Convolutional Neural Network
History
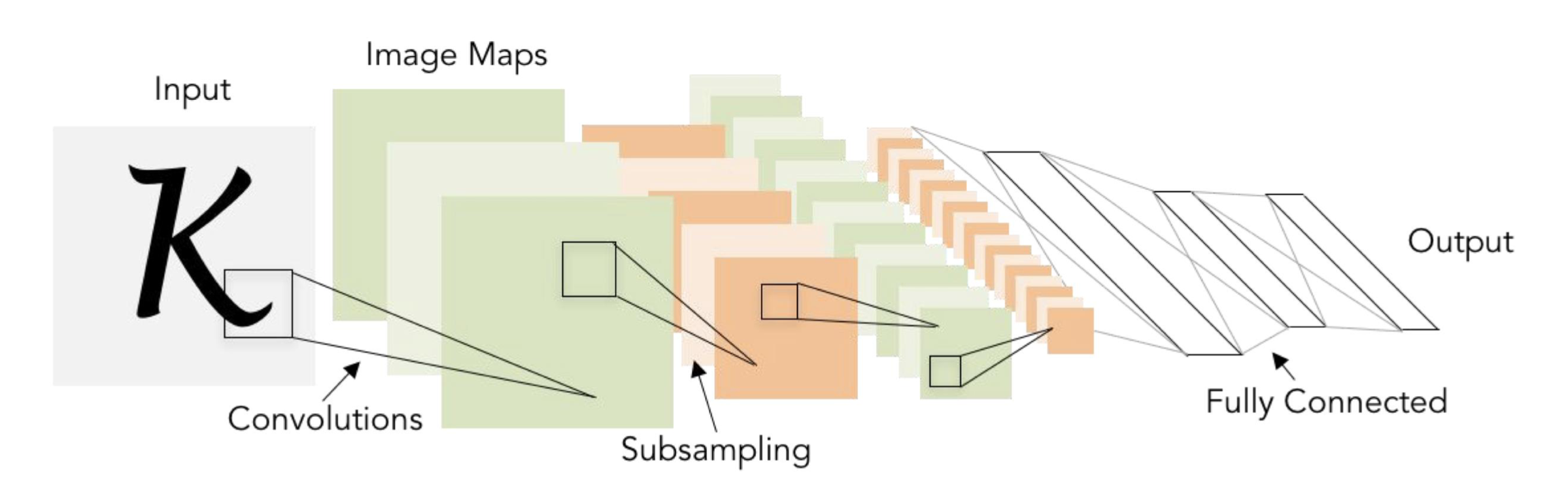
🔗 LeNet-5
- Gradient-based learning applied to document recognition
- 1998년
- 사람이 visual perception chain을 통해 물체를 인식하는 것처럼, transformations의 chain을 가지고 있어 pixel based information이 edges, shapes, objects, 그리고 aphabet 등으로 transform되기를 바란다.
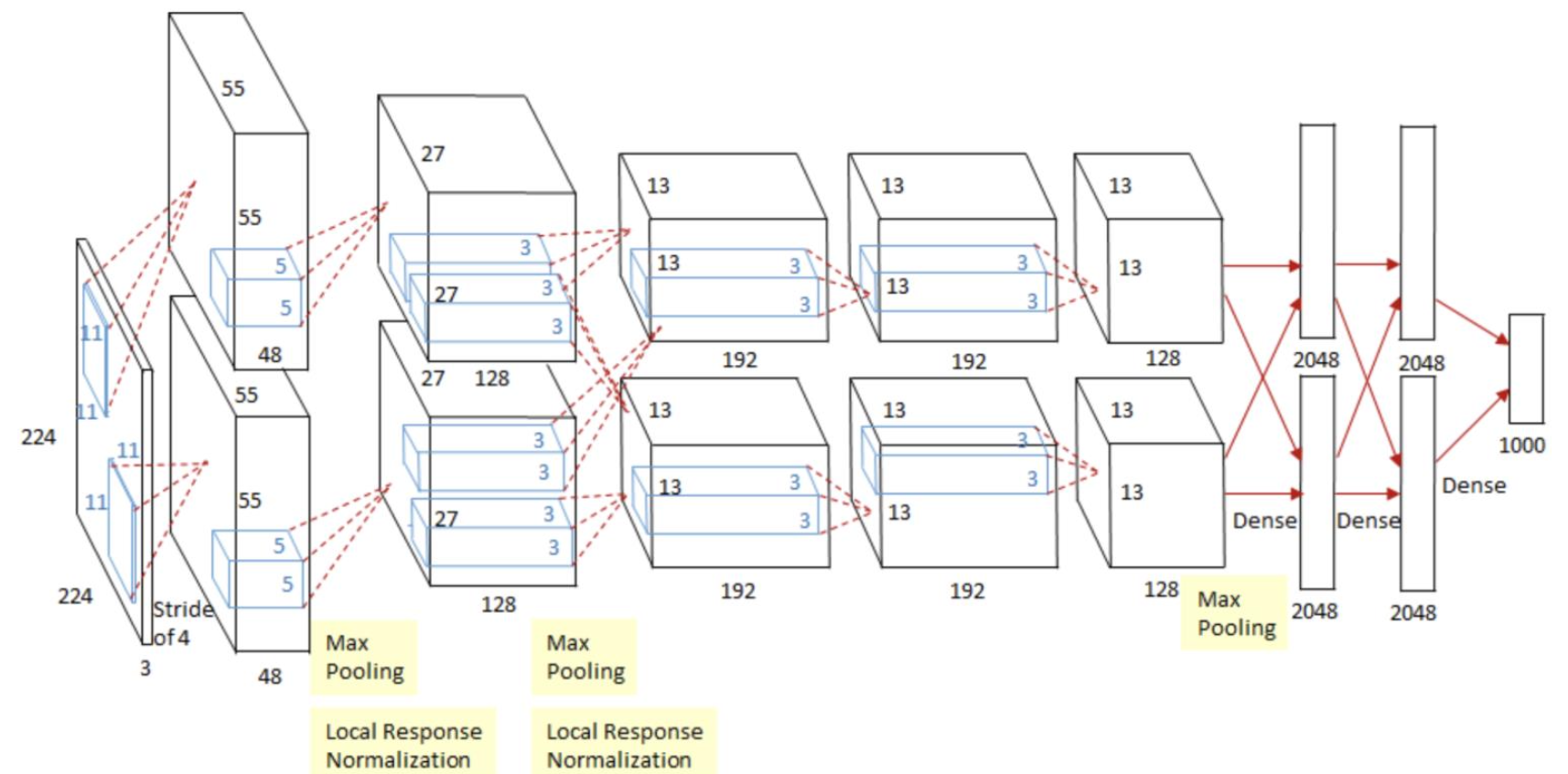
🔗 AlexNet
- ImageNet Classification with Deep Convolutional Neural Networks
- 2012년
- 두 개의 signal propagation 갈래가 있고, 끝에는 concatenate되거나 결합되어 있고 그러고 나서 1000개의 classes가 남는다(ImageNet class의 수).
ConvNet은 Transformer와 비교해서 훨씬 적은 parameter로 좋은 성능을 낸다. 훈련이 더 빠르게 된다.
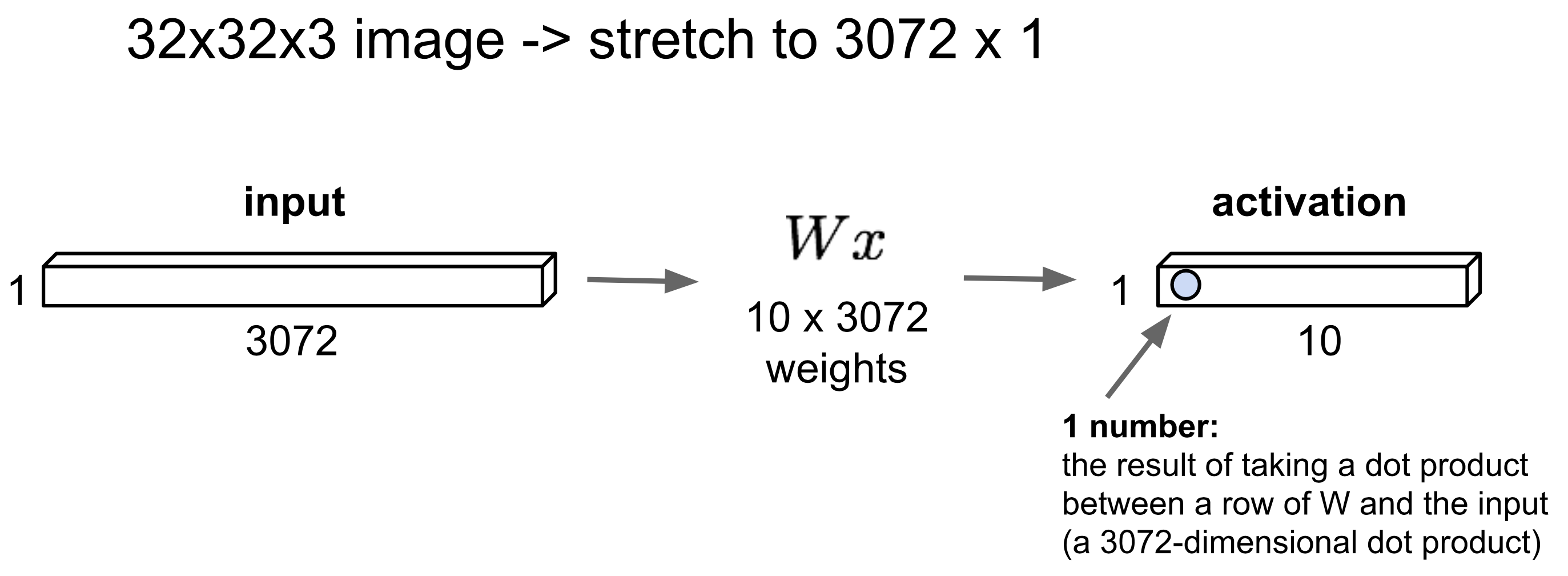
✔️ Fully Connected Layer
- 30K의 learnable parameter들이 필요하다.
- Flatten하였기 때문에 공간 structure를 활용하지 못한다.
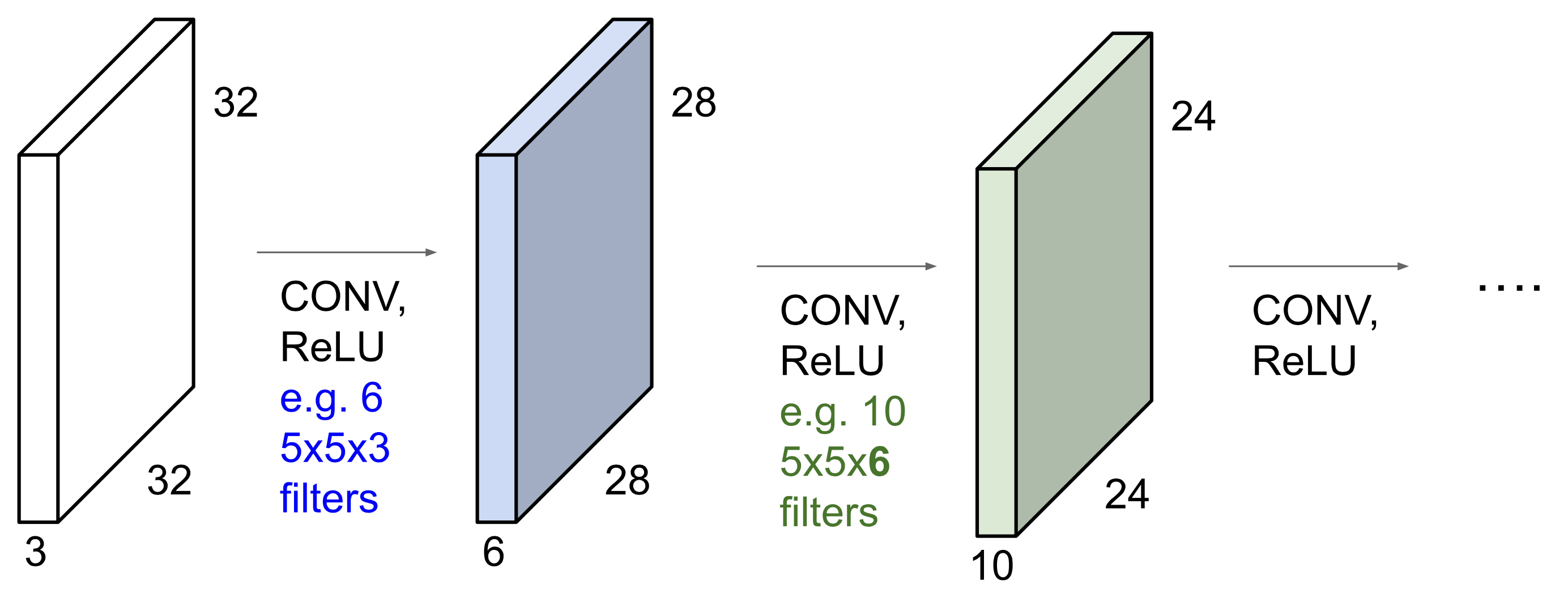
Convolution Layer
- Spatial structure를 보존한다.
🔗 Convolution operation
- Filter와 Image를 convolve한다.
Filter depth는 input depth와 항상 같다.- Filter마다 capture하려고 하는 것이 다르다. 각 filter는 서로 다른 activation map을 준다. 각 activation map은 서로 다른 의미와 정보를 가지고 있다.

- Activation map하나를 만드는 데 오직 75개의 parameter가 필요하다.
Output depth는 몇 개의 filter를 사용하는가에 달려있다.
-
ConvNet은 sequence of Convolutional Layers이며, non-linear activation functions가 포함되어 있다. -
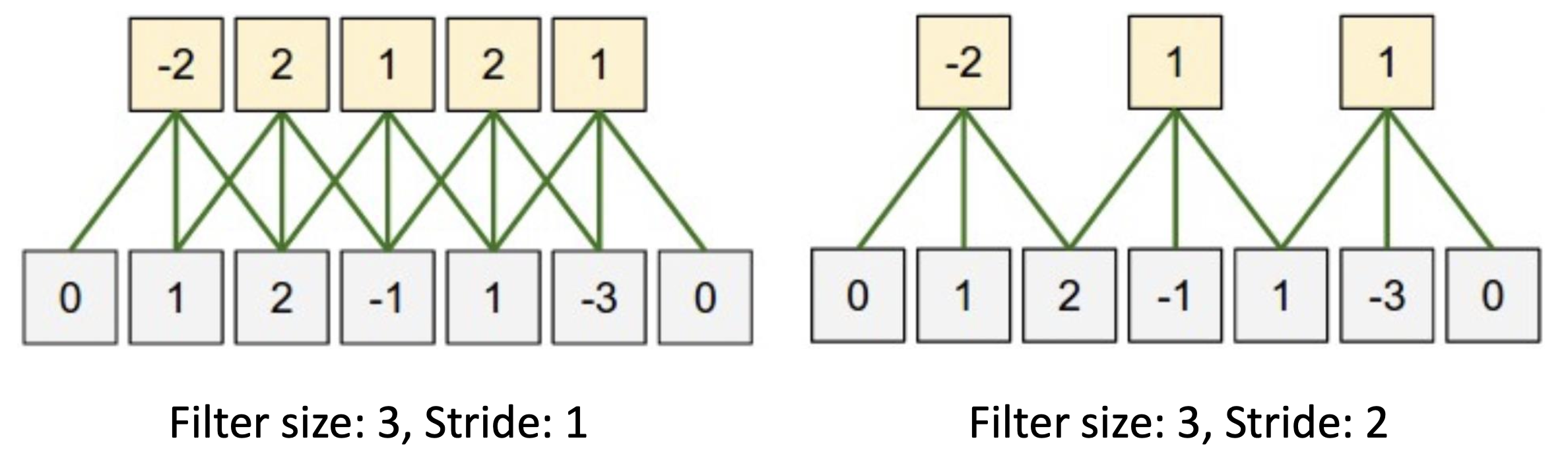
Stride를 잘 선택해야 한다. 잘 맞지 않으면 끝까지 가지 못하고 process가 terminate되어 pixel information을 잃어버린다.
🔗 Padding
- Activation map이 input보다 작아지는 것을 원하지 않으면 padding을 할 수 있다.
- 보통 0으로 채우거나 mean value로 채운다.
- Padding을 사용하여 activation map이 축소되는 것을 방지할 수 있다.
🔗 Summary

- 5개(N, K, F, S, P)가 output의 size를 결정한다.
🔗 1*1 convolution layer

- 한번에 1개의 pixel을 본다.
- Same dimensional output을 얻는다. Spatial structure는 바뀌지 않고 depth만 작아지거나 커진다.
- Depth가 너무 크다고 생각하거나 너무 얇다고 생각되면, 1*1 conv를 써서 spatial structure는 건들지 않고 depth만 shrink하거나 expand할 수 있다.
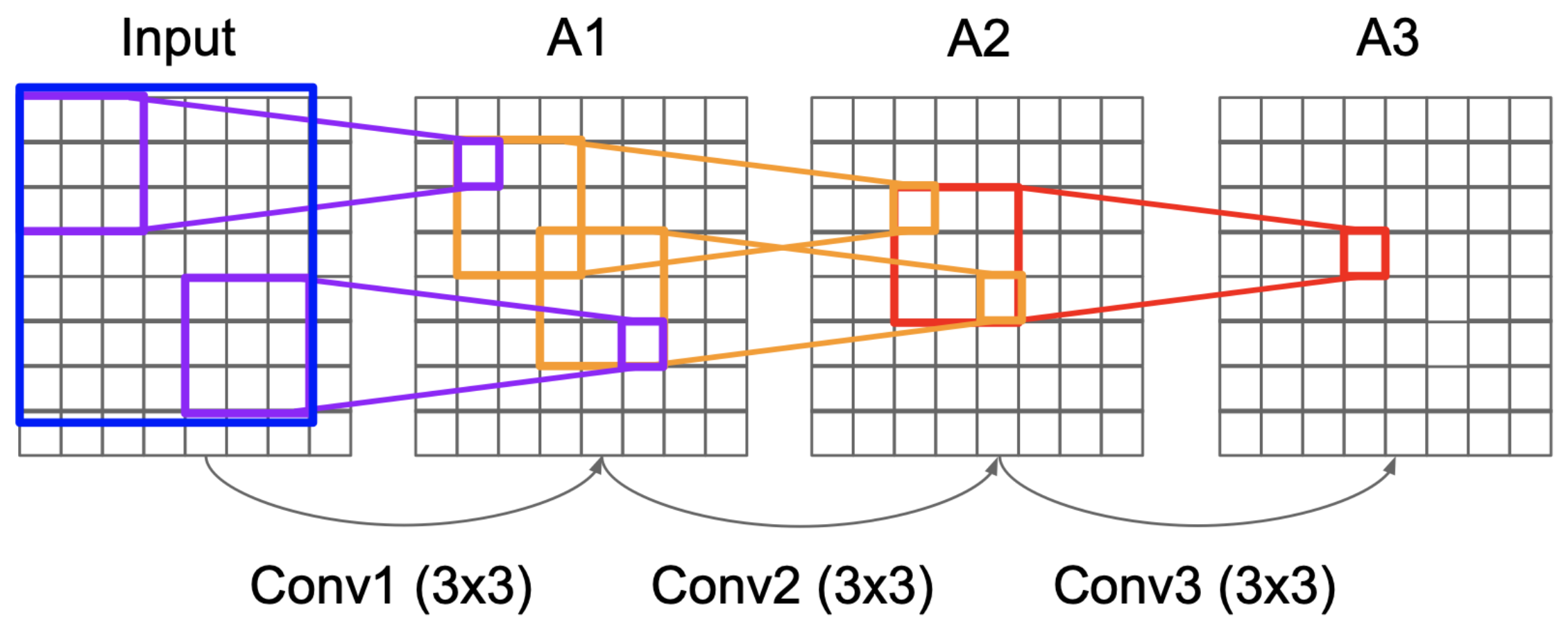
이렇게 convolution을 반복하면 어떻게 될까?
Receptive Field
-
반복적인 Conv layers는 receptive field를 늘린다.
- Final activation map에서 single scaler value는 이전 activation map의 3*3 spatial information에게 책임이 있다.
- Chain을 따라 적용해보면, 결국 final activation에서의 single scaler value는 input signal의 7*7 patch에게 책임이 있다.
-
3 layer of 3*3 filter는 single 7*7 filter와 같은 receptive field를 갖는다.
-
같은 receptive field 영역을 커버하기 위해서는, 보통 항상 작은 filter를 써서 반복하는 것이 하나의 큰 filter를 사용하는 것보다 좋다.
- Less parameter를 갖는다.
- 3 layer of 3*3 filter : 27 parameters
- single 7*7 filter : 49 parameters
- Deeper하기 때문에 non-linear transformation의 기회가 많다.
- Deeper해질수록, latent space를 찌그러트리거나 늘릴 기회가 많아 neural network가 더 강력해진다.
- 이 principle이 처음에 VGGNet에서 쓰였다. 적은 parameter로 더 효율적이다.
- AlexNet과 ZFNet은 이런 거 안 썼다.
- Less parameter를 갖는다.
Convolutional Neural Network
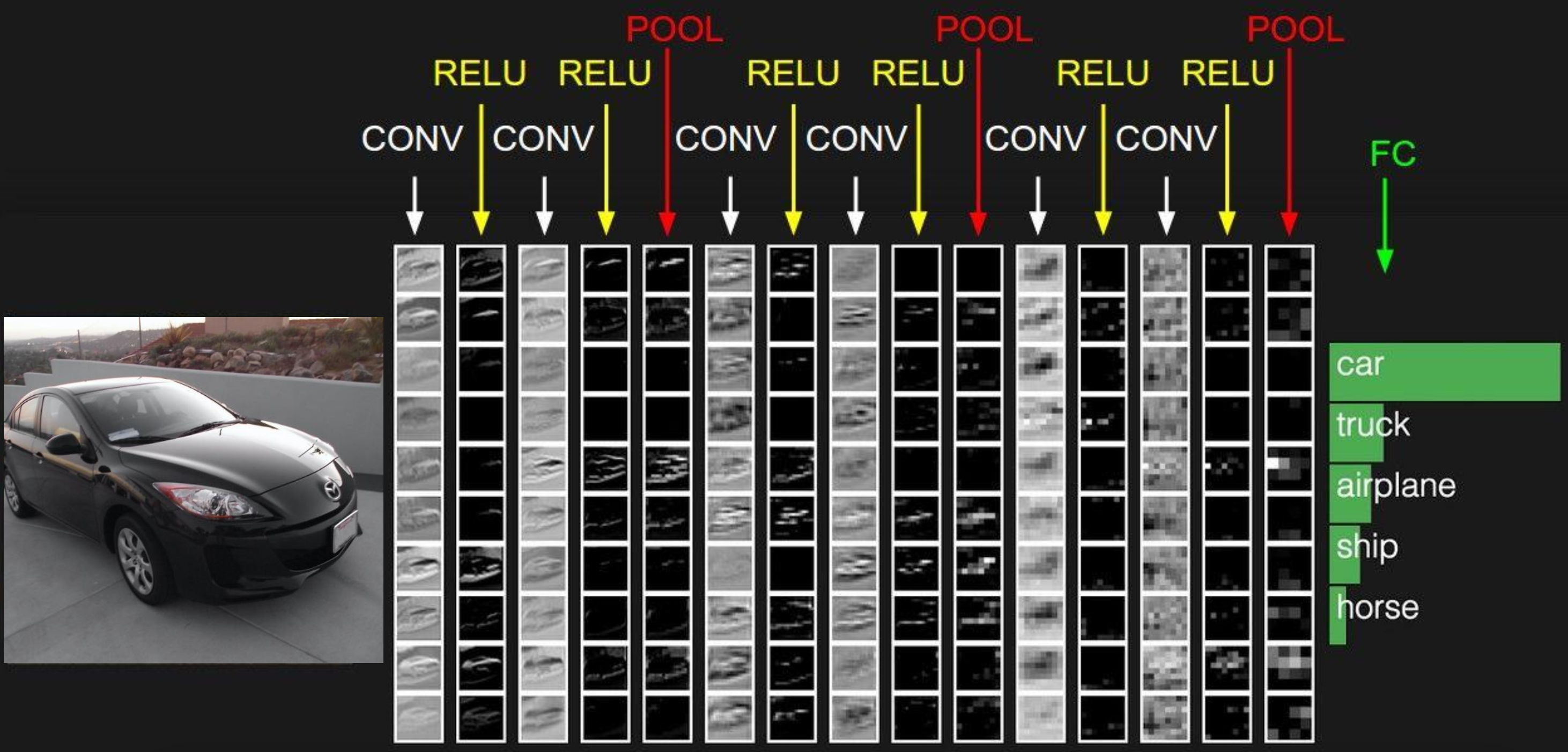
- 최근의 현대적인 InceptionNet, ResNet, DenseNet, WideNet은 모두 이 concept의 extension이다.
Pooling layer
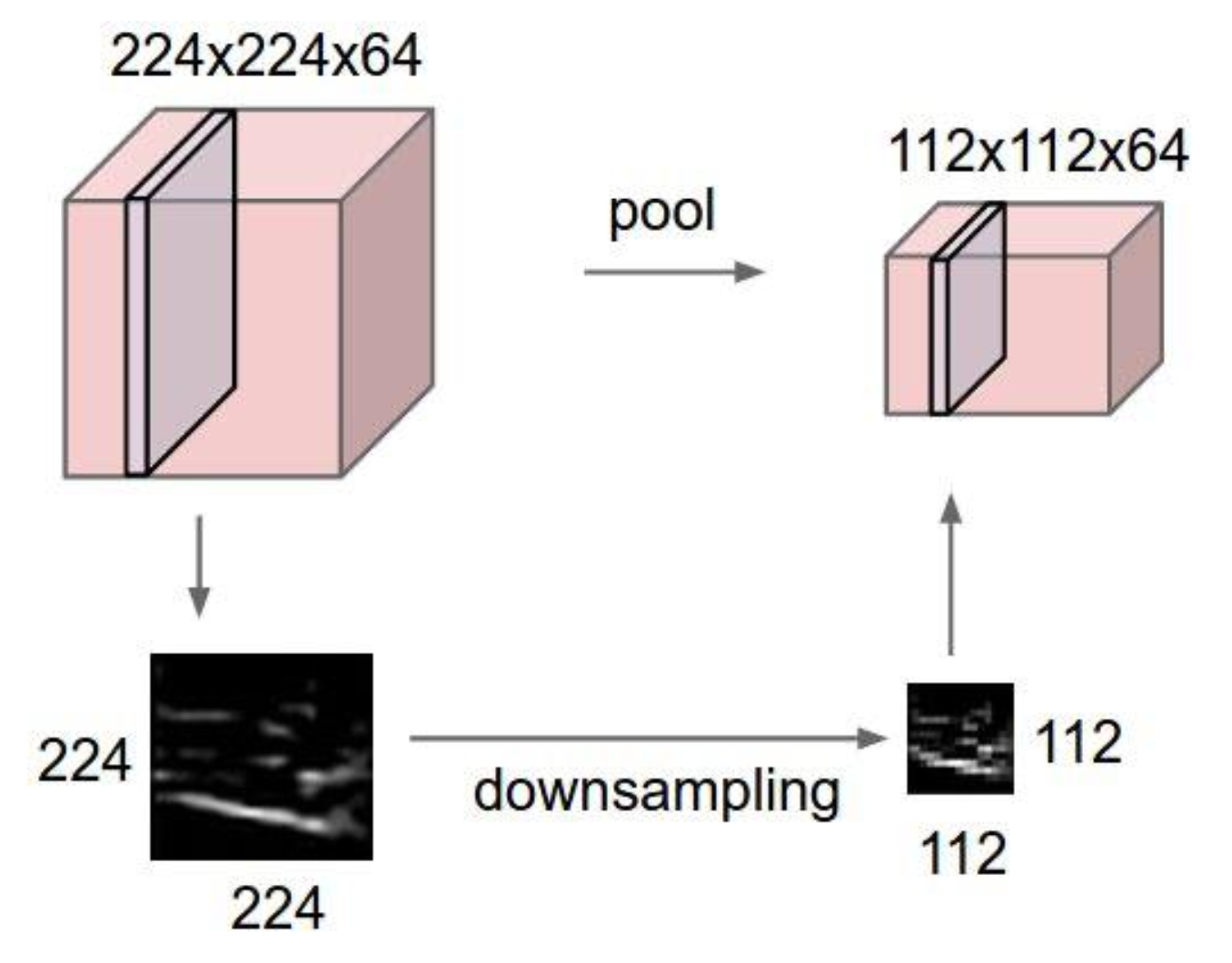
- Spatial structure의 size를 줄이고 싶을 때 사용한다. Depth는 보존된다.
- 그럼으로써 operation이 빨라지고, 더 manageable해지고 compressed해진다.
- 주로 downsamling을 할 때 사용하는데, supersampling에 써도 된다.
🔗 Max Pooling
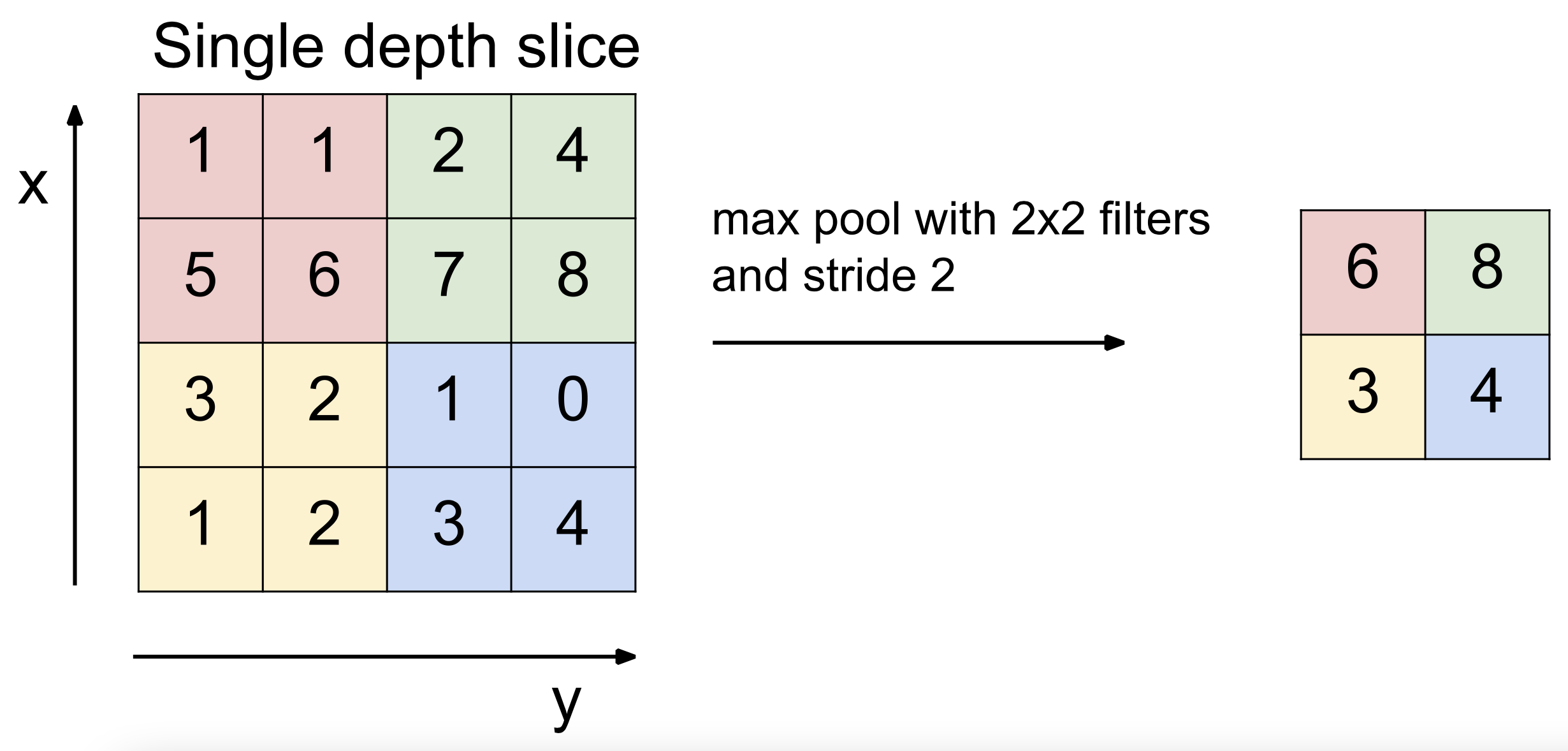
- Small size patch를 보고 가장 강한 signal이 가장 중요한 signal이라고 가정한다. 그래서 가장 중요한 signal만 추출하고 다른 관련된 약한 signal은 버린다.
포인트일부로 손실을 시킨다. 전체 neural net이 손실이 있다는 것을 알기 때문에 정말 중요한 정보만 최대한 뽑아내고 뽑아낸다. 가장 강한 것만 택하겠다 하면, filter들이 선택받기 위해 진짜 중요한 것만 내보내게 된다.- 결정해야할 parameter :
filter,stride - 사람들은 주로 max pooling을 쓴다.
🔗 Mean Pooling
- 주어진 patch를 평균을 취한다. 모든 정보를 다 고려한다.
✔️ Pooling은 애초에 spatial structure 차원을 줄이려고 있는 것이다.
✔️ Conv layer는 차원을 줄이는 것은 부차적, side-effect이다. Conv layer는 local dependency/interaction을 포착하기 위해 예를 들어 오직 이 9개의 pixel이 서로 interaction한다라고 가정하고 small patch/neighborhood/단위를 보고서 calculation하겠다는 것이 핵심이다.
- 만약 모든 것이 서로 interact한다고 가정하면 fully connected neural network를 쓰면 된다.
1D ConvNet
- 주로 sequence를 processing할 때 사용
- Sentences, audios, time-series
- 1D ConvNet은 width와 depth만 가지며, output structure는 2 dimension이다.
3D ConvNet
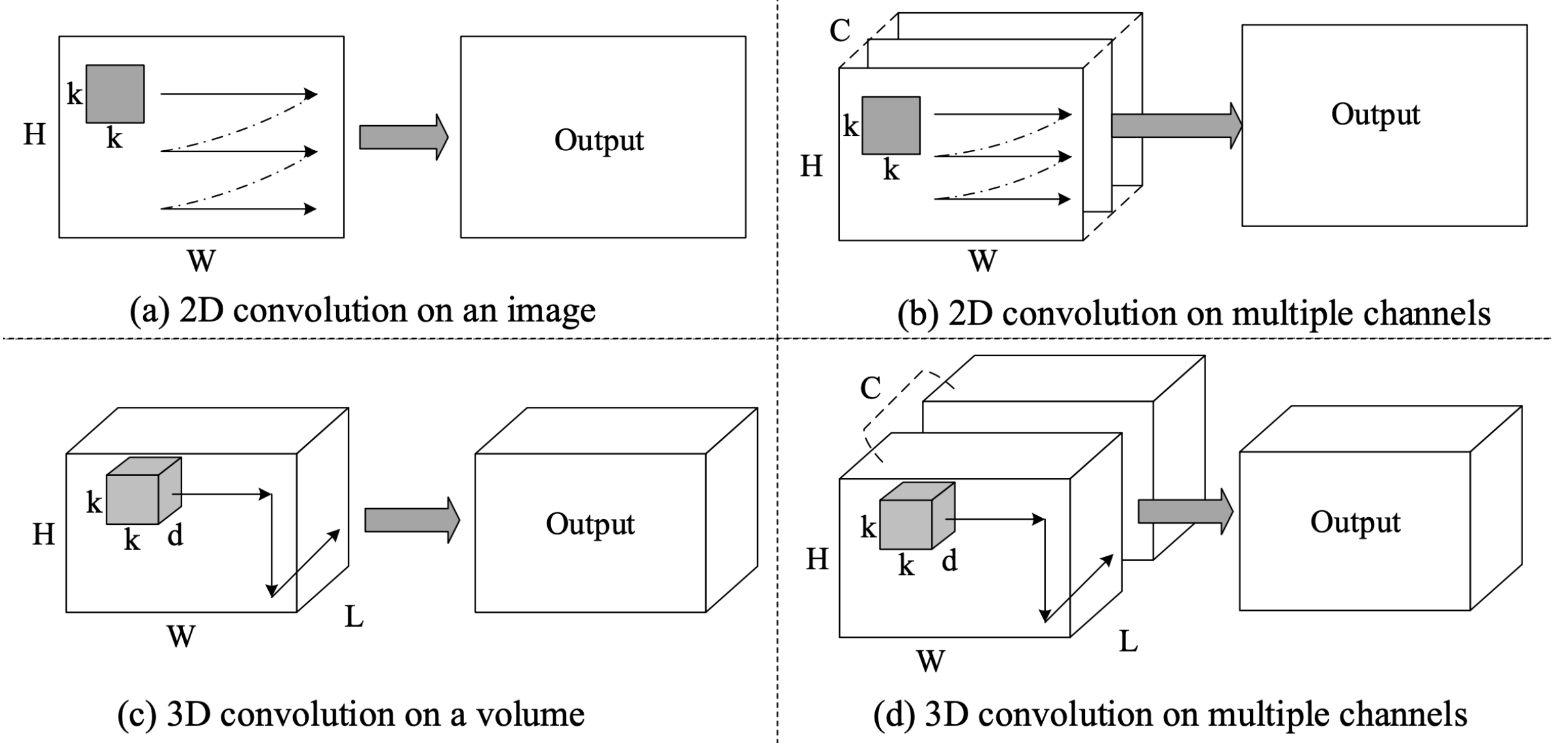
- 3D tensors(3-dimensional structure)를 processing하는 데 사용한다.
- 3D images, videos(2-dimensional structure with time)
- 4 dimensional filter가 사용된다.
- 3D ConvNet은 계산량이 많아 많은 시간과 memory를 필요로 한다.
Training Technique
BatchNorm
🔗 Distribution Shift
- 만약 training data와 test data가 다른 distribution을 가질 때, normalization을 적용하지 않으면 model이 poor performance가 나올 것이다.
- Machine learning model은 보통 distribution shift에 취약하다.
Distribution Shift는 input level에서만 일어나는 것이 아니라 training하는 동안에 layer 내부적으로도 일어난다.
🔗 Internal Distribution Shift
- Internal covariate shift라고도 부른다.
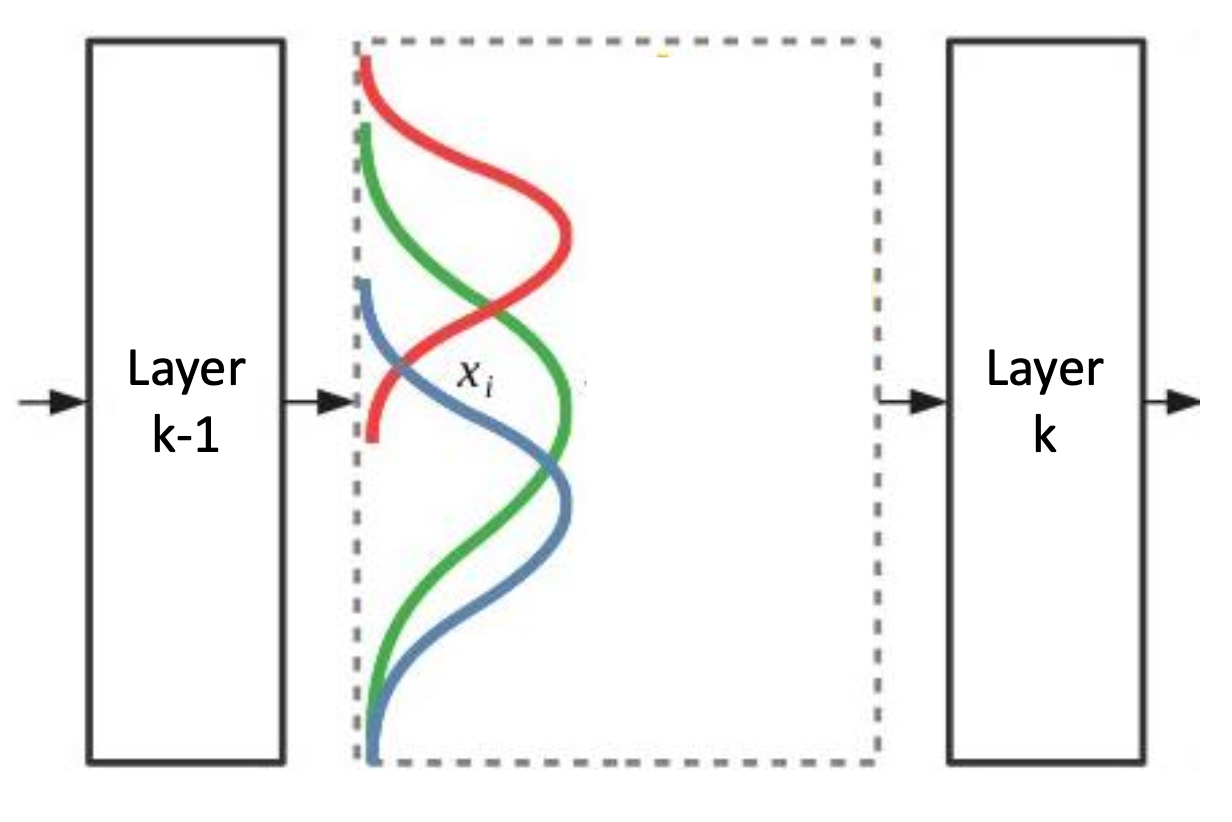
① k-1번째 layer의 activation이 k번째 layer의 input이 된다.
② Backpropagate할 때 k-1번째 layer의 learnable parameter들이 update되기 때문에, k-1번째 layer의 activation map distribution이 바뀌게 된다.
③ 하지만 k번째 layer는 k-1번째 layer가 매 iteration마다 이렇게 activation map이 바뀌는 것을 모른다. 즉, 이전 activation map distribution에 적응하여 update를 했는데, 다음 iteration에서는 activation map distribution이 바뀌어있는 것이다. 그래서 매 update 후에 k번째 layer는 매번 새로운 distribution에 적응해야 한다.
④ 이로 인해 전체 training/optimization process가 오래걸리고 비효율적이다. 잘 훈련이 되지 않는다.
⑤ 이것이 internal distribution shift가 문제가 되는 이유이다.
따라서 input pixel을 normalize한 것 처럼 activation map values도 normalize를 한다.
🔗 Batch Normalization
- Internal distribution shift 문제를 해결하였다.

-
Activation map(output) value를
normalize하고,rescale it back하여 next layer에 friendly하게 맞춘다. Optimizing process가 smoothier해지도록 한다.- 모든 layer에 있는 모든 activation values가 정확히 unit gaussian을 따르길 바라는 것은 너무 큰 제약이고 현실적이지 않다.
-
BatchNorm은 2개의 learnable parameter를 갖는다 : γ , β
-
BatchNorm은 batch의 평균을 취한다.
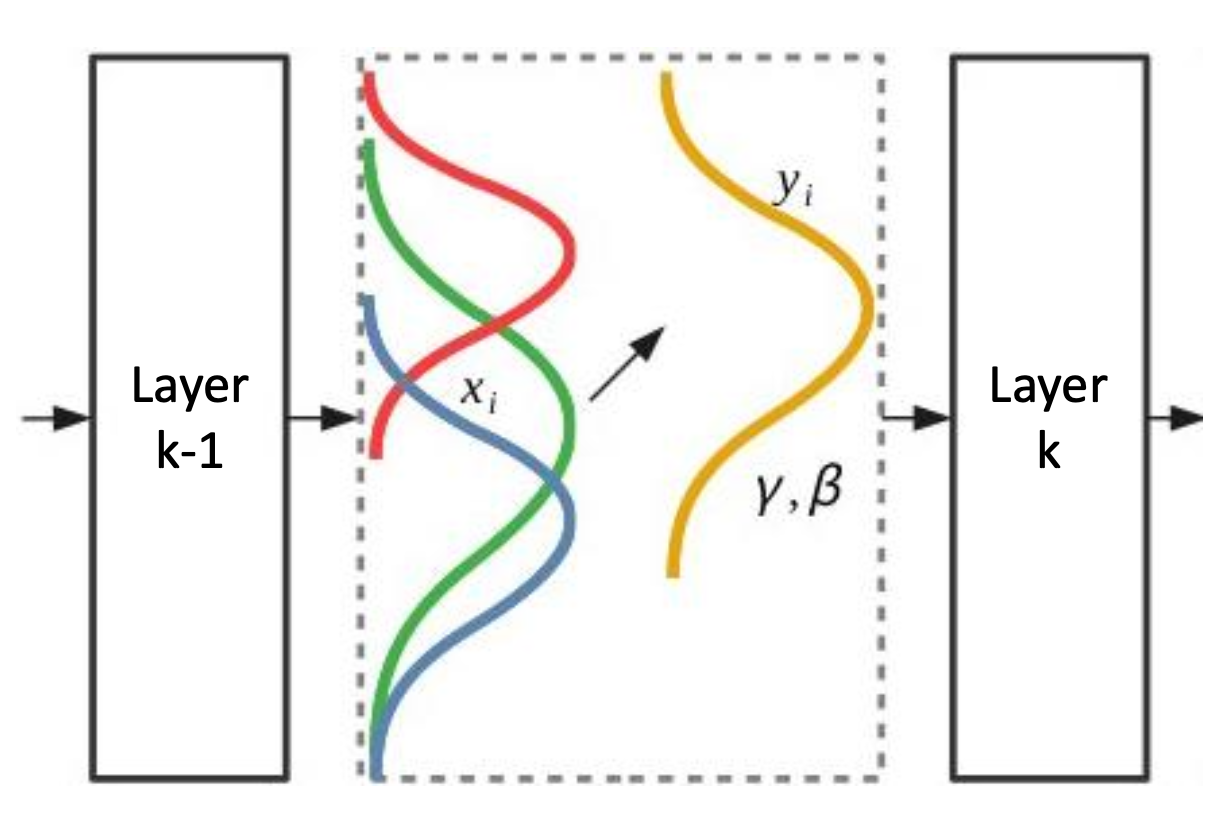
- 특정 layer 이후에는 그 output이 항상 일정한 distribution을 따르도록 한다.
- 그러면 다음 layer는 그 distribution에 적응하여 paramter를 optimize하기 쉬워진다.
🔗 Batch Normalization: Test-Time
- ⭐️ Training은 minibatch로 수행되지만, Inference는 한 번에 한 sample에 대해 진행하기도 한다. 그래서 minibatch로 수행한다는 보장이 없다.
- BatchNorm을 계산하려면 minibatch가 있어야 한다.
➡️ Problem of batch normalization : Training과 testing할 때의 불일치가 생긴다.
- 그래서 training하는 동안 μs와 σs의 평균을 취해서 저장해놓는다. 그리고 test할 때 이것을 load해서 재사용한다.
- 이것이 버그의 주 원인이 된다.
주로 fully connected 또는 convolutional layer 후에, non-linear activation function 전에 BatchNorm을 취한다.
🔗 Batch Normalization for ConvNets

- 오직 channel마다 다른 μ와 σ를 가진다.
- N, H, W의 평균을 취한다.
🔗 Layer Normalization
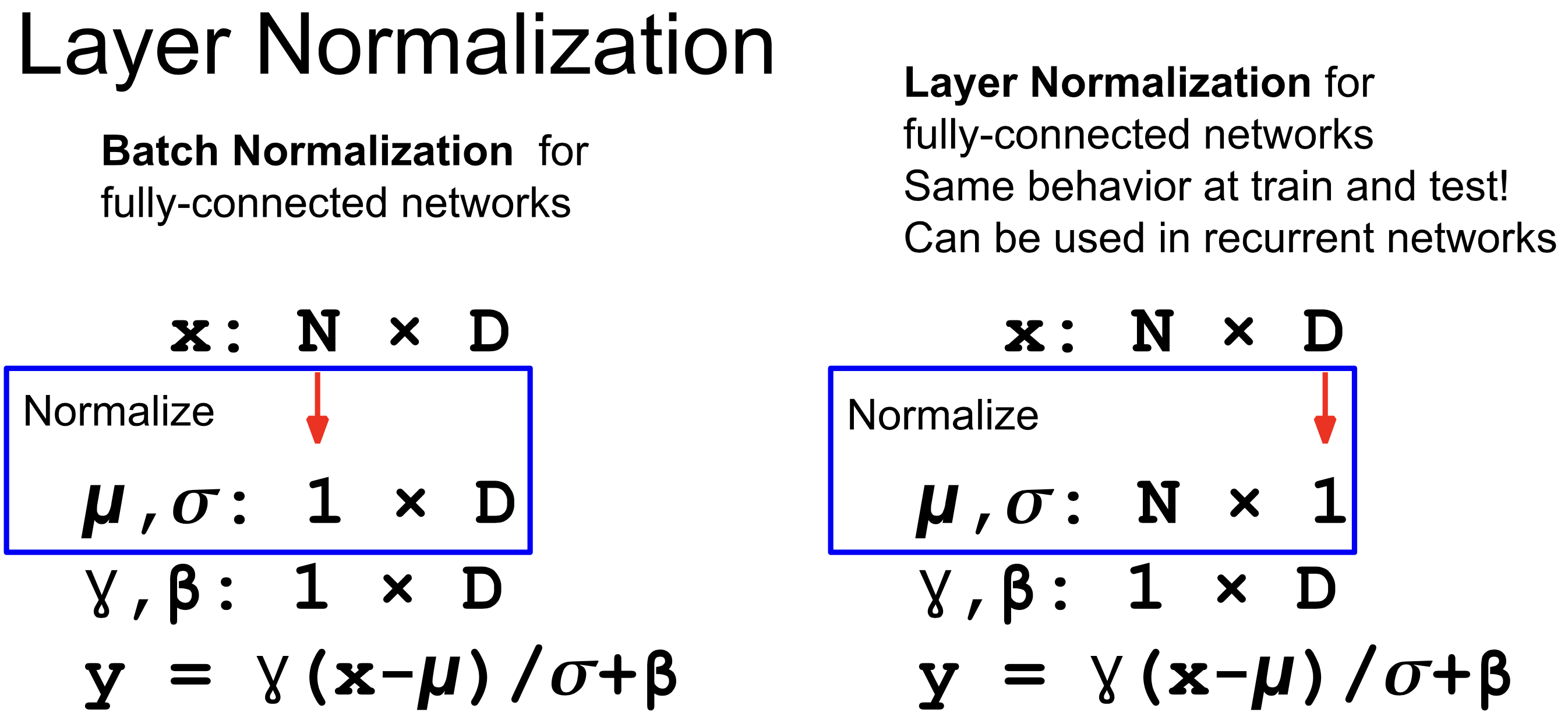
- Dimension의 평균을 취한다.
- Batch의 평균을 취하지 않는다.
- 그래서 train과 test에서 같은 behavior를 보인다.
🔗 Instance Normalization

- Height와 weight의 평균만 취한다.
- Batch의 평균을 취하지 않는다.
- 그래서 train과 test에서 같은 behavior를 보인다.
- Convolutional neural network specific하다.
🔗 Comarison of Normalization Layers
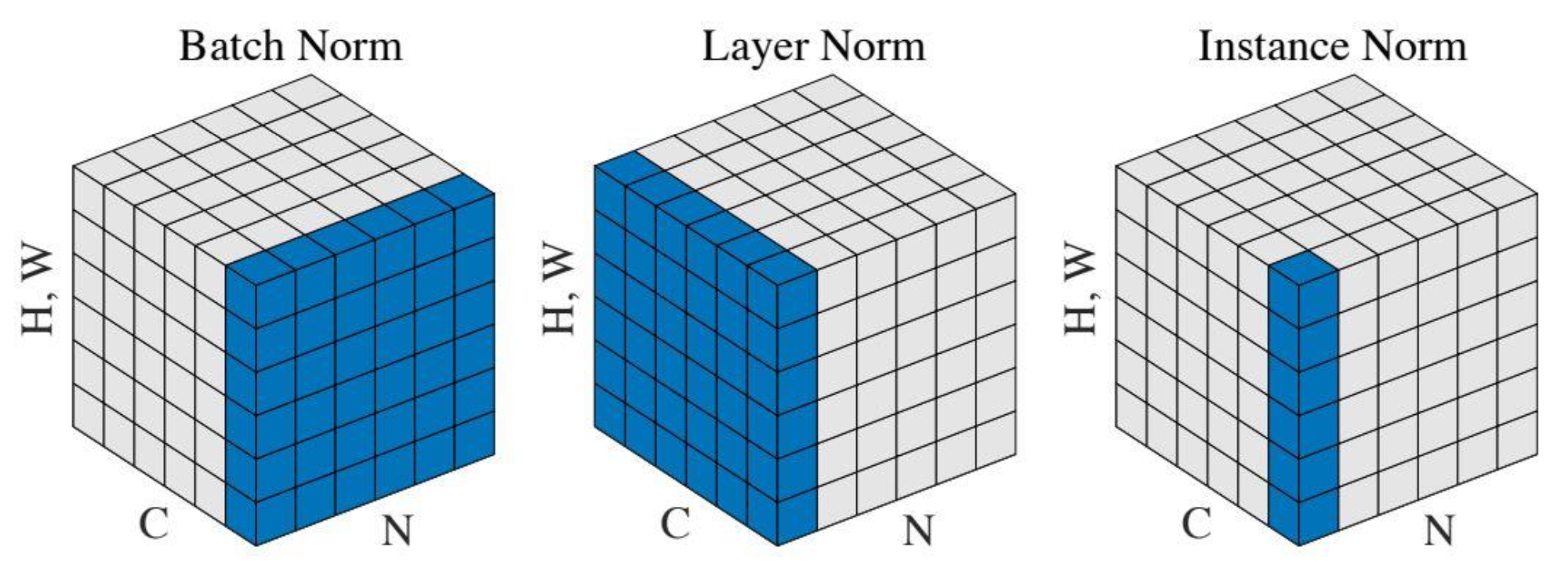
- Batch Norm : CNN에서 사용됨
- Layer Norm : Transform에서 사용됨
- Instance Norm : StyleGAN에서 사용됨
Dropout
- 모델이 test environment에서 더 잘 generalize되도록 만드는 데에 매우 중요한 technique이다.
- Random하게 p(ex. 10%) hidden nodes를 0으로 만든다.
- p: hyperparameter
- Regularization의 일종이다.
- 2012~2013년에 ALEXNET에서 처음 제시되었다.
🔗 Dropout in ConvNet
두 가지 방법이 있다.
-
Activation map에서 작은 비율의 activation value를 cancel out
-
Activation map filter 전체를 cancel out
- Feature를 cancel out할 수 있기 때문에 이것을 더 흔하게 사용한다.
Reference
- AI504: Programming for AI Lecture at KAIST AI
