MySQL - Master - Slave 구조에서 Slave를 Scale-Out 해보기

🤔 지금 인프라로 장애가 발생한다면 대응이 가능할까?
Pet-Hub 프로젝트를 마치고 기능과 성능 부분에서 많은 리팩토링을 진행하고 있던 와중에 프로젝트를 위해 구성한 인프라가 과연 견고한가에 대한 의문점이 생겼습니다.
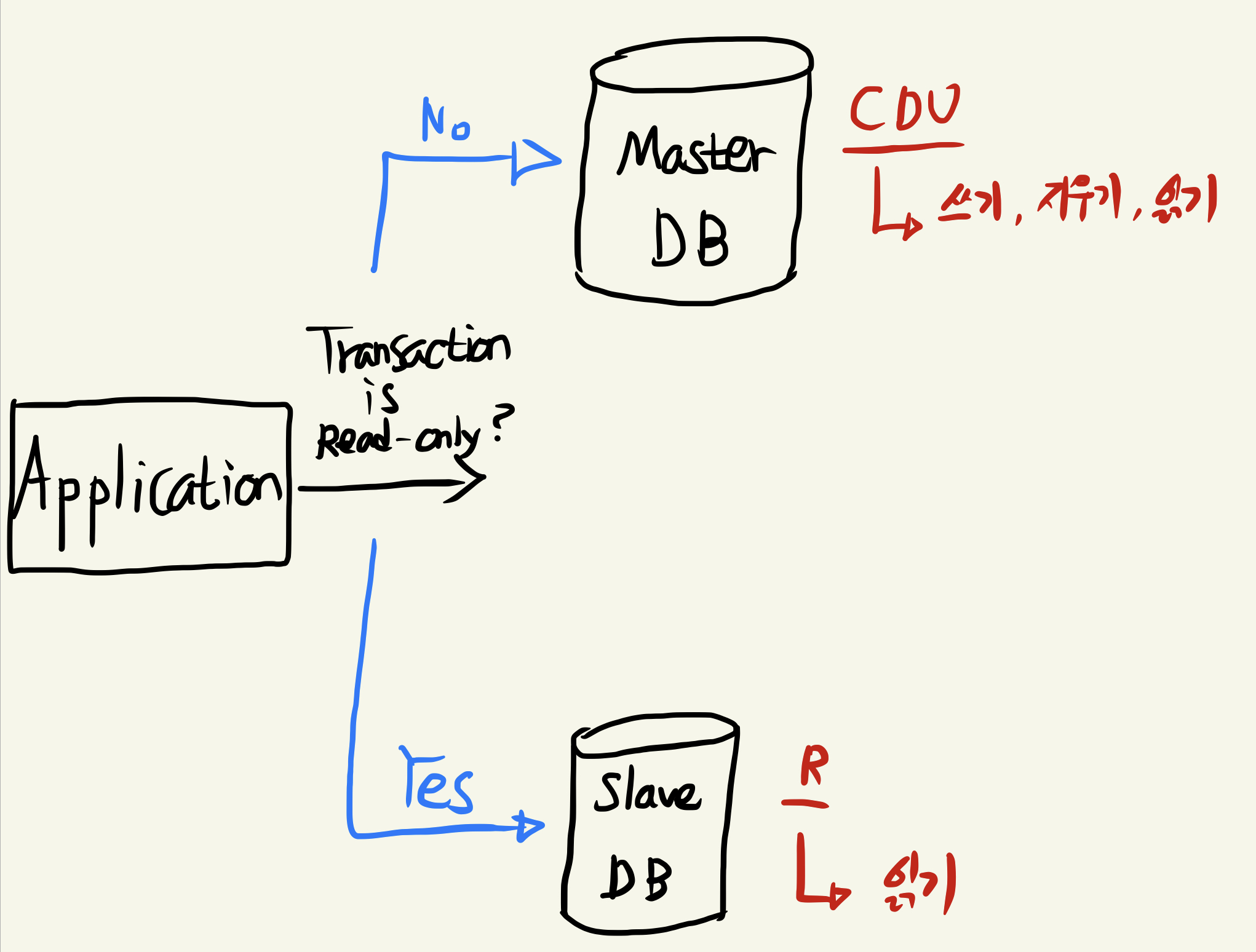
기존에는 Master와 Slave가 1:1로 매칭되어 있는 상태로 Replication을 진행했습니다.
만약 Master DB가 다운된다면 데이터를 쓰는 작업이 불가능해지고, Slave DB가 다운된다면 읽기 작업이 불가능해집니다.
MySQL Replication에서 Master DB가 다운되었을때 가장 최신의 Slave를 Master로 승격시키는 MHA 방식이 많이 사용되고 있는데, Slave DB가 한대뿐이라면 이 역시도 불가능하기에 장기적으로 큰 리스크를 안고있다고 판단했습니다.
🧐 어떻게 바꿔야 할까?
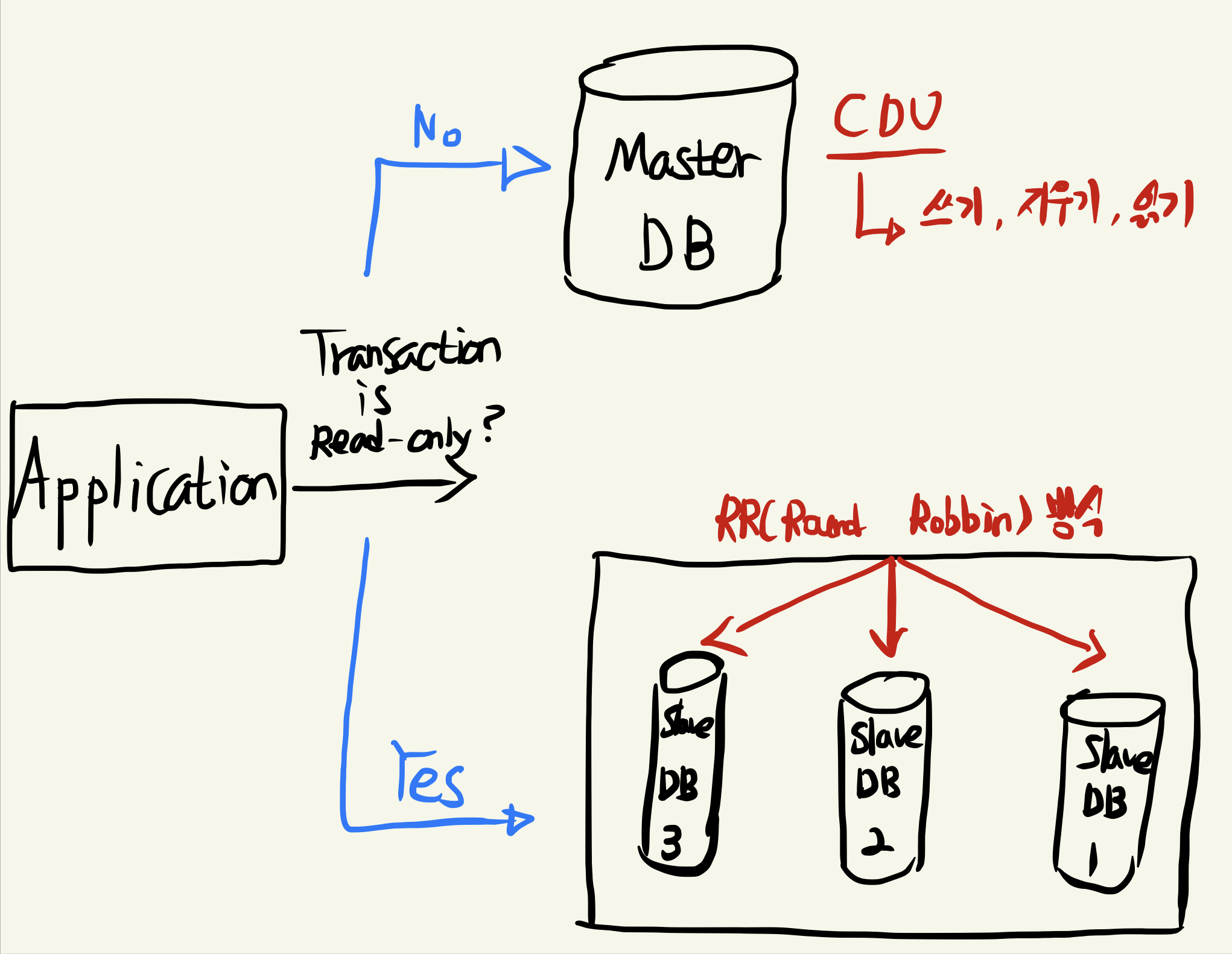
구조적인 부분에서는 현재 2대의 Slave DB를 수평적 확장을 통해 총 3대로 늘려서, 현재 3대의 Slave DB가 동작하는 상태입니다.
애플리케이션 내에서도 코드가 변경되어야 하는 부분이 생겼는데요.
그 이유는 기존에는 트랜잭션이 readOnly인지 확인하여 Master와 Slave 어디에 요청을 보낼지만 판단하면 되었습니다. 하지만 현재는 Slave DB가 3개있고 또 경우에 따라서 N개 까지 확장할 수 있습니다.
그렇다면 애플리케이션 내에서 RR(Round-Robin) 방식으로 균등하게 요청을 분산시켜줘야 하는 로직이 추가되어야 합니다.
어떻게 이런 문제를 해결할 수 있을까요?
😎 Spring Boot Application 구성하기
먼저 Spring Boot Application을 생성하고 설정클래스들을 작성하겠습니다.
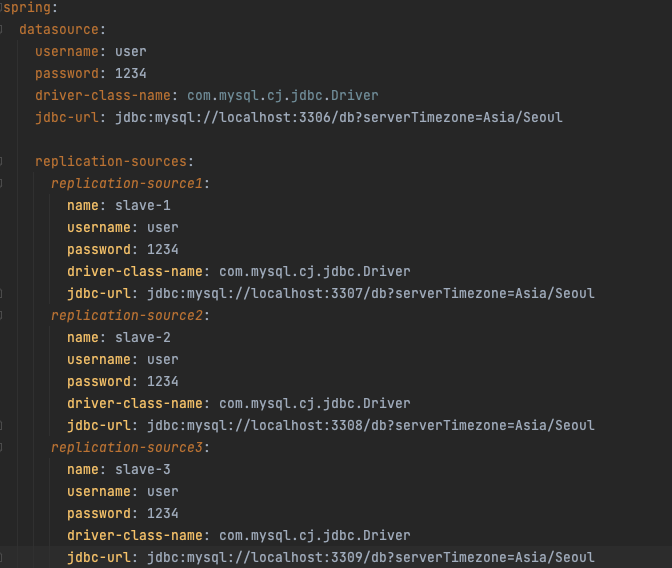
저는 docker-compose를 이용해 master db 1대와 slave db 3대를 동시에 컨테이너로 띄운 상태이고, MySQL Replication 설정에 대한 내용은 제 예전 게시글을 참고해주세요.
application.yml
DataSourceProperties
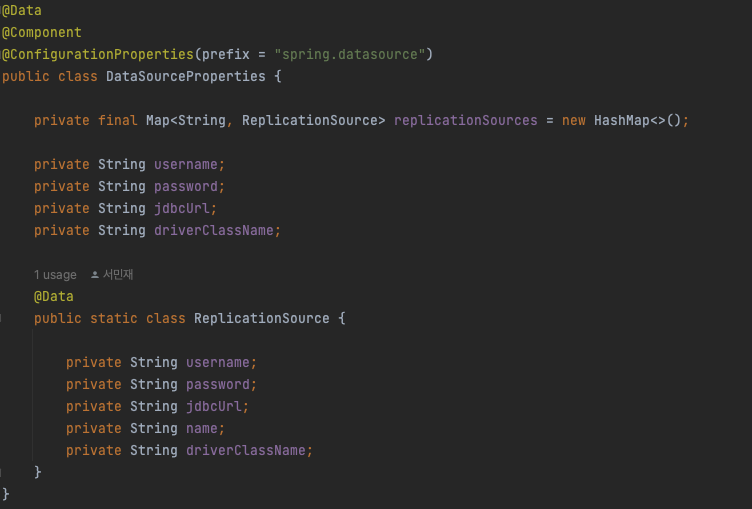
Map으로 선언된 replicationSources에 yml 파일에서 작성한 replication-source 1번부터 3번까지 모두 바인딩되게 됩니다.
ReplicaSourceNames
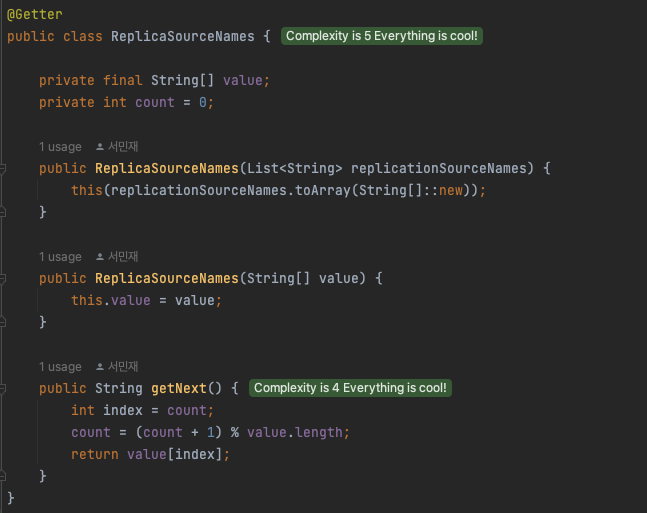
Replication 된 각 DB에 순차적으로 요청을 보낼 수 있도록 구현된 클래스입니다.
getNext 메서드는 내부에서 나머지 연산을 통해 0,1,2 순번대로 value 배열에 있는 Slave DB의 이름을 꺼내 반환하게 됩니다.
RoutingDataSource
@Slf4j
public class RoutingDataSource extends AbstractRoutingDataSource {
private ReplicaSourceNames replicaSourceNames;
@Override
public void setTargetDataSources(Map<Object, Object> targetDataSources) {
super.setTargetDataSources(targetDataSources);
List<String> replicationSources = targetDataSources.keySet().stream()
.map(Object::toString)
.filter(string -> string.contains("slave"))
.collect(Collectors.toList());
this.replicaSourceNames = new ReplicaSourceNames(replicationSources);
}
@Override
protected Object determineCurrentLookupKey() {
boolean isReadOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
if (isReadOnly) {
String sourceName = replicaSourceNames.getNext();
log.info("SourceName = {}", sourceName);
return sourceName;
}
return "master";
}
}
살펴봐야 할 부분을 뜯어서 살펴보겠습니다.

Map 형태로 넘어오는 targetDataSources에는 Master와 Slave 3개 총 4개의 DataSource들이 내부에 할당되어 있습니다.
여기서 slave1, slave2, slave3라는 이름을 가진 3대의 slaveDB를 번갈아가며 요청을 보내기 위해서, slave라는 키워드를 포함한 key들을 List에 저장해주고 ReplicationSourceNames 클래스에 넣어줍니다.
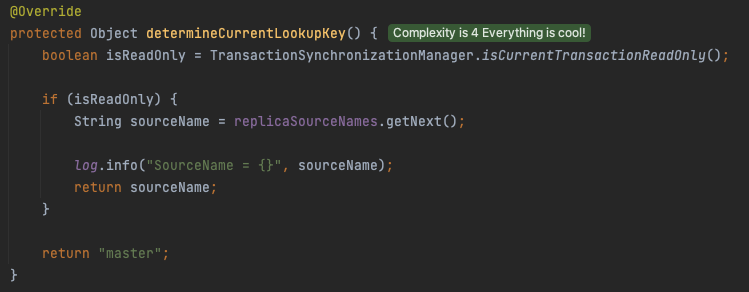
실질적인 분기처리를 해주는 로직인데, readOnly일때 getNext 메서드를 호출하여 0~2번까지 인덱스를 번갈아가면서 slaveDB를 호출하도록 구현되어 있습니다.
- 첫 번째 요청 -> slave1
- 두 번째 요청 -> slave2
- 세 번째 요청 -> slave3
- 네 번째 요청 -> slave1
...
이런 식으로 번갈아 가며 slaveDB 들에 요청을 보내는 로직입니다.
DataSourceConfiguration
@Configuration
@RequiredArgsConstructor
@EnableTransactionManagement
public class DataSourceConfiguration {
private final DataSourceProperties properties;
@Bean
public DataSource routingDataSource() {
DataSource masterSource = createDataSource(
properties.getUsername(),
properties.getPassword(),
properties.getJdbcUrl(),
properties.getDriverClassName()
);
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put("master", masterSource);
properties.getReplicationSources().forEach((key, value) ->
dataSourceMap.put(value.getName(), createDataSource(
value.getUsername(), value.getPassword(), value.getJdbcUrl(), value.getDriverClassName()
))
);
RoutingDataSource routingDataSource = new RoutingDataSource();
routingDataSource.setTargetDataSources(dataSourceMap);
routingDataSource.setDefaultTargetDataSource(masterSource);
return routingDataSource;
}
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactory() {
LocalContainerEntityManagerFactoryBean entityManagerFactoryBean =
new LocalContainerEntityManagerFactoryBean();
entityManagerFactoryBean.setDataSource(dataSource());
entityManagerFactoryBean.setPackagesToScan("replication.test");
entityManagerFactoryBean.setJpaVendorAdapter(jpaVendorAdapter());
entityManagerFactoryBean.setPersistenceUnitName("entityManager");
return entityManagerFactoryBean;
}
private JpaVendorAdapter jpaVendorAdapter() {
HibernateJpaVendorAdapter hibernateJpaVendorAdapter = new HibernateJpaVendorAdapter();
// DDL 생성 기능을 비활성화
hibernateJpaVendorAdapter.setGenerateDdl(false);
// SQL 쿼리를 로깅하지 않도록 설정
hibernateJpaVendorAdapter.setShowSql(false);
// SQL 방언을 MySQL 5 Inno DB 방언으로 설정
hibernateJpaVendorAdapter.setDatabasePlatform("org.hibernate.dialect.MySQL5InnoDBDialect");
return hibernateJpaVendorAdapter;
}
@Bean
@Primary
public DataSource dataSource() {
return new LazyConnectionDataSourceProxy(routingDataSource());
}
private DataSource createDataSource(String username, String password, String jdbcUrl, String driverClassName) {
return DataSourceBuilder.create()
.type(HikariDataSource.class)
.url(jdbcUrl)
.driverClassName(driverClassName)
.username(username)
.password(password)
.build();
}
@Bean
public PlatformTransactionManager transactionManager (
// 이름이 entityManager인 Bean을 주입받는다.
@Qualifier("entityManagerFactory") LocalContainerEntityManagerFactoryBean entityManagerFactory) {
JpaTransactionManager jpaTransactionManager = new JpaTransactionManager();
// 주입받은 entityManagerFactory의 객체를 설정한다 -> 트랜잭션 매니저가 올바른 엔티티 매니저 팩토리를 사용하여 트랜잭션을 관리할 수 있다.
jpaTransactionManager.setEntityManagerFactory(entityManagerFactory.getObject());
return jpaTransactionManager;
}
}
DataSourceConfiguration 클래스는 저번 게시글과 많이 달라진 부분이 없으니, 설명이 필요하신 분들은 이전 게시글 참고 부탁드립니다.
🙂 제대로 동작하는지 검증해보자!
slaveDB가 정말 요청을 번갈아가면서 잘 보내고 있는지 테스트코드 작성을 통해 검증해보겠습니다.
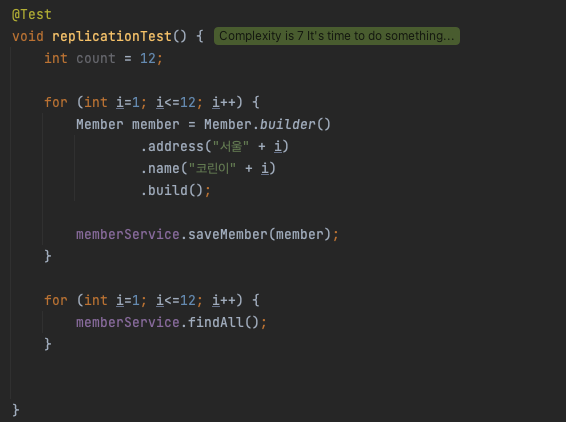
테스트 코드는 정말 간단하게 12번의 요청을 readOnly로 보내보겠습니다.
그렇다면 1번 ~ 3번 Slave DB가 균등하게 요청을 받아야 제대로 구성되었다고 할 수 있습니다.
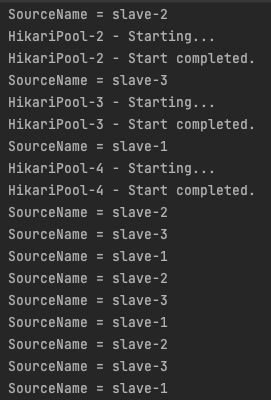
Slave DB를 번갈아가면서 균등하게 요청을 분산시키고 있는 것을 볼 수 있습니다.
ReplicaSourceNames에서 getNext 메서드를 호출하면 인덱스가 증가하고 시작하기 때문에 바로 2번 DB부터 호출되고 있지만 결과적으로 균등하게 요청이 분배되고 있습니다.
😲 다음으로..
Slave 확장을 통해 Master 장애시 Slave 승격을 통한 서비스 정상화를 기대할 수 있고, 한 대 뿐인 Slave의 장애시 읽기 작업이 불가능해지는 리스크를 개선하기 위해 이 작업을 진행했습니다.
생각해보니 수평적 확장 구조를 만든 것에 대한 이득은 이것뿐만이 아니라는 생각이 들었습니다.
천만번의 요청이 온다고 하면, 현재 Slave DB가 3대이므로 각 333만번 정도의 요청만 처리하면 되기 때문에 Slave DB의 부하도 많이 줄어들었습니다.
또한 코드 수정없이 yml 파일에 slaveDataSource에 대한 정보만 넣어주면, Slave를 N개까지 수평적 확장을 할 수 있게 되었습니다.
아직 Master와 Slave에 장애가 생기면 대응할 수 있는 시스템이 구축되지는 않은 상태입니다.
MHA에 대한 공부를 통해 Master 장애시 Slave를 승격하는 장애 복구 시스템과, Slave가 승격 또는 장애로 인해 사용할 수 없을경우 데이터소스 라우팅에서 제외 시킬 수 있는 방법에 대해 고민할 생각입니다.
오늘도 읽어주셔서 감사합니다
docker-compose 설정 파일들과, 코드가 필요하신 분들은 아래 저장소로 방문해주세요
-> repo로 이동

크...