SQL은 데이터 연산 작업이 가능한 "쿼리(query)를 위한 언어"입니다. 파이썬 기반의 프레임 워크인 pandas를 이용하면 sql과 유사한 기능을 쓸 수 있습니다. pandas는 많은 파일에게 흩어져 있는 데이터를 효과적으로 모아 깔끔하게 처리할 수 있습니다.
데이터 합치기: merge, join, concat
- 학생 A: 국어점수 - 90점, 학교 - 고등학교
- 학생 B: 나이 - 12살, 사는 곳 - 서울
- 사원 A: 입사 연도 - 2009년
- 고객 A: 계좌번호 - 11111347234, 카드 소유 여부 - Yes
만약 이런 데이터가 있다면, 합치는 방법은 무엇이 있을까요? 사람마다 인덱스를 지정하는 방법이 있을 것 같고, 일정한 column으로 묶이지도 않습니다.
데이터를 합칠 때는 연관이 있어야 합니다. 서로 관계가 있는 데이터를 합칠 수 있습니다.
- pandas에서는 공통으로 연관이 되는 칼럼이 있는 경우에 대해 그 칼럼을 key로 지정해주어 연산이 가능합니다.
- pandas에서 제공하는 메소드는 merge(), join(), concat()이 있습니다.
pd.merge
import pandas as pd
df1 = pd.DataFrame({'Student': ['KimTaemin','HaJaehwa','JungSayoung','Sonjimin','Leesoomin','KangJun'],
'Korean': [90, 85, 88, 35, 40, 44],
'English': [80, 90, 40, 44, 55, 90]})
df2 = pd.DataFrame({'Student': ['KimTaemin','HaJaehwa','JungSayoung','Sonjimin','Leesoomin','KangJun'],
'Math': [100, 55, 38, 43, 68, 82]})
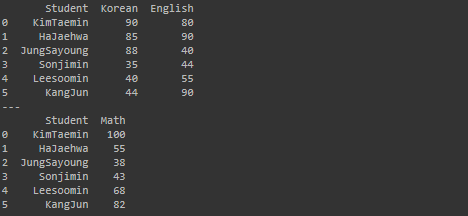
print(df1)
print('---')
print(df2)실행 결과
merge() 메소드는 공통 칼럼에 있는 값을 키로 합쳐줍니다. 여기선 'Student'가 공통이었기 때문에 자동으로 이를 기준으로 합쳐줍니다. merge() 를 이용해서 df1, df2를 합쳐주면 어떻게 나올까요?
pd.merge(df1, df2)실행결과
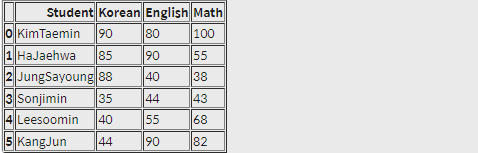
df1 뒤에 df2의 'math' 컬럼이 추가되었습니다.
pd.merge(df1, df2, on='Student')이렇게 코드를 작성해주면 기준이 되는 key 값이 'Student'가 됩니다. 직접 지정해 주면 더 명확한 데이터프레임을 만들 수 있습니다.
pd.merge(how='inner')
예제 데이터에 student 항목은 다 동일한 값이었습니다. 만약 학생 정보가 다르다면 어떻게 될까요? 일부만 같은 값을 만들어보겠습니다.
df1 = pd.DataFrame({'Student': ['KimTaemin','HaJaehwa','JungSayoung','Sonjimin','Leesoomin','KangJun'],
'Korean': [90, 85, 88, 35, 40, 44],
'English': [80, 90, 40, 44, 55, 90]})
df2 = pd.DataFrame({'Student': ['Jiyoungmin','KimTaemin'],
'Math':[44,33]})
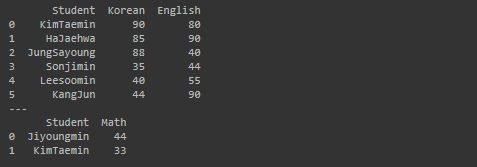
print(df1)
print('---')
print(df2)
실행 결과
inner join은 공통의 데이터에 대해서만 데이터를 합쳐주는 기능입니다. pandas가 아니더라도 관계형 DB 전반에 쓰이는 용어입니다. merge()의 how 매개변수 기본값이 inner입니다.
pd.merge(df1, df2, how='inner')df1과 df2에서 겹치는 건 'KimTaemin' 한 명뿐이었죠.
그래서
실행 결과

사실 how의 기본값이 inner이기 때문에
pd.merge(df1, df2)라고 적어도 같은 실행값이 나옵니다. 그럼 이제 inner가 아닌 다른 것도 궁금하시겠죠? 저도 사실 그닥 궁금하진 않습니다.🤣
pd.merge(how='outer')
이를 outer join이라 부릅니다.
pd.merge(df1, df2, how='outer')실행 결과
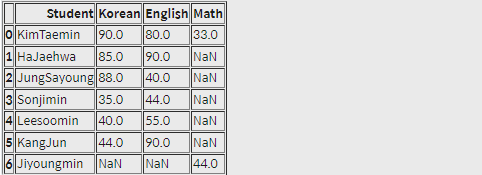
inner join보다 outer join시 인덱스가 더 늘어났습니다. 겹치지 않는 데이터까지 포함하여 합쳐주기 때문인데요. 그러면 없는 데이터는 어떻게 되었나요? 자동으로 NaN 값이 되었습니다.
NaN은 Not a Number의 약자입니다.
df.join
merge() 대신 join을 사용해보겠습니다. join은 DataFrame 클래스의 메소드입니다.
df1.join(df2, how='outer', lsufiix='_caller', rsuffix='_other')
# '_caller'인 df1 컬럼이 왼쪽에 가도록 배치실행 결과
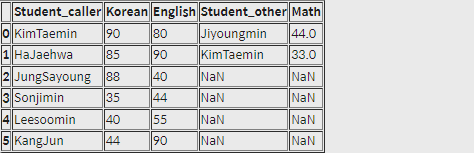
join 메소드 사용시, 이때까지의 결과값과는 확실히 다르네요. df1 전체가 왼쪽에 정렬되어 있습니다.
df.concat()
데이터를 합치는 또다른 방법은 concat()입니다. df.concat의 파라미터 axis를 1로 지정하면 column 방향으로 합칩니다.
df1 = pd.DataFrame({'Student': ['KimTaemin','HaJaehwa','JungSayoung','Sonjimin','Leesoomin','KangJun'],
'Korean': [90, 85, 88, 35, 40, 44],
'English': [80, 90, 40, 44, 55, 90]})
df2 = pd.DataFrame({'Student': ['Jiyoungmin','LeeJae','KimJaehee'],
'Korean': [44,73,100]})
print(df1)
print(df2)실행 결과
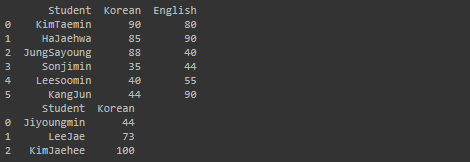
pd.concat([df1, df2], sort=False)실행 결과
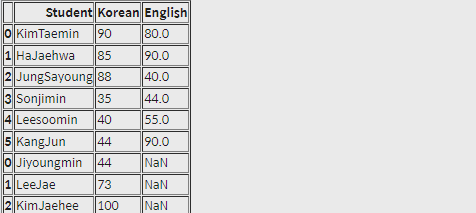
pd.concat([df1, df2], sort=False, ignore_index=True)실행 결과
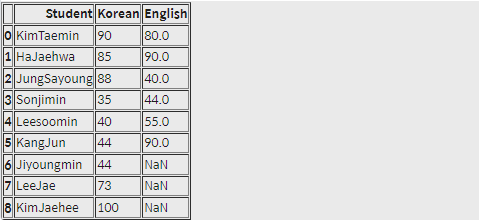
인덱스가 처음부터 시작하는 경우에는 ignore_index 인자를 True로 설정해주면 이어지는 인덱스를 만들 수 있습니다.
Pandas의 주요 메소드 merge(), join(), concat()를 사용해 데이터를 합치는 방법을 살펴보았습니다.
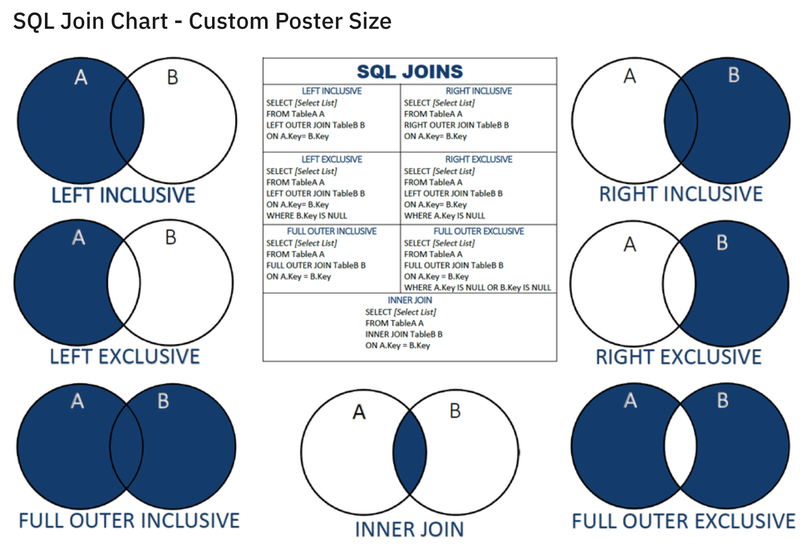
데이터를 합치는 join 연산은 데이터 연산에 있어 중요한 개념입니다. 위에선 join연산을 Pandas의 merge()와 join으로 구현해 보았는데, 데이터 연산용 언어인 SQL에서도 비슷한 단어와 의미로 표현합니다.
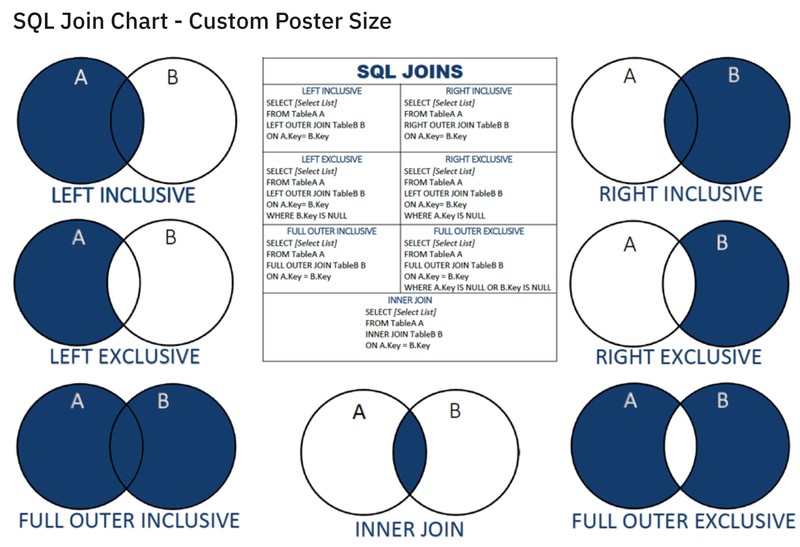
이미지 출처: https://www.reddit.com/r/SQL/comments/aysflk/sql_join_chart_custom_poster_size/
데이터베이스 정리 글
