Week 7: Convolutional Neural Networks
In this practice session, we will cover implementation of Convolutional Neural Networks (CNNs) using PyTorch library. Particulary, in part 1, we will see how to define and use convolutional, batch normalization, and dropout layer to build a simple CNNs to classify MNIST. In part 2, we will implement ResNet for CIFAR-10 classification task and see the effectiveness of residual connection.
0. Preliminary
Let's import required libraries and datasets. We will use MNIST and CIFAR-10 to train a simple CNNs and ResNet, respectively.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
import torchvision
import torchvision.transforms as transforms
from torchvision.datasets import MNIST, CIFAR10
from IPython.display import Image# MNIST
mnist_train = MNIST("./", train=True, transform=transforms.ToTensor(), target_transform=None, download=True)
mnist_test = MNIST("./", train=False, transform=transforms.ToTensor(), target_transform=None, download=True)
mnist_train, mnist_val = torch.utils.data.random_split(mnist_train, [50000, 10000])
dataloaders = {}
dataloaders['train'] = DataLoader(mnist_train, batch_size=128, shuffle=True)
dataloaders['val'] = DataLoader(mnist_val, batch_size=128, shuffle=False)
dataloaders['test'] = DataLoader(mnist_test, batch_size=128, shuffle=False)Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to ./MNIST/raw/train-images-idx3-ubyte.gz
0%| | 0/9912422 [00:00<?, ?it/s]
Extracting ./MNIST/raw/train-images-idx3-ubyte.gz to ./MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to ./MNIST/raw/train-labels-idx1-ubyte.gz
0%| | 0/28881 [00:00<?, ?it/s]
Extracting ./MNIST/raw/train-labels-idx1-ubyte.gz to ./MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to ./MNIST/raw/t10k-images-idx3-ubyte.gz
0%| | 0/1648877 [00:00<?, ?it/s]
Extracting ./MNIST/raw/t10k-images-idx3-ubyte.gz to ./MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to ./MNIST/raw/t10k-labels-idx1-ubyte.gz
0%| | 0/4542 [00:00<?, ?it/s]
Extracting ./MNIST/raw/t10k-labels-idx1-ubyte.gz to ./MNIST/rawIn case of CIFAR-10, we use conventional transforms and normalization.
For more example, please refer to
https://pytorch.org/vision/stable/auto_examples/plot_transforms.html#sphx-glr-auto-examples-plot-transforms-py
transforms_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transforms_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
cifar_train = CIFAR10(root='./', train=True,
download=True, transform=transforms_train)
cifar_test = CIFAR10(root='./', train=False,
download=True, transform=transforms_test)
cifar_loader = {}
cifar_loader['train'] = DataLoader(cifar_train, batch_size=128,
shuffle=True, num_workers=4)
cifar_loader['test'] = DataLoader(cifar_test, batch_size=128,
shuffle=False, num_workers=4)Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./cifar-10-python.tar.gz
0%| | 0/170498071 [00:00<?, ?it/s]
Extracting ./cifar-10-python.tar.gz to ./
Files already downloaded and verified1. Convolutional, Batch Norm and Dropout Layer Practice
1.1. Convolutional Layer
In PyTorch, 2-dimensional convolutional layer is given with the pytorch torch.nn.Conv2d package. In this section, we will learn basic usage of pytorch convolutional layer with some example codes and practices.
As in our lecture session, we should specify convolution with the number of channels of input and output, kernel size, the size of stride and padding. In Pytorch torch.nn.Conv2d class, those traits can be specified as class parameters. The detailed explanation and default values are available on below and the official sites (https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html)
-
in_channels (int) – Number of channels in the input image
-
out_channels (int) – Number of channels produced by the convolution
-
kernel_size (int or tuple) – Size of the convolving kernel
-
stride (int or tuple, optional) – Stride of the convolution. Default: 1
-
padding (int or tuple, optional) – Zero-padding added to both sides of the input. Default: 0
Now, let's define our convolutional layer and practice. As in our lecture note, let's suppose we have 32x32-sized image with 3 channels.
"""
Note: Since PyTorch Conv2d receives 4-dimensional input (i.e. a batch of image(s)),
we define input x with the first argument 1.
"""
x = torch.randn(1, 3, 32, 32)Then, the number of input channel is 3, which is the same value with the input images' channel (the second argument of above randn method).
How about the number of output channel, kernel and stride size? Following the figure in our lecture note, we can easily see that the number of output channel should be 1. You can naively regard the kernel size as the spatial size of filter in the lecture note. Thus, the kernel size should be (5,5), and the stride size should be 1. In practice, since the spatial size of filter in in square form (i.e., width = height), we usually specifiy kernel size with only single integer (in our case 5).
# Fill out the ?? of below
conv_layer = torch.nn.Conv2d(in_channels=3, out_channels=1, kernel_size=5, stride=1)# You should check the output size of covolution layer is [1, 1, 28, 28].
conv_layer(x).size()torch.Size([1, 1, 28, 28])Also check the other example in the lecture note as below.
- Input volume: 3x32x32
- 10 5x5 filters with stride 1, pad 2
# Fill out the ?? of below
x = torch.randn(1, 3, 32, 32)
conv_layer = torch.nn.Conv2d(in_channels=3, out_channels=10, kernel_size=5, stride=1, padding=2)
print(conv_layer(x).size())torch.Size([1, 10, 32, 32])1.2. BatchNorm and Dropout layer
In a similar manner, batch normalization and dropout layer also can be used from torch.nn.BatchNorm2d and torch.nn.Dropout2d.
x = torch.randn(1, 3, 32, 32)
bn = torch.nn.BatchNorm2d(num_features=3) # channel의 개수와 num_features가 같아야 한다.
print(bn(x).size()) # check batch norm does not change the size of input
dropout = torch.nn.Dropout2d(p=0.5) # dropout can specify probability of an element to be zeroed.
print(dropout(bn(x)).size()) # check dropout does not change the size of inputtorch.Size([1, 3, 32, 32])
torch.Size([1, 3, 32, 32])1.3. Build a Simple Convolutional Neural Network
We can combine convolution layer, batch norm layer and activation function (e.g., ReLU) to construct a functional unit. In this case, we can use torch.nn.Sequential to define a block of sequential layers.
x size : (128, 1, 28, 28)
output : (128, 10)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 32 output channels, 7x7 square convolution, 1 stride
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=32, kernel_size=7, stride=1),
nn.BatchNorm2d(num_features=32),
nn.ReLU(),
)
# 32 input image channel, 64 output channels, 7x7 square convolution, 1 stride
self.layer2 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=7, stride=1),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
)
self.fc = nn.Linear(64*16*16, 10)
def forward(self, x):
# x's shape : (128,1,28,28)
out = self.layer1(x)
# out's shape : (128,32,22,22)
out = self.layer2(out)
# out's shape : (128,64,16,16)
out = torch.flatten(out, 1)
# out's shape : (128,64*16*16)
out = self.fc(out)
# out's shape : (128,10)
return out
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
net = Net().to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)cuda:0criterion = torch.nn.CrossEntropyLoss()for _ in range(20):
for x, y in dataloaders['train']:
x, y = x.to(device), y.to(device)
out = net(x)
loss = criterion(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()net.eval()
correct = 0.0
for x, y in dataloaders['test']:
x, y = x.to(device), y.to(device)
out = net(x)
correct += (out.argmax(1) == y).float().sum().item()
print(100. * correct / len(dataloaders['test'].dataset))99.092. CNN Architecture: ResNet
In this section, we will implement ResNet and see the effectiveness of residual connection in terms of test performance.
The overall structure of ResNet is like below.
- input(channel:3) -> (conv 3x3) -> (bn) -> (relu) -> output(channel:16)
- n Residual blocks: (16 channels -> 16 channels)
- n Residual blocks: (16 channels -> 32 channels)
- n Residual blocks: (32 channels -> 64 channels)
- global average pooling + fully connected layer
n can be chosen from {3,5,7,9,18} which of each corresponds to ResNet-20, 32, 44, 56, and 110, respectively.
2.1. Residual Block
Residual Block consists of 2 convolution layers with 3x3 size kernel and ReLU activation function (See below figure). Let's implement ResidualBlock class below with 2 convolutional layers and residual connection.
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, down_sample=False):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.down_sample = down_sample
self.stride = stride
self.in_channels = in_channels
self.out_channels = out_channels
def down_sampling(self, x):
out = F.pad(x, (0, 0, 0, 0, 0, self.out_channels - self.in_channels))
out = nn.MaxPool2d(2, stride=self.stride)(out)
return out
def forward(self, x):
shortcut = x # this will be used to build residual connection.
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.down_sample:
shortcut=self.down_sampling(x)
out += shortcut # residual connection
out = self.relu(out)
return outResidualBlock class which extends torch.nn.Module. ResidualBlock class receives in_channels, out_channels, stride and down_sample.
In ResNet, there are residual blocks that twice the output channel(16 to 32, 32 to 64). The stride argument for ResidualBlock is set to 2 in such residual blocks to down sample (reduce spatial dimension) while increasing channels.
However, the residual connection in the residual block can occur dimension mismatch since the output of other path (through convolutional layers) change the dimension of input with stride=2. Thus, residual block should support downsample through the residual connection in demand.
We support this feature in down_sampling method in ResidualBlock class. It conducts zero-padding to exapnd the channels and max-pooling to shrink spatial dimension through residual block. Using down_sampling in the middle of the forward method to handle down_sample condition to residual connection.
2.2. ResNet
Now implement ResNet class. Assume the block argument will be ResidualBlock we implemented above. Here are required implementation details.
- In
initmethod, specifiy all details of convolution, batch norm layers. - In
get_layersmethod, set down_sample boolean variable according to the stride information. Then, define a list of residual blocks (layer_list). Make sure the down-sample only occurs at the first block in demand.
class ResNet(nn.Module):
def __init__(self, num_layers, block, num_classes=10):
super(ResNet, self).__init__()
self.num_layers = num_layers
#input(channel:3) -> (conv 3x3) -> (bn) -> (relu) -> output(channel:16)
self.conv1 = nn.Conv2d(
in_channels=3,
out_channels=16,
kernel_size=3,
stride=1,
padding=1,
bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.relu = nn.ReLU(inplace=True)
# feature map size = 16x32x32
self.layers_2n = self.get_layers(block, 16, 16, stride=1)
# feature map size = 32x16x16
self.layers_4n = self.get_layers(block, 16, 32, stride=2)
# feature map size = 64x8x8
self.layers_6n = self.get_layers(block, 32, 64, stride=2)
# output layers
self.avg_pool = nn.AvgPool2d(8, stride=1)
self.fc_out = nn.Linear(64, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def get_layers(self, block, in_channels, out_channels, stride):
if stride == 2:
down_sample = True
else:
down_sample = False
layer_list = nn.ModuleList([block(in_channels, out_channels, stride, down_sample)])
for _ in range(self.num_layers-1):
layer_list.append(block(out_channels, out_channels))
return nn.Sequential(*layer_list)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.layers_2n(x)
x = self.layers_4n(x)
x = self.layers_6n(x)
x = self.avg_pool(x)
x = x.view(x.size(0), -1)
x = self.fc_out(x)
return xIn this practice we use resnet32 to train CIFAR-10.
def resnet18():
block = ResidualBlock
model = ResNet(3, block)
return model
def resnet32():
block = ResidualBlock
model = ResNet(5, block)
return modelBy replacing ResidualBlock with plain Block (without residual connection), we can compare the effectiveness of residual connection.
class Block(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, down_sample=False):
super(Block, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.stride = stride
self.in_channels = in_channels
self.out_channels = out_channels
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
return outdef cnn18():
block = Block
model = ResNet(3, block)
return model
def cnn32():
block = Block
model = ResNet(5, block)
return model2.3. Train
Training resnet is not different with other training schemes. We train 64000 batch steps with 128 batch size. The learning rate starts from 0.1 and is decayed at 32,000 and 48,000 step with 0.1 factor.
net = resnet18().to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=0.1, momentum=0.9, weight_decay=1e-4)
decay_epoch = [32000, 48000]
step_lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=decay_epoch, gamma=0.1)import time
start_time = time.time()
net.train()
step = 0
epochs = 0
losses = []
while step < 64000:
train_loss = 0.0
correct = 0.0
total = 0.0
for batch_idx, (x, y) in enumerate(cifar_loader['train']):
step += 1
step_lr_scheduler.step()
x, y = x.to(device), y.to(device)
out = net(x)
loss = criterion(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
correct += (out.argmax(1) == y).float().sum().item()
total += x.size(0)
train_loss += loss.item()
losses.append(train_loss)
epochs += 1
print("Epoch[{:d} ({:d}/64000) ({:.4f}sec)] loss: {:.2f} acc: {:.2f}".format(epochs, step, time.time()-start_time, train_loss, 100.*correct/total))
/usr/local/lib/python3.9/dist-packages/torch/optim/lr_scheduler.py:138: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
warnings.warn("Detected call of `lr_scheduler.step()` before `optimizer.step()`. "
Epoch[1 (391/64000) (7.3776sec)] loss: 770.94 acc: 28.60
Epoch[2 (782/64000) (14.8934sec)] loss: 553.97 acc: 48.27
Epoch[3 (1173/64000) (22.6149sec)] loss: 423.91 acc: 61.23
Epoch[4 (1564/64000) (30.1059sec)] loss: 338.47 acc: 69.58
Epoch[5 (1955/64000) (37.5786sec)] loss: 292.68 acc: 73.91
Epoch[6 (2346/64000) (44.9162sec)] loss: 262.95 acc: 76.47
Epoch[7 (2737/64000) (52.4001sec)] loss: 240.67 acc: 78.48
Epoch[8 (3128/64000) (59.6620sec)] loss: 226.10 acc: 80.03
Epoch[9 (3519/64000) (66.7264sec)] loss: 211.61 acc: 81.14
Epoch[10 (3910/64000) (74.0309sec)] loss: 201.14 acc: 82.09
Epoch[11 (4301/64000) (81.4279sec)] loss: 192.44 acc: 82.89
Epoch[12 (4692/64000) (88.6449sec)] loss: 185.66 acc: 83.48
Epoch[13 (5083/64000) (95.6921sec)] loss: 179.04 acc: 84.08
Epoch[14 (5474/64000) (103.2531sec)] loss: 172.97 acc: 84.52
Epoch[15 (5865/64000) (110.4206sec)] loss: 168.45 acc: 85.00
Epoch[16 (6256/64000) (117.7995sec)] loss: 163.93 acc: 85.55
Epoch[17 (6647/64000) (125.0056sec)] loss: 159.06 acc: 85.89
Epoch[18 (7038/64000) (131.9813sec)] loss: 154.58 acc: 86.24
Epoch[19 (7429/64000) (139.2963sec)] loss: 149.25 acc: 86.76
Epoch[20 (7820/64000) (146.5095sec)] loss: 147.14 acc: 86.90
Epoch[21 (8211/64000) (153.8556sec)] loss: 145.00 acc: 86.98
Epoch[22 (8602/64000) (161.2942sec)] loss: 143.00 acc: 87.27
Epoch[23 (8993/64000) (168.7739sec)] loss: 140.13 acc: 87.60
Epoch[24 (9384/64000) (176.0373sec)] loss: 138.12 acc: 87.62
Epoch[25 (9775/64000) (183.3021sec)] loss: 134.82 acc: 88.06
Epoch[26 (10166/64000) (190.4438sec)] loss: 132.00 acc: 88.19
Epoch[27 (10557/64000) (198.0074sec)] loss: 129.47 acc: 88.56
Epoch[28 (10948/64000) (205.5802sec)] loss: 127.74 acc: 88.62
Epoch[29 (11339/64000) (212.6293sec)] loss: 127.16 acc: 88.73
Epoch[30 (11730/64000) (219.8726sec)] loss: 124.96 acc: 88.80
Epoch[31 (12121/64000) (227.2215sec)] loss: 123.96 acc: 88.99
Epoch[32 (12512/64000) (234.4533sec)] loss: 121.24 acc: 89.43
Epoch[33 (12903/64000) (241.7689sec)] loss: 121.30 acc: 89.14
Epoch[34 (13294/64000) (248.7863sec)] loss: 117.79 acc: 89.52
Epoch[35 (13685/64000) (256.2139sec)] loss: 118.10 acc: 89.44
Epoch[36 (14076/64000) (263.5176sec)] loss: 115.68 acc: 89.59
Epoch[37 (14467/64000) (270.9365sec)] loss: 115.37 acc: 89.69
Epoch[38 (14858/64000) (278.3734sec)] loss: 115.04 acc: 89.83
Epoch[39 (15249/64000) (285.9757sec)] loss: 112.16 acc: 89.97
Epoch[40 (15640/64000) (292.9311sec)] loss: 111.84 acc: 89.85
Epoch[41 (16031/64000) (300.4760sec)] loss: 109.70 acc: 90.10
Epoch[42 (16422/64000) (307.9932sec)] loss: 109.83 acc: 90.18
Epoch[43 (16813/64000) (315.1947sec)] loss: 107.85 acc: 90.25
Epoch[44 (17204/64000) (322.2472sec)] loss: 107.05 acc: 90.46
Epoch[45 (17595/64000) (329.4798sec)] loss: 105.78 acc: 90.47
Epoch[46 (17986/64000) (336.6178sec)] loss: 107.77 acc: 90.26
Epoch[47 (18377/64000) (343.9944sec)] loss: 107.88 acc: 90.28
Epoch[48 (18768/64000) (351.4488sec)] loss: 105.09 acc: 90.56
Epoch[49 (19159/64000) (359.2252sec)] loss: 105.22 acc: 90.65
Epoch[50 (19550/64000) (366.4349sec)] loss: 103.85 acc: 90.72
Epoch[51 (19941/64000) (373.9526sec)] loss: 103.95 acc: 90.60
Epoch[52 (20332/64000) (381.5875sec)] loss: 100.33 acc: 90.91
Epoch[53 (20723/64000) (389.3188sec)] loss: 101.65 acc: 90.89
Epoch[54 (21114/64000) (396.4953sec)] loss: 100.06 acc: 90.99
Epoch[55 (21505/64000) (403.9685sec)] loss: 101.06 acc: 90.89
Epoch[56 (21896/64000) (411.0765sec)] loss: 99.19 acc: 91.10
Epoch[57 (22287/64000) (418.5723sec)] loss: 100.30 acc: 90.98
Epoch[58 (22678/64000) (426.1539sec)] loss: 99.05 acc: 91.10
Epoch[59 (23069/64000) (433.3991sec)] loss: 98.29 acc: 91.00
Epoch[60 (23460/64000) (440.8175sec)] loss: 99.99 acc: 91.18
Epoch[61 (23851/64000) (448.1590sec)] loss: 97.27 acc: 91.34
Epoch[62 (24242/64000) (455.1867sec)] loss: 98.78 acc: 91.03
Epoch[63 (24633/64000) (462.4172sec)] loss: 97.50 acc: 91.19
Epoch[64 (25024/64000) (469.4981sec)] loss: 97.14 acc: 91.25
Epoch[65 (25415/64000) (477.0369sec)] loss: 94.74 acc: 91.54
Epoch[66 (25806/64000) (484.3379sec)] loss: 98.58 acc: 91.23
Epoch[67 (26197/64000) (491.7179sec)] loss: 96.46 acc: 91.20
Epoch[68 (26588/64000) (498.8555sec)] loss: 94.97 acc: 91.48
Epoch[69 (26979/64000) (506.3740sec)] loss: 95.55 acc: 91.46
Epoch[70 (27370/64000) (513.6973sec)] loss: 91.85 acc: 91.77
Epoch[71 (27761/64000) (521.2321sec)] loss: 91.67 acc: 91.58
Epoch[72 (28152/64000) (528.9102sec)] loss: 93.36 acc: 91.51
Epoch[73 (28543/64000) (536.1781sec)] loss: 93.85 acc: 91.56
Epoch[74 (28934/64000) (543.5638sec)] loss: 91.23 acc: 91.83
Epoch[75 (29325/64000) (550.4284sec)] loss: 94.02 acc: 91.56
Epoch[76 (29716/64000) (557.9773sec)] loss: 92.61 acc: 91.70
Epoch[77 (30107/64000) (565.2475sec)] loss: 92.84 acc: 91.59
Epoch[78 (30498/64000) (572.4811sec)] loss: 92.01 acc: 91.85
Epoch[79 (30889/64000) (580.0703sec)] loss: 89.81 acc: 91.93
Epoch[80 (31280/64000) (587.3492sec)] loss: 91.17 acc: 91.83
Epoch[81 (31671/64000) (594.7008sec)] loss: 90.31 acc: 91.84
Epoch[82 (32062/64000) (602.0518sec)] loss: 88.09 acc: 92.12
Epoch[83 (32453/64000) (609.5276sec)] loss: 55.12 acc: 95.01
Epoch[84 (32844/64000) (616.7906sec)] loss: 47.74 acc: 95.84
Epoch[85 (33235/64000) (624.1608sec)] loss: 42.93 acc: 96.36
Epoch[86 (33626/64000) (631.1735sec)] loss: 40.43 acc: 96.55
Epoch[87 (34017/64000) (638.5726sec)] loss: 39.21 acc: 96.62
Epoch[88 (34408/64000) (645.9556sec)] loss: 36.76 acc: 96.87
Epoch[89 (34799/64000) (653.2316sec)] loss: 36.14 acc: 96.96
Epoch[90 (35190/64000) (660.9627sec)] loss: 33.30 acc: 97.22
Epoch[91 (35581/64000) (668.3827sec)] loss: 31.57 acc: 97.17
Epoch[92 (35972/64000) (675.5018sec)] loss: 31.88 acc: 97.22
Epoch[93 (36363/64000) (682.8006sec)] loss: 30.31 acc: 97.43
Epoch[94 (36754/64000) (689.9211sec)] loss: 29.82 acc: 97.39
Epoch[95 (37145/64000) (697.3719sec)] loss: 28.64 acc: 97.57
Epoch[96 (37536/64000) (705.3345sec)] loss: 28.83 acc: 97.45
Epoch[97 (37927/64000) (712.7620sec)] loss: 27.33 acc: 97.71
Epoch[98 (38318/64000) (720.2508sec)] loss: 25.83 acc: 97.87
Epoch[99 (38709/64000) (727.6618sec)] loss: 25.94 acc: 97.68
Epoch[100 (39100/64000) (734.5958sec)] loss: 25.71 acc: 97.73
Epoch[101 (39491/64000) (742.2419sec)] loss: 24.99 acc: 97.81
Epoch[102 (39882/64000) (750.0543sec)] loss: 24.45 acc: 97.92
Epoch[103 (40273/64000) (757.1618sec)] loss: 24.02 acc: 97.92
Epoch[104 (40664/64000) (764.5942sec)] loss: 22.69 acc: 98.08
Epoch[105 (41055/64000) (771.7031sec)] loss: 22.70 acc: 98.06
Epoch[106 (41446/64000) (779.2763sec)] loss: 21.59 acc: 98.18
Epoch[107 (41837/64000) (786.7181sec)] loss: 22.31 acc: 98.04
Epoch[108 (42228/64000) (793.8452sec)] loss: 20.78 acc: 98.23
Epoch[109 (42619/64000) (801.4266sec)] loss: 20.54 acc: 98.20
Epoch[110 (43010/64000) (808.9340sec)] loss: 20.38 acc: 98.28
Epoch[111 (43401/64000) (816.5496sec)] loss: 20.61 acc: 98.23
Epoch[112 (43792/64000) (823.7053sec)] loss: 20.64 acc: 98.22
Epoch[113 (44183/64000) (831.0946sec)] loss: 19.89 acc: 98.25
Epoch[114 (44574/64000) (838.1194sec)] loss: 20.06 acc: 98.26
Epoch[115 (44965/64000) (845.7004sec)] loss: 19.35 acc: 98.36
Epoch[116 (45356/64000) (853.1254sec)] loss: 19.46 acc: 98.36
Epoch[117 (45747/64000) (860.7161sec)] loss: 19.38 acc: 98.33
Epoch[118 (46138/64000) (868.0838sec)] loss: 19.21 acc: 98.34
Epoch[119 (46529/64000) (875.4143sec)] loss: 18.16 acc: 98.43
Epoch[120 (46920/64000) (883.0658sec)] loss: 18.06 acc: 98.42
Epoch[121 (47311/64000) (890.5691sec)] loss: 17.26 acc: 98.52
Epoch[122 (47702/64000) (898.1425sec)] loss: 17.24 acc: 98.57
Epoch[123 (48093/64000) (905.6408sec)] loss: 17.67 acc: 98.54
Epoch[124 (48484/64000) (912.7591sec)] loss: 15.04 acc: 98.80
Epoch[125 (48875/64000) (919.8622sec)] loss: 14.24 acc: 98.87
Epoch[126 (49266/64000) (927.0275sec)] loss: 13.96 acc: 98.88
Epoch[127 (49657/64000) (934.2595sec)] loss: 13.83 acc: 98.91
Epoch[128 (50048/64000) (941.7233sec)] loss: 12.73 acc: 99.01
Epoch[129 (50439/64000) (949.4730sec)] loss: 13.47 acc: 98.94
Epoch[130 (50830/64000) (956.3760sec)] loss: 13.00 acc: 99.00
Epoch[131 (51221/64000) (964.1147sec)] loss: 12.73 acc: 99.03
Epoch[132 (51612/64000) (971.5320sec)] loss: 12.90 acc: 99.04
Epoch[133 (52003/64000) (978.7294sec)] loss: 12.80 acc: 99.01
Epoch[134 (52394/64000) (986.0192sec)] loss: 12.28 acc: 99.11
Epoch[135 (52785/64000) (993.1015sec)] loss: 12.77 acc: 99.02
Epoch[136 (53176/64000) (1000.2869sec)] loss: 12.77 acc: 98.99
Epoch[137 (53567/64000) (1007.5633sec)] loss: 12.44 acc: 99.09
Epoch[138 (53958/64000) (1014.4154sec)] loss: 12.59 acc: 99.00
Epoch[139 (54349/64000) (1021.9794sec)] loss: 12.80 acc: 99.01
Epoch[140 (54740/64000) (1029.1151sec)] loss: 12.11 acc: 99.06
Epoch[141 (55131/64000) (1037.0154sec)] loss: 11.83 acc: 99.10
Epoch[142 (55522/64000) (1044.2304sec)] loss: 12.21 acc: 99.06
Epoch[143 (55913/64000) (1052.0665sec)] loss: 12.36 acc: 99.02
Epoch[144 (56304/64000) (1059.4328sec)] loss: 12.20 acc: 99.03
Epoch[145 (56695/64000) (1067.1640sec)] loss: 12.19 acc: 99.05
Epoch[146 (57086/64000) (1074.0894sec)] loss: 11.74 acc: 99.10
Epoch[147 (57477/64000) (1081.3311sec)] loss: 11.91 acc: 99.09
Epoch[148 (57868/64000) (1089.0102sec)] loss: 12.08 acc: 99.11
Epoch[149 (58259/64000) (1096.2499sec)] loss: 12.17 acc: 99.03
Epoch[150 (58650/64000) (1103.7006sec)] loss: 11.59 acc: 99.16
Epoch[151 (59041/64000) (1111.1318sec)] loss: 11.78 acc: 99.08
Epoch[152 (59432/64000) (1118.4786sec)] loss: 11.68 acc: 99.08
Epoch[153 (59823/64000) (1125.7784sec)] loss: 11.71 acc: 99.10
Epoch[154 (60214/64000) (1133.2468sec)] loss: 11.25 acc: 99.14
Epoch[155 (60605/64000) (1140.5466sec)] loss: 11.38 acc: 99.12
Epoch[156 (60996/64000) (1148.2231sec)] loss: 11.42 acc: 99.14
Epoch[157 (61387/64000) (1155.5876sec)] loss: 11.47 acc: 99.16
Epoch[158 (61778/64000) (1163.0776sec)] loss: 11.76 acc: 99.14
Epoch[159 (62169/64000) (1170.4764sec)] loss: 11.48 acc: 99.16
Epoch[160 (62560/64000) (1177.9013sec)] loss: 11.55 acc: 99.16
Epoch[161 (62951/64000) (1185.1235sec)] loss: 11.17 acc: 99.22
Epoch[162 (63342/64000) (1192.7358sec)] loss: 11.11 acc: 99.22
Epoch[163 (63733/64000) (1199.8564sec)] loss: 11.27 acc: 99.15
Epoch[164 (64124/64000) (1207.2868sec)] loss: 10.85 acc: 99.20Plot train loss and calculate test performance.
import matplotlib
import matplotlib.pyplot as pltplt.plot(losses)[<matplotlib.lines.Line2D at 0x7fc6fc5d45b0>]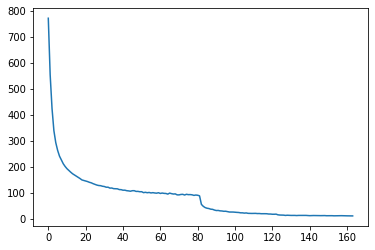
net.eval()
test_correct = 0.0
test_total = 0.0
for batch_idx, (x, y) in enumerate(cifar_loader['test']):
x, y = x.to(device), y.to(device)
out = net(x)
test_correct += (out.argmax(1) == y).float().sum().item()
test_total += x.size(0)
print(test_correct/test_total * 100.)
90.91Train CNNs wihtout residual connection.
start_time = time.time()
net_plain = cnn18().to(device)
optimizer = torch.optim.SGD(net_plain.parameters(), lr=0.1, momentum=0.9, weight_decay=1e-4)
decay_epoch = [32000, 48000]
step_lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=decay_epoch, gamma=0.1)
net_plain.train()
step = 0
epochs = 0
losses_plain = []
while step < 64000:
train_loss = 0.0
correct = 0.0
total = 0.0
for batch_idx, (x, y) in enumerate(cifar_loader['train']):
step += 1
step_lr_scheduler.step()
x, y = x.to(device), y.to(device)
out = net_plain(x)
loss = criterion(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
correct += (out.argmax(1) == y).float().sum().item()
total += x.size(0)
train_loss += loss.item()
losses_plain.append(train_loss)
epochs += 1
print("Epoch[{:d} ({:d}/64000) ({:.4f}sec)] loss: {:.2f} acc: {:.2f}".format(epochs, step, time.time()-start_time, train_loss, 100.*correct/total))
Epoch[1 (391/64000) (7.2146sec)] loss: 689.96 acc: 32.64
Epoch[2 (782/64000) (14.0851sec)] loss: 534.03 acc: 49.99
Epoch[3 (1173/64000) (21.1075sec)] loss: 431.50 acc: 60.38
Epoch[4 (1564/64000) (27.8955sec)] loss: 365.12 acc: 67.19
Epoch[5 (1955/64000) (35.2117sec)] loss: 322.34 acc: 71.42
Epoch[6 (2346/64000) (42.2845sec)] loss: 294.47 acc: 73.99
Epoch[7 (2737/64000) (49.2290sec)] loss: 271.72 acc: 75.82
Epoch[8 (3128/64000) (56.3330sec)] loss: 254.65 acc: 77.43
Epoch[9 (3519/64000) (63.5271sec)] loss: 241.44 acc: 78.56
Epoch[10 (3910/64000) (70.4259sec)] loss: 230.29 acc: 79.66
Epoch[11 (4301/64000) (77.7810sec)] loss: 221.22 acc: 80.33
Epoch[12 (4692/64000) (84.4624sec)] loss: 213.80 acc: 80.99
Epoch[13 (5083/64000) (91.6520sec)] loss: 207.05 acc: 81.70
Epoch[14 (5474/64000) (98.5922sec)] loss: 202.37 acc: 82.03
Epoch[15 (5865/64000) (105.6009sec)] loss: 196.83 acc: 82.59
Epoch[16 (6256/64000) (112.5703sec)] loss: 190.15 acc: 83.11
Epoch[17 (6647/64000) (119.7448sec)] loss: 186.84 acc: 83.63
Epoch[18 (7038/64000) (126.8488sec)] loss: 183.72 acc: 83.64
Epoch[19 (7429/64000) (133.8145sec)] loss: 180.63 acc: 84.00
Epoch[20 (7820/64000) (141.3312sec)] loss: 173.23 acc: 84.69
Epoch[21 (8211/64000) (148.5181sec)] loss: 171.94 acc: 84.75
Epoch[22 (8602/64000) (155.6639sec)] loss: 172.15 acc: 84.83
Epoch[23 (8993/64000) (162.7647sec)] loss: 166.39 acc: 85.33
Epoch[24 (9384/64000) (169.8326sec)] loss: 164.23 acc: 85.60
Epoch[25 (9775/64000) (176.5753sec)] loss: 162.15 acc: 85.63
Epoch[26 (10166/64000) (184.2141sec)] loss: 159.41 acc: 85.83
Epoch[27 (10557/64000) (191.5325sec)] loss: 157.73 acc: 86.02
Epoch[28 (10948/64000) (198.5394sec)] loss: 154.05 acc: 86.34
Epoch[29 (11339/64000) (205.9462sec)] loss: 154.87 acc: 86.25
Epoch[30 (11730/64000) (213.1766sec)] loss: 151.16 acc: 86.58
Epoch[31 (12121/64000) (220.3204sec)] loss: 148.59 acc: 86.81
Epoch[32 (12512/64000) (227.7061sec)] loss: 149.22 acc: 86.74
Epoch[33 (12903/64000) (234.9168sec)] loss: 145.34 acc: 87.20
Epoch[34 (13294/64000) (242.4034sec)] loss: 145.30 acc: 87.09
Epoch[35 (13685/64000) (249.7116sec)] loss: 144.28 acc: 87.20
Epoch[36 (14076/64000) (256.6604sec)] loss: 145.93 acc: 87.09
Epoch[37 (14467/64000) (263.6526sec)] loss: 141.30 acc: 87.39
Epoch[38 (14858/64000) (270.8084sec)] loss: 141.42 acc: 87.42
Epoch[39 (15249/64000) (278.1218sec)] loss: 139.26 acc: 87.79
Epoch[40 (15640/64000) (285.5205sec)] loss: 138.97 acc: 87.62
Epoch[41 (16031/64000) (292.6338sec)] loss: 137.25 acc: 87.71
Epoch[42 (16422/64000) (299.8960sec)] loss: 137.89 acc: 87.68
Epoch[43 (16813/64000) (306.4615sec)] loss: 135.12 acc: 88.06
Epoch[44 (17204/64000) (313.7000sec)] loss: 134.36 acc: 88.04
Epoch[45 (17595/64000) (321.3406sec)] loss: 132.38 acc: 88.35
Epoch[46 (17986/64000) (328.3074sec)] loss: 131.92 acc: 88.36
Epoch[47 (18377/64000) (335.5251sec)] loss: 132.07 acc: 88.24
Epoch[48 (18768/64000) (342.7595sec)] loss: 130.68 acc: 88.37
Epoch[49 (19159/64000) (349.6263sec)] loss: 131.12 acc: 88.36
Epoch[50 (19550/64000) (357.0380sec)] loss: 129.32 acc: 88.59
Epoch[51 (19941/64000) (364.0892sec)] loss: 129.24 acc: 88.47
Epoch[52 (20332/64000) (371.3756sec)] loss: 125.61 acc: 88.80
Epoch[53 (20723/64000) (378.6191sec)] loss: 126.88 acc: 88.69
Epoch[54 (21114/64000) (386.2752sec)] loss: 127.91 acc: 88.60
Epoch[55 (21505/64000) (393.5364sec)] loss: 128.70 acc: 88.63
Epoch[56 (21896/64000) (401.0215sec)] loss: 125.44 acc: 88.89
Epoch[57 (22287/64000) (408.1538sec)] loss: 125.58 acc: 88.75
Epoch[58 (22678/64000) (415.5634sec)] loss: 125.72 acc: 88.87
Epoch[59 (23069/64000) (422.6407sec)] loss: 123.13 acc: 88.96
Epoch[60 (23460/64000) (430.0556sec)] loss: 122.40 acc: 89.13
Epoch[61 (23851/64000) (437.3062sec)] loss: 125.74 acc: 88.78
Epoch[62 (24242/64000) (444.5036sec)] loss: 122.89 acc: 89.15
Epoch[63 (24633/64000) (452.3249sec)] loss: 123.77 acc: 88.91
Epoch[64 (25024/64000) (459.5320sec)] loss: 122.94 acc: 89.25
Epoch[65 (25415/64000) (466.6736sec)] loss: 120.77 acc: 89.23
Epoch[66 (25806/64000) (473.8049sec)] loss: 120.41 acc: 89.33
Epoch[67 (26197/64000) (481.0442sec)] loss: 121.50 acc: 89.21
Epoch[68 (26588/64000) (488.1004sec)] loss: 119.03 acc: 89.32
Epoch[69 (26979/64000) (495.2542sec)] loss: 119.38 acc: 89.39
Epoch[70 (27370/64000) (502.5304sec)] loss: 118.89 acc: 89.41
Epoch[71 (27761/64000) (509.6415sec)] loss: 118.88 acc: 89.42
Epoch[72 (28152/64000) (517.0511sec)] loss: 119.19 acc: 89.33
Epoch[73 (28543/64000) (524.6494sec)] loss: 116.20 acc: 89.56
Epoch[74 (28934/64000) (532.1471sec)] loss: 117.11 acc: 89.50
Epoch[75 (29325/64000) (539.0524sec)] loss: 116.53 acc: 89.57
Epoch[76 (29716/64000) (546.3680sec)] loss: 116.04 acc: 89.69
Epoch[77 (30107/64000) (553.8518sec)] loss: 114.30 acc: 89.81
Epoch[78 (30498/64000) (560.7083sec)] loss: 117.23 acc: 89.61
Epoch[79 (30889/64000) (568.3386sec)] loss: 115.09 acc: 89.64
Epoch[80 (31280/64000) (575.4272sec)] loss: 115.39 acc: 89.71
Epoch[81 (31671/64000) (582.9671sec)] loss: 115.24 acc: 89.78
Epoch[82 (32062/64000) (590.4794sec)] loss: 111.38 acc: 90.12
Epoch[83 (32453/64000) (597.6994sec)] loss: 72.23 acc: 93.75
Epoch[84 (32844/64000) (604.8231sec)] loss: 62.88 acc: 94.50
Epoch[85 (33235/64000) (611.8527sec)] loss: 56.76 acc: 94.99
Epoch[86 (33626/64000) (619.0148sec)] loss: 54.20 acc: 95.25
Epoch[87 (34017/64000) (626.0946sec)] loss: 51.18 acc: 95.52
Epoch[88 (34408/64000) (633.2502sec)] loss: 48.66 acc: 95.59
Epoch[89 (34799/64000) (640.3661sec)] loss: 47.33 acc: 95.76
Epoch[90 (35190/64000) (647.5268sec)] loss: 45.99 acc: 96.00
Epoch[91 (35581/64000) (654.4824sec)] loss: 45.55 acc: 95.94
Epoch[92 (35972/64000) (661.5328sec)] loss: 43.50 acc: 96.10
Epoch[93 (36363/64000) (669.0501sec)] loss: 42.39 acc: 96.25
Epoch[94 (36754/64000) (675.8983sec)] loss: 41.10 acc: 96.30
Epoch[95 (37145/64000) (683.0879sec)] loss: 40.02 acc: 96.43
Epoch[96 (37536/64000) (689.9680sec)] loss: 39.87 acc: 96.43
Epoch[97 (37927/64000) (697.5684sec)] loss: 38.91 acc: 96.40
Epoch[98 (38318/64000) (705.0191sec)] loss: 37.55 acc: 96.64
Epoch[99 (38709/64000) (712.0232sec)] loss: 38.73 acc: 96.52
Epoch[100 (39100/64000) (719.0744sec)] loss: 37.01 acc: 96.65
Epoch[101 (39491/64000) (726.0455sec)] loss: 35.86 acc: 96.82
Epoch[102 (39882/64000) (733.0002sec)] loss: 34.39 acc: 96.92
Epoch[103 (40273/64000) (740.0890sec)] loss: 34.96 acc: 96.80
Epoch[104 (40664/64000) (747.1744sec)] loss: 34.97 acc: 96.85
Epoch[105 (41055/64000) (754.5613sec)] loss: 33.63 acc: 97.05
Epoch[106 (41446/64000) (761.6926sec)] loss: 33.05 acc: 96.99
Epoch[107 (41837/64000) (768.4621sec)] loss: 31.74 acc: 97.07
Epoch[108 (42228/64000) (775.7621sec)] loss: 31.21 acc: 97.12
Epoch[109 (42619/64000) (783.0051sec)] loss: 30.95 acc: 97.28
Epoch[110 (43010/64000) (790.3146sec)] loss: 30.28 acc: 97.30
Epoch[111 (43401/64000) (797.2794sec)] loss: 30.53 acc: 97.29
Epoch[112 (43792/64000) (804.7434sec)] loss: 28.15 acc: 97.52
Epoch[113 (44183/64000) (811.9753sec)] loss: 28.40 acc: 97.43
Epoch[114 (44574/64000) (819.5330sec)] loss: 29.56 acc: 97.38
Epoch[115 (44965/64000) (826.2002sec)] loss: 29.17 acc: 97.38
Epoch[116 (45356/64000) (833.0710sec)] loss: 27.47 acc: 97.51
Epoch[117 (45747/64000) (839.8714sec)] loss: 28.09 acc: 97.48
Epoch[118 (46138/64000) (847.1031sec)] loss: 27.38 acc: 97.54
Epoch[119 (46529/64000) (853.9757sec)] loss: 27.01 acc: 97.68
Epoch[120 (46920/64000) (861.0741sec)] loss: 27.05 acc: 97.49
Epoch[121 (47311/64000) (868.4948sec)] loss: 25.27 acc: 97.70
Epoch[122 (47702/64000) (875.9437sec)] loss: 26.23 acc: 97.68
Epoch[123 (48093/64000) (883.0364sec)] loss: 25.37 acc: 97.69
Epoch[124 (48484/64000) (890.1893sec)] loss: 21.02 acc: 98.17
Epoch[125 (48875/64000) (897.0977sec)] loss: 19.10 acc: 98.36
Epoch[126 (49266/64000) (904.3798sec)] loss: 19.64 acc: 98.38
Epoch[127 (49657/64000) (911.3010sec)] loss: 19.37 acc: 98.37
Epoch[128 (50048/64000) (918.2357sec)] loss: 18.63 acc: 98.46
Epoch[129 (50439/64000) (925.3542sec)] loss: 18.14 acc: 98.56
Epoch[130 (50830/64000) (932.3081sec)] loss: 18.32 acc: 98.48
Epoch[131 (51221/64000) (939.6098sec)] loss: 17.52 acc: 98.50
Epoch[132 (51612/64000) (946.9333sec)] loss: 18.32 acc: 98.46
Epoch[133 (52003/64000) (954.2119sec)] loss: 18.10 acc: 98.41
Epoch[134 (52394/64000) (961.7445sec)] loss: 17.30 acc: 98.60
Epoch[135 (52785/64000) (968.3853sec)] loss: 16.70 acc: 98.63
Epoch[136 (53176/64000) (975.5887sec)] loss: 17.46 acc: 98.57
Epoch[137 (53567/64000) (982.8676sec)] loss: 16.70 acc: 98.65
Epoch[138 (53958/64000) (989.9611sec)] loss: 16.97 acc: 98.61
Epoch[139 (54349/64000) (997.1548sec)] loss: 17.21 acc: 98.60
Epoch[140 (54740/64000) (1004.1162sec)] loss: 16.58 acc: 98.58
Epoch[141 (55131/64000) (1011.4397sec)] loss: 16.97 acc: 98.54
Epoch[142 (55522/64000) (1018.6986sec)] loss: 16.68 acc: 98.64
Epoch[143 (55913/64000) (1026.1204sec)] loss: 16.96 acc: 98.59
Epoch[144 (56304/64000) (1033.3482sec)] loss: 16.73 acc: 98.62
Epoch[145 (56695/64000) (1040.8932sec)] loss: 16.49 acc: 98.65
Epoch[146 (57086/64000) (1047.9436sec)] loss: 15.84 acc: 98.64
Epoch[147 (57477/64000) (1055.0756sec)] loss: 16.30 acc: 98.62
Epoch[148 (57868/64000) (1062.2017sec)] loss: 16.09 acc: 98.70
Epoch[149 (58259/64000) (1069.3741sec)] loss: 15.77 acc: 98.70
Epoch[150 (58650/64000) (1076.7737sec)] loss: 15.84 acc: 98.73
Epoch[151 (59041/64000) (1084.0027sec)] loss: 15.53 acc: 98.73
Epoch[152 (59432/64000) (1091.1483sec)] loss: 15.96 acc: 98.68
Epoch[153 (59823/64000) (1098.4126sec)] loss: 16.13 acc: 98.60
Epoch[154 (60214/64000) (1105.4872sec)] loss: 15.56 acc: 98.72
Epoch[155 (60605/64000) (1112.7199sec)] loss: 14.85 acc: 98.78
Epoch[156 (60996/64000) (1119.6450sec)] loss: 15.91 acc: 98.66
Epoch[157 (61387/64000) (1127.0011sec)] loss: 15.38 acc: 98.73
Epoch[158 (61778/64000) (1134.2234sec)] loss: 16.08 acc: 98.68
Epoch[159 (62169/64000) (1141.3570sec)] loss: 15.36 acc: 98.76
Epoch[160 (62560/64000) (1148.5884sec)] loss: 15.25 acc: 98.80
Epoch[161 (62951/64000) (1155.6970sec)] loss: 15.60 acc: 98.76
Epoch[162 (63342/64000) (1162.9399sec)] loss: 15.12 acc: 98.72
Epoch[163 (63733/64000) (1170.2920sec)] loss: 14.52 acc: 98.81
Epoch[164 (64124/64000) (1177.5772sec)] loss: 14.71 acc: 98.79Plot train loss and calculate test performance.
plt.plot(losses, label='resnet')
plt.plot(losses_plain, label='cnn')
plt.legend()
plt.show()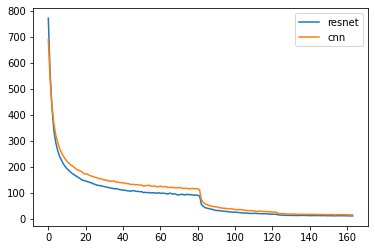
net_plain.eval()
test_correct = 0.0
test_total = 0.0
for batch_idx, (x, y) in enumerate(cifar_loader['test']):
x, y = x.to(device), y.to(device)
out = net_plain(x)
test_correct += (out.argmax(1) == y).float().sum().item()
test_total += x.size(0)
print(test_correct/test_total * 100.)
90.47Reference
- https://tutorials.pytorch.kr/beginner/blitz/neural_networks_tutorial.html
- https://github.com/dnddnjs/pytorch-cifar10/blob/enas/resnet/model.py
- https://icml.cc/2016/tutorials/icml2016_tutorial_deep_residual_networks_kaiminghe.pdf
Reference
- AI504: Programming for AI Lecture at KAIST AI
