OCR?
오늘은 OCR을 공부하려고 합니다. OCR은 Optical Character Recognition의 줄임말입니다.
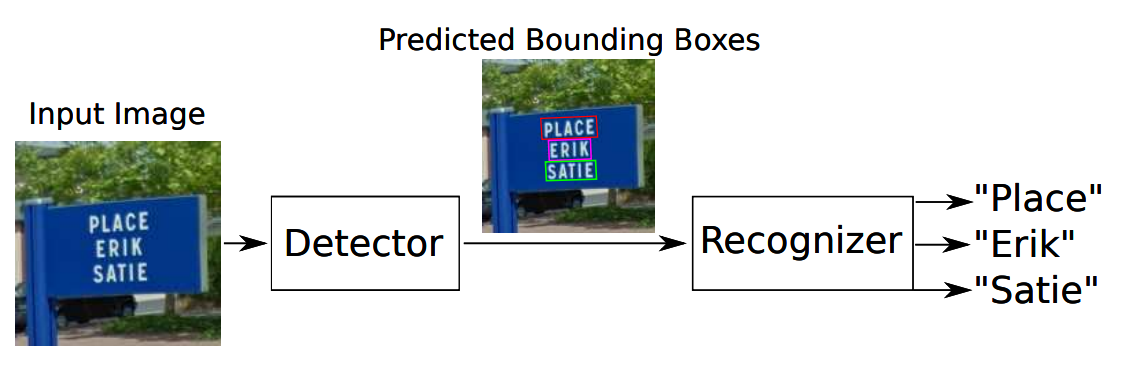
딥러닝 기반의 OCR은 위의 그림에서 보이는 것처럼, 이미지 속 문자를 읽는 문자 영역 검출 Text detection과 검출된 영역의 문자를 인식하는 Text Recognition으로 구분할 수 있습니다.
OCR = Text detection + Text recognition
Text detection
그동안 다루어왔던 object detection 태스크를 문자 찾아내기로 확장한 버전이라 생각할 수 있습니다. 그러나 Text detection은 단순히 object detection 기법 뿐 아니라 Segmentation 기법도 동원되며, 문자가 가지는 독특한 특성까지 고려한 형태로 지속적으로 발전해 왔습니다.
Text recognition
Text recognition은 검출된 영역의 문자가 무엇인지를 인식해 내는 과정입니다. MNIST Dataset의 이미지 안의 문자를 구분해 내는 작업과는 살짝 다른게, 문자 단위로 잘 분리된 텍스트 이미지만 존재하지 않기 때문입니다.
그래서 OCR 분야의 모델은 독특한 구조를 많이 가졌다고 하는데요.
Classification, Detection, Segmentation 등의 기법이 결합된 OCR을 공부해 보도록 하겠습니다!
혹시 OCR의 역사에 대해 관심이 있다면 여기를 클릭해 보십시오. 전 패스하겠습니다.
Before Deep Learning
OCR 기술은 이미 일상생활 속에 상용화 되어 있습니다. 자동차 번호판 자동인식, 신용카드 광학 인식 등 사례는 어렵지 않게 찾을 수 있습니다.
그렇다면 딥러닝이 OCR에 활용되기 전에는 어떤 방식으로 이미지 속 문자를 찾아냈을까요? 아래 링크의 논문에 예시가 있습니다.
위 논문은 브라우저에서 동작하는 OCR을 이용하여 웹에서 유저의 행동을 관찰하는 방법을 제안합니다. 온라인 마케팅, 광고 등에도 OCR 기술을 활용할 수 있다는 내용입니다. 이 논문에서 제안하는 솔루션 구성도는 아래와 같습니다.
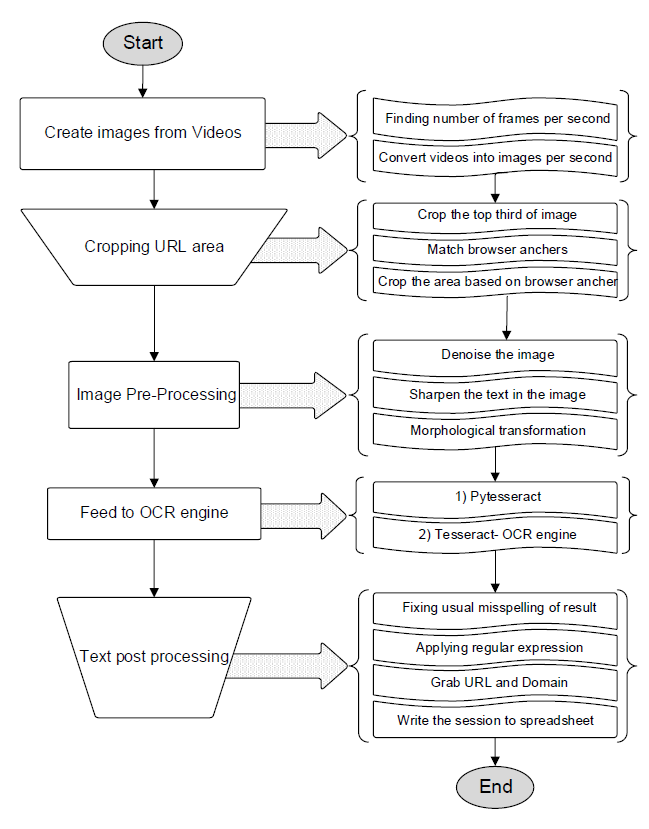
[2]
OCR engine으로 Tesseract OCR을 사용하려고 하는 것을 확인 할 수 있습니다. Tesseract OCR은 1985년 휴렛 패커드 사에서 개발이 시작되었고, 2005년에 오픈소스로 출시되었습니다. 현재는 구굴의 후원을 받는 오픈소스 OCR engine이라고 합니다.
최근엔 Tesseract ocr에도 LSTM을 적용하는 등 딥러닝 베이스 아키텍처로 발전 중입니다. (Tesseract ocr github)
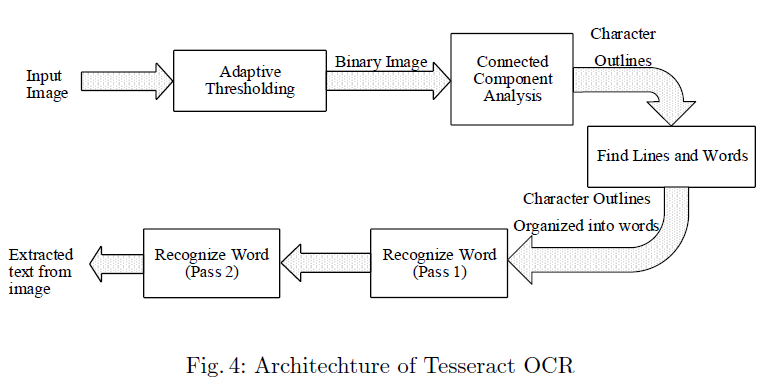
[2]
Adaptive Thresholding 단계에서 Input Image를 Binary Image로 바꾸고, 흑백으로 변환합니다.
이후 Connected Component Analysis 단계에서 문자 영역을 검출한 후 Find Lines and Word 단계에서 라인 또는 단어 단위를 추출합니다.
Recognize Word단계에서 단어 단위 이미지를 Text로 변환하기 위해 문자를 하나씩 인식하고 다시 결합하는 과정을 거칩니다.
딥러닝 기반의 OCR도 위의 경우처럼 기본적인 기능을 하기 위해 필요한 단계가 많습니다. 원하는 단위로 문자를 검출해내고, 한 번에 인식하도록 아케텍처를 단순화하여 빠른 인식을 이뤄냅니다.
요즘은 Detection과 Recognition을 동시에 해내는 End-to-End OCR 모델도 연구 중이라고 합니다.
Reference
1️⃣ STN-OCR: A single Neural Network for Text Detection and Text Recognition
2️⃣ From Videos to URLs: A Multi-Browser Guide To Extract User’s Behavior with Optical Character Recognition
