Hash Table에 대해 알아보도록 하겠습니다.
해싱은 요소에 빠르게 액세스하기 위해 주어진 값을 특정 키로 매핑하는 데 사용되는 해시 함수라는 특수 함수를 사용하도록 설계된 중요한 데이터 구조입니다.
매핑 효율성은 사용 된 해시 함수의 효율성에 따라 다릅니다.
해시함수(hash function)란 데이터의 효율적 관리를 목적으로 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수입니다. 이 때 매핑 전 원래 데이터의 값을 키(key), 매핑 후 데이터의 값을 해시값(hash value), 매핑하는 과정 자체를 해싱(hashing)라고 합니다.
해시함수는 해쉬값의 개수보다 대개 많은 키값을 해쉬값으로 변환(many-to-one 대응)하기 때문에 해시함수가 서로 다른 두 개의 키에 대해 동일한 해시값을 내는 해시충돌(collision)이 발생하게 됩니다.
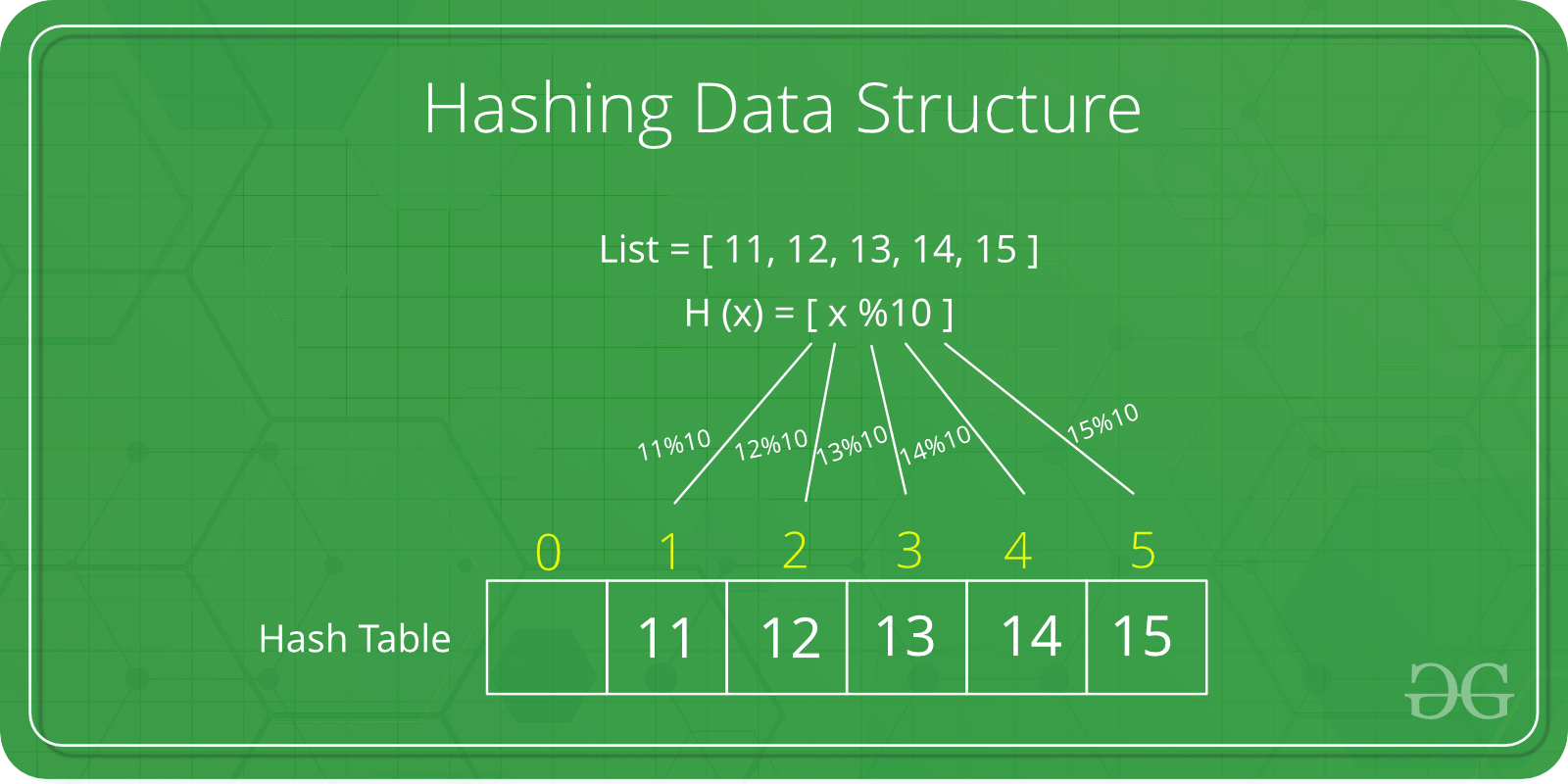
해시 함수
해시 충돌
- insert()
해시함수로 인덱스를 가져온다.
인덱스에 맞춰 버킷에 저장한다.
만약 limit의 80%가 차면 리밋을 확장한다. - retrive()
해시함수로 구한 인덱스에 맞춰 값을 찾는다. - remove()
해시함수로 구한 인덱스에 맞춰 버킷을 돌면서 동일하면 제거한다.

command and obey