[Python] timestamp 형식을 datetime 형식으로 바꿔주는 방법
timestamp 형식을 datetime으로 바꿔주는 방법
이런 형식의 DataFrame이 있습니다.
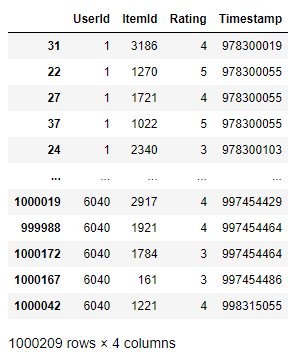
컬럼은 총 4개 ['UserId', 'ItemId', 'Rating', 'Timestamp'] 이고, index는 1000209개입니다.
저는 여기서 data['Timestamp']를 'yyyy-mm-dd hh:mm:ss'의 datetime 형식으로 바꿔주고 싶었습니다.
제가 쓴 코드
from datetime import datetime
import time
date = []
for i in range(1000209) :
time = datetime.fromtimestamp(data['Timestamp'][i]).strftime('%Y-%m-%d %H:%M:%S')
date.append(time)
data['date'] = datedata
>>>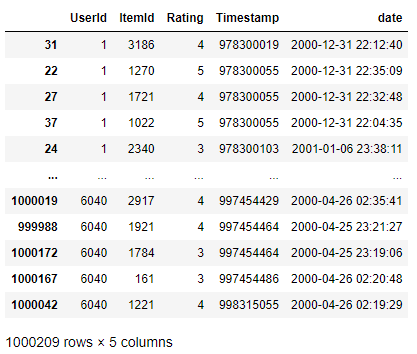
date라는 새로운 컬럼이 추가되었습니다.
datetime 코드
from datetime import datetime
import time
date = datetime.fromtimestamp(965333392).strftime('%Y-%m-%d %H:%M:%S')
date잘못 쓴 코드 1
data['Timestamp'].nunique()
>>> 458455고유값을 확인해서 넣으면 기존 DataFrame과 index 수가 다르기 때문에 추가가 되지 않습니다.
from datetime import datetime
import time
date = []
for i in range(458455):
time = datetime.fromtimestamp(data['Timestamp'][i]).strftime('%Y-%m-%d %H:%M:%S')
date.append(time)잘못 쓴 코드 2
from datetime import datetime
import time
date = []
for i in data['Timestamp']:
time = datetime.fromtimestamp(data['Timestamp'][i]).strftime('%Y-%m-%d %H:%M:%S')
date.append(time)range 값에 리스트를 넣으면 될 거라 생각해서 넣었는데, error가 떴습니다.
깨달은 점
- 리스트엔 int 가 못 들어간다.
TypeError: 'int' object is not iterable리스트 함수에는 인자로서 시퀀스(문자열, 튜플) 또는 집합(딕셔너리) 또는 iterable 하는 객체(range)가 와야 합니다.
저 에러가 떴을 때 time = str(time)으로 저장해두었지만 변환이 잘 되지 않았습니다.
- for문으로 새 리스트를 추가하려면 for 문 시작 전에 빈 리스트를 만들어 두어야 합니다.
- append 함수를 사용해야 빈 리스트에 값이 저장됩니다.
- 새로운 컬럼을 생성하는 방법
df['컬럼명'] = '추가하고 싶은 리스트'
한 번에 떠오르지 않았습니다! - 데이터프레임에서 컬럼을 삭제하는 방법
data.drop('컬럼명', axis=1)
컬럼을 삭제하는 방법입니다. drop 대신 pop의 방법도 있습니다.

AI/ML Engineer