Pandas는 내부적으로 인덱스(index)를 가지고 있어서 필터링, 탐색, 그룹 질의 등을 매우 빠르게 수행해줍니다.
필터링 연산
조건에 따라 특정 데이터를 선택하는 방법인 데이터 필터링 연산에 대해 알아보겠습니다.
필터링 방법에는 몇 가지 방법이 있습니다.
행 선택, 열 선택, 컬럼 선택 후 특정 행만 선택 등 데이터를 필터링하여 불러올 수 있습니다.
df = pd.DataFrame({"A":[1,4,7], "B":[2,5,8], "C":[3,6,9]})
df실행 결과

df'컬럼명' 형식 사용
df['A']를 실행하면 df의 A 컬럼에 있는 [1, 4, 7] 이 나옵니다. 어떤 형식으로 나오는지 볼까요?
실행 결과

loc() 사용
loc는 라벨을 사용하여 행 또는 열을 지정하여 데이터를 추출합니다. 아래의 형식을 외워두세요.
df.loc[[행], [열]]
print(df.loc[0])df의 0번째 행은 0번 인덱스니까 각 컬럼의 0 인덱스 값이 나옵니다.
실행 결과

print(df.loc[0, 'B'])0번째 인덱스의 B 컬럼 값은? 2입니다. 2가 나옵니다.
print(df.loc[:, 'A'])는
실행 결과

가 나옵니다. ':'의 의미가 무엇일까요? : 이거는 전체를보여달라는 의미입니다.
iloc() 사용
loc 앞에 i 가 붙은 iloc를 보겠습니다.
iloc는 정수 인덱스를 사용하여 행 또는 열을 지정하여 데이터를 추출해줍니다. loc와의 차이가 느껴지시나요? loc는 라벨을 이용하는데 iloc는 무조건 정수 인덱스입니다.
iloc의 형식을 보고 갑시다.
df.iloc[[행], [열]]
print(df.iloc[0])은 앞에 나왔던 'print(df.loc[0])'과 같음을 알 수 있죠.
print(df.iloc[:,0])그렇다면 이것도? 네 맞습니다.
'print(df.loc[:, 'A'])' 와 같습니다.
print(df.iloc[0,'B'])는 어떻게 나올까요?
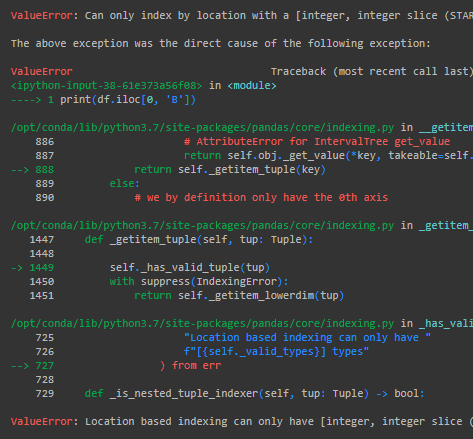
Error가 뜹니다. 이유는 iloc에 컬럼 값을 써서. 파이썬은 에러 이유를 잘 알려줍니다. 다른 언어도 그런지는 안 해봐서 모릅니다...
ValueError: Location based indexing can only have [integer, integer slice (START point is INCLUDED, END point is EXCLUDED), listlike of integers, boolean array] types
밑을 보면 integer, integer slice를 주라고 요구하네요. 그럼 요구에 맞게 고쳐줍시다. 'B' 컬럼은 몇 번 컬럼일까요? 0부터 시작하니 1이겠죠. 0은 'A'입니다.
print(df.iloc[0, 1])을 출력하면 0이 나옵니다.
그룹연산: groupby(), apply()
값을 선택하거나 데이터를 정렬할 때 기준이 되는 값을 뭐라 불렀죠? 네. key입니다. 일반적인 DB에서는 이 키 값에 따라 그룹을 묶은(grouping) 뒤 원하는 연산을 수행할 수 있습니다. Pandas에서 groupby() 연산이라 합니다.
개인적으로 groupby() 연산은 전처리 및 EDA, 시각화 과정에서 필수적인 연산 같습니다. feature 늘리면서 비교하고 싶을 때, 시각화하고 싶을 때 groupby를 거의 필수적으로 사용했습니다.
df = pd.DataFrame({'Columns1':['A','A','B','B','C','C','A','B'],
'Columns2':[10, 2, 30, -6, 8, 9, 5, 2]})
print(df)df에 두 컬럼을 추가해주었습니다.
실행 결과

import numpy as np
df.groupby(['Columns1']).max().apply(np.sqrt)실행 결과

이는 무엇을 의미하나요? sqrt는 제곱근입니다. 쉽게 루트를 씌어주었을 때 값이라 생각하면 되겠죠? 근데 앞에 max라는 연산 조건이 하나 더 있습니다. 그럼 Columns1의 A, B, C 에 해당하는 Columns2의 각각의 값중에서 가장 max한 값을 찾고 제곱근을 씌어주면 됩니다. 그 값이 나온 DataFrame 형태라 볼 수 있습니다.
노드에서는 gropuby() 객체를 사용하면서 apply 메소드를 통해 수식 연산에 활용하는 방법을 알려주고 있군요. 왜냐하면 데이터에서 필요한 요약 정보를 보기 위해서겠죠?
groupby(), apply()는 어차피 많이 나올테니 한 번 더 정리를 하고 가겠습니다.😝
groupby()
groupby()는 그룹별 집계, 요약합니다.
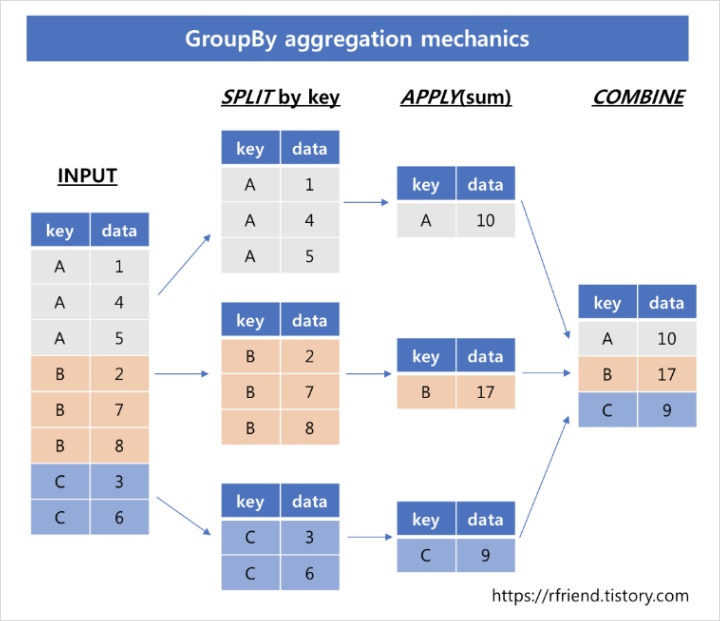
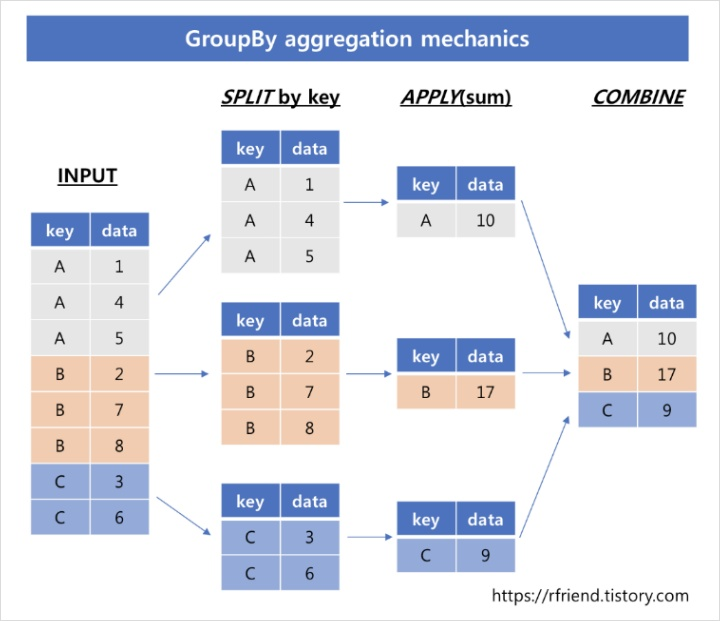
아래 그림은 그룹별로 split, 각 그룹별로 집계함수 사용 apply 후, 그룹별 집계 결과를 합치는 Combine 단계를 거칩니다.
위에 사용한 컬럼 2개인 데이터프레임보다 더 복잡한 데이터를 데려오겠습니다. 캐글의 일본 레스토랑 데이터입니다.
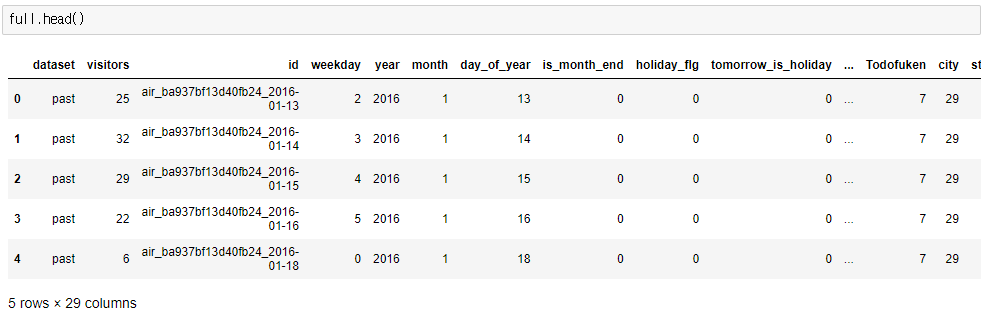
해당 full이란 데이터가 있습니다. 이는 레스토랑의 reserve, date, stores 등의 정보를 merge하여 저장했던 데이터입니다.
import seaborn as sns
temp = full.groupby(['air_store_id'])['visitors'].mean().to_frame()
f,ax = plt.subplots(1,1, figsize=(15,8))
sns.distplot(a=temp.visitors.values, ax=ax)
plt.xlabel('Visitors')
plt.ylabel('Density')
plt.title('Average visitors per restaurant')
plt.show()위에선 full 데이터에 groupby가 쓰였습니다. air_store_id 별로 visitor의 평균(mean)을 알고 싶다는 코드로 해석할 수 있습니다.
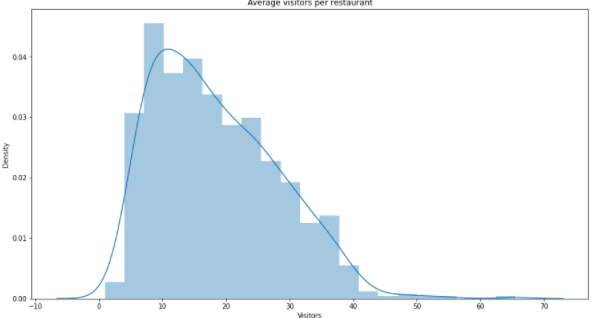
그러면 이렇게 시각화 할 때 사용하기에 편합니다!
# 예약건수, 방문자수, 방문시간 - 예약시간의 평균(hour) 추가
reserve_summary = reserves.groupby(['air_store_id', 'visit_date'])\
[['reserve_visitors', 'hours_gap']]\
.agg({'reserve_visitors': ['count','sum'], 'hours_gap': 'mean'})\
.reset_index()
reserve_summary.columns=['air_store_id', 'visit_date',
'n_reserves', 'n_reserve_visitors', 'reserve_avg_hours_ahead']
reserve_summary.head()해당 코드도 있습니다. groupby는 여러 개를 기준으로 만들어 줄 수 있다는 걸 볼 수 있네요. 뒤에 연산도 agg()를 통해 그룹별로 count, sum, mean 등의 연산이 가능합니다.
agg()
위에선 배열에 numpy의 apply를 활용한 연산을 추가했습니다. 하지만 위의 코드에서 보았듯이 gropuby()에게는 일반 연산도 가능하고, apply 연산도 가능하고, agg() 함수도 많이 사용합니다.
agg()를 추천하는 이유는 여러 개의 열에서 여러 가지를 한 꺼번에 사용이 가능하기 때문입니다.
- 모든 열에 여러 함수 매핑: group객채.agg([함수1, 함수2, 함수3, ...])
- 각 열마다 다른 함수 매핑: group객체.agg({'열1': 함수1, '열2':함수2, ...})
여기까지 다양한 기능을 살펴보았는데요. 솔직히 이해하는데 어렵진 않습니다. 쓰는게 어렵지. 다들 파이팅입니다~
