
Abstract
- Keyword: only single text condition, patch-wise text-image matching loss, CLIP(pre-trained text-image embedding model)
원래 존재하는 스타일 트랜스퍼 방법은 스타일 이미지의 정보를 콘텐츠 이미지로 바꾸기 위한 참고 스타일 이미지가 필요하다.
우리의 프레임워크는 이 스타일 이미지 없이 스타일을 원하는 스타일의 텍스트 설명만으로 가능하다.
CLIP의 사전 훈련된 text-image 임베딩 모델을 사용해서 오로지 single text condition만으로 콘텐츠 이미지의 스타일을 조정하는 것을 증명한다.
특별히 우리는 사실적인 텍스쳐 전송을 위한 다양한 관점의 증강을 하는 patch-wise text-image matching loss를 제안한다.
이 광범위한 실험 결과는 시맨틱 쿼리 텍스트를 반영하는 사실적인 텍스처와 함께 이미지 스타일 전송의 성공적인 모습을 확인할 수 있다.
1. Introduction
기존 neural style transfer의 방법과 한계를 짚고, 클립을 사용하여 텍스트 조건만으로 시맨틱 텍스처를 전달하는 새로운 이미지 스타일 트랜스퍼를 제안함. 거기에 사용된 방법을 간단히 소개하였음
Style transfer aims to transform a content image by transferring the semantic texture of a style image.
Neural style transfer
- Require a reference style image
- pre-trained VGG network
- style loss that matches the Gram matrices of the content and style features
- 한계:
- ‘imitiating’ the texture of the style images
- 임베딩 모델의 성능 한계로 인해 의미가 제대로 반영되지 않는 단점
- 사전 훈련된 생성 모델에 크게 의존하여 특정 콘텐츠 도메인(예: 사람 얼굴)으로 제한되기도 함
따라서 클립을 사용하여 텍스트 조건의 semantic texture를 전달하는 새로운 이미지 스타일 트랜스퍼를 제안
- AdaIN처럼 픽셀 최적화에 의존하거나 인스턴스 정규화 계층을 조작하는 대신, 텍스트 조건에 대한 텍스처 정보를 표현하고 사실적이고 다채로운 결과를 생성할 수 있는 경량 CNN 네트워크를 훈련함
- 콘텐츠 이미지는 전송된 이미지의 CLIP 모델 출력과 텍스트 조건 간의 유사도를 일치시켜 텍스트 조건을 따르도록 경량 CNN에 의해 변함
- 네트워크가 여러 콘텐츠 이미지에 대해 훈련될 때 콘텐츠 이미지에 관계없이 텍스트 기반 스타일 전송을 가능하게 함
Method
- Patch-wise CLIP loss
- loss 계산 후에 첫 번째 샘플 패치를 다른 관점 뷰에 적용하는 증강을 적용
- query text condition과 processed patches 사이의 유사도를 계산해서 CLIP loss를 얻음
- 이를 통해 콘텐츠 이미지의 각 영역에 스타일을 전송할 수 있음
- 증강은 더 선명하고 다양하게 유도
- patch-dependent over-stylization problem ← a novel threshold regualarization (비정상적으로 높은 점수를 가진 패치가 네트워크 훈련에 영향을 미치지 않도록)
2. Related Works
2.1. Style Transfer
Gatys et al. [7]의 iterative pixel-optimization을 참고하여, content와 style losses를 동시에 최소화하는 feed-forward network를 학습시키는 Johnson et al. [10]과 Ulyanov et al. [24]에 의해 제안됨
이후 Li et al. [16, 17]은 single-content style transfer 방법을 확장하여, content features를 style features의 통계를 따르도록 변환하는 Whitening and Coloring Transform (WCT) 방법을 제안
Huang et al. [9]은 Adaptive Instance Normalization (AdaIN)을 제안하여, style image features의 평균과 표준편차가 content image features의 정규화된 feature statistics에 적용되도록 함
2.2. Text-guided synthesis
2.2. Text-guided synthesis은 기존의 text-guided image synthesis에서, text embedding을 위한 encoders가 generative models의 guide 조건으로 작동함
Zhang et al. [28, 29]은 고화질 이미지 합성을 위해 다중 스케일 생성 모델에 텍스트 조건을 통합시킴
AttnGAN [25]은 텍스트와 이미지 feature에 대한 attention mechanism으로 성능을 개선
ManiGAN [14]은 동시에 text와 image features를 embedding하기 위한 모듈을 제안
Method
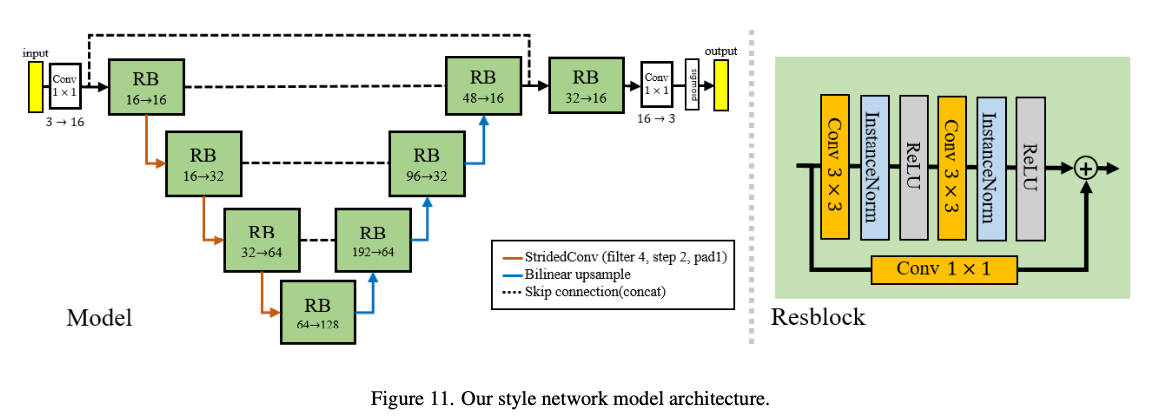
3.1. Basic framework of CLIPstyler
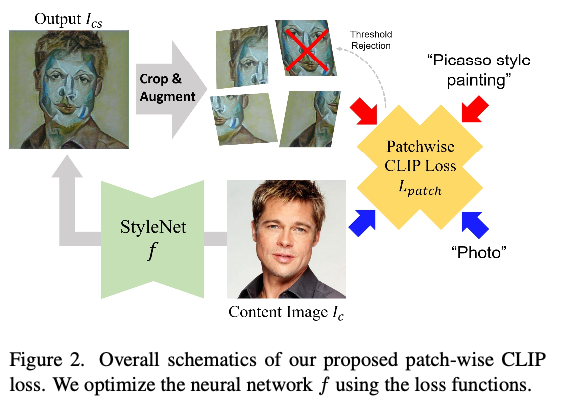
Purpose
To transfer the semantic style of target text to the content image through the pre-trained text-image embedding model CLIP
→ 기존 방법과의 주요한 차이는 레퍼런스로 사용할 스타일 이미지 가 없다는 것
우리의 목표는 CLIP의 단독 지도로 의미적으로 변환된 이미지를 얻는 것이므로, 우리는 해결해야 할 몇 가지 기술적 문제가 있다.
- CLIP model에서 어떻게 semantic ‘texture’를 추출하고, 콘텐트 이미지에 텍스처를 적용할 것인지
- 출력 이미지가 질적으로 손상되지 않도록 훈련을 정규화하는 것
아키텍처 설명
- 콘텐트 이미지 가 주어질 때, 우리는 스타일 트랜스퍼 출력 를 얻고자 함
- 원하는 텍스처는 우리가 전통적인 픽셀 최적화 방법을 사용할 때 반영되지 않음
- 이 문제를 해결하기 위해 제안 → CNN encoder-decoder model : 콘텐트 이미지의 hierarchical(계층적) visual feature를 포착하고 동시에 사실적인 텍스처 표현을 얻기 위해 deep feature space에서 이미지를 동시에 스타일화함
- 그러므로 우리의 스타일화된 이미지 는 이고, 최종적인 목표는 출력 이미지가 target texutre를 갖도록 의 파라미터를 최적화하는 것임
- 부가설명: 이 논문에서 "대상 텍스처"는 우리가 조건으로 넣어주는 텍스트를 의미. 입력하는 텍스트는 대상 도메인을 설명하는 조건부로 볼 수 있음. 따라서, CLIPstyler는 입력된 텍스트에 따라 이미지의 스타일을 변환하여 대상 도메인에 맞게 출력함
3.2. Loss function
- CLIP loss
- To guide the content image to follow the semantic of target text
- To minimize the global clip loss function
- : CLIP-space cosine distance
- transform the output image of the whole frame to follow the semantic of the textual condition
- 그러나 이 global CLIP loss를 사용할 때, 출력물의 질이 망가지기도 하고 최적화 과정의 안정성이 낮음
- 이 문제를 해결하기 위해 StyleGAN-NADA가 directional CLIP loss를 제안하였음
- A directional CLIP loss that aligns the CLIP-space direction between the text-image pairs of source and output.
- 따라서 이 directional CLIP loss도 사용함
- : image encoder of CLIP
- : text encoder of CLIP
- : semantic text of the style target
- : semantic text of the input content (콘텐트에 자연 이미지를 사용할 경우, 단순히 “Photo”로 설정됨
- : the content image
- : the style image
- : CNN encoder-decoder model (스타일화함)
이 손실 함수는 생성된 이미지와 원본 이미지 간의 CLIP 공간 코사인 거리를 계산하고, 이 거리를 최소화하는 방향으로 매개변수를 업데이트함
이렇게 함으로써, 생성된 이미지가 원본 이미지와 유사한 시맨틱 정보를 보존하면서도 대상 텍스트에 따라 스타일을 변환할 수 있음
- PatchCLIP loss
는 좋은 성능을 보여주지만, 우리에게 완벽히 맞지는 않은 손실함수이다. 그 이유는 우리의 목표는 의 semantic texture를 주어진 콘텐트 이미지에 적용하는 것이기 때문임.
CLIP loss들의 단점을 극복하기 위해 텍스처 전송을 위한 PatchCLIP loss를 제안함
- A directional CLIP loss directional CLIP loss는 StyleGAN-NADA [6]에서 제안된 방법으로, 텍스트-이미지 쌍의 CLIP 공간 방향을 정렬하는 방식으로 작동합니다. 이를 통해 생성된 이미지가 텍스트 조건과 더 일치하도록 유도합니다. 따라서 CLIPstyler에서는 global CLIP loss와 함께 directional CLIP loss를 사용하여 이미지 생성을 수행함
- PatchCLIP loss 이미지 생성 과정에서 전체 이미지 대신 이미지의 패치(patch)를 사용하여 손실을 계산하는 방식입니다. 이를 통해 생성된 이미지가 브러시 스트로크와 같은 지역적인 스타일 변화를 보이도록 유도합니다. 이 논문에서는 global CLIP loss와 함께 PatchCLIP loss를 사용하여 이미지 생성을 수행하며, 이를 통해 생성된 이미지의 질과 안정성이 향상되었다고 주장하고 있음
- PatchCLIP loss와 directional CLIP loss는 이미지 생성 과정에서 지역적인 스타일 변화를 유도하기 위해 사용되고, global CLIP loss는 전체 이미지가 텍스트 조건과 일치하도록 유도하기 위해 사용
- Threshold rejection
패치 샘플링 및 증강으로 인한 stochastic randomness(확률적 무작위성) 때문에 이 방법은 스타일 네트워크 가 손실 점수를 최소화하기 위해 쉬운 특정 패치에 지나치게 최적화하는 과도한 스타일화로 어려움을 겪음
이 문제를 완화하기 위하여
→ 높은 점수의 패치에 gradient optimization을 거부하는 정규화 추가. 임계점 값 가 주어졌을 때, 우리는 단순히 해당 패티에서 계산된 loss를 무효화함
- : -th cropped patch from the output image
- : random perspective augmentation
- : threshold function
정리
스타일 네트워크가 손실 함수를 최소화하는 데에 있어서 쉬운 패치들에만 집중하여 과도한 스타일화가 발생하는 것을 방지하기 위해 사용됩니다.
Threshold rejection에서는 임계값 τ를 설정하고, 해당 임계값보다 높은 점수를 받은 패치들의 손실을 0으로 만듭니다. 이렇게 함으로써, 스타일 네트워크가 어려운 패치들에 대해서도 균형적으로 학습할 수 있게 됩니다.
이 논문에서는 Threshold rejection을 위해 추가적인 로스 함수를 사용하지 않습니다. 대신, 기존의 로스 함수들과 함께 Threshold rejection을 적용하여 최종 total loss function을 구성합니다.
- Total loss
4 different losses
- Standard directional CLIP loss to modulate the whole part of the content image
- PatchCLIP loss for local texture stylization
- content loss 입력 이미지의 콘텐츠 정보를 유지하기 위해 사용
- 스타일 네트워크가 입력 이미지의 콘텐츠 정보를 유지하면서도 스타일을 적용할 수 있게함
- CLIP 손실 함수 위에 입력 이미지의 콘텐츠 정보를 유지하기 위해 콘텐츠의 특징과 사전 훈련된 VGG-19 네트워크에서 추출한 출력 이미지 간의 평균 제곱 오차(mean-square error)를 계산하여 콘텐츠 손실 Lc를 포함
: directional CLIP loss
: PatchCLIP loss
: content loss
: total variation regularization loss
- total variation regularization loss 이 로스 함수는 이미지 생성 과정에서 생기는 불규칙한 픽셀들로 인한 부작용을 완화하기 위해 사용됨
4. Results
4.1. Experiment settings
-
데이터셋: COCO-Stuff dataset과 WikiArt dataset을 사용
-
모델 아키텍처: 스타일 네트워크로서 U-Net 구조를 사용
- sigmoid function at the last layer of
- Adam optimizer with learning rate of 5 × 10−4
- total training iteration is set as 200
- learning rate to half at the iteration of 100
- 하이퍼파라미터 값: λd=1, λp=0.5, λc=5, λtv=0.01으로 설정
-
patch cropping
- patch size of 128
- total number of cropped patches is set as n = 64
-
Augmentation
- PyTorch library
-
Threshold rejection
- : 0.7
-
텍스트 임베딩의 노이즈를 줄이기 위해 Radford et al.이 제안한 프롬프트 엔지니어링 기법을 사용
-
구체적으로, 우리는 동일한 의미를 가진 여러 텍스트를 만들어 텍스트 인코더에 공급
-
그 다음 원본 단일 텍스트 조건 대신 평균 임베딩을 사용
4.2. Qualitative evaluations


정성적 결과는 figure 1과 3으로 확인할 수 있음
- 텍스트 조건으로 이미지 스타일을 성공적으로 변환할 수 있었음
- 이미지의 콘텐트를 변경하지 않고(유지하면서) 텍스트 조건과 일치하는 스타일을 적용할 수 있었음
- 텍스트 조건을 통해 텍스처 유형 뿐만 아니라 각 스타일의 세부 조건도 제어 가능
- 색상에 대한 추가 조건도 제공 가능(”white”, “green”)
- 텍스처로 사용할 객체의 종류도 선택 가능(”oil painting”, “flower”)
4.3. Comparison with baselines
Comparison with existing style transfer
- CLIP 모델은 예술적 이미지 뿐만 아니라 다양한 범위의 자연 이미지로 훈련되어 해당하는 텍스트 조건과 함께 스타일 전이가 가능함
- AdaAttn [18], SANet [19], CST [23], AdaIN [9] 및 픽셀 최적화[7]의 baseline 사용

- 텍스트 조건만 사용하고서도 스타일 트랜스퍼와 비슷한 결과를 보여주고 있다
- 예전의 방법은 색상 변화에만 집중하여 변화시키는 반면, 최신의 방법들은 콘텐츠 이미지의 구조를 보존하면서 복잡한 텍스처 정보를 갖는 것을 확인할 수 있음
- 우리의 결과는 선명한 텍스처 패턴을 갖고 있으면서, 원래의 콘텐트 이미지의 유형과 구조의 손상을 배제하였음
- 마지막 4행을 통해 예술 작품이 아닌 결과를 비교해보면, 다른 베이스라인 같은 경우에는 대부분 작품에 의해 사전 훈련되었기 때문에 비예술적 스타일 텍스처 전이에 어려움이 있으나, 우리의 방법은 쿼리 텍스트에서 의미적인 텍스처를 성공적으로 추출하여 콘텐트 이미지에 적용함
Comparison with text-guided manipulation models

-
베이스라인 모델은 CLIP 모델과 사전 훈련된 StyleGAN을 사용
-
우리의 방법은 콘텐트에 초점을 맞추어 전체 이미지에 대한 스타일을 적용. 콘텐트 이미지에 대한 사실적인 텍스처를 표현하고, 쿼리 텍스트 조건에 매치됨
-
StyleGAN-NADA는 텍스처에 초점을 맞춰서 텍스트 조건에 맞게 일부분만 변경하는 방식, 텍스트 조건의 의미를 완전히 반영하지 못하는 결과
-
Style-CLIP는 학습된 잠재 도메인 내에서 이미지를 조작할 수 있지만, 세 번째 줄을 제외한 대부분의 결과는 이미지를 변형하지 못합니다.
-
우리의 방법은 CLIP 손실을 사용한 네트워크 가중치 최적화(또는 미세 조정)를 기반으로 하기 때문에 CLIP 손실과 결합하여 더 나은 스타일 전이를 얻을 수 있는지 조사하였음
- CLIP 손실과 픽셀 최적화 결합
- 스타일 트랜스퍼 네트워크에서 CLIP 손실을 사용하여 AdaIN 코드 최적화만 사용
- VQGAN-CLIP의 소스 코드를 사용하여 CLIP-loss를 사용하여 사전 훈련된 VQGAN [4]의 잠재 코드 최적화와 비교

- 그림 7의 결과는 우리가 네트워크 를 최적화하는 방법이 기준 모델에 비해 우수한 품질을 달성한다는 것을 보여주고 있음
- VQGAN+CLIP 및 AdaIN+CLIP은 내용에 텍스처를 적용하지만 콘텐트 구조가 심각하게 저하됨
- 픽셀 최적화는 텍스트 조건의 의미를 반영하지 못함
- 부록 자료에서는 다른 기준 모델과의 추가 비교 결과를 제공
4.4. Ablation studies
loss를 하나씩 빼가는 방식으로 비교 연구를 진행하였음
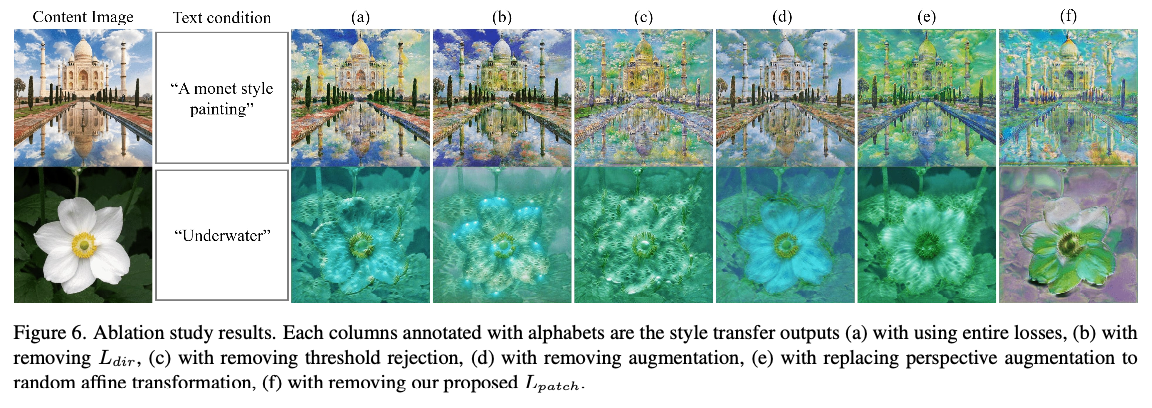
(a) with using entire losses,
(b) with removing ,
(c) with removing threshold rejection,
(d) with removing augmentation,
(e) with replacing perspective augmentation to random affine transformation,
(f) with removing our proposed
(a)가 가장 우수한 결과
- 3차원 텍스처와 색상 면에서 artifact 없이 깨끗한 이미지 얻음
(b)를 사용하지 않는 경우, global semantic을 포착할 수 없어 색상이 불규칙한 패턴으로 매핑
(c) 임계값 거부를 제거할 경우, 이미지가 특정 패치에 초점을 맞추어 지나치게 스타일화된 이미지가 생성
(d) 증강을 사용하지 않는 경우, 3차원 실제적인 텍스처가 반영되지 않음
(e) perspective augmentation 대신 아핀 변형을 사용할 경우, 원하지 않는 artifact가 발생
(f) 전체 이미지에 대한 손실함수인 방향성 CLIP loss만 사용할 경우, 색상을 제외한 질감에 거의 변화가 없음
5. Further Extensions
5.1. Fast style transfer
우리의 디폴트 프레임워크는 하나의 콘텐트 이미지를 주어진 스타일에 적용할 수 있는 스타일 네트워크 를 학습시켜야 함
이를 극복하기 위해 단일 콘텐츠 이미지 대신 다양한 텍스처 패치를 사용하여 f를 학습시키는 방법을 사용함
이러한 방식으로 네트워크를 훈련시키면 다양한 콘텐츠 이미지에서 훈련된 네트워크를 사용 가능
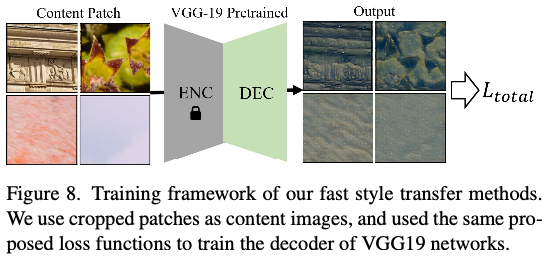
figure 8로 확인할 수 있음
- 훈련 세트에서 고해상도 텍스처 이미지로부터 랜덤하게 패치를 크롭한다.
- 더 빠른 훈련을 위해 스타일 네트워크 로 U-Net 대신 사전 훈련된 VGG 인코더-디코더 네트워크를 사용하고 디코더 네트워크만 fine-tuning한다.
- 학습 단계에서 동일한 손실 함수를 사용했지만 입력 패치가 이미 큰 이미지에서 잘려나갔기 때문에 하위 패치를 자르지 않았음

그림 9가 그 결과임
- 다양한 텍스처 입력으로 모델을 학습했기 때문에 임의의 콘텐츠 이미지에 대해 실시간으로 스타일 전송을 수행할 수 있음
- 결과 이미지가 텍스트 조건의 semantic texture를 반영했음
- Fig. 1과 3에
- 이 실험의 의미는 빠른 트랜스퍼 자체로도 임의의 콘텐트 이미지에 대한 고품질 스타일 전송을 가능하게 했음을 강조할 수 있다.
5.2. High-resolution style transfer
- 빠른 스타일 전송은 패치 기반 학습을 통해 모든 종류의 콘텐츠 이미지에 적용할 수 있으므로 고해상도 콘텐츠 이미지로 스타일을 전송할 수 있음
- 훈련 방식은 우리의 빠른 스타일 전이 방법과 동일
- VGG 모델을 교육한 후 스타일 전송을 위해 고해상도 이미지를 교육된 네트워크에 공급할 수 있음

- 그림 10에서 내용의 세부 사항을 유지하면서 입력 스타일을 주어진 텍스트 조건으로 변경할 수 있음
6. Conclusion
본 논문에서는 텍스트 조건만을 이용하여 의미론적 텍스처 정보를 전달하는 새로운 이미지 스타일 전달 프레임워크를 제안하였다. 새로운 patchCLIP 손실 및 augmentation scheme을 사용하여 스타일 이미지를 요구하지 않고 단순히 텍스트 조건을 변경하여 현실적인 스타일 전송 결과를 얻었습니다. 실험 결과는 우리의 프레임워크가 최첨단 이미지 스타일 전송을 생성했음을 보여주었습니다.

👍