
C#에는 Hash를 활용해 Key와 Value 데이터 쌍을 저장하는 두 가지 자료구조를 지원한다. 이 둘의 차이를 알아보자.
· Hashtable
해시 테이블은 Non-generic 자료구조로, 한 객체 안에 어떤 타입의 데이터든 저장할 수 있다.
using System.Collections;
static class Program
{
static void Main()
{
Hashtable hashtable = new Hashtable();
int keyInt = 40;
int valueInt = 4;
string keyString = "Hello, ";
string valueString = "World!";
hashtable.Add(keyInt, valueInt);
hashtable.Add(keyString, valueString);
foreach(DictionaryEntry pair in hashtable) {
Console.WriteLine(pair.Key + "" + pair.Value);
}
}
};404
Hello, World!hashtable 안에 int, int 쌍과 string, string 쌍이 함께 저장되는 것을 확인할 수 있다. 이때 담으려는 데이터 타입을 더 넓은 범주의 데이터 타입으로 변환하는 Boxing이라는 과정을 거쳐 데이터를 저장한다. 박싱으로 변환된 데이터는 DictionaryEntry라는 구조체에 저장되어 해시 테이블을 구성한다.
- Boxing
-
C#의 박싱은 값 타입(기본 타입, 구조체)을
Object타입으로 또는 상속 받은 인터페이스 형식으로 변환하는 프로세스다.-
값 타입 →
Object타입으로의 변환int num = 5; object obj = num;위와 같이 단순 값 타입을
Object타입으로 변환하는 경우 박싱이 일어나고, 앞선 해시 테이블 예제에선 다음과 같은 데이터 타입의 변환을 확인할 수 있다.
int,string타입을object타입으로 박싱하였다. 변환된object데이터 쌍은DictionaryEntry라는 구조체로 해시 테이블을 구성한다. -
값 타입 → 인터페이스 객체
using System.Collections; interface IAcceptance { void PutObject(string objectName); } struct Bookshelf : IAcceptance { int size; string bookType; string[] book = new string[100]; public Bookshelf(){ size = 0; bookType = "Everything"; } public Bookshelf(string _bookType, string[] _book) { size = _book.Length; bookType = _bookType; for(int index = 0; index < _book.Length; index++) { book[index] = _book[index]; } } public void PutObject(string objectName) { book[size++] = objectName; } } static class Program { static void Main() { Bookshelf bookshelf = new Bookshelf("Cook", new string[] { "Korean", "Japanese" }); IAcceptance container = bookshelf; container.PutObject("Chinese"); } }
-
위와 같이 값 타입인 구조체 상속한 인터페이스 객체에 구조체를 저장할 때도 박싱이 일어난다. 이때 박싱할 값을 boxed 임시 객체에 저장하고 System.Object 인스턴스 내부에 래핑하여 관리되는 힙에 저장한다. 즉, 복사가 일어나는 것이다.
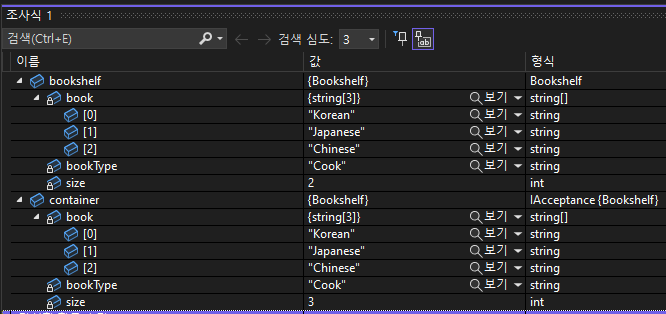
하지만 위 코드에선 값 타입인 구조체 안에 참조 타입인 Array를 포함하고 있다. 이 경우에는 참조 타입 변수의 주소를 복사하고, 그대로 참조 타입으로 동작한다. 위 디버그 결과에서 book에 Chinese 원소가 정상적으로 추가되었지만, size의 값 변화는 직접 함수를 호출한 container 객체에서만 일어나고 bookshelf 객체는 그대로인 것을 확인할 수 있다.
- Unboxing
-
언박싱은 박싱된 데이터를 특정 타입의 데이터로 변환시켜주는 작업이다. 이때, 박싱은 모든 타입을
object라는 통일된 타입이나 명시된 인터페이스 타입으로 변환시켜주기 때문에 명시적 변환이 아닌 암시적 변환을 해주었지만, Unboxing은 명시적 변환이 필요하다.
언박싱 작업이 호출되면
Object인스턴스를 관리하던 힙에서 개체를 찾아 값 형식을 추출한다.
· Dictionary
딕셔너리는 해시 테이블과 다르게 Generic type을 활용하여 객체를 생성하고, 그에 맞는 타입만 데이터로 저장할 수 있다.
using System.Collections;
static class Program
{
static void Main()
{
Dictionary<int, int> dictionary = new Dictionary<int, int>();
int keyInt = 40;
int valueInt = 4;
string keyString = "Hello, ";
string valueString = "World!";
dictionary.Add(keyInt, valueInt);
// dictionary.Add(keyString, valueString); // Error!
foreach (KeyValuePair<int, int> pair in dictionary) {
Console.WriteLine(pair.Key);
}
}
};40앞선 해시 테이블의 데이터로 딕셔너리를 구성하면 위와 같다. 제네릭 타입을 사용하여 미리 자료구조에 담을 데이터 타입을 지정했기 때문에 다른 타입의 데이터를 저장하는 것은 불가능하다. 딕셔너리는 KeyValuePair<> 구조체로 데이터를 저장한다.
· 차이
앞서 말한 것처럼 해시 테이블은 Non-generic이므로 자료구조에 담을 데이터형을 미리 지정해주지 않고, 어떤 타입이든 저장할 수 있다. 반대로 딕셔너리는 Generic type으로 미리 데이터형을 지정해주어야 한다.
해시 테이블은 여러 타입을 수용할 수 있다는 장점, 딕셔너리는 속도가 빠르다는 장점이 있다. MS 공식 박싱은 단순 참조 할당보다 20배, 언박싱 캐스트 프로세스는 할당의 4배에 달하는 시간이 소요될 수 있다고 한다. 사실 시스템을 개발하다 보면 한 컨테이너에 '굳이' 여러 타입을 수용해야 할 이유가 거의 없기도 하다. 따라서 웬만해선 딕셔너리를 사용하도록 하자.
· 참고
▶ C# - 해시테이블 vs 딕셔너리 ( hashtable vs. dictionary )
▶ C# - 박싱 과 언박싱 (Boxing & UnBoxing)
▶ [MS Document] Boxing 및 Unboxing(C# 프로그래밍 가이드)
▶ [MS Document] .NET 성능 팁
