Image-to-text (Image Captioning)
- Image to sequence
- Encoder: CNN, ViT
- Decoder: RNN, Transformer
Show and Tell
- Show and Tell: A Neural Image Caption Generator (NIC)
- Vinyals et al. CVPR 2015
- First paper to perform neural image captioning without any domain knowledge
- No object detection, language modeling, description templates
- Not text ranking, but pure generation
- End-to-end training
- 이 모델로도 이미 여러 dataset에서 human보다 좋은 성능을 보였다.
🔗 Architecture
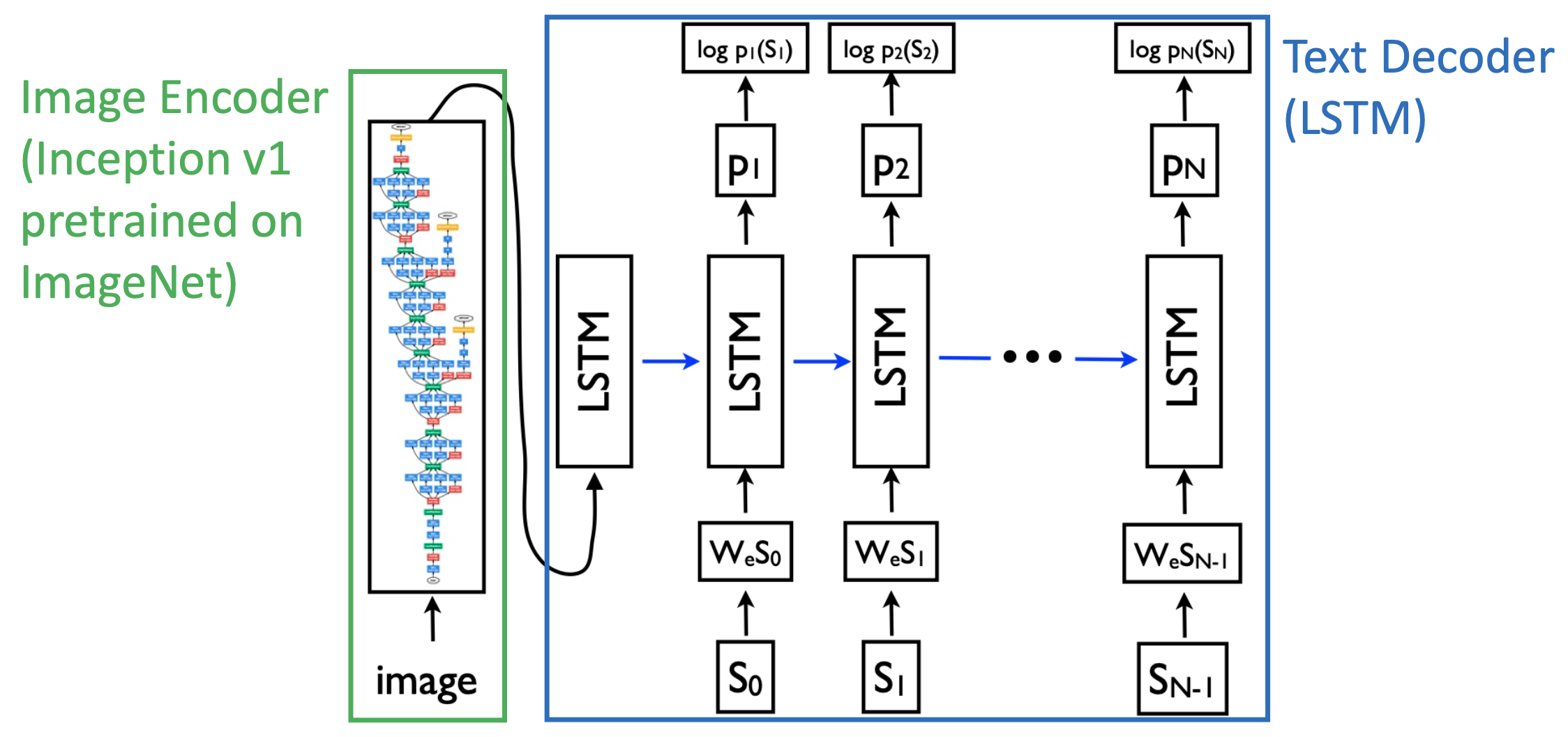
: token, word
: hidden layer/memory from LSTM or GRU
: word embedding
: CNN(Image)
: START, : END
- = Softmax( + b)
- = RNN(, )
- LSTM의 첫 번째 input은 image embedding이다.
- Decoder의 hidden layer를 image embedding으로 initialize하는 것이 아니다. Image embedding이 첫 번째 input으로 들어간다.
Show, Attend and Tell
- Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
- Xu et al. ICML 2015
- Mixing attention mechanism with image captioning
- Attention mechanism을 적용하므로써 NIC보다 성능이 좋아졌다.
🔗 High-level architecture
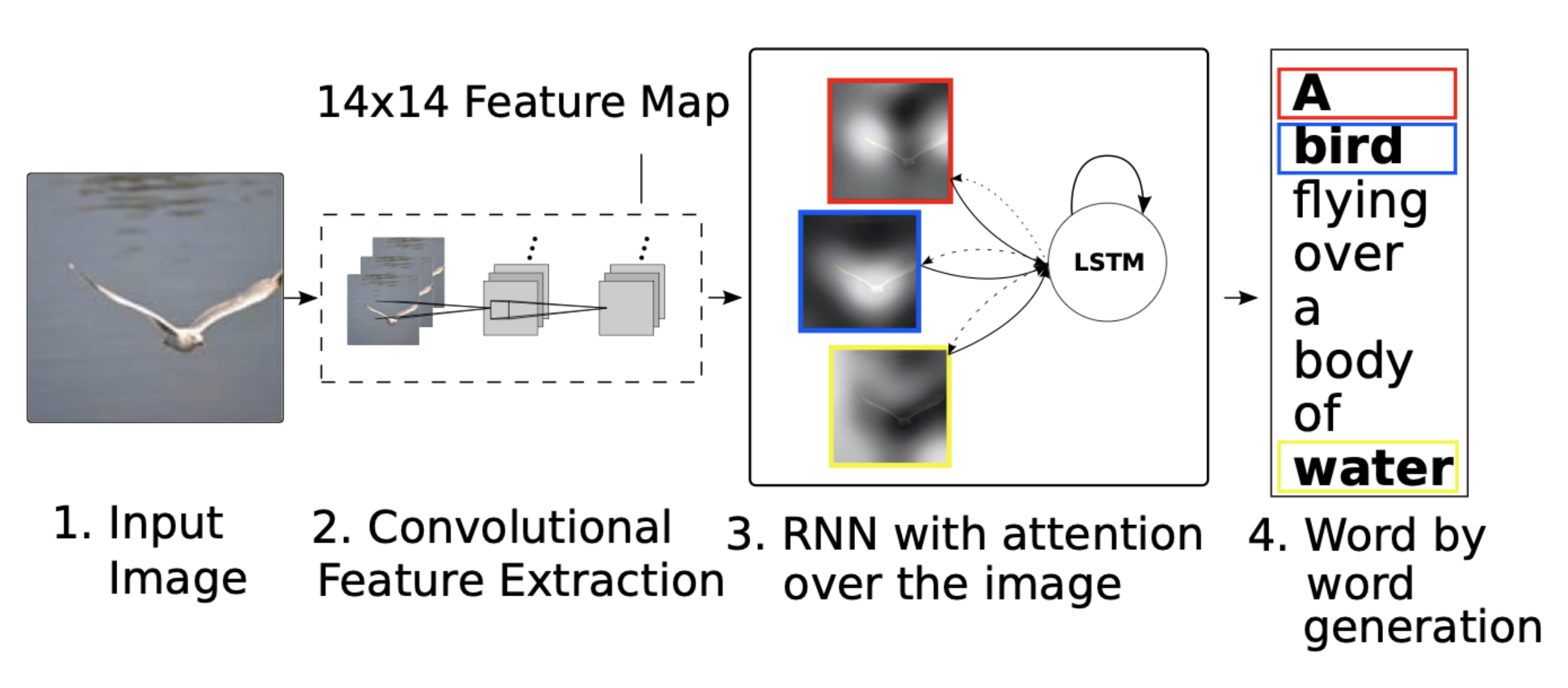
- Show and Tell에서는 512 dimensional vector였는데, 여기서는 feature map을 이용한다. Feature map에 spacial information이 살아있다. 그리고 그 위에 attention mechanism을 적용한다.
🔗 Example

- Example : "A bird flying over a body of water ."
- Original show, attend, and tell에서는 두 가지 attention mode가 있었다.
- Top row : "soft" attention
- Bottom row : "hard" attention
- 모델이 한번에 오직 한 image fiber or feature map에만 attend하는 제약이 있다.
- Model이 word를 generate할 때 image에서 관련된 부분을 "attend"하는 것을 볼 수 있다.
🔗 Encoder-Decoder Architecture
What we need
- Encoder to obtain image representation
- Oxford VGGnet
- Decoder to generate caption
- LSTM
- Attention module to calculate attention weights
- MLP
🔗 How to Attend to Part of Image
-
VGG 16
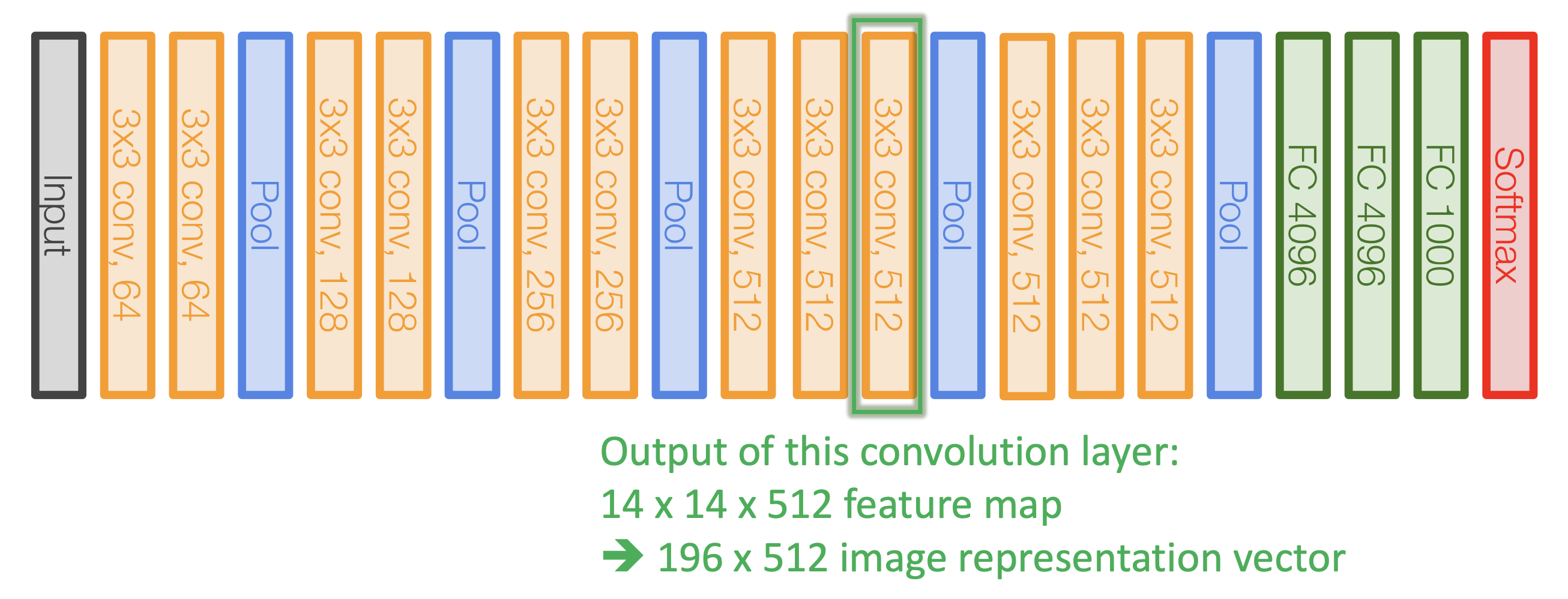
- Show, attend and tell에서 이 9번째 convolutional layer의 output을 선택했다.
- 128 * 128 spatial dimension이 14 * 14 spatial information으로 줄어든 것이다. 각 14 * 14 feature map이 input에서 꽤 큰 receptive field를 가질 것이라는 것을 알 수 있다.
-
Flattening the image feature maps
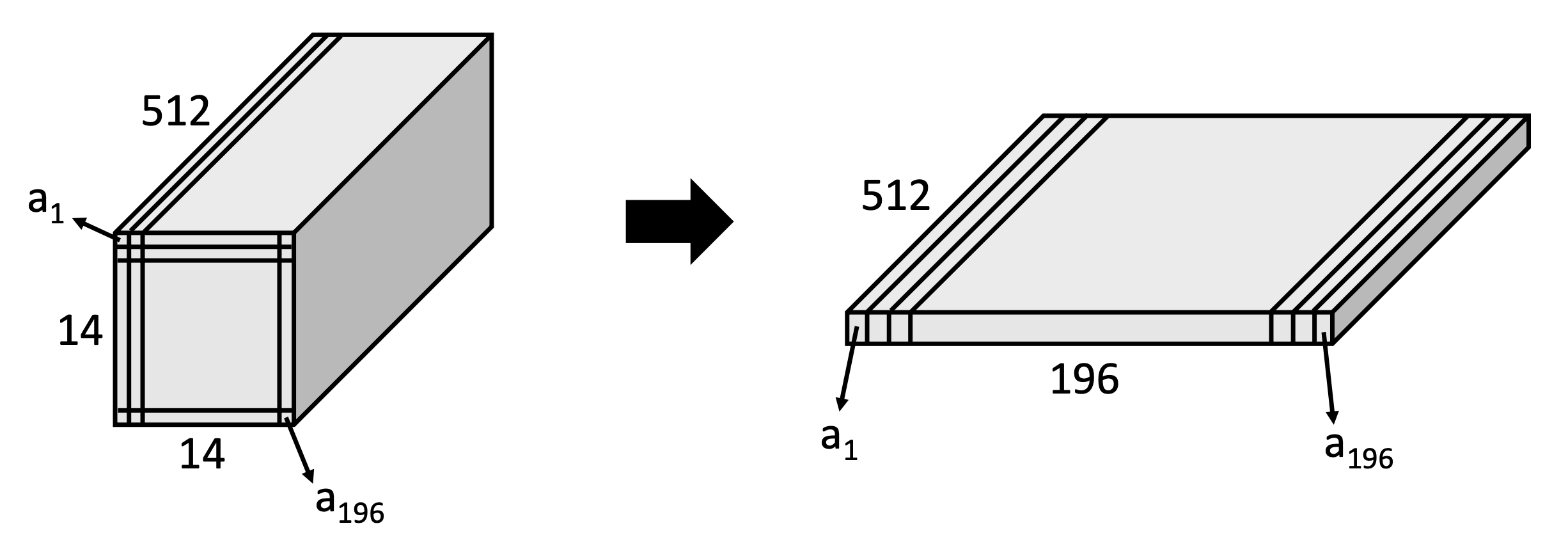
- Spatial information을 약간 파괴한다.
- 결국 196개의 feature map이 있고, 각 feature map은 512 dimension이다.
🔗 Show, Attend and Tell
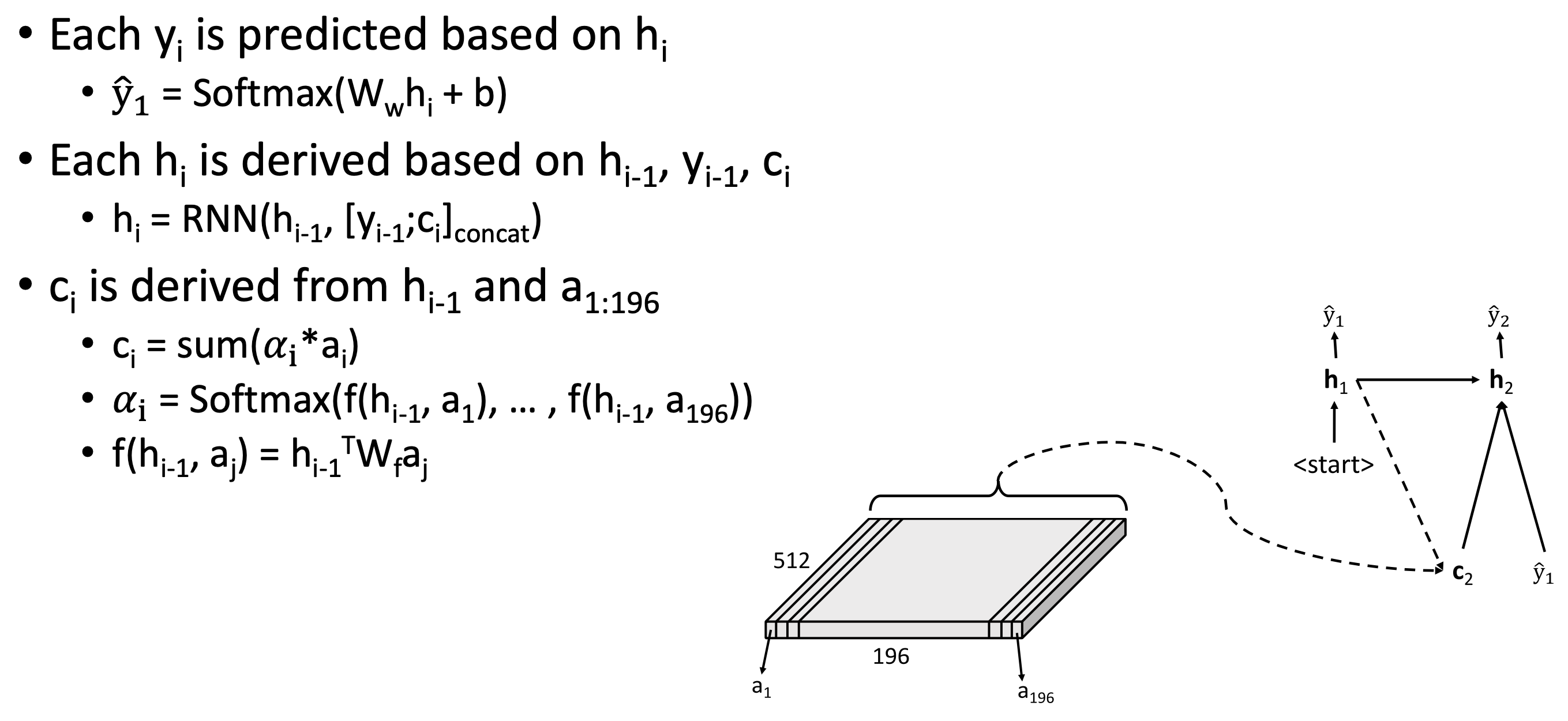
🔗 Some technical details
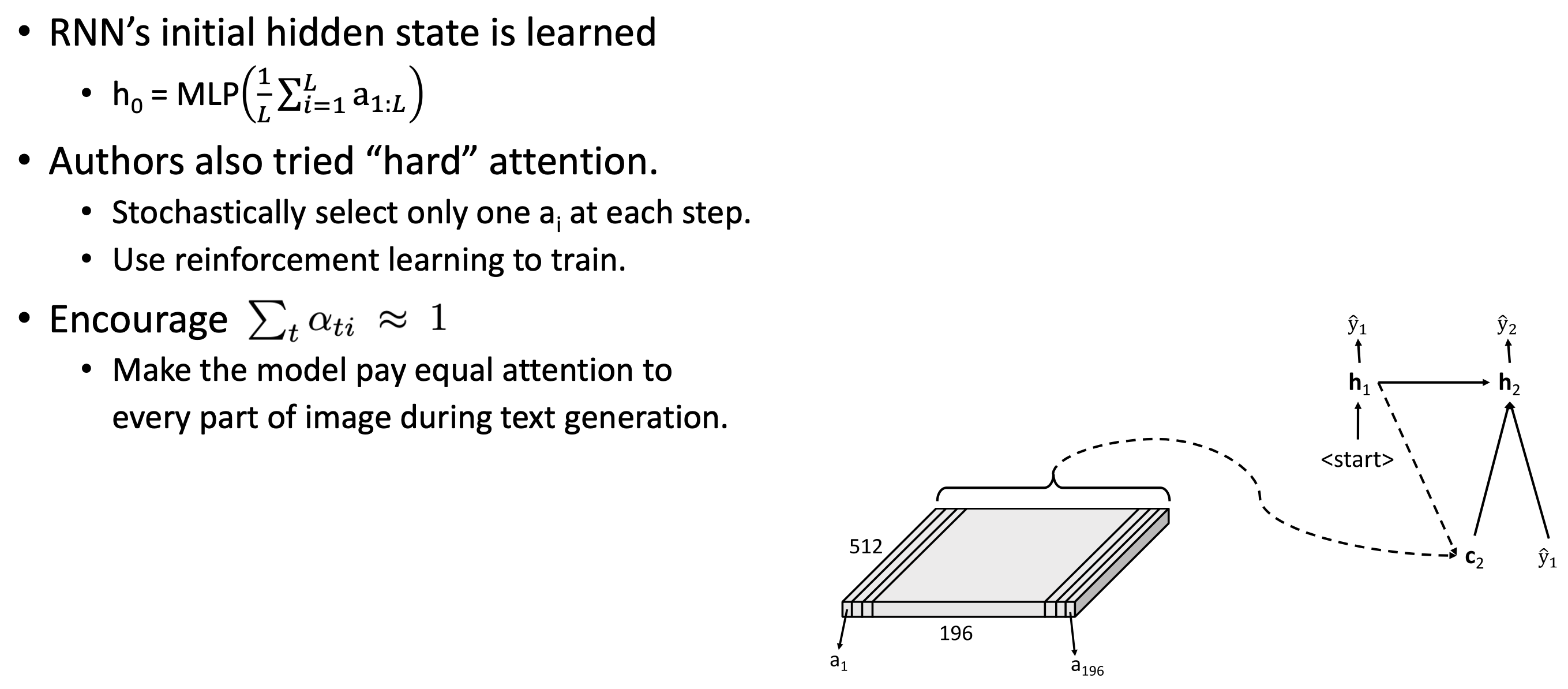
- RNN의 initial hidden state는 random하게 또는 zero로 initialize되지 않는다.
- 부터 까지 모든 captioning process 통틀어서 모든 fiber들이 평균적으로 최소 한 번은 사용될 수 있도록 한다. 이렇게 하여 detail을 놓치지 않도록 한다.
Text-to-Image
🔗 Generative Adversarial Text to Image Synthesis
- Reed et al. ICML 2016
- Text-conditioned image generation with GAN
- Model Architecture
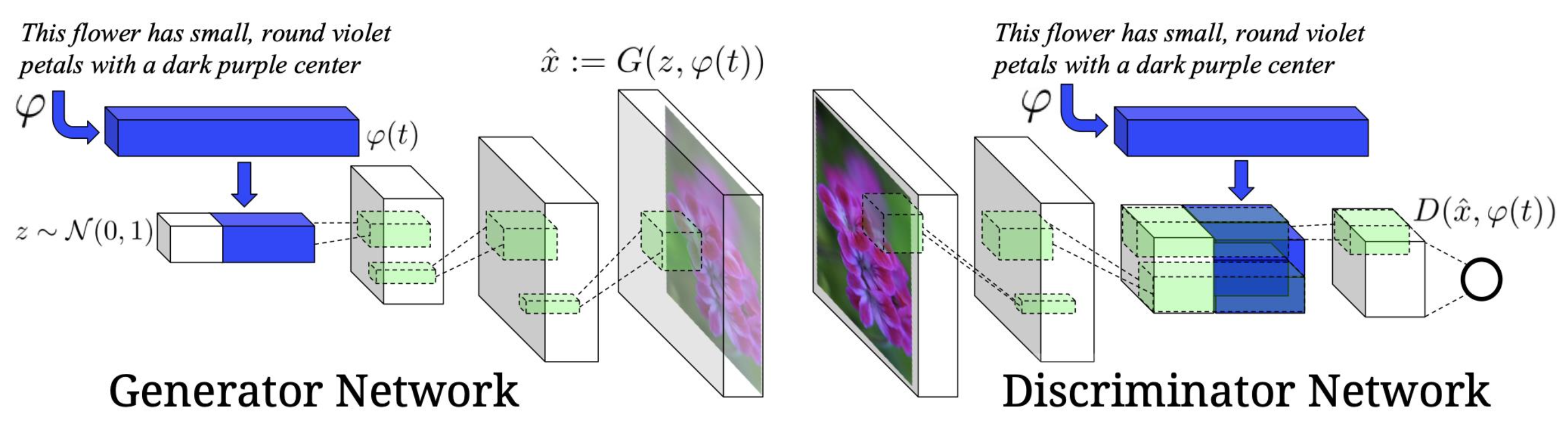
- Encode text with RNN
- Decode (i.e. generate) image with GAN
- Use deconvolution (like DC-GAN) to upsample.
- Generator network : 처음에 text embedding에 noise z 추가
- GAN을 이용할 때 항상 noise를 uniform distribution에서 sampling하는 것을 적용
- Discriminator network : Image embedding과 text embedding을 동시에 받아드려 1인지 0인지 본다.
- Training Strategy

- 성능 : 디테일적으로 완벽하진 않다.
- 2016년 이므로 low resolution image이었던 것에도 주요 원인이 있다.
DALL-E
- 위 모델이 나오고 4~5년 뒤 나왔다.
- Zero-Shot Text-to-Image Generation
- Ramesh et al. (OpenAI), 2021
- Purely based on Transformers + Vector Quantization
- No GAN, no VAE, only decoder
- 의의
- 이전 모델의 captions는 test set의 sample이다. Train distribution과 test distribution이 거의 같아 test sample들이 distribution을 벗어나지 않는다.
- 하지만 DALL-E 1은 model을 많은 양의 text-image 쌍들로 train하였고, distribution에서 완전히 벗어난 것들에서도 동작한다.
- 이 세상에 없는 image들, 완전히 imaginary한 것들이라고 보장할 수 있다.
- 이는 DALL-E 1이 얼마나 generalizable한지를 보여준다.
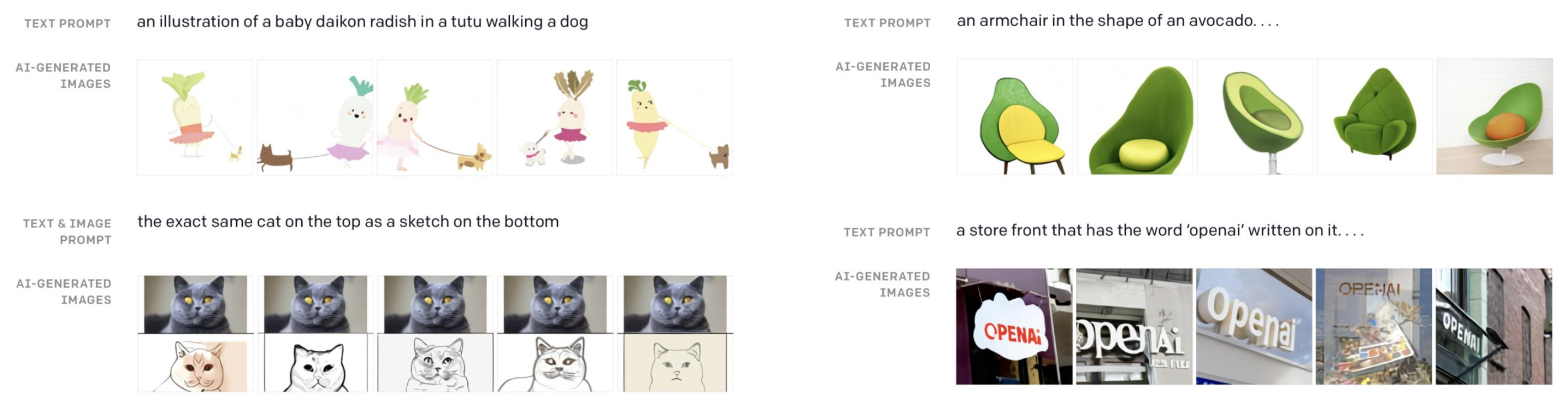
🔗 Image Tokens
- DALL-E는 "vector quantization"을 사용한다.
- 각 image feature를 image token으로 대체한다.
- There is a predefined dictionary of image tokens
- 이제 image는 text처럼 sequence of tokens로 represent될 수 있다.
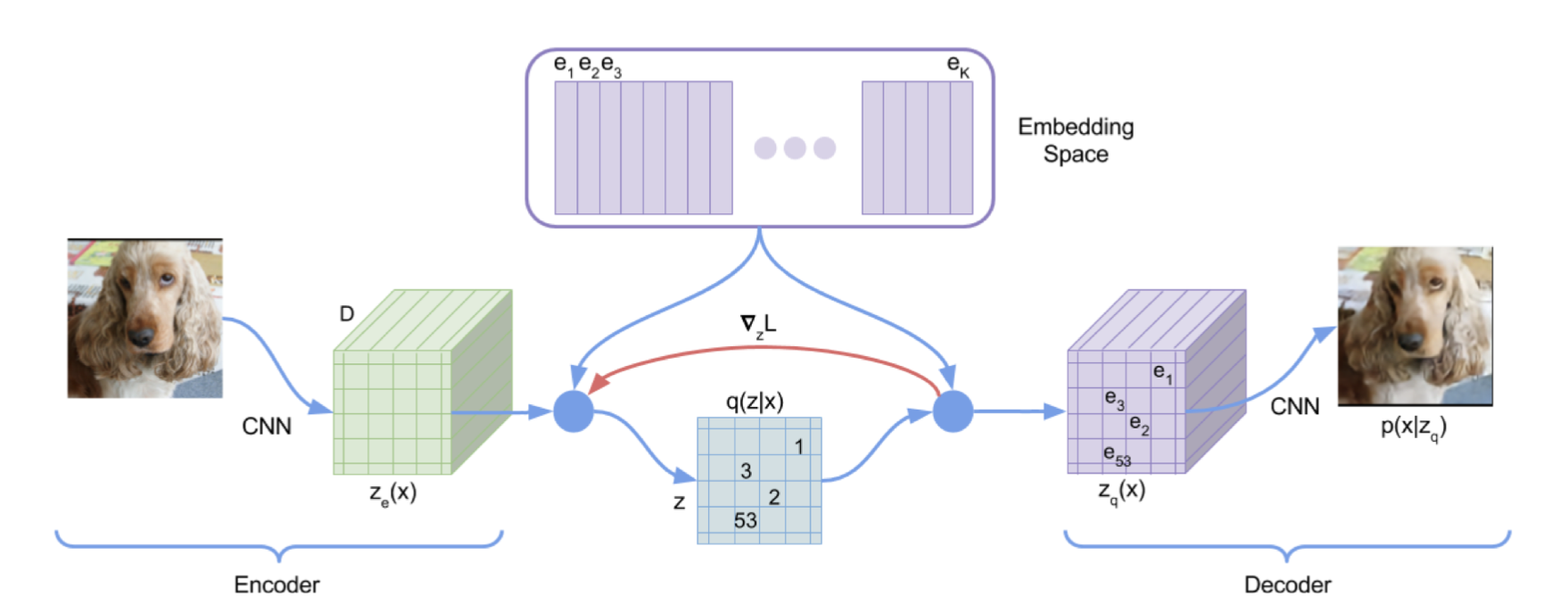
- 가운데 bottleneck part에서의 각 하나의 image fiber/image feature을 하나의 look-up embedding으로 대체한다.
- Latent space에서 각 image fiber or image feature마다 하나의 image embedding을 가지고 있다.
- 이렇게 하여 image를 sequence of codes로 discretize한다.
🔗 DALL-E Architecture
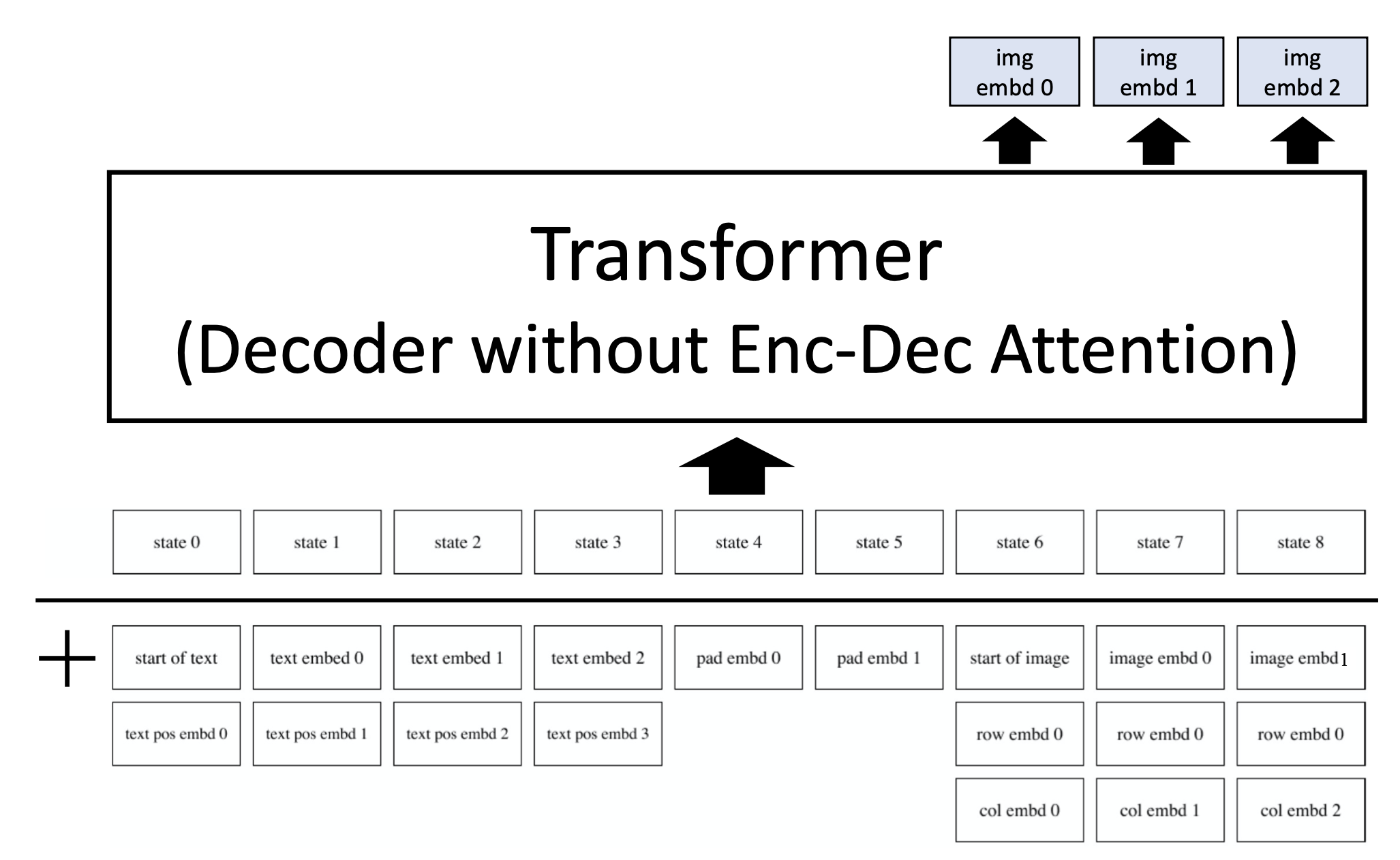
- Transformer의 절반 부분에 text token들이 들어간다.
- 그리고 text가 주어지면 한번에 하나의 image token or image unit이 generate되도록 한다.
- In a autoregressive manner
- 이렇게 하기 위해 vector quantization(guantize image into sequence of codes)가 필요하다.
- Pixel 단위로 generate하지 않음으로써 엄청 많은 for-loop을 돌지 않아도 되고, unscalable하고 intractable하다는 문제를 해결할 수 있다.
- Pixel 단위로 generate 하는 예 : PixelCNN
CLIP
-
Learning Transferable Visual Models From Natural Language Supervision
- Radford, Kim et al. 2021 (OpenAI)
-
Contrastive learning between text and image
- 많은 양의 text-image pairs 데이터를 모으고, text encoder와 image encoder를 이용하여 contrastive learning을 한다.
-
Purely zero shot인데 great zero-shot performance를 보인다. - Understands the relationship between text and image very well
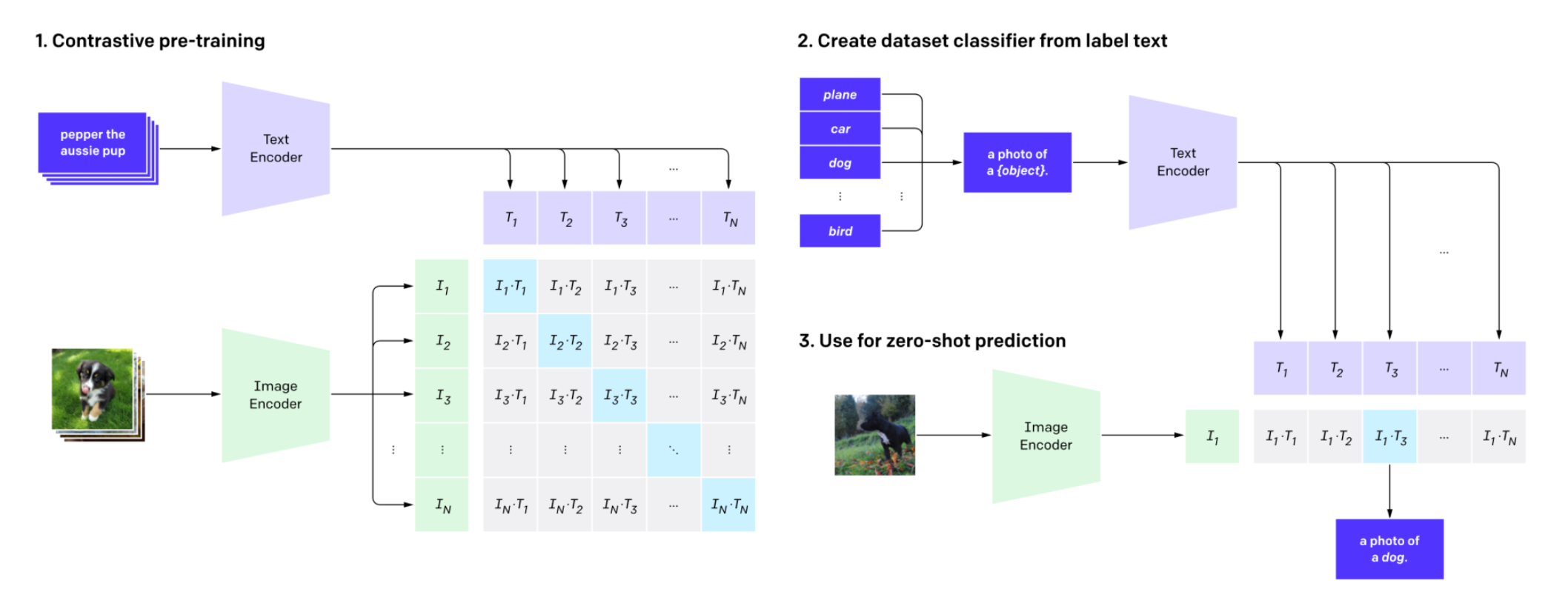
🔗 Contrastive Learning
- Batch size가 N이면, N개의 text embedding과 image embedding이 있다.
- 여기서 diagonal line에 있는 image-text pair들의 cosine similarity가 높기를 바라고, 그 외의 부분에 있는 pair들의 cosine similarity는 낮기를 바란다.
- 이렇게를 엄청 많은 데이터로 train하게 되면, text encoder와 image encoder가 text와 image들을 같은 shared latent space에 보내게 된다. 그리고 이 latent space는 text와 image 사이의 relationship에 대해 매우 잘 알고 있다.
- 예를 들어 text "dog"와 dog image는 latent space에서 서로 근처에 있을 것이다. 왜냐하면 이 latent space는 shared dimensional space이기 때문이다.
🔗 Use for zero-shot prediction
주어진 image와 potential answers간의 cosine similarity를 계싼하여 가장 높은 cosin similarity를 가지는 potential answer를 선택한다.
DALL-E 2
- Hierarchical Text-Conditional Image Generation with CLIP Latents
- Ramesh et al. 2022 (OpenAI)
💡 Core Idea
-
Text-to-image generation using CLIP priors and classifier-free guided diffusion
- DALL-E 1과 공통된 것은 없다. CLIP을 사용하였고, vector quantization은 아예 사용하지 않았다.
- Pretrained CLIP을 사용하였다.
-
Two-step upsampling (also diffusion)
🔗 DALL-E 2 동작 방식
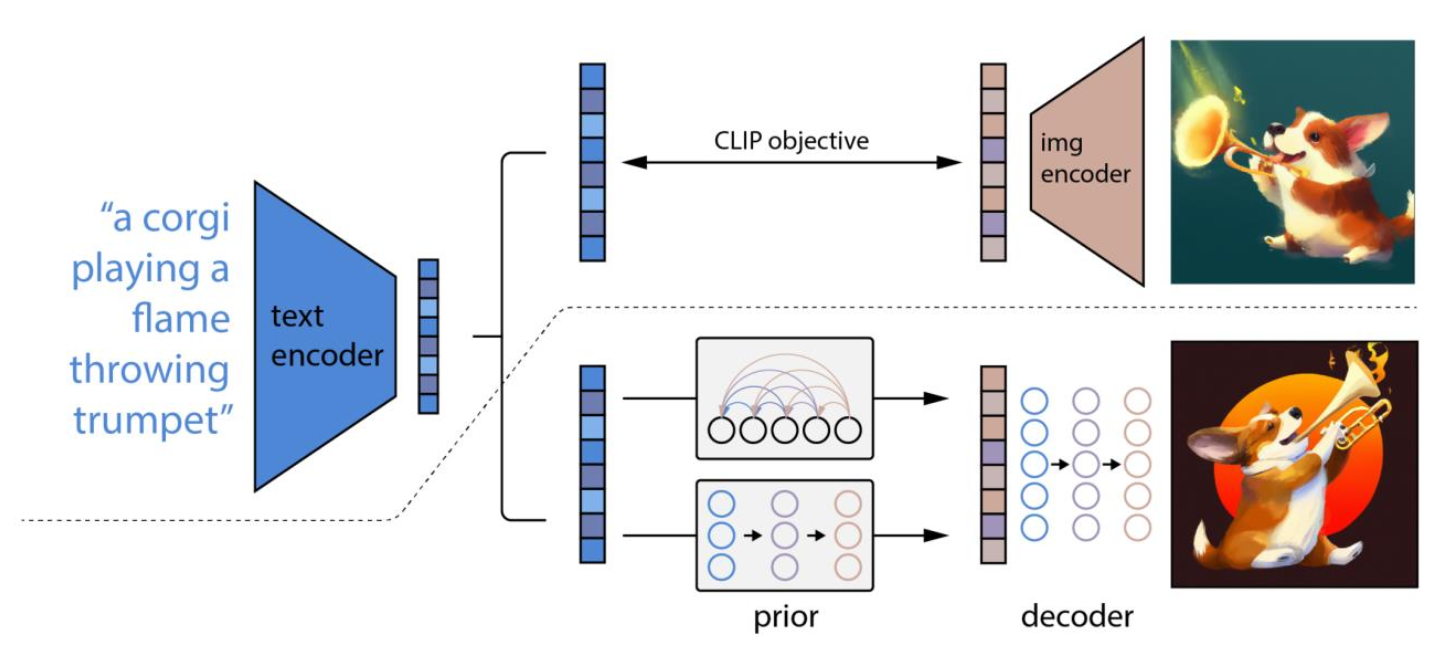
① Text input이 주어진다.
② CLIP text encoder에 넣어 CLIP text embedding을 얻는다.
③ Diffusion model을 이용해서, shared latent space에서 주어진 CLIP text embedding을 condition으로 하여 CLIP image embedding을 generate한다.
-
여기서 두 개의 route가 있다.
- Autoregressively generate 1-dimension of your CLIP image embedding at a time.
- Use diffusion to generate CLIP image embedding
두 개다 잘 작동하긴 하는데 diffusion prior model이 조금 더 좋은 성능을 보였기 때문에 diffusion prior model로 갔다.
④ 이 CLIP image embedding을 동시에 CLIP text embedding과 함께 diffusion model에 넣어 classifier-free guidance 방식으로 최종 image를 generate한다.
Diffusion은 내가 알고 있는(보통 N(0,1)) noise에서 sample을 뽑아 내가 원하는 distribution으로 보내는 일을 하는 것이다.
마찬가지로 CLIP text embedding하고 가장 상응하는 CLIP image embedding이 이 shared latent space z의 어디에 있는지를 diffusion으로 생성한다.
생성한 CLIP image embedding을 갖다가 다른 diffusion에 넣으면 매우 high quality image가 나왔다는 것이다.
즉, CLIP-space에서 한번 diffusion을 하고, 거기서 뽑은 CLIP image embedding으로 다시 실제 image로 diffusion한다. 2번에 걸쳐서 diffusion을 하기 때문에 이름에 hierarchical이 붙는 것이다.
⑤ Two-step upsampling (also diffusion)
- Diffusion은 64*64*3 image를 생성한다. 그래서 256*256으로 super sample하고, 다시 또 1024*1024로 supersample하였다.
- 즉, upsampling diffusion 2개가 사용되었다.
➡️ 총 4개의 diffusion model(initial diffusion, prior diffusion, upsampling diffusion 2개)이 사용되었다.
🔗 성능
- DALL-E 1보다 성능이 훨씬 앞서 있다.

Image-Text Multi-modal Pre-training
- 2019년부터 매우 활발한 연구 분야
- VideoBERT, ViLBERT, InterBERT, LXMERT, UNITER, Unified VLP, PixelBERT, CoCa, Flamingo, BEiT v3
🔗 Objective
- Images와 text간의 relationship을 이해하기 위해 model을 pre-train한다.
- CLIP도 완전 같은 objective를 가지고 있다.
- CLIP과 이 model들이 다른 점은 CLIP은 fusion process가 없고, 이 model들은 Early Fusions라는 것이다.
- 이 model들 중에는 image와 text를 둘 다 동시에 받도록 encoder를 통합한 model들이 있다.
- CLIP은 seperate image encoder와 text encoder를 가지고 있다.
Common Strategy
-
Extract image features from the image
세 가지 방법이 있다.
- Pre-trained object detectors (e.g. Fast R-CNN, Mask R-CNN)
- Extract object embedding
- Directly feed pixel feature maps
- Use VQVAE to quantize images into code
- Pre-trained object detectors (e.g. Fast R-CNN, Mask R-CNN)
-
Feed image features and text to BERT
- BERT가 아니더라도 주로 Transformer model이다.
-
Optimize for some pre-training objective
- Masked language modeling
- Masked image predicting
- Image-text alignment
- 등등
Models
-
ViLBERT
- ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
- Lu et al, NeurIPS 2019
- Object detection model에서 추출한 image features와 그 이미지의 text discription을 single BERT model에 함께 넣는다.
- Masked image modeling
- predict object detection class labels
- Masked language modeling
- Image-Text alignment prediction
- 주어진 pair가 matching pair인지 예측한다.
- like next-sentence prediction
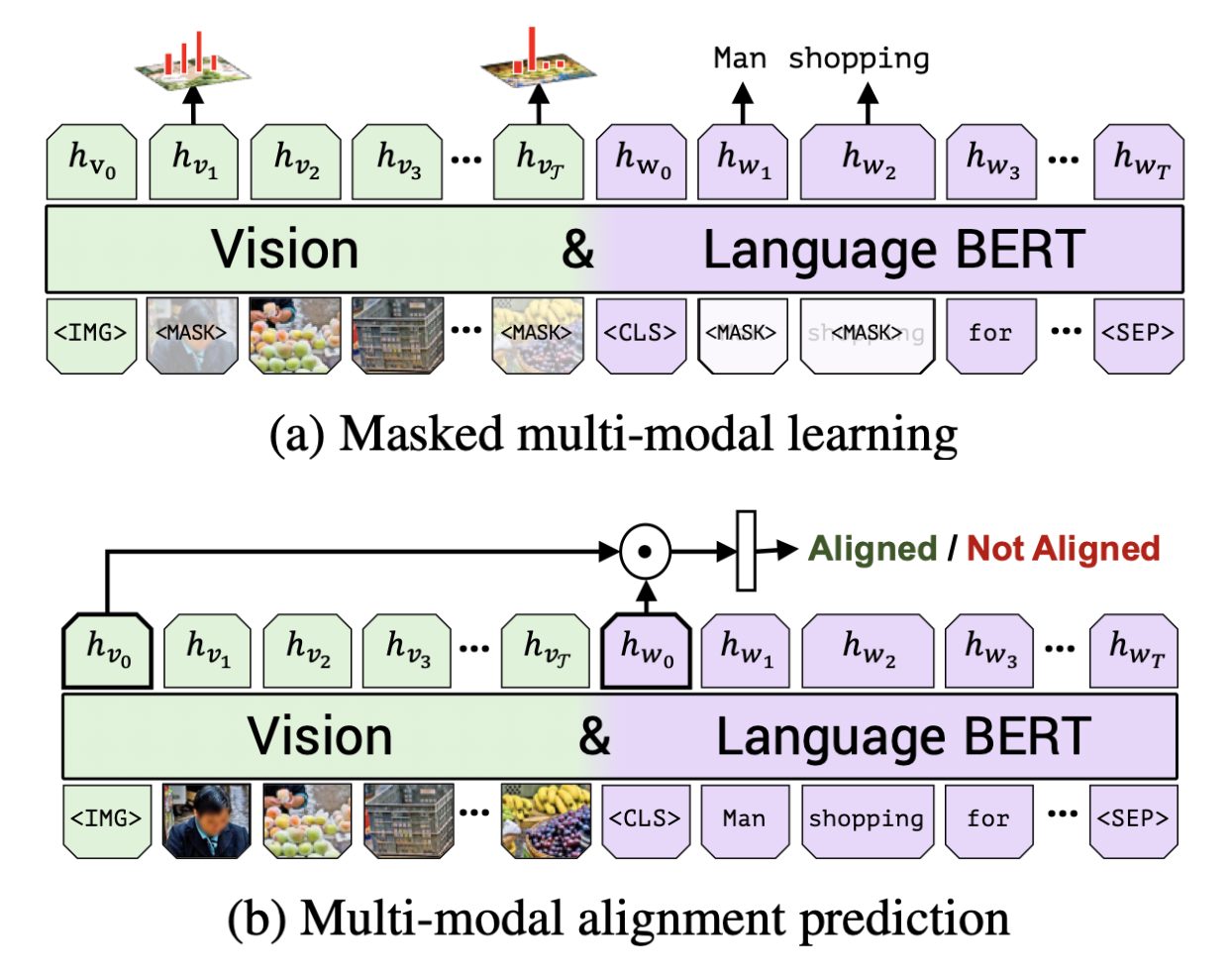
- ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
-
LXMERT
-
VL-BERT
-
UNITER
-
Pixel-BERT
- Pixel-BERT: Aligning Image Pixels with Text by Deep Multi-Modal Transformers
- Simple architecture (only CNN + Transformer, NO Object detector)
이거는 전 BERT-based model들과 다르다. 처음으로 object detection model을 사용하지 않은 model이다. ResNet으로부터 얻은 image features를 직접 BERT에 넣었고, object detection model 없이도 성능이 좋다는 것을 보여주었다.
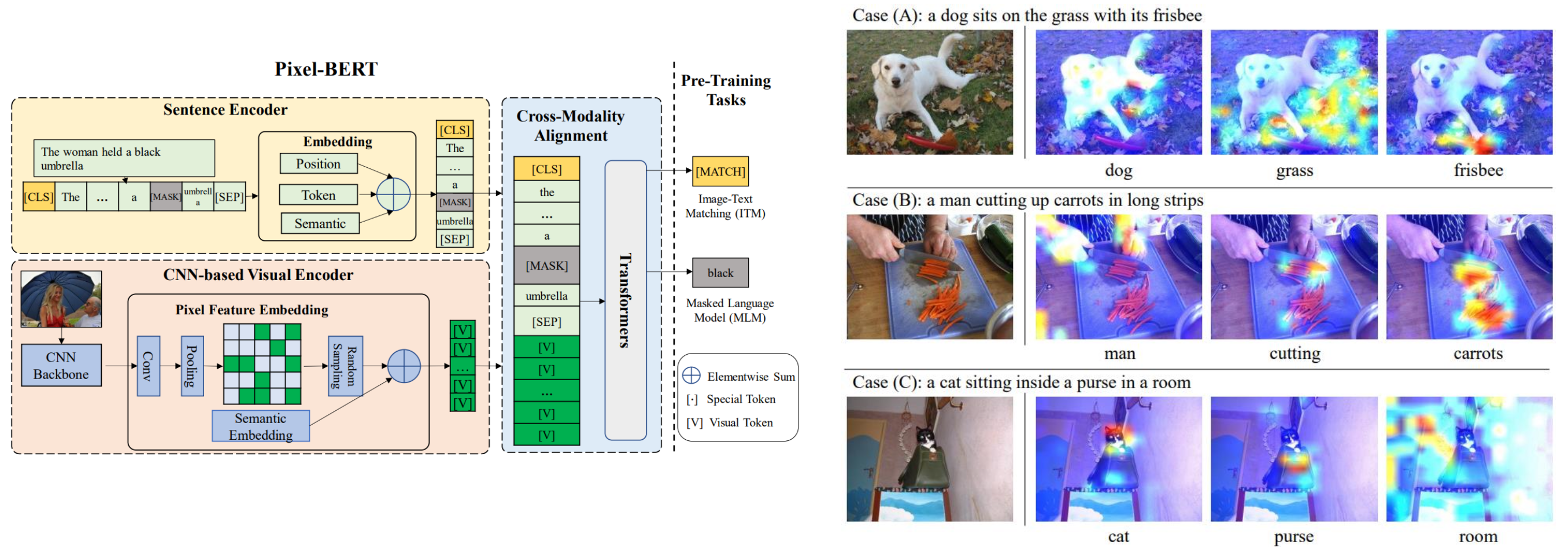
-
CoCa
- CoCa: Contrastive Captioners are Image-Text Foundation Models
- Contrastive loss + captioning loss
- 오직 이 두개 loss만 사용한다. Mask language modeling이나 다른 것들을 하지 않는다.
- Special model for captioning only
- 매우 휼륭한 captioning quality를 가진다.
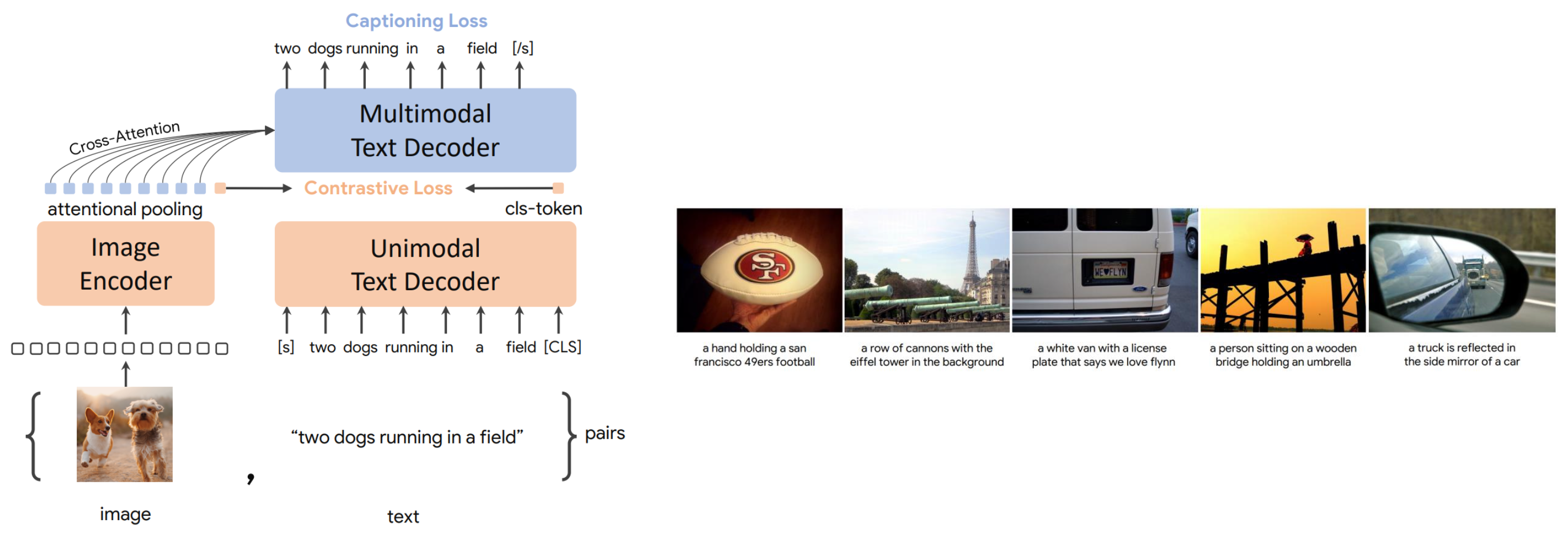
-
Flamingo
- Flamingo: a Visual Language Model for Few-Shot Learning
- Inter-leaved text-image sequences for prompt-based few-shot tasks/inference
- GPT-3와 비슷하다.
- 매우 거대한 vision encoder(ex. ViT)와 매우 거대한 language model을 사용한다. 그리고 image와 text를 sequence에다 interleave한다.
- Image 2개가 있으면 한 image에 대해서는 그것과 쌍을 이루는 text를 넣고, 다른 image에 대해서는 incomplete text를 넣는다. 그리고 모델이 이 incomplete part를 predict/fill하기를 바란다.
- 이런 task를 여러 다른 종류의 combination으로 매우 오랜시간을 매우 거대한 model로 진행하면, 오른쪽과 같은 것들을 할 수 있게 된다.
굉장히 강력한 LM과 Image Encoder들이 있는데, 이것을 잘 combine하고, 많은 양의 data로 오랜 시간 학습을 진행하면 이런 식의 few-shot task들을 할 수 있다. Generalize capability가 굉장히 높다.

Reference
- AI504: Programming for AI Lecture at KAIST AI
