논문 리뷰
- Title: HiREC – Hierarchical Retrieval with Evidence Curation for Open-Domain QA
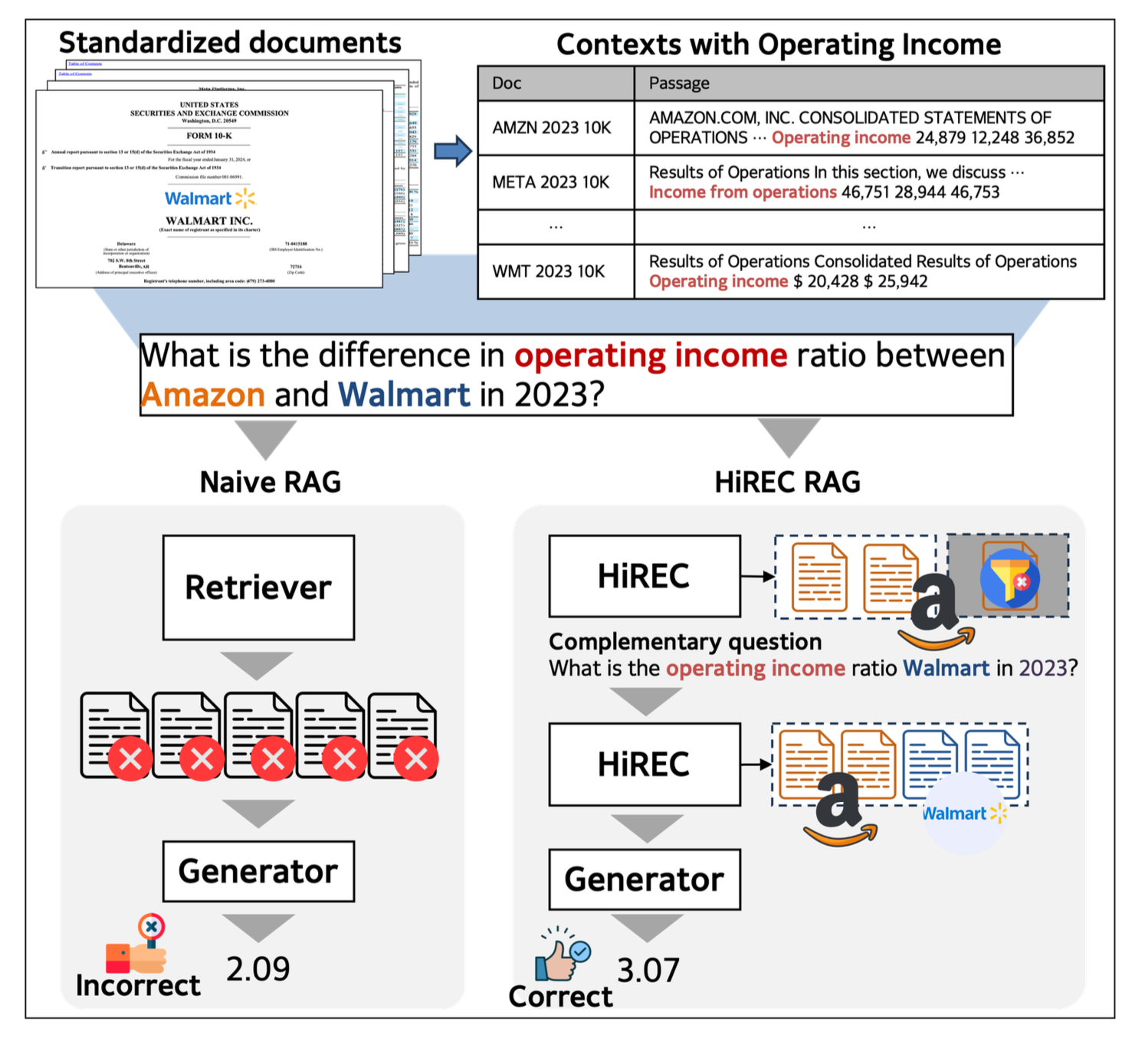
HiREC는 금융 문서에서 계층적 검색과 증거 선별로 오픈 도메인 질문 답변 성능을 높이는 방법을 연구한 논문이다.
1. 개요
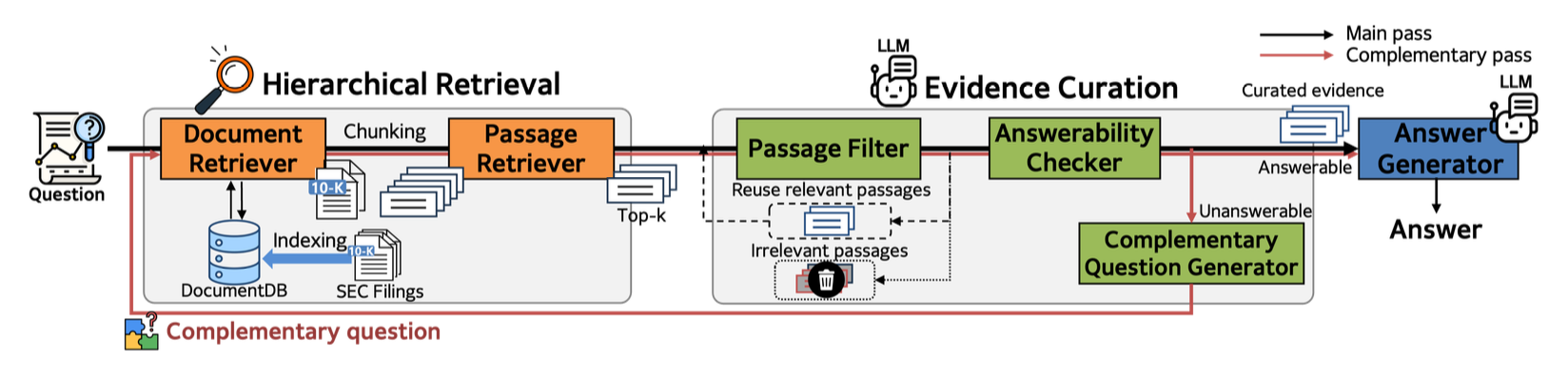
HiREC은 표준화된 금융 문서(SEC 보고서 등)에 최적화된 질의응답 시스템을 위해 계층적 검색과 증거 선별·보강 과정을 결합한 프레임워크이다.
이 프레임워크는 금융 문서의 표준화된 형식과 반복적 구조 문제를 해결하기 위해 설계되었으며, 단순히 검색하는 것이 아니라 증거의 품질을 지속적으로 개선하면서 완전한 답변에 필요한 모든 정보를 수집하는 것이 목표입니다.
- 대상: 145,897개의 SEC 문서(10-K, 10-Q, 8-K)
- QA 쌍: 1,595개 오픈도메인 질문-답변
- 핵심 기여
- 문서→패시지 순차 검색으로 중복·상세 불일치 해소
- 증거 선별(필터링) 및 보강(보완 질의 생성)으로 정보 누락 방지
- LOFin 벤치마크 공개
2. 주요 구성요소
2.1 계층적 검색 (Hierarchical Retrieval)
- 문서 검색
- 질문을 LLM으로 정제 후, bi-encoder로 후보 문서 상위 100개 선별
- cross-encoder로 상위 5개 재순위
- 패시지 검색
- 선택된 문서 내 패시지를 cross-encoder로 스코어링
- 상위 5개 패시지 추출
2.2 증거 선별 및 보강 (Evidence Curation)
- 패시지 필터: 질문과 무관한 패시지 제거
- Answerability Checker: 현재 증거로 답변 가능 여부 판단
- 보완 질의 생성: 정보 부족 시, 부족한 항목만 묻는 보완 질문 생성
- 최대 3회 반복하여 완전한 증거 확보
2.3 답변 생성
- 수치 문제: Program-of-Thought 방식으로 Python 코드 생성 후 계산
- 텍스트 문제: Chain-of-Thought 방식으로 단계별 추론
3. 벤치마크: LOFin
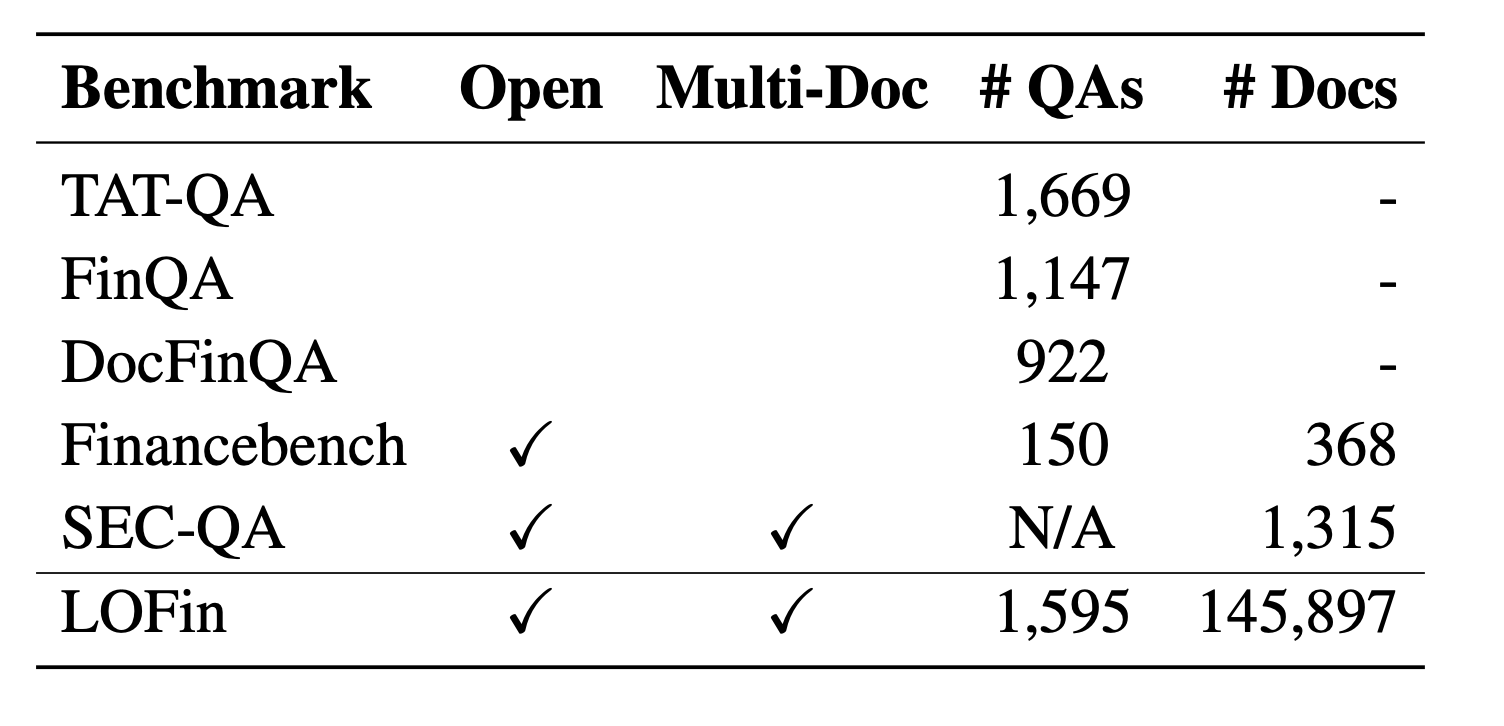
- 문서 수: 145,897
- QA 수: 1,595 (FinQA, Financebench, SEC-QA 기반)
- 다문서·다단계 추론 과제 포함
4. 주요 실험 결과 및 해석
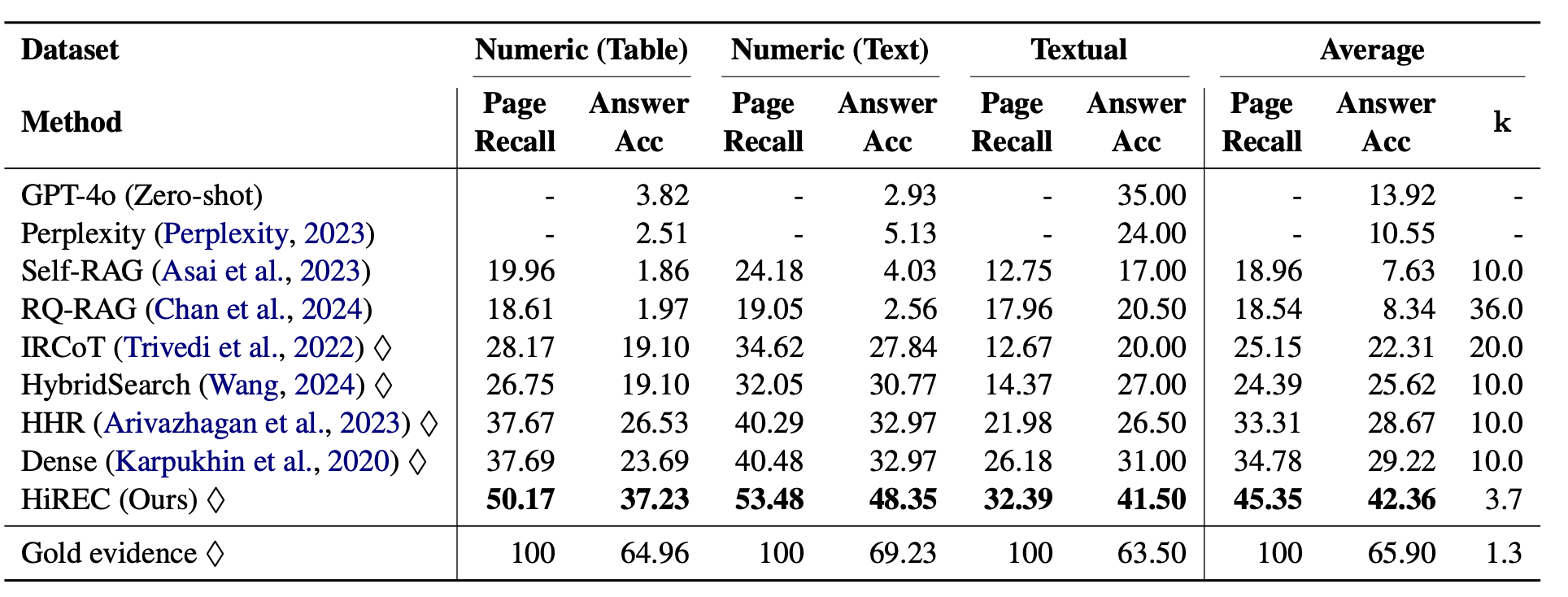
- 전체 성능: HiREC는 Dense, Self-RAG 등 기존 방법 대비 페이지 리콜 10%↑, 정답 정확도 13%↑
- Ablation:
- 계층적 검색 미사용 시 정확도 ~32.8% (기본 42.4%)
- 증거 선별 미사용 시 정확도 ~36.7%
- 효율성: 평균 3.7개 패시지만 사용, 토큰·비용 절감
- 다양한 LLM: GPT-4o 외에도 Qwen, Deepseek 등 소형 모델과 결합 시에도 우수
5. 인사이트 및 의의
- 표준화 문서의 반복 구조를 극복하는 계층적 검색 설계
- 증거 보강으로 정보 누락 문제 해소
- 대규모 실제 금융 QA 벤치마크 공개로 RAG 연구 촉진
6. 한계 및 향후 과제
- LLM 의존성: 변환·선별·생성 단계에서 LLM 품질 영향 큼
- 금융 도메인 특화: 다른 분야 확장성 검증 필요
- 실시간 처리: 최대 3회 반복 구조로 지연 발생 가능
HiREC는 대규모 표준화 문서 환경에서 RAG 시스템의 검색 정확도와 응답 완전성을 동시에 개선한 중요한 연구이다.

AI/ML Engineer