시작하면서
대학원 시절 졸업 프로젝트가 간간히 생각이 안나 두 파트로 정리하고자 한다.
동적 제스처 인식(dynamic gesture recognition)을 활용하여 인지 재활 환자의 증상 완화를 위한 목적으로 개발된 프로젝트.
Dynamic gesture recognition 이란
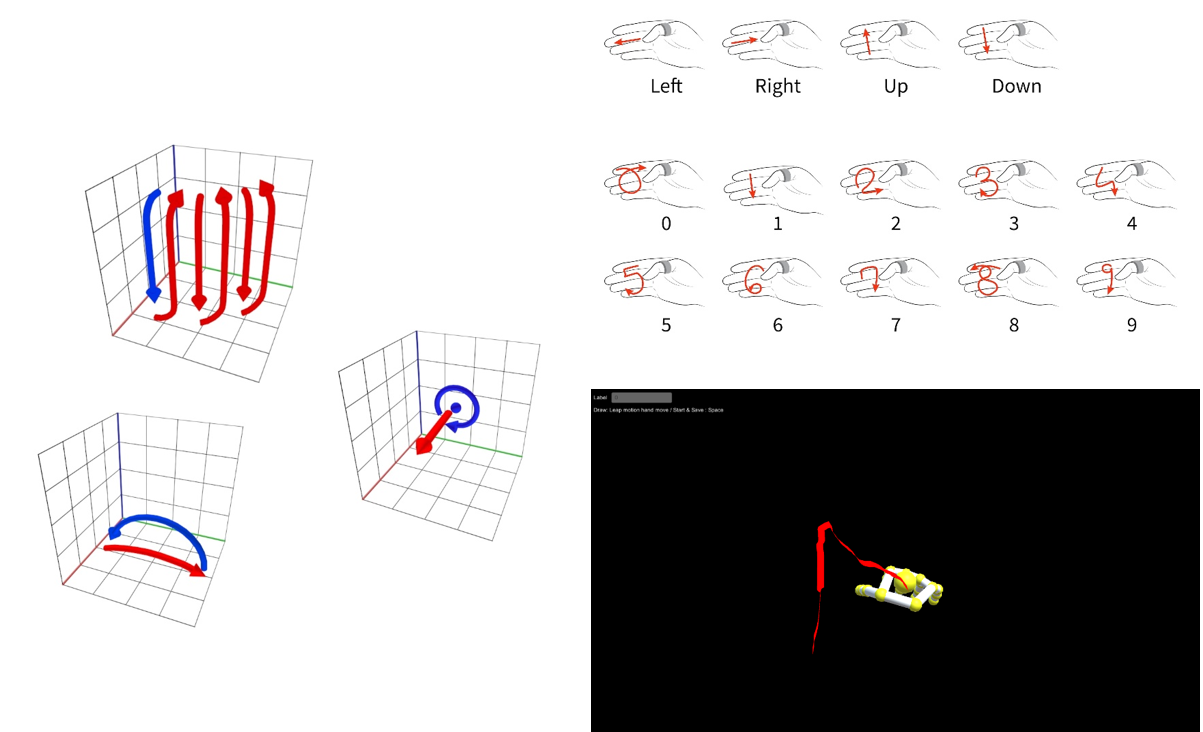
손의 자취나 움직임을 인식하는 연구
연구 내용
- 제스처 데이터 전처리 과정
- 학습 데이터 구성
- 제스처 데이터 예측 모델(CNN) 구축
- 프로젝트 영상
제스처 데이터 전처리 과정
초기 진행한 연구에서는 3차원 VR공간에서 입력되는 위치 벡터를 CNN을 활용하여 제스처의 궤적을 이미지로 생성하여 예측했다. 전처리 과정은 아래 그림과 같다.

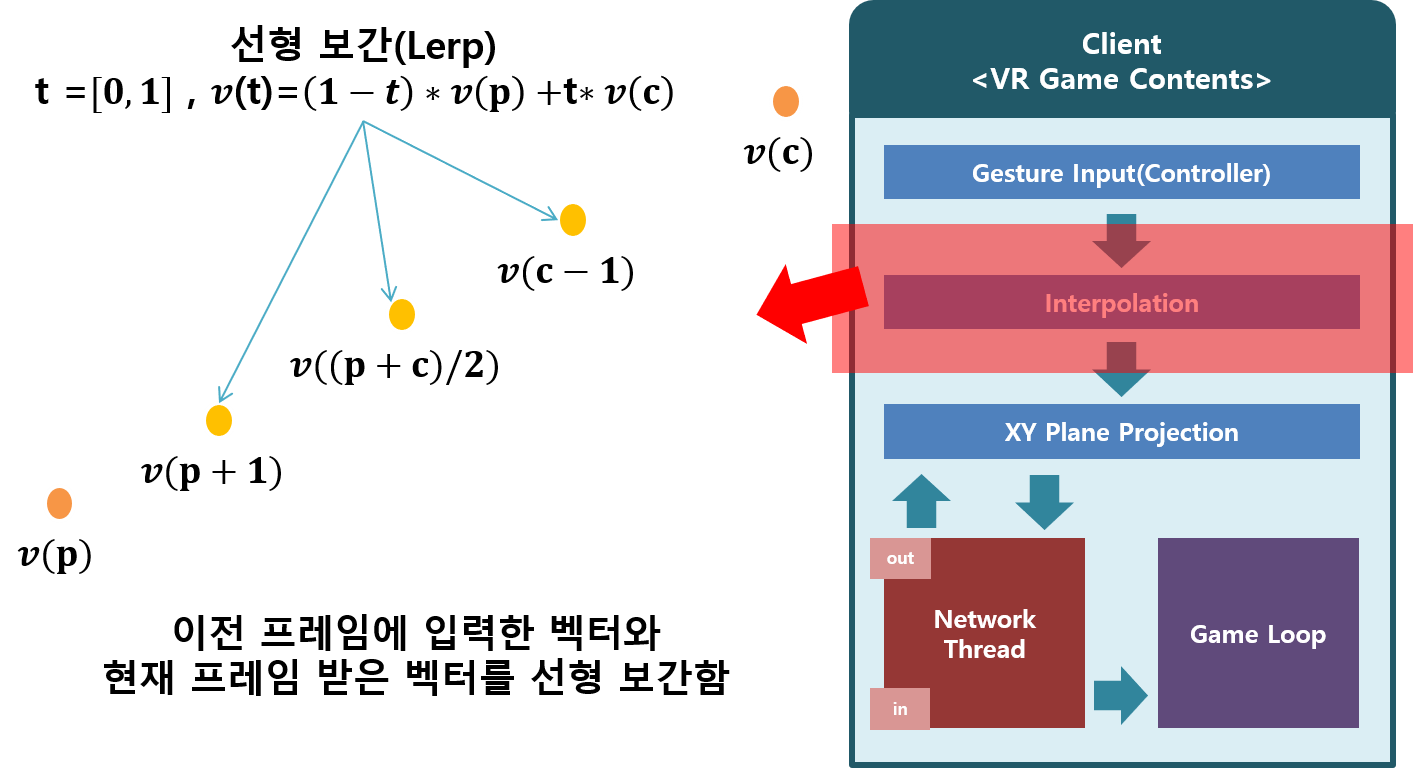
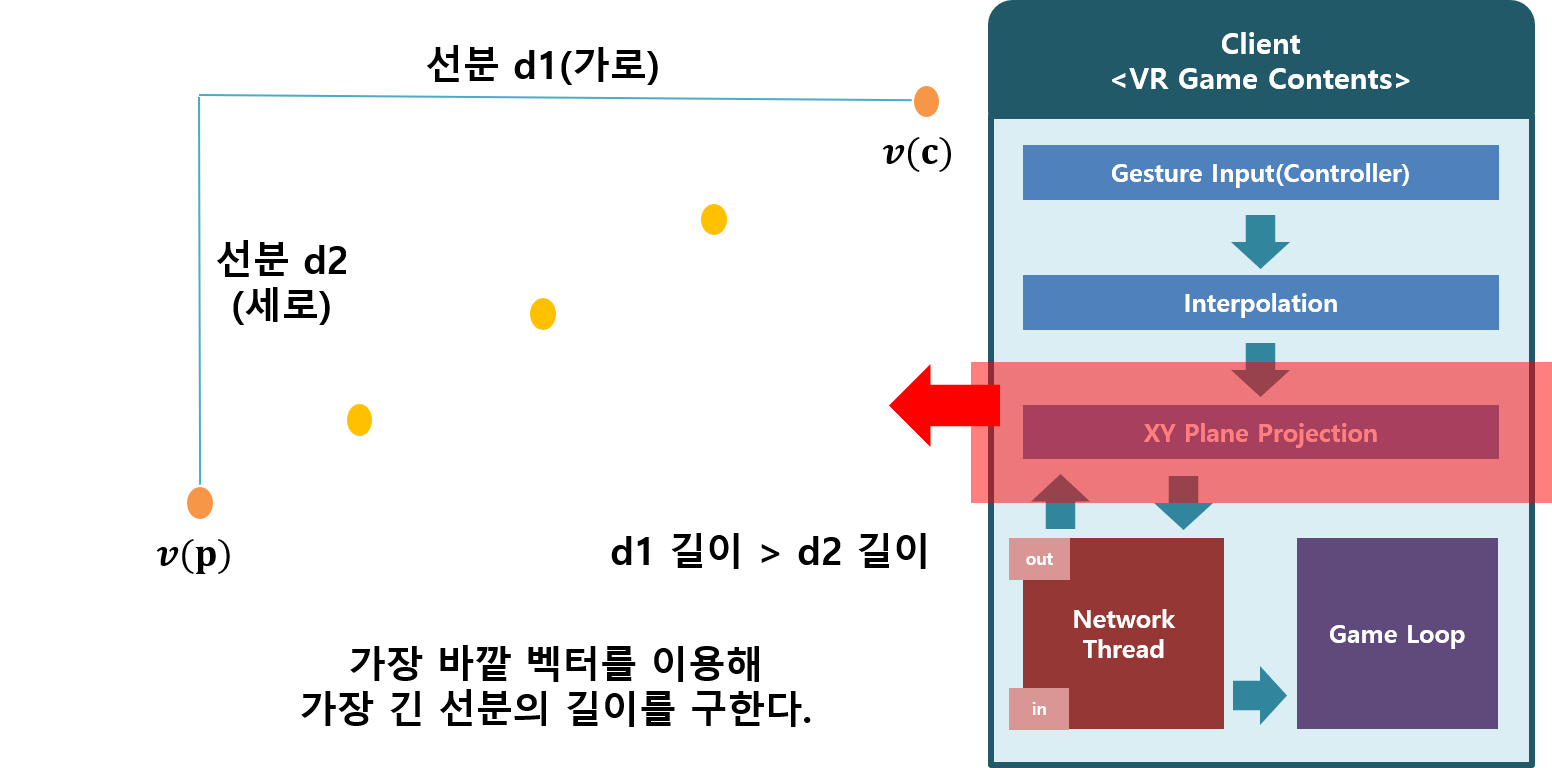
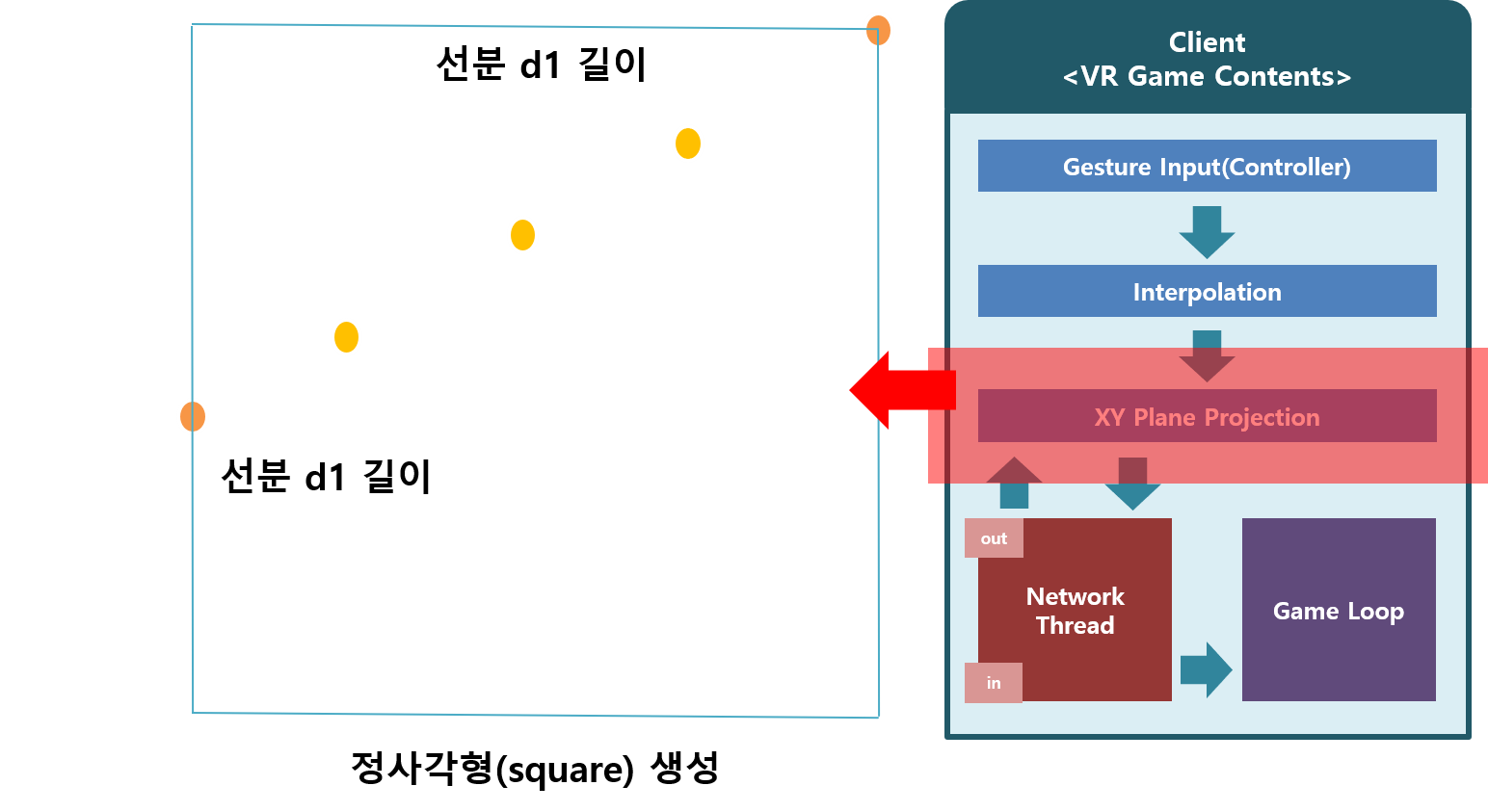


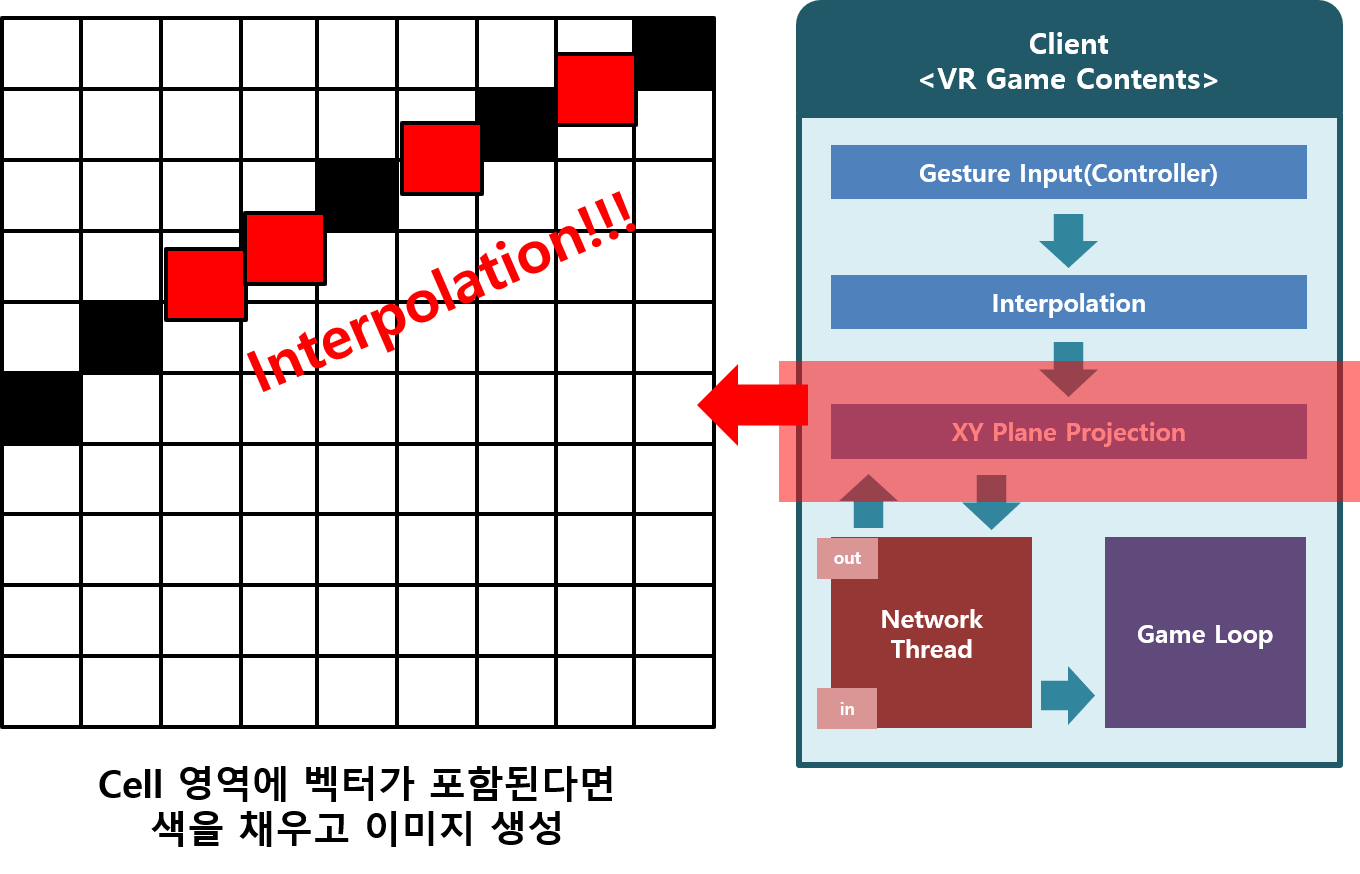
매 프레임 마다 입력 받은 벡터를 샘플링하는 Snippet Code
List<Vector3> points = new List<Vector3>(); // 실제 코드에선 멤버 변수로 할당
List<Vector3> point_list = new List<Vector3>();
//Interpolation Threshold에 따라 처리
for (float t = pixel_Interpolation; t < 1; t += pixel_Interpolation)
{
Vector3 from = new Vector3(points[points.Count - 2].x, points[points.Count - 2].y, points[points.Count - 2].z);
Vector3 to = new Vector3(points[points.Count - 1].x, points[points.Count - 1].y, points[points.Count - 1].z);
Vector3 point = Vector3.Lerp(from, to, t);
point_list.Add(point);
}
//Point List를 points에 Insert(Interpolation)
for (int i = 0; i < point_list.Count; i++) points.Insert(points.Count - 1, new Vector3(point_list[i].x, point_list[i].y, point_list[i].z));
//Line Renderer에 적용
int start = vertexCount;
for (int i = start; i < points.Count; i++)
{
vertexCount += 1;
currentGestureLineRenderer.SetVertexCount(vertexCount);
currentGestureLineRenderer.SetPosition(vertexCount - 1, points[vertexCount - 1]);
} Grid로 분할된 정사각형을 생성하여 3차원 벡터의 궤적을 2차원 이미지로 바꾸는 함수 Snippet Code
//Gesture Data - Export
public byte[] ExportGesture(ref List<Vector3> point, int gridSize = 32)
{
Vector3 tl = new Vector3();
if (point.Count > 0) tl = point[0];
Vector3 br = new Vector3();
if (point.Count > 0) br = point[0];
for(int i=0;i<point.Count;i++)
{
Vector3 p = point[i];
if (tl.x > p.x) tl.x = p.x;
if (tl.y < p.y) tl.y = p.y;
if (br.x < p.x) br.x = p.x;
if (br.y > p.y) br.y = p.y;
}
//Distance 구해서 Max 찾기
float distance1 = Mathf.Abs(tl.x - br.x);
float distance2 = Mathf.Abs(tl.y - br.y);
float maxD = distance1;
if (distance1 < distance2) maxD = distance2;
float cellSize = maxD / (float)gridSize;
byte[] data = new byte[gridSize * gridSize];
for(int i=0;i<point.Count;i++)
{
float _x = 0;
if (cellSize != 0) _x = Mathf.Abs(point[i].x - tl.x) / cellSize;
float _y = 0;
if (cellSize != 0) _y = Mathf.Abs(tl.y - point[i].y) / cellSize;
int x = (int)_x;
int y = (int)_y;
if (x >= gridSize) x = x - 1;
if (y >= gridSize) y = y - 1;
data[y * gridSize + x] = (byte)255;
}
return data;
}학습 데이터 구성

생성된 이미지를 통해서 CNN 모델 학습을 학습함. 제스처 카테고리는 총 10개, 10000개의 학습데이터를 수집후 학습.
제스처 데이터 예측 모델(CNN) 구축
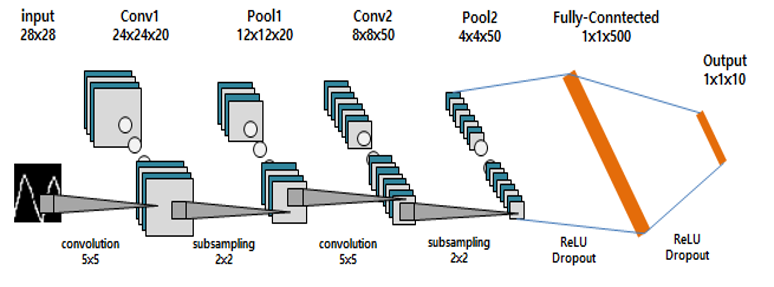
이렇게 만든 CNN 모델을 VR 공간에서 인지 재활 환자의 재활치료 목적으로 제스처 인식을 개발했다.
프로젝트 영상
Reference

그냥 프로그래머