
HTTP란?
HyperText Transfer Protocol
웹상에서 서로 다른 서버 간에 하이퍼텍스트문서(HTML)를 서로 주고 받을 수 있도록 만들어진 규약이다.
둘 다 이해하는 공용어를 사용해야 대화가 되듯
서버 간의 통신에서도 서로 이해할 수 있는 공통 통신 형식이 필요하다.
- '통신 형식' 내지 '통신 구조'
- 가장 널리 사용되는 프로토콜
HTML 통신 방식
HTML 통신은 두 가지 특징을 가진다.
- HTTP: 요청&응답
- stateless
HTTP 요청&응답
클라이언트가 서버에 HTTP 요청을 보내고
서버는 요청을 처리한 후 결과를 HTTP 응답으로 클라이언트에게 보낸다.
이것이 하나의 HTTP 통신이 된다.
백엔드 API 시스템의 엔드포인트 구현
기본적으로 HTTP 요청을 input으로 받아서
HTTP응답을 output으로 return하는 구조이다.
앞서 구현했던 'ping 엔드포인트'를 예로 들자면
@app.route("/ping", methods=['GET'])
def ping():
return "pong"여기서도 HTTP 요청이 있다.
/ping 주소에 GET요청을 보내는 것이 HTTP 요청이다.
HTTP 응답은 status=200 코드와 함께 "pong"이라는 텍스트를 보내는 것이다.
헌데 status=200 등의 HTTP 요소는 전혀 보이지 않는다.
Flask가 HTTP 부분을 자동으로 처리해 주기 때문이다.
ping함수는 단순히 문자열 "pong"을 return할 뿐이지만
Flask가 이를 자동으로 HTTP 응답으로 변환해준다.
그러므로 Flask를 사용하면
개발자는 일반함수를 구현하듯이 엔드포인트를 구현할 수 있다.
stateless
말 그대로 state(상태)라는 말이 존재하지 않는다.
클라이언트와 서버는 HTTP 통신을 여러 번 주고 받는 게 일반적인데
HTTP 프로토콜에서는 동일한 클라이언트와 서버가 주고받은 HTTP 통신이라할지라도 서로 연결되어있지 않다.
즉 , 각각의 HTTP 통신은 독립적이고 그 전에 처리된 HTTP 통신에 대해서는 전혀 알지 못한다.
이러한 이유로 stateless라고 하는 것이다.
-
장점
: 서버 디자인이 훨씬 간단해지고 효과적이다 -
단점
: HTTP 요청을 보낼 때 해당 요청을 처리하기 위해
필요한 모든 데이터를 매번 포함시켜 요청을 보내야 한다
예를 들어 이미 로그인을 거친 사용자가 그 다음 요청을 보내기 위해서는 로그인했다는 사실을 포함시켜 보내야 한다.
이러한 점들을 해결하기 위해 쿠키(cookie) 세션(session)등을 사용하여 HTTP 요청을 처리할 때 필요한 진행과정이나 데이터를 저장한다.
- 쿠키(cookie)
웹 브라우저가 웹사이트로부터 받은 정보를 저장해놓는 파일
- 세션(session)
웹 서버가 브라우저로부터 받은 정보를 저장할 수 있게 하는 메커니즘
HTTP 요청 구조
- Start Line
- Headers
- Body
우리가 HTTP 요청과 응답 메시지의 모든 부분을 직접 구현할 필요는 없다. 웹 프레임워크가 거의 대부분을 알아서 처리해준다.
일반적으로 개발자가 직접 지정해야 하는 부분은 HTTP 메소드, status code, 헤더 정보, body 부분이다.그럼에도 HTTP 응답과 요청의 구조와 내용을 아는 것은 중요하다.
1. Start Line
요청의 시작줄.
만약 "search" 엔드포인트에 GET 요청을 보낸다고 하면 다음과 같다.
$ GET /search HTTP/1.1

start line도 세 부분으로 구성되어 있다.
-
HTTP 메소드: 요청이 의도하는 액션을 정의하는 부분
GET, POST, PUT, DELETE 등 -
Requset Target
해당 요청이 전송되는 목표 주소 -
HTTP version
HTTP의 버전을 나타낸다
2. 헤더
HTTP 요청 그 자체에 대한 정보를 담고 있다.
예를 들면
요청 메세지의 전체크기, 전송되는 target의 주소, 요청자의 정보 등이 있다.
헤더는 Python의 dictionary처럼 key:value로 이뤄져있다.
다양한 헤더 중에 자주 쓰이는 몇 종류를 알아두자.
-
HOST : (value)
요청이 전송되는 target의 호스트 URL주소
HOST : google.co.kr -
User-Agent : (Value)
요청을 보내는 클라이언트의 정보(웹 브라우저의 정보)
User-Agent : Mozilla/5.0(Mac; ...) -
Accept : (value)
해당 요청이 받을 수 있는 응답의 body 부분의 데이터 타입
MIME 타입이 value가 된다
JSON 데이터 타입으로 응답을 요청하는 경우에는
application/json
이런 식이다MIME 타입은 굉장히 다양하다.
자주 사용되는 MIME 타입은 아래와 같다- application/json, octet-stream, xml
- text/csv, html, plain
- image/jpeg, png
모든 MIME 타입을 열고 싶다면 */*를 입력한다
-
Connection : (value)
해당 요청이 끝난 후 클라이언트와 서버가 계속해서 연결을 유지할지에 대해 알려주는 헤더
keep-alive: 계속해서 요청 보낼 예정이니 연결 유지 바람
close: 닫자 -
Content-Type
HTTP 요청 속에 담긴 메세지의 body가 어떤 타입인지 알려준다
JSON 데이터로 메세지의 body가 구성되어 있다면
value는 application/json이 될 것이다 -
Content-Length:
HTTP 요청 속에 담긴 메세지의 body부분 크기를 알려준다
3.Body
HTTP 요청 메세지에서 body 부분은
요청이 전송하는 데이터를 데이터를 담고 있는 부분이다.
전송하는 데이터가 없다면 body 부분은 비어있다.
HTTP 응답 구조
응답구조도 요청구조처럼 나뉘어져있다.
- Status Line
- Headers
- Body
1. Status Line

-
status code:
HTTP 응답 상태를 미리 지정되어 있는 숫자로 된 코드로 나타낸다
ex. 요청이 정상 처리 -> status code는 200 -
status text:
HTTP 응답 상태를 간략하게 글로 설명해주는 부분
ex. 요청이 정상 처리 -> "OK"
2. 헤더
-
HTTP 요청의 헤더 부분과 동일
-
단, HTTP 응답에서만 사용되는 헤더 값들이 있다
ex. HTTP응답에서는 User-Agent 대신 Server헤더가 사용된다
3. Body
HTTP 요청 메세지의 body와 동일하다.
자주 사용되는 HTTP 메소드
-
GET
이름 그대로 어떤 데이터를 서버로부터 요청할 때 사용
단순히 데이터를 받아오는 요청
body가 비어있는 경우가 많다 -
POST
GET메소드와 함께 가장 자주 사용되는 HTTP 메소드
생성 수정 및 삭제 요청까지 할 수 있다 -
OPTIONS
특정 엔드포인트에서 어떤 메소드를 허용하는 알고자 할 때 보내는 요청
엔드포인트는 허용하는 HTTP를 지정되도록 되어 있다(?)앞서 구현했던 ping 엔드포인트의 경우
GET 요청만 받도록 구현되어 있다만약 POST 요청을 보내면
405 Method Not Allowed 응답을 Flask가 자동으로 보낸다
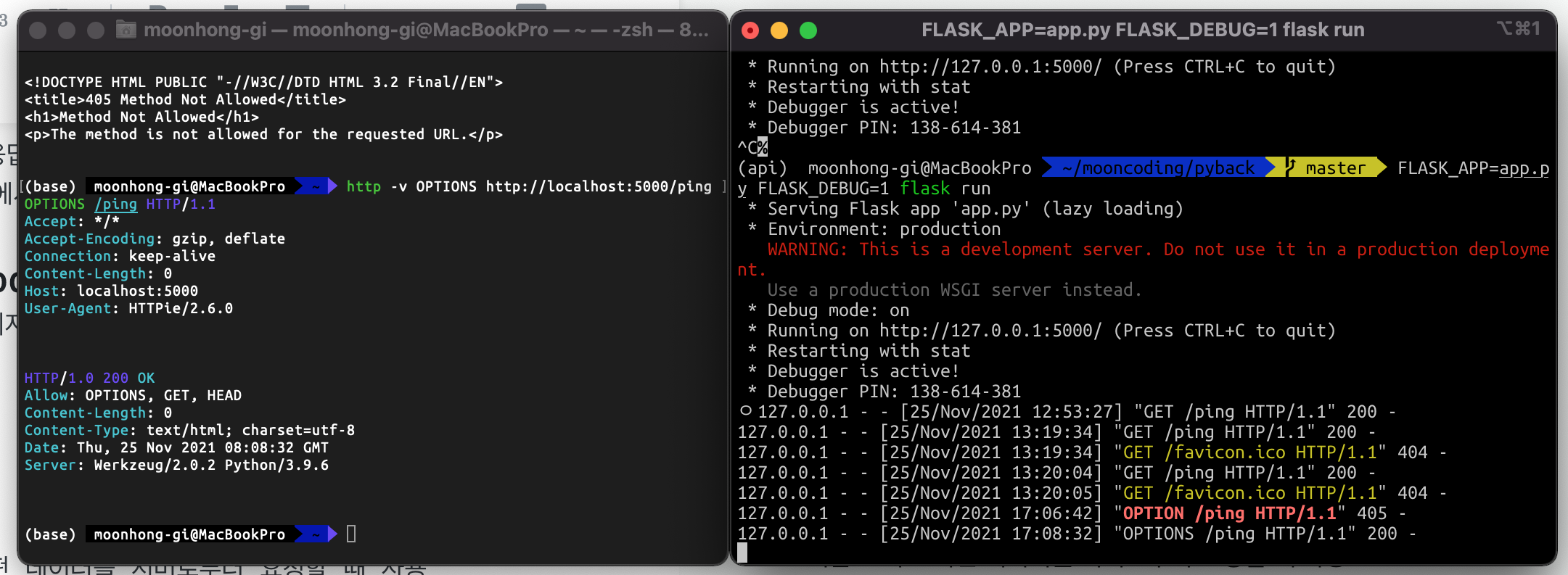
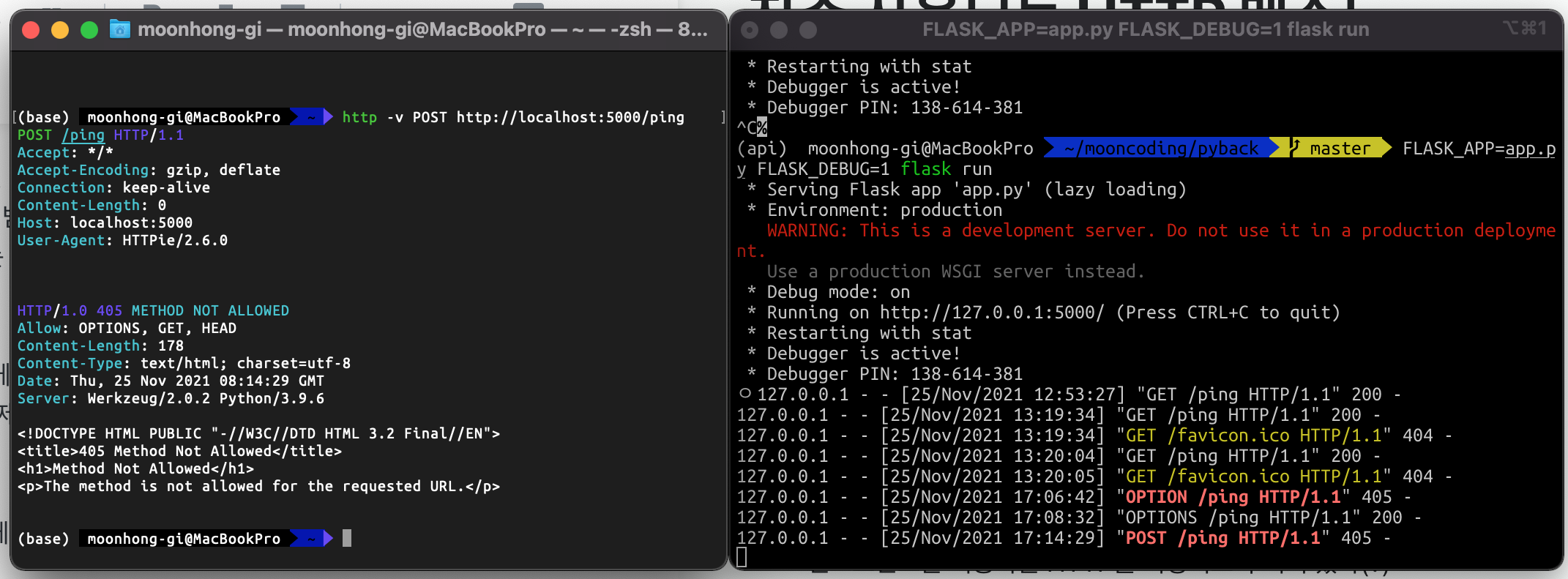
OPTIONS 요청은 정상적으로 들어가서 200 OK를 받아냈지만
POST 요청은 405 Method Not Allowed를 받았다.
ping 엔드포인트를 구현할 때 GET만 설정했는데
OPTIONS와 HEAD가 왜 들어가 있을까?OPTIONS와 HEAD는 Flask가 알아서 해준다
-
PUT
POST 메소드와 비슷한 의미를 가지고 있다
POST와 중복되는 의미라 굳이 이걸 쓰지 않고 POST로 통일하여 사용하는 추세로 돌아섰다 -
DELETE
이름 그대로 삭제 요청을 할 때 보내는 메소드
PUT과 마찬가지로 POST로 통합되어 가는 추세다
자주 사용되는 HTTP Status Code와 TEXT
HTTP요청에서 HTTP메소드를 잘 이해하는 것만큼
HTTP응답에서는 HTTP Status code와 TETX를 잘 이해하여 적절한 응답을 하는 것 또한 중요하다.
-
200 OK
자주 보고 싶은 status code
잘했음 문제 없음 -
301 Moved Permanently
엔드포인트의 URL 주소가 바뀌었다는 뜼
301 status code의 HTTP 응답은 Location 헤더가 포함되는 것이 일반적이다
Location 헤더에 해당 엔드포인트의 새로운 주소가 포함되어 나온다
301을 받은 클라이언트는 Location 헤더의 새로운 주소에 해당 요청을 다시 보내게 된다
이것을 redirection이라 한다 -
400 Bad Request
잘못된 요청
주로 요청한 놈이 잘못했을 때 사용된다
이상한 거 보냈을 때 나오는 응답 -
401 Unauthorized
해당 요청을 보내는 주체의 신분이 확인될 수 없는 상황일 때
주로 HTTP 요청을 보내는 사용자에게 로그인이 필요하다면 401을 보내준다 -
403 Forbidden
HTTP 요청을 보내는 주체가 해당 요청에 대한 권한이 없음을 나타내는 코드
예를 들어 돈 낸 사람만 할 수 있는 요청을 돈 안 낸 사람이 하면 이걸 보내주면 합리적이다 -
404 Not Found
매우 자주보는 코드
해당 페이지를 찾을 수 없습니다
HTTP 요청을 보내고자 하는 URI가 존재하지 않을 때 보내주는 응답 -
500 Internal Server Error
내부 서버 오류가 발생
HTTP 요청을 받은 서버에서 해당 요청을 처리하는 과정에서 오류가 생겼기에 요청을 처리할 수 없다는 뜻
API 백엔드 개발자들이 가장 싫어하는 응답 코드 중 하나
RESTful HTTP API
몇 번째인지 모르겠는데 봐도봐도 헷갈리니까 또 본다
- API 시스템을 구현하기 위한 아키텍처의 한 형식
- API에서 전송하는 리소스(resource)를 URI로 표현
- 리소스에 행하고자 하는 의도를 HTTP 메소드로 정의
- 각 엔드포인트는 리소스를 표현하는 고유의 URI 주소 보유
- 해당 리소스에 행할 수 있는 행위를 표현하는 HTTP 메소드 처리 가능
예를 들어 사용자 정보를 리턴하는 '/user' 엔드포인트에서
사용자 정보를 받아온다 치면
HTTP GET /users
GET /users
보통 GET 요청은 body가 없기 때문에 명령어가 깰끔쓰.
새로운 사용자를 생성하는 엔드포인트 URI를 '/user'라고 정하면
HTTP 요청은
POST /user
{
"name" : "conqueror",
"email" : "conqueror@gmail.com",
}이런 식으로 표현된다.
이러한 구조로 설계된 API를 RESTful API라고 한다.
장점은 강한 자기 설명력에 있다.
엔드포인트의 구조만 보더라도 해당 엔드포인트가 제공하는 리소스와 기능을 파악할 수 있다.
REST 방식의 API설계는 구조가 직관적이며 간단하다.
GraphQL
REST API에서 생기는 문제를 극복하기 위해 등장했다.
REST API의 문제점
-
API의 구조가 특정 클라이언트에 맞춰져서 다른 클라이언트에서 사용하기에 적합하지 않게 된다는 점이다.
-
REST 방식의 API에서는 클라이언트들이 API가 엔드포인트들을 통해 구현해놓은 틀에 맞춰 사용해야 하다 보니 틀에서 벗어나는 사용은 어려워진다
GraphQL이 REST API와 다른 점?
-
엔드포인트가 오직 하나다
-
엔드포인트에 클라이언트가 필요한 것을 정의해둔다
-
서버가 정의한 틀에서 클라이언트가 요청하는 REST와 구별된다
아이디가 1인 사용자의 정보 & 그의 친구들의 이름 정보를 API로부터 받는다고 가정할 때
- REST API 방식
$ GET /users/1 # 아이디가 1인 사용자의 정보
$ GET /users/1/friends # 그의 친구들의 이름 정보이런 식으로 HTTP 요청을 두 번 보내야 두 종류의 정보를 얻을 수 있음.
이걸 한 번의 HTTP 요청으로 압축하려면 아래처럼 해야 함.
$ GET /users/1?include=friends.name요청을 두 번 하는 건 횟수가 늘어날 수록 비효율적일 것이고
압축한 요청은 불필요하게 복합해지는 느낌이 있다.
GraphQL 기반으로 동일한 HTTP 요청을 한다면?
POST /graphql
{
user(id: 1){
name
age
friends {
name
}
}
}이런 식이다.
만일 사용자 정보는 이름만 필요하고, 대신 친구들의 이름과 이메일이 필요하다면?
POST /graphql
{
user(id: 1){
name
friends{
name
email
}
}
} 이게 뭔가 좀 좋아보이긴 함.
좀 더 자유로운 느낌 굿.
단 GraphQL은 장점이 많지만 REST에 비해 나이가 적다. 따라서 입문자에게는 REST가 추천되는 편이다.
