강의 자료 출처: [CS224W Lecture 7]
1. A general Perspective on Graph Neural Networks
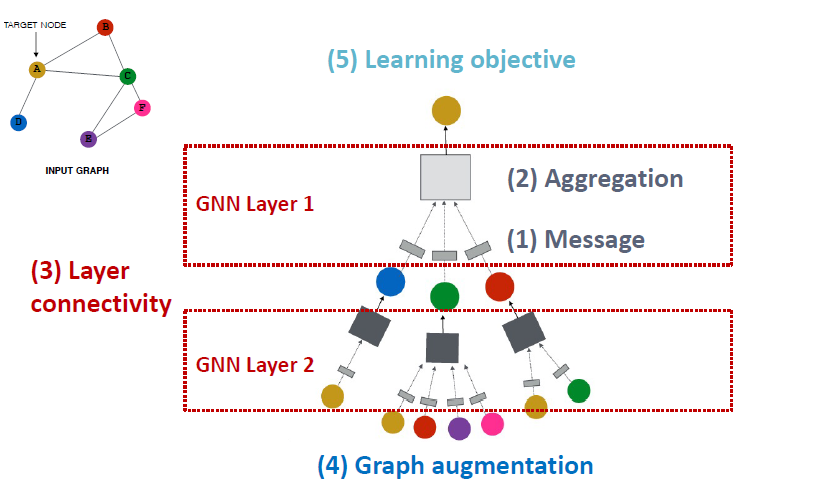
A general GNN Framework (1)
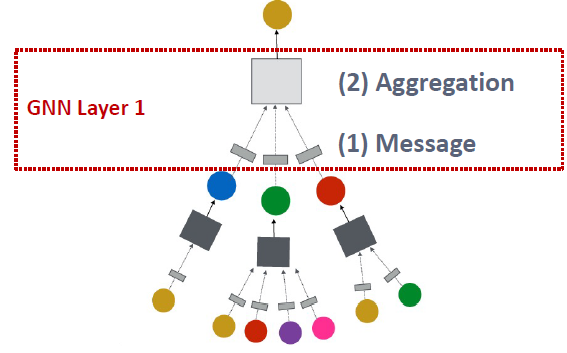
GNN Layer = Message + Aggregation
- 이 관점에서 다른 인스턴스화
- GCN, GraphSAGE, GAT, …
A general GNN Framework (2)
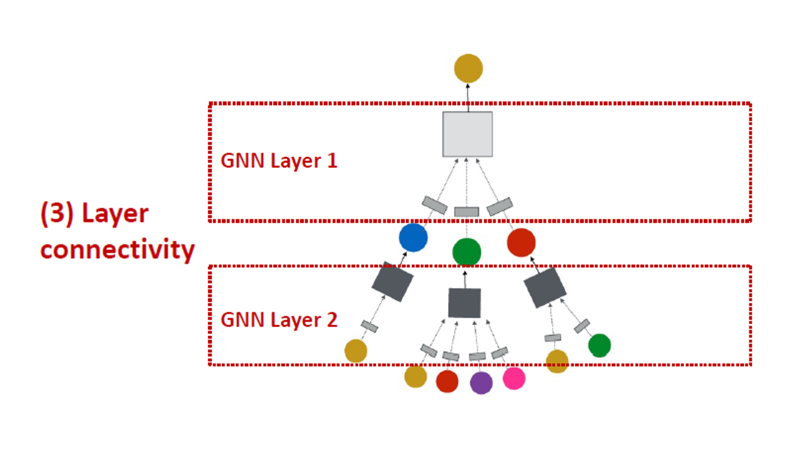
Connect GNN layers into a GNN
- Stack layers sequentially
- Ways of adding skip connections
A general GNN Framework (3)
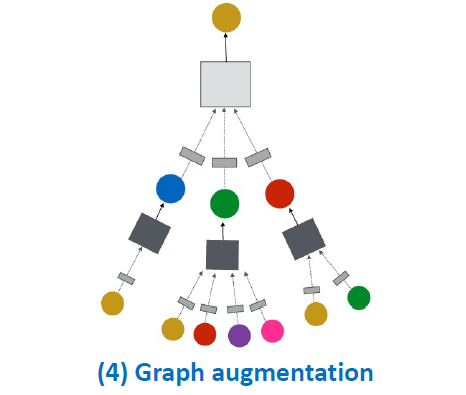
Idea: Raw input graph ≠ computational graph
- Graph feature augmentation
- Graph structure augmentation
A general GNN Framework (4)
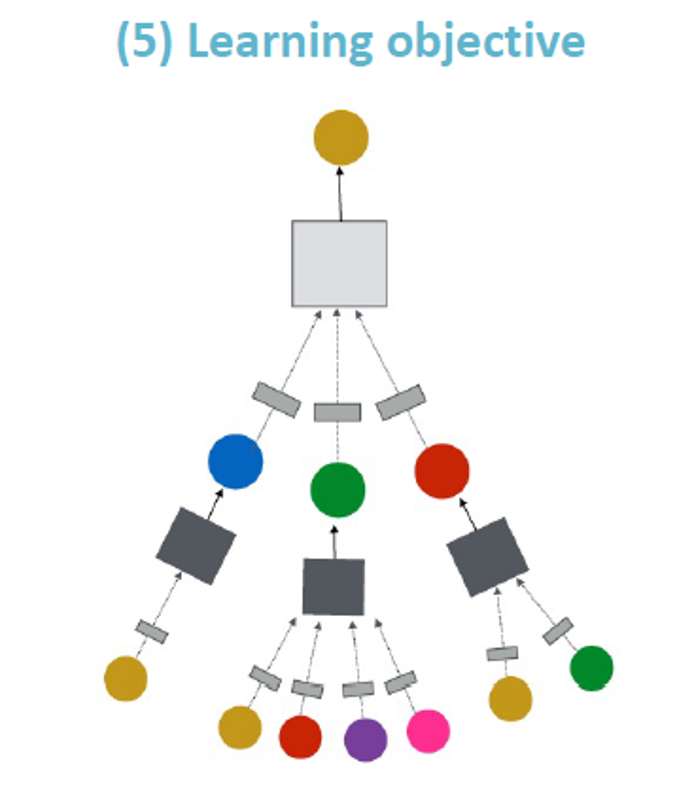
How do we train a GNN
- Supervised/Unsupervised objectives
- Node/Edge/Graph level objectives (We will discuss all of these later in class)
GNN Framework: Summary
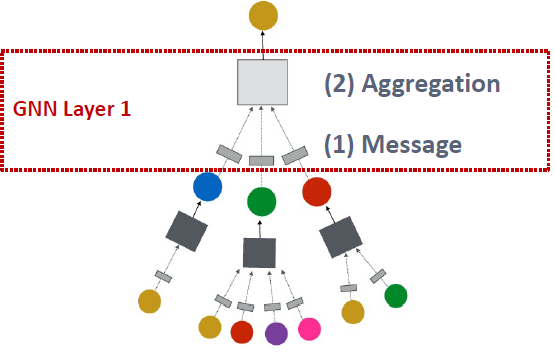
2. A single Layer of a GNN
A GNN layer
GNN Layer = Message + Aggregation
- 이 관점에서 다른 인스턴스화
- GCN, GraphSAGE, GAT, …
Idea of a GNN Layer:
- 벡터의 집합을 하나의 벡터로 압축합니다
- 두 단계 과정
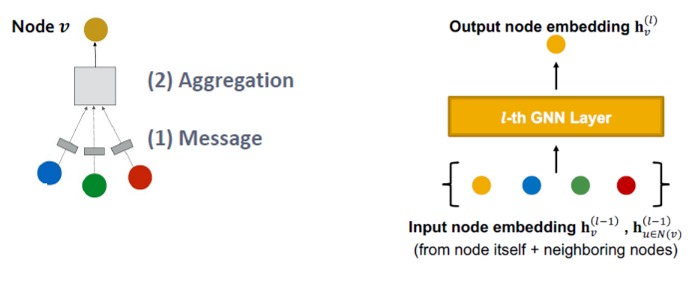
- (1) Message
- (2) Aggregation
즉, Message와 Aggregation이라는 두 스텝을 거쳐 벡터 집합을 single vector로 압축시킵니다.
Message Computation & Message Aggregation
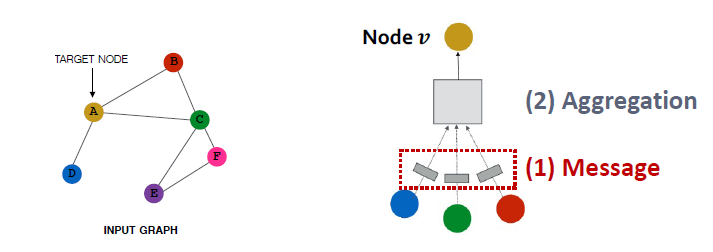
- Message function
- 이전 레이어의 정보가 message function을 통과해 현재 레이어의 정보가 됩니다.
- Example: 선형 레이어
- weight matrix 과 node featues를 곱합니다.
-
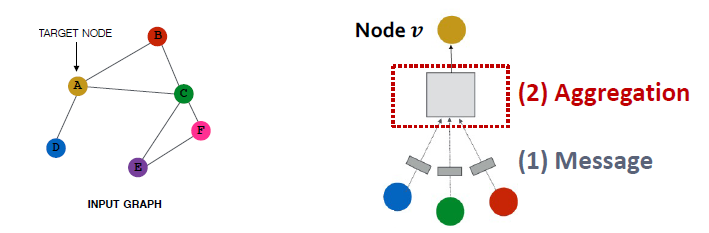
Agg<regation
- message function을 통해 변환된 정보를 종합하는 함수가 필요합니다.
- 이웃 노드 간에는 순서가 없으므로 평균, 최댓값 등과 같은 order invariant한 함수가 적합합니다.
-
Example: aggregator
-
Nonlinearlity
- 합쳐진 정보는 최종적으로 ReLU나 Sigmoid 같은 비선형 함수를 통과시킵니다.

Message Aggregation: Issue
문제점:
- 노드 자체의 정보가 손실될 수 있습니다.
- 의 계산이 에 직접적으로 의존하지 않습니다.
해결 방법:
- 을 계산할 때, 을 포함합니다.
(1) Message: 노드 𝒗 자체에서 메시지 계산
일반적으로 다른 메시지 계산이 수행됩니다.
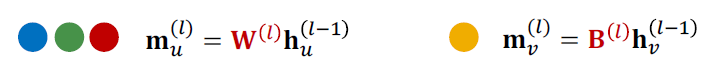
(2) Aggregation: concatenation과 summation을 통해서 이웃에서 집계한 후 노드 자체에서 메시지를 집계할 수 있습니다.
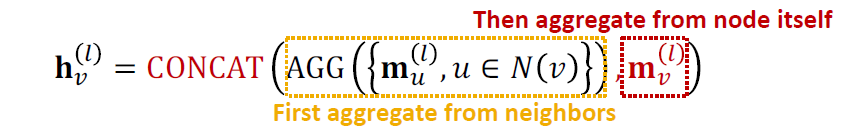
Classical GNN Layers: GCN (1)
(1) Graph Convolutional Networks (GCN)
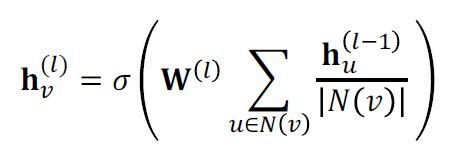
해당 식을 Message + Aggregation으로 다시 적는다면,
으로 표현합니다.
Classical GNN Layers: GCN (2)
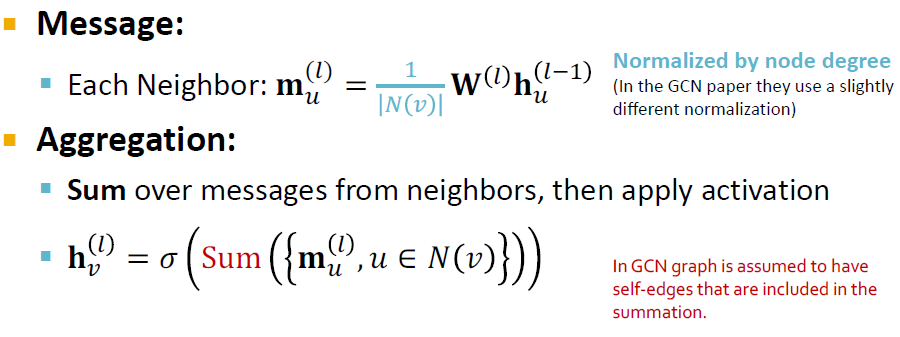
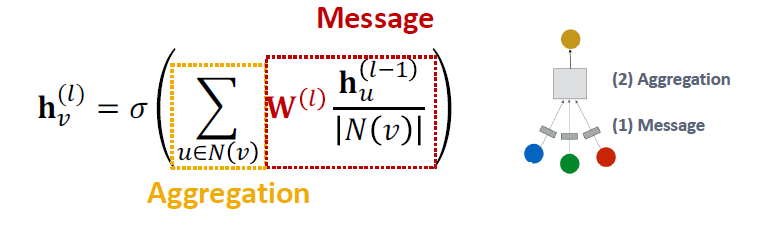
- Message는 중심노드의 degree로 normalization을 한 후 선형변환하며, Aggregation은 message transform을 거친 모든 이웃 노드들의 정보를 더합니다.
Classical GNN Layers: GraphSAGE
(2) GraphSAGE
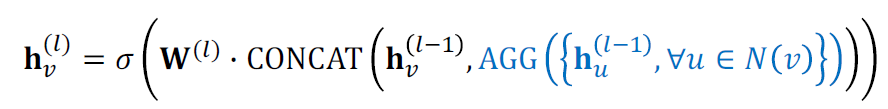
- 메시지는 AGG(⋅) 안에서 계산됩니다.
- 두 단계의 agrregation를 거칩니다.
- Stage 1: Aggregate from node neighbors
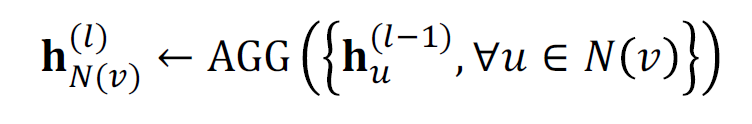
- Stage 2: Further aggregate over the node itself
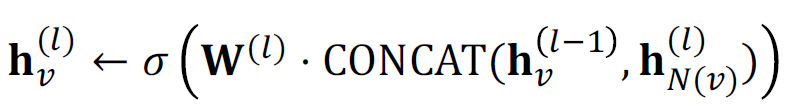
- 중심 노드와 주변 노드가 다르게 처리되는데, 중심 노드는 AGG 함수를 거쳐 계산되고, 이웃 노드와 Concatenation합니다.
GraphSAGE Neighbor Aggregation

- Aggregation 함수로는 mean, pool, LSTM 등이 있습니다.
GraphSAGE: L2 Normalization
- 각 레이어의 결과 에 norm을 취해서 정규화합니다.
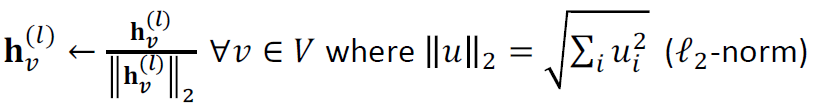
- 정규화가 없으면 임베딩 벡터는 벡터에 대해 서로 다른 스케일(ℓ'-norm)을 갖습니다.
- 경우에 따라(항상 그런 것은 아님) 임베딩 정규화가 성능 향상을 가져옵니다.
- 정규화 후 모든 벡터는 동일한 -norm을 갖습니다.
Classical GNN Layers: GAT
(3) Graph Attention Networks
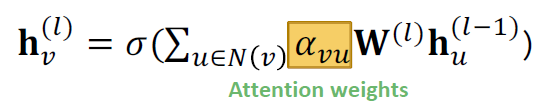
In GCN / GraphSAGE
- 는 노드 가 노드 로 가는 weighting factor (importance)입니다.
- 는 그래프의 구조적 특성에 기반하여 명시적으로 정의됩니다.
- 모든 이웃 는 노드 에 대하여 동등하게 중요합니다.
그러나 모든 노드의 이웃이 똑같이 중요한 것은 아닙니다. Attention은 cognitive attention에서 영감을 받습니다. attention 는 입력 데이터의 중요한 부분에 집중하고 나머지는 희미하게 만듭니다.
- 아이디어: NN은 작지만 중요한 데이터 부분에 더 많은 컴퓨팅 성능을 투입해야 합니다.
- 데이터의 어느 부분이 더 중요한지는 상황에 따라 다르며 훈련을 통해 학습됩니다.
Graph Attention Networks
- 단순한 neighborhood aggregation보다 더 나은지?
- weighting factor 을 학습할 수 있는지?
Goal:
그래프에서 각 노드의 서로 다른 이웃에 임의의 중요도 지정합니다.
Idea:
그래프의 각 노드 임베딩 을 attention strategy에 따라 연산
- 노드는 이웃의 메시지에 참석합니다.
- 이웃의 다른 노드에 다른 가중치를 암시적으로 지정합니다.
attention의 경우, 이웃 노드에 따라 중요도가 다르기 때문에 적용하게 됩니다.
Attention Mechanism
를 attention mechanism 의 byproduct로 계산합니다.
- (1) attention coefficients: 는 메시지에 따른 노드의 쌍 에 따라서 계산합니다.
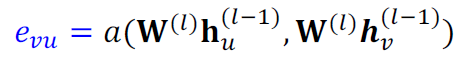
- 는 노드 에 대한 메시지의 중요성을 나타냅니다.
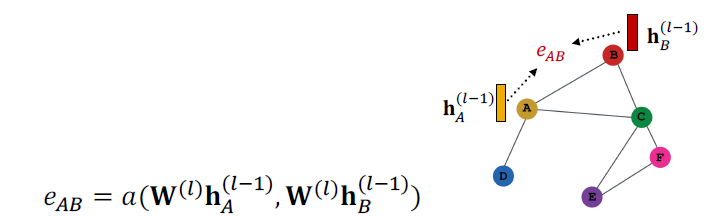
- (2) Normalizing: 마지막 attention 가중치 를 $e_{uv}*$로 정규화합니다.
- 여기선 소프트맥스를 취해서 얻을 수 있고, 이들의 합은 1입니다.
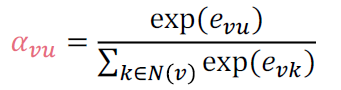
- (3) Weighted sum: 마지막 attention 가중치 를 합합니다.
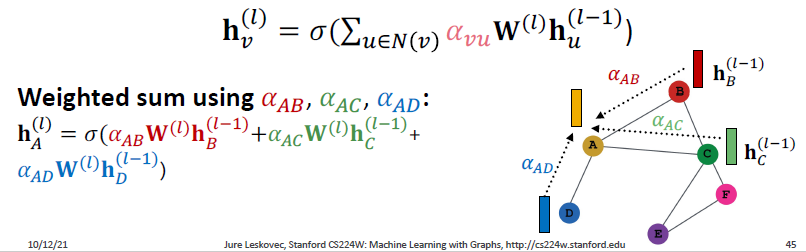
attention mechanism 의 형태는 어떻나요?
- 접근 방식은 의 선택에 구애받지 않습니다.
- 예를 들어 간단한 단일 계층 신경망을 사용합니다.
- 는 학습 가능한 매개변수(선형 레이어의 가중치)를 갖습니다.
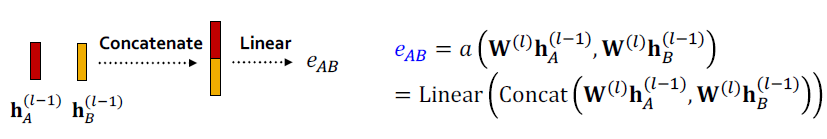
-
의 매개변수는 함께 학습됩니다.
-
가중치 행렬과 함께 end-to-end로 학습됩니다.
-
(4) Multi-head attention: attention mechanism에 따라 학습하며 안정됩니다.
-
multiple attention scores를 만듭니다. (매개변수 세트가 다른 각 복제본입니다.)
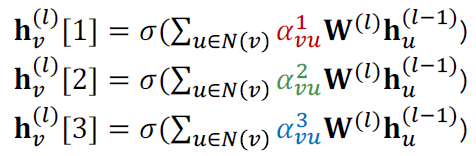
- Outputs are aggregated:
- concatenation 또는 summation에 의해 이루어집니다.
Benefits of Attention Mechanism
- Key benefit:
- 서로 다른 이웃에 대해 서로 다른 중요도 값()을 (암시적으로) 지정할 수 있습니다.
- Computationally efficient:
- attentional coefficients 계산은 그래프의 모든 가장자리에서 병렬화될 수 있습니다.
- Aggregation는 모든 노드에서 병렬화될 수 있습니다.
- Storage efficient:
- 희소 행렬 연산은 개 이상의 항목을 저장할 필요가 없습니다.
- 그래프 크기에 관계없이 고정 매개변수 수
- Localized:
- local network neighborhoods를 통해서만 attend됩니다.
- Inductive capability:
- 이것은 edge-wise mechanism으로 공유됩니다.
- global graph 구조에 의존하지 않습니다.
2. GNN Layers in Practice
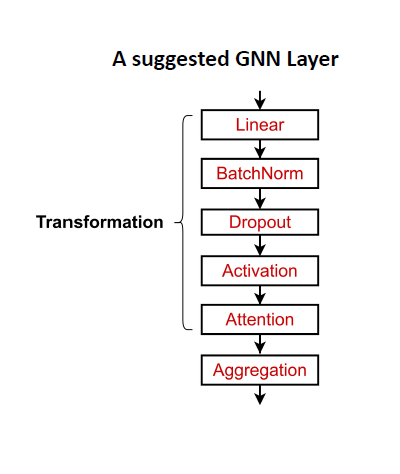
실제로 클래식한 GNN 레이어는 좋은 출발점이 있습니다.
- 일반적인 GNN 계층 설계를 고려하면 종종 더 나은 성능을 얻을 수 있습니다.
- 구체적으로 많은 영역에서 유용한 것으로 입증된 최신 딥 러닝 모듈을 포함할 수 있습니다.
많은 최신 딥러닝 모듈을 GNN 레이어에 통합할 수 있습니다.
- Batch Normalization:
- Stabilize neural network training
- Dropout:
- Prevent overfitting
- Attention/Gating:
- Control the importance of a message
- More:
- Any other useful deep learning modules
Batch Normalization
Goal:
Stabilize neural networks training
Idea:
Given a batch of inputs (node embeddings)
- 노드 임베딩을 0 평균으로 다시 중심화
- 분산을 단위 분산으로 재조정

Dropout
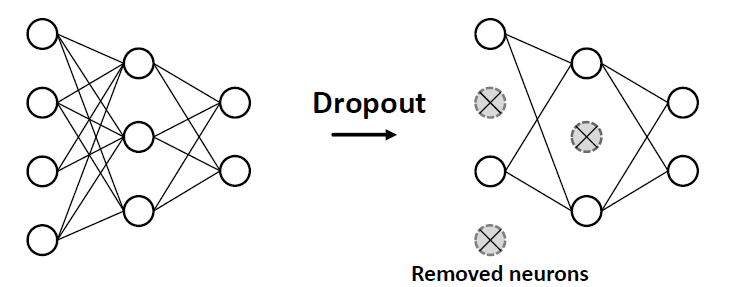
Goal:
과적합을 막기 위해 신경망을 정규화합니다.
Idea:
- During training: with some probability , randomly set neurons to zero (turn off)
- During testing: Use all the neurons for computation
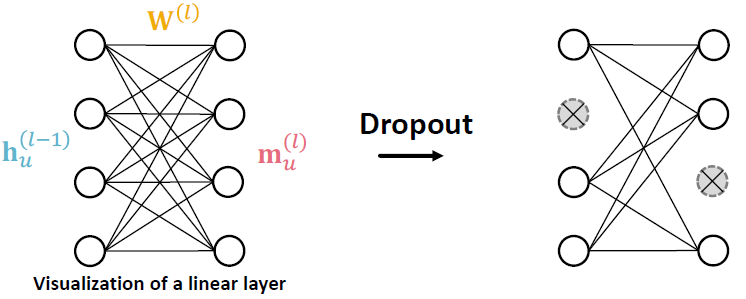
Dropout for GNNs
- GNN에서, Dropout은 메시지 함수에서 선형 레이어로 적용됩니다.
- 선형 레이러를 간단한 메시지 함수:
Activation (Non-linearity)
임베딩 번째 차원에 활성화 적용
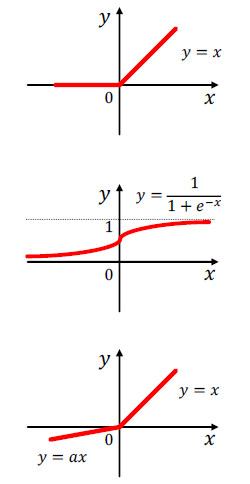
- Rectified linear unit (ReLU): 가장 흔하게 사용
- Sigmoid: 임베딩의 범위를 제한하고 싶을 때만 사용
- Parametric ReLU → PReLU() = max() + min()
- 는 학습 파라미터로 경험적으로 ReLU보다 좋을 때 사용됩니다.
GNN Layers in Practice
- 요약
- 현재 딥러닝 모듈은 GNN 레이어에서 더 좋은 성능을 포함합니다.
- 현재 디자인 된 GNN 레이어는 여전히 연구 중입니다.
- 제안 리소스: 다양한 GNN 디자인을 탐색하거나 GraphGym에서 자신의 아이디어를 시도할 수 있습니다.
3. Stacking Layers of a GNN
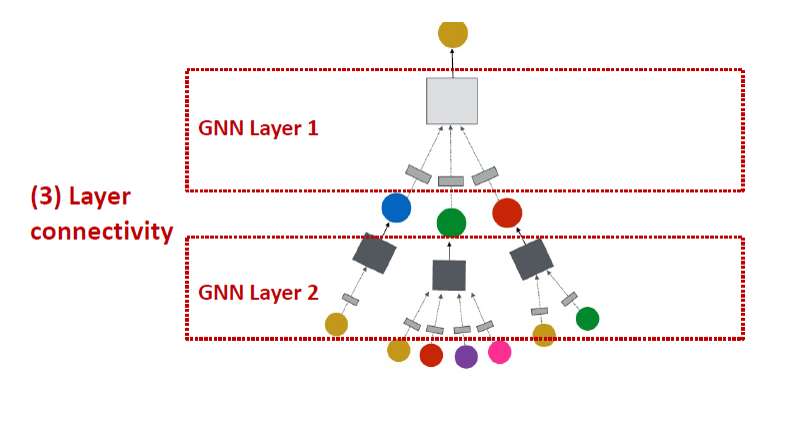
어떻게 GNN에서 GNN 레이어를 연결합니까?
- 레이어를 연속적으로 쌓습니다.
- skip connections을 더하는 방법
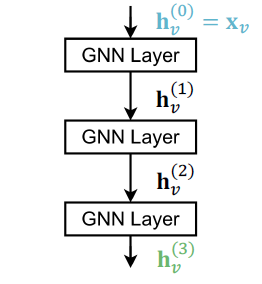
어떻게 GNN을 구성합니까?
- 표준 방법: GNN layer를 연속적으로 쌓습니다.
- 입력값: 초기 행 노드 feature
- 출력값: GNN 레이어 이후 노드 임베딩
The Over-smoothing Problem
- 많은 GNN 레이어를 쌓는 문제
- GNN은 과도한 스무딩 문제를 겪고 있습니다.
- Over-smoothing 문제: 모든 노드 임베딩이 동일한 값으로 수렴
- 노드 임베딩을 사용하여 노드를 구별하기 때문에 이는 좋지 않습니다.
- 과도한 스무딩 문제가 발생하는 이유는 무엇입니까?
Receptive Filed of a GNN
Receptive Filed: 노드가 흥미 있는 임베딩을 결정 짓는 노드의 집합
- k-레이어의 GNN에서 각 노드는 K-hop 이웃의 수용 영역을 가집니다.
- GNN에서의 깊은 레이어는 중심노드에서 더 많은 hop의 정보를 가져오는 것을 의미합니다.
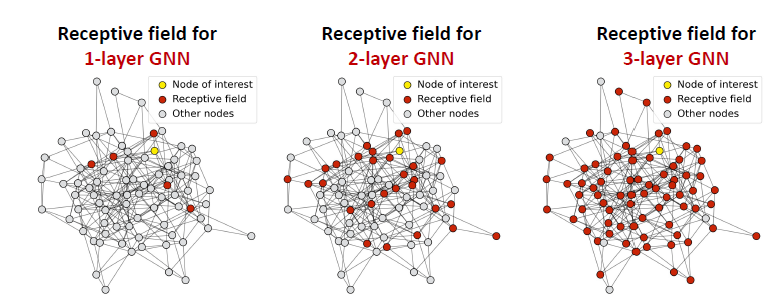
- 수용 필드의 개념을 통해 over-smoothing를 설명할 수 있습니다.
- Hop의 수가 늘어나면 overlap되는 receptive field가 빠르게 증가합니다.
- 우리는 노드의 임베딩이 수용 필드에 의해 결정된다는 것을 알고 있습니다.
- 두 노드에 고도로 중첩된 수용 필드가 있는 경우 임베딩이 매우 유사합니다.
- 많은 GNN 레이어를 쌓음 → 노드는 고도로 중첩된 수용 필드를 갖습니다. → 노드 임베딩은 매우 유사하고 → 오버 스무딩 문제로 인해 어려움을 겪습니다.
- over-smoothing problem: GNN 레이어를 깊게 쌓으며 모든 노드 임베딩이 같은 값으로 수렴하는 현상
- Next: 과도한 스무딩 문제를 어떻게 극복합니까?
Expressive Power for Shallow GNNs
더 많이 표현하는 얕은 GNN을 어떻게 만듭니까?
- Solution 1: 각 GNN 레이어를 포함하는 표현력을 높입니다.
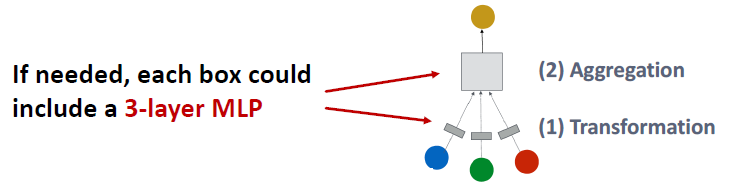
- 이전의 예시에서 각 트랜스포머나 집계 함수는 오직 하나의 선형 레이어만 포함했습니다.
- 집계와 트랜스포머가 깊은 신경망이 되도록 만듭니다.
- Solution 2: 메시지를 전달하지 않는 레이어를 더합니다.

- GNN은 GNN 레이어를 더이상 포함하는 것을 필요로 하지 않습니다.
- 예를 들어, 사전 처리 레이어 및 사후 처리 레이어로 GNN 레이어 전후에 MLP 레이어(각 노드에 적용됨)를 추가할 수 있습니다.
Design GNN Layer Connectivity
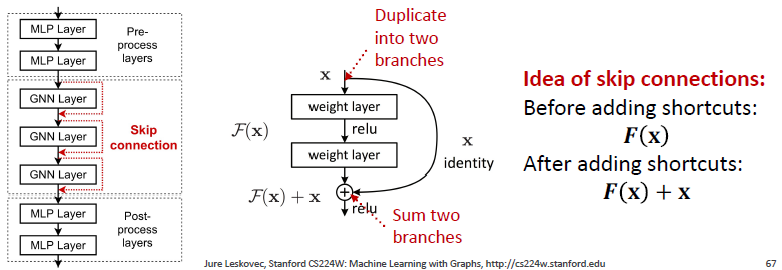
여전히 많은 GNN 레이어가 필요한 경우 어떻게 합니까? GNN에서 skip connection 추가합니다.
- Over-smoothing에서 관찰: 이전 GNN 레이어의 노드 임베딩은 때때로 노드를 더 잘 구별할 수 있습니다.
- 솔루션: GNN에 바로 가기를 추가하여 최종 노드 임베딩에 대한 이전 레이어의 영향을 높일 수 있습니다.
Idea of Skip Connections
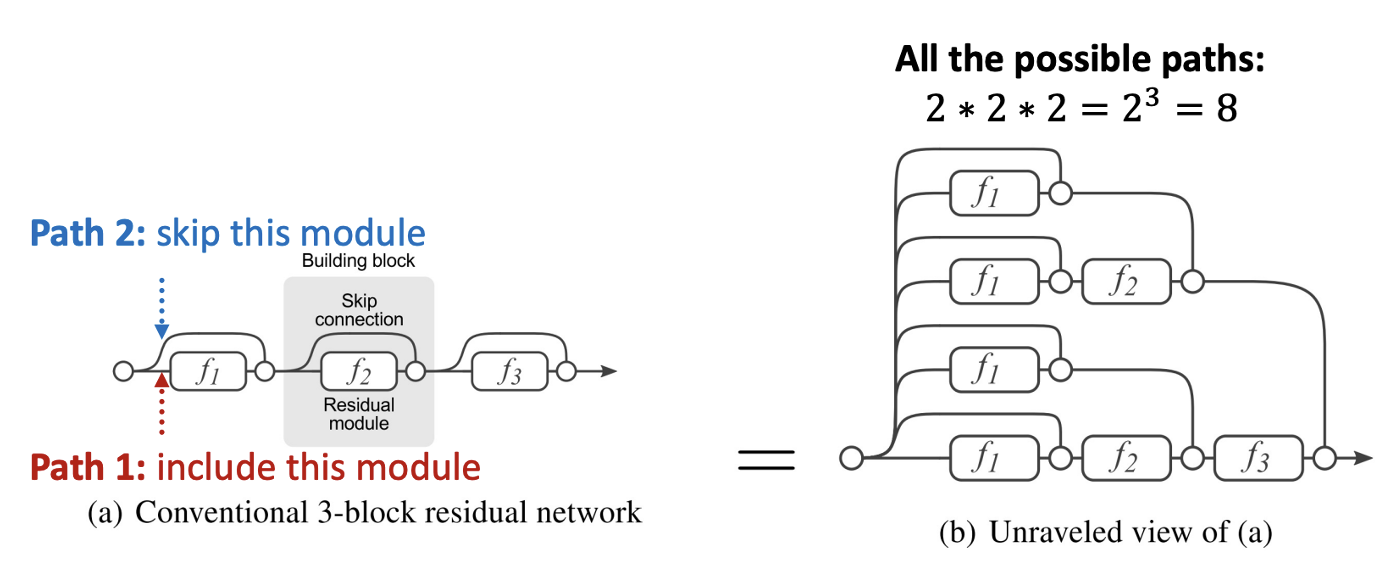
왜 skip connections을 수행합니까?
- 이전에 레이어를 적게 쌓아 over-smoothing 문제를 해결했지만 모델의 표현력이 떨어집니다. 따라서 GNN layer를 깊게 쌓으려고 skip connection을 활용합니다.
- N개의 skip connection을 쓰면 개의 paths가 만들어집니다.
- 적은 레이어만 통과하는 shallow model처럼 작동하며, 많은 레이어를 통과하여 깊은 모델처럼 작동하기도 합니다.
Example: GCN with Skip Connections
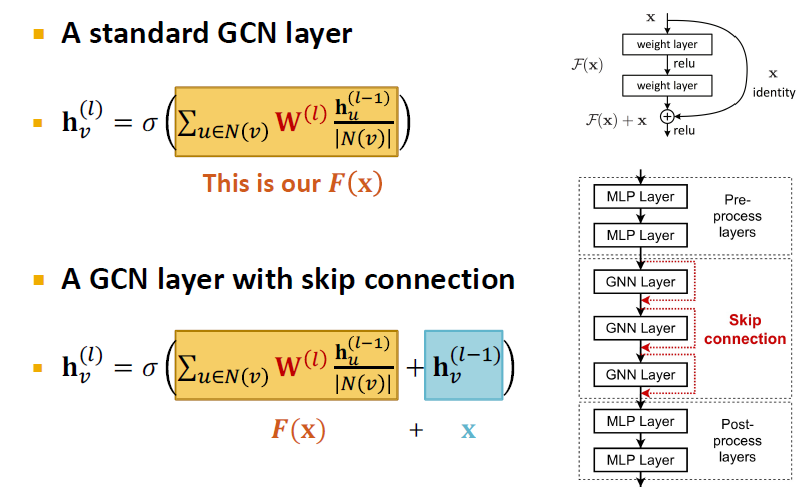
Other Options of Skip Connections
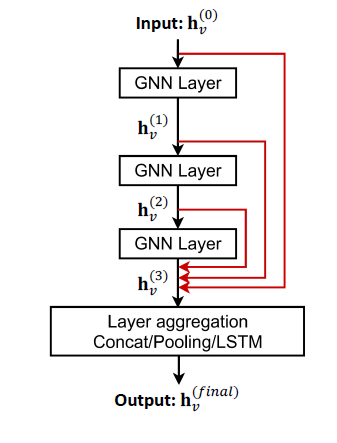
- Other options: 마지막 레이어로 직접 건너뛰기
- 최종 레이어는 이전 레이어의 모든 노드 임베딩에서 직접 집계됩니다.
