
📄 PDF Download - Deep Residual Learning for Image Recognition
📄 Review Posting
📄 Review Posting 2
"Deep Residual Learning for Image Recognition" (CVPR 2016) - Kaiming He
Keyword
shortcut mapping: =
after-add mapping: f = ReLU
short-cut connection: , identity mapping을 위한 함수
Abstract
ResNet의 논문은 아주 유명한 논문이고, 저자가 Kaiming He입니다.
ResNet의 발표 이후로 Computer Vision task에서 accuracy를 크게 개선되었습니다.
이 논문이 나온 배경은 무엇일까요?
딥러닝 연구에서 layer가 더 깊어지면 깊어질수록 모델의 accuracy가 saturating되고 training error가 높아져서 성능 저하되는 degradation 문제가 발생합니다.
network의 깊이의 중요성에 대한 질문을 던집니다.
"Is learning better networks as easy as stacking more layers?"
더 나은 network를 학습하는 것이 layer를 더 쌓는 것만큼 쉬운가요?
라는 접근이었습니다.
이 말의 의미를 해석하기 위해
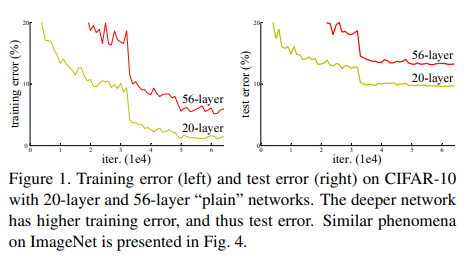
논문 첫 페이지에 나오는 Figure 1를 참고하겠습니다.
왼쪽은 training error, 오른쪽은 test error인데요. layer가 더 깊은 빨간색 line이 error가 더 높은 것을 확인할 수 있습니다.
위에 나왔던 질문에 대해 접근하기 위해서는 vanishing/exploding gradients 문제점이 학습의 obstacle이 된다는 점을 알아야 합니다.
layer가 깊어질수록 gradient가 vanishing되거나 exploding 된다는 점이었습니다.
이 문제를 normalized initialization이나 batch normalization 등으로 해결이 가능합니다.
training accuracy가 저하되는 것은 모든 system이 비슷하게 optimize하기 쉽지 않다는 것을 의미하는데요.
더 shallow한 architecture와 더 많은 layer를 추가하는 더 깊은 architecture를 고려하면 추가된 layer는 identity mapping이고, 다른 layer는 학습된 shallow model에서 복사됩니다.
따라서 더 깊은 model은 더 얕은 모델보다 더 높은 training error를 생성하지 않아야 합니다.
그 문제점을 해결하기 위해 제시한 새로운 개념이 Deep Residual Learning입니다.
layer에서 학습하는 양을 줄여서 optimization 과정을 더 쉽게 만드는 개념입니다.
Deep residual learning framework
Residual Network의 기본 구조는 아래 그림과 같습니다.
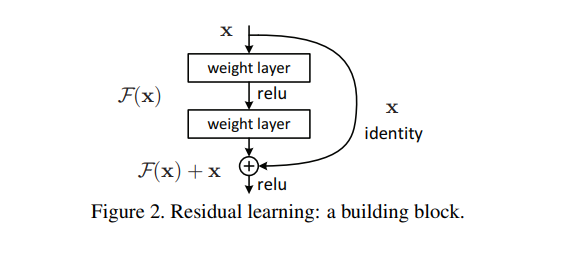
또한, 입력과 출력의 관계는 아래의 식으로 이해해보셨으면 합니다.
여기서 는 identity 함수 와 Residual 함수 의 합에 대해 activation function인 ReLU를 한 결과입니다.
Identity Mapping
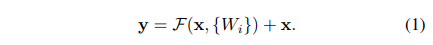
따라서 shortcut mapping하는 를 identity라 하고, ReLU를 통과하는 를 after-add mapping 이라 이름을 붙입니다.
Residual learning을 수행하는 block들에 대해 shorcut connection기법을 적용합니다.
위의 그림에서 는 바로 직전 layer까지 학습된 값을 의미합니다.
위 residual block을 통해 함수 를 identity mapping을 위한 short-cut connection이라고 부릅니다.
1개의 Residual Network만 보기 때문에 큰 차이가 없어보이지만, 이를 여러 개 연결시킨다고 생각해보면
addition 뒤에 오는 ReLU로 인해 blocking이 일어나서
이 과 의 합으로 표현되는 것이 아닌, 함수 f 처리를 꼭 해줘야 합니다.
따라서 는 residual block에 속하는 layer들에 대한 학습 결과와 그 전까지 학습된 결과를 더해준 값입니다.
Shorcut connection
ResNet에서 layer는 Residual function 를 학습하는데요.
그런 다음 가 나중에 결과에 추가되며 이를 shortcut connection이라고 합니다.
input/output channel을 변경할 때와 같이 와 의 차원이 같지 않으면 linear projection을 추가하여 차원을 일치시킵니다.
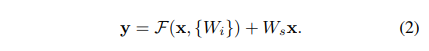
다시 식을 정리해보자면,
- = number of inputs
- = mapping function from input to output, normally H(x) would be learned)
- = residual function
- proposed:
- is learned and is recovered by adding
만약 layer가 2개 존재하는 함수 F를 생각해본다면, 식을
로 생각할 수 있습니다.
는 ReLU activation을 의미합니다.
요약: 입력값 를 출력값에 더하는 identity mapping을 수행하여 gradient가 잘 흐를 수 있도록 지름길처럼 도와주는 것을 shortcut connection이라고 부름
ResNet
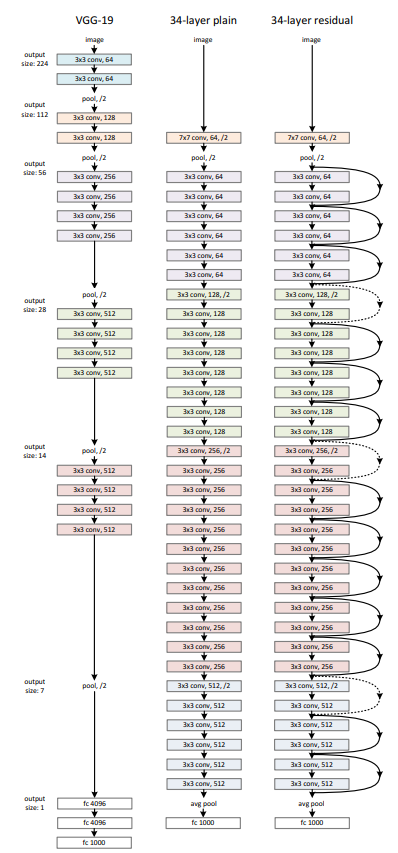

왼쪽은 VGG-19 model입니다. 중간과 오른쪽의 Network는 VGG-19 model을 기반으로 설계한 plain network, residual network입니다.
오른쪽 ResNet을 보면 input/output dimension이 다른 경우는 점선으로 표현되고 있습니다.
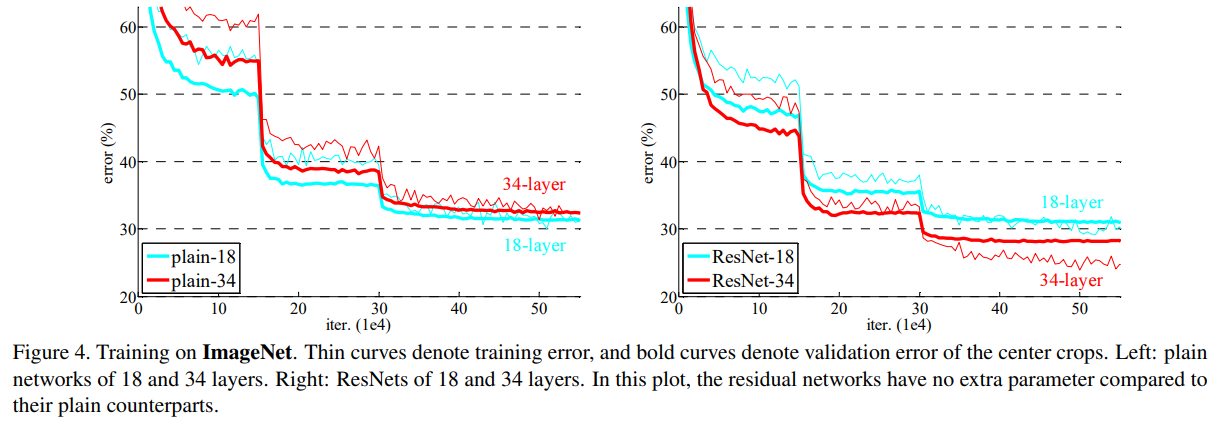
ImageNet dataset을 바탕으로 실험을 진행한 결과이며, ResNet layer의 수에 따라 error가 낮아짐을 확인할 수 있습니다.
가장 처음에 나왔던 Figure 1과 비교하여 생각해본다면, layer가 더 deep해졌지만, error가 떨어지는 결과로 성능을 입증하고 있습니다.
Bottleneck Architectures
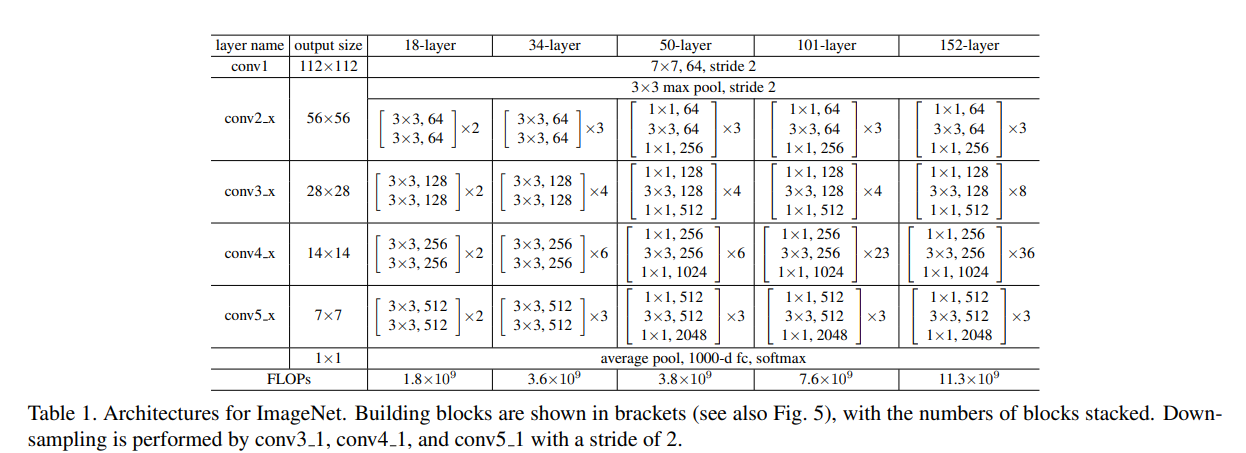
ResNet은 위 Table 1을 통해 확인해볼 수 있듯이, 18-layer부터 152-layer까지 layer를 점점 더 깊게 쌓았는데요.
layer가 더 깊어질수록 dimension의 크기가 커집니다.
그 의미는 parameter 수가 많아지게 되고, 복잡도가 증가합니다.
이를 해결하기 위한 아이디어가 bottleneck architectures입니다.
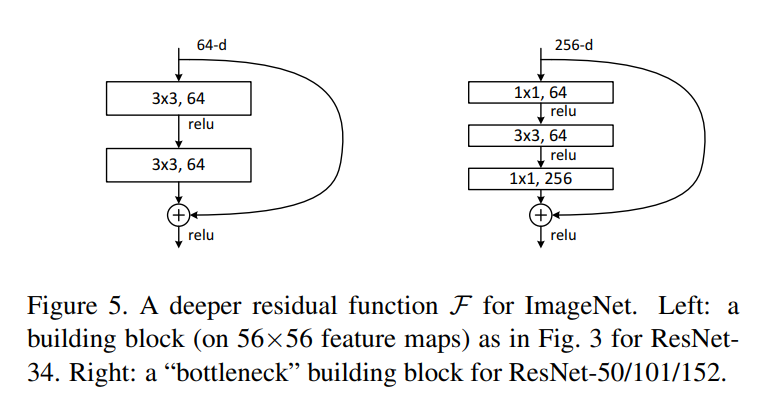
bottleneck architectures는 1x1 filter를 사용합니다.
1x1 filter를 사용하여 dimension의 크기를 줄인 후에
다시 1x1 filter를 사용하여 dimension의 크기를 늘립니다.
이 모습이 마치 bottleneck과 비슷하여 해당 용어를 빌려 사용했습니다.
위 그림에서 왼쪽은 64, 오른쪽은 256 크기의 dimension이 input으로 들어옵니다.
하지만 ResNet의 경우 bottleneck architecture를 이용하기 때문에 두 그림의 time complexity는 비슷하게 맞춰집니다.
따라서 ResNet은 layer의 수가 많아지더라도 모델의 크기가 다른 모델들에 비해 비교적 작습니다.
Conclusion
논문에는 classification 이외에 다양한 목적의 computer vision task의 실험을 하고, 결과를 보여줍니다.
관심 있는 분들은 논문을 통해 더 자세히 살펴보면 좋겠습니다.
결론을 정리해보면, 일반 CNN은 layer가 깊어질수록 오히려 error가 증가하는 모습을 보여주었는데
residual learning을 도입한 Deep residual learning framework을 통해 깊이가 증가함에 따라 error가 감소하고 plain network보다 훨씬 더 좋은 성능을 보여줍니다.
- residual learning은 optimize를 용이하게 합니다.
- degradation 문제를 해결하였습니다.
- deep neural network의 더 빠른 훈련 time을 가집니다.
- 더 깊은 network의 error를 낮췄습니다.
ResNet은 Image recognition, image detection, image localization, and segmentation tasks에서 많은 기여를 하였습니다.
결론: ResNet은 이전 model보다 더 깊은 layer를 가지지만, parameter수는 적으므로 속도는 빠르며 성능면에서도 더 뛰어남을 입증했습니다.
Backbone
덧붙이자면, ResNet은 backbone network로 많이 쓰입니다.
처음 프로젝트를 진행할 때 backbone이라는 단어가 많이 생소했는데요.
찾아보니 DeepLab model에서 사용되는 용어라고 합니다.
DeepLab이 computer vision task인 segmentation을 수행하는 framework다 보니 용어가 여기저기서 혼동되어 사용하고 있는 듯 합니다.
저는 해당 링크에서 조금 더 정확한 의미를 찾아보았으며, stackoverflow에 올라온 답변을 통해서 한 번 정리를 해보려 합니다.
backbone의 의미는 등뼈입니다.
CV의 여러가지 task가 몸의 각 부분이라고 생각하면 ResNet은 입력을 받아서 각 task에 맞는 모듈로 전달해주는 역할이라고 생각할 수 있습니다.
어떤 task를 맡아서 하든 neural network는 input image로부터 feature를 추출해야 합니다.
그래서 backbone의 의미는 feature를 추출하는 network를 나타냅니다.
결국 feature extractor는 network의 특정 feature representation을 encoding하는데 사용됩니다.
아까 앞에서 소개했던 DeepLap framework는 feature extractor을 wrapping한다고 하는데요.
feature extractor를 교환할 수 있어서 정확도와 효율성 측면에서 task에 맞는 다양한 model을 선택할 수 있다고 합니다.
그리고 backbone network로서의 그 역할을 ResNet이 수행한다고 생각하시면 될 것 같습니다.
그럼 이상 ResNet 논문 리뷰를 마치겠습니다!
