아마존의 해당 영상에서는 음악을 연주하는 DeepComposer을 소개했습니다. 이외에도 아주 많은 모델이 있습니다. 오늘은 이미지를 다루는 실습을 진행할 예정이어서 이미지와 관련된 응용 생성 모델 기법을 보고 가겠습니다.
Pix2Pix
Pix2Pix는 간단한 이미지를 입력할 경우 실제 사진처럼 보이도록 바꿔줄 때 많이 사용되는 모델입니다.
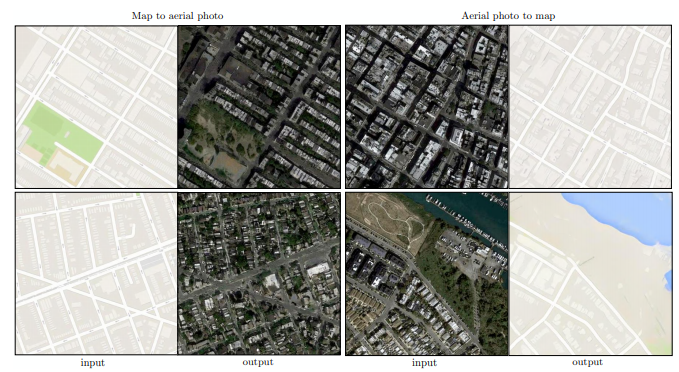
모델은 아래 그림처럼 단순화 된 이미지(Input Image)와 실제 이미지(Ground Truth)가 쌍을 이루는 데이터셋으로 학습을 진행합니다.

왼쪽의 Input Image를 받으면, 내부 연산을 통해 실제 사진 같은 형상으로 변환된 Predicted Image를 출력합니다. 학습 초기에는 모델이 생성한 Predicted Image가 Ground Truth 이미지와 많이 다르겠지만, 계속해서 Ground Truth와 얼마나 비슷한지 평가하며 점차 실제 같은 결과물을 만들어 냅니다. 이렇게 한 이미지를 다른 이미지로 픽셀 단위로 변환한다는 뜻의 Pixel to Pixel의 이름을 딴 Pix2Pix이 탄생했습니다.
Predicted Image에는 구조적인 정보를 바탕으로 건물 이미지를 만들며 그에 어울리는 세부 디자인을 생성하게 됩니다. 그 결과물은 Ground Truth와 완벽하게 똑같지는 않아도 비슷한 느낌을 주게 됩니다.
Pix2Pix 논문
논문의 제목은 Image-to-Image Translation with Conditional Adversarial Networks입니다. 17p의 논문을 읽고 오라고 주면서, 학습 시간은 10분을 주다니 너무하네요😢






논문 내에는 굉장히 다양한 이미지로 예시가 들어 있습니다. 17p나 되는 이유가 있었네요.😉 지금 읽을 시간은 없으니 pass하겠습니다.
대신 TensorFlow에서 소개하는 Pix2Pix를 보는 것도 좋은 학습 방법이라 볼 수 있겠네요!
Conditional Adversarial Networks를 사용한 이미지 간 변환
TensorFlow를 보고 학습하실 땐 주의점이 있습니다❗ 바로 무조건 English 버전으로 보는 것입니다. 한국어 판은 업데이트가 잘 되지 않습니다.
