👩🔬 이번에는 혼공머 책의 챕터 4-2 파트입니다.
참고 자료
📚 혼자공부하는머신러닝+딥러닝, 한빛미디어
📄 Gradient Descent - 경사하강법, 편미분, Local Minimum
📑 경사하강법(Gradient Descent)
🔗 배치와 미니 배치, 확률적 경사하강법(Batch, Mini-Batch and SGD
🔗 딥러닝 용어정리, MGD(Mini-batch gradient descent), SGD(stochastic gradient descent)의 차이
이번 단원에서 나오는 키워드
- 확률적 경사 하강법(SGD)
- 미니배치 경사 하강법(Minibatch gradient descent)
- 배치 경사하강법(Batch gradient descent)
- 손실 함수(loss function)
- 로지스틱 손실함수(logistic loss function)
- 크로스 엔트로피 손실함수(cross entropy loss function)
- 조기 종료(early stopping)
- 힌지 손실(hinge loss)
- 서포트 벡터 머신(support vector machine)
우와! 차라리 죽여줘!🥺 이번 게시글에서는 경사 하강법에 대해서만 정리하도록 하겠습니다.
경사하강법이 왜 이렇게 많아?😡
- 경사하강법(Gradient descent)
- 배치 경사하강법(Batch gradient descent)
- 확률적 경사 하강법(SGD)
- 미니배치 경사 하강법(Minibatch gradient descent)
경사하강법 같은 경우는 정리한 적이 있으니 배치 경사하강법부터 차례대로 살펴보겠습니다. 🤦♀️
경사하강법(Gradient descent)
📄 Gradient Descent - 경사하강법, 편미분, Local Minimum
📑 경사하강법(Gradient Descent)
경사 하강법이란 최적의 예측 모델을 만들기 위해서 실제 값과 예측값과의 에러가 최소가 되도록 조정해 나가는 방법입니다.
비용함수(Cost Function)을 이용하여 예측 모델이 최소가 되도록 파라미터를 학습과정에서 변경해 나갑니다.
+) 책에서는 비용함수와 손실함수의 차이에 대해 언급하고 있습니다.
손실함수는 샘플 하나에 대한 손실을 정의하고, 비용함수는 훈련 세트에 있는 모든 샘플에 대한 손실함수의 합을 의미한다고 합니다. 참고하면 좋을듯 하네요!
배치 Batch란?
배치는 일괄적으로 처리되는 집단을 의미합니다. 한 번에 여러 개의 데이터를 묶어서 입력하는 방식인데, GPU의 병렬 연산 기능을 최대한 효율적으로 사용하기 위해 쓰는 방식입니다.
배치는 1 epoch당 사용되는 training dataset의 묶음이며, epoch의 의미는 훈련 세트를 한 번 모두 사용하는 과정을 의미합니다.
예를 들어, MNIST 데이터의 경우 이미지가 28x28으로 이루어져 있습니다.
1개의 데이터를 사용하는 신경망의 입력과 출력은
(1, 784) → (784, 100) → (100, 50) → (50, 10) → (10, 1)
로 (1, 784)는 1개의 이미지 입력인 784개 픽셀 데이터를 의미합니다.
(10, 1)은 10개 숫자에 대한 분류 결과입니다.
그러면 한 번에 100개의 데이터를 이용하는 방식은 100회 반복하는 것이 아니라, 신경망 계산은 행렬 연산이기 때문에 행렬의 크기만 키워 입력하면 됩니다.
(100, 784) → (784, 100) → (100, 50) → (50, 10) → (10, 100)
이렇게 계산하여 100개 데이터에 대한 출력을 한 번에 얻을 수 있습니다.
이런 계산 방식이 GPU를 활용한 병렬 연산 기능입니다. 그래서 Batch를 활용하면 학습 속도를 줄일 수 있습니다.
해당 내용 출처: https://light-tree.tistory.com/133
배치 경사하강법(Batch gradient descent)
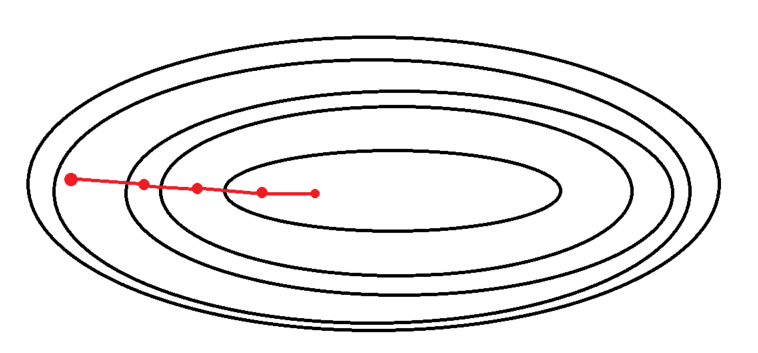
배치 경사 하강법은 경사 하강법의 손실 함수의 기울기 계산에 전체 학습 데이터셋에 대한 에러를 구한 뒤 기울기를 한 번만 계산하여 모델의 파라미터를 업데이트하는 방식을 의미합니다.
여기서의 배치(Batch)의 의미는 전체 데이터셋을 의미합니다.
정리하자면
전체 데이터셋에 대한 손실을 계산하고 그래디언트(기울기)의 반대 방향으로 parameter를 개선하여, 학습 속도(learning rate)를 이용하여 업데이트를 수행합니다.
배치 경사 하강법의 특징
- BGD은 한 스텝에 전체 데이터를 이용하기 때문에 연산 횟수가 적습니다.(1 epoch 당 1회 update)
- 최적해에 대한 수렴이 안정적으로 진행됩니다.
- 하지만 local optimal 상태가 되면 빠져나오기 힘듭니다.
- parameter 업데이트를 위해 모든 학습 데이터에 대해 저장해야 하므로 데이터가 큰 경우 전체 데이터를 못 읽거나 많은 메모리가 필요합니다.
확률적 경사 하강법(SGD)
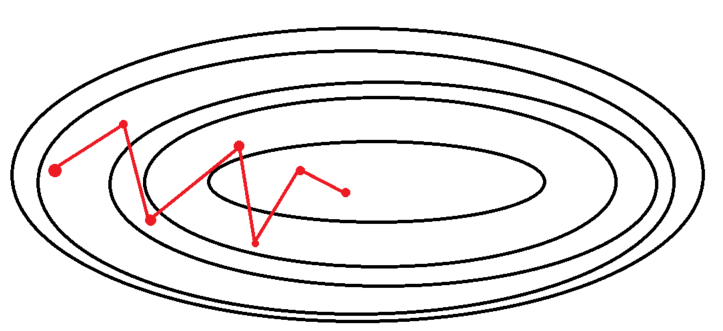
확률적 경사 하강법은 Stochastic Gradient Descent입니다. 여기서 Stochastic의 의미가 '확률적'이란 의미인데요. 왜 그런 표현을 썼을까요?
SGD가 바로 학습 데이터셋에서 무작위로 한 개의 샘플 데이터셋을 추출해 그 샘플에 대해서만 기울기를 계산하는 방법이기 때문인데요.
전체 학습 데이터 중 랜덤하게 선택된 하나의 데이터로 학습을 하기 때문에 '확률적'이라고 부릅니다.
추출된 데이터 한 개에 대해서 에러를 계산하고, Gradient descent 알고리즘을 적용하는 방법
모델의 레이어 층은 하나의 행렬곱이며, 여러 개의 묶음 데이터는 행렬로 생각할 수 있습니다.
여기서 하나의 데이터만 뽑아서 사용한다는 것은 그중 한 벡터를 뽑아 특정 레이어 층에 입력하여 '' 연산을 하게 됩니다.
확률적 경사 하강법의 특징
- 오로지 샘플 데이터셋에 대해서만 경사를 계산하므로 매 반복마다 다뤄야 할 데이터가 줄어들었고, 학습 속도가 빠르다는 장점이 있습니다.
- 같은 이유로 메모리 소모량이 매우 낮으며, 큰 데이터 셋이라 할지라도 학습이 가능합니다.
- 학습 중간 과정에서 진폭이 크고 배치 경사 하강법보다 불안정하게 움직입니다.
- 데이터를 하나씩 처리하기 때문에 오차율이 크고, GPU의 성능을 전부 활용할 수 없습니다.
- 손실 함수가 최솟값에 가는 과정이 불안정하다 보니 최적해(global minimum)에 정확히 도달하지 못할 가능성이 있습니다.
- 배치 경사 하강법과 반대로 local minimum에 빠지더라도 쉽게 빠져나올 수 있습니다. 또한, global minimum을 찾을 가능성이 SGD가 더 큽니다.
이러한 단점들을 보완하기 위해 나온 방법들이 Mini batch를 이용한 방법입니다.
확률적 경사 하강법의 노이즈를 줄이면서도 전체 배치보다 더 효율적인 것으로 알려져 있습니다.
미니배치 경사 하강법(Minibatch gradient descent)
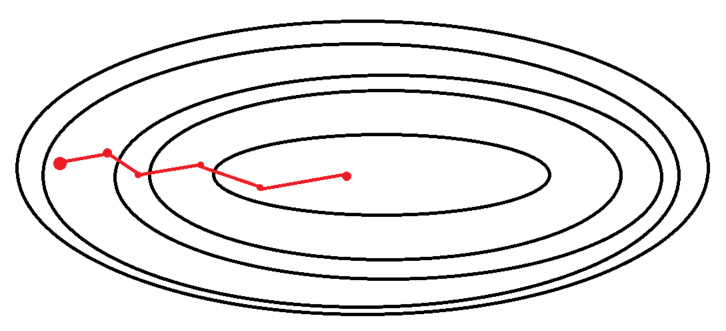
딥러닝 라이브러리 등에서 SGD를 얘기하면 최근에는 대부분 이 방법을 의미합니다.
SGD와 BGD의 절충안으로 배치 크기를 줄여 확률적 경사 하강법을 이용하는 방법입니다.
전체 데이터를 batch_size개씩 나눠 배치로 학습 시키는 방법이고, 배치 크기는 사용자가 지정합니다.
예를 들어, 1,000개인 학습 데이터 셋에서 batch_size를 100으로 잡았으면 총 10개의 mini batch가 나오게 됩니다.
이 100개씩의 mini batch를 갖고 한 번씩 SGD를 진행합니다. 1 epoch 당 총 10번의 SGD를 진행하게 됩니다.
정리하자면,
일반적으로 말하는 SGD는 실제로 미니 배치 경사 하강법(mini-BGD)이므로, 앞으로 SGD를 떠올릴 때 미니 배치 경사 하강법을 떠올리면 됩니다.
미니배치 경사 하강법의 특징
- 전체 데이터셋을 대상으로 한 SGD 보다 parameter 공간에서 shooting이 줄어듭니다.(미니배치의 손실 값 평균에 대해 경사 하강을 진행하기 때문에)
- BGD에 비해 Local Minima를 어느정도 회피할 수 있습니다. - 최적해에 더 가까이 도달할 수 있으나 local optima 현상이 발생할 수 있습니다.
- local optima의 문제는 무수히 많은 임의의 parameter로부터 시작하면 해결됩니다. → 학습량을 늘리면 해결됨!
- 배치 크기는 총 학습 데이터 셋의 크기를 배치 크기로 나눴을 때 딱 떨어지는 크기로 하는 것이 좋습니다.
- 1,050개의 데이터 셋이 있을 때batch_size를 100으로 하면 마지막 50개는 과도한 평가를 할 수 있기 때문입니다. - 만약 딱 떨어지지 않는다면, 50개의 데이터는 버리는 것이 좋습니다.
정리
-
Batch경사 하강법 1회에 사용되는 데이터의 묶음을 의미 -
배치의 크기에 따라 경사 하강법이 달라짐
-
Batch Size=전체 학습 데이터: 배치 경사 하강법(BGD) -
Batch Size=1: 확률적 경사 하강법(SGD) -
Batch Size=batch_size(사용자 지정): 미니 배치 확률적 경사 하강법(MSGD) -
보통
SGD라 함은미니 배치 확률적 경사 하강법을 의미함
-
-
Stochastic 방법은 1회 학습당 계산량이 줄어들고, shooting이 발생해 local minima를 피할 수 있음
-
Mini-Batch 는 전체 학습데이터를 배치 사이즈로 나누어서 순차적으로 진행함. 2의 n승이 좋음.
- Batch 보다 빠르고 SGD 보다 낮은 오차율을 가진다는 장점이 있음

5개의 댓글


잘 봤습니다!
epoch의 len(data) = batch의 len(data) = len(minibatch) * batch_size 인거 맞죠?
epoch이 전체 데이터셋을 학습한 단위이고
batch도 전체 데이터셋 길이라서 1 batch가 끝났으면 1 epoch이 끝났다고 할 수 있겠죠?
minibatch는 전체 데이터셋 길이 / 데이터 셋 나눈 상수 인거죠?
잘 정리된 자료 감사합니다 !