Machine Learning
1. Frequentist와 Bayesian의 차이는 무엇인가?
- Frequentist: 확률을 반복 시행에서 사건이 발생하는 상대적 빈도로 정의. 데이터만을 이용해 추정을 수행하며, 사전 정보(Prior)를 고려하지 않습니다.
- Bayesian: 확률을 주관적 믿음으로 정의. 데이터와 사전 정보(Prior)를 결합하여 추정을 수행합니다.
2. Frequentist와 Bayesian의 장점은 무엇인가?
- Frequentist:
- 계산이 상대적으로 간단하며, 많은 데이터에서 좋은 성능.
- 사전 확률을 정의할 필요 없음.
- Bayesian:
- 사전 지식을 결합하여 적은 데이터에서도 강력한 성능.
- 확률 분포 형태로 불확실성을 직관적으로 표현 가능.
3. 차원의 저주란?
데이터의 차원이 증가함에 따라 데이터 포인트 간 거리가 증가하고, 학습이 어려워지는 현상을 의미합니다. 차원이 높아질수록 데이터가 희소해지며, 모델의 복잡도가 급격히 증가합니다.
4. Train, Validation, Test를 나누는 이유는 무엇인가?
- Train: 모델 학습에 사용. / Validation: 하이퍼파라미터 튜닝 및 모델 성능 평가. / Test: 최종 모델의 일반화 성능 평가.
- 이렇게 분리함으로써 모델의 과적합(Overfitting)을 방지하고, 성능을 공정하게 평가합니다.
5. Cross Validation이란?
데이터를 여러 번 나누어 Train/Validation 세트를 생성하고, 평균 성능을 측정하여 모델의 일반화 성능을 평가하는 방법입니다. 일반적으로 K-Fold Cross Validation이 사용됩니다.
6. Supervised Learning / Unsupervised Learning / Semi-Supervised Learning이란 무엇인가?
- Supervised Learning: 라벨이 있는 데이터를 사용하여 입력과 출력 간의 관계를 학습.
- Unsupervised Learning: 라벨 없이 데이터를 군집화하거나 패턴을 탐지.
- Semi-Supervised Learning: 일부 라벨된 데이터와 라벨 없는 데이터를 결합하여 학습.
7. Decision Theory란?
의사결정을 최적화하기 위한 이론으로, 특정 상태에서 최적의 행동을 결정하기 위해 확률 및 기대값을 고려합니다. 기계학습에서는 손실 함수 최소화와 관련이 깊습니다.
8. Receiver Operating Characteristic (ROC) Curve란 무엇인가?
모델의 True Positive Rate (TPR)와 False Positive Rate (FPR)를 다양한 임곗값에서 시각화한 곡선입니다. 성능이 우수한 모델일수록 곡선은 왼쪽 위로 가깝게 위치합니다.
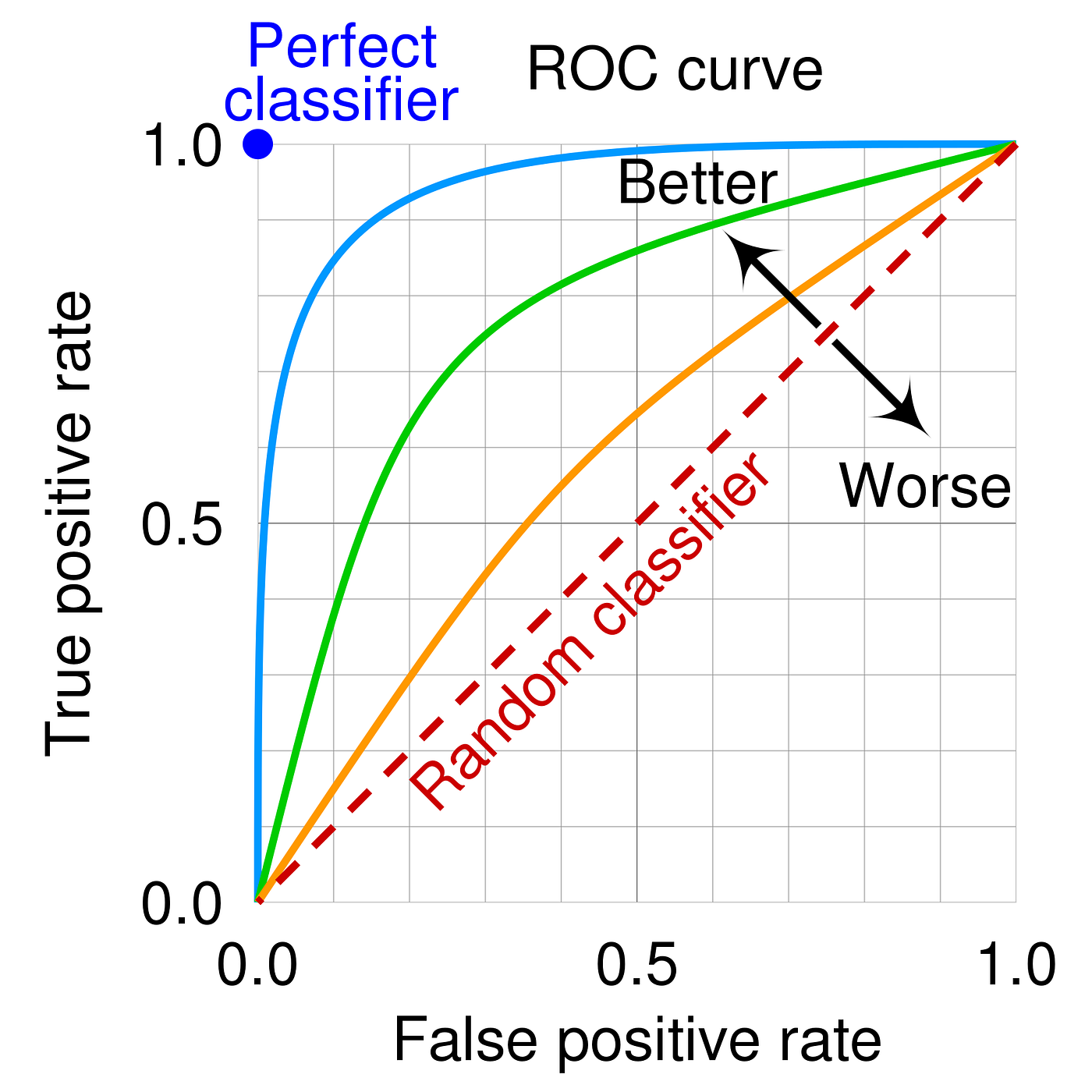
이미지 출처: 링크
9. Precision Recall에 대해서 설명해보라
- Precision (정밀도): Positive로 예측한 것 중 실제로 Positive인 비율.
- Recall (재현율): 실제 Positive 중에서 올바르게 예측한 비율.
10. Precision Recall Curve란 무엇인가?
Precision과 Recall 간의 관계를 다양한 임곗값에서 시각화한 곡선입니다. 특히 데이터가 불균형한 경우 성능 평가에 유용합니다.
11. Type 1 Error와 Type 2 Error는?
- Type 1 Error: 실제로는 False인 귀무가설을 기각 (False Positive).
- Type 2 Error: 실제로는 True인 귀무가설을 기각하지 못함 (False Negative).
12. Entropy란 무엇인가?
엔트로피는 불확실성이나 혼란의 척도로, 확률 분포의 정보량을 나타냅니다. 계산식은 다음과 같습니다:
이 수식은 확률 분포 p(x)를 가지는 랜덤 변수 X의 엔트로피를 계산합니다.
13. Kullback-Leibler Divergence (KL-Divergence) 란 무엇인가?
두 확률 분포 P와 Q의 차이를 측정하는 비대칭 척도입니다. P가 실제 분포이고 Q가 근사 분포일 때 다음과 같이 정의됩니다:
이 식은 두 확률 분포 P(x)와 Q(x) 사이의 차이를 측정하는 데 사용됩니다.
*로그는 정보량을 측정하는 데 사용됨
- 정보량의 측정
- 어떤 사건 x가 발생할 확률 p(x)가 낮을수록 그 사건은 더 많은 정보를 제공합니다.
- 정보량은 −log(p(x))로 정의되며, log를 사용하면 정보량이 확률에 반비례하도록 설계됩니다.
- 예: p(x)=0.1이면 정보량은 높고, p(x)=0.9이면 정보량은 낮음.
- 로그를 사용하면 곱셈 관계를 덧셈으로 변환할 수 있습니다.
- 엔트로피와 KL 발산은 확률 분포의 곱셈적 구조를 포함하며, 로그를 통해 계산을 단순화할 수 있습니다.
14. Mutual Information이란 무엇인가?
두 확률 변수 간에 공유하는 정보량을 측정하는 지표입니다. 변수 간 상호의존성을 평가합니다.
15. Cross-Entropy란 무엇인가?
한 확률 분포가 다른 분포를 근사하는 데 사용하는 정보량입니다. 엔트로피를 기반으로 한 거리 척도입니다.
16. Cross-Entropy Loss란 무엇인가?
모델의 출력 분포와 실제 라벨의 분포 간의 차이를 최소화하기 위한 손실 함수입니다. 주로 분류 문제에서 사용됩니다.
17. Generative Model이란 무엇인가?
데이터의 확률 분포를 학습하여 새로운 데이터를 생성할 수 있는 모델입니다. 예: GAN, VAE.
Generative Model은 데이터의 확률 분포 p(x)를 학습하여 새로운 데이터를 생성하는 데 초점이 맞춰져 있습니다.
- 주요 목적:
- 실제 데이터와 유사한 샘플 생성.
- 데이터의 구조와 분포를 이해.
- 예시:
- GAN (Generative Adversarial Network): Generator와 Discriminator를 활용해 데이터를 생성.
- VAE (Variational Autoencoder): 잠재 공간(latent space)에서 데이터를 샘플링해 생성.
- PixelRNN, Flow-based Models: 픽셀 단위로 확률 분포를 모델링하거나 역변환 가능(확률 밀도 함수 학습).
18. Discriminative Model이란 무엇인가?
데이터가 특정 클래스에 속할 확률을 학습하거나, 입력과 출력 간의 관계를 학습하는 모델입니다. 예: 로지스틱 회귀, SVM.
Discriminative Model은 입력 데이터 x와 목표 변수 y 간의 관계를 학습하거나, 데이터가 특정 클래스에 속할 확률 P(y|x)를 직접 학습합니다.
- 주요 목적:
- 데이터 분류(Classification).
- 회귀 분석(Regression).
- 예시:
- 로지스틱 회귀(Logistic Regression): P(y∣x)를 직접 학습해 클래스 확률 계산. P(y∣x)P(y|x)
- SVM (Support Vector Machine): 데이터의 결정 경계를 학습.
- 딥러닝 모델: 다층 퍼셉트론(MLP), ResNet 등은 데이터를 분류하거나 예측하는 데 사용.
- 로지스틱 회귀(Logistic Regression): P(y∣x)를 직접 학습해 클래스 확률 계산. P(y∣x)P(y|x)
19. Discriminator Function이란 무엇인가?
Generative Model(GAN)에서, 생성된 데이터가 진짜인지 가짜인지 판별하는 함수입니다.
Discriminator는 Generative Model (특히 GAN)에서 진짜 데이터(Real Data)와 생성된 데이터(Fake Data)를 구분하는 역할을 하는 함수입니다.
- 역할:
- Generator가 만든 가짜 데이터를 판별해 Generator의 품질을 높이는 피드백 제공.
- 진짜 데이터에 가까울수록 높은 확률을 반환하고, 가짜 데이터에 가까울수록 낮은 확률을 반환.
- 수학적 정의:
- 목적 함수: D(x), D(x)∈[0,1].
- 진짜 데이터에 대해 D(x)를 최대화하고, 가짜 데이터 G(z)에 대해 1−D(G(z))를 최대화.
- Discriminator와 Generator의 관계:
- GAN은 Generator와 Discriminator 간의 적대적 학습(adversarial training)을 통해 점진적으로 더 정교한 데이터를 생성.
예시:
- GAN: Discriminator가 Generator와 경쟁하며 가짜 데이터를 구분하려고 학습.
- Advances: Wasserstein GAN (WGAN)은 Discriminator 대신 비판자(Critic)를 도입해 안정성을 높임.
20. Overfitting이란?
모델이 학습 데이터에 지나치게 적합하여, 새로운 데이터에 대한 일반화 성능이 낮아지는 현상입니다.
21. Underfitting이란?
모델이 데이터의 패턴을 충분히 학습하지 못하여, 학습 데이터와 테스트 데이터 모두에서 성능이 낮은 현상입니다.
22. Overfitting과 Underfitting은 어떤 문제가 있는가?
- Overfitting: 일반화 성능 저하.
- Underfitting: 학습 자체가 부족하여 성능 저하.
23. Overfitting과 Underfitting을 해결하는 방법은?
- Overfitting:
- 더 많은 데이터 사용.
- Regularization 기법 활용 (L1, L2).
- Dropout, Early Stopping.
- Underfitting:
- 더 복잡한 모델 사용.
- 충분한 학습 시간 제공.
24. Regularization이란?
모델의 복잡도를 줄여 과적합을 방지하는 기법. L1 (Lasso)와 L2 (Ridge) Regularization이 대표적입니다.
25. Activation Function이란 무엇인가?
신경망의 각 뉴런에서 입력 신호를 비선형으로 변환하는 함수입니다. 대표적인 종류:
- Sigmoid
- ReLU
- Tanh
26. CNN에 대해서 설명해보라
Convolutional Neural Network(CNN)는 이미지 처리에 특화된 신경망 구조로, 특징 추출 및 패턴 인식을 위해 Convolution Layer와 Pooling Layer를 사용합니다.
27. RNN에 대해서 설명해보라
Recurrent Neural Network(RNN)는 순차 데이터(시계열, 텍스트)를 처리하도록 설계된 신경망으로, 이전 상태의 정보를 메모리로 활용합니다.
28. Gradient Descent란 무엇인가?
손실 함수를 최소화하기 위해 파라미터를 점진적으로 업데이트하는 최적화 알고리즘입니다.
29. Stochastic Gradient Descent란 무엇인가?
전체 데이터가 아닌 무작위로 선택된 소규모 데이터(batch)를 사용하여 Gradient Descent를 수행하는 알고리즘입니다.
30. Batch Normalization은 무엇이고 왜 하는가?
각 층의 입력 분포를 정규화하여 학습을 안정화하고 속도를 높이는 방법입니다.
31. Backpropagation이란 무엇인가?
신경망 학습에서 손실 함수의 기울기를 역방향으로 계산하여 가중치를 업데이트하는 알고리즘입니다.
32. Ensemble이란?
여러 모델의 예측을 결합하여 성능을 향상시키는 방법입니다.
33. Bagging이란?
데이터를 샘플링하여 여러 모델을 독립적으로 학습한 후 평균을 내는 방식입니다. 예: Random Forest.
34. Boosting이란?
여러 모델을 순차적으로 학습하여 이전 모델의 오류를 개선하는 방식입니다. 예: AdaBoost, Gradient Boosting.
35. Bagging과 Boosting의 차이는?
- Bagging: 모델이 병렬적으로 독립적으로 학습.
- Boosting: 모델이 순차적으로 학습하며, 이전 모델의 오류를 보정.
36. Support Vector Machine이란 무엇인가?
데이터를 분류하기 위해 결정 경계를 최적화하는 알고리즘으로, Margin을 최대화하여 분류 성능을 높입니다.
37. Margin을 최대화하면 어떤 장점이 있는가?
데이터 분포 변화에 강건해지며, 일반화 성능이 향상됩니다.
