이번 포스팅은 standford university의 cs231 lecture 3를 공부하고, 강의와 슬라이드를 바탕으로 정리한 글임을 밝힙니다.
Reference
💻 유튜브 강의: Loss Functions and Optimization
📑 slide: PDF
Contents
- Outline
- Multiclass Support Vector Machine Loss(Multiclass SVM loss)
- Questions 1~6
- Regularization
- Weight Decay
- Softmax
- Questions 1~3
- Softmax vs. SVM
- 중간 Summary
- Optimization
- 1-1. Random Search
- 1-2. Random Local Search
- 2-1. Gradeint 따라가기(Follow the slope)
- 2-2. gradient 계산
- Gradient
- Stochastic Gradient Descent(SGD)
- 정리한 글
- Summary
0. Outline
이번 강의는 loss function에 대해 정의를 내리고 image classification에서 쓸만한 몇 가지 loss function을 소개하고 있습니다. (예를 들면, SVM loss)
뒷부분은 loss function을 최소화하는 parameter를 찾는 optimization 방법에 대해 배웁니다.
Lecture 2에서는 image pixel 값에서 class score에 이르는 function을 정의했으며, 이는 에 의해 parameterized 되었습니다.
이는 데이터 에 대한 제어는 없지만 가중치를 제어할 수 있음을 의미하며,
예측된 class score가 ground truth과 일치하도록 만들어줍니다.
앞에서 살펴보았던 ['Cat', 'Dog', 'Ship']의 예를 이용하여 살펴보고 가겠습니다.
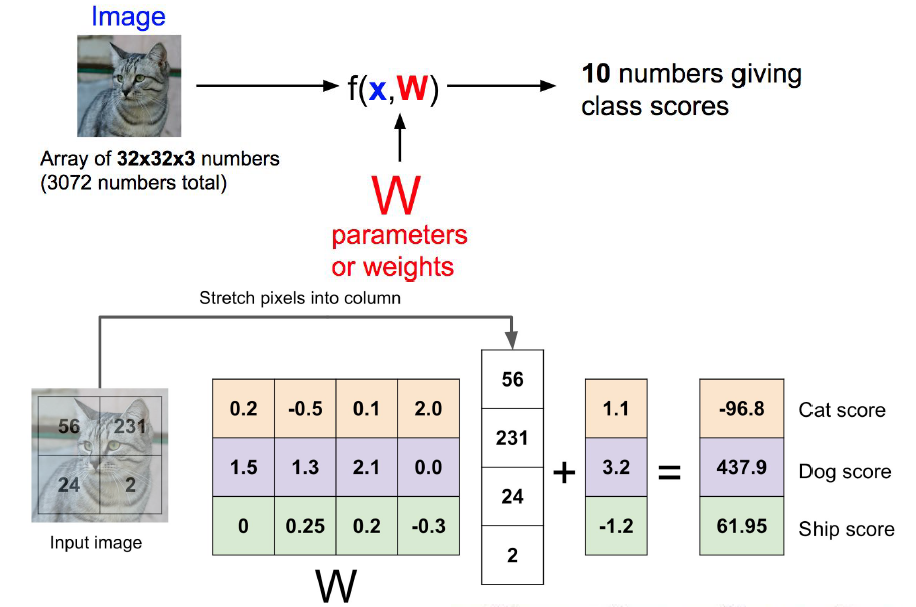
위의 예시는 사실 가 별로 좋지 않은데요. 그이유는 'Cat' 임에도 불구하고 'Dog'의 class score가 가장 높아서입니다.
이렇게 좋지 않은 결과를 이제 loss function을 이용하여 다룰 예정입니다.
1. Multiclass Support Vector Machine Loss(Multiclass SVM loss)
Loss function은 손실함수, cost function, objective 등 부르기도 합니다.
loss function이 하는 역할이 도대체 무엇인가요?
loss function은 모델이 나타내는 확률 분포와 데이터가 따르는 실제 확률 분포 사이의 차이를 나타내는 함수입니다.
더 쉽게 말하면, loss function는 실제값과 예측값의 차이(loss, cost)를 수치화해주는 함수입니다.
임의의 값 가 얼마나 좋은지 나쁜지를 정량화 시켜주는 역할인 것이죠.
그렇다면 자연스럽게 클수록 loss function의 값이 크고, 오차가 작을수록 loss function의 값이 작아진다는 것을 알 수 있습니다.
그리고 loss function의 값을 최소화 하는 W, b를 찾아가는것이 학습 목표입니다. 이 과정을 '최적화 과정'이라 부릅니다. 이건 뒷부분에 나옵니다.😆

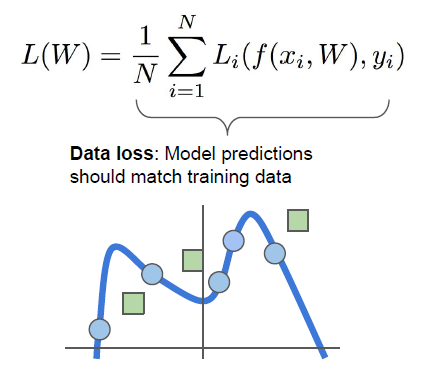
해당 ppt를 통해서 ['Cat', 'Dog', 'frog']를 분류하는 문제에서 최종 loss는 dataset에서 각 N개의 샘플들의 Loss 평균이 됩니다.
이 경우가 loss function의 아주 일반적인 공식입니다.
이제 image classification에 아주 적합한 loss function인 multi-class SVM loss를 소개합니다.

ppt 내용을 바탕으로 정리한 자료입니다.
을 계산하여, class score라는 s vector가 계산됩니다.
로 i번째 예에 대한 멀티클래스 SVM 손실은 다음과 같이 공식화됩니다.
하지만 SVM의 특이한 점은 각 image에 대한 correct class가 incorrect class보다 일부 고정적인 margin을 갖기를 원합니다.
강의에서는 safety margin이라 소개하고 1로 고정되어 있습니다.
식은 이렇습니다.
계산 방식은 어렵지 않아서 따로 정리하진 않겠습니다.
대신 이 SVM loss를 더 쉽게 설명하는 hinge loss 그래프를 보고 가겠습니다.
Max(0, value)와 같은 식의 loss function을 hinge loss라고 한답니다.
hinge는 참고로 '경첩'을 의미합니다.😓

참고로 SVM 알고리즘에 대해 배우지 않고, 바로 SVM loss를 설명해주기 때문에 개념이 생소하게 느껴질 수 있다고 생각합니다.
그래프로 나타내면 이렇습니다. 축에 닿아 있지 않지만 값이 0이라 생각하고 봐주시면 될 것 같습니다.
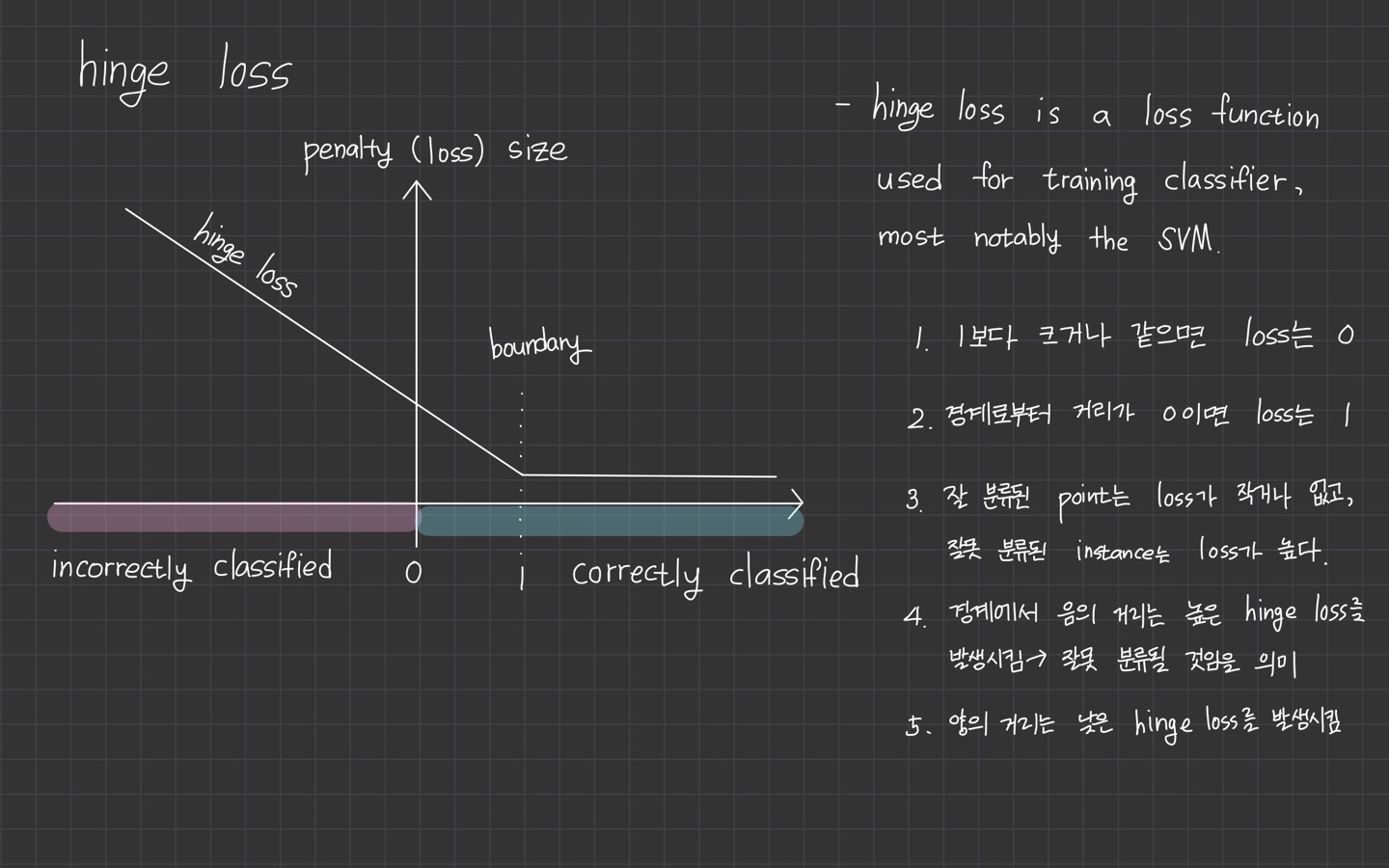
와 에 대해 이해를 하셨다면, hinge loss 그래프를 이해하는데 어렵지 않을 거라 생각합니다.
정확하게 예측했을 수록 의 값이 클테니까 의 식에서 음숫값이 나올 가능성이 더 큽니다. 그러면 max(0, vlaue)에 따라 loss는 0이 되겠죠.
여기서 +1을 해주기 때문에 1만큼의 을 갖게 된다는 점도 잊지 말아주세요!
잘못 분류했을 경우, loss 값은 더 커지게 될 것입니다.
정답 카테고리의 점수가 올라갈수록 Loss가 선형적으로
줄어든다. Loss가 0이 됐다는 건 클래스를 잘 분류했다는 뜻이다.
Questions 1~6
-
잘 예측했을 경우의 값이 미세하게 바뀐다고 해서 loss 값은 바뀌지 않습니다.
-
만약 ground truth의 class score가 엄청 낮은 음수 값을 갖고 있다고면, 아마 Loss는 아마 무한대일 것입니다.
max(0, vlaue)는 최솟값이 0, 최댓값이 무한대를 갖게 됩니다. -
parameter를 initialization하고 training할 때 보통은 행렬 을 임의의 작은 수로 초기화합니다. 그렇기 때문에 처음 학습 시에는 class score가 임의의 일정한 값을 갖게 됩니다. (처음부터 바로 잘 예측할 수 없는 부분)
-
와 가 비슷할 경우에는 Multiclass SVM에서 Loss가 어떻게 계산될까요? 강의에서는 'class 수 - 1'이라고 답변을 하는데요. 조금 불친절한 감이 있습니다.
와 가 비슷할 경우에는 {- + 1} 계산시 인 1만 남게 됩니다. 그러면 class 수에 따라 계산할 수가 달라지겠죠.
위 식은 ground truth끼리의 계산을 제외하고 비교를 하는 거기 때문에, class가 3개라면 식은 2개가 나오게 되겠죠. 그럼 남는 1이
class 수 - 1개가 됩니다.그래서
class 수 - 1이라 설명을 한 것입니다.여기에 플러스로 정답 class도 계산한다면? 이란 추가 질문을 하는데요. 그렇담 당연히 loss에 1이 증가한 값이 될 것입니다.
정답 class만 빼고 정리하는 이유는 일반적으로 loss가 0이 되어야만 하기 때문입니다.
-
loss를 계산할 때 전체 합이 아닌 평균을 쓰면 어떻게 되나요? 정답은 별로 영향을 미치지 않는다입니다. class 수는 정해져 있어서 평균을 취해도 loss function을 rescale할 뿐 상관없습니다.
궁극적으로 SVM loss는 class score의 값이 몇 인지가 중요한 것이 아니기 때문입니다. 여기서 집중하고 있는 것은 정답 class가 정답이 아닌 class보다 더 높은 점수를 내기만을 바라고 있습니다.
-
loss function을 아래와 같이 제곱항으로 바꾸면 어떻게 될까요?
결과는 달라집니다. 제곱을 해버리면 잘 예측한 것과 잘 예측하지 못한 것의 관계를 비선형적으로 바꾸기 때문입니다.(음숫값이 사라짐)
loss function 계산 자체가 바뀌게 됩니다.
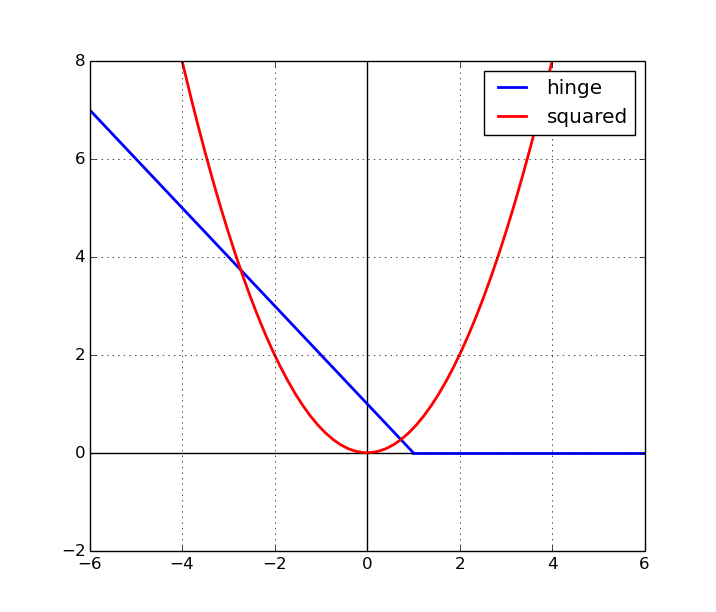
그래프를 보면 square hinge loss의 변한 모습이 잘 보이실 겁니다.
loss function의 역할은 임의의 값 가 얼마나 좋은지 나쁜지를 정량화 시켜주는 것입니다.
classifier가 얼마나 잘 하고 있는지 penalty를 주는 것이기 때문에, loss에 제곱을 하게 된다면 잘못 예측한 것(loss가 큰 경우)은 제곱만큼 loss가 커지게 됩니다.
따라서 square hinge loss는 잘못 분류되는 것을 절대 용납하지 못한다, 그냥 hinge loss는 잘못된 것과 조금 잘못된 것에 대해 크게 신경을 안 쓴다는 입장입니다.
이렇게 어떤 loss를 사용하냐는 error 값을 얼마나 신경 쓰고 있으며, 어떻게 정량화할 것인지에 따라 달라지게 됩니다.
앞으로 loss function 선택에 따라 '어떤 에러를 내가 신경쓰고 있는지', '어떤 에러가 트레이드오프 되는 것인지'를 알려주게 됩니다. 그래서 loss function 설계가 엄청 중요하다고 합니다.
2. Regularization
위에서 설명한 loss function에 🐞가 있답니다.
모든 sample data를 올바르게 분류하는 data set과 parameter 집합 를 찾았다고 가정합니다.
문제는 이 집합이 반드시 유일한 것은 아니라는 것인데요.
예를 들어, 를 0으로 만드는 이 있는데, 여기다가 를 한다고 해서 는 변하지 않습니다.
이미 모든 이 1보다 크다면 2배를 해도 loss는 0입니다.
loss function이 어떤 W를 찾고 있고, 어떤 W에 신경쓰고 있는지를 말해주는 것이라면
수많은 중에 loss가 0이 되는 것을 선택한다면 모순이 있습니다.
왜냐하면 오직 data의 loss에만 신경을 쓰고 있기 때문인데요. training data에만 신경을 쓰는 를 선택하게 된다면 과대 적합 등의 문제가 발생하겠죠.
슬라이드에서는 이렇게 보여줍니다.
이러한 문제점을 해결하기 위해 추가하는 것이 입니다.
특정 가중치 집합 에 를 확장합니다. 가장 일반적인 정규화 규제 방법은 모든 매개변수에 대해 제곱하여 가중치를 규제하는 이 있습니다.
위 식에서 에 제곱한 값을 모두 더합니다.
regularization function은 에 대한 function이 아니라 기반의 함수입니다.
위의 식처럼 regularization penalty를 추가하면 data loss와 regularization loss의 요소로 구성된 loss function이 완성됩니다.
mutil-class Suport Vector Machine Loss로는 아래의 이미지를 참고해주세요.
는 하이퍼 파라미터입니다. 과 trade-off 관계를 갖습니다.

3. Weight Decay
을 라고도 합니다.
L2 Regularization은 가중치 행렬 에 대한 Euclidean Norm입니다. 해당 내용은 lecture 2를 참고해주세요.
가중치 감소는 가중치 크기를 제한하는 제약 조건으로 loss function의 일부 항으로 표현됩니다.
*위의 data loss + regularization loss가 합쳐진 형식
이는 최적화 과정에서 원래의 손실 함수와 함께 regularization term도 같이 최소화되므로 크기가 작은 가중치 집합 을 구할 수 있습니다.
regularization term 은 으로 정의합니다.
norm을 사용하면 정규화라 하며, Ridge regression이라고도 부릅니다.
norm을 사용하면 정규화라하며, Lasso Regression이라고도 부릅니다.
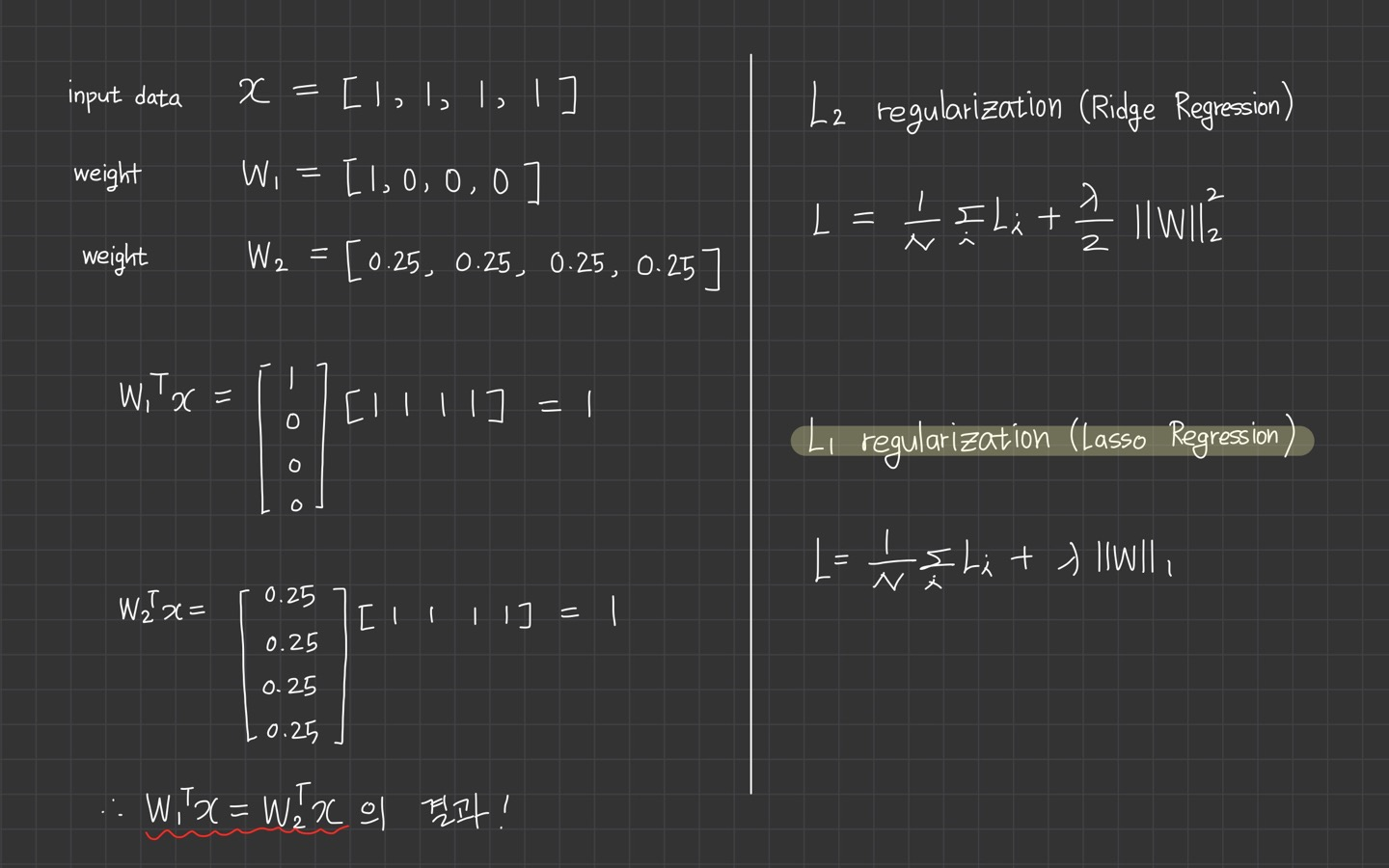
위 그림을 참고하면, 두 가중치 벡터는 같은 값을 만듭니다.
하지만 L2 penalty 은 1.0인 반면, 는 0.25에 불과합니다.
따라서 L2 페널티에 따르면, weight vector 는 더 낮은 regularization loss를 달성하기 때문에 더 선호됩니다.
직관적으로 이것은 의 가중치가 더 작고 더 분산되기 때문입니다. (L2 Regularization은 x의 모든 요소가 영향을 줬으면 하는 것이 바람)
페널티는 더 작고 더 확산된 가중치 벡터를 선호하기 때문에 최종 분류기는 모든 입력 차원을 소수의 입력 차원보다 작은 양으로 매우 강력하게 고려하도록 권장됩니다.
이 강의의 뒷부분에서 나오긴 하지만, 이 효과는 테스트 이미지에 대한 classifer의 일반화 성능을 개선하고 과대적합을 줄입니다.
bias는 weight과 달리 input dimension의 영향 강도를 제어하지 않기에 동일한 효과가 없습니다.
따라서 가중치 만 정규화하고 편향 는 정규화하지 않는 것이 일반적입니다.
그러나 실제로 이것은 종종 무시할 만한 효과가 있기도 합니다.
마지막으로, 정규화 패널티로 인해 모든 예에서 정확히 0.0의 손실을 달성할 수 없다는 점도 알고 있어야 합니다.
4. Softmax
Softmax는 Multinomial logistic regression입니다.
softmax function은 score를 전부 이용하고, 이 score에 지수를 취해서 양수가 되게 만듭니다.
그리고 지수들의 합으로 정규화 시킵니다.
softmax 함수를 거치게 되면 확률 분포를 얻을 수 있고 해당 클래스일 확률로 표현됩니다.
확률이기 때문에 0에서 1 사이의 값이고 모든 확률들의 합은 1이 됩니다.
softmax에 대한 정리는 해당 게시글에서 정리해두었습니다.
다항 로지스틱 회귀부터 보시면 도움이 될 것 같습니다.
💡 Logistic Regression(로지스틱 회귀)
Questions 1~3
-
softmax의 최솟값과 최댓값
- 정답 class에 대한 log 확률이기 때문에 이고 입니다.
-
loss가 0이 되려면 score 값은 얼마여야 하나요?
- 정답 score가 극단적으로 높아야 합니다. (거의 무한대에 가깝게)
왜냐하면 여기서는 class socre를 지수화하고 정규화를 하기 때문에 확률 1(정답)과 0(그 외)를 얻으려면
정답 class의 score는 무한대가 되어야 하고, 나머지는 -무한대가 되어야 합니다.
은 음의 무한대, 은 양의 무한대가 됩니다.
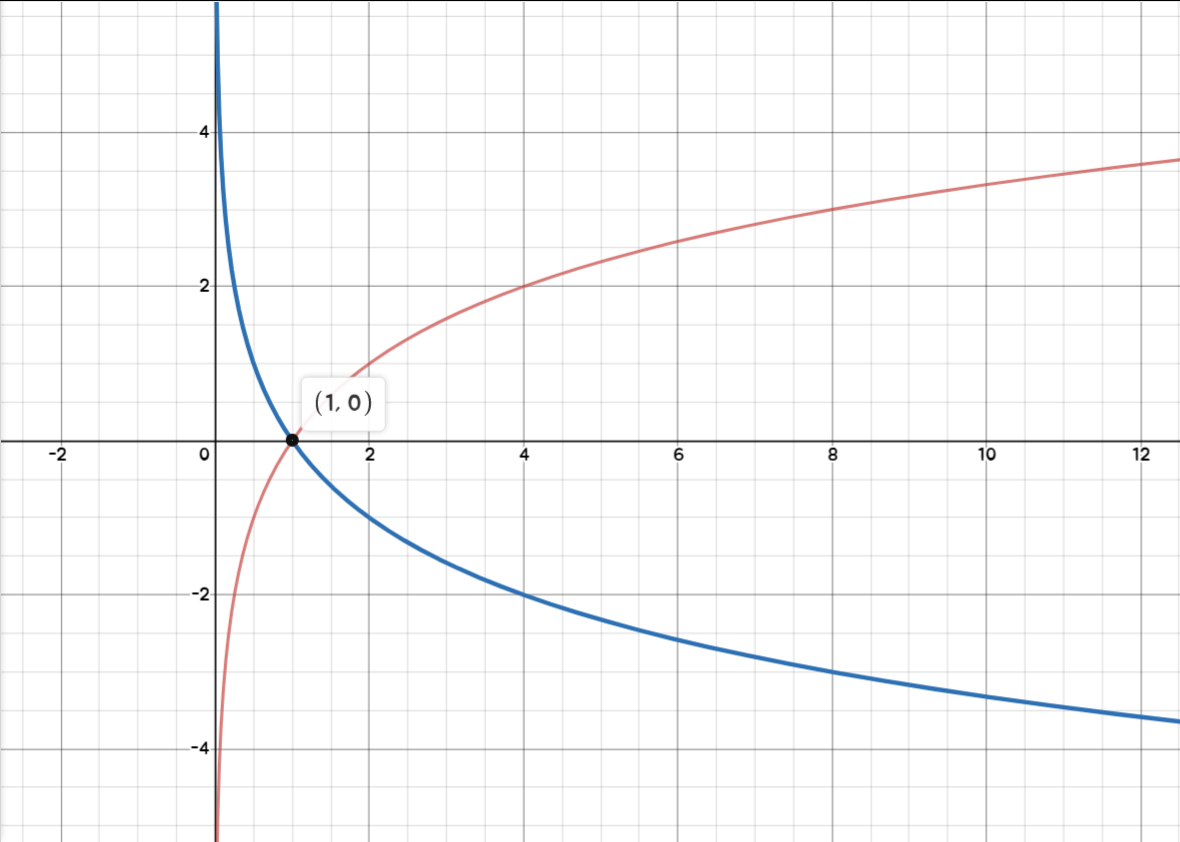
해당 그래프를 참고해주세요.
-
가 모두 0에 가까운 작은 값일 때, loss는 어떻게 될까요?
- 가 된다. (=)
5. Softmax vs. SVM
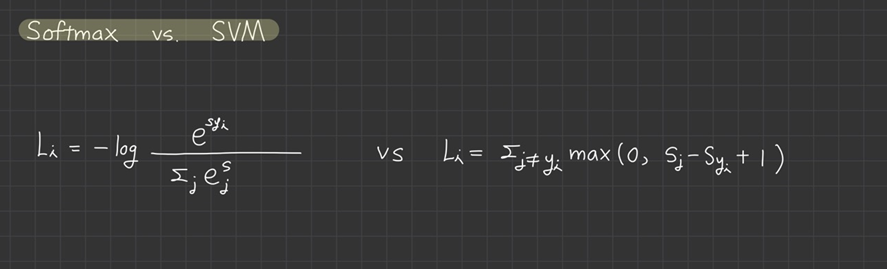
두 loss function의 차이점은 class score 해석 관점에 있습니다.
SVM에서는 class score의 수치보다는 정답 score와 정답이 아닌 score 간의 차(margin)에 신경을 썼습니다.
반면 softmax의 경우는 확률을 구해서 -log(class score)에 신경을 씁니다.

multi-class SVM loss의 예시 중에 car class에서 car score가 다른 class score보다 훨씬 높았습니다.
여기서 car score를 미세하게 조정한다고 해서 SVM loss는 변하지 않았습니다.
하지만 softmax loss는 다릅니다. 확률을 1로 만드는 것(정확하게 예측하는 것)이 목표입니다.
softmax는 정답 score가 충분히 높고, 다른 score가 충분히 낮은 상황에서도 정답 class의 확률을 높이는데 최선을 다할 것입니다.
이것은 '성능 개선'의 관점에서 차이가 발생하는 부분입니다.
6. 중간 Summary
-
image pixel에서 class score까지 score function을 정의했습니다.
- weihgt 과 biases 를 기반으로 한
-
K-NN classifier과 달리 parametric approach의 이점은 parameter를 학습하면 training data를 버릴 수 있다는 점입니다.
- 새로은 test image에 대한 예측은 모든 training example에 대한 것이 아닌 의 matrix product를 필요로 하기 때문에 K-NN보다 빠릅니다.
-
하나의 weight matrix를 찾기 위해 bias vector를 추가해 parameter matrix를 만들었습니다.
-
loss function을 정의했습니다.
- linear classifier에 주로 사용되는 SVM과 softmax
- parameter set이 train dataset의 label을 얼마나 잘 찾는지
- train data에 대해 잘 예측하는 것이 작은 loss 값을 갖는 것과 동일하다는 것을 살펴보았음
중간 요약을 하는 이유는 갑자기 justin이 요약을 하길래... 따라 했습니다. loss function까지 lecture 2부터의 흐름을 정리해주는 참교수입니다.
7. Optimization
(최적화 부분을 정리하다가 다 날아가서 정말 속상하네요...😡)
는 parameter 행렬의 질을 측정합니다. 강의에서 내내 '얼마나 구린지'라는 말로 언급했던 부분입니다.
최적화의 목적은 이 loss function을 최소화시키는 을 찾아내는 과정입니다. 궁극적인 목적은 신경망(neural networks)를 최적화시키는 것입니다.
마지막 파트가 loss function을 최적화하는 방법에 대해 설명하는 파트입니다!
시작 전, loss function이 왜 필요한지?를 이해하면 다음 단계로 넘어가는데 어려움이 없을 것 같습니다!
신경망 학습에서는 최적의 parameter(, )를 탐색할 때 loss function의 값을 가장 작게하는 parameter를 찾습니다.
이때 parameter의 미분(정확히는 기울기)을 계산하고, 그 미분 값을 단서로 parameter의 값을 서서히 개선하는 과정을 반복합니다. 이 야기는 조금 더 뒤에 다뤄질 내용이긴 합니다.
신경망 최적화 알고리즘은 대부분 경사 하강법(gradient descent)에서 확장된 형태입니다.
신경망의 기본 알고리즘으로 경사하강법을 채택한 이유와 최적화 원리를 살펴보도록 하겠습니다.
1-1. Random Search
첫 번째는 'very bad solution'이라 소개되는 무작위 탐색 방법입니다.
주어진 parameter 이 얼마나 좋은지를 측정하는 것은 매우 간단합니다.
처음 떠오른 생각은 단순히 무작위로 parameter를 골라서 넣어보고 넣어 본 값들 중 제일 좋은 값을 찾는 방법입니다.
bestloss = float("inf") # Python assigns the highest possible float value
for num in xrange(1000):
W = np.random.randn(10, 3073) * 0.0001 # generate random parameters
loss = L(X_train, Y_train, W) # get the loss over the entire training set
if loss < bestloss: # keep track of the best solution
bestloss = loss
bestW = W
print 'in attempt %d the loss was %f, best %f' % (num, loss, bestloss)코드를 보면 얼마나 무모한지 더 잘 느껴지실 겁니다.
이 강의에서는 CIFAR10 데이터의 경우 아무거나 찍어도 10%의 정확도를 보이는데, random search 방법을 쓰면 최대 15.5%의 정확도가 나오므로 나쁘지 않다고 비꼬고 있습니다.(ㅋㅋㅋㅋ)
대신 여기서 얻은 아이디어로는 '반복'이었습니다.
최선의 parameter 를 찾는 것은 매우 어렵지만, 주어진 parameter 를 조금씩 개선 시키는 방법을 이용할 수 있다는 점이었습니다.
우리의 전략은 무작위로 뽑은 파라미터(parameter/weight)으로부터 시작해서 반복적으로 조금씩 개선시켜 손실(loss)을 낮추는 것이다.
이때 항상 나오는 비유가 산 꼭대기에서 눈을 가리고 산을 내려오는 방법입니다.

경사진 지형에서 눈을 가리고 서있다면 당연히 '내리막길'인 것 같은 곳으로 발이 닿게 되겠죠. 그리고 점점 내려오는 방법입니다. 언덕의 각 지점에서의 고도가 loss function의 loss 역할을 합니다.
1-2. Random Local Search
위에서 언급한 '내리막길'을 상상해봅시다.
이 경우는 임의의 에서 시작해 또 다른 임의의 방향 로 살짝 움직이는 것입니다.
움직인 자리 에서의 loss가 더 낮으면 그곳으로 이동하고 다시 탐색합니다.
W = np.random.randn(10, 3073) * 0.001 # 임의의 시작 파라미터를 랜덤하게 고른다.
bestloss = float("inf")
for i in xrange(1000):
step_size = 0.0001
Wtry = W + np.random.randn(10, 3073) * step_size
loss = L(Xtr_cols, Ytr, Wtry)
if loss < bestloss:
W = Wtry
bestloss = loss
print 'iter %d loss is %f' % (i, bestloss)아까와 같은 횟수 1,000번을 loss function을 계산했습니다. 이 방법을 사용했을 때 21.4%의 정확도가 나왔다고 합니다. 하지만 여전히 비효율적인 방법입니다.
2-1. Gradeint 따라가기(Follow the slope)
parameter 공간에서 parameter vector를 향상 시키는 방법으로 두 가지를 시도해 보았습니다.
하지만 방향을 무작위로 탐색할 필요는 없습니다. 여기서는 gradient(기울기)를 이용해서 기울기가 가장 가파른 곳을 찾아 최선의 방향으로 이동할 수 있습니다.
이 방향이 loss function의 gradient와 관계있는 이유는 기울기는 미분으로 구할 수 있기 때문입니다.
1차 함수일 때, 어떤 점에서 움직이는 경우의 기울기는 함수의 순간 증가율을 의미합니다.
가 있다면 만큼 이동한 x의 변화량 이 되겠죠. gradient라는 것은 변수 하나가 아닌 여러 개의 경우를 일반화시킨 것입니다.
x에 대해 각 해당하는 기울기입니다.
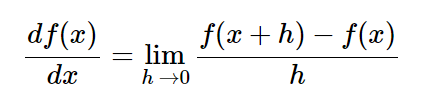
미분 식은 위와 같습니다.
2-2. gradient 계산
gradient를 계산하는데 크게 두 가지 방법이 있습니다.
- 수치 gradient
- 해석 gradient
주로 수치 미분, 해석적 미분이라 일컫습니다.
(1) 수치 미분
여기서 되게 낯선 용어 유한 차분법(finite difference methods)이 나오는데요.
유한한 차이(Finite Difference)를 이용해 수치적으로 gradient를 계산하는 방법입니다.
임이의 함수 에 들어갈 입력값 벡터 가 있습니다. 에서 의 gradient를 계산해주는 코드입니다.
def eval_numerical_gradient(f, x):
"""
함수 f의 x에서의 그라디언트를 매우 단순하게 구현하기.
- f 는 입력값 1개를 받는 함수여야한다.
- x는 numpy 어레이(array)로서그라디언트를 계산할 지점 (역자 주: 그라디언트는 당연하게도 어디서 계산하느냐에 따라 달라지므로, 함수 f 뿐 아니라 x도 정해줘야함).
"""
fx = f(x) # 원래 지점 x에서 함수값 구하기.
grad = np.zeros(x.shape)
h = 0.00001
# x의 모든 인덱스를 다 돌면서 계산하기.
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
# 함수 값을 x+h에서 계산하기.
ix = it.multi_index
old_value = x[ix]
x[ix] = old_value + h # 변화랑h
fxh = f(x) # evalute f(x + h)
x[ix] = old_value # 이전 값을 다시 가져온다. (매우 중요!)
# 편미분 계산
grad[ix] = (fxh - fx) / h # 기울기
it.iternext() # 다음 단계로 가서 반복.
return grad위 코드는 gradient 식을 이용해 모든 차원을 하나씩 돌아가며 loss function 값을 구합니다.
라는 매우 작은 변화를 통해 loss 값의 변화를 살펴보고, 그 방향의 편미분 값을 계산합니다.
*편미분이란 변수가 여럿인 함수에 대한 미분을 의미합니다.
h가 0으로 수렴할 때의 극한값이 gradient의 수학적 정의입니다. 강의에서 나온 것처럼 0.0001의 작은 값이면 충분하다고 합니다.
수치적인 문제를 일으키지 않는 수준에서 가장 작은 값을 쓰는 것입니다.
하지만 gradient를 수치적으로 게산하는데 드는 비용은 parameter 수에 따라 선형적으로 증가합니다.
위 예시에서는 30,730개의 parameter가 있습니다. 그러면 30,731번 loss function을 계산해 gradient를 계산해도 딱 한 번 업데이트가 가능합니다.
데이터가 커질 수록 이 문제는 아주 심각해집니다.
(2) 해석적 미분
gradient의 각 요소가 말해주는 것은 우리가 그쪽 방향으로 아주 조금 이동했을 때 loss가 어떻게 변하는지입니다.
수치적으로 계산하는 gradient는 finite difference를 이용해서 매우 단순하게 계산이 가능합니다.
하지만 단점이 존재합니다.
근사값이라는 점과 gradient의 진짜 정의는 “h”가 0으로 수렴할 때의 극한값"인데, 여기서는 그냥 작은 “h”값을 쓰기 때문에 계산이 비효율적이라는 점을 지적하게 됩니다.
그래서 나온 것이 해석적 미분입니다.
미적분을 이용해서 해석적으로 gradient를 구하는 것입니다. 이는 근사치가 아닌 정확한 수식을 이용하기 때문에 계산하기 매우 빠릅니다.
해석적으로 푸는 것이 수치적으로 푸는 것보다 더 효율적이라고 합니다.
8. Gradient Descent
while True:
weights_grad = evaluate_gradient(loss_fun, data, weights)
weights += - step_size * weights_grad # 파라미터 업데이트(parameter update)Gradient Descent에서는 우선 를 임의의 값으로 초기화합니다.
그리고 loss와 gradient를 계산한 뒤, 가중치를 gradient의 반대 방향으로 업데이트합니다.
gradient가 함수에서 증가하는 방향이기 때문에 - gradient를 해야 내려가는 방향이 됩니다.
그리고 이걸 영원히 반복하다 보면 결국엔 수렴하게 됩니다.('그렇게 되면 행복하겠지요...' 자막ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ)
여기서 나오는 step_size는 hyper parameter입니다. 이것은 gradient 방향으로 얼마나 나아가야 하는지를 알려줍니다. 이는 learning rate라고도 부르며, 주로 줄여서 lr으로 부릅니다.
내려 가야 하는 건 알지만 얼마큼씩 내려가야 하느냐?를 결정짓는 parameter입니다.
momentum, Adam optimizer에 대한 예시도 동영상을 통해 살짝 소개되고 있습니다. 다음 강의에 나온다고 합니다.
gradient 계산 과정을 살펴보면, loss는 그저 각 데이터 loss의 gradient의 합이라는 것을 알 수 있습니다.
그러니 gradient를 한 번 더 계산하려면 개의 전체 training set을 한 번 더 돌면서 계산해야 합니다. 이 과정은 데이터의 크기가 클수록 아주 비효율적입니다.
이 방법을 개선 시킨 방법이 아래의 Stochastic Gradient Descent입니다.
9. Stochastic Gradient Descent(SGD)
Minibatch라는 작은 training sample 집합으로 나눠서 학습하는 방법입니다.
미니 배치 그라디언트 하강(Mini-batch gradient descent (MGD))의 방법이긴 한데 SGD라고 통용되고 있습니다. training data가 수백만개 주어질 수 있는데, 파라미터를 한 번 업데이트하려고 학습데이터 training data 전체를 계산에 사용하는 것은 낭비가 될 수 있습니다.
이를 극복하기 위해서 흔하게 쓰이는 방법이 배치(batches)만 이용해서 그라디언트(gradient)를 구하는 것입니다.
예를 들어 ConvNets을 쓸 때, 한 번에 120만개 중에 256개짜리 배치만을 이용해서 그라디언트(gradient)를 구해 parameter를 업데이트 합니다.
참고로 batch는 전체 데이터셋 크기 을 의미합니다.
minibatch를 이용해 전체 합의 추정치와 실제 gradient의 추정치를 계산하는 코드입니다.
# 단순한 미니배치 (minibatch) 그라디언트(gradient) 업데이트
while True:
data_batch = sample_training_data(data, 256) # 예제 256개짜리 미니배치(mini-batch)
weights_grad = evaluate_gradient(loss_fun, data_batch, weights)
weights += - step_size * weights_grad # 파라미터 업데이트(parameter update)이 개념들에 대해선 상세히든 간단히든 정리한 포스팅이 있습니다. 링크를 달아두는 것은 절대 다시 정리하기 귀찮아서가 아닙니다.
정리한 글
🔗 경사하강법(Gradient Descent)
🔗 신경망 학습과 최적화(optimization)
🔗 배치와 미니 배치, 확률적 경사하강법
10. Summary
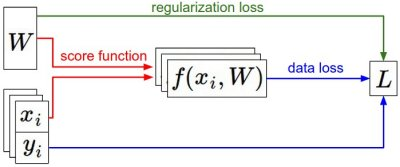
이 이미지를 통해 지금까지 배운 내용의 흐름을 살펴보면 좋겠습니다.
라는 고정된 데이터 쌍이 있을 때, 처음에 무작위로 뽑은 parameter 값으로 바뀌어 나갑니다.
왼쪽에서 오른쪽으로 이동하면서 score function은 각 class의 score를 계산하고, 그 값이 f 벡터에 저장됩니다.
loss function은 data loss와 regularization loss로 나뉘어져 있습니다. Gradient descent 과정에서 parameter로 미분한 gradient를 계산하고 이를 이용해 parameter를 업데이트합니다.
정리를 해보겠습니다.
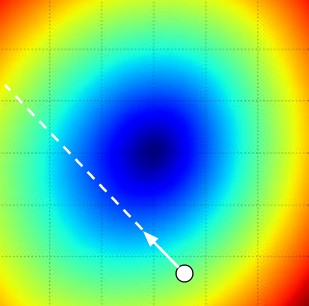
- loss function은 산 꼭대기에서 아래로 내려가는 것으로 최적화 과정을 설명했습니다. 특히 SVM loss 의 경우
loss function은 선형의 모양으로 가장 좋은 parameter 값인 파란색으로 이동해야 하는 경우였습니다.
-
loss function을 optimize한다는 것은 무작위로 시작해서 반복하며 더 나은쪽으로 이동한다는 핵심 개념에서 시작되었습니다.
-
gradient(기울기)는 그 함수값이 감소하는 가장 빠른 방향이었습니다. 이것을 유한 차분(finite difference, 즉 미분할 때 h의 값이 유한하다는 의미)를 이용하여 단순 무식하게 수치적으로 어림잡아 계산하는 방법도 살펴 보았습니다.
- 강의에서는 이러한 수치적 미분보다 해석적 미분이 더 좋다고 언급합니다.
-
parameter 를 업데이트할 때, 한 번에 얼마나 움직여야 하는지를 결정하는 것이
step size(learning rate, lr)이었습니다. 학습 속도에 영향을 주는 hyper parameter입니다.- 이 값이 너무 낮으면 너무 느려지고, 너무 높으면 빨라지지만 위험한 점이 있다. 이것에 대해선 또 다음 강의에 다룬다고 합니다.
-
수치적 미분과 해석적 미분의 방법
- 수치적 gradinet: 단순하지만 근사값이고 비효율적임
- 해석적 gradient: 정확하고 빠르지만 손으로 계산해서 실수할 수 있음
- 실제 응용에서는 해석적인 gradient을 씁니다. 또한, 둘 다 구한 다음 비교해보고, 틀린 경우 고치는 gradient check 과정을 갖습니다.
-
반복적으로 루프(loop)를 돌려서 gradient를 계산하고 parameter를 업데이트하는 Gradient Descent 알고리즘을 소개했습니다!


꼼꼼한 정리 감사합니다!