[논문 리뷰] FinDER: Financial Dataset for Question Answering and Evaluating Retrieval-Augmented Generation
0


논문 리뷰
- Title: FinDER – Financial Dataset for Question Answering and Evaluating Retrieval-Augmented Generation
FinDER는 S&P 500 기업의 10-K 연차보고서를 기반으로 실제 투자 전문가들의 5,703개 질의를 수집하여 금융 도메인에서 RAG(검색 기반 증강 생성) 시스템의 검색·재순위·생성 성능을 종합 평가할 수 있는 최초의 대규모 벤치마크 데이터셋을 제시한 논문이다.
1. 개요
FinDER는 금융 분야의 실제 질문을 대상으로 검색 기반 증강 생성(RAG, Retrieval-Augmented Generation) 시스템을 평가하기 위해 고안된 대규모 데이터셋이다.
- 5,703개의 실제 투자 전문가 질의–증거–정답 쌍으로 구성
- S&P 500 기업의 최신 Form 10-K 연차보고서를 원문으로 사용
- 각 질의는 도메인 전문가(CPA, 애널리스트)가 관련 증거 구간(문단·표·그림)을 직접 선별하고, 이를 기반으로 정답을 검증
이 데이터셋은 기존의 정형화된 QA 벤치마크와 달리, 약어·전문용어·문맥의 모호성을 포함한 실제 검색 행태를 반영하여 RAG 시스템의 검색 및 생성 능력을 종합적으로 평가한다.
2. 주요 구성 및 통계
2.1 데이터 구성
- Documents: S&P 500 기업 490곳의 최신 Form 10-K 연차보고서
- Questions: 초기 7,000개 실질 질의 중 증거 식별 실패 문항 제거 → 최종 5,703개
- Ground-truth Evidence: 10-K 보고서에서 추출한 핵심 패시지(문단/테이블/그림)
- Answers: 증거 구간에 근거한 정밀 계산 및 서술형 응답
2.2 질의 특징
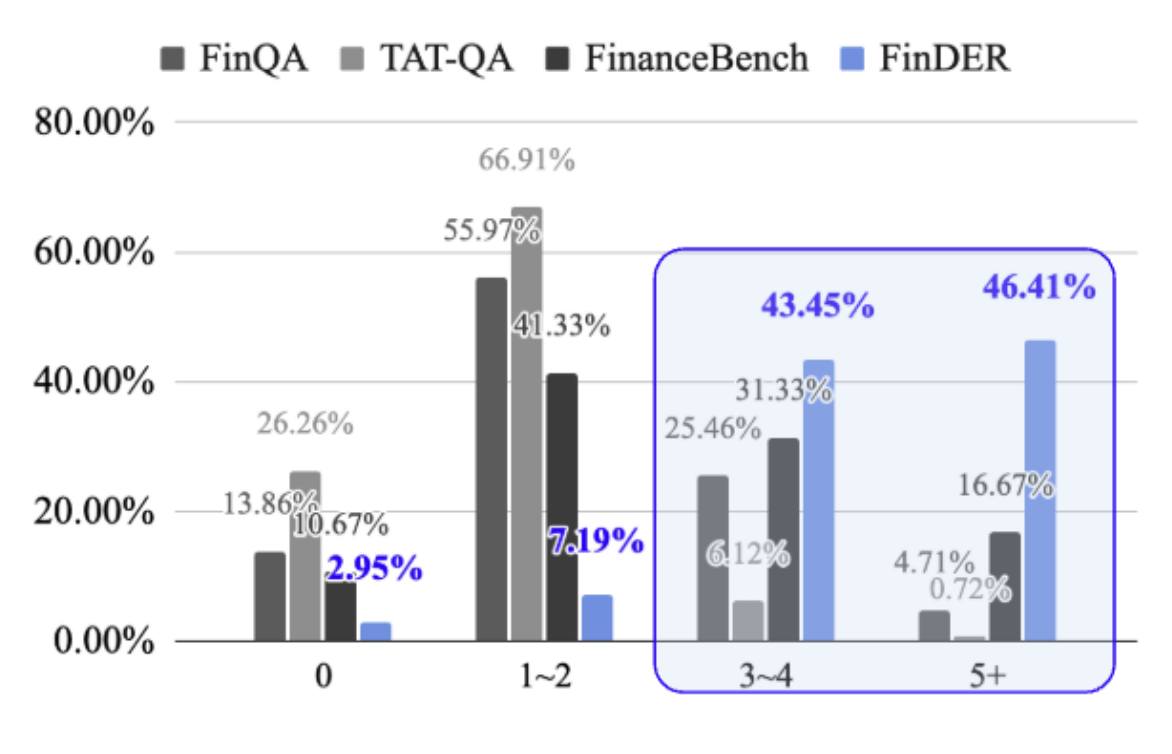
- 도메인 표현 사용량:
- 3~4개 전문용어 포함 질문: 43.45%
- 5개 이상 전문용어 포함 질문: 46.41%
- 질문 주제 분포 (Table 1)
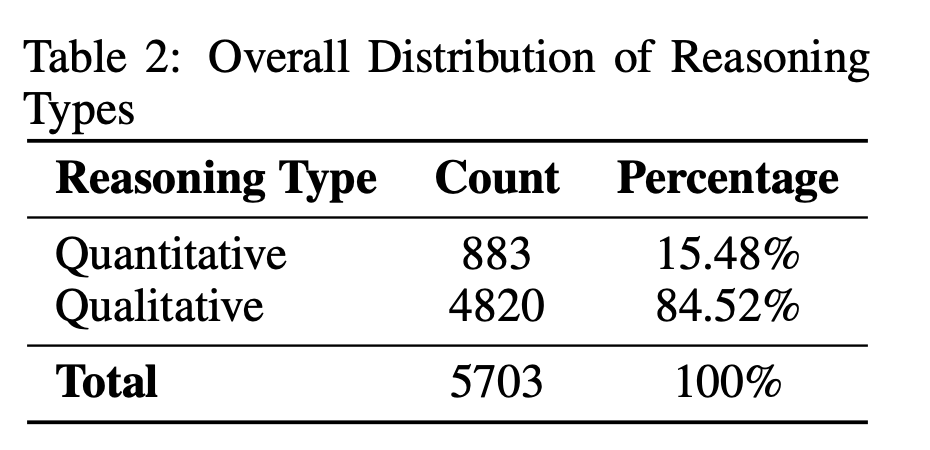
- 추론 유형 (Table 2)
- 질적(정성) 추론: 84.52%
- 양적(정량) 추론: 15.48%
- 양적 추론 세부 (Table 3)
- 조합적(Compositional): 49.83%
- 나머지(덧셈, 뺄셈, 곱셈, 나눗셈): 각각 8.49%~14.50% 분포
3. 실험 설정
3.1 검색(Retrieval) 모델
- Sparse: BM25 (k1=1.2, b=0.75)
- Dense:
- E5-Mistral-7B-instruct (디코더 기반)
- multilingual-e5-large-instruct
- gte-large-en-v1.5
- 평가지표: Context Recall (LLM 기반 평가, 0~100)
3.2 재순위(Reranking)
- 상위 10개 패시지를 LLM (Claude-3.7-Sonnet, GPT-o1, Qwen-QWQ-32B, Deepseek-R1-Distill)로 재순위 → 상위 5개 선택
- 지표: F1-score (Precision & Recall)
3.3 생성(Generation) 모델
- GPT-o1, Claude-3.7-Sonnet, Qwen-QWQ-32B, Deepseek-R1-Distill
- 세 가지 정보 설정:
- Without Context (검색 결과 없음)
- Partial Context (상위 10개 검색 결과)
- Perfect Context (전문가-주석 Gold Context)
- 지표: Correctness, Faithfulness (0~100)
4. 주요 결과 및 해석
4.1 검색 성능 비교
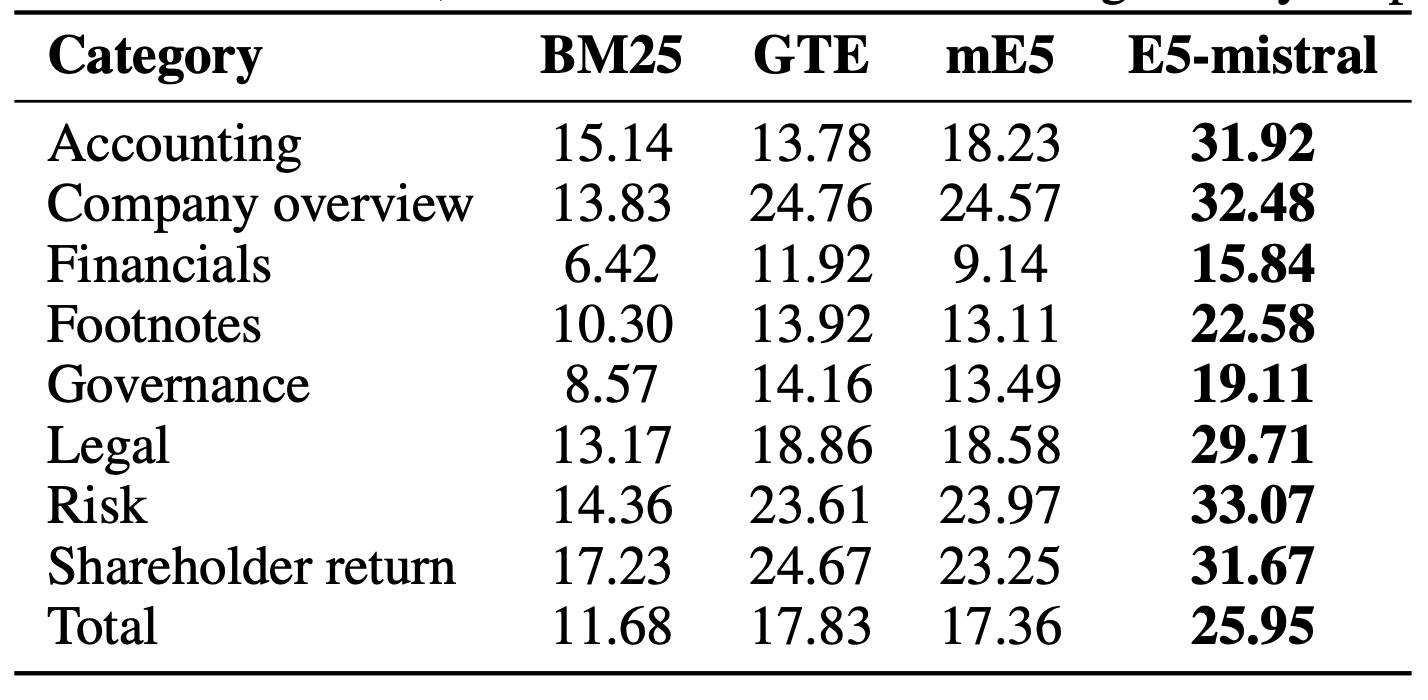
- E5-Mistral이 BM25 대비 2배 이상 우수
- 모든 신경망 임베딩 모델이 BM25를 상회, 금융 도메인 의미 포착에 강점
4.2 질의 양식에 따른 Precision 차이
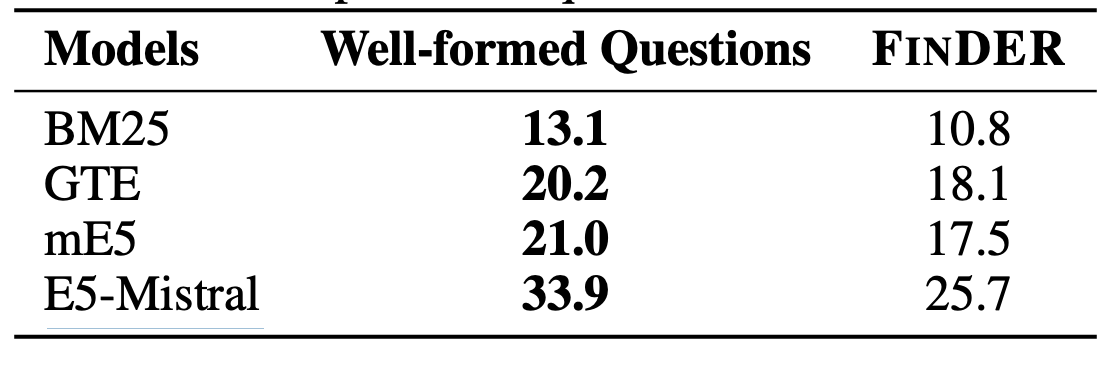
- 전문가가 명확히 다듬은 질의 대비 실제 질의에서 Precision 하락
- 실제 금융 질의의 모호성이 검색 정확도 저하 원인
4.3 재순위 성능
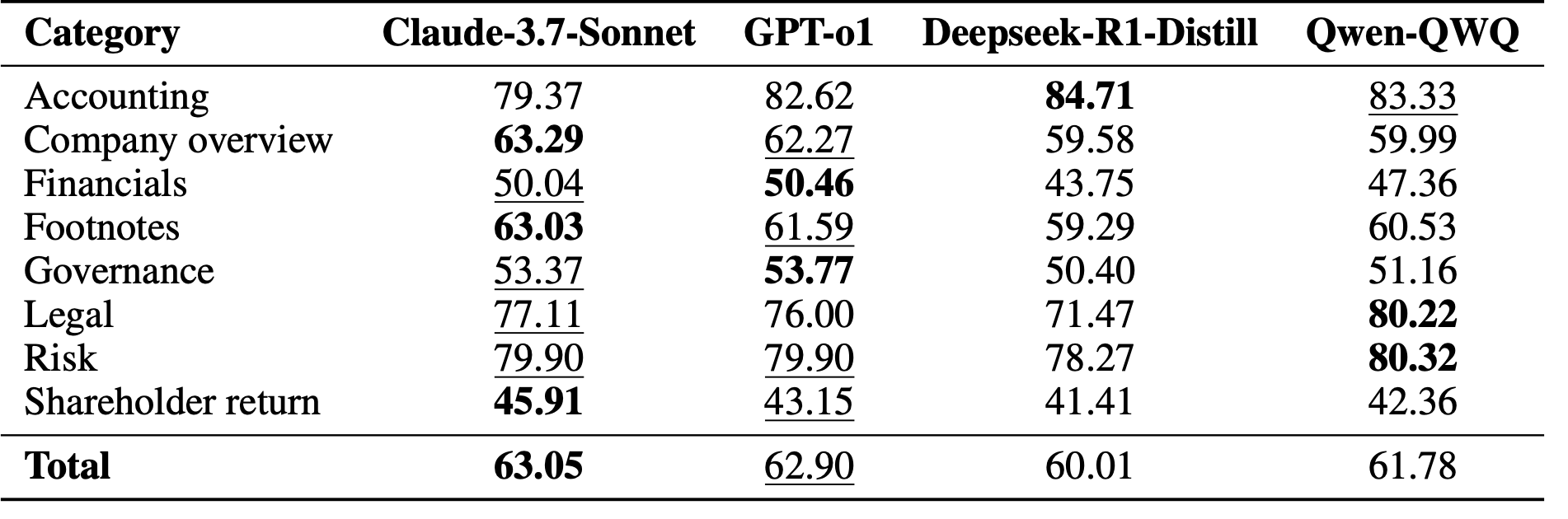
- 전체 F1: Claude-3.7 (63.05), GPT-o1 (62.90), Qwen (61.78), Deepseek (60.01)
- LLM 기반 재순위가 Retrieval 단계 노이즈 완화
- 모델별로 도메인 카테고리 편차 존재
4.4 생성 성능 (Table 7 & 8)

- Partial Context 환경에서 GPT-o1, Qwen-QWQ가 정확도(Correctness) 선두 (∼32%)
- Faithfulness: Claude-3.7 최고 (84.75)
- Without Context: 전 모델 정확도 ∼10% 수준
- Perfect Context: 정확도 급상승 (Claude 66.48, GPT-o1 68.13)
핵심 인사이트:
1) 정확한 검색 및 Gold Context 제공 시 성능 대폭 향상
2) 재순위 단계가 실제 환경에서 Retrieval 노이즈를 효과적으로 보완
3) 단일 모델이 모든 금융 추론 과제에서 우월하지 않음
5. 기여 및 한계, 향후 과제
기여
- 실제 금융 전문가 질의를 반영한 고밀도 도메인 표현 데이터셋
- 검색→재순위→생성 전체 RAG 파이프라인 일관 평가
- 도메인 특화 검색 모델(E5-Mistral) 및 LLM 재순위 효과 입증
한계
- 일부 섹션에 대한 재현성 제약 (데이터셋 공개 시기 미정)
- S&P 500 연차보고서에 국한 → 비상장·신흥 시장 분석 미포함
향후 과제
- 동적 질의 재작성 및 온더플라이 쿼리 보강 기법 개발
- 다양한 금융 문서(MD&A, 분기보고서, 뉴스) 통합
- RAG 파이프라인의 실시간 처리 최적화
FinDER는 금융 QA 연구에 있어 실제 전문가 검색 행태를 반영한 최초의 대규모 벤치마크로, RAG 시스템의 검색력과 생성력 개선을 위한 핵심 자원으로 자리매김할 전망이다.

AI/ML Engineer