Q-learning
Q-learning은 optimal policy를 찾는 해결 방법이고, 모델 없이 학습하는 강화학습의 알고리즘이다.

Q-learning 주어진 state에서 주어진 action을 수행하는 것이 가져다 줄 reward의 기댓값을 예측하는 함수인 Q-function을 사용함으로써 optimal policy를 학습한다.
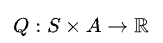
Q-function를 학습하고나면 각 state에서 최고의 Q를 주는 action을 수행함으로써 optimal policy를 유도할 수 있다. Q-learning 장점 중 하나는 주어진 environment의 모델 없이도 수행하는 action의 기대값을 비교할 수 있다는 점이다.
뿐만 아니라 Q-learning은 전이가 확률적으로 일어나거나 보상이 확률적으로 주어지는 환경에서도 별다른 변형 없이 적용될 수 있다. Q-learning은 임의의 유한 MDP에 대해서 현재 state에서 최대의 reward을 획득하는 최적의 policy를 학습할 수 있다는 사실이 증명되어 있다.
장기적인 reward를 계산할 때에는 보통 할인된 reward의 총계(sum of discounted rewards)의 기댓값을 계산하며, 여기서 지금으로부터 Δt 시간 후에 얻는 reward ᵞ는 ᵞ^Δt만큼 할인되어 ᵞ*ᵞ^Δt으로 계산된다.
이때 ᵞ는 0과 1 사이의 값을 가지는 할인 인자이며, 현재 얻는 reward가 미래에 얻는 reward보다 얼마나 더 중요한지를 나타내는 값이다.
Q-network(Deep Q-learning)
실제 문제를 풀어가기에는 Q-table 구성 사이즈가 너무 크다. 따라서 Network를 구성해서 문제를 해결한다. 주어진 input, output을 agent가 조절하면서 state, action을 주어 원하는 output을 얻어낸다. 작은 table을 이용해서 원하는 결과를 얻어낸다.
- state-action 조합을 표로 그린다
- 거기에 모든 Q-value를 사용한다
- 벨만 방정식을 이용해 업데이트한다
Experience Replay
우선, 연속된 sample들에 대한 batch들로부터 학습하는 것은 문제가 있다.
- sample들은 서로 연관되어 있다. -> 비효율적인 학습
- 현재 상태의 Q-network 파라미터가 다음 상태를 sample하는 것을 결정한다. (예를 들어, 지금 왼쪽으로 가는게 최적이라고 생각했다면 그 후에는 왼쪽에서 얻은 sample들만 가지고 학습을 진행하게 된다.)
이 문제를 experience replay를 통해 해결한다.
- 게임 에피소드가 play 됨에 따라서 상호작용 테이블 (st,a_t,_r_t,s(t+1)) 메모리를 지속적으로 리플레이 하면서 업데이트 하자.
- 연속적인 sample들 대신에 replay memory로부터의 상호작용들의 랜덤한 미니배치로 Q-network를 학습하자.
이를 통한 이점
1. 우선 위에서 발생하는 문제점들을 해결할 수 있다.
2. 하나의 샘플이 가중치 업데이트에 여러번 기여할 수 있다.(여러번 메모리에서 랜덤한 미니배치를 뽑기 때문에)
Deep Q-Learning with Experinece Replay
해당 내용 출처: 여기
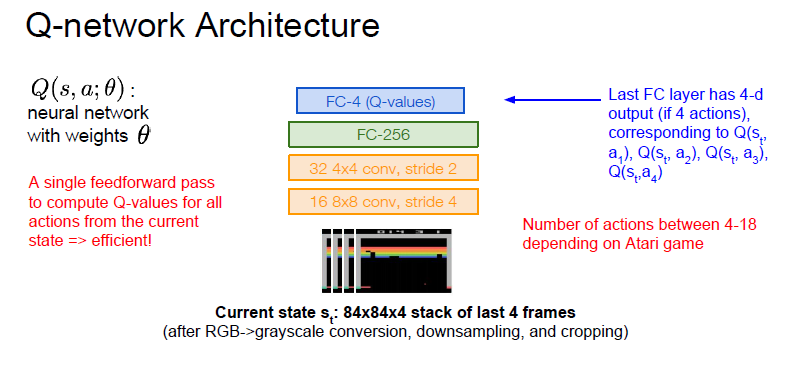
줄여서 DQN이라 하며, 신경망과 Q-learning을 결합한 모델이다. 위에서 사용했던 Q-table 대신 신경망을 사용해서, 그 신경망 모델이 Q-value를 근사해낼 수 있도록 학습시킨다.
그래서 이 모델은 주로 approximator (근사기), 또는 approximating function (근사 함수) 라고 부르기도 한다. 모델에 대한 표현은 Q(s,a;θ) 라고 하고, 여기서 θ는 신경망에서 학습할 가중치를 나타낸다.
RL에 Deep Learning(DL) 적용시 문제점과 해결방법
-
Deep Learning은 Label (정답)이 있는 Data를 학습시키는데, Reinforcement Learning은 Label이 없고, 가끔 들어오는 Reward로 학습을 시켜야하기 때문에, 제대로 된 학습이 되기 힘들다.
-
Deep Learning은 Data Sample이 i.i.d (서로 독립적)이라는 가정을 하지만, Reinforcement Learning에서는 다음 State가 현재 State과 연관성 (Correlation)이 크기 때문에 이 가정이 성립하지 않는다.
이런 문제점 때문에 단순히 Q-Table을 Deep Learning Model로 치환하는 것으로는 제대로된 학습 효과를 보기 힘들다. 따라서, DQN을 제시한 논문[1]에서는 Experience Replay라는 방법을 사용한다.
쉽게 말하면, '강화학습 Episode를 진행하면서, 바로 DL의 Weight를 학습시키는 것이 아니라, Time-Step마다 [S(Current State), A(Action), R (Reward), S'(Next State)] Data set을 모아서 학습하자는 방법'이다.
이렇게 모은 Data를 Random하게 뽑으면, 각 Data 간의 Correlation이 줄어들기 때문에 2번 문제를 해결할 수 있다. 추가적으로, Data를 여러 번 재활용할 수 있다는 부수효과도 얻을 수 있다. 이렇게 만든 Experience-Replay Buffer는 N개의 크기를 갖고 있다가, Buffer가 꽉차면 일부 Data를 새로운 Sample로 대체하는 방식을 갖게 된다.

