[논문 리뷰] Learning Deep Features for Discriminative Localization - Class Activation Map(CAM)
Paper Review

📄 PDF Download - Learning Deep Features for Discriminative Localization
📄 Review Posting

"Learning Deep Features for Discriminative Localization" (CVPR 2015) - Bolei Zhou
해당 논문은 2015년에 나온 논문으로 오래되긴 했지만, 아직 많이 인용되는 개념인 Class Activation Maps (CAM)을 다룬 내용입니다.
저는 논문을 title, abstract, figures, table 위주로 먼저 읽은 후에, introduction과 conclusion만 읽고 정리했습니다.
따라서 논문 전체 내용을 꼼꼼히 다 읽지 않아서 내용의 오류가 있을 수 있는데, 그런 경우엔 댓글로 지적 부탁드립니다.
Keyword 참고
GAP: global average pooling
CAM: class activation mapping
Abstract
해당 논문은 Global Averaging Pooling과 Class Activation Maps의 내용을 다루고 있습니다.
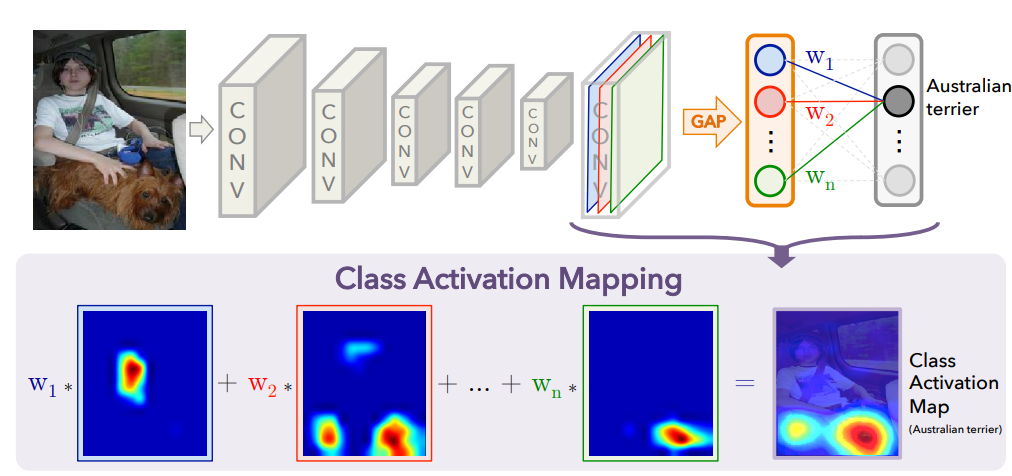
Figure 2. Class Activation Mapping: the predicted class score is mapped back to the previous convolutional layer to generate the class activation maps (CAMs). The CAM highlights the class-specific discriminative regions.
예측된 class score는 CAM을 생성하기 위해 이전 convolution layer에 다시 mapping됩니다. CAM은 class별 차아점을 두는 영역을 강조해 표시합니다.
해당 논문의 내용을 요약한다면
-
Global averaging pooling을 통해 ConvNet이 localizaiton 능력을 유지할 수 있다.
- Conv layer에서 object를 localize하는 능력이 뛰어남에도 불구하고, 이 능력은 classification을 위한 FC layer에서 손실됩니다. 이 작업에서 localization ability를 마지막 layer까지 유지하기 위한 machanism으로 Global Average Pooling을 제안하고 있습니다.
-
weakly-supervised, end-to-end, sigle-pass object localization을 위한 CAM 기술 소개
-
ILSVRC 2014에서 상위 5개 localization error 37.1%를 달성하고, fully-supervised AlexNet의 34.2%와 가깝게 결과를 냈습니다.
Convolution Neural Network이 가진 lcalization 기능과 GAP의 이점에 대한 연구를 진행하였습니다.
Computer Vision 연구에서 널리 적용되는 ConvNets은 본질적으로 pyramid 구조와 native translation invariance 속성을 가지므로
계층적인 방식으로 spatial feature map에서 추상적으로 representation을 증가하는 기능을 추출할 수 있습니다.
Global Average Pooling(GAP)
GAP의 개념은 pooling을 알고 계신다면 쉽게 이해할 수 있습니다.
보통 filter에서 최댓값을 추출해서 요약하는 max pooling을 흔히 더 잘 알 것 같은데, gap는 이름 그대로 평균값을 추출하여 요약하는 pooling layer입니다.
이는 overfitting을 방지하기 위해 regularization 장치로 연구되었습니다.
논문에서는 weakly-supervised에서 GAP와 GMP를 비교하였습니다.
GAP의 경우 전체 object의 localization을 식별합니다.
average pooling이 모든 discriminative regions(object의 잘 인식하는데 기여하는 기능)의 식별을 장려하는 반면에
GMP는 이미지의 가장 discriminative regions을 식별을 장려한다는 점에서 차이를 둡니다.
Class Activation Map(CAM)
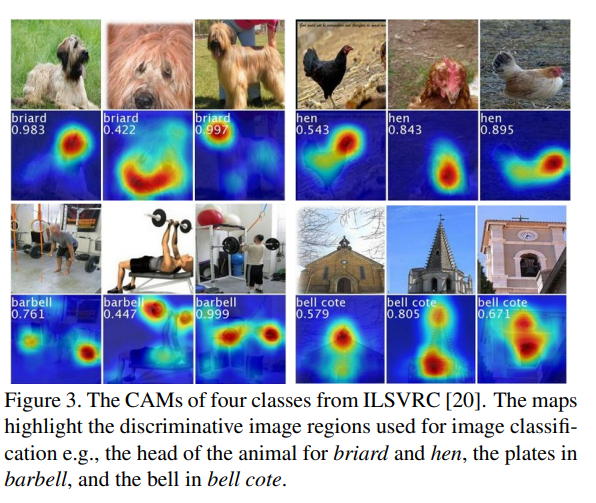
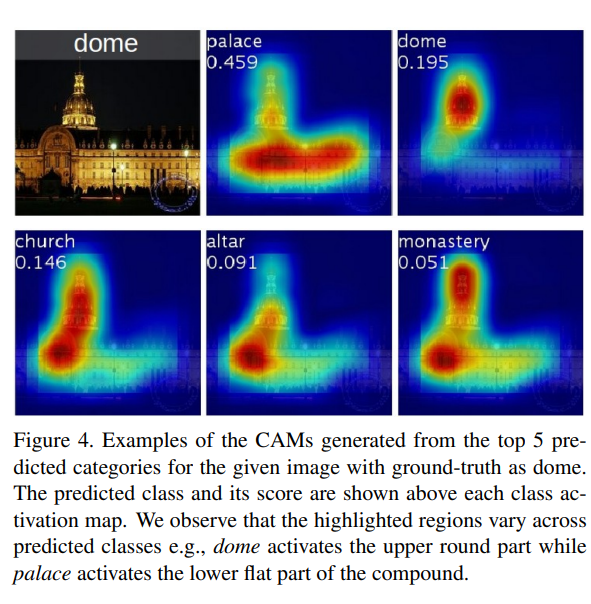
CAM은 마지막 convolutional feature map의 내적(dot product)와 FC-layer의 Class별 Weight(GAP 이후에 적용됨)의 합으로 설명할 수 있습니다.
이것은 공식적으로 다음과 같이 설명됩니다.
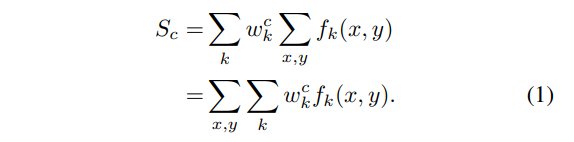
따라서 저자는 CAM을
"a weighted sum of the presence of visual patterns at difference spatial location"
이라 설명합니다.
또한, 마지막 convolutional feature map의 해상도에 따라 CAM은 input image의 discriminative regions을 시각화하기 위해 upsampling하며,
softmax/sigmoid output function을 통해 전달되어 image-level classification label을 생성합니다.
Experiments
3가지 ConvNet baselines인 AlexNet, VGGNet and GoogLeNet에서 8개의 classification dataset에 대한 CAM을 weakly-supervised bounding box localisation를 위해 ILSVRC 2014 및 CUB-200–2011 데이터 세트와 함께 평가합니다.
classification datasets에 대한 실험을 통해 2가지 결과를 얻습니다.
첫째, 해당 GAP는 localization information를 유지하면서 baseline model의 분류 성능에 심각한 영향을 미치지 않습니다.
Conv 레이어를 추가하여 조정하는 바닐라 AlexNet 제외됩니다.
둘째, spatial feature와 semantic features 사이에서 trade-off가 존재합니다.
여기서 Conv layer를 제거하면(더 높은 mappping 해상도를 얻기 위해, 즉 마지막 convolution feature map이 덜 downsampling됨) localize에는 이점이 있지만 분류에는 해가 됩니다.
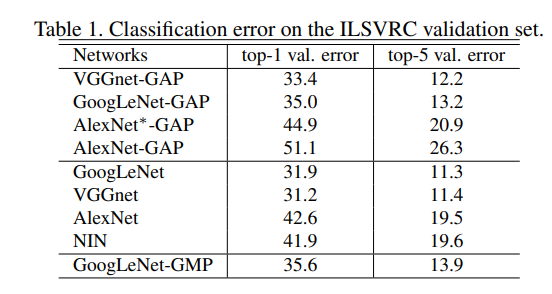
이것은 Conv layer를 제거한 후 표 1의 top-5 error 및 top1 error가 약간 증가한 것을 보여줍니다.
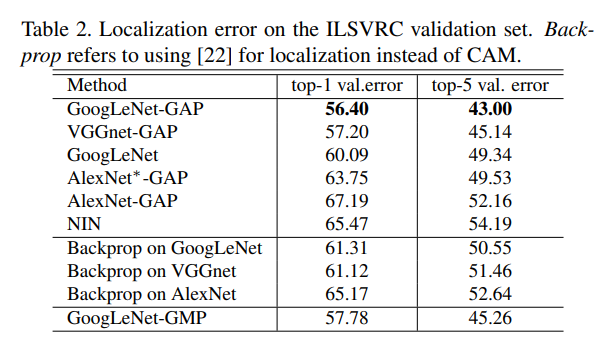
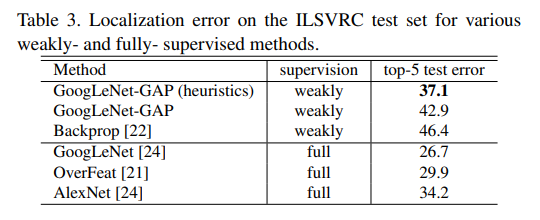
표 2와 3은 CAM 방법이 이전 방법([4]의 역전파 및 [5] 의 네트워크 내 네트워크 포함)과 vanilla(이미지 수준 레이블에 대해 교육됨) ConvNet baseline보다 더 잘 localize하는 것을 보여줍니다.
특히 GoogLeNet-GAP(휴리스틱 포함)은 image-level classification label에 대해 학습을 했지만
fully-supervised(bounding box annotations에 trained됨) AlexNet의 결과에 가까운 결과를 달성합니다.
저자는 3가지 설정으로 GoogLeNet-GAP에 대한 결과를 보고합니다.
- image-level label이 있는 weakly-supervised 접근 방식
- croppings을 사용하는 generation-to-generation 접근 방식
- bounding box annotation을 사용하는 fully-supervised 접근 방식을 사용.
classifcation result는 각각 63.0%, 67.8%, 70.5%로 대부분의 이전 방법을 뛰어 넘으며, GAP로 식별된 feature들이 분류 성능에 도움이 됩니다.
따라서 localization task 이상으로 유용함을 보여줍니다. - 마지막으로 bounding box 0.5 IoU(Intersection Over Union) 기준을 사용한 평가는 41.0%의 정확도를 제공합니다. (5.5%의 성능과 비교).
CUB-200–2011 데이터셋에 대한 실험을 통해, Zhou et al. GAP 접근 방식은 classifcation 및 localization task에 모두 적용할 수 있는 심층적이고 현지화 가능한 feature를 식별할 수 있음을 보여줍니다.

그 외에도 다양한 실험 결과를 제공하는데요.
해당 논문에 figure들만 봐도 재밌으니 한 번 논문으로도 직접 다 살펴 보시길 추천드립니다.

Pattern Discovery로 장면에서 informative한 objects를 인식하는 것에서 어디를 보고 판단했는지 알 수 있다는 결과를 해당 Figure 7에서 보여주고 있으며,

Figure 12는 VQA(visual question answering) 분야에서 predictor가 문제에 대한 답을 어떻게 맞혔는지에 대한 결과도 보여줍니다.
Conclusion
"Learning Deep Features for Discriminative Localization"에서는 classification 및 localisation 모두에 유용한 weakly-supervised method를 소개하고 벤치마크 데이터 세트에 대한 엄격한 실험을 수행하여 결과를 검증합니다.
이 결과는 CNN의 결과를 설명할 수 있는(explainable) GAP, CAM라 볼 수 있습니다.
Global Average Pooling 기능에 대한 새로운 통찰력과 Class Activation Maps의 개발을 통해 이 작업은 ConvNet의 내부 작동을 이해하는 데 크게 발전했습니다.
그 다음엔 GAP와 CAM을 같이 사용하는 grad-CAM이 나옵니다!
여기까지 아주 간단히 한 논문 리뷰를 마칩니다.🙂
