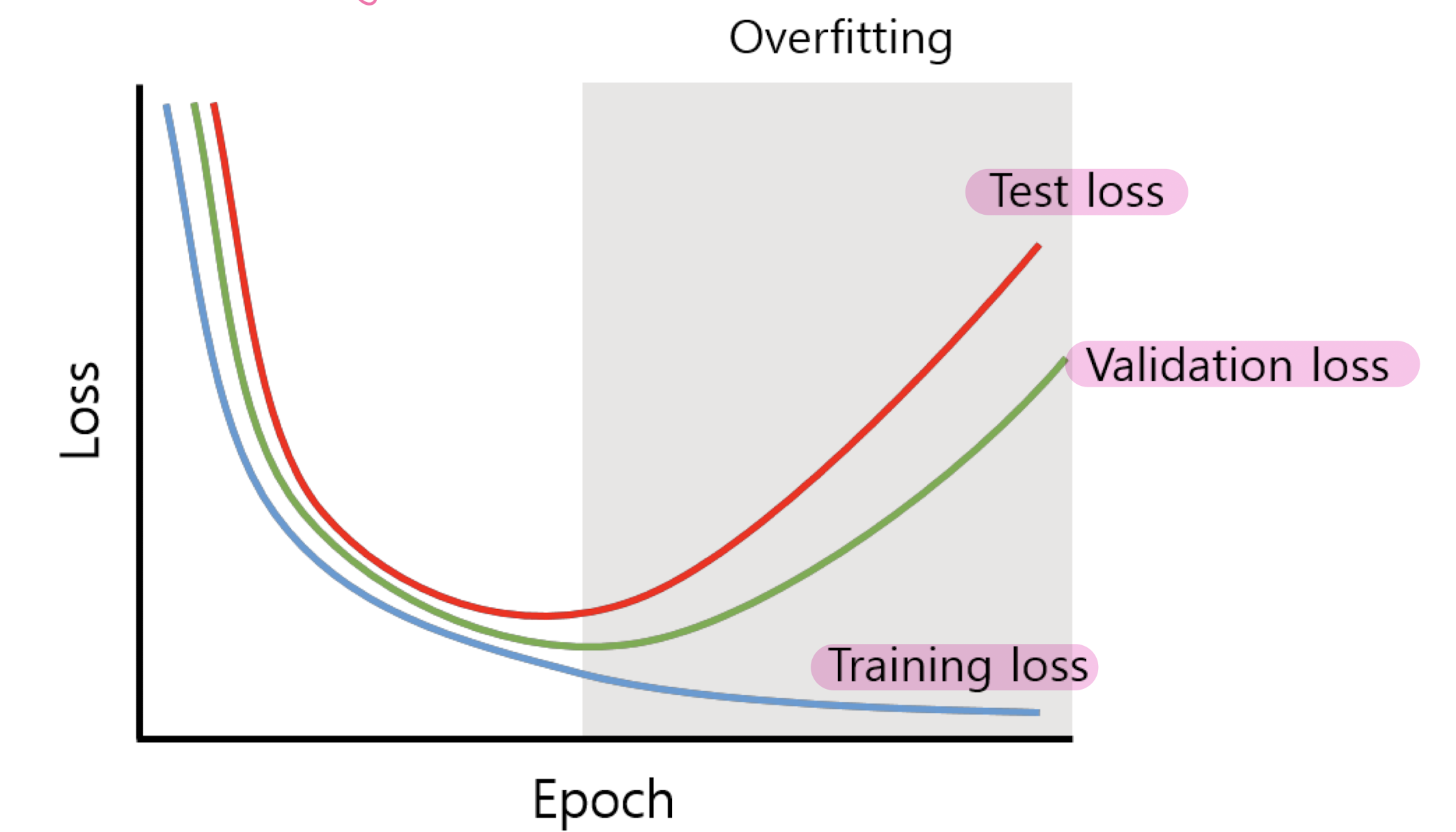
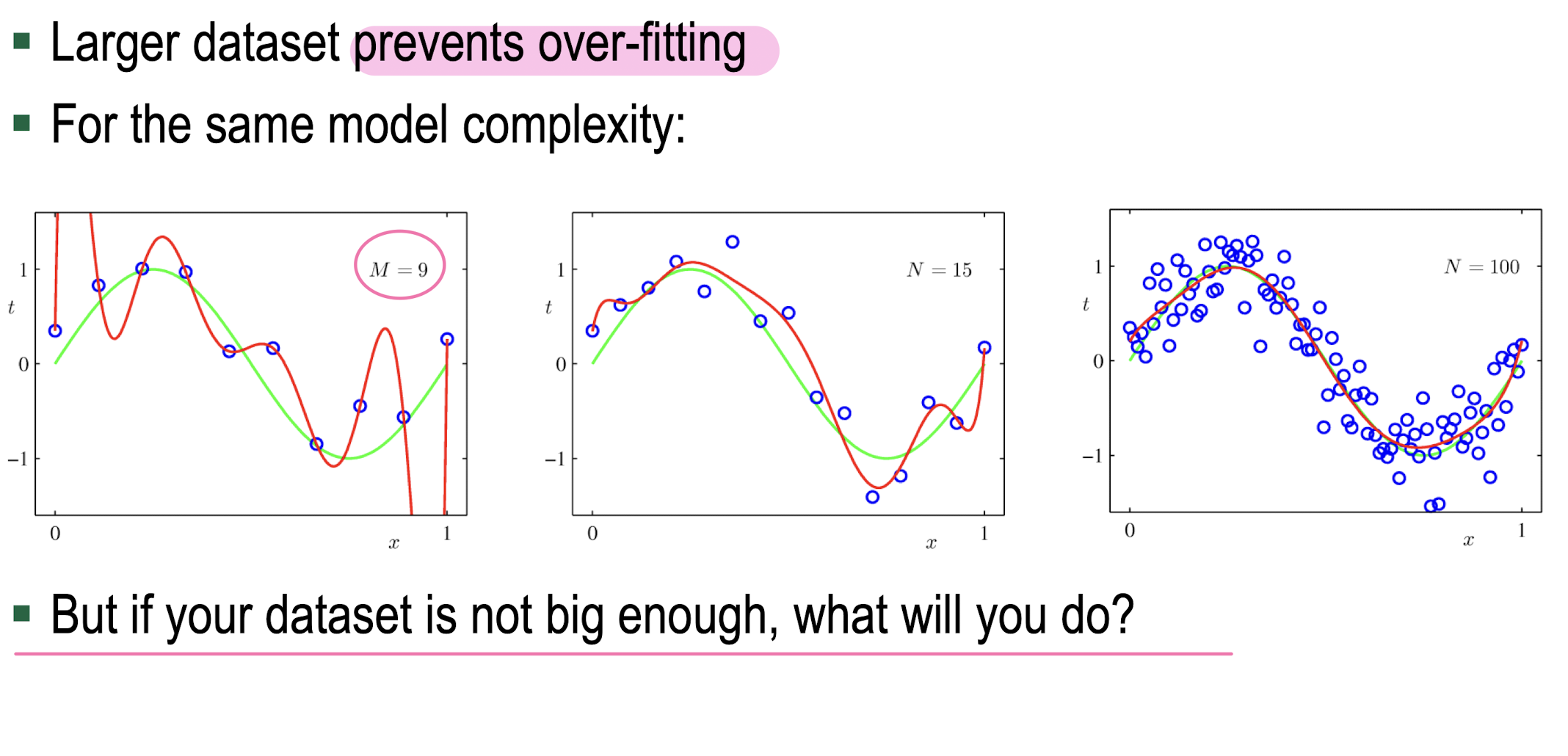
Underfitting/Overfitting
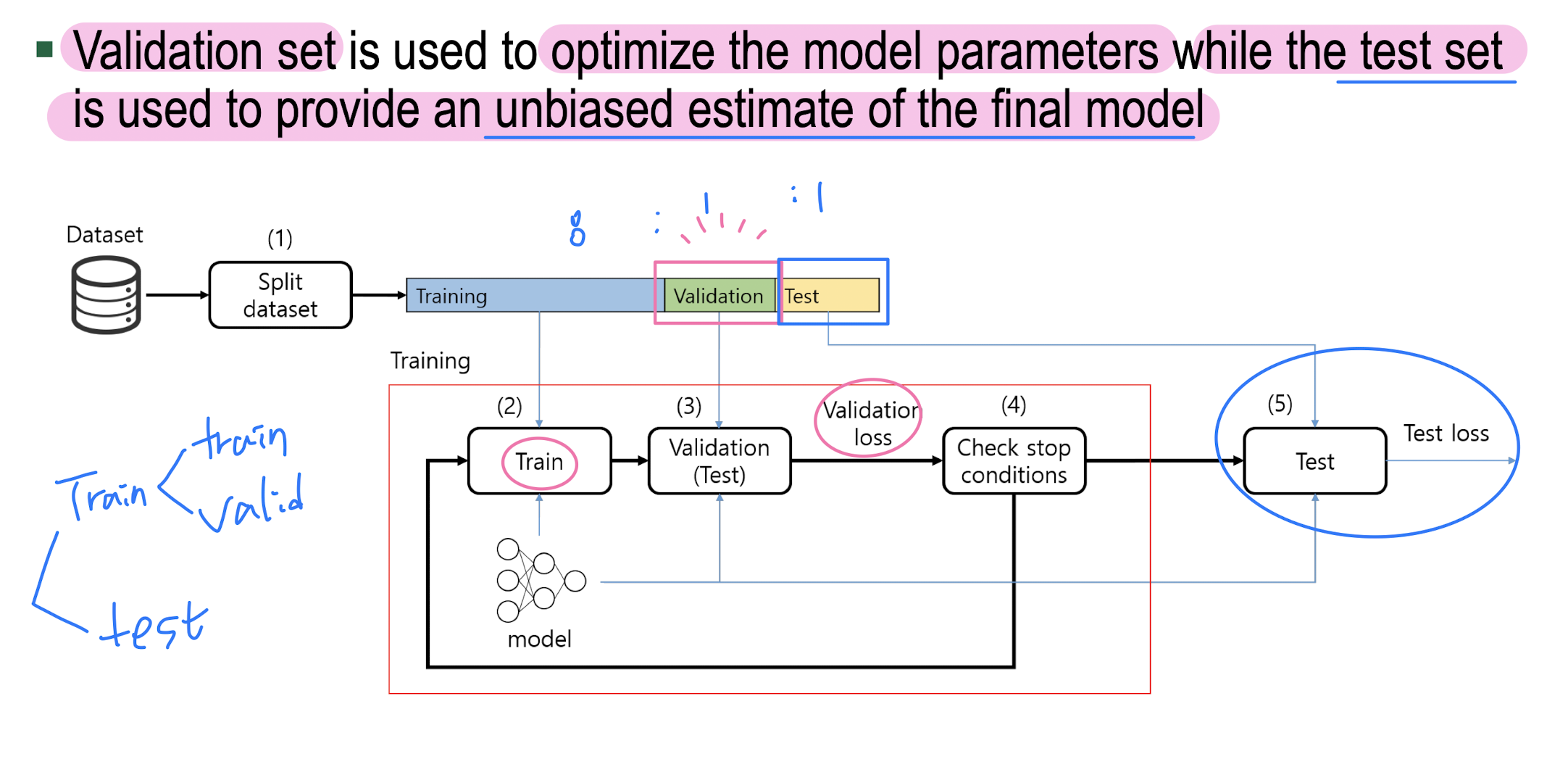
Validation set
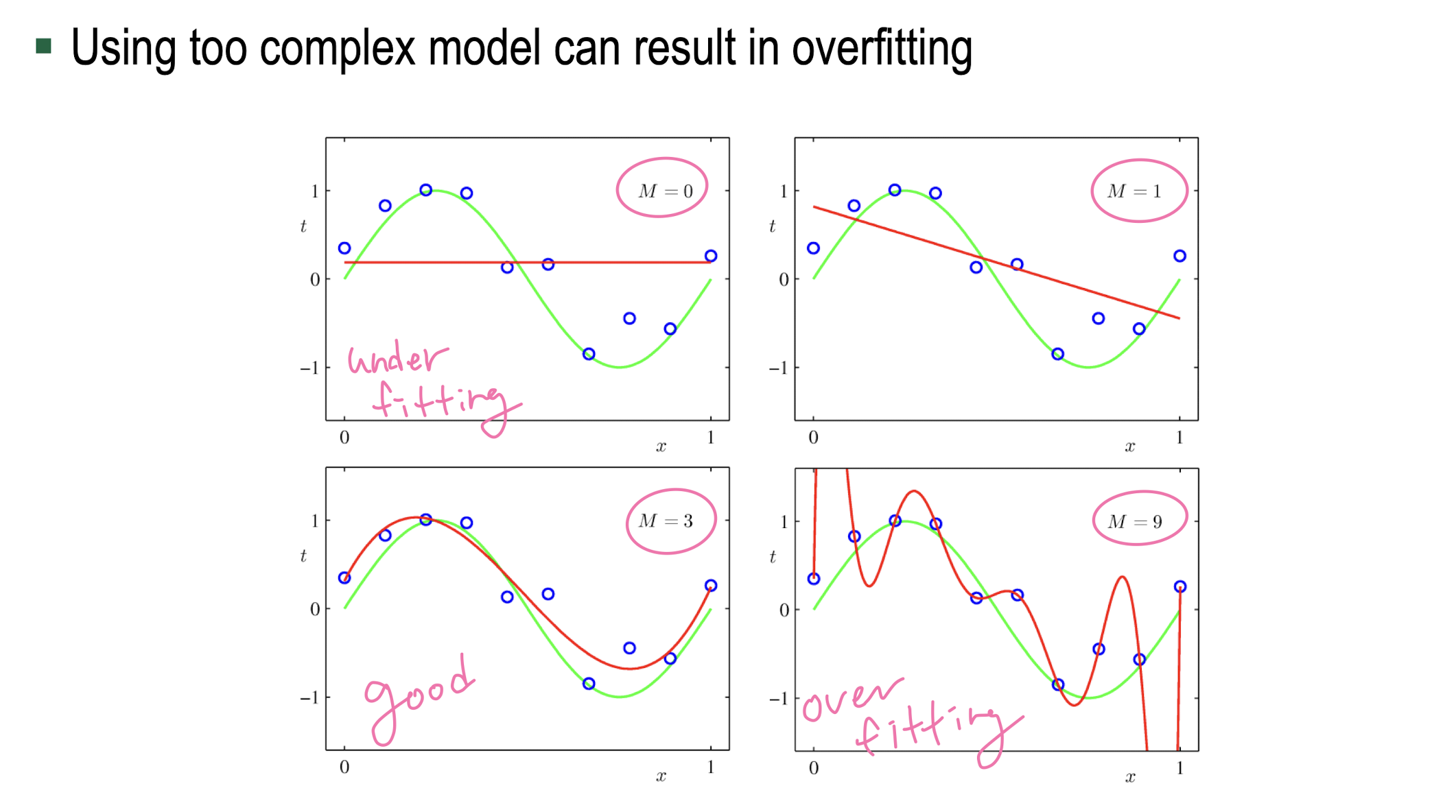
Model architecture selection
Data augmentation


Weight decay
Early stopping
Dropout
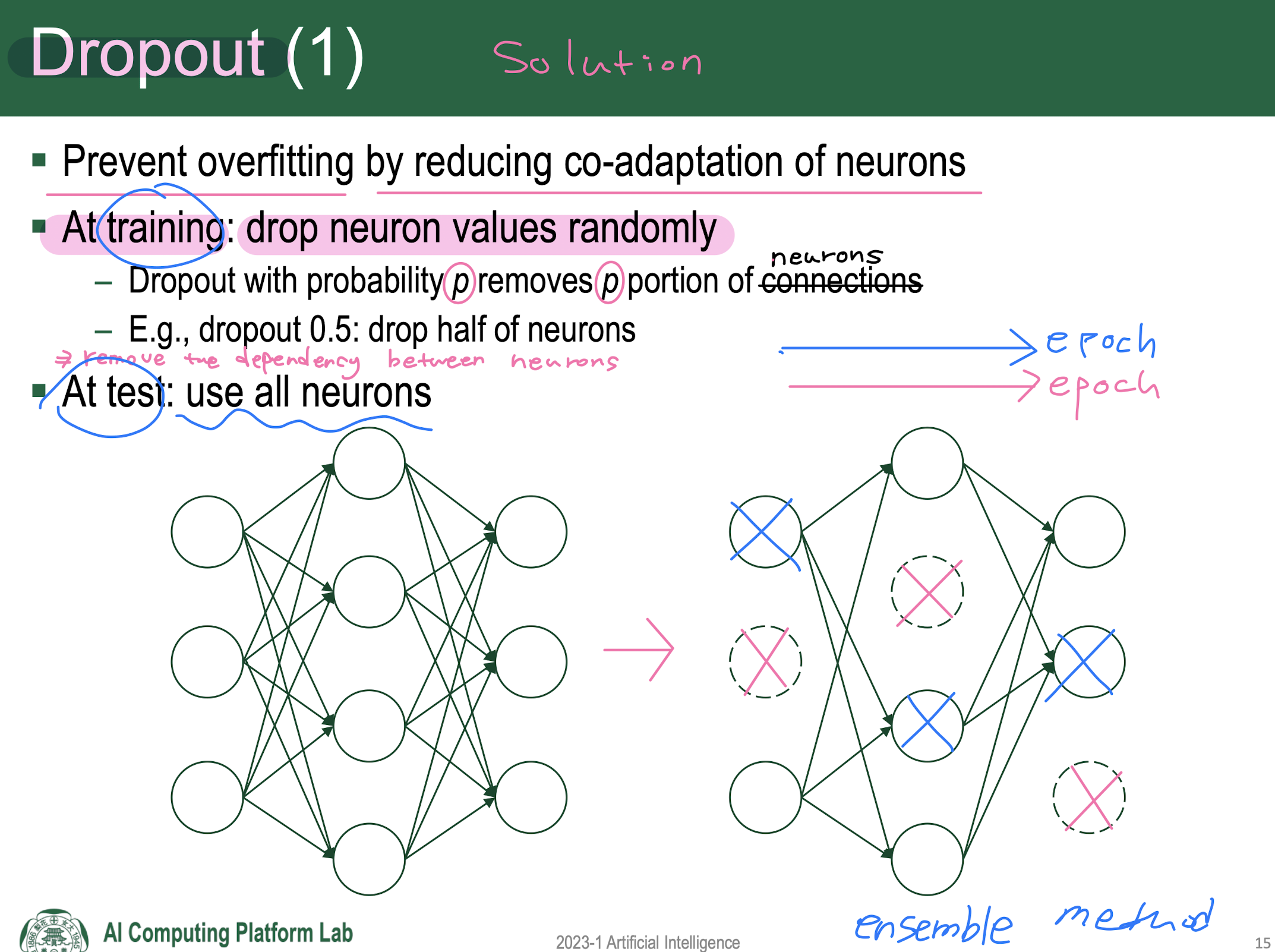
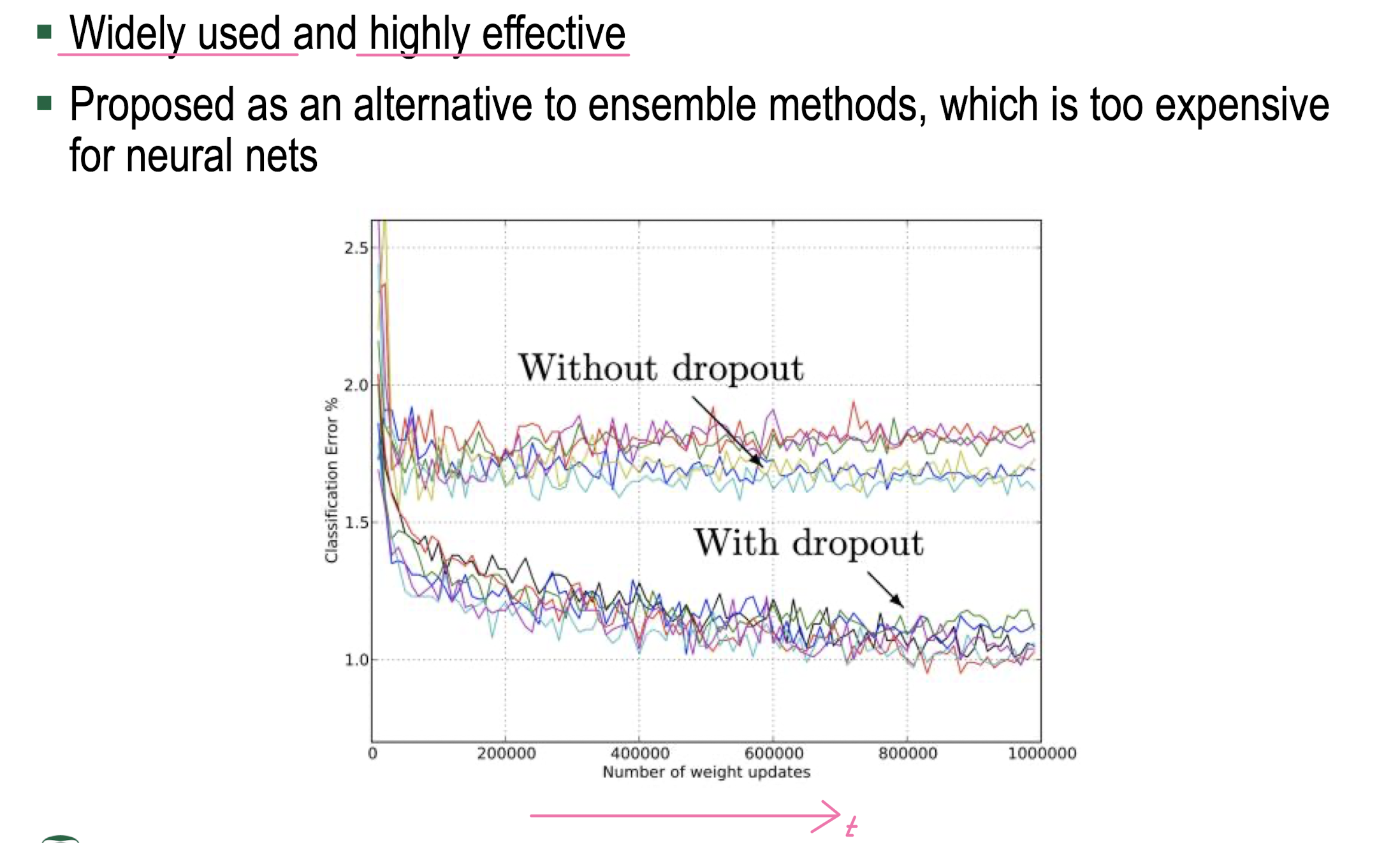


기출
 x
x
 x
x
 x
x
 x
x
 o
o
 a
a
 e
e
 a
a
- Universal Approximation Theorem이란 1개의 히든 레이어를 가진 Neural Network를 이용해 어떠한 함수든 근사시킬 수 있다는 이론
 50
50
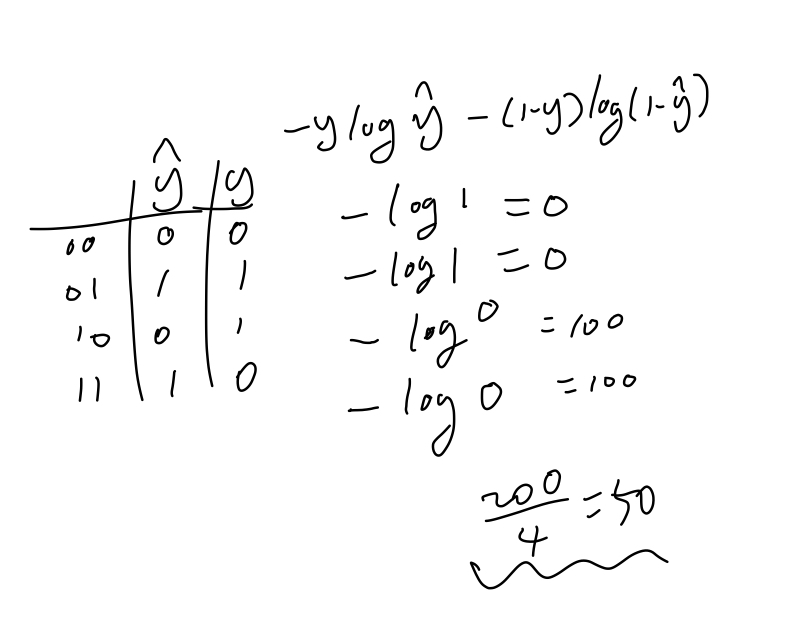
 ReLU 사용/ residiual block 사용/ Auxiliary Classifier 사용
ReLU 사용/ residiual block 사용/ Auxiliary Classifier 사용
 단일 sample을 input으로 넣는게 아닌 여러 sample을 input으로 한번에 넣는 것.
단일 sample을 input으로 넣는게 아닌 여러 sample을 input으로 한번에 넣는 것.
1. 전체 dataset에 대해 1번의 weight update을 하는 것은 불가능
2. matrix 연산이 빠르기 때문
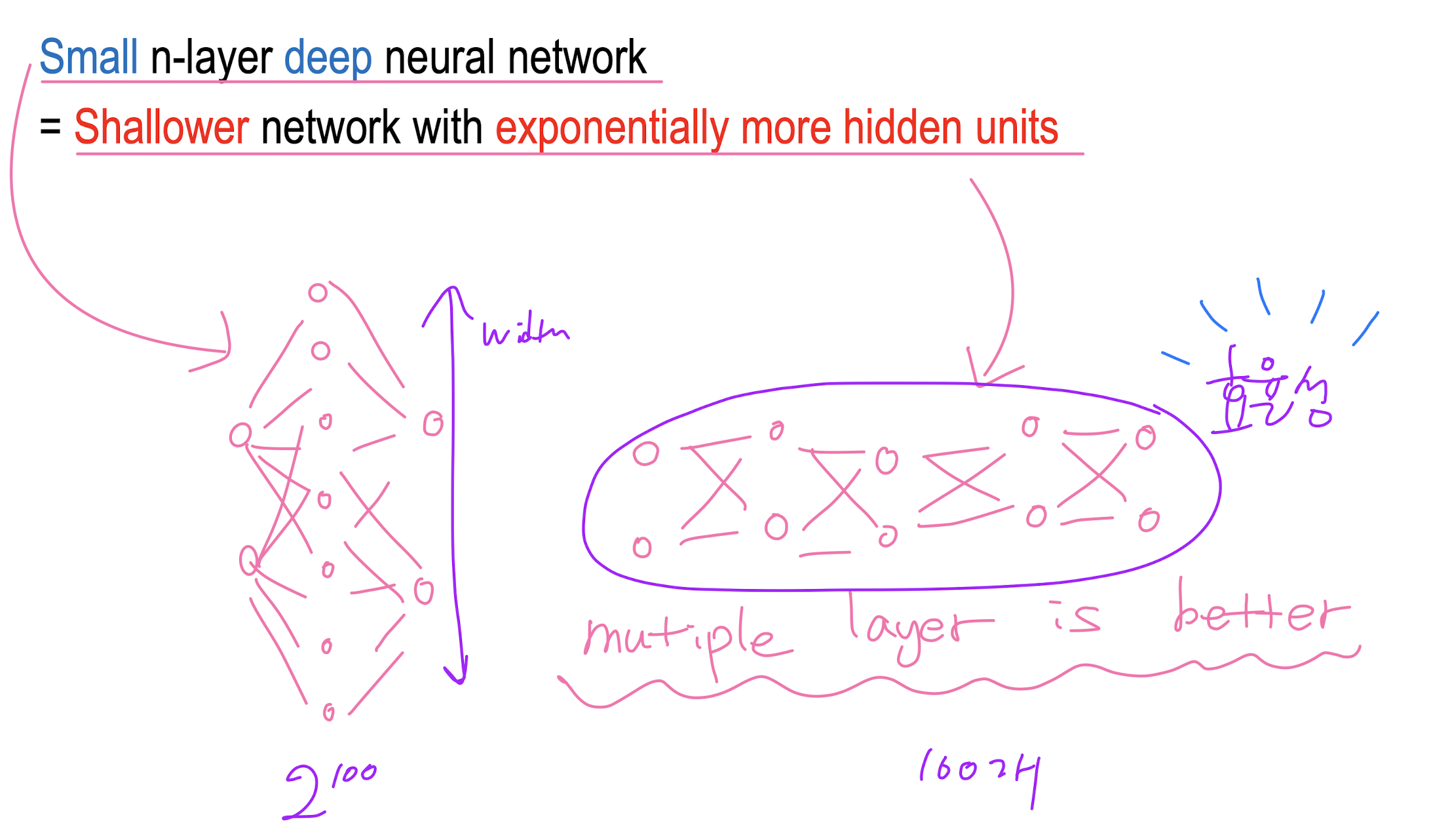
 1. 옅은 층의 신경망이 exponential하게 hidden unit을 더 필요로 함
1. 옅은 층의 신경망이 exponential하게 hidden unit을 더 필요로 함
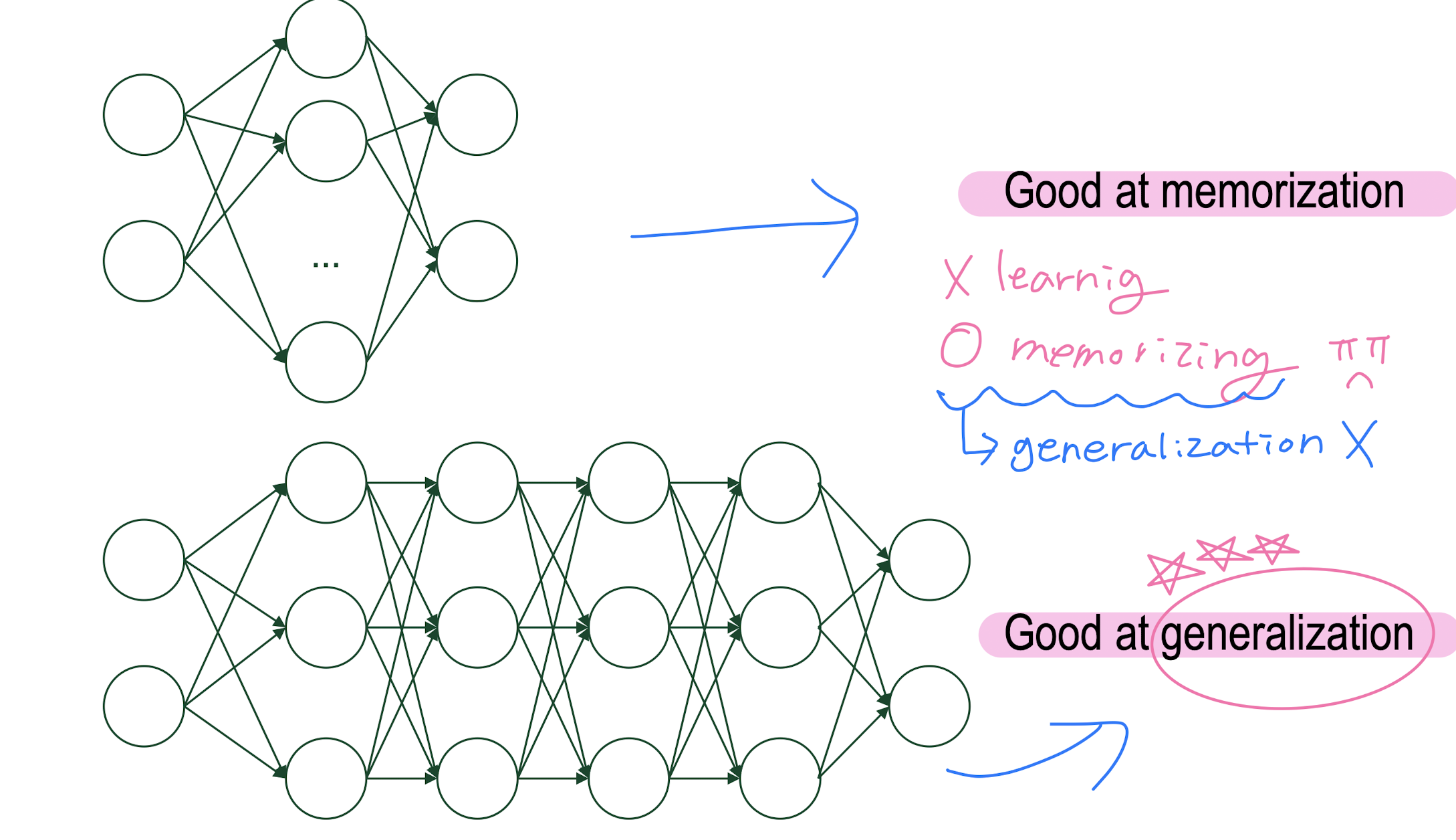
2. 깊은 층이 non-linearity가 좋음/ good at generalization
 추출한 feature를 classification해주기 위해서
추출한 feature를 classification해주기 위해서
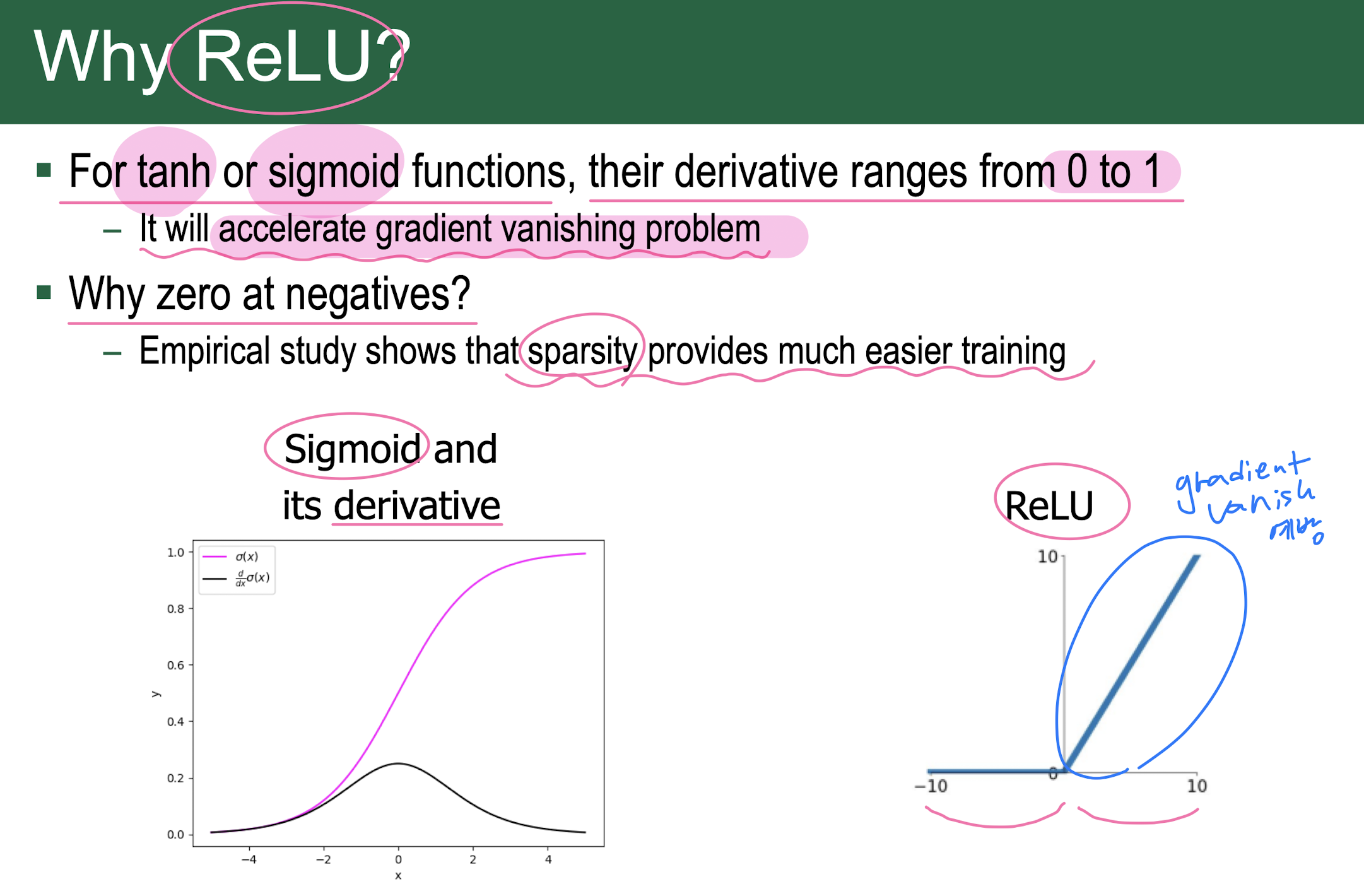
 1. activation함수로 tanh, ReLU 사용 시 weight가 0값으로 계속 고정
1. activation함수로 tanh, ReLU 사용 시 weight가 0값으로 계속 고정
2. sigmoid 사용 시 weight가 column(혹은 row) 단위로만 update된다.
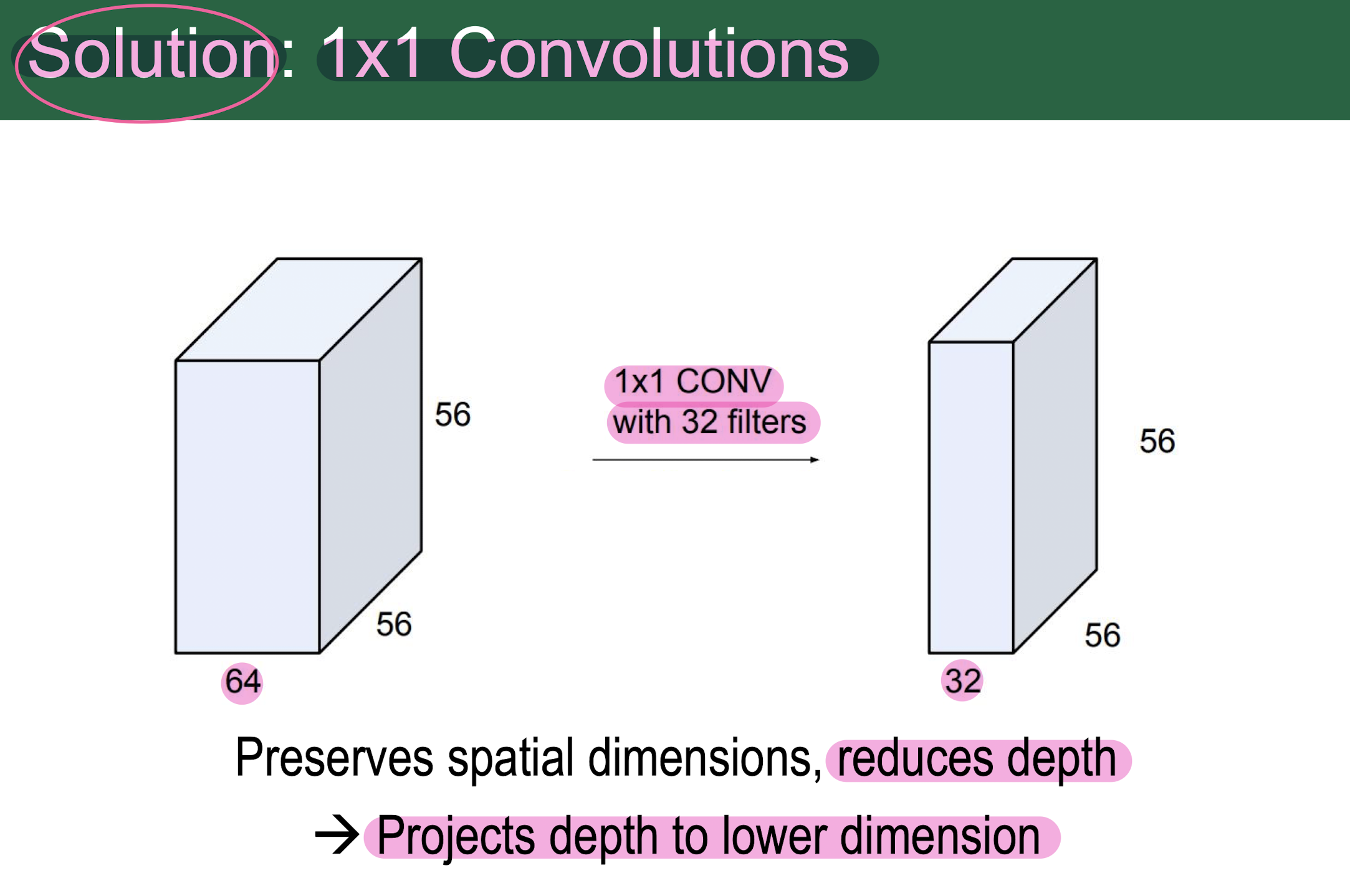
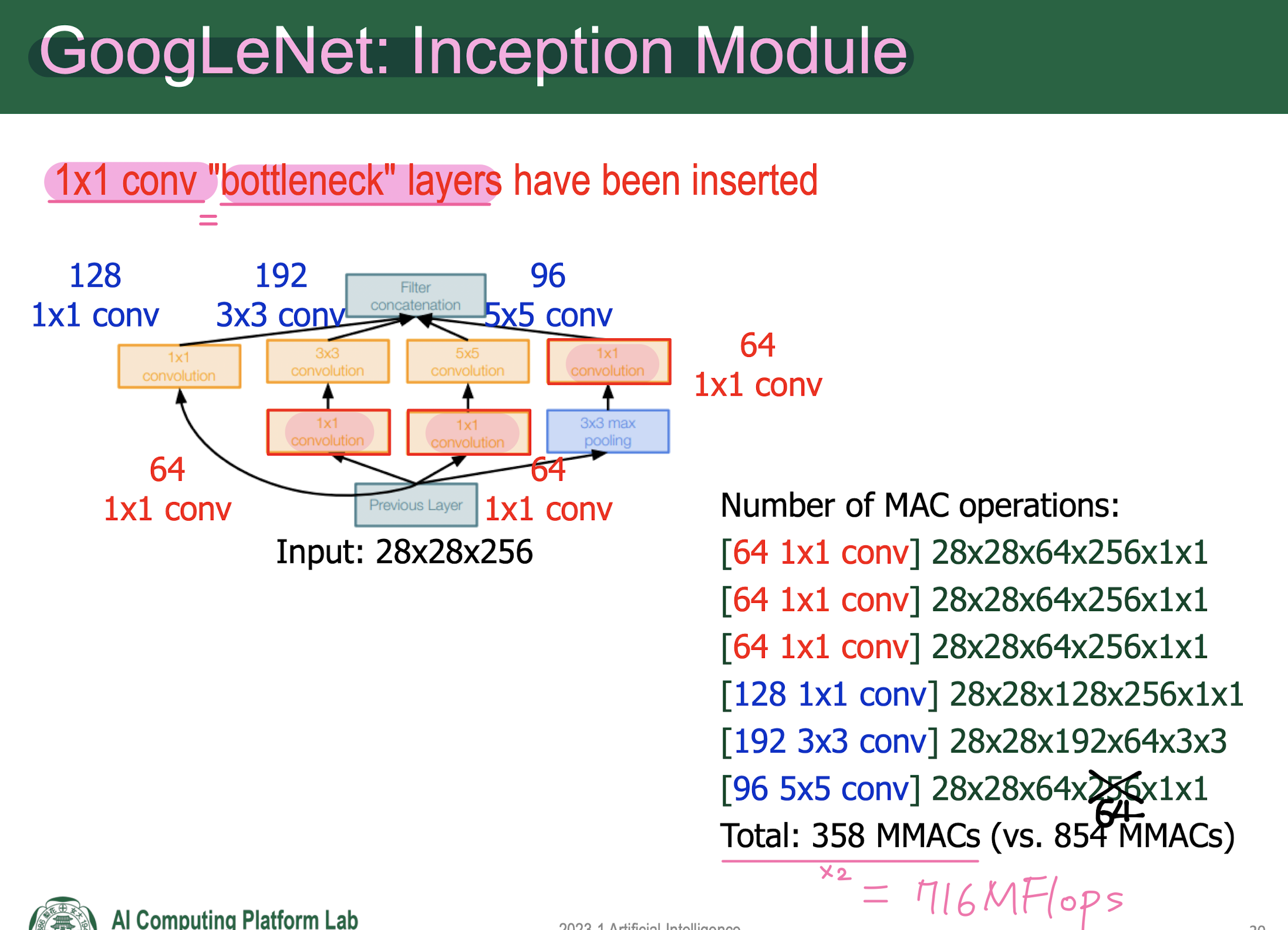
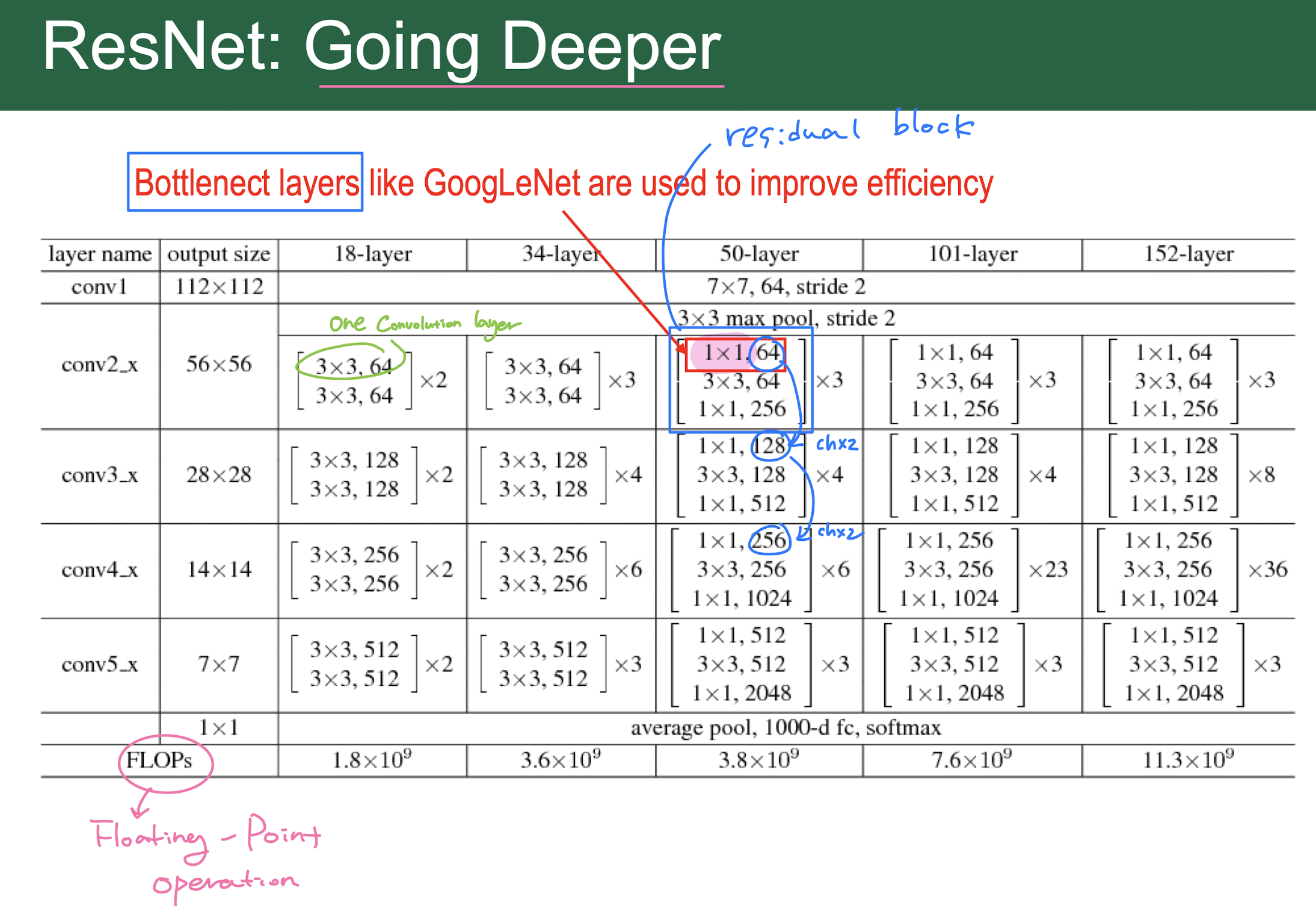
 1x1 convolution을 수행하여 channel size를 조절시켜 줌
1x1 convolution을 수행하여 channel size를 조절시켜 줌
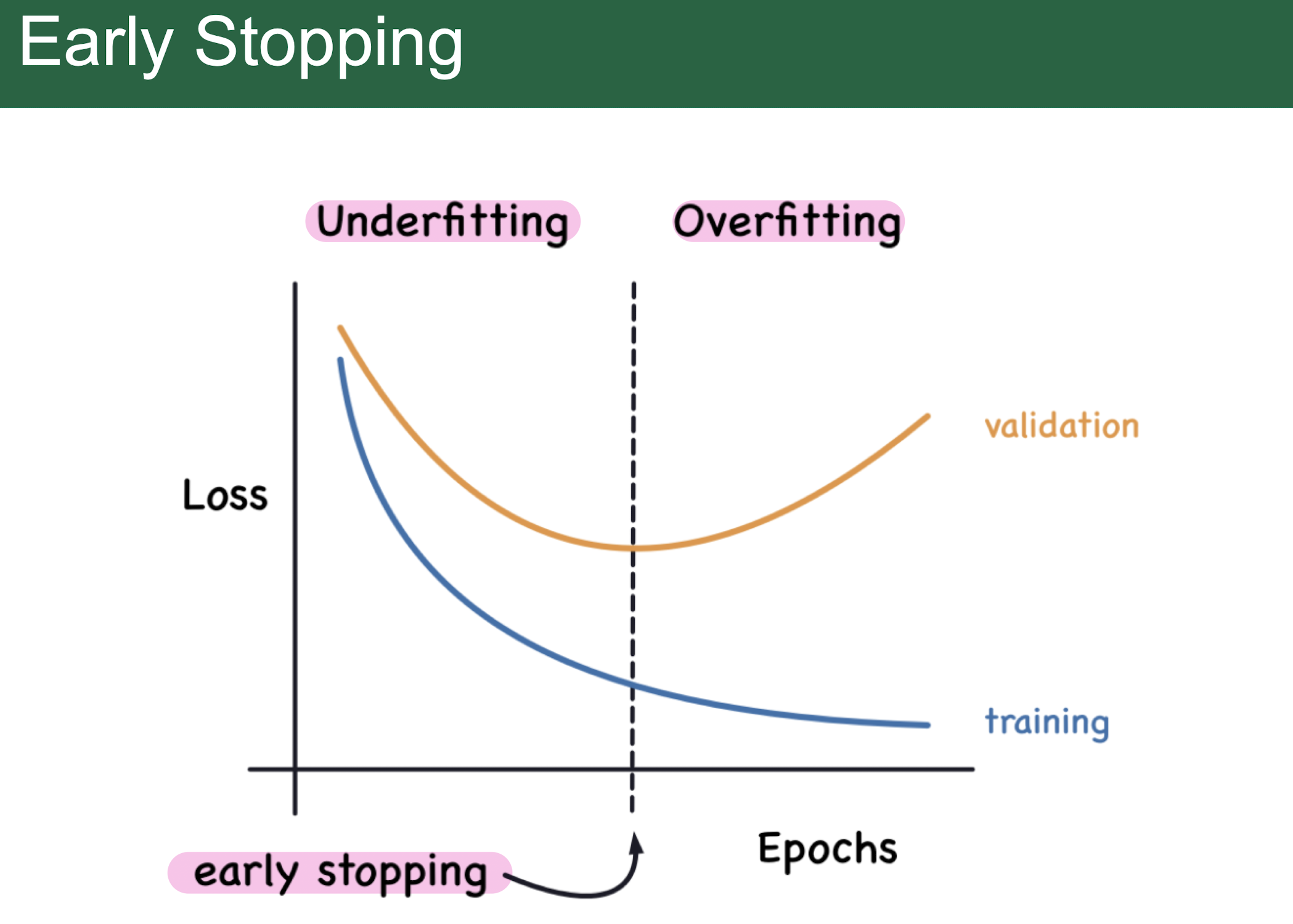
 epoch별 validation loss(accuracy)를 추출하여 training accuracy와의 격차를 모니터링함. 격차가 벌어지기 시작하면 overfitting이 발생
epoch별 validation loss(accuracy)를 추출하여 training accuracy와의 격차를 모니터링함. 격차가 벌어지기 시작하면 overfitting이 발생
- 오버피팅 해결방법:
- model archiecture selection: 너무 복잡한 모델은 오버피팅 일어나므로 적절한 모델 선택
- Larger Dataset Size=> Data Augmentation
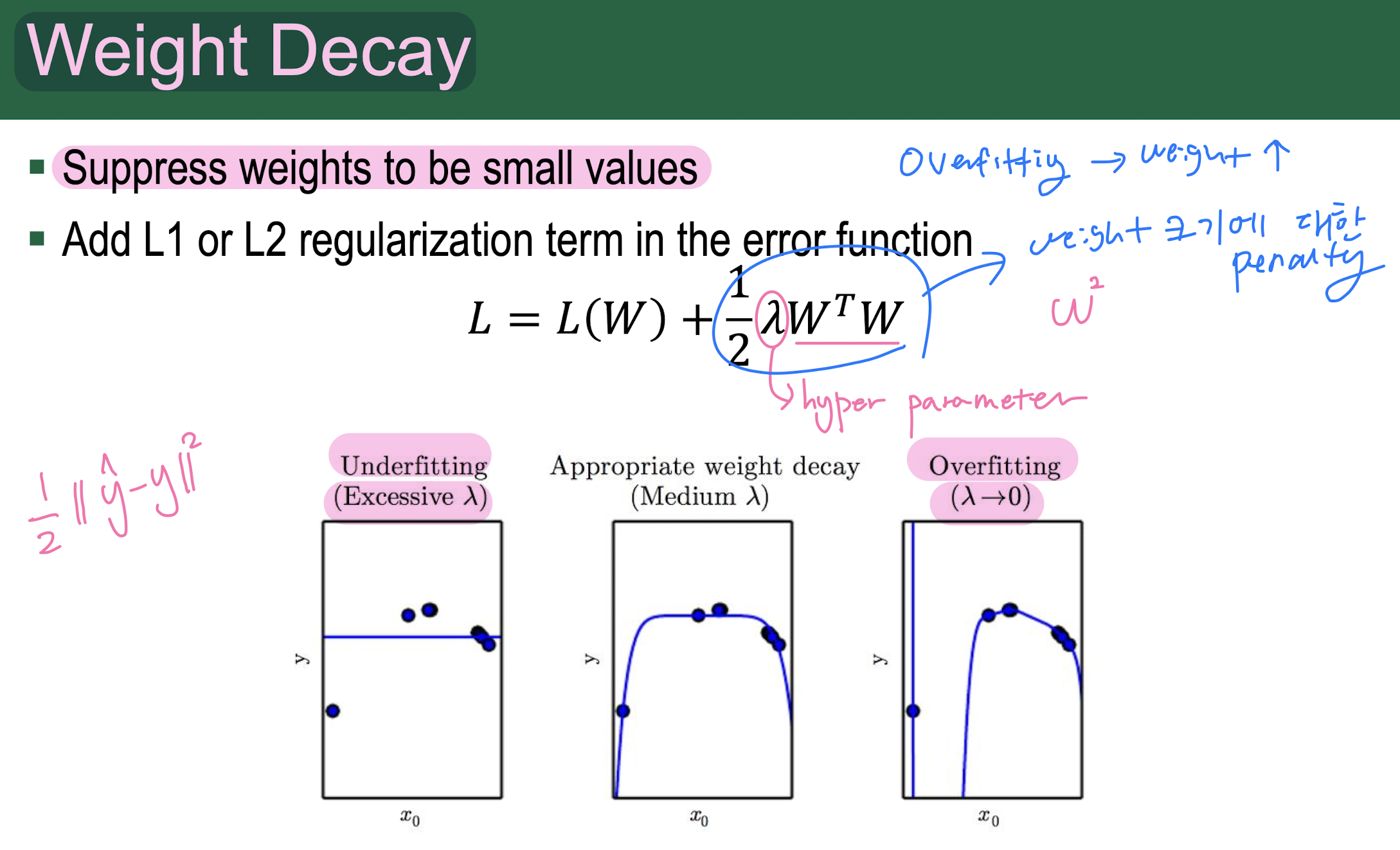
- Weight Decay: Suppress weights to be small values. Add L1 or L2 regularization term in the error function
- Early Stopping
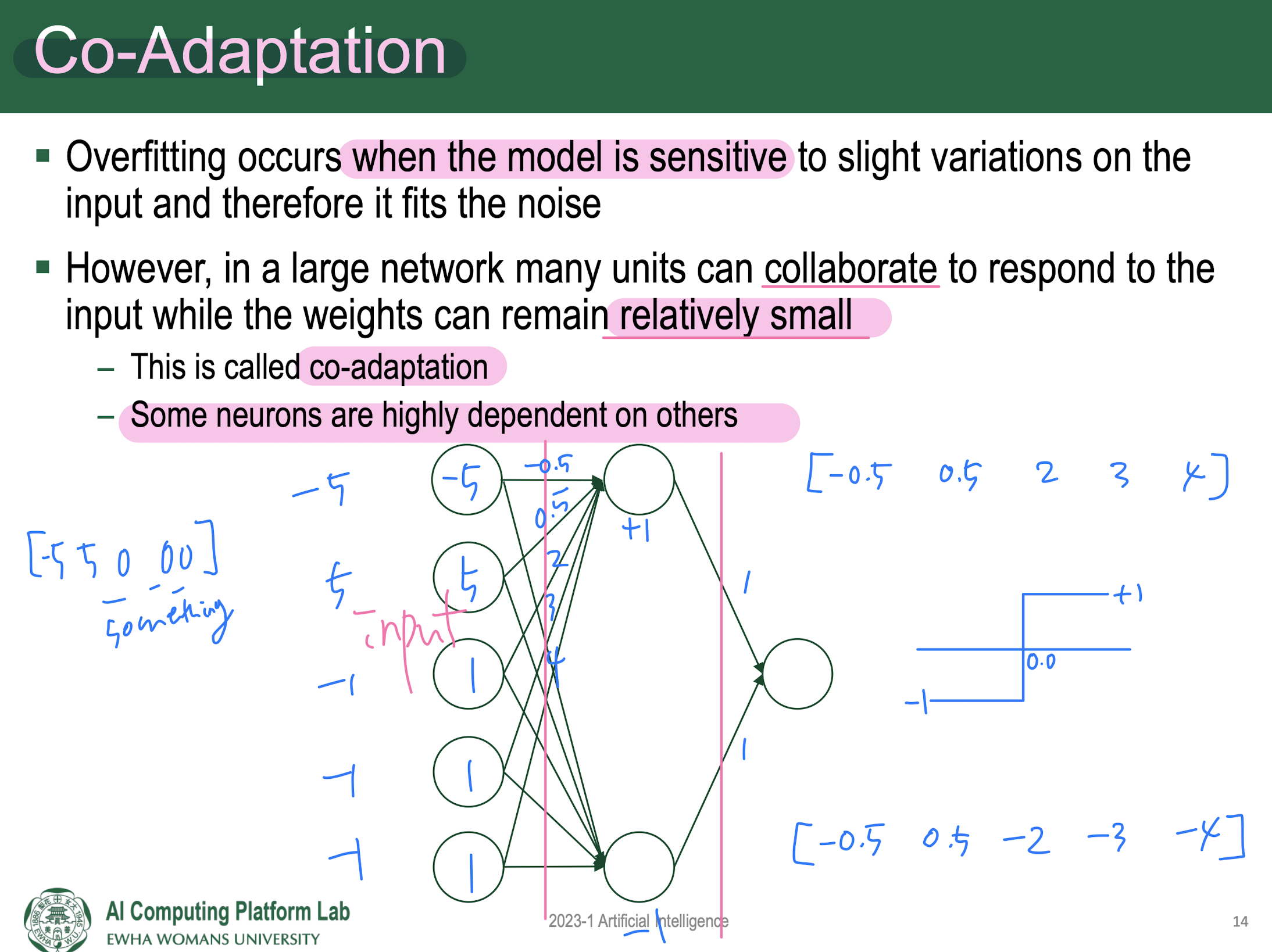
- Dropout : Prevent overfitting by reducing co-adaptation of neurons
- why is the activationn function important?
withoutact func, it's just another linear classifier.
기말 기출

Brevity Penally란 길이가 짧은 문장의 modified n-gram precision을 평가할 떄 패널티를 부여하는 것이다.
BLEU는 문장의 길이가 짧을수록 precision이 높아지기 때문에 이에 대한 Penaty를 부여하게 된다
답a
generator 목적O
d








11. Recurrent Neural Network
Recurrent neural network (RNN)
-
nueral network that process sequences
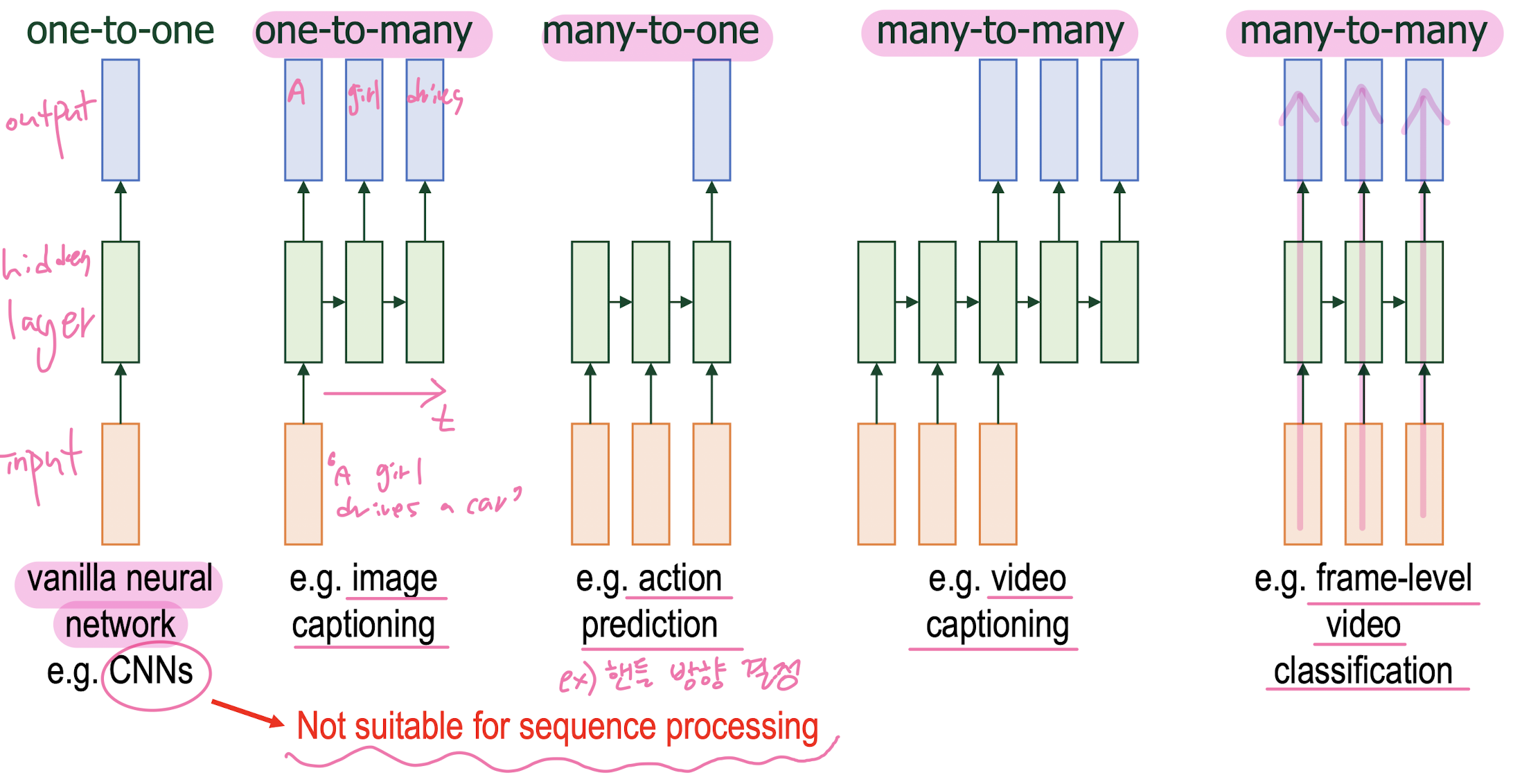
-
RNN
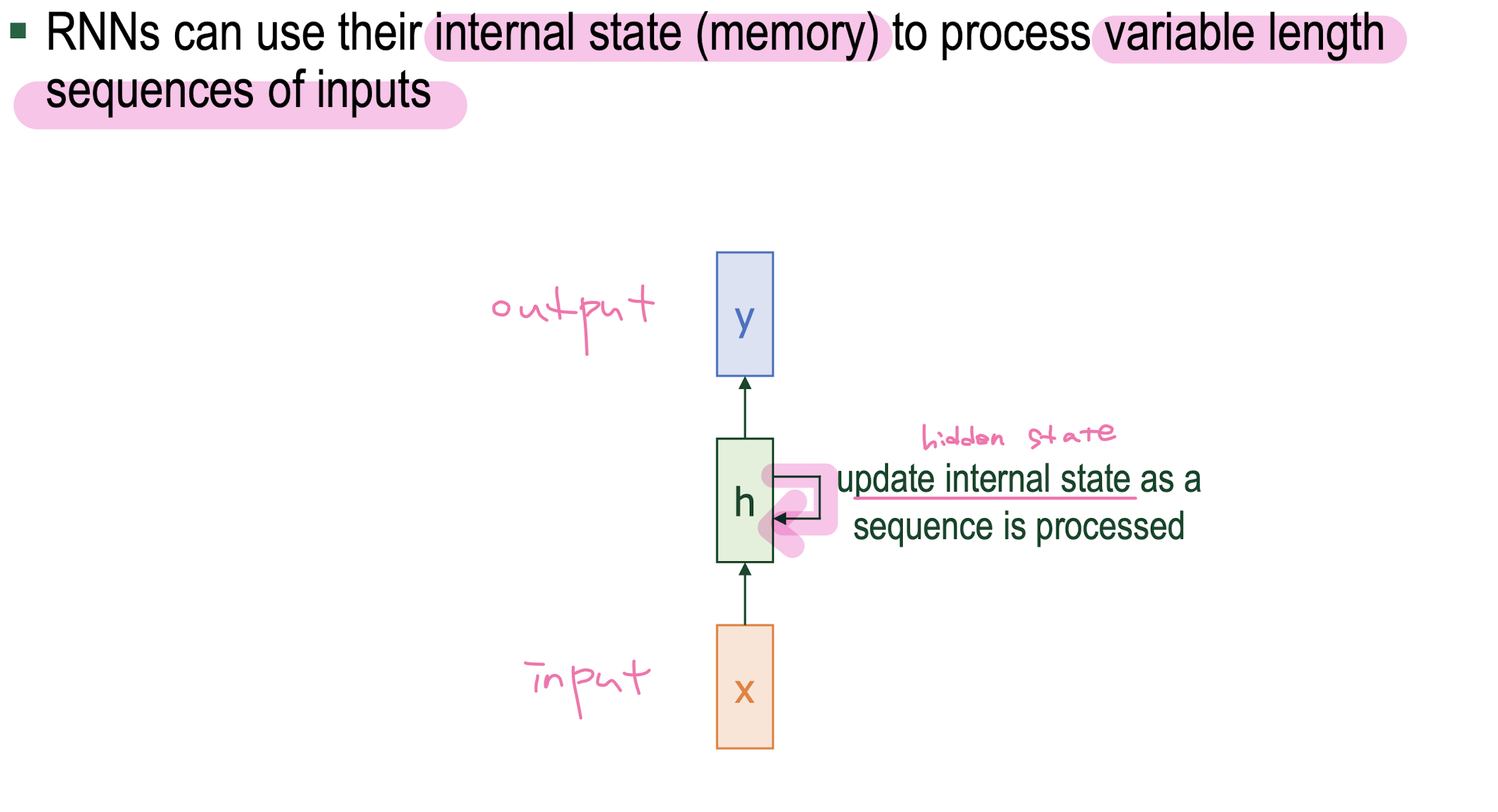
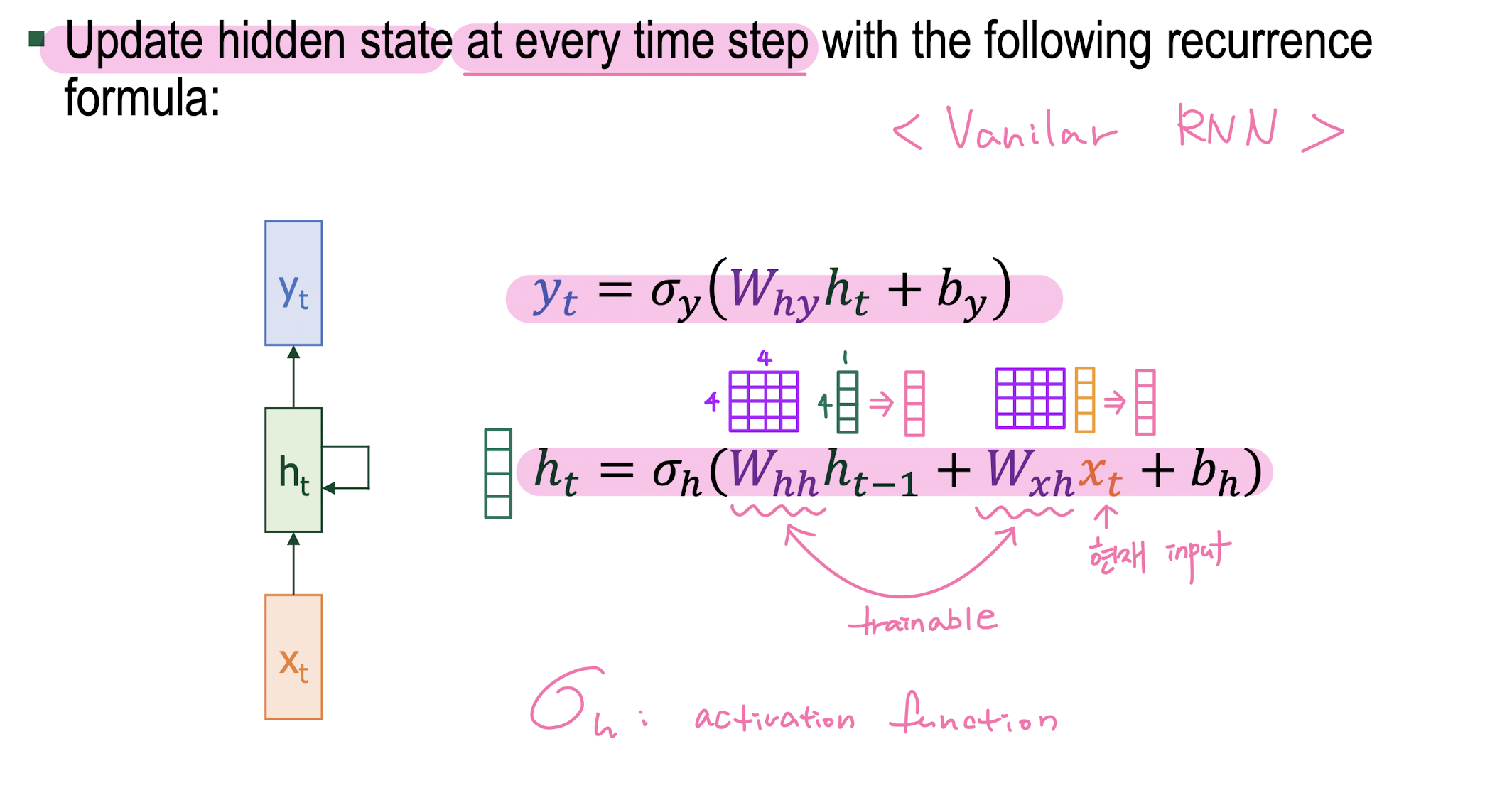
-
Unrolled RNN
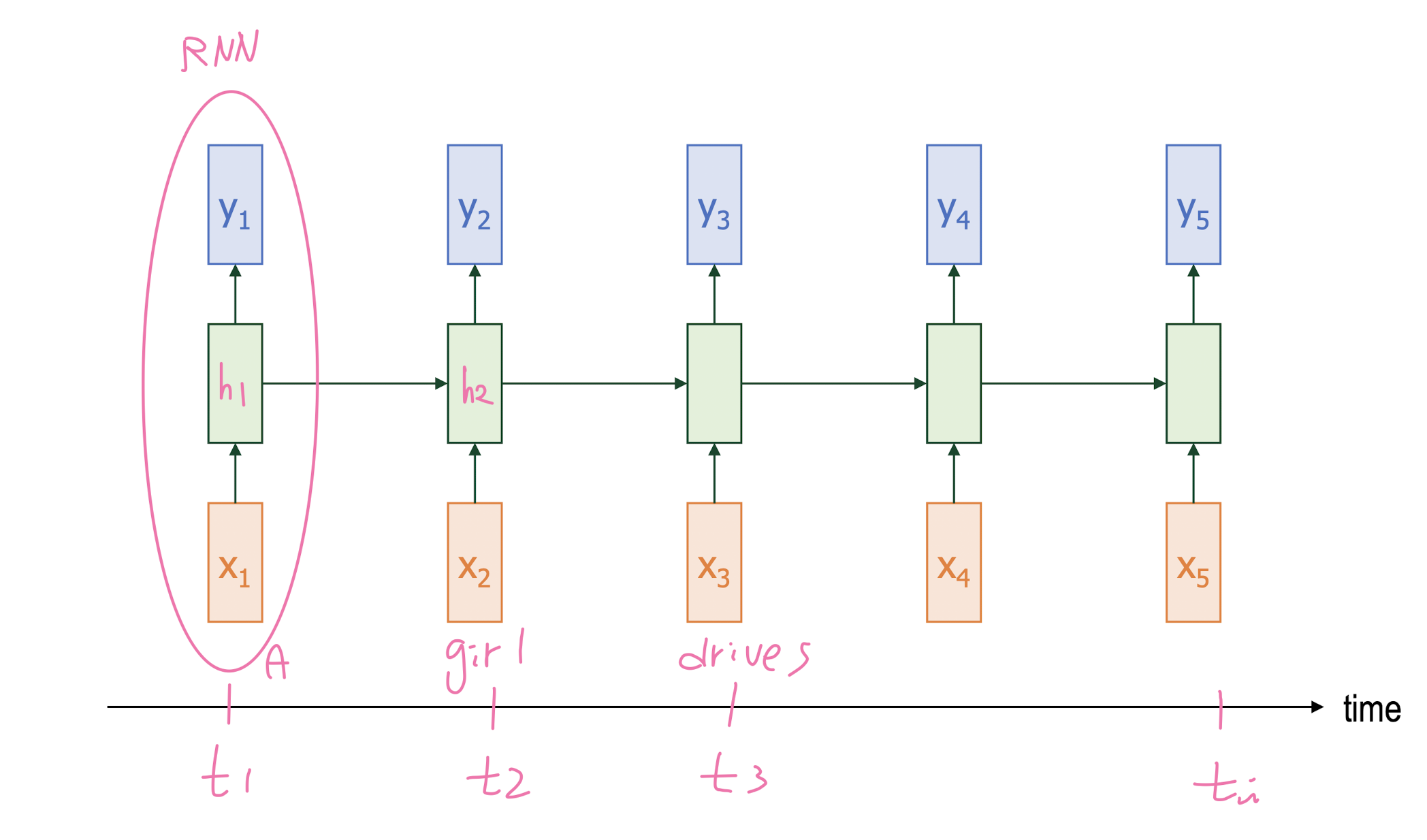

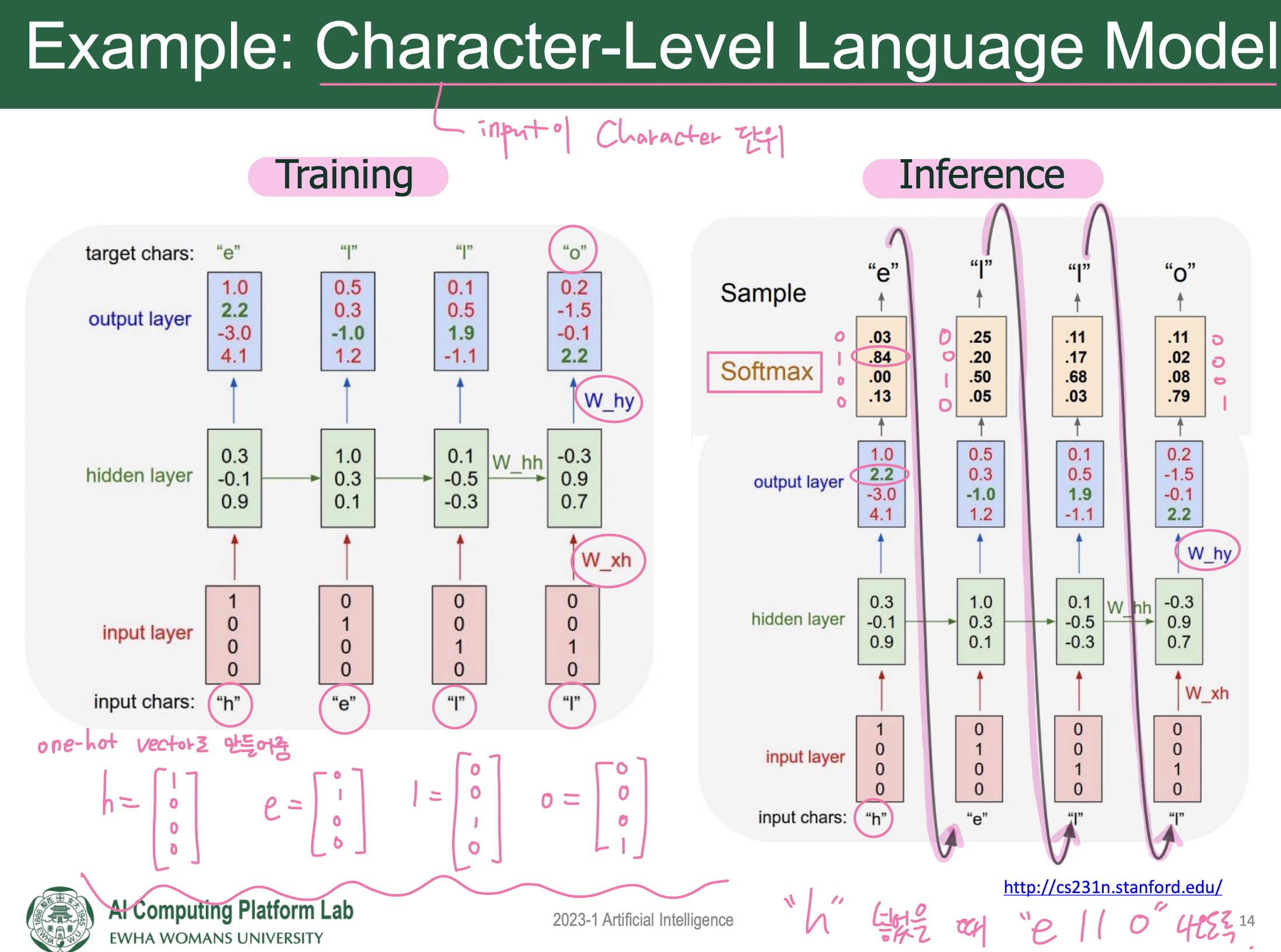
-
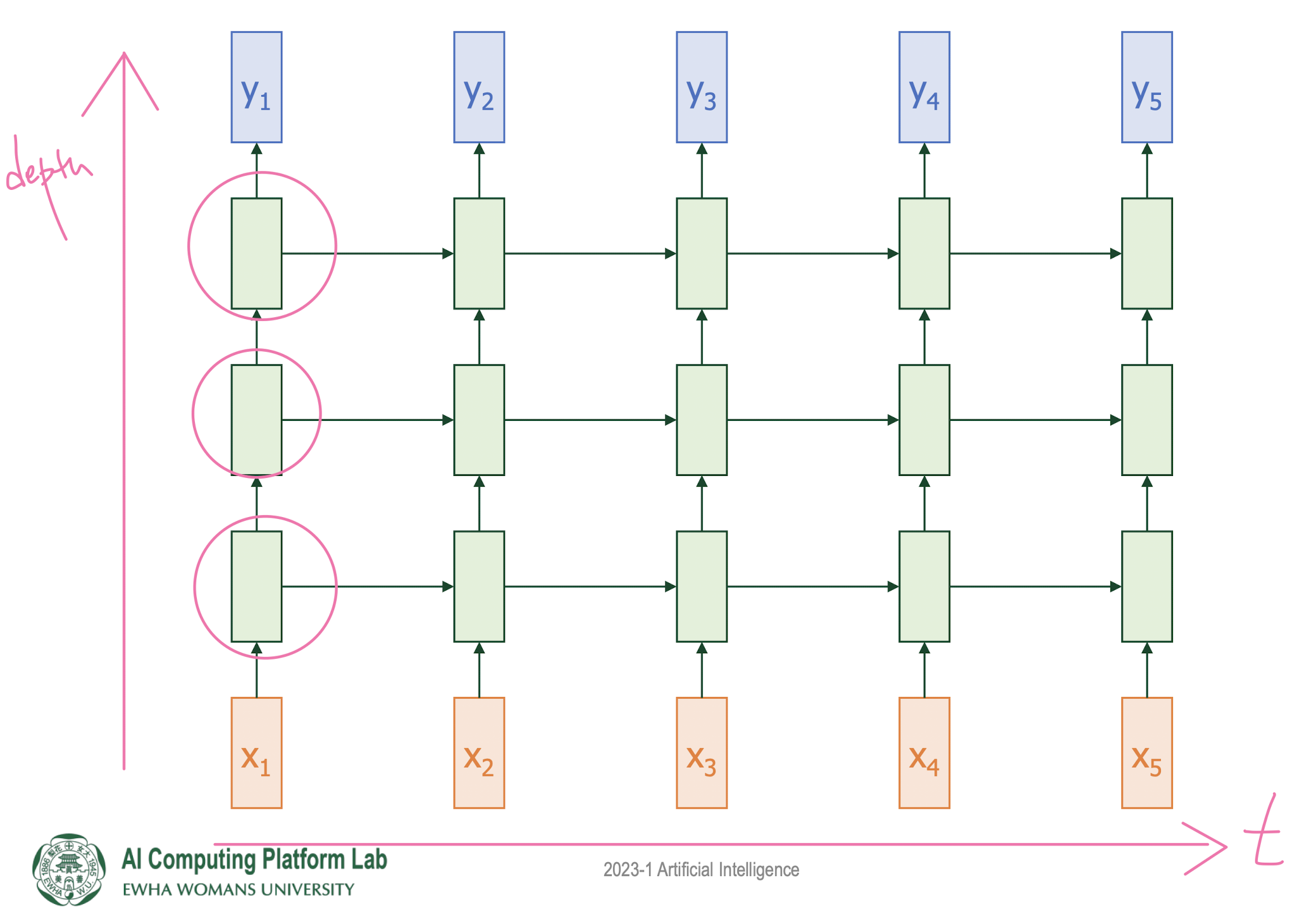
Multi-Layer RNN
Problem of RNN
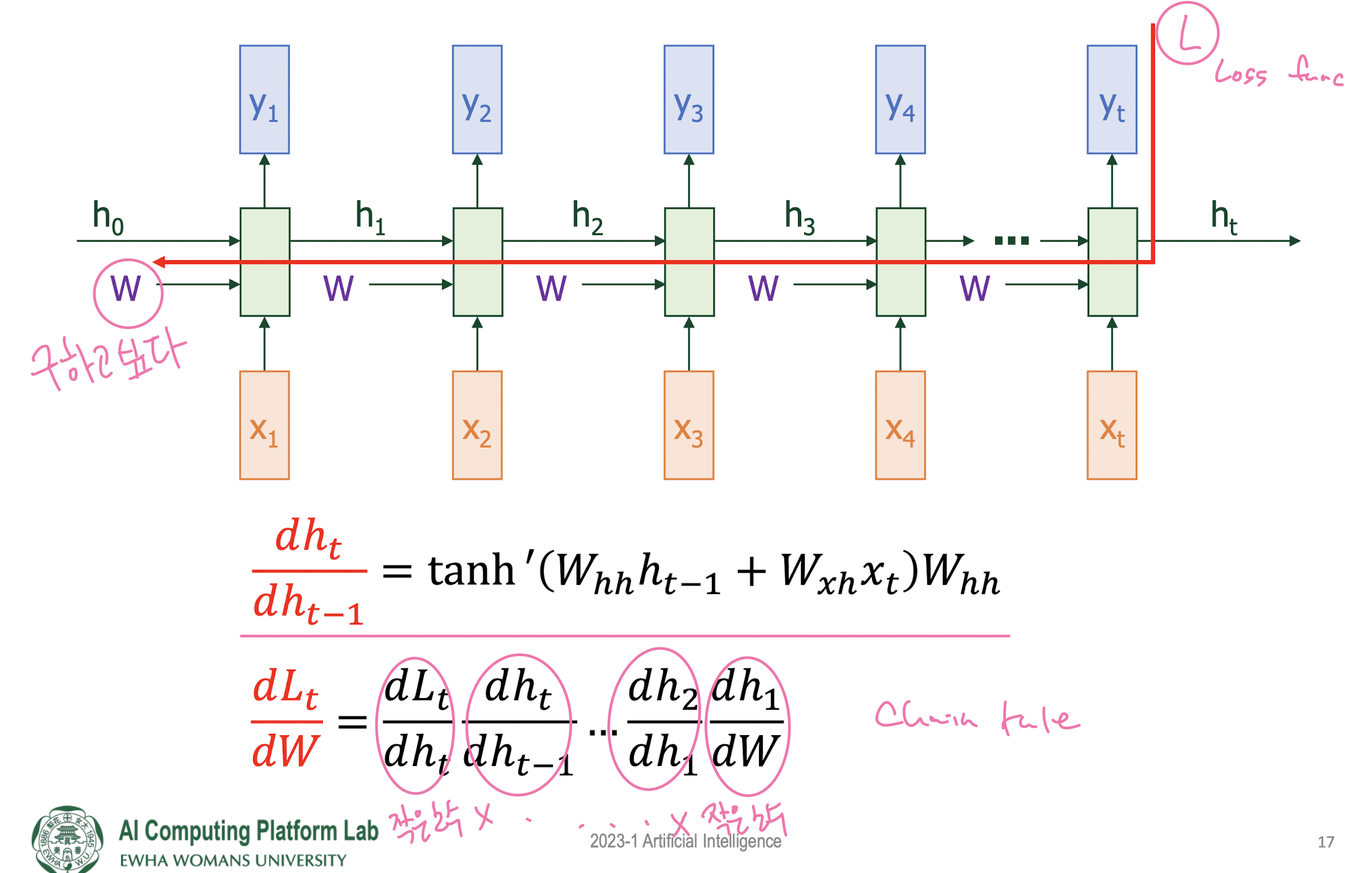
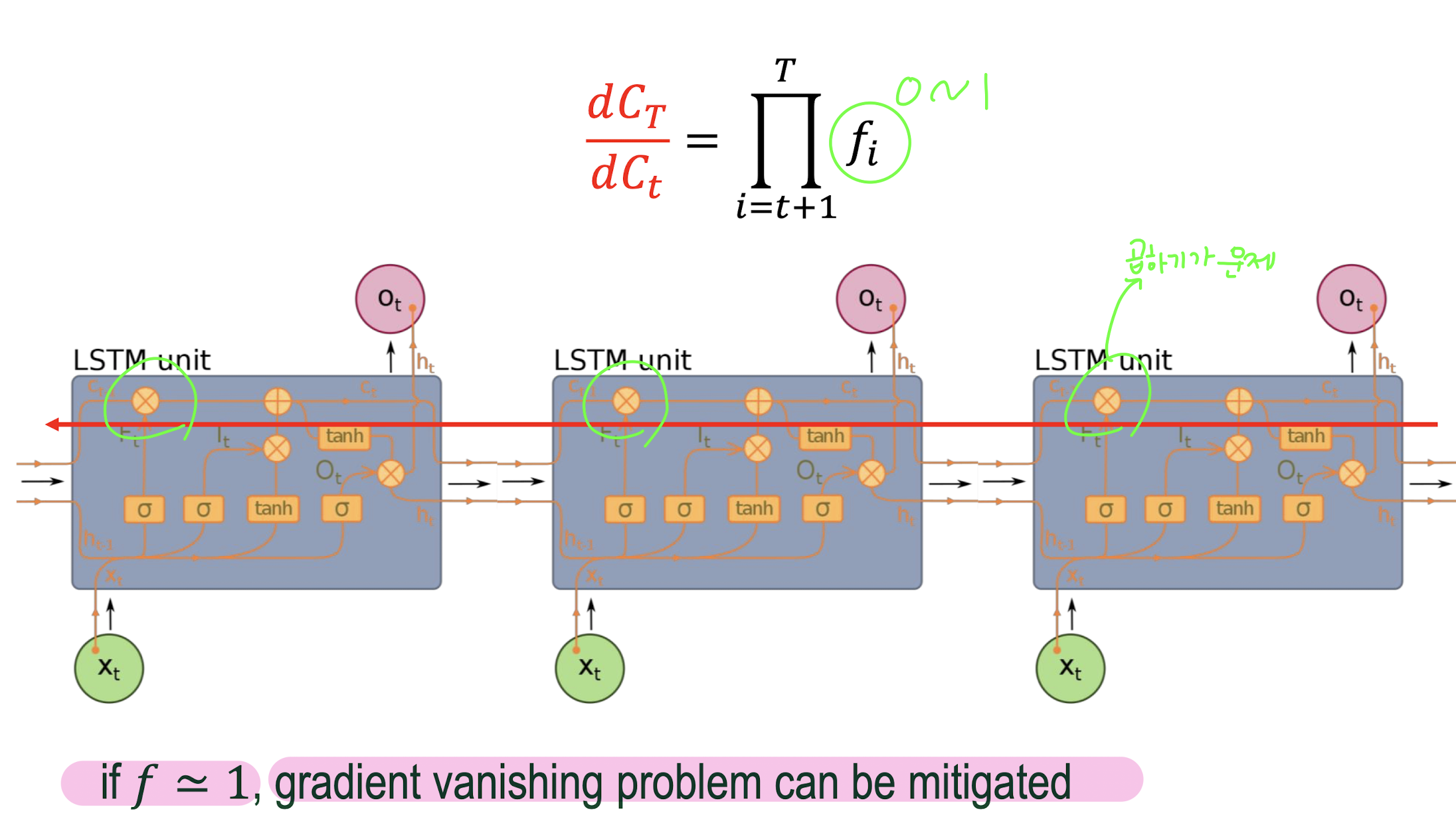
- Gradient Vanishing problem in RNN
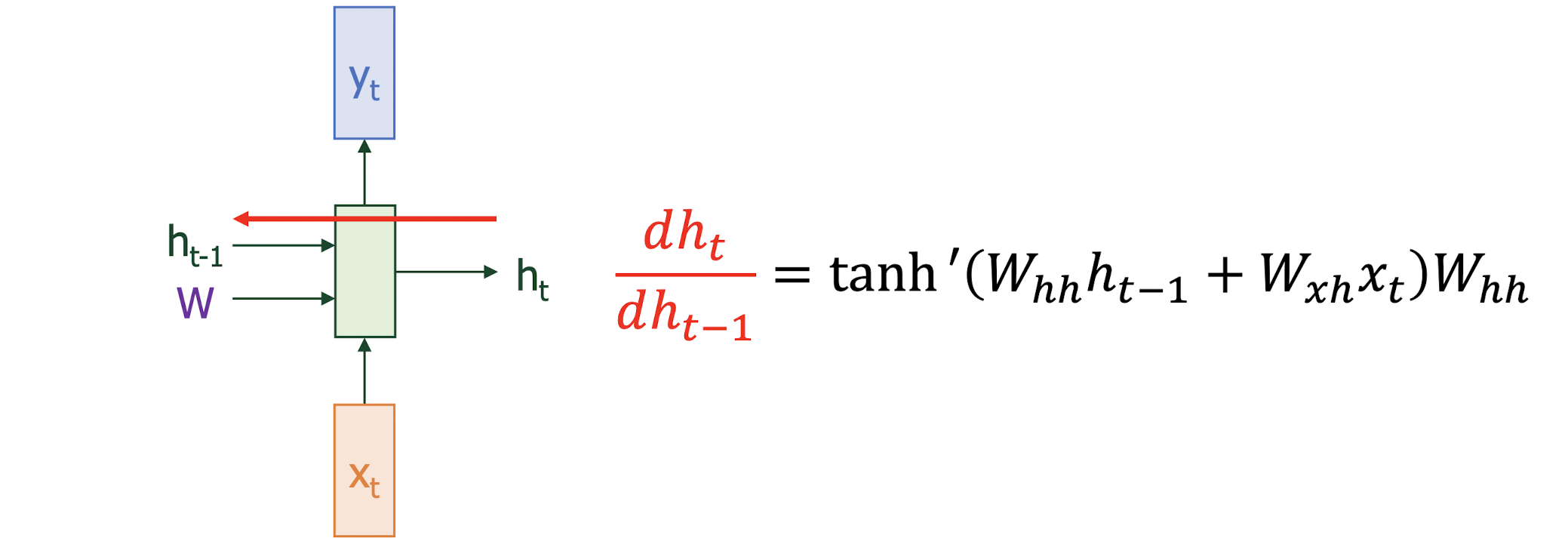
Long Short-Term Memory (LSTM)
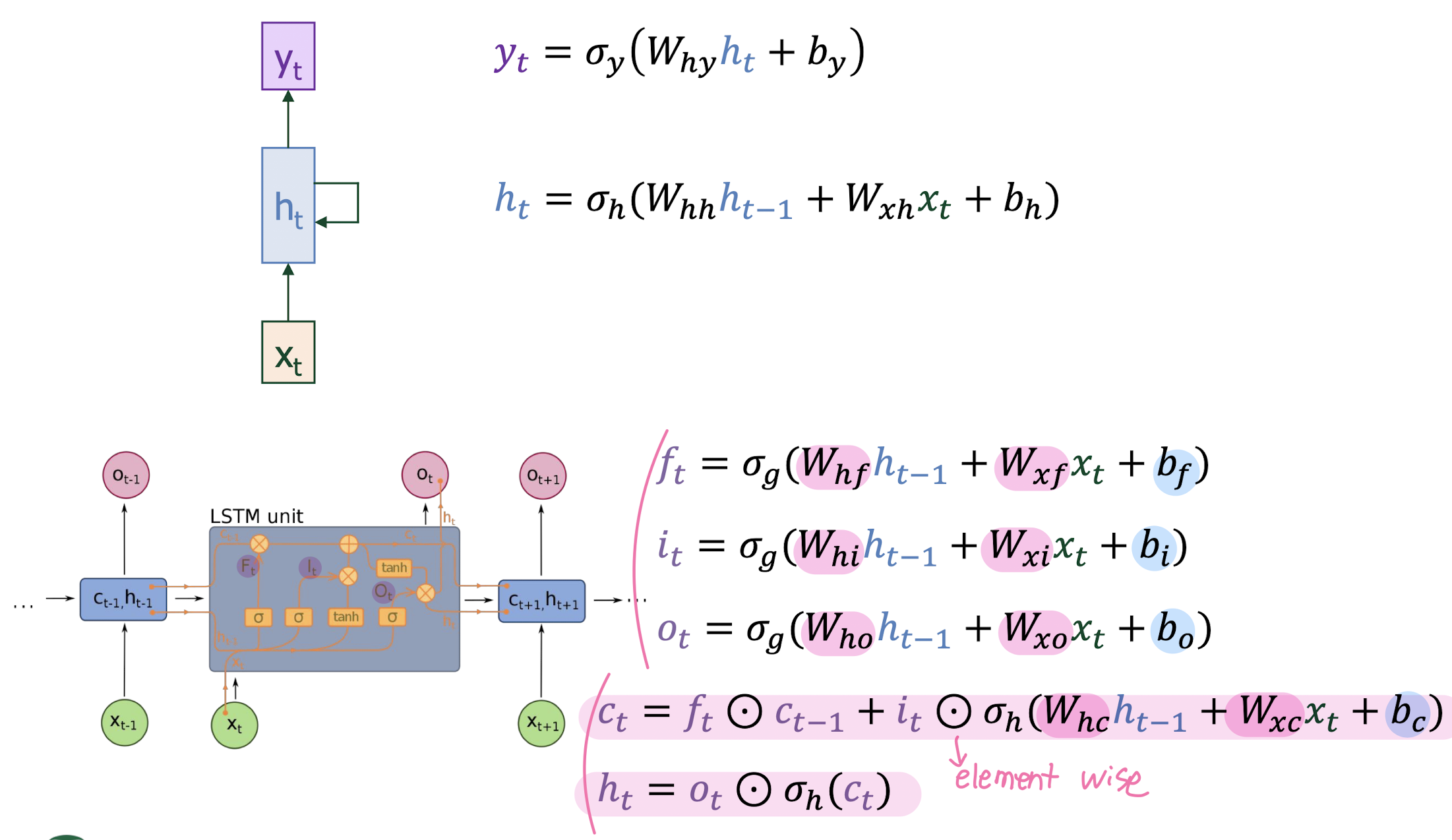
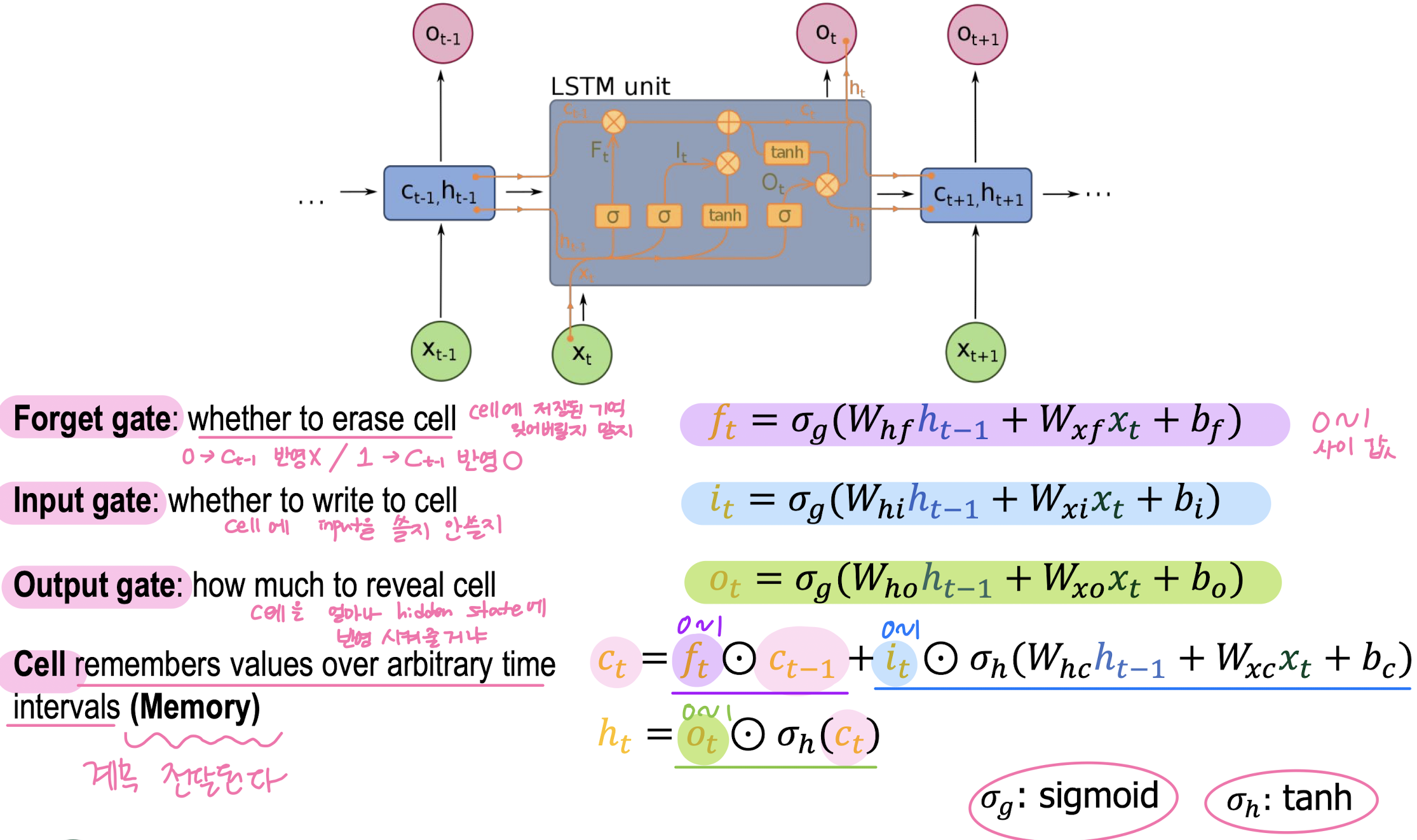
- LSTM Gradient Flow
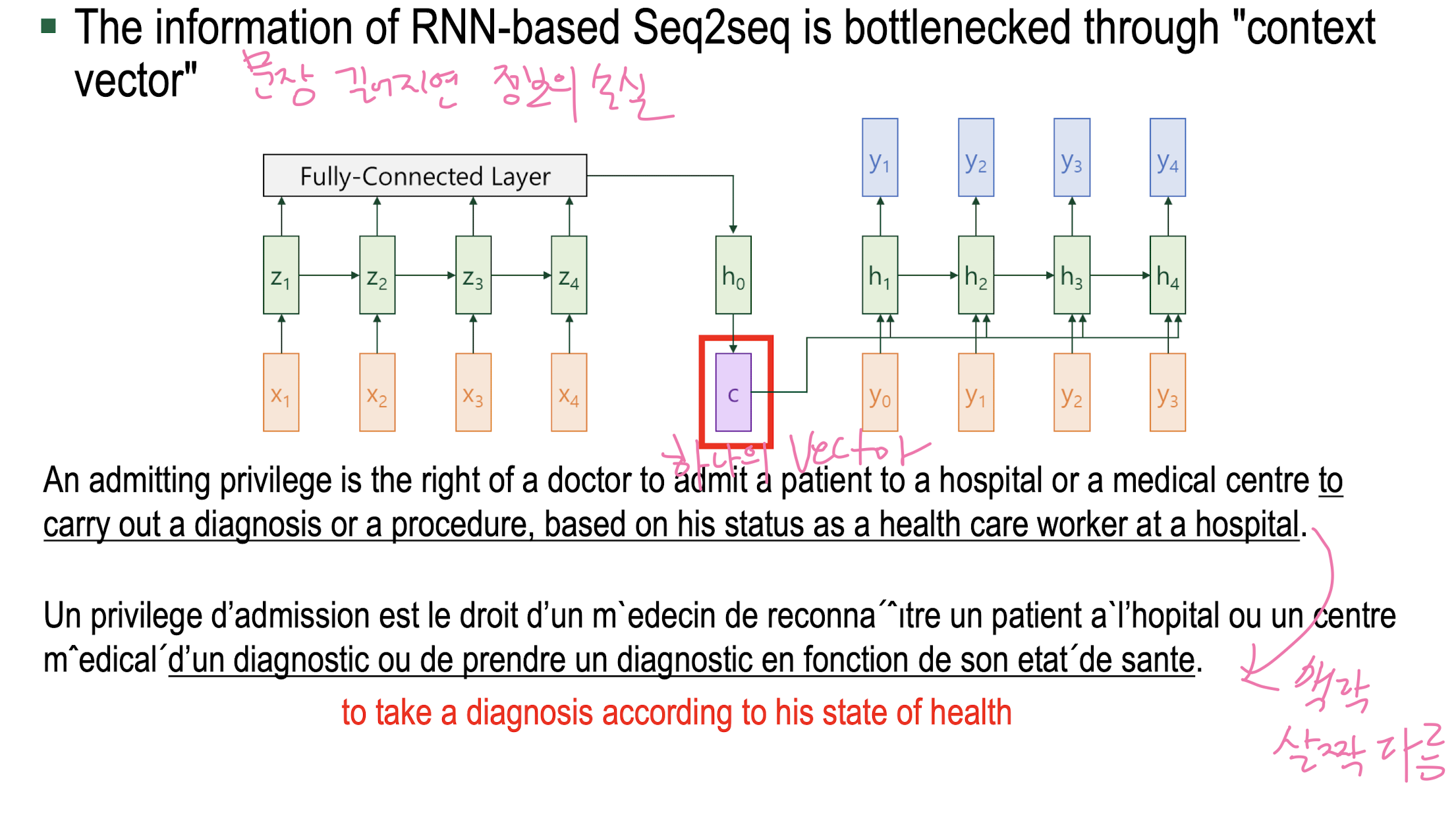
Language Translation (Seq2Seq) Example
use of context vector 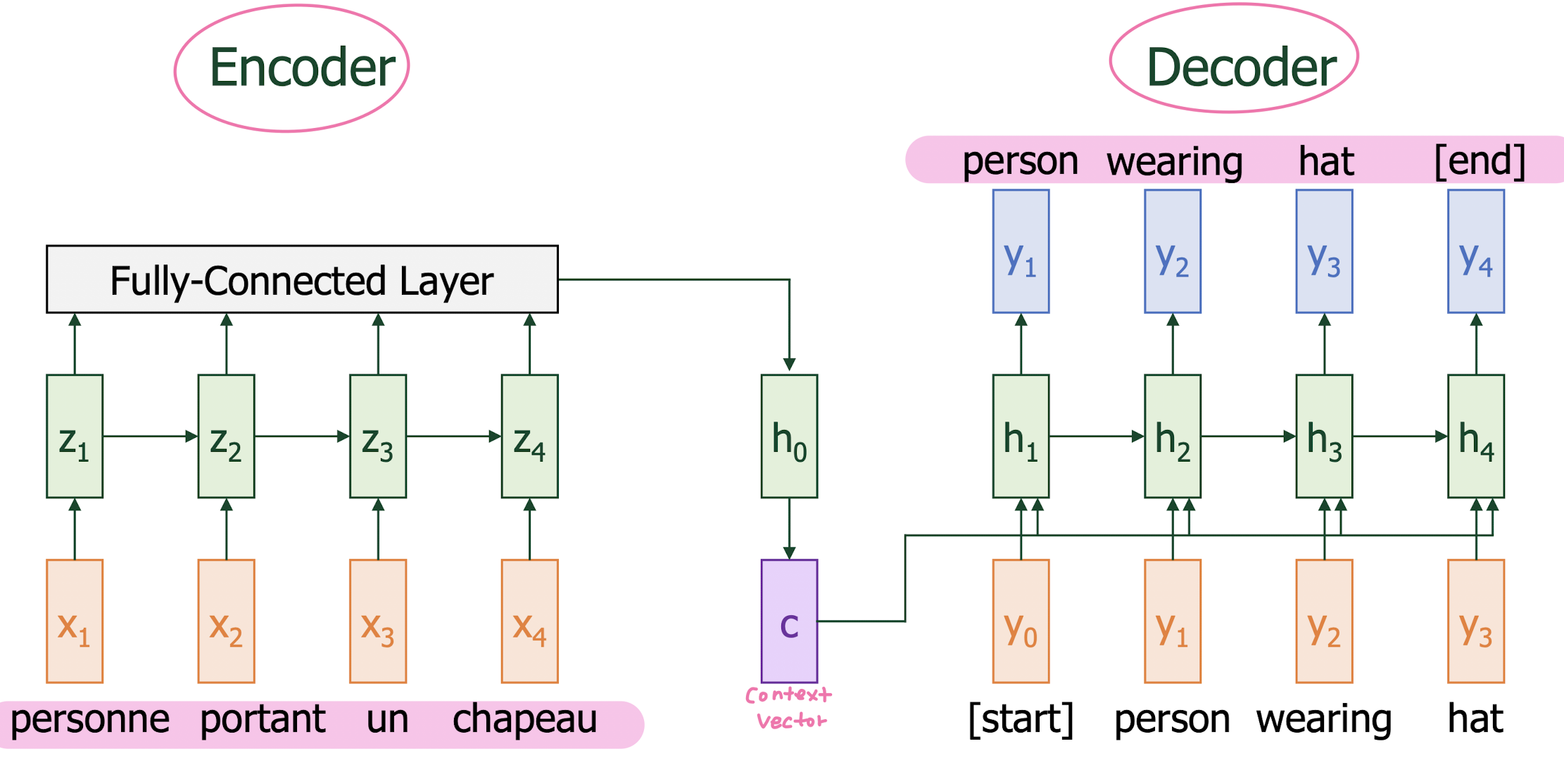
12. Attention
-
Problem of RNN-Bases Seq2Seq
-
Attention

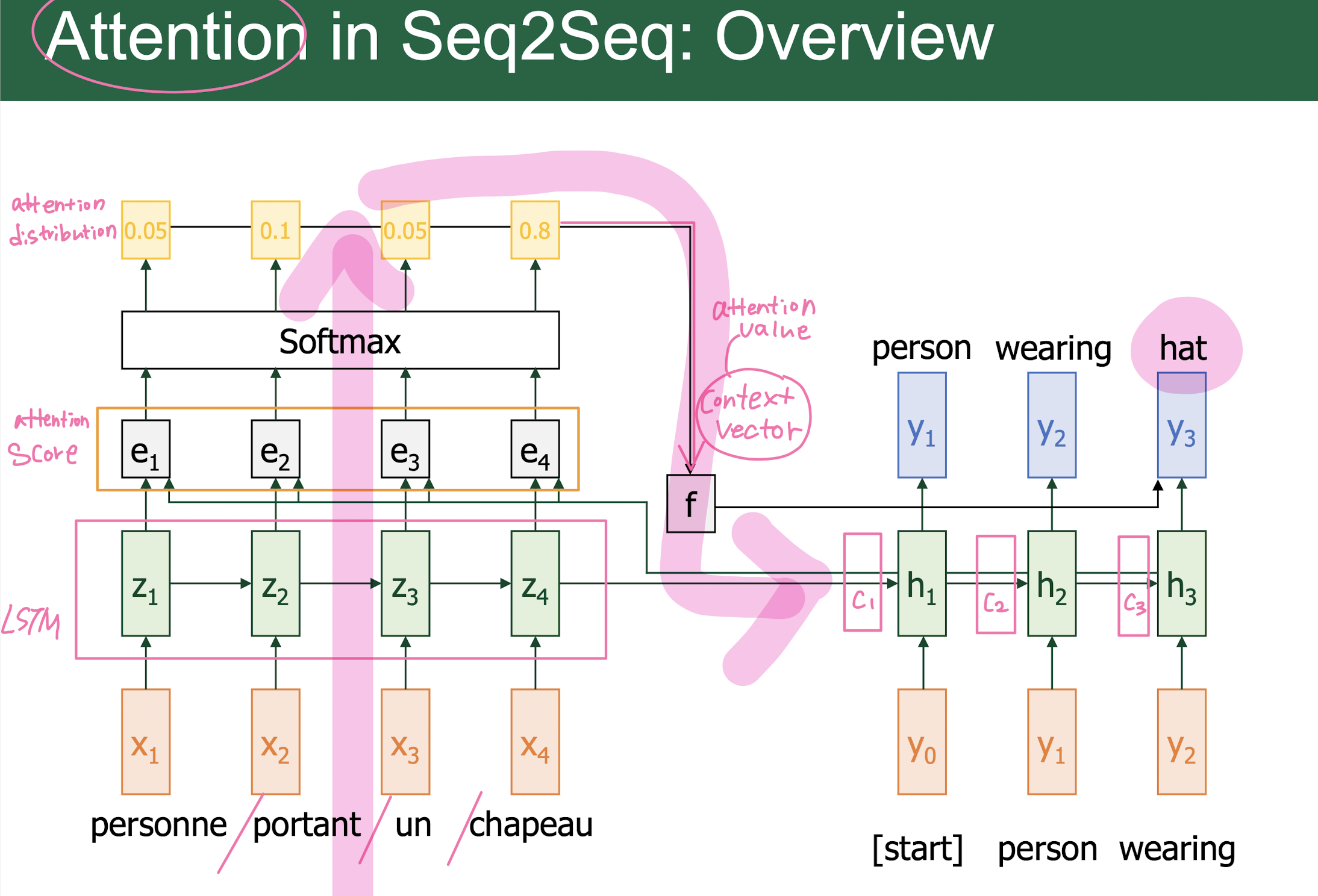
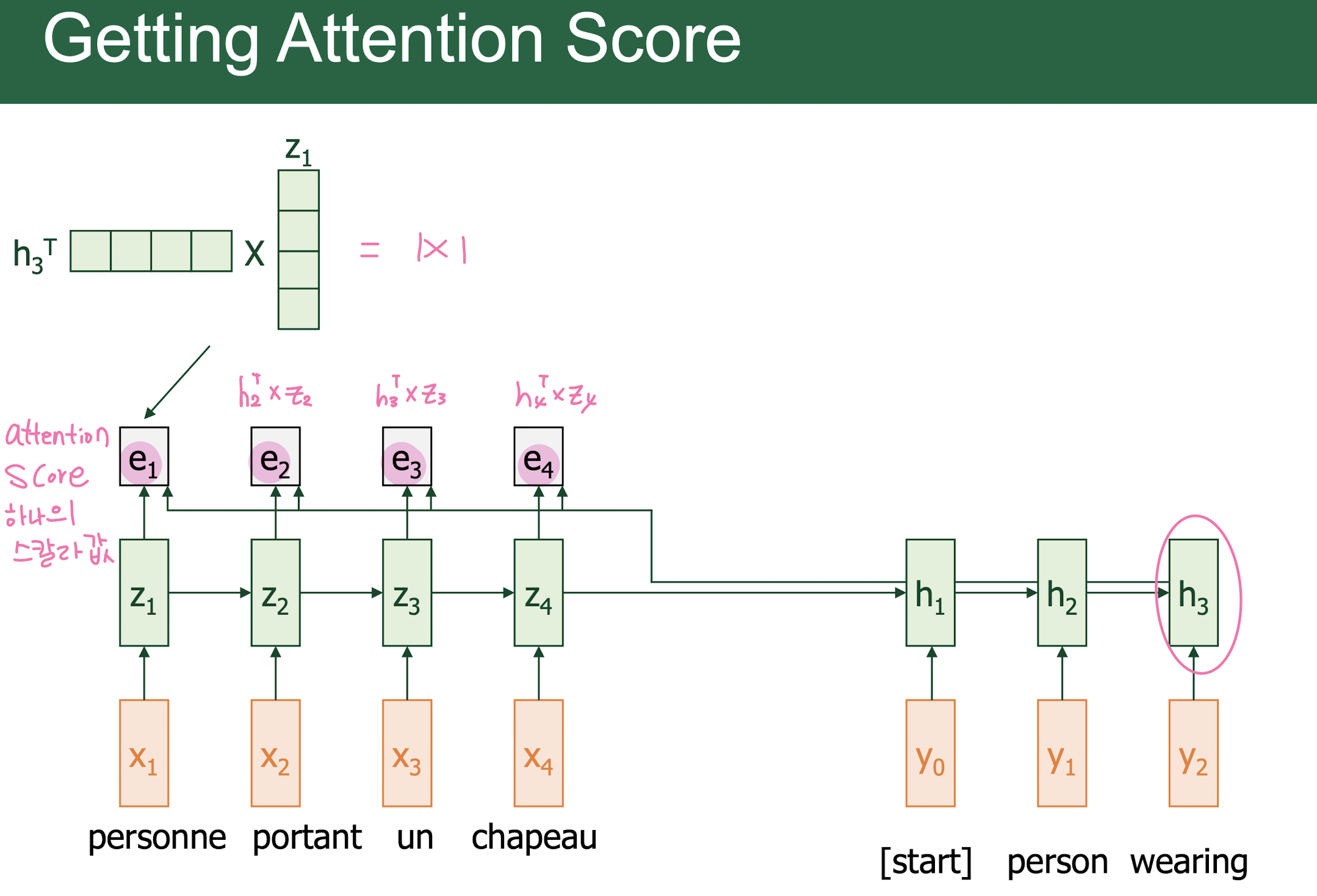
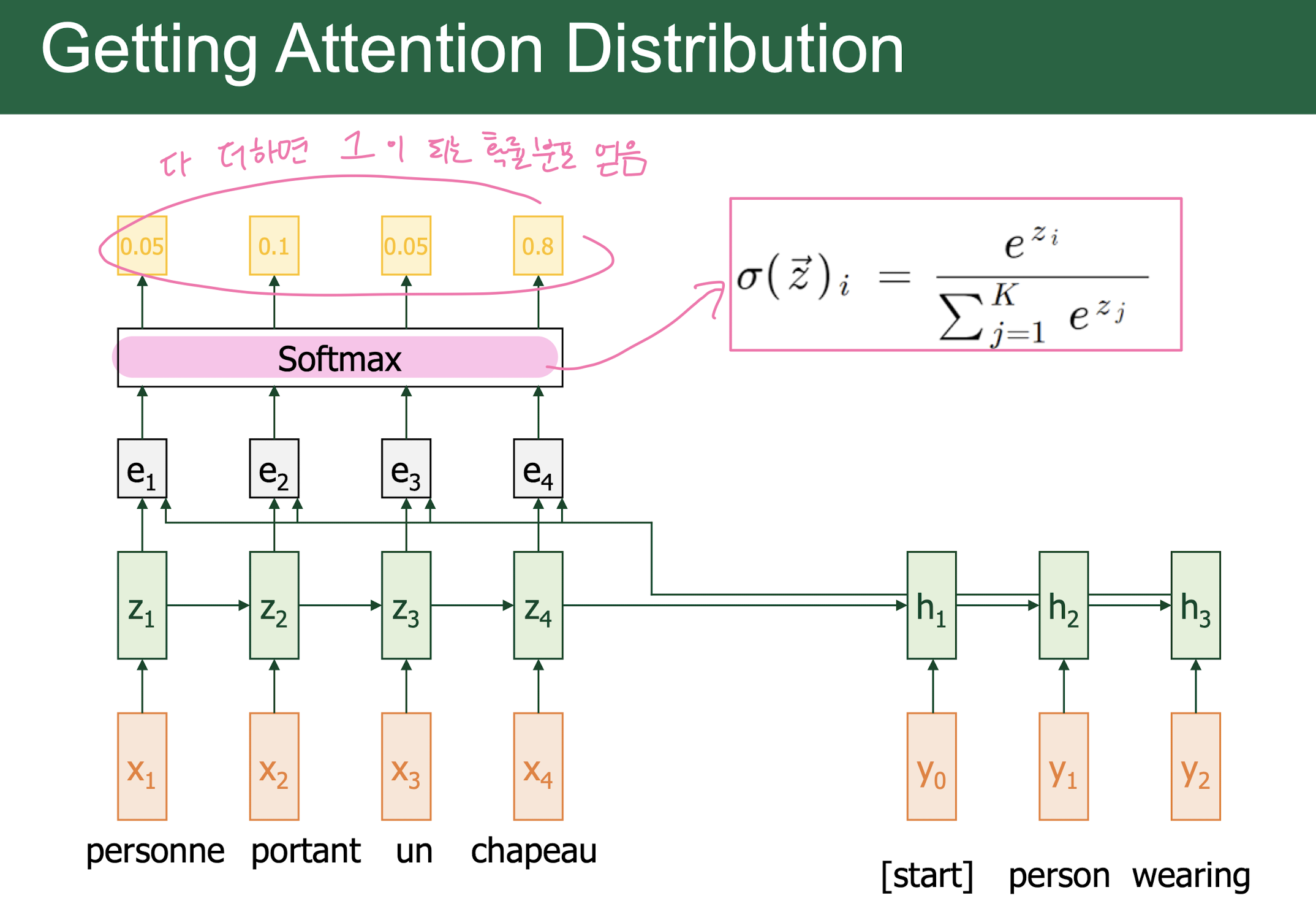
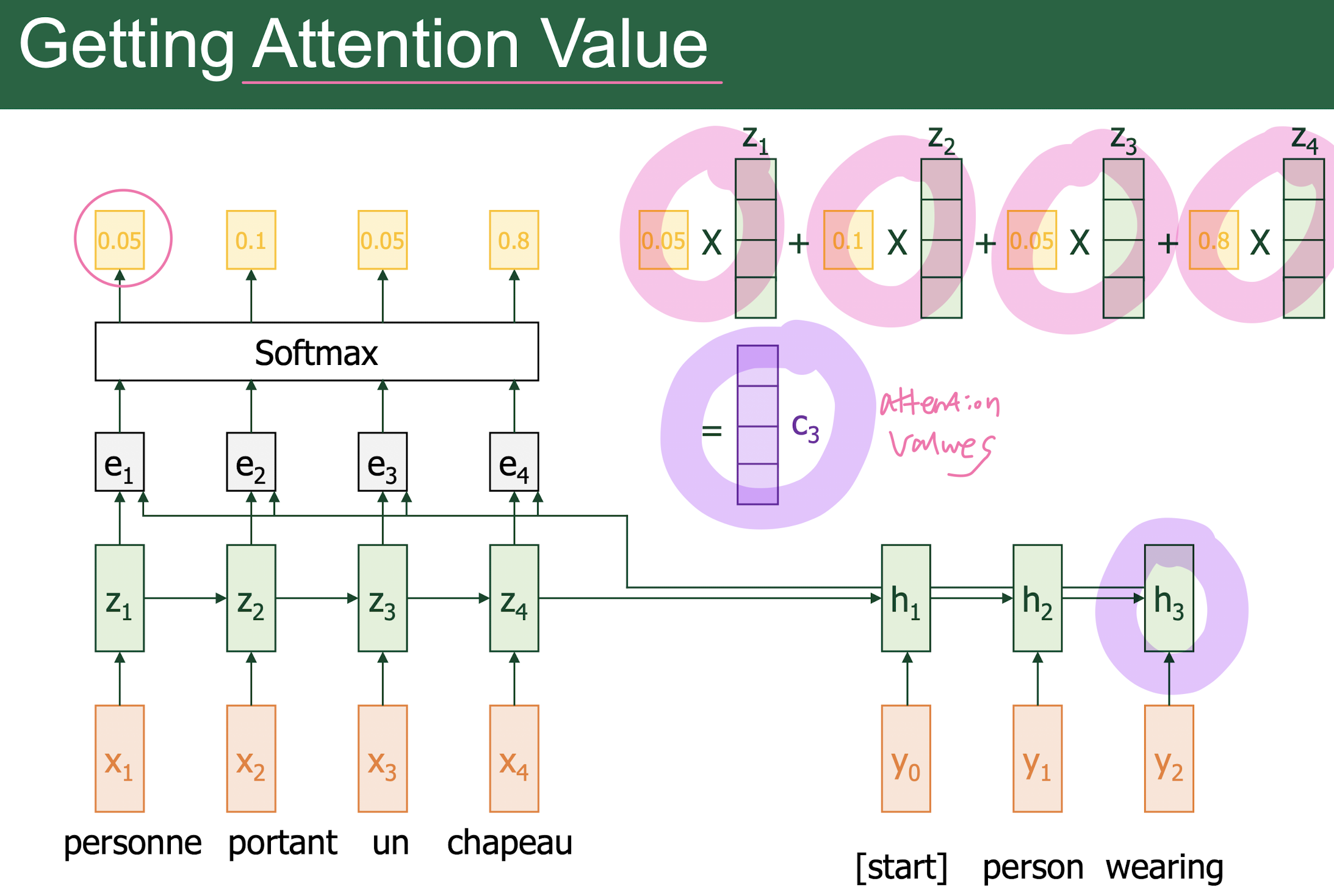
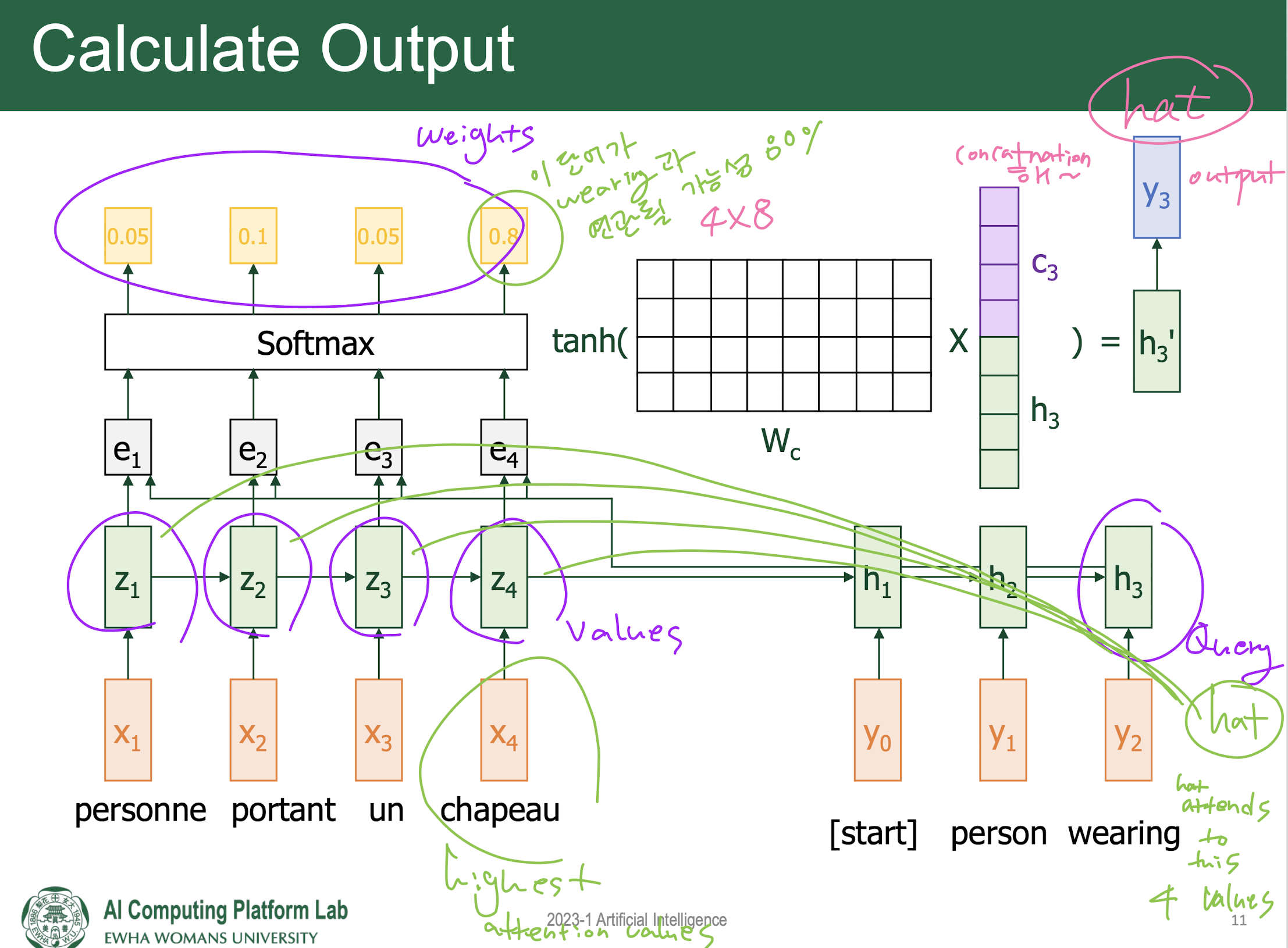
-
Attention is General Technique

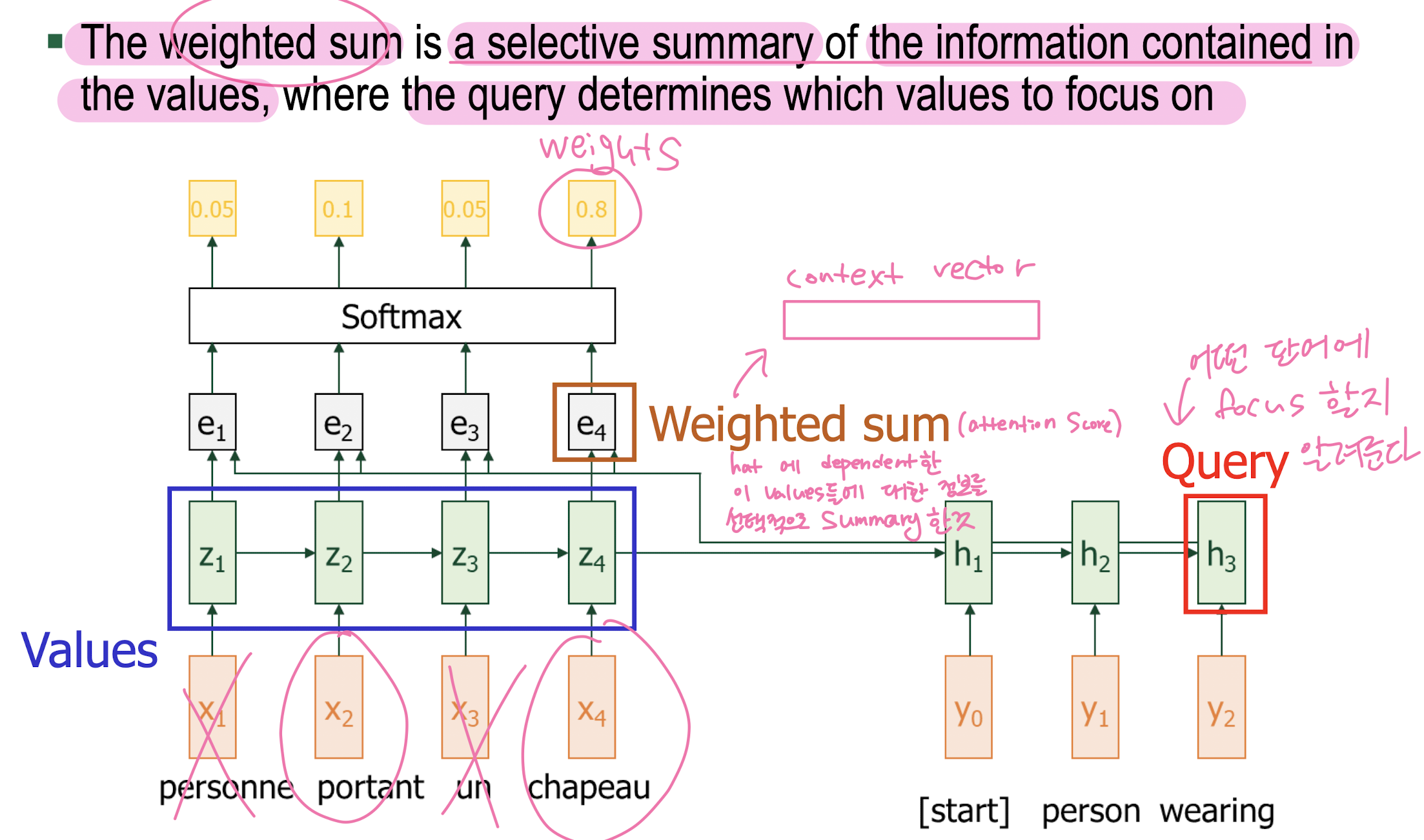
13. Transformer
Attention is all ypu need!
기존의 RNN(LSTM) + Attention 에서 Attention만!
Transformer: Model Architecture
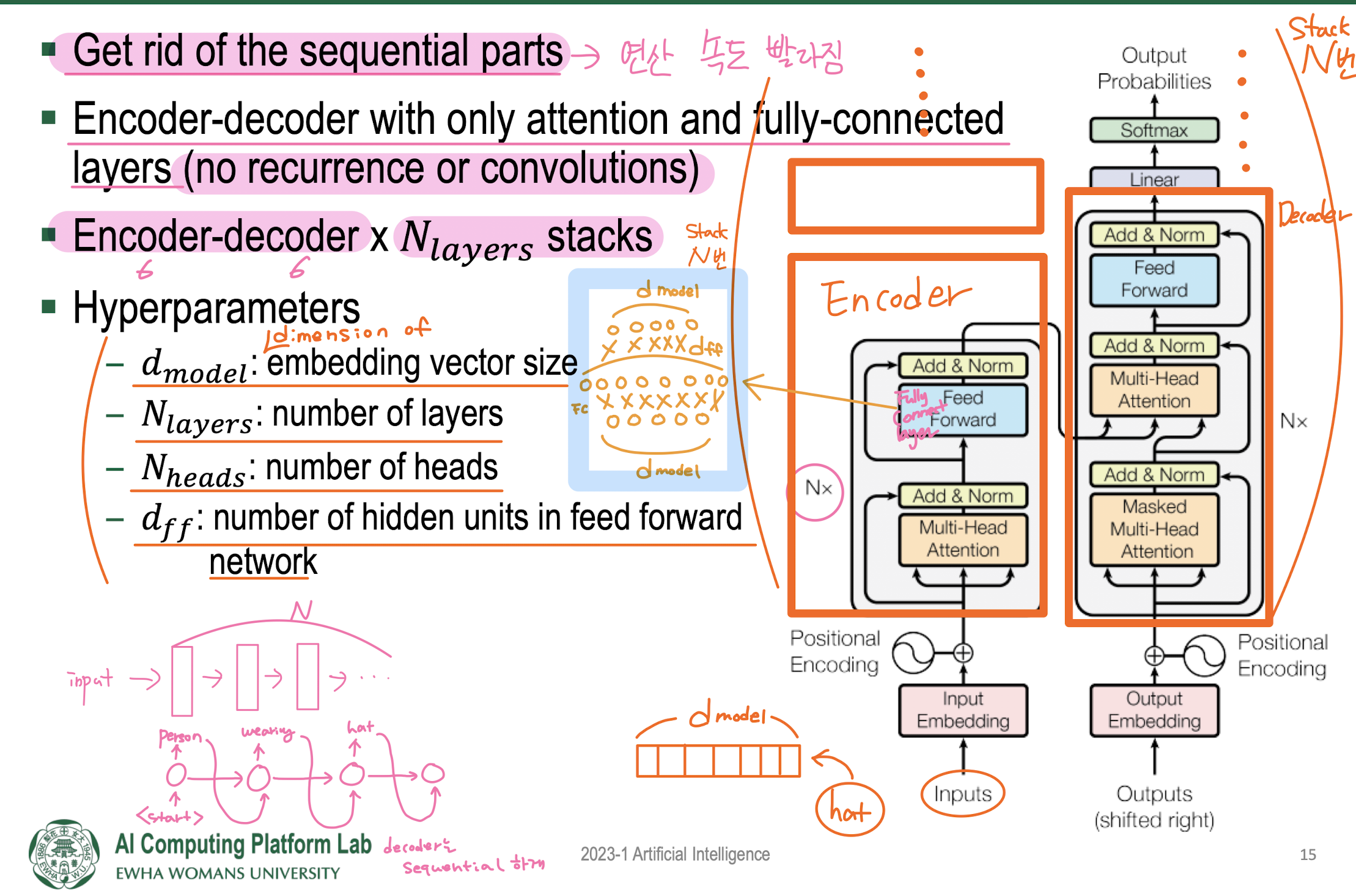
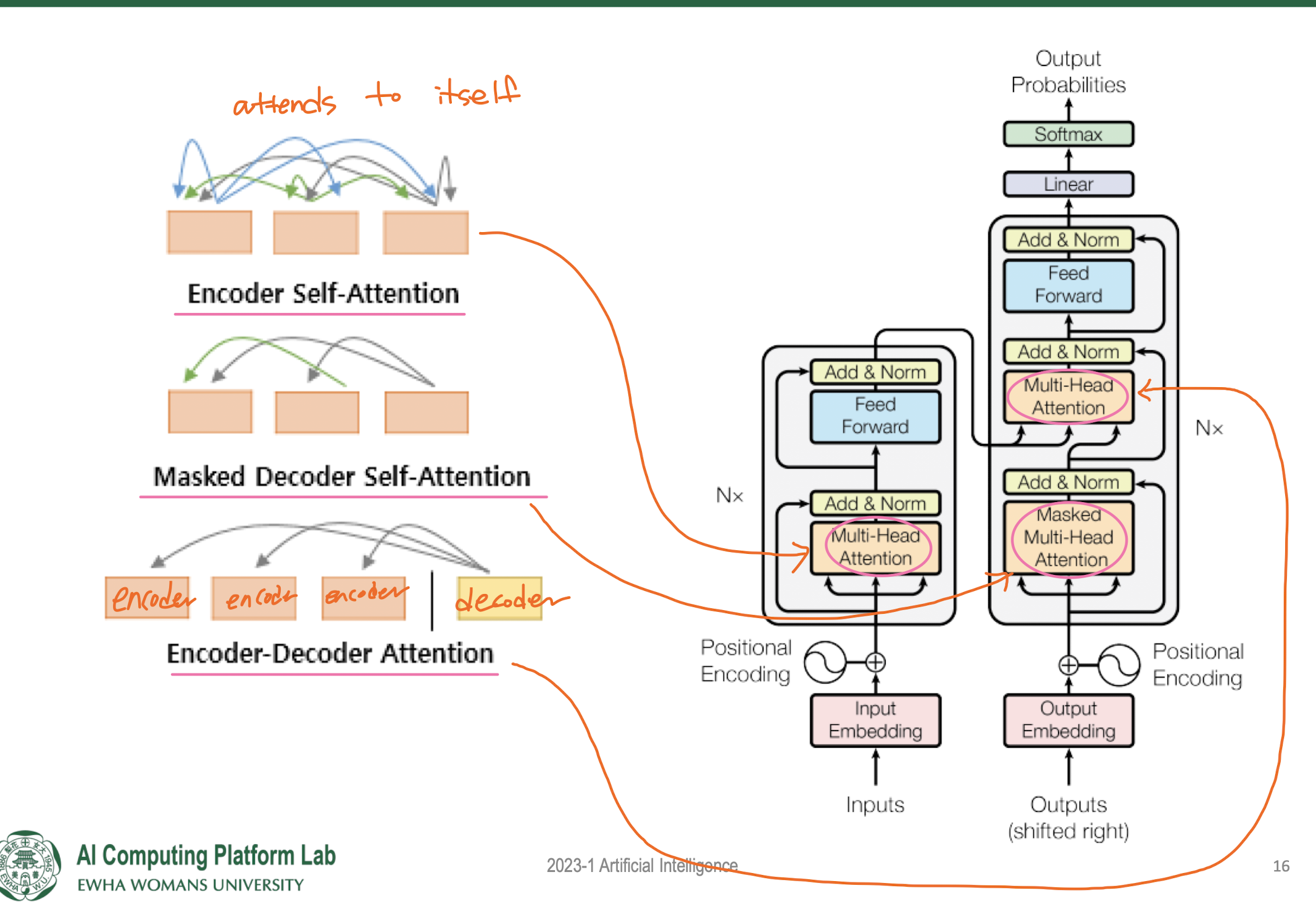
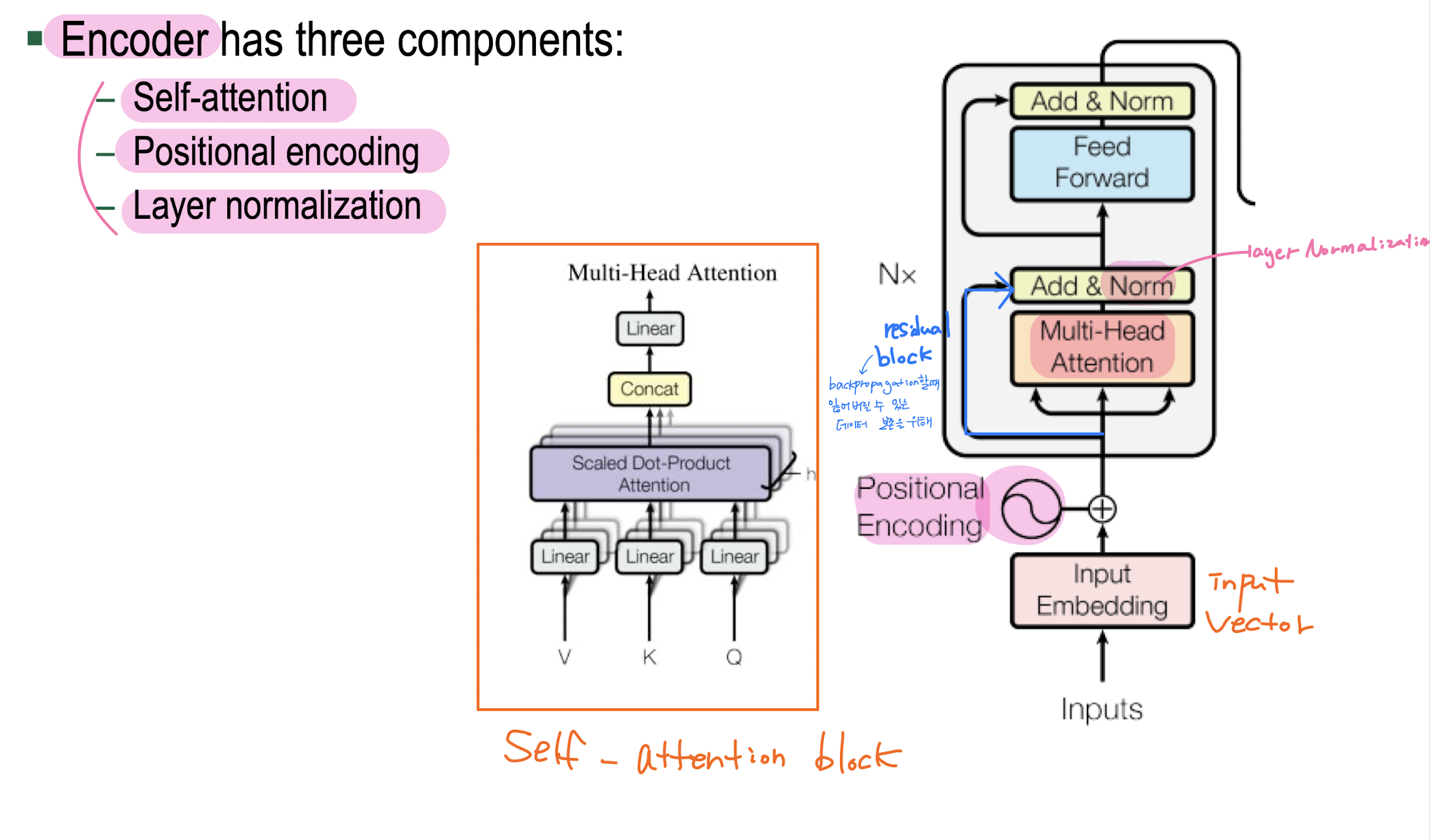
Transformer: Encoder Architecture
1. Self Attention
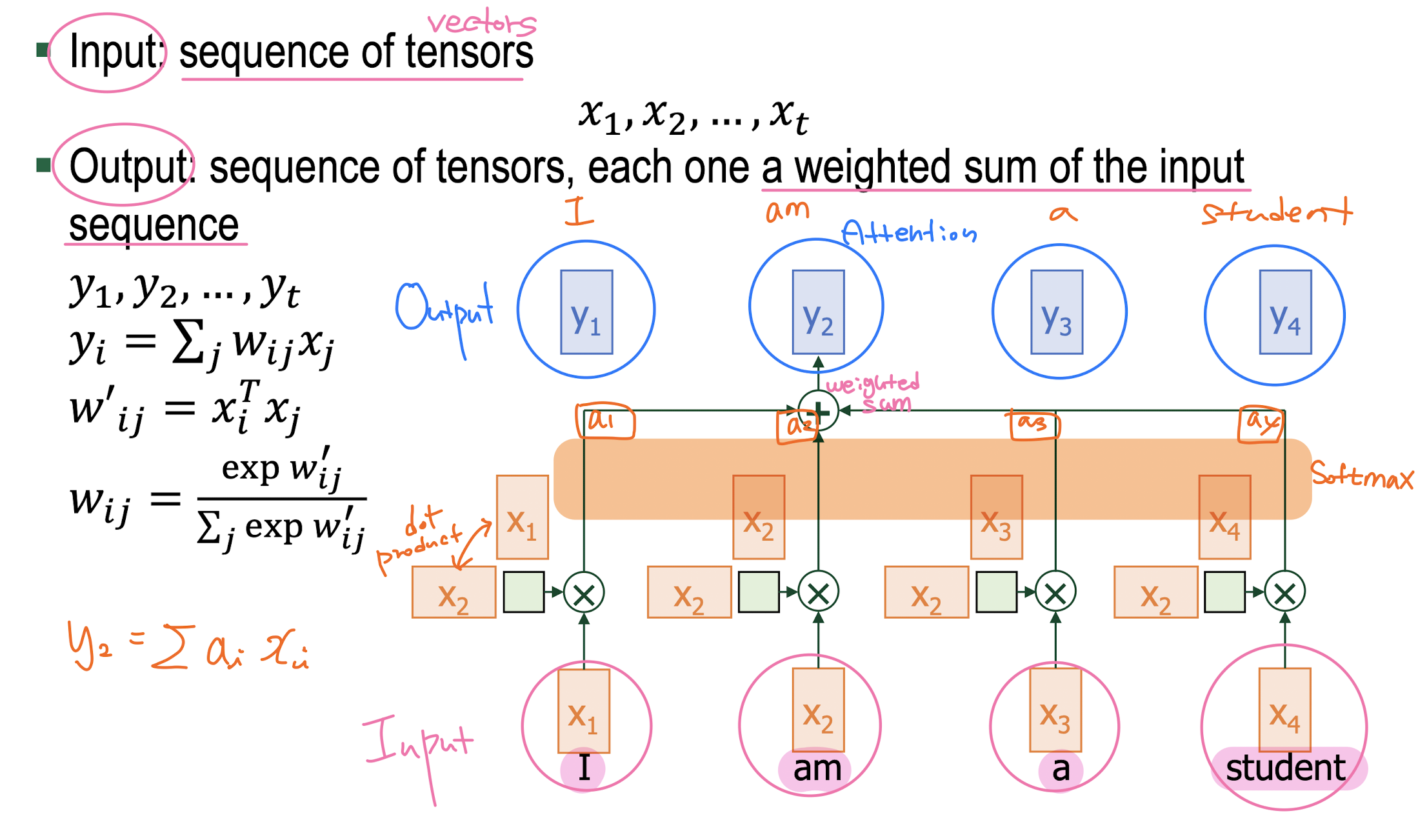
-
Query, Key, Value
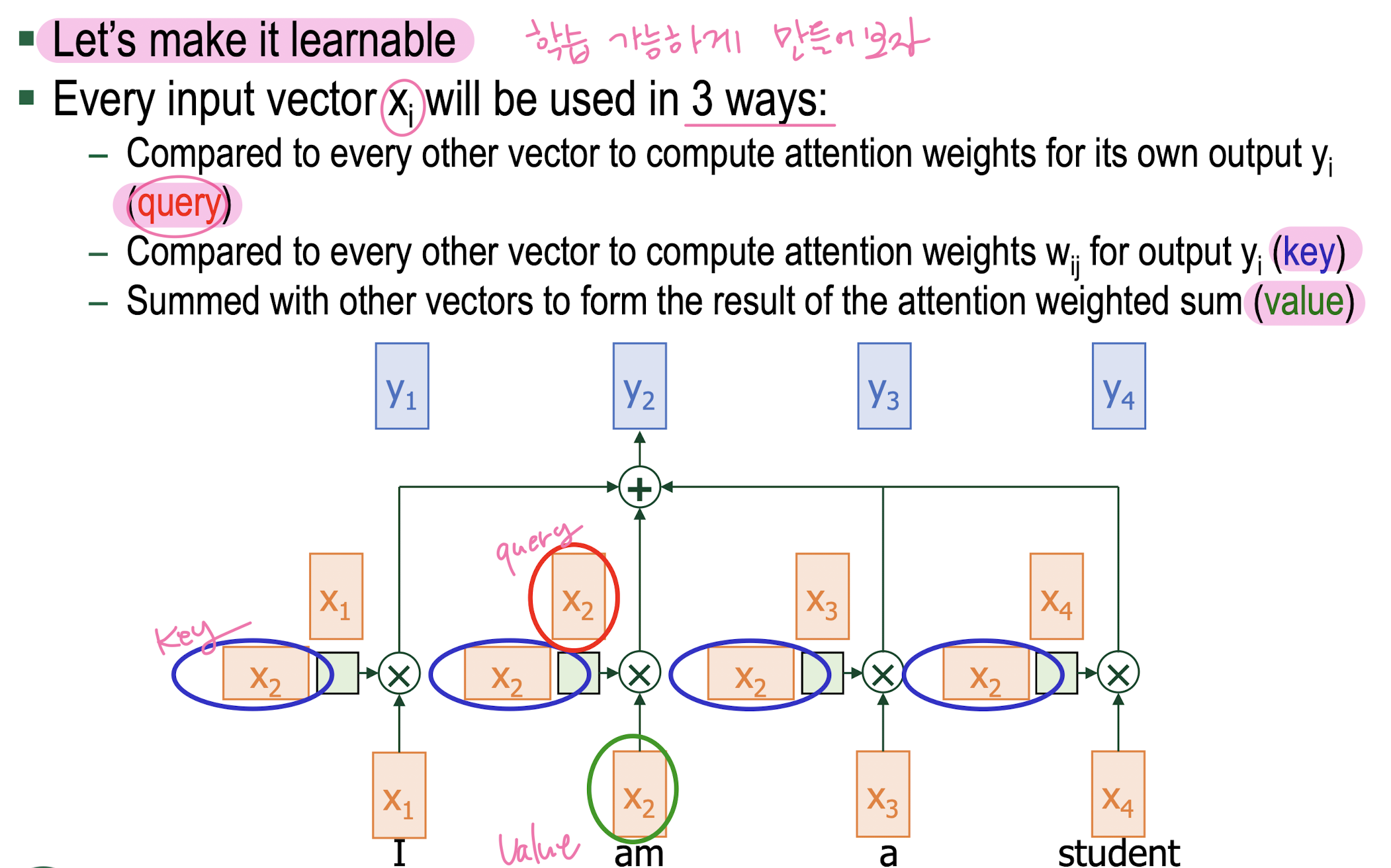
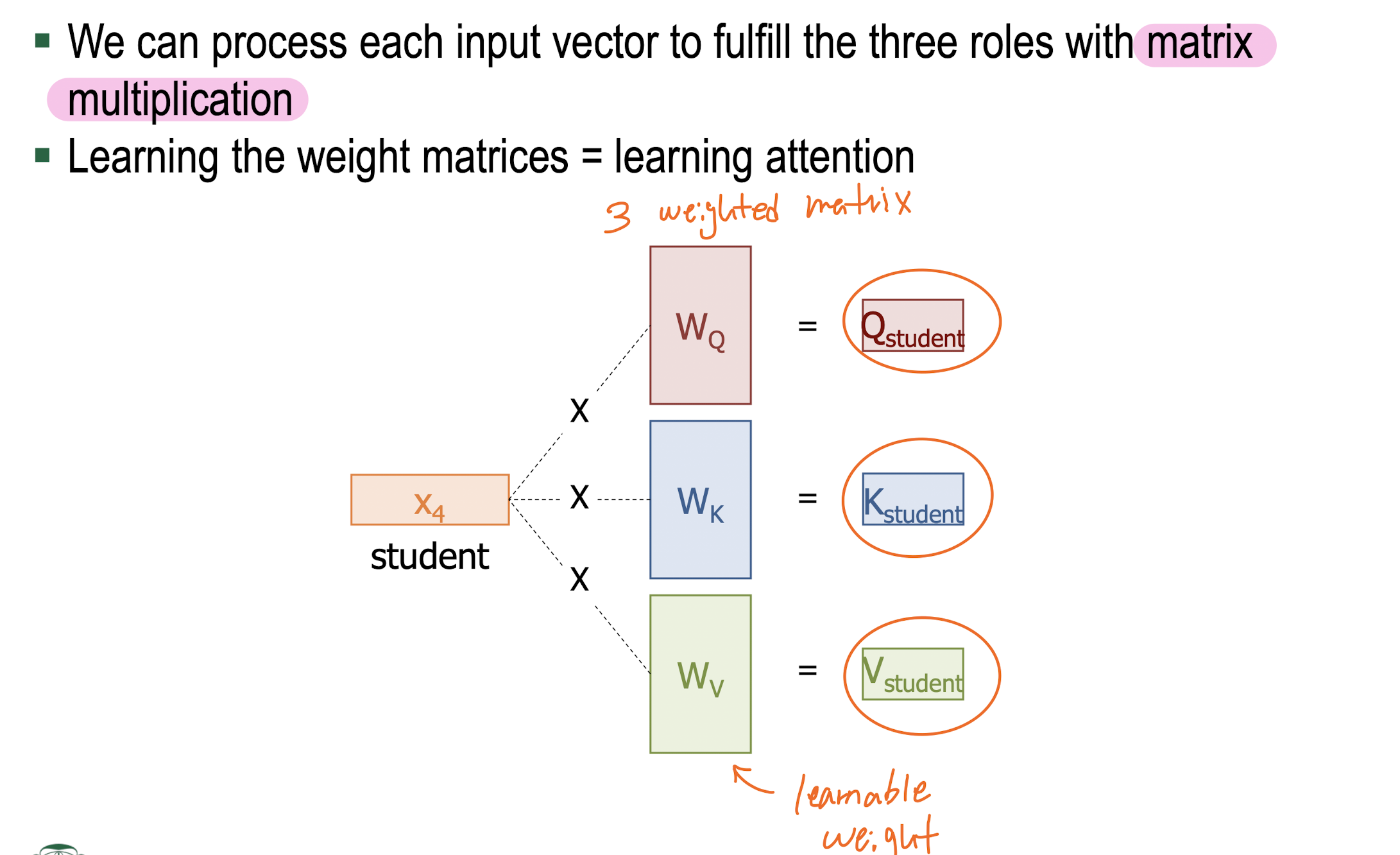
-
Scaled Dot-Product Attention
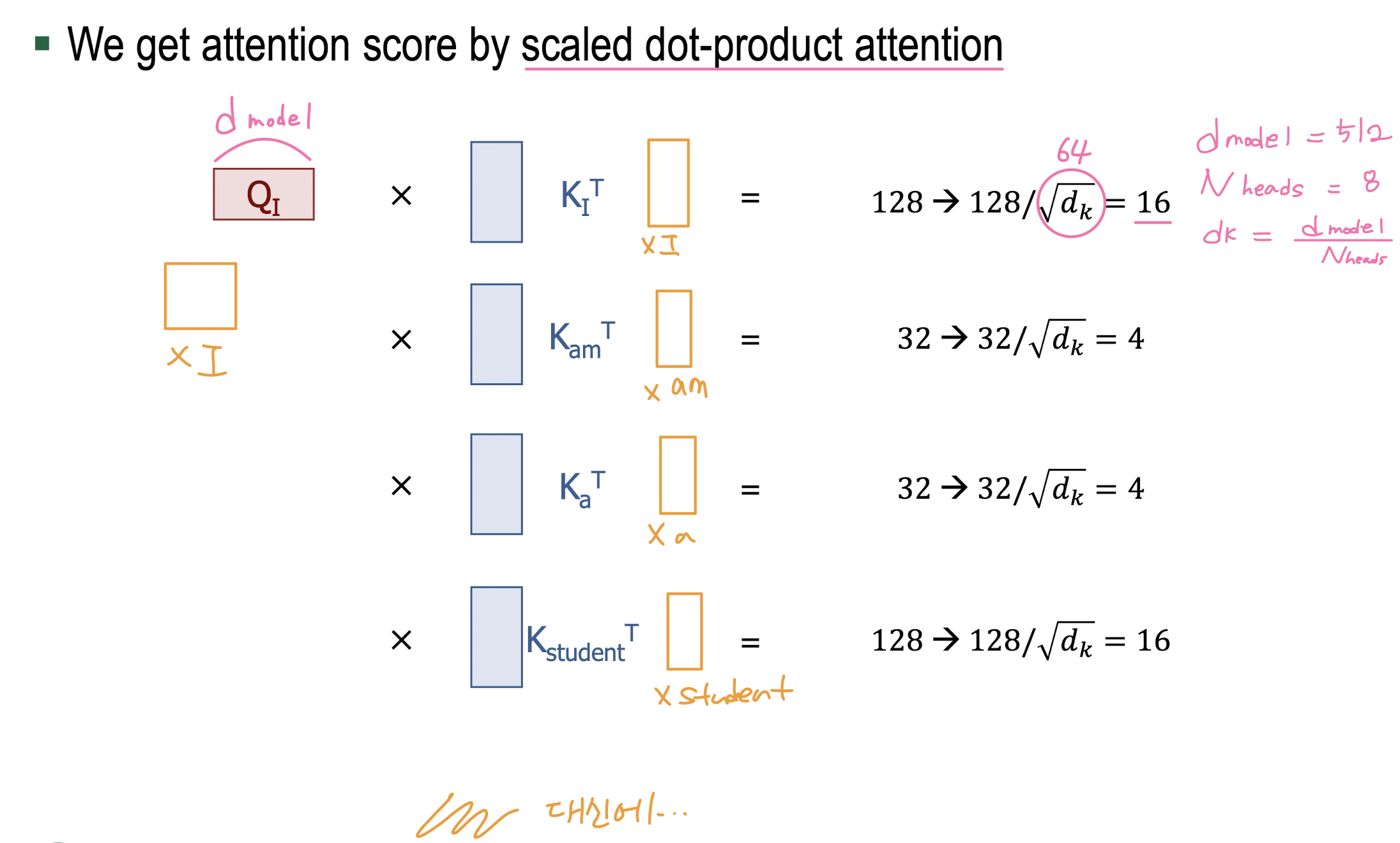
-
Attention Value

-
Doing It at Once with Matrix Operations
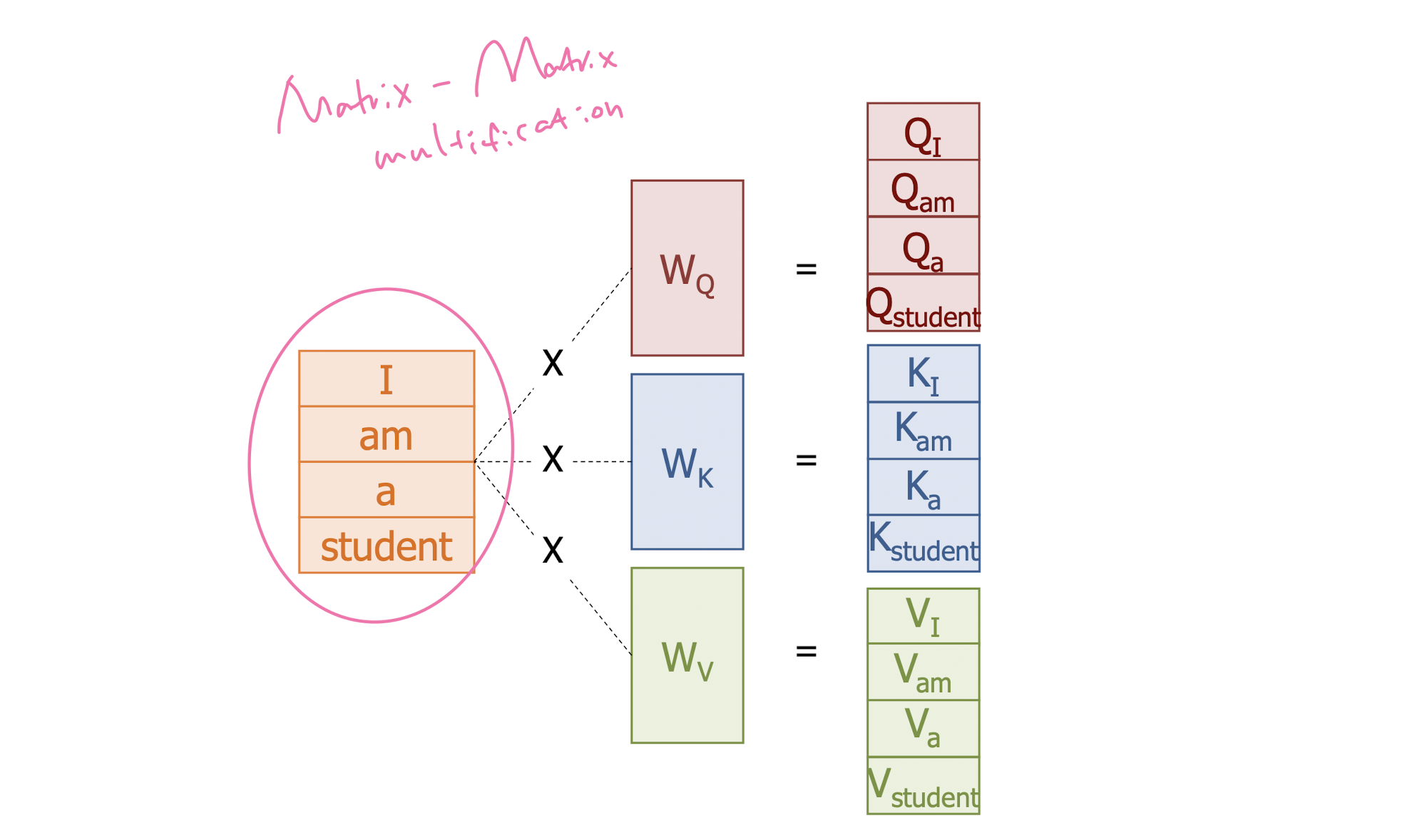
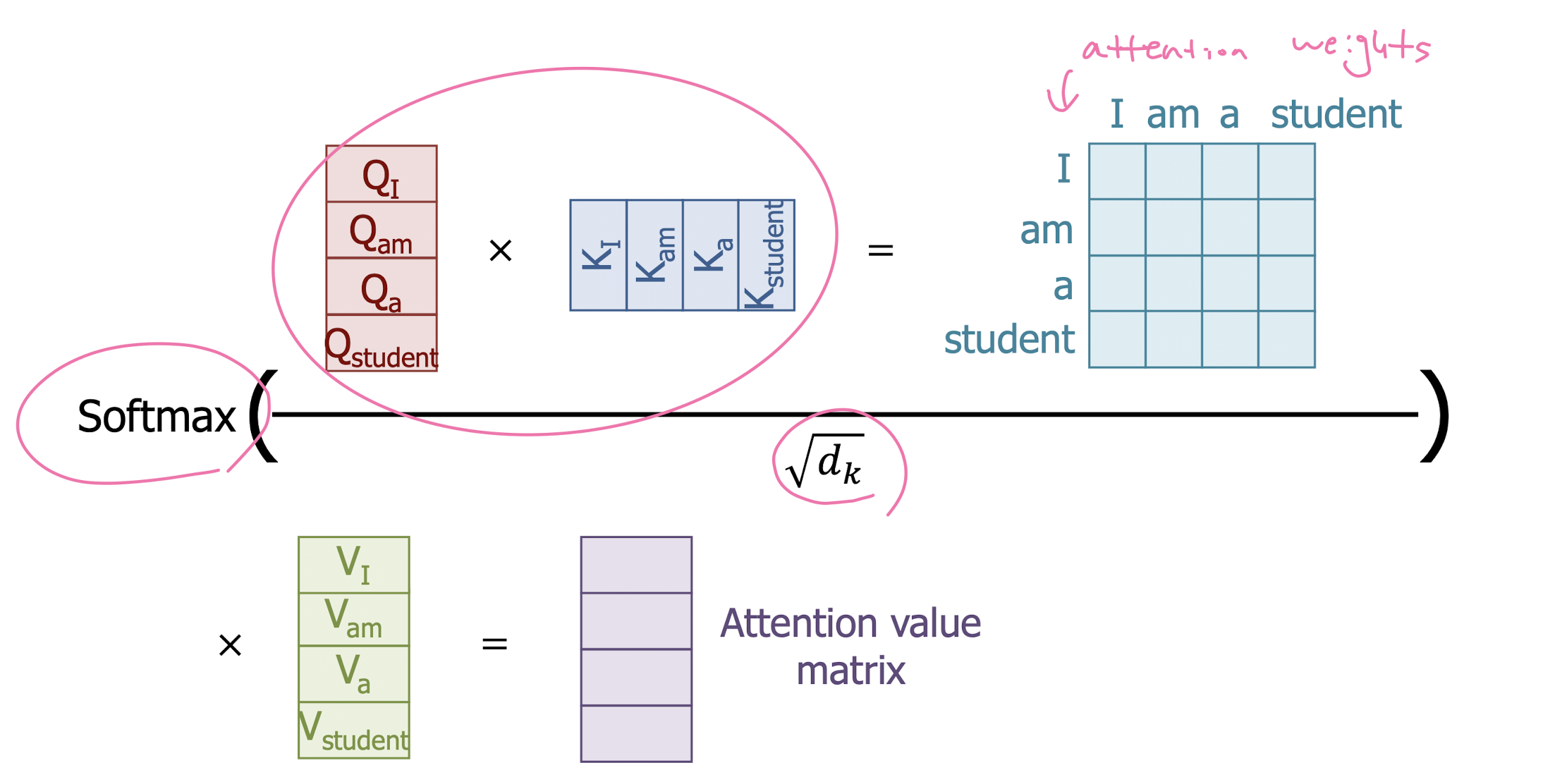
-
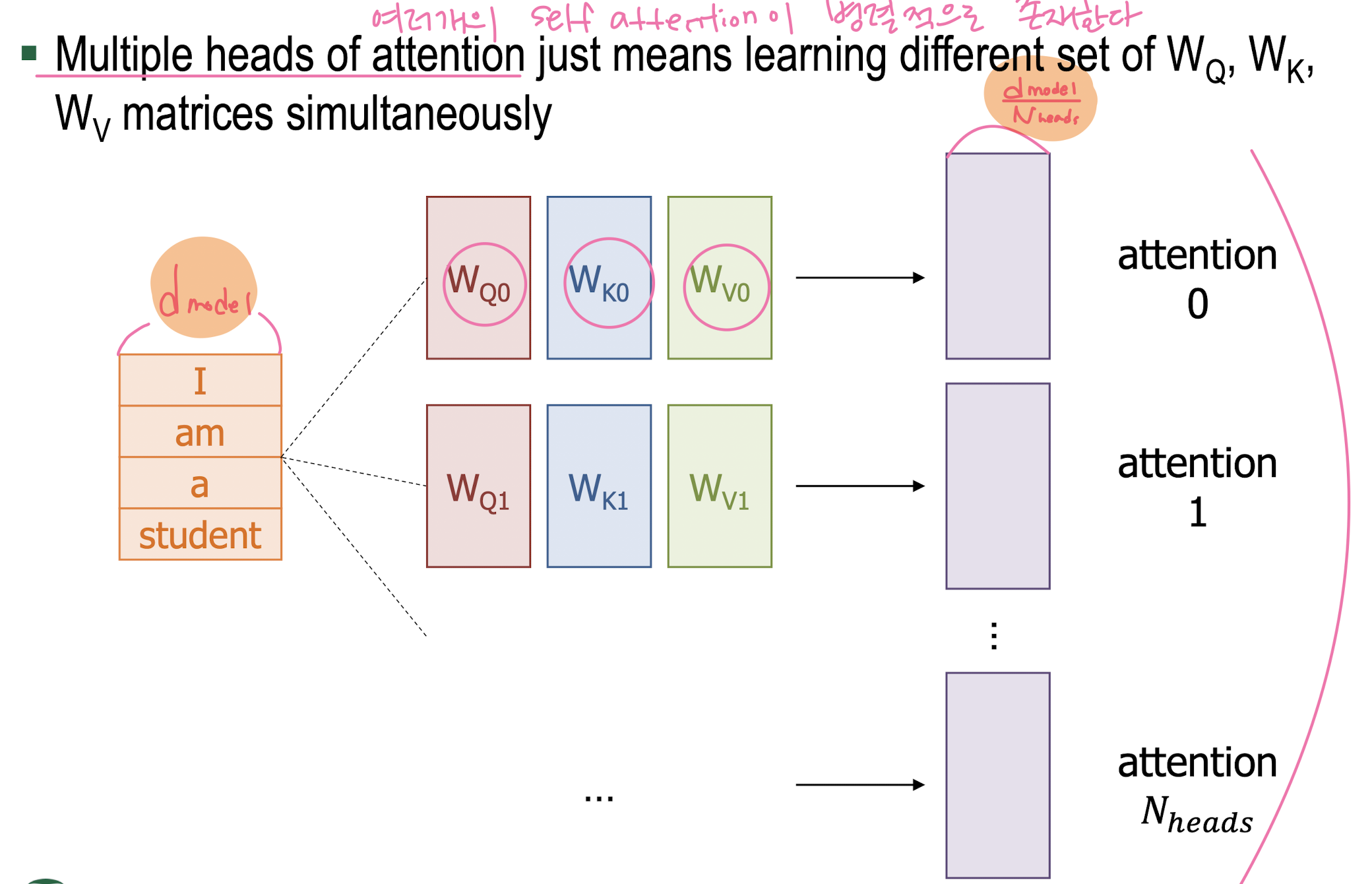
Multi-Head Attention
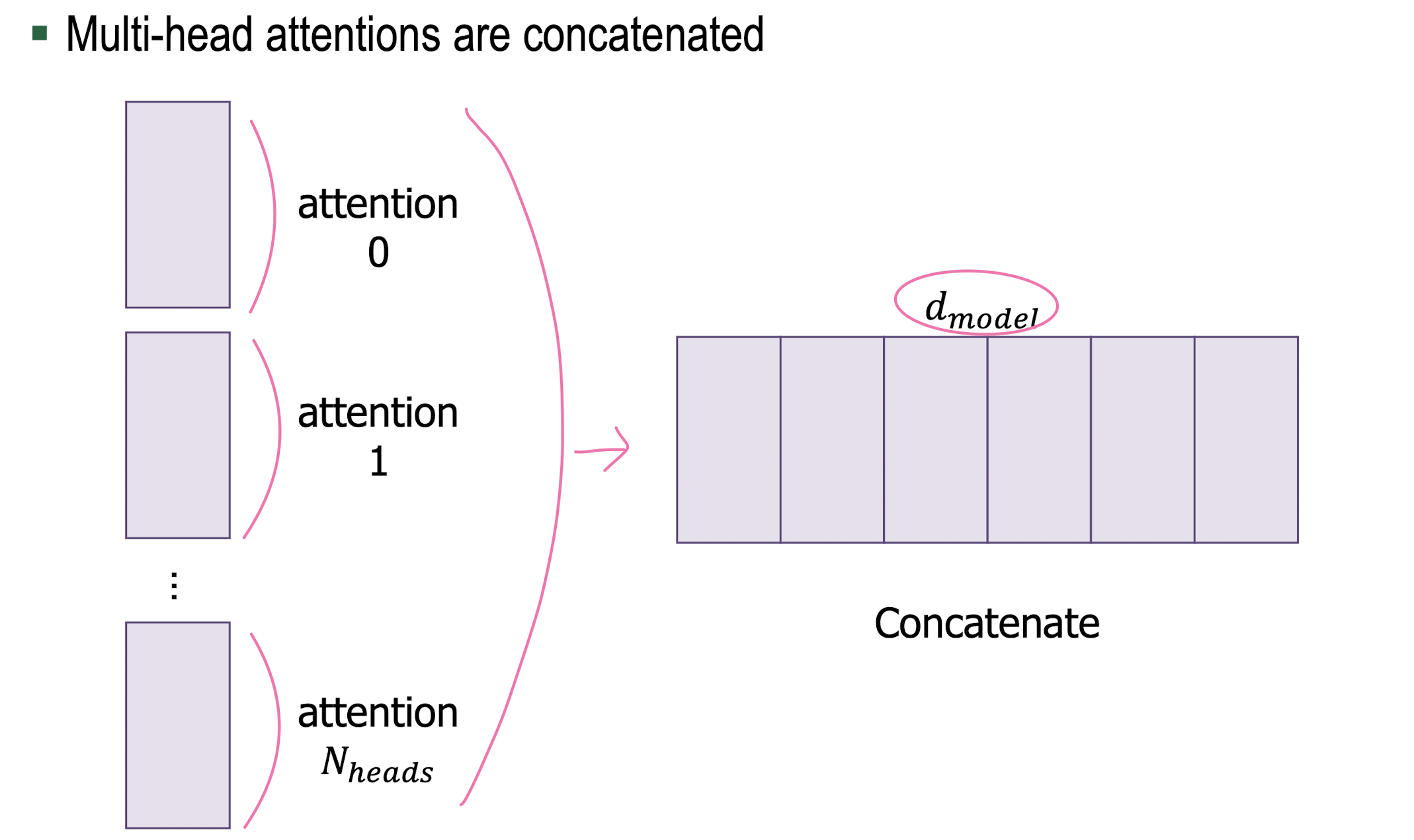
2. Positional Encoding
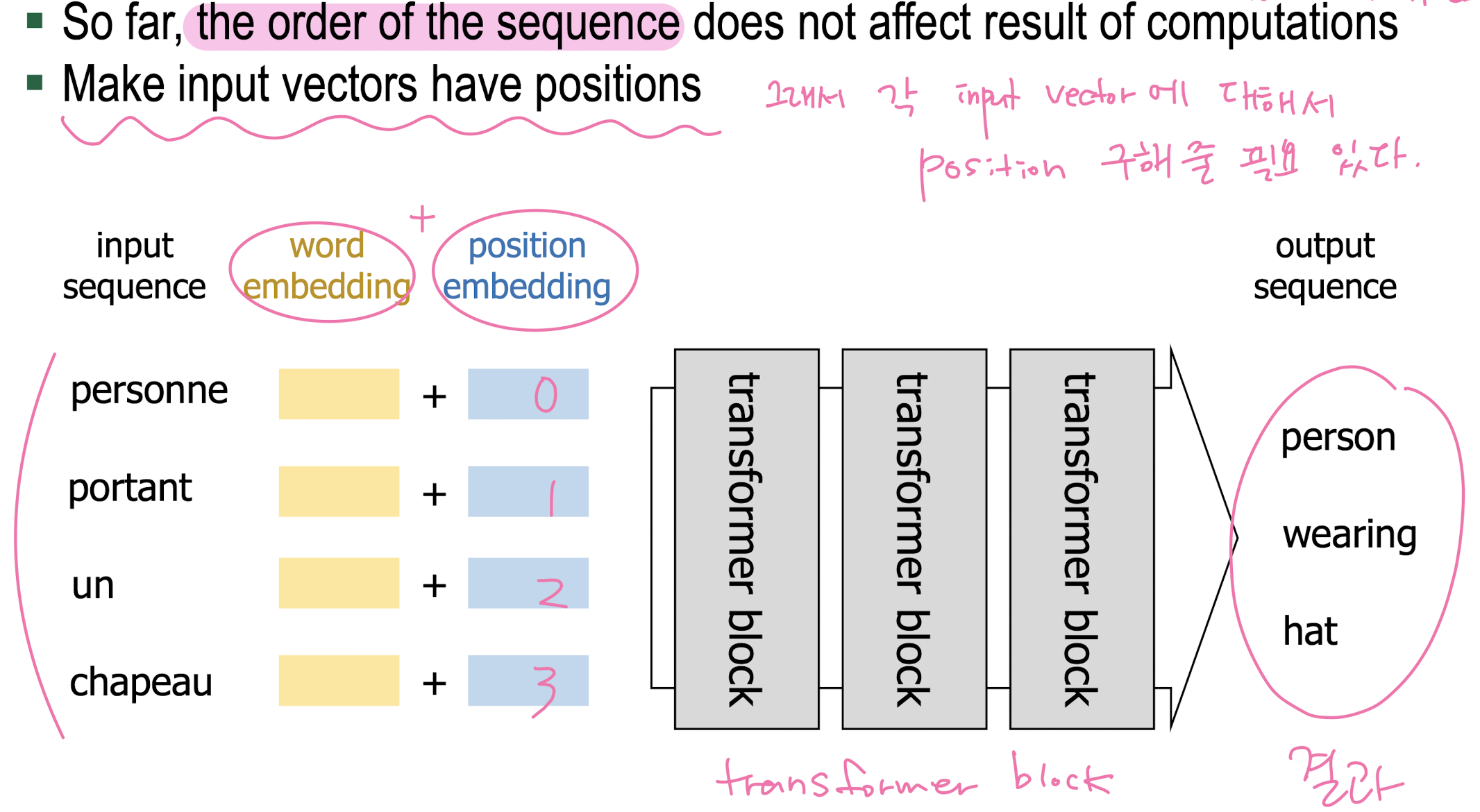
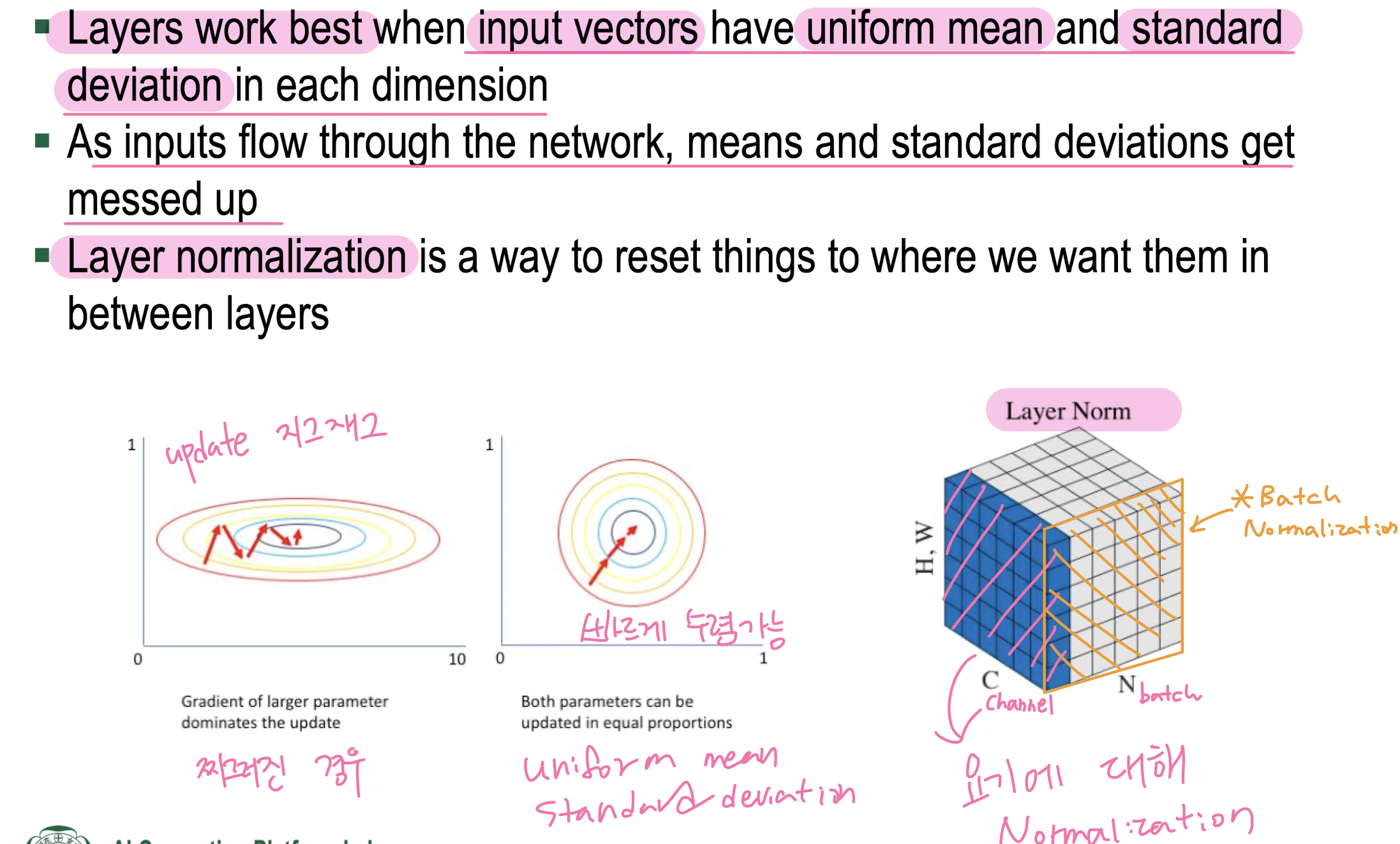
3. Layer Normalization
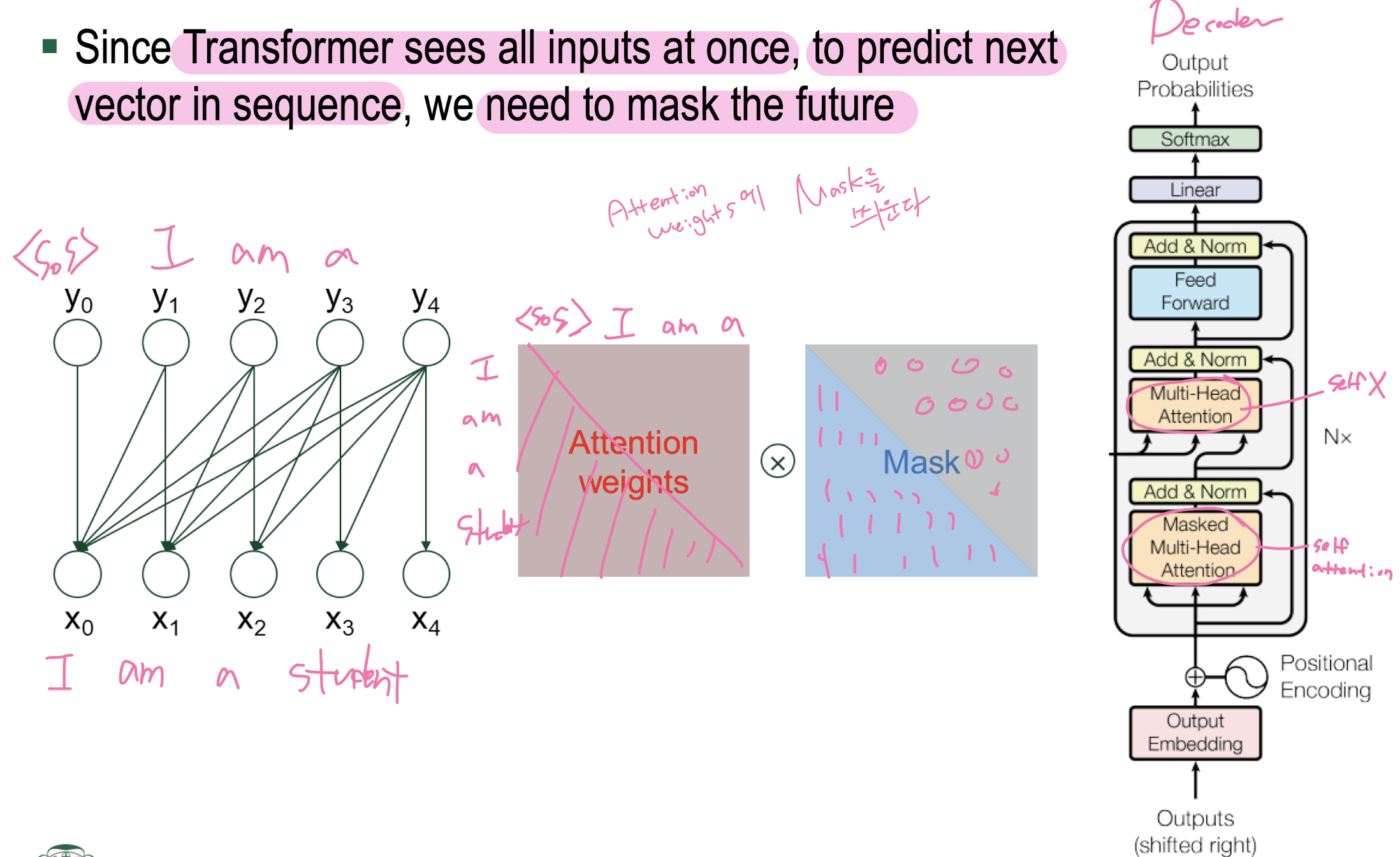
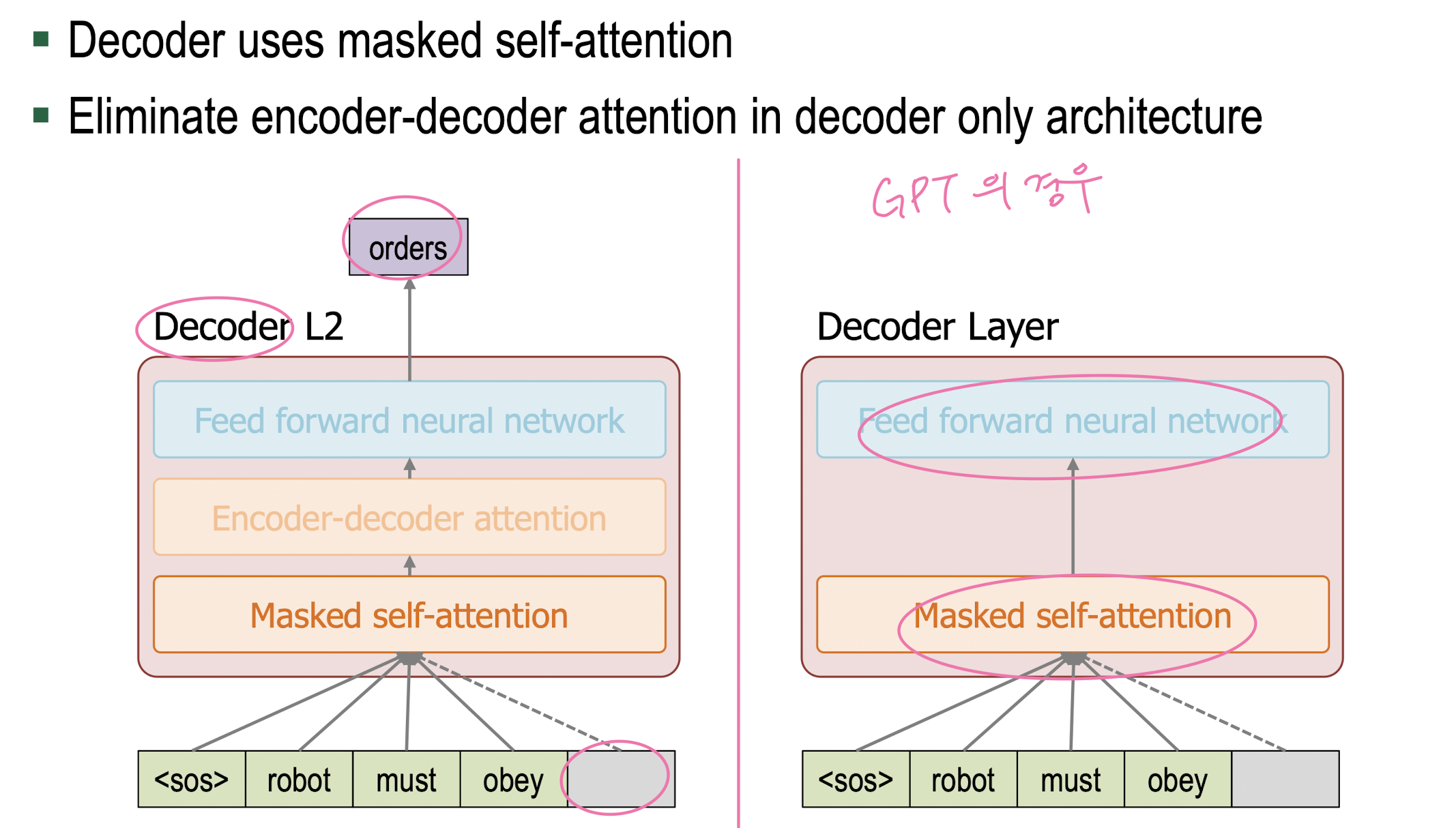
Masked Self Attention
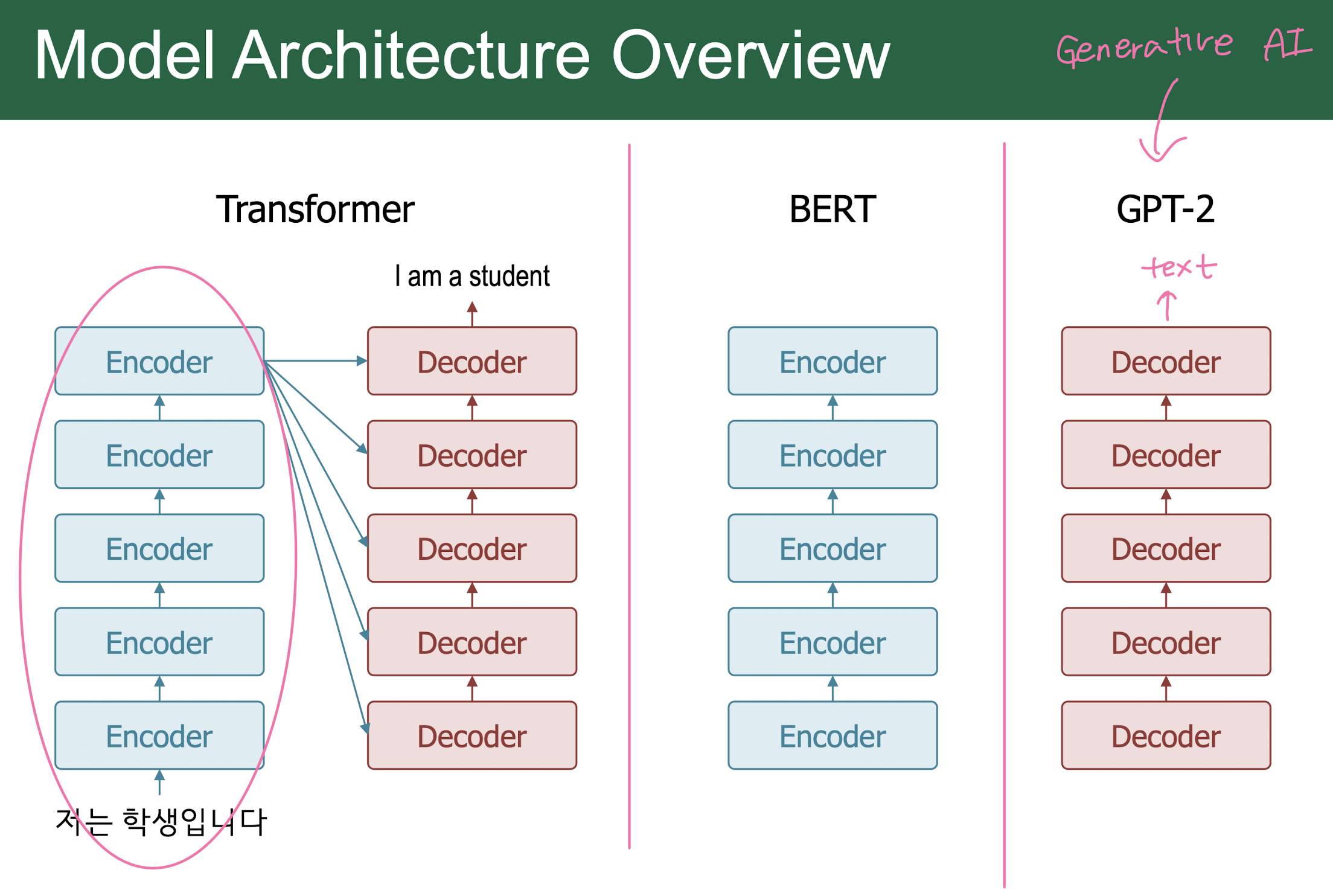
Transformer Model
Language Model(LM)

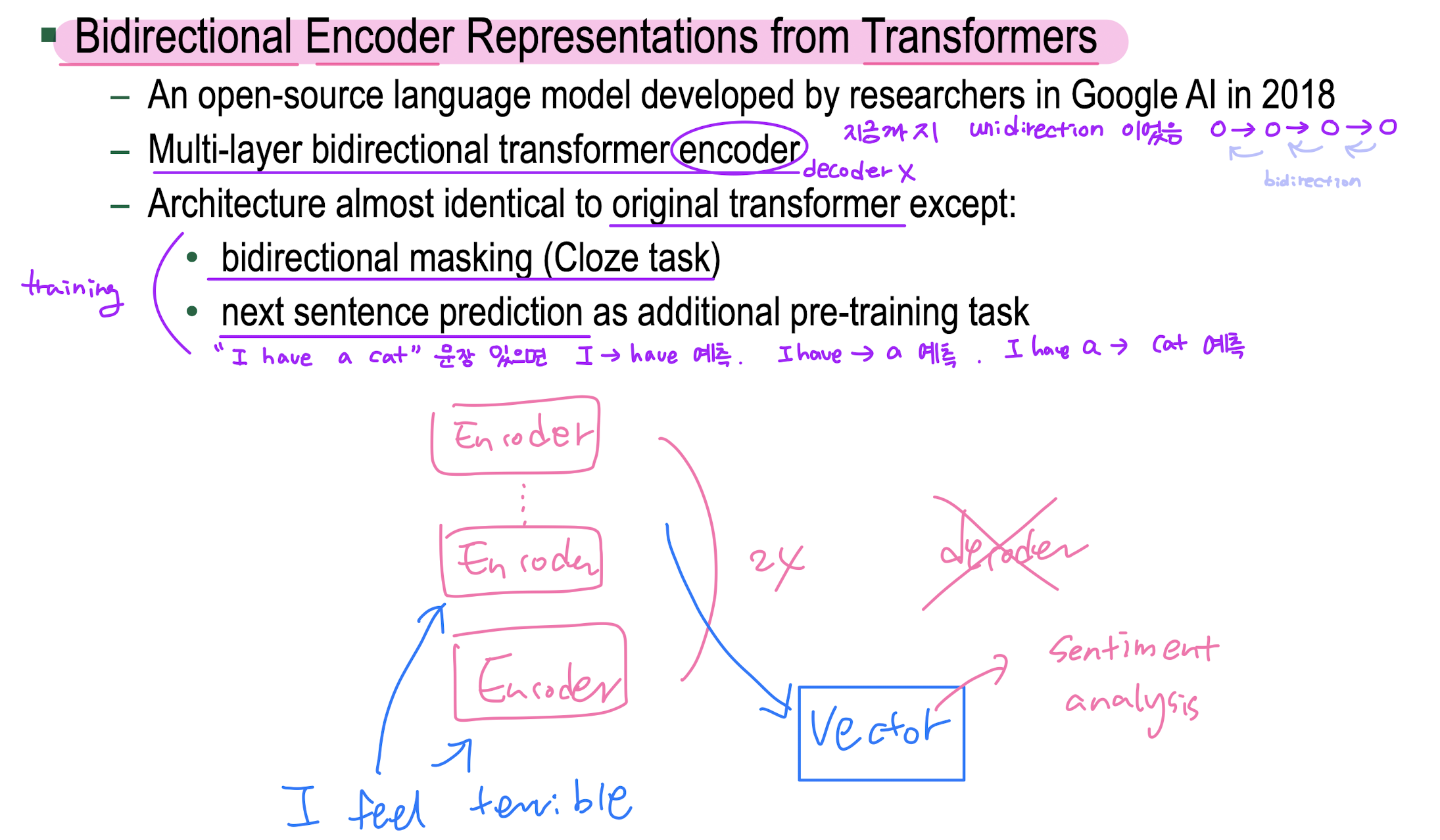
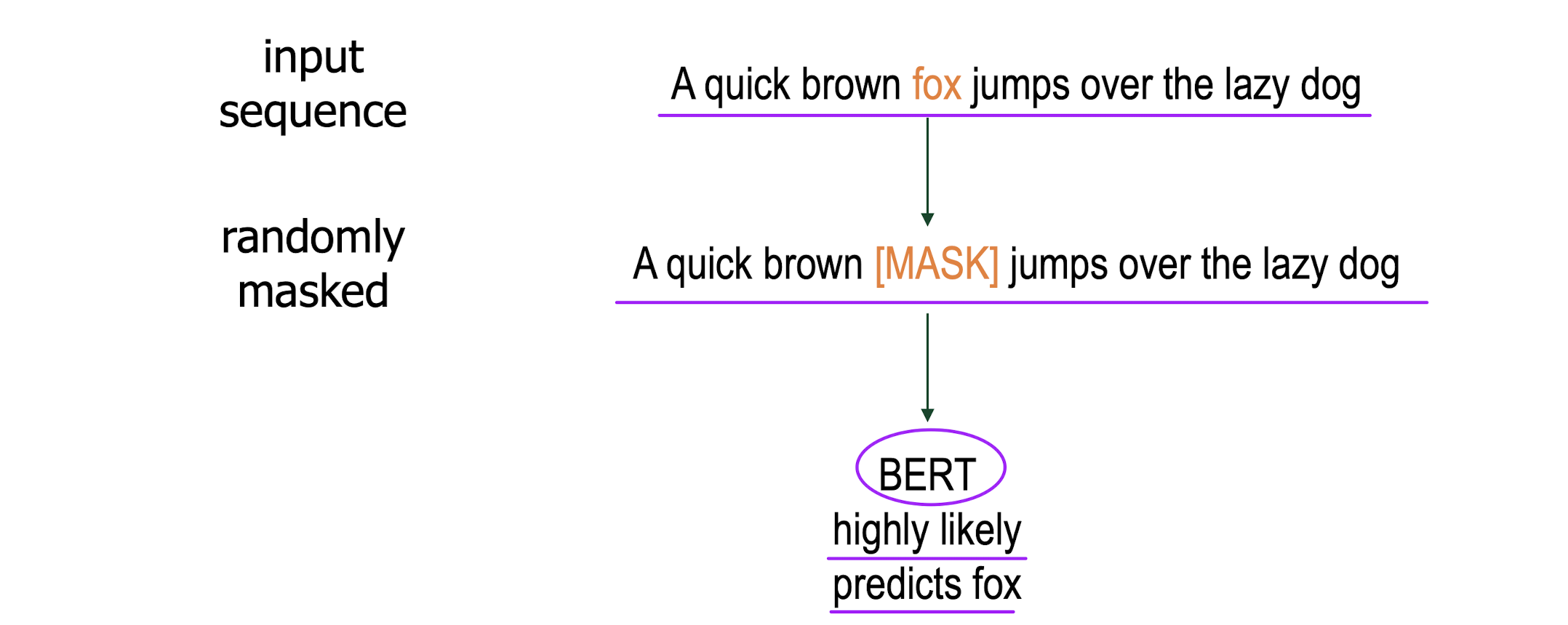
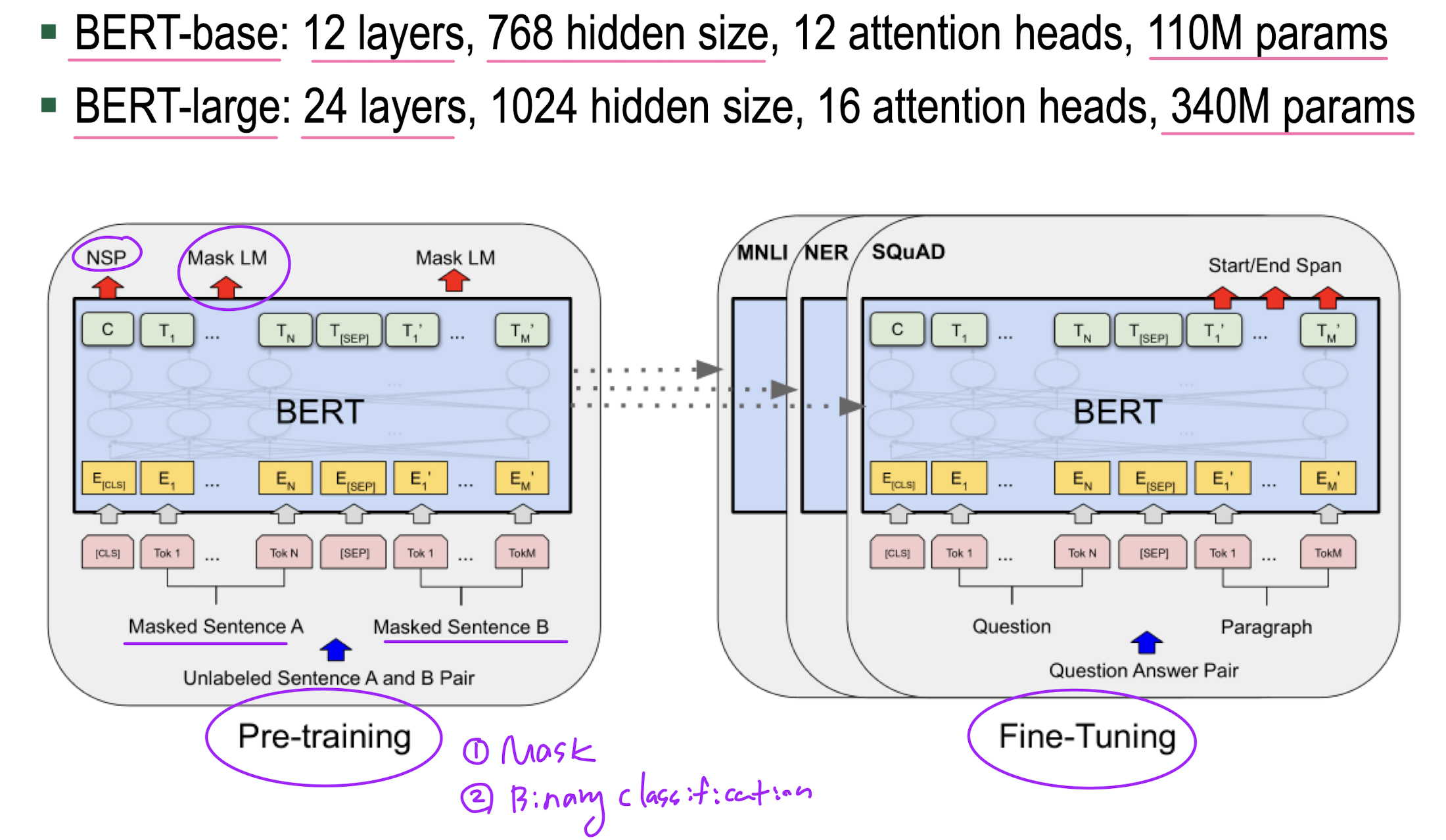
BERT

-
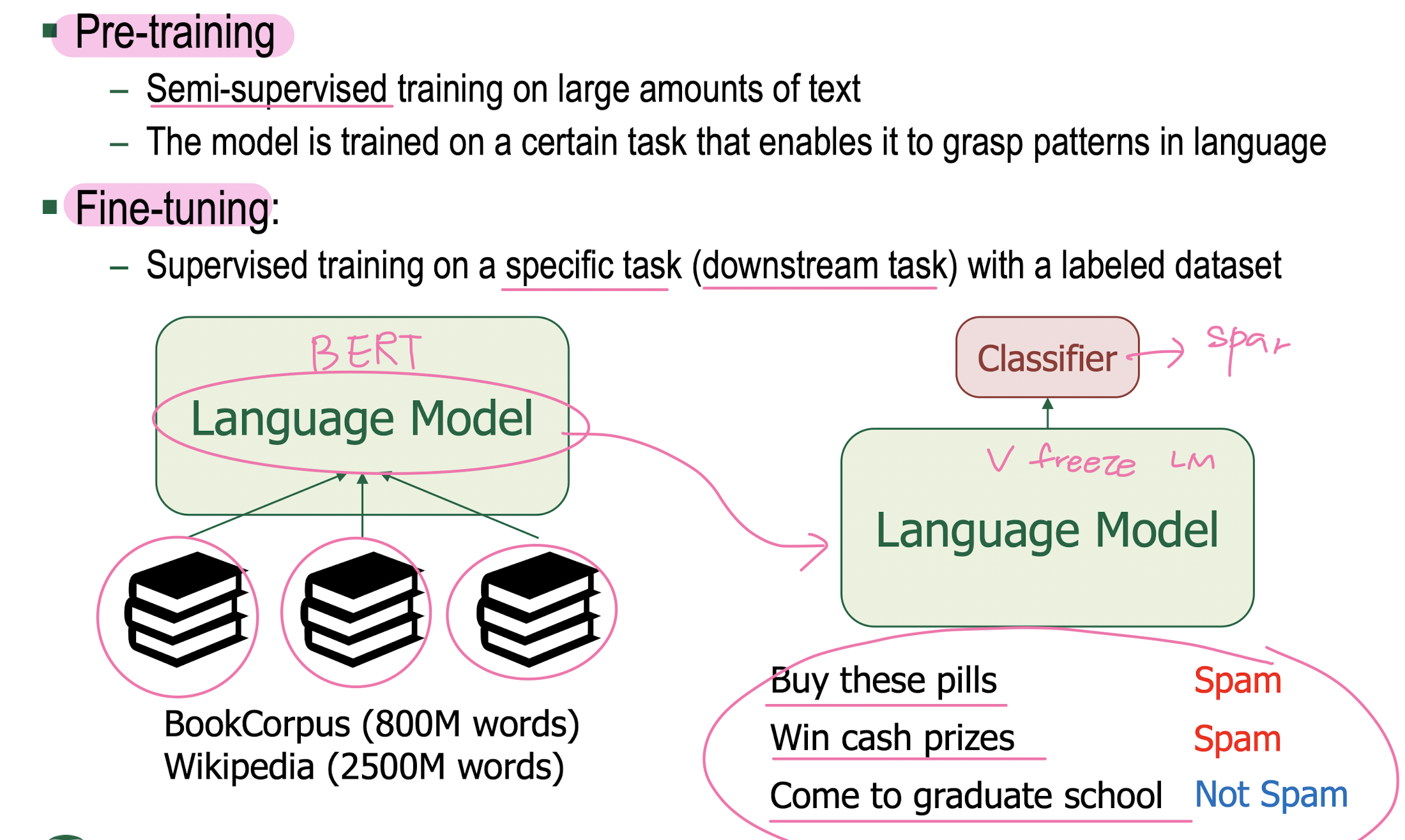
Pre-Training and Fine-Training
-
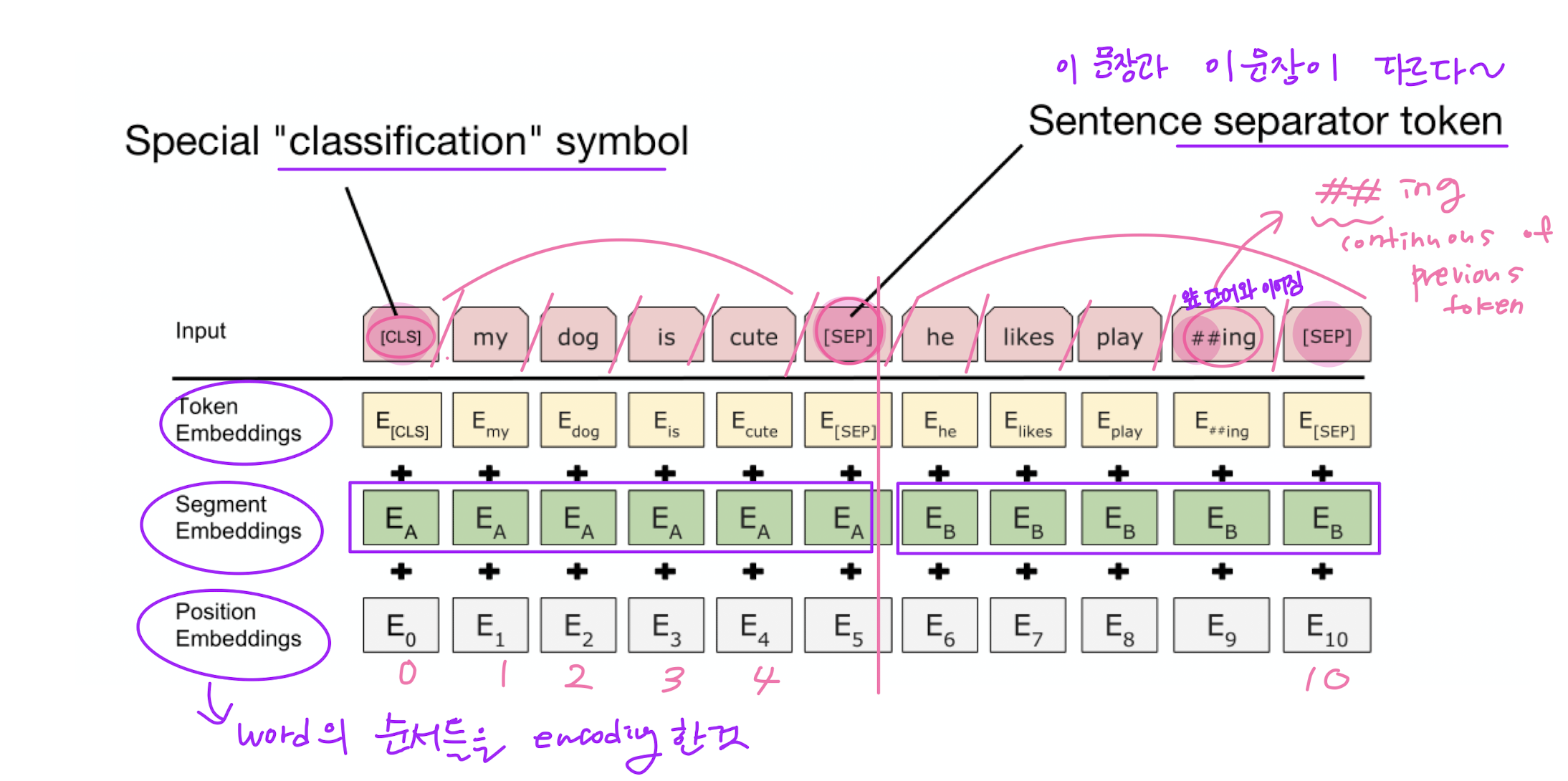
BERT input representaion
Pre-Training


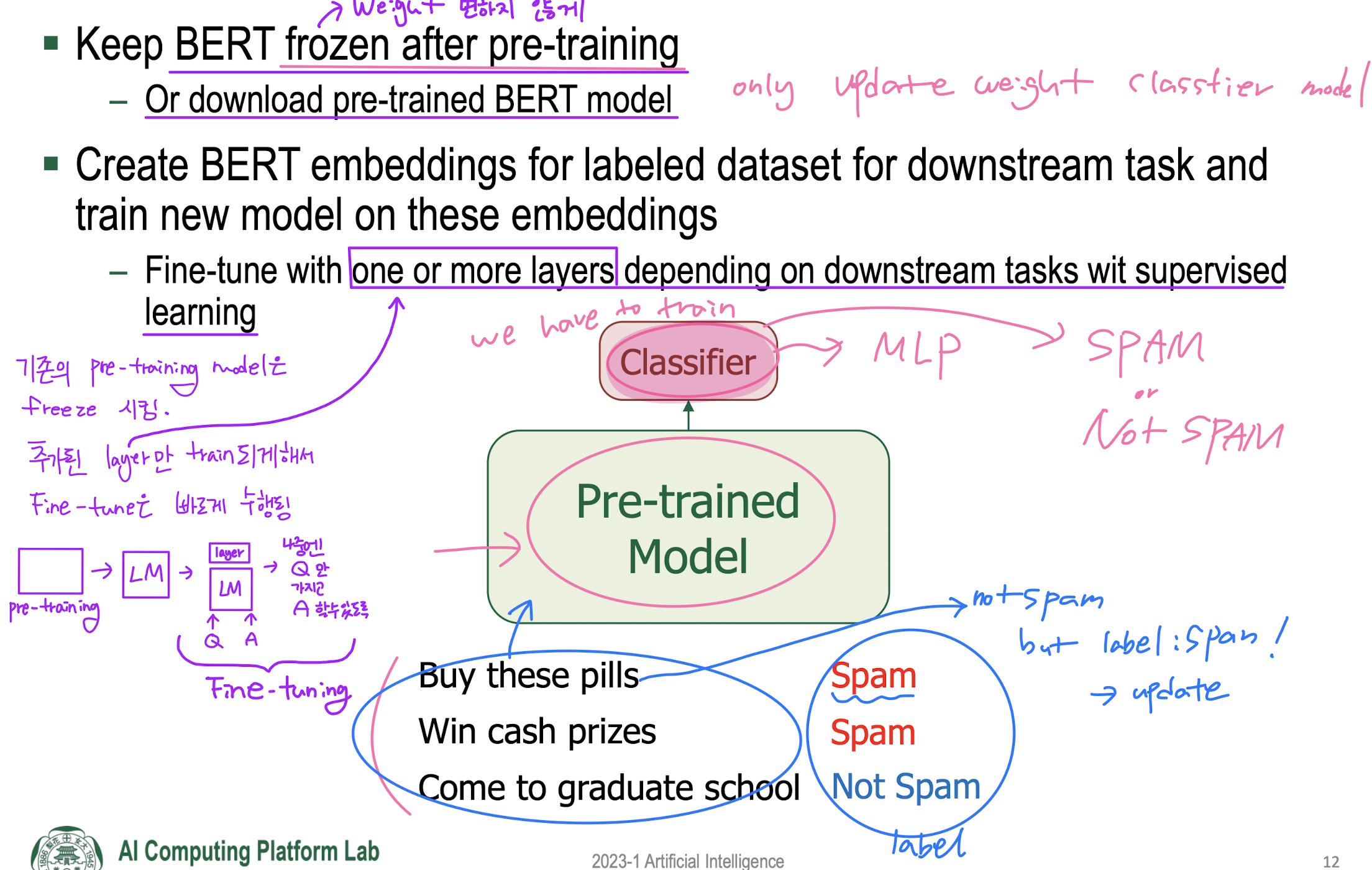
Fine-Training
BERT architecture
What Can/Cannot BERT Do

- Limitations of Pre-Training → Fine-Tuning

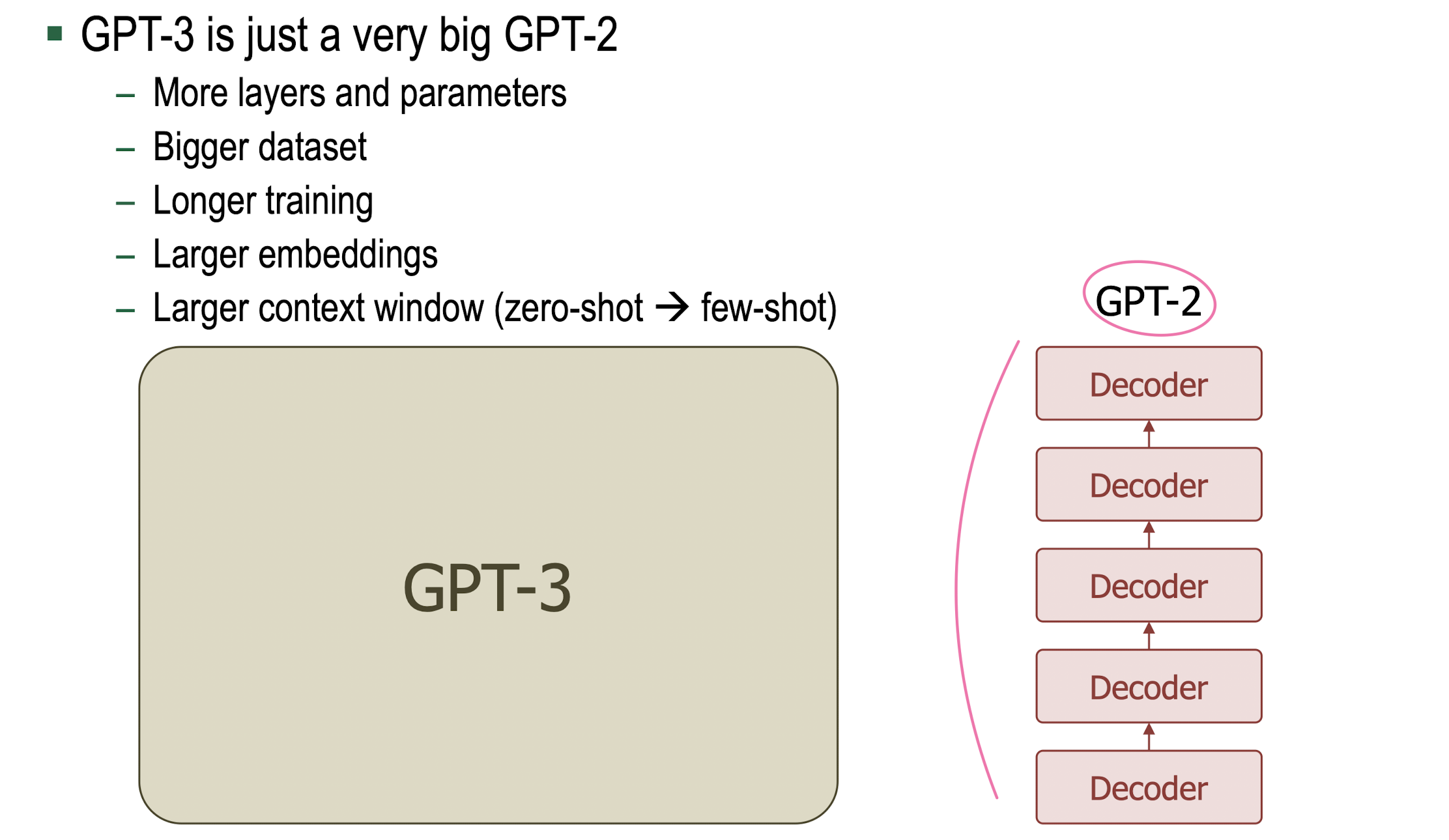
GPT
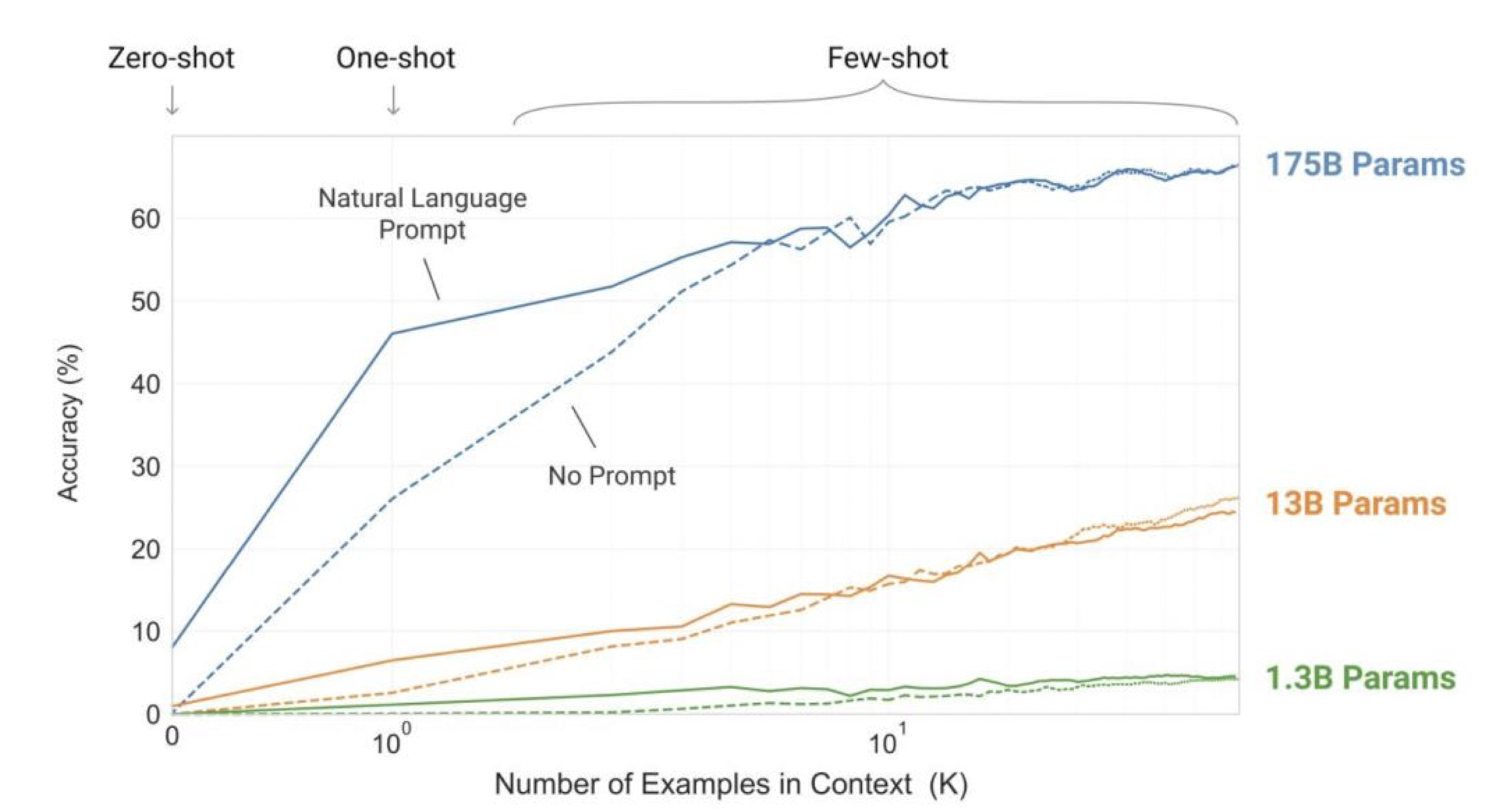
- LM Landscape with GPT-3
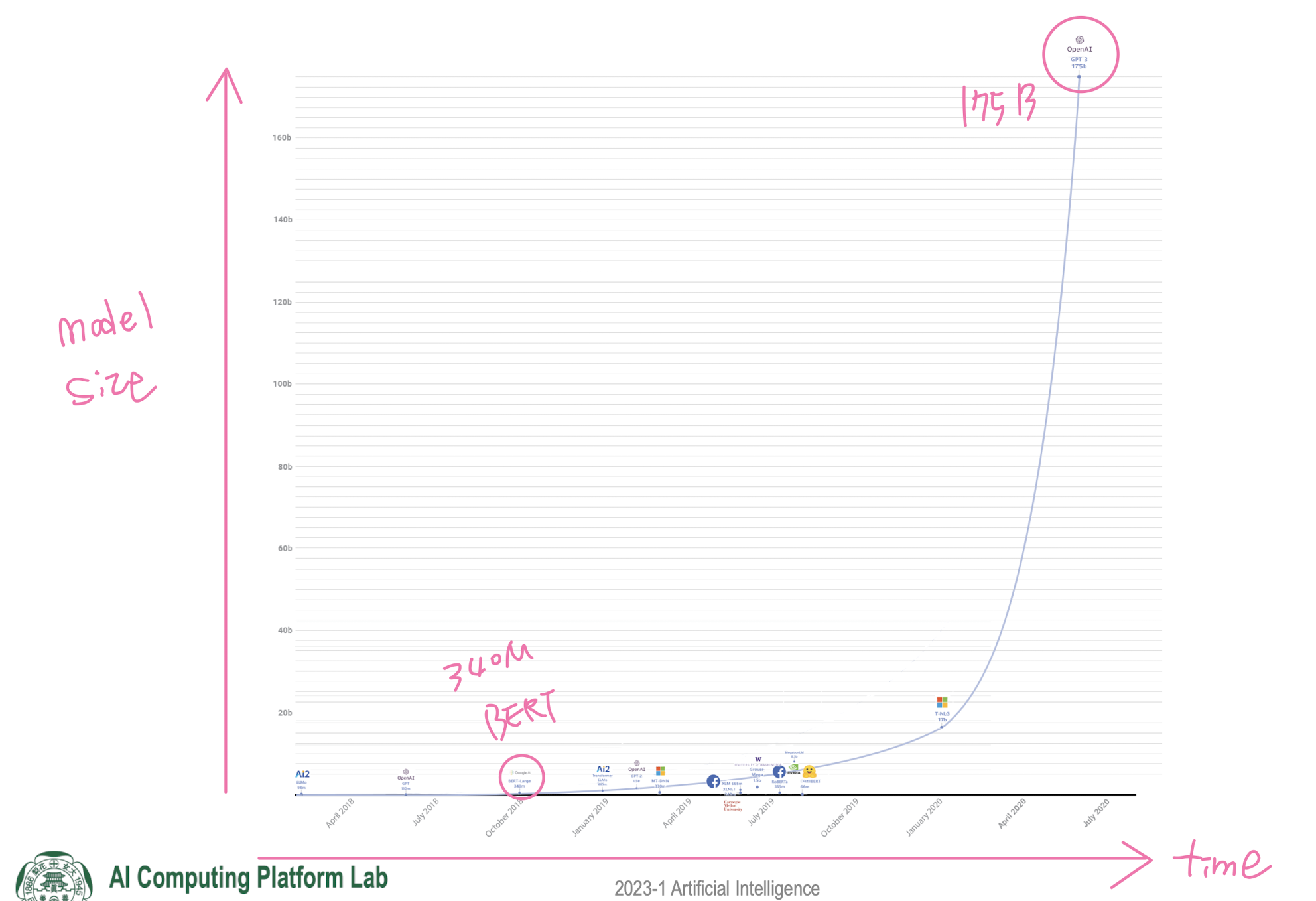
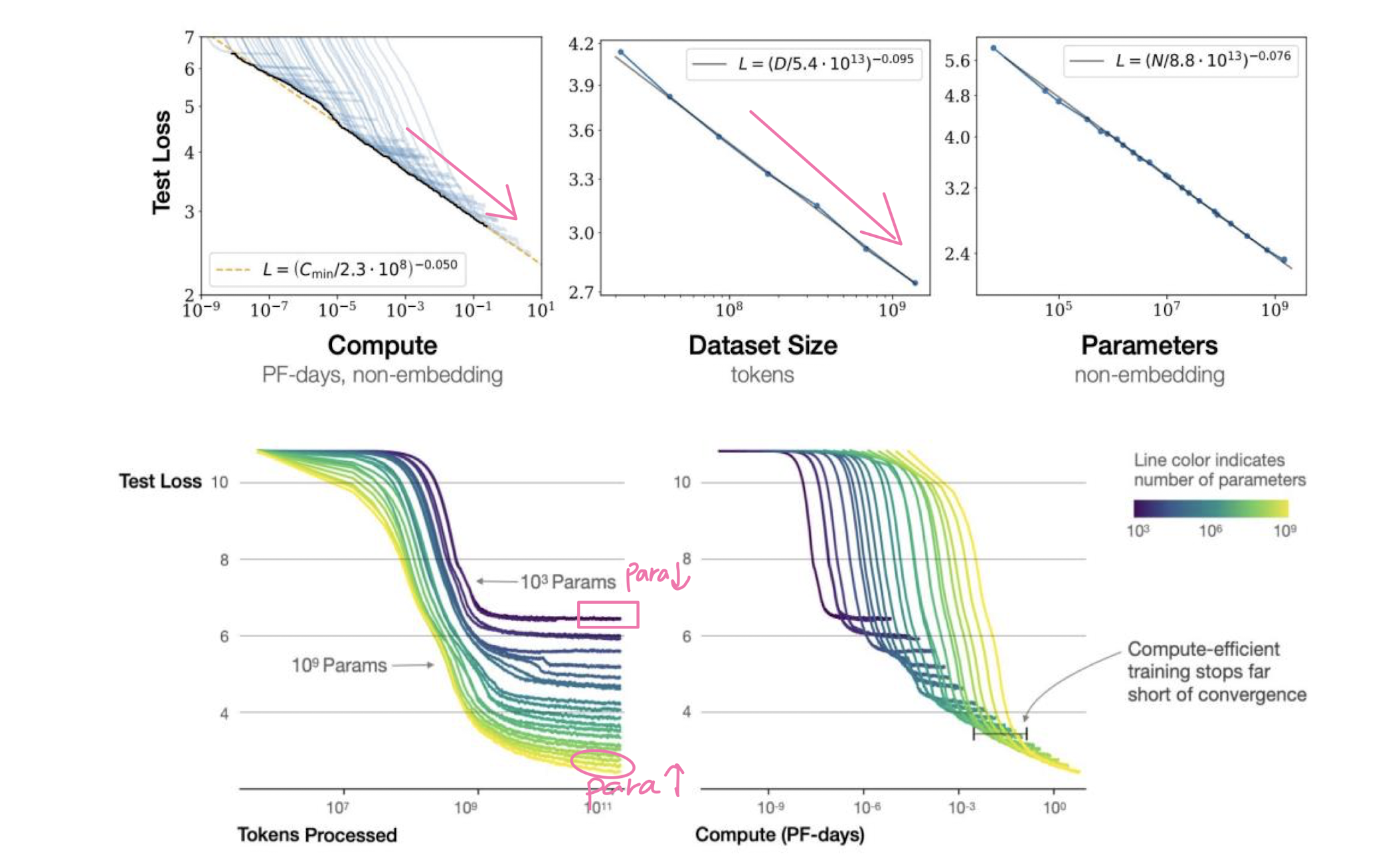
- Why Scale? Bigger is better!

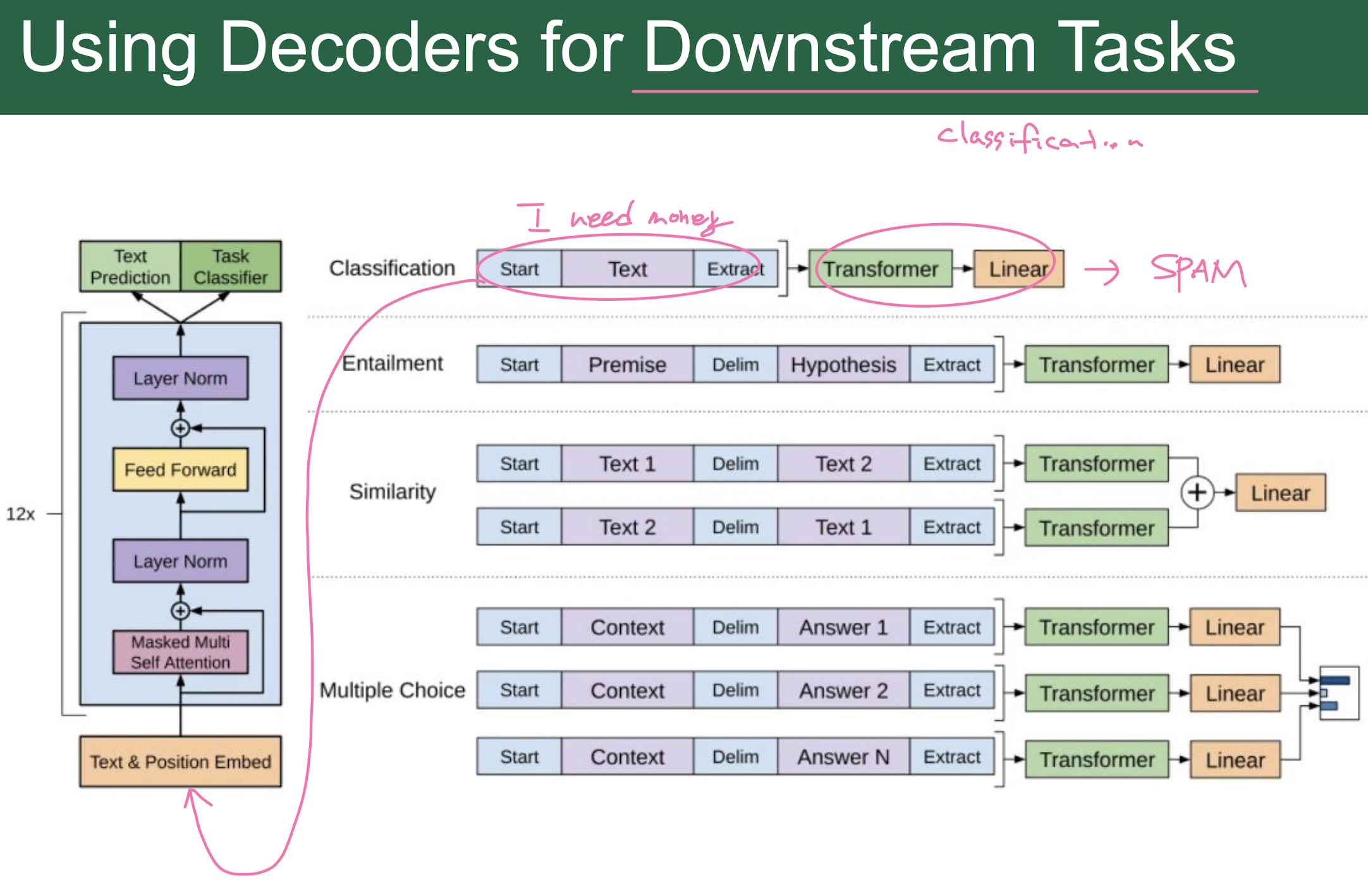
Decoder Only Architecture
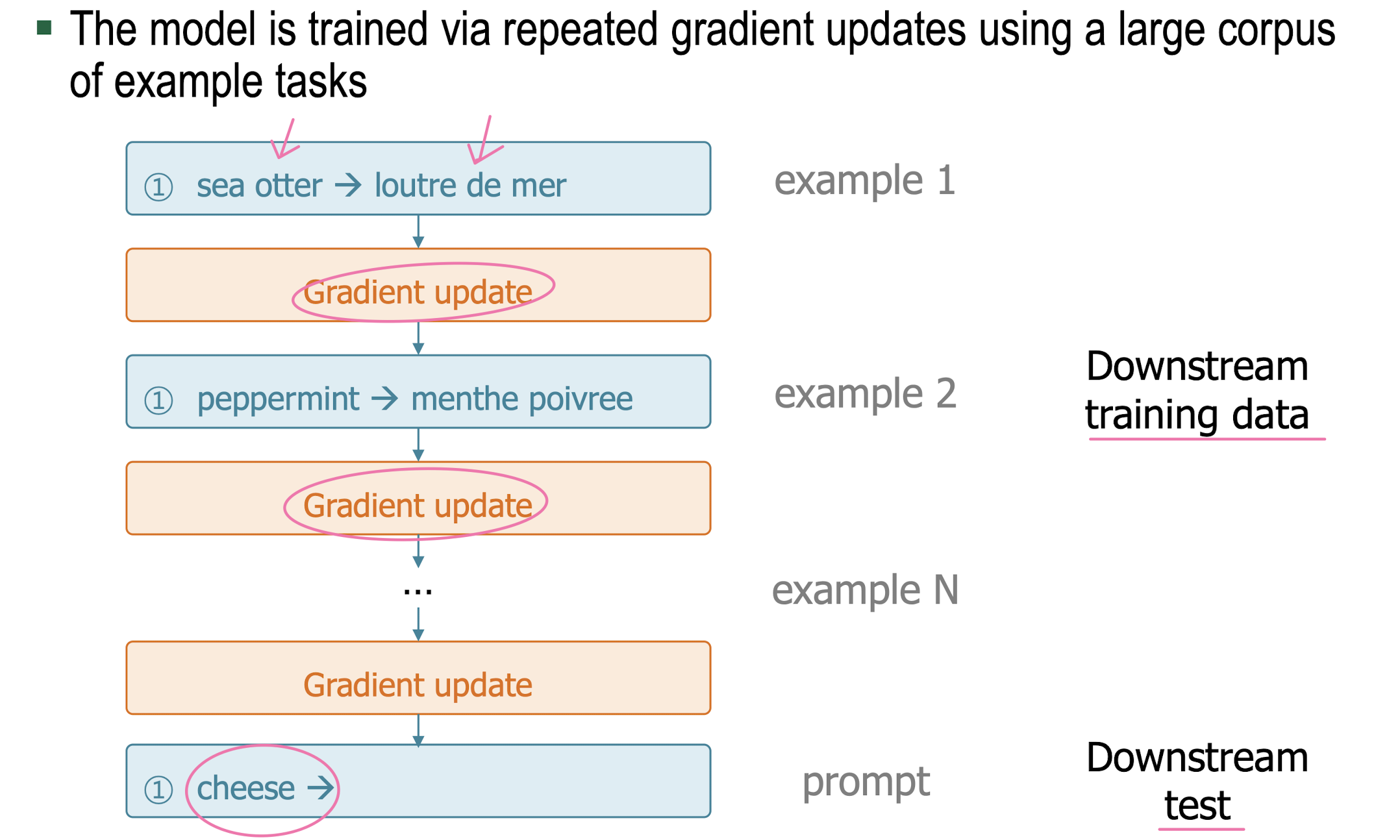
Traditional Fine-Tuning
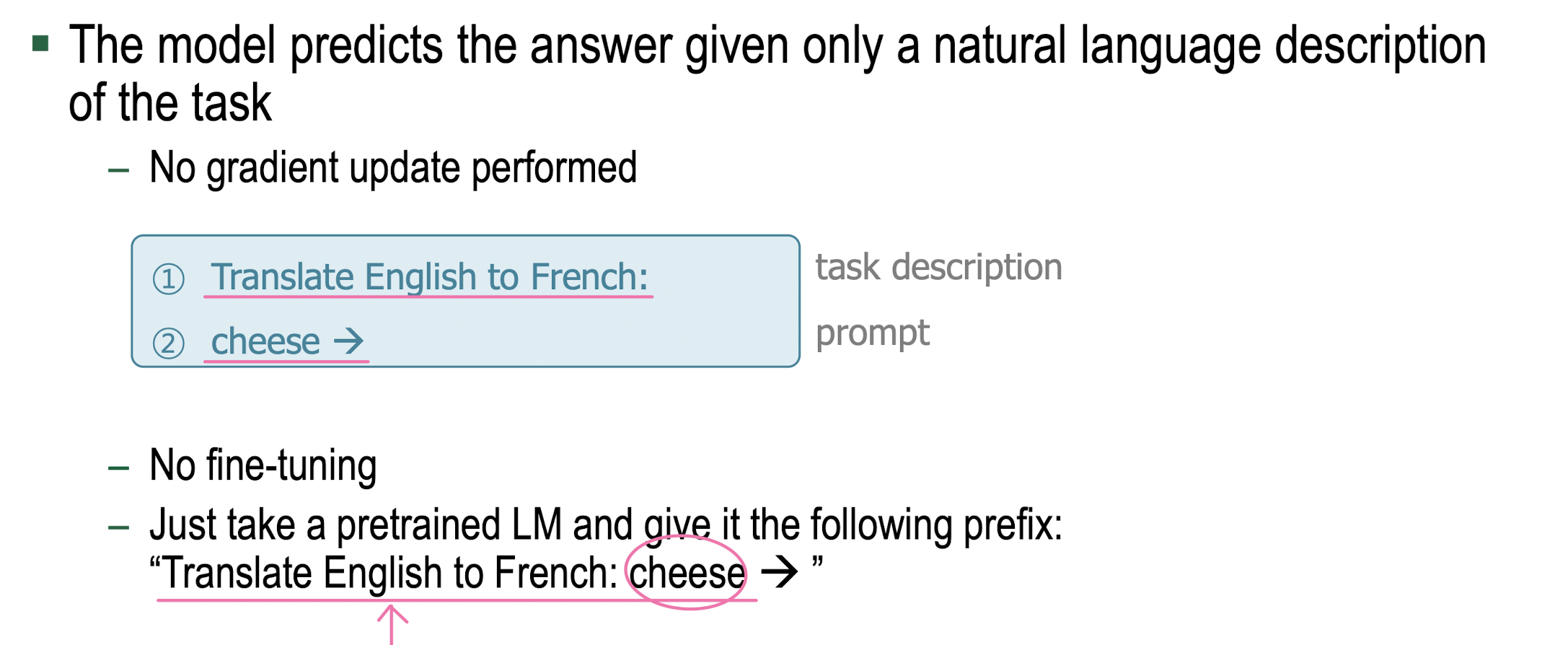
Zero-Shot
One-Shot

Few-Shot

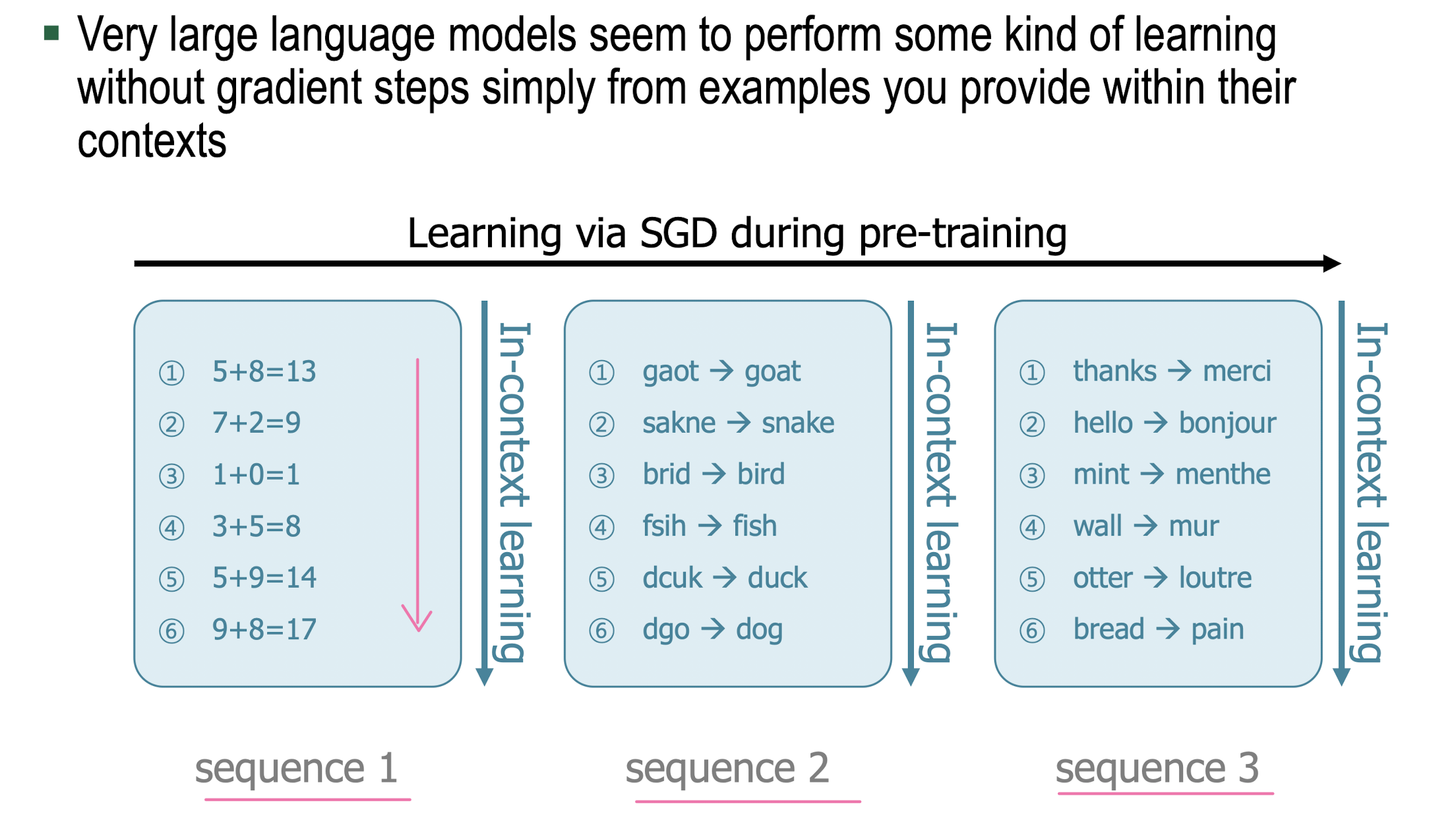
In-Context Learning
- Larger Model Learns Better In-Context
GPT-3


14. NLP pipeline
NLP pipeline
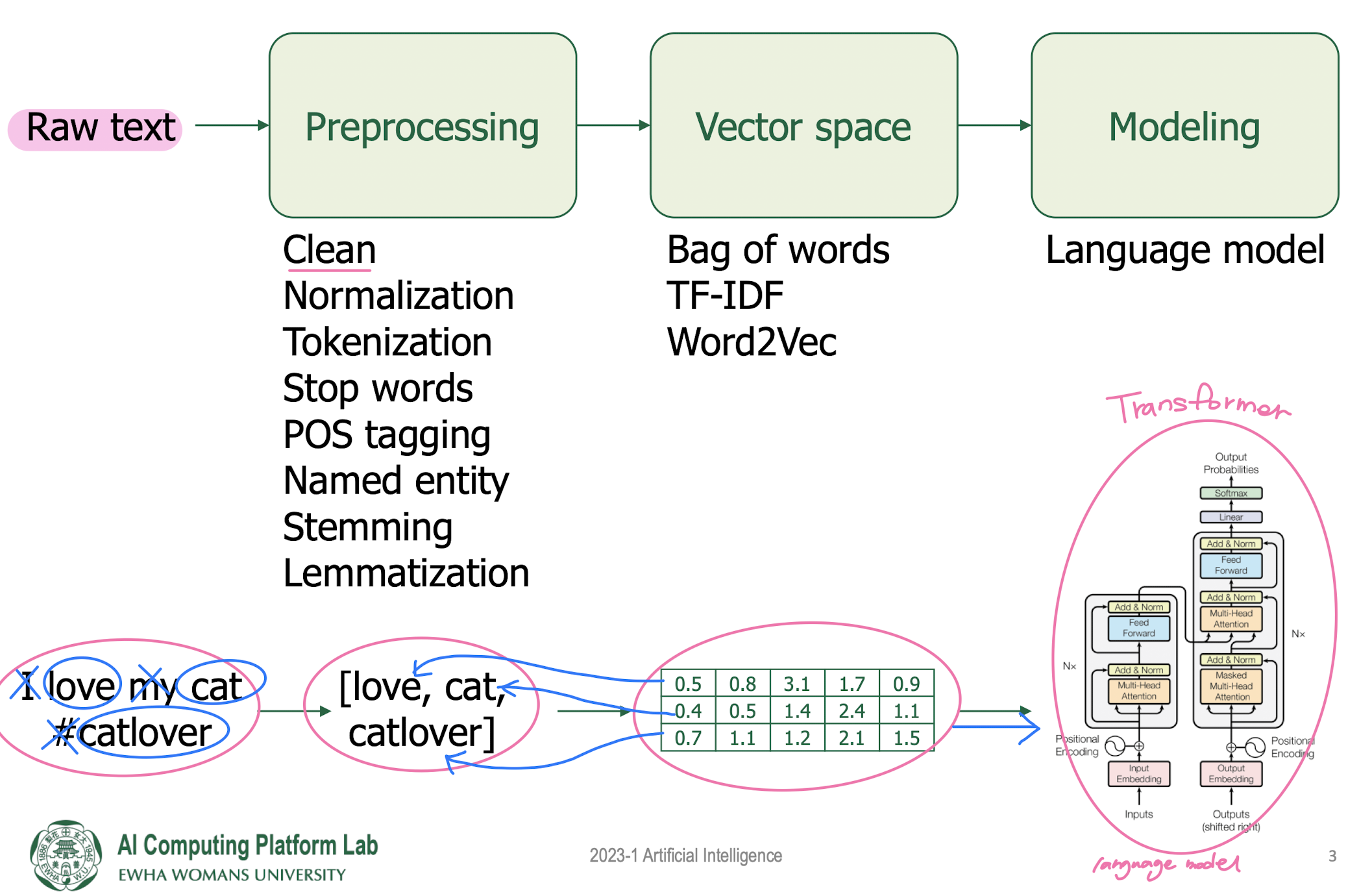
Preprocessing
clean

Normalization

Tokenization

Stop Words Removal

POS Tagging

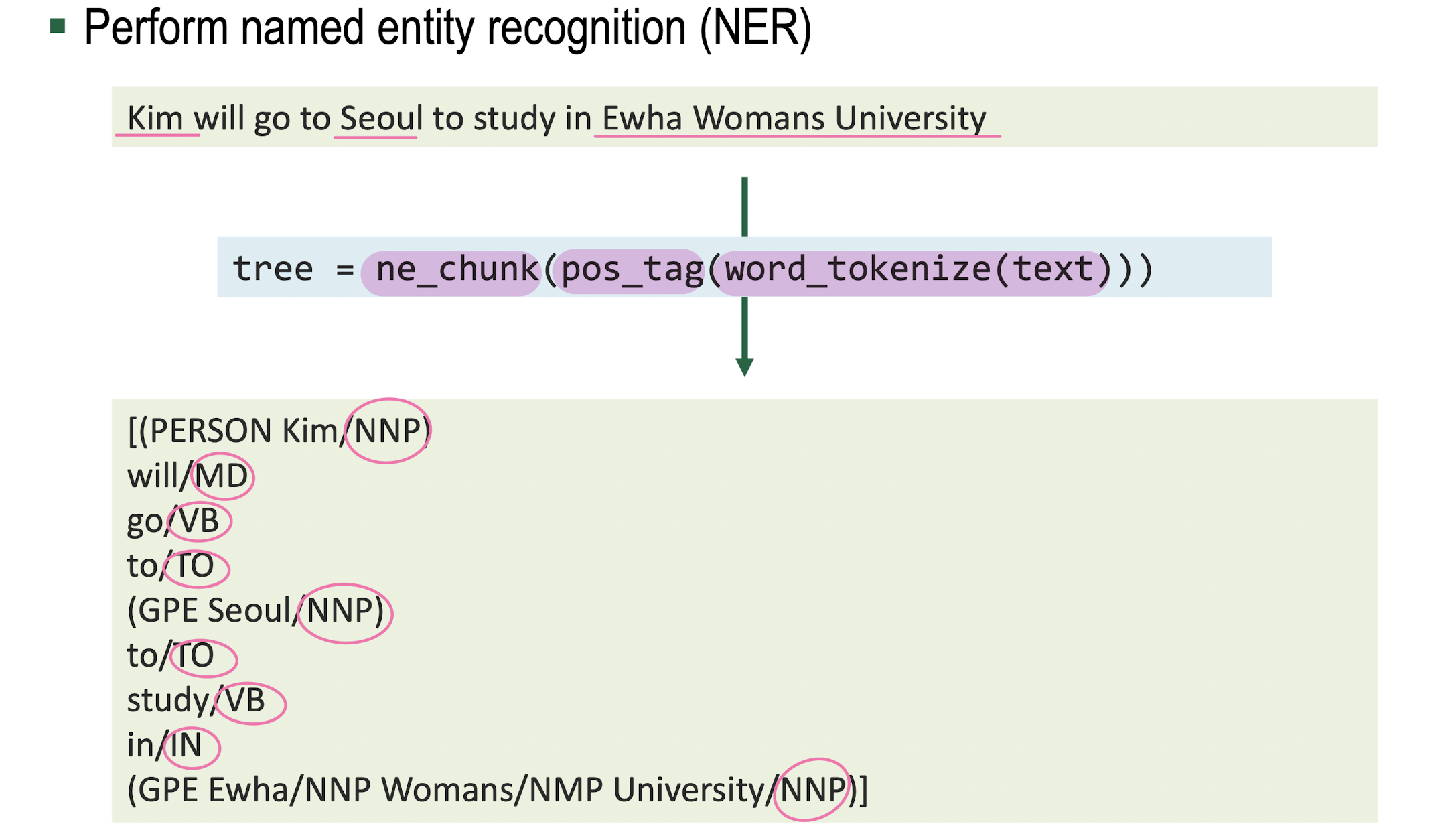
Named Entity
Stemming

Lemmatization

Vector space
Representing Words
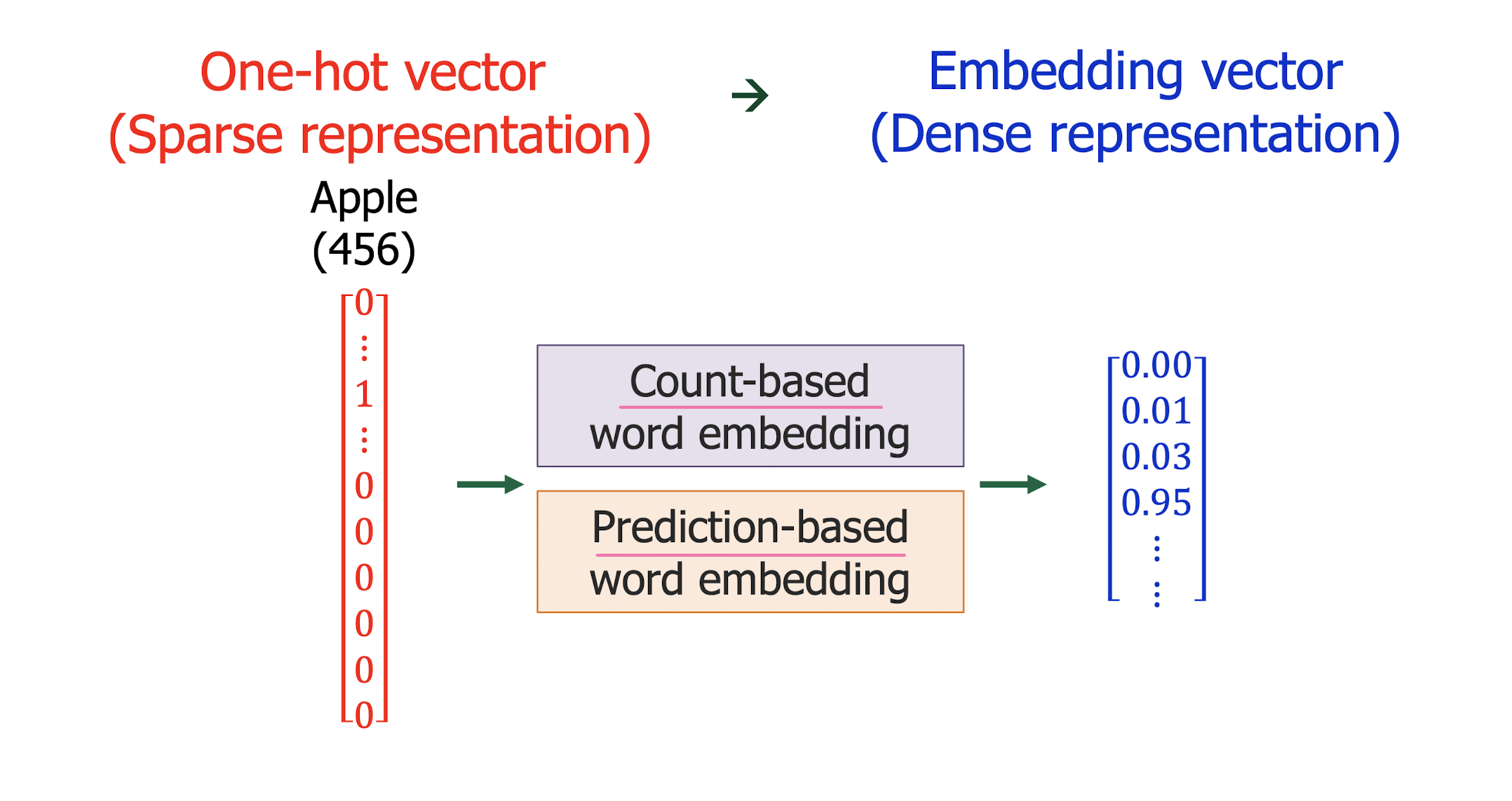
Count-based word embedding: BOW, TF-IDF
-
BOW

-
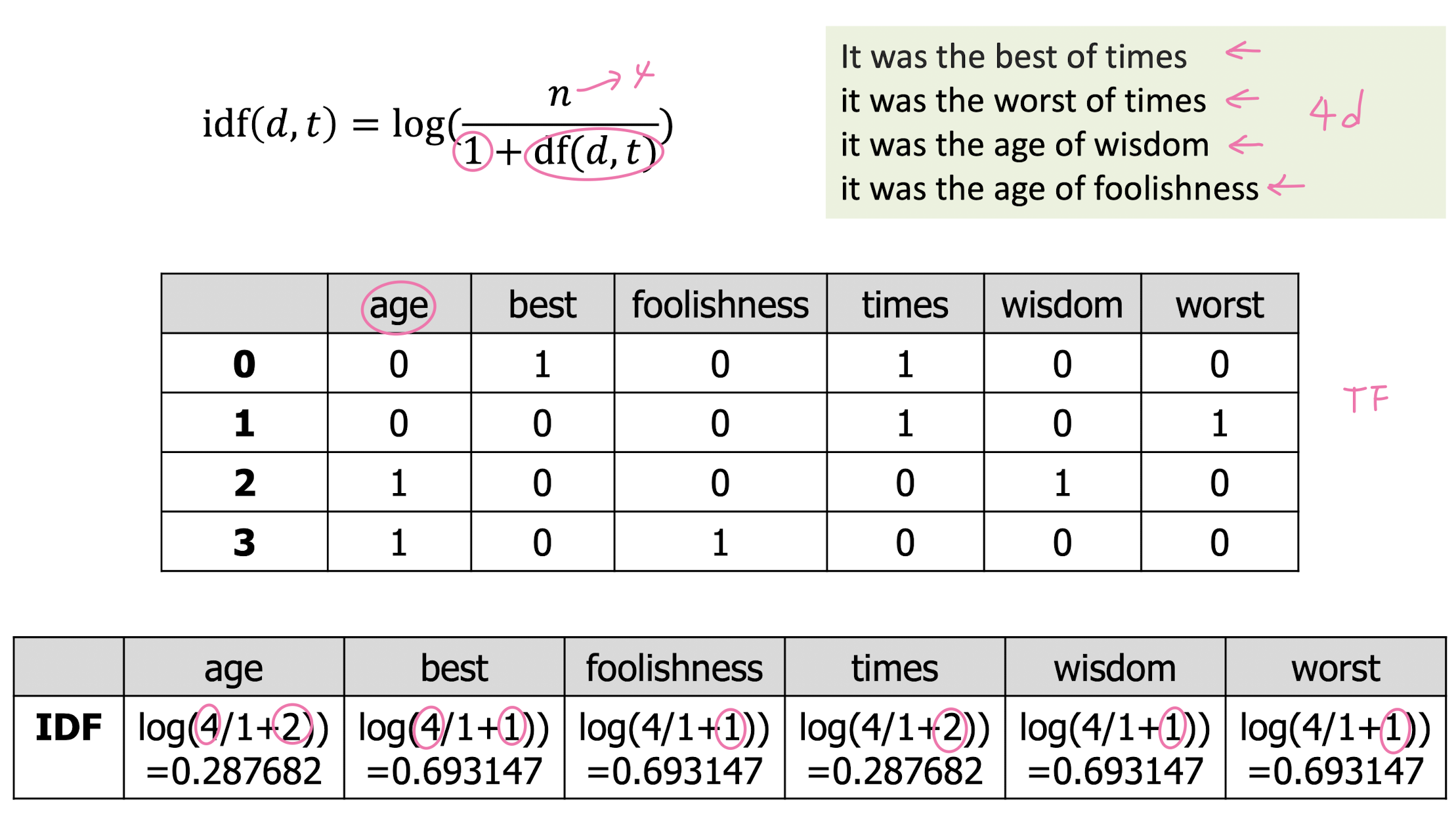
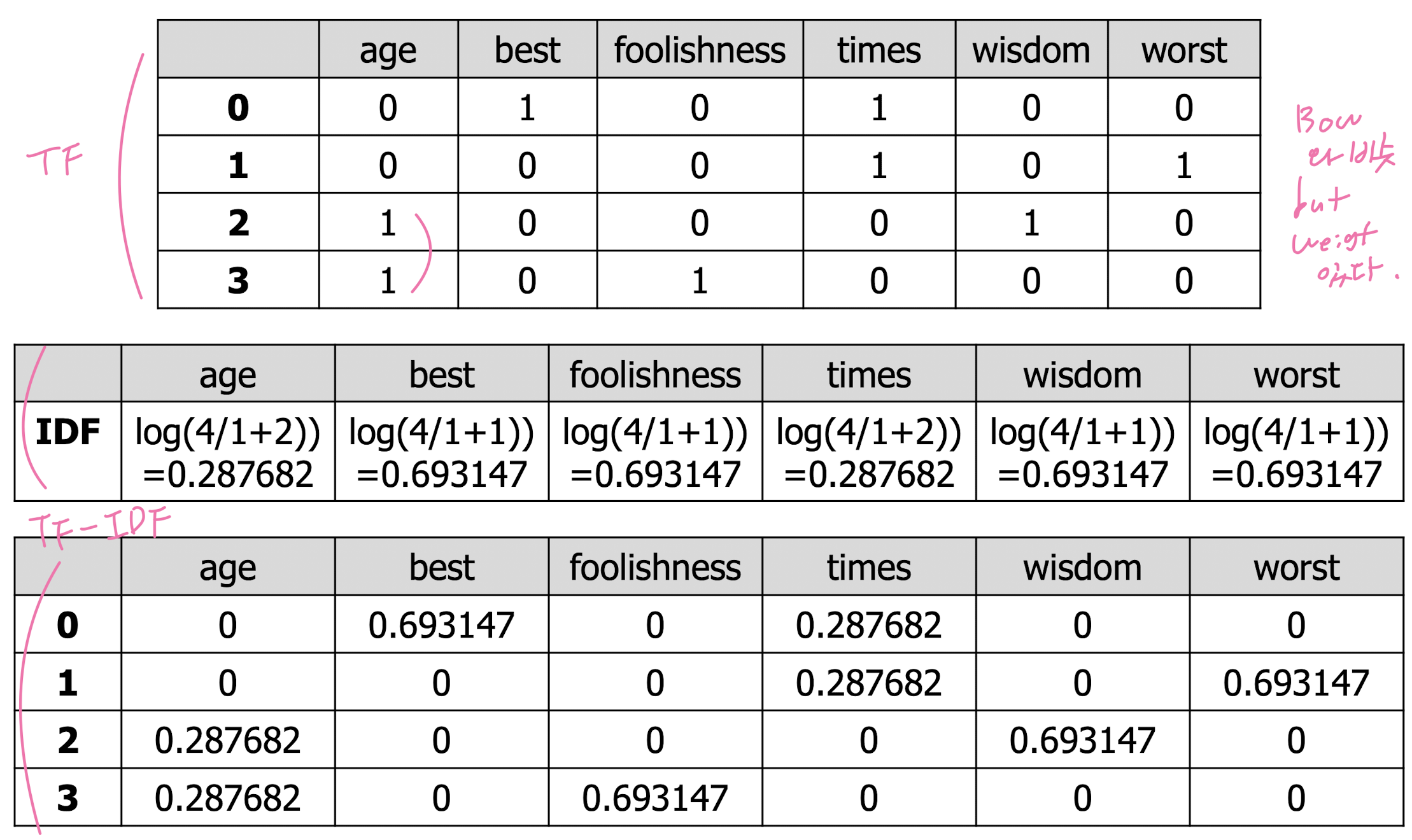
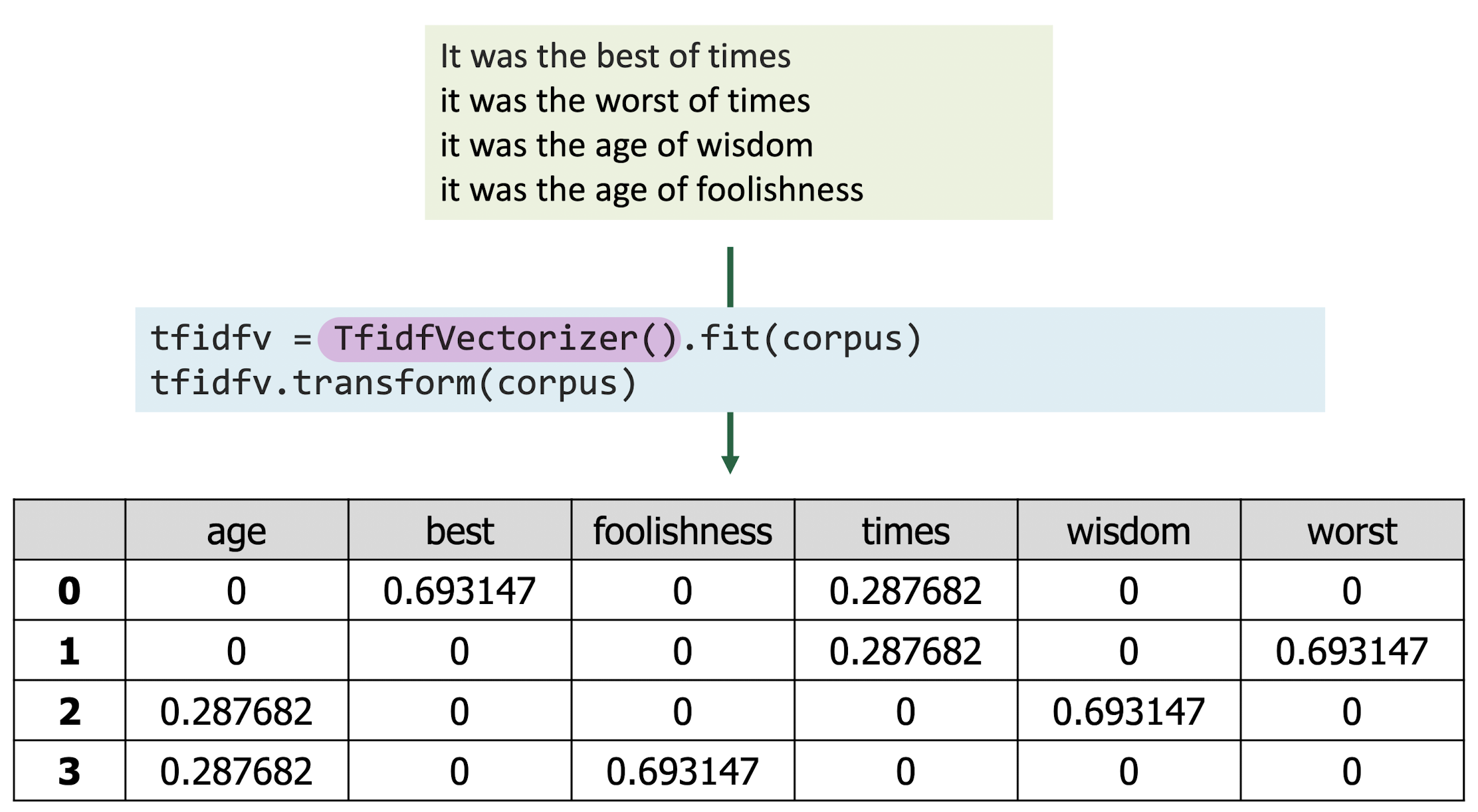
TF-IDF

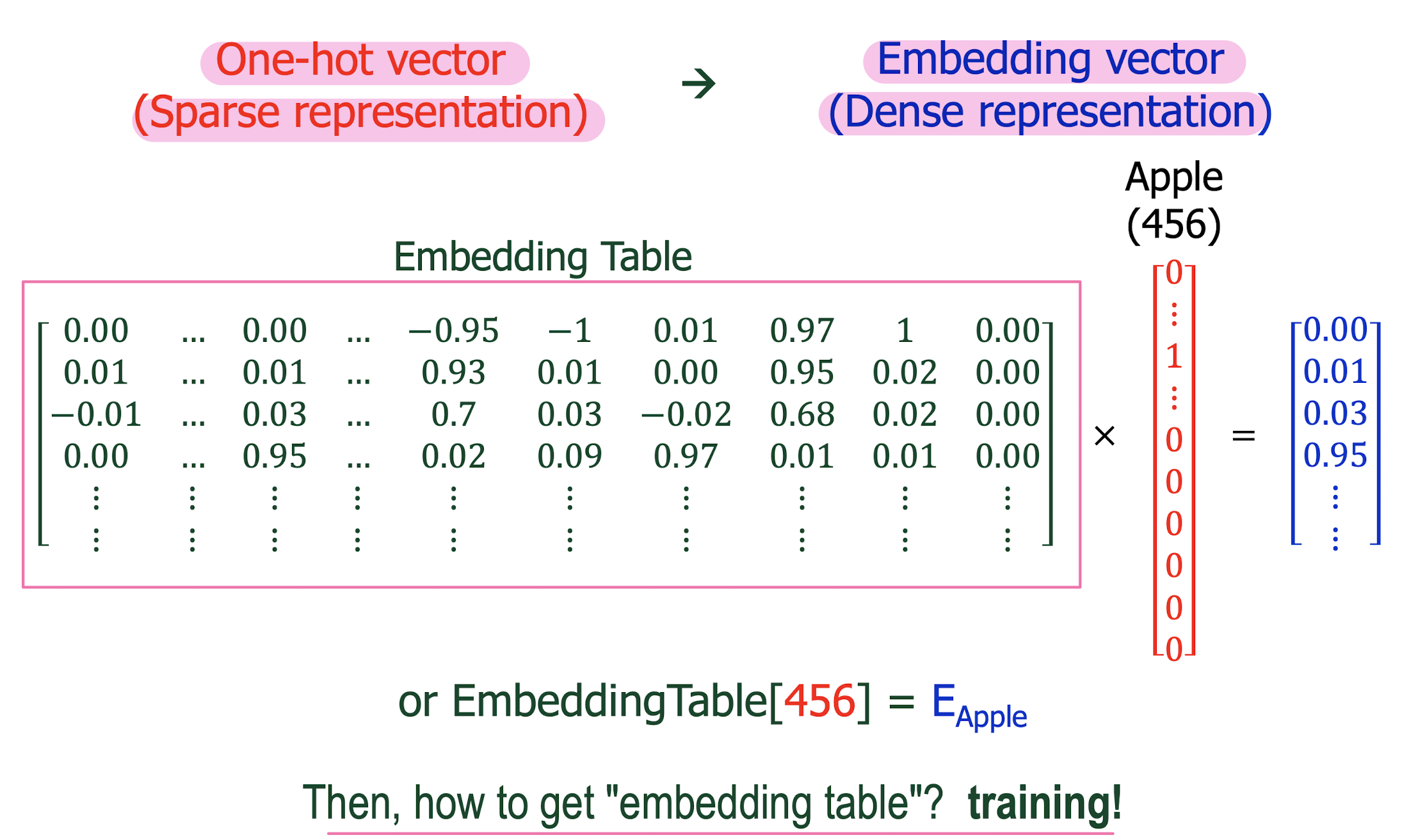
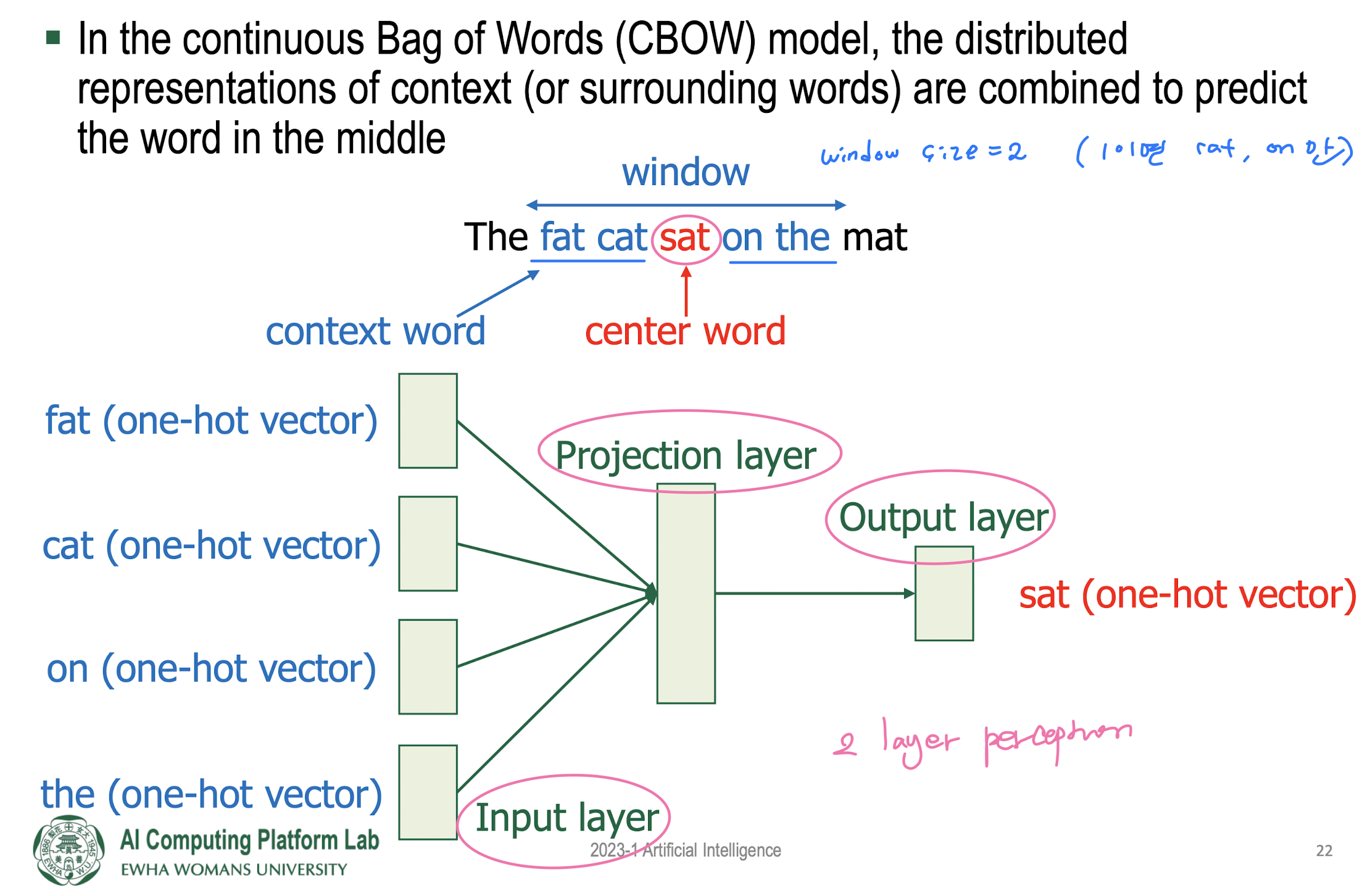
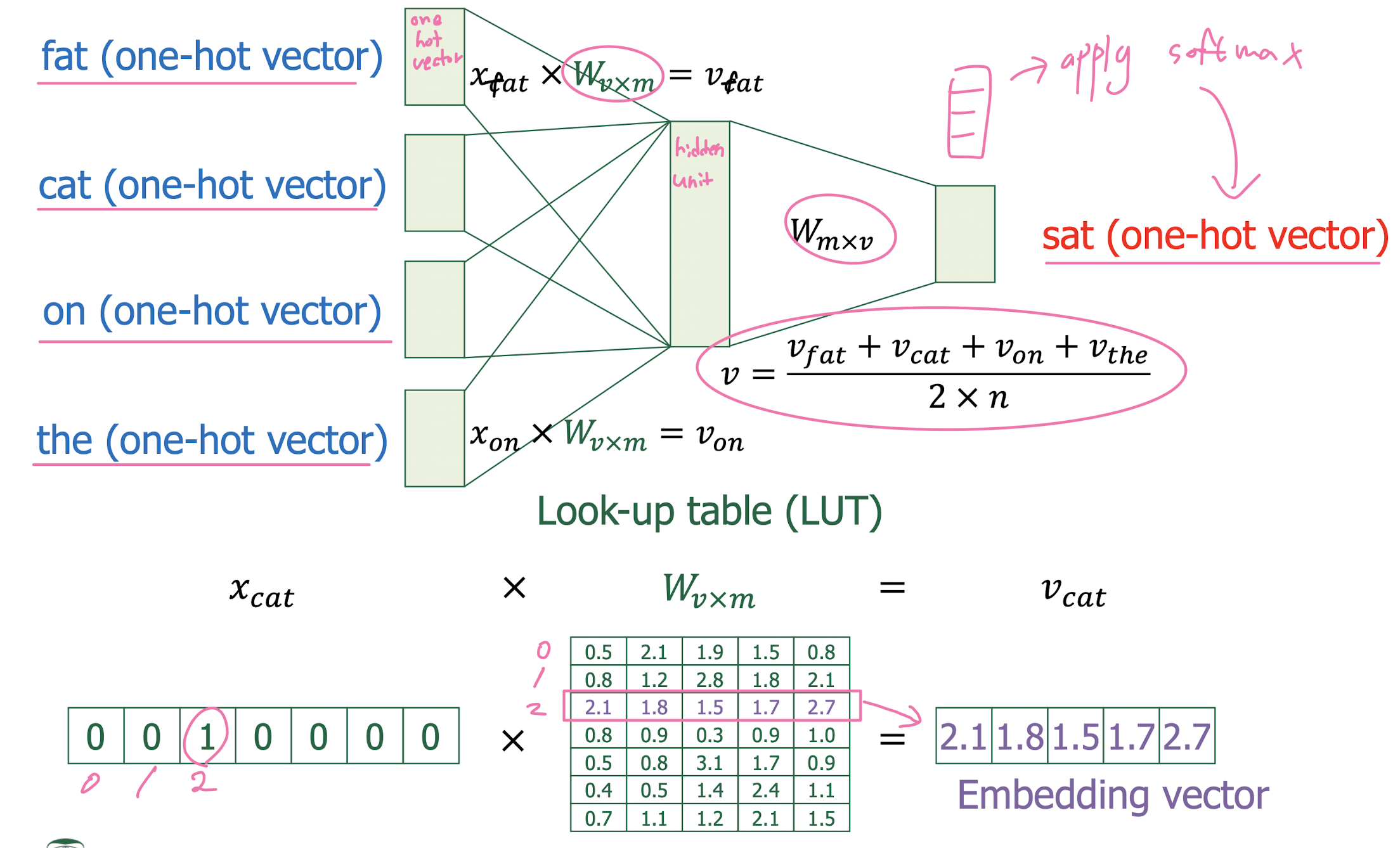
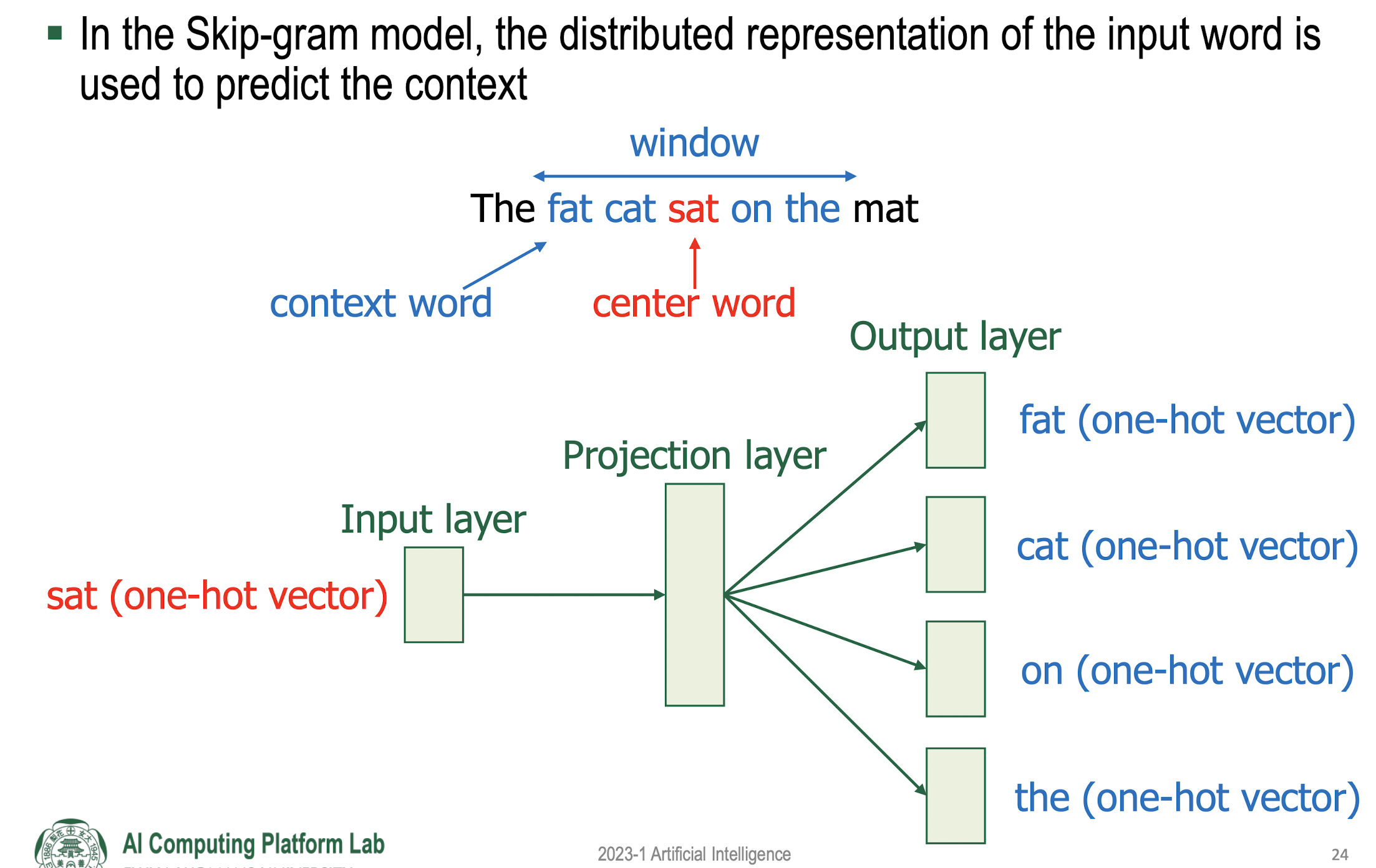
Prediction-based word embedding: Word2Vec
- CBOW
- Skip-Gram
Evaluating NLP tasks
Language model: perplexity
헷갈리는 정도



Evaluating Machine Translation: BLEU


-
Unigram Precision

-
Modified Unigram Precision

-
Modified n-gram Precision

-
BLEU Score
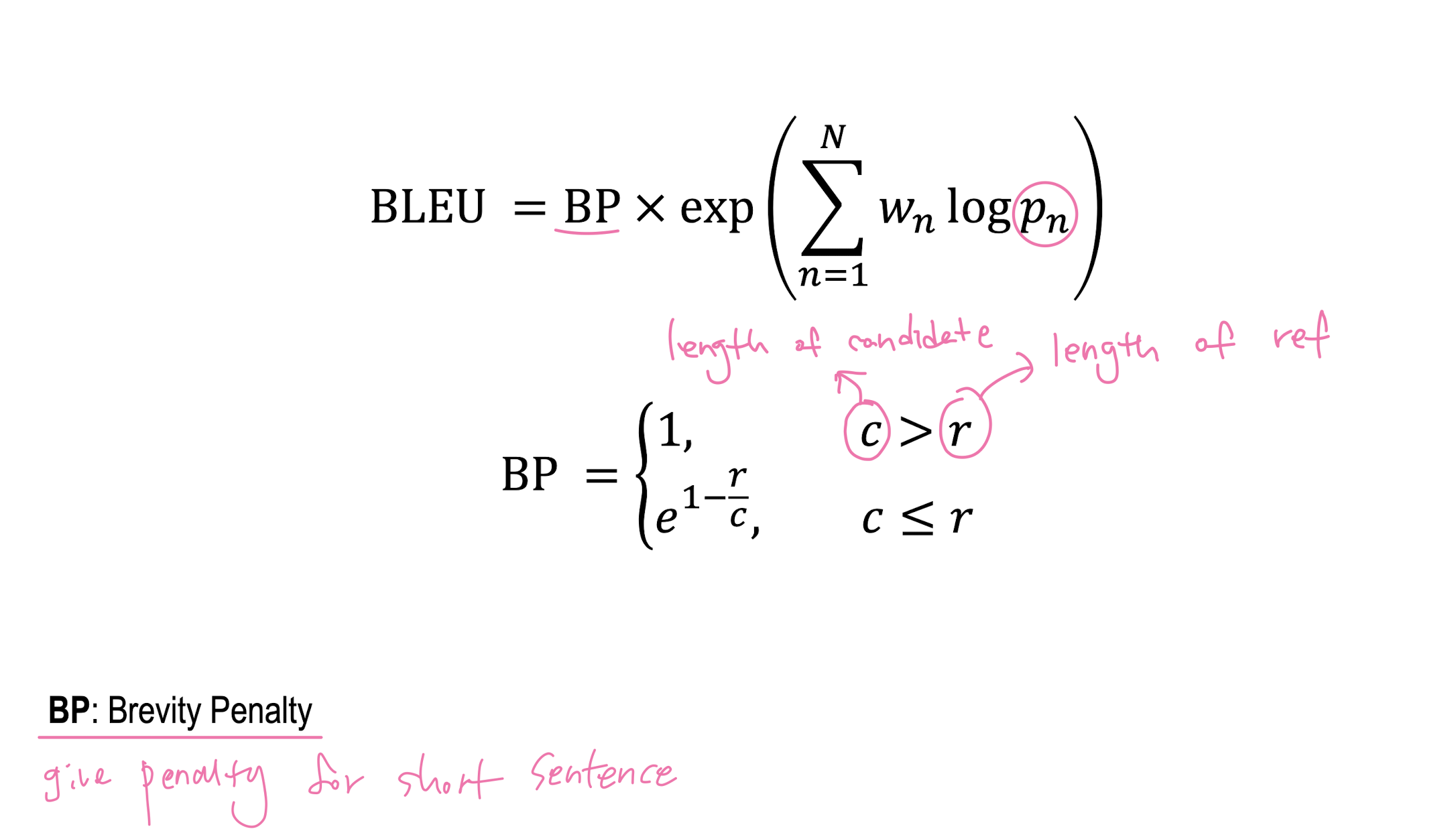
15.Prompt Engineering
Basic prompting
- Few-shot

- Few-shot Learning Tpis

Instruction prompting
Completion prompting
Chain-of-thought prompting
Limitation
16.Generative models
Generative adversarial network (GAN)
Diffusion model
17.Graph Neural Network
Idea using deep learning for graphs
Multiple layers of embedding transformation
At every layer, use the embedding at previous layer as the input – Aggregation of neighbors
Graph convolutional network – Mean aggregation
Applications of GNNs
▪ Remark: GNN is a general architecture
– CNN and Transformer can be viewed as a special GNN
18. Recommendation System
Recommendation System Architecture
Two candidate generation approaches:
1. Content-based filtering
2. Collaborative filtering
- Using matrix factorization
- Using deep neural networks
19. Meta learning
Meta learning
Few shot learning examples
Mathematics
Algorithm: optimization-based inference
- Model-agnostic meta learning
