Reference : Tutorial for Img2Text
0. Preliminary
In this practice, we'll cover
- Preprocessing image captioning data
- Implement show, attend and tell
- Train & Evaluate
- Generate captions & Visualize attentions with beam search
0-1. Download dataset
import gdown
gdown.download(
f"https://drive.google.com/uc?export=download&confirm=pbef&id=1uSsg5JSHGivwRCz5-3pfp7q5J-ph4mpB", "/content/practice_week12.zip"
)
!unzip practice_week12.zip0-2. Dataset description
We will use Flickr8k for training and subset of MS COCO for evaluation.
Flickr8k is a labeled dataset consisting of 8000 photos with 5 captions for each photos. It includes images obtained from the Flickr website.
MS COCO is a large-scale object detection, segmentation, and captioning dataset. It also contains photos with 5 captions for each photo, but the size of the dataset is much larger than Flickr8k (~13GB).
Below is the example from MS COCO dataset. You can also explore MS COCO here
Image:

Captions:
- the orange cat looks at a television set in a chair.
- a cat on a wood floor watching a tv sitting on a chair.
- a cat is sitting on the floor and watching television.
- a fat cat in the living room watching the tv
- a cat on the floor watching a tv on a chair.
1. Preprocess image captioning data
1-1. Preprocess dataset and cache them into local disk
Creates input files for training, validation, and test data.
For image, we're using a pretrained Encoder, we would need to process the images into the form this pretrained Encoder is accustomed to.
The pixel values must be in the range [0,1] and we must then normalize the image by the mean and standard deviation of the ImageNet images' RGB channels.
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]We will resize all images to 256x256 for uniformity.
For text, we'll tokenize sentences and add special tokens.
before: a man holds a football
after : <start> a man holds a football <end> <pad> <pad> <pad>....import os
import numpy as np
import h5py
import json
import torch
from skimage.io import imread
from skimage.transform import resize
from tqdm import tqdm
from collections import Counter
from random import seed, choice, sample
def create_input_files(dataset='flickr8k',
db_configure_path='practice_week12/caption_datasets/dataset_flickr8k.json',
image_folder='practice_week12/Flicker8k_Dataset',
captions_per_image=5,
min_word_freq=5,
output_folder='cache_features',
max_len=50):
assert dataset in {'coco', 'flickr8k', 'flickr30k'}
# Read DB configuration file
with open(db_configure_path, 'r') as j:
data = json.load(j)
# Read image paths and captions for each image
train_image_paths = []
train_image_captions = []
val_image_paths = []
val_image_captions = []
test_image_paths = []
test_image_captions = []
word_freq = Counter()
for img in data['images']:
captions = []
for c in img['sentences']:
# Update word frequency
word_freq.update(c['tokens'])
if len(c['tokens']) <= max_len:
captions.append(c['tokens'])
if len(captions) == 0:
continue
path = os.path.join(image_folder, img['filepath'], img['filename']) if dataset == 'coco' else os.path.join(
image_folder, img['filename'])
if img['split'] in {'train', 'restval'}:
train_image_paths.append(path)
train_image_captions.append(captions)
elif img['split'] in {'val'}:
val_image_paths.append(path)
val_image_captions.append(captions)
elif img['split'] in {'test'}:
test_image_paths.append(path)
test_image_captions.append(captions)
# Sanity check
assert len(train_image_paths) == len(train_image_captions)
assert len(val_image_paths) == len(val_image_captions)
assert len(test_image_paths) == len(test_image_captions)
# Create vocab
words = [w for w in word_freq.keys() if word_freq[w] > min_word_freq]
vocab = {k: v + 1 for v, k in enumerate(words)}
vocab['<unk>'] = len(vocab) + 1
vocab['<start>'] = len(vocab) + 1
vocab['<end>'] = len(vocab) + 1
vocab['<pad>'] = 0
# Create a base/root name for all output files
base_filename = dataset + '_' + str(captions_per_image) + '_cap_per_img_' + str(min_word_freq) + '_min_word_freq'
if not os.path.isdir(output_folder):
os.mkdir(output_folder)
# Save word map to a JSON
with open(os.path.join(output_folder, 'WORDMAP_' + base_filename + '.json'), 'w') as j:
json.dump(vocab, j)
# Sample captions for each image, save images to HDF5 file, and captions and their lengths to JSON files
seed(123)
for impaths, imcaps, split in [(train_image_paths, train_image_captions, 'TRAIN'),
(val_image_paths, val_image_captions, 'VAL'),
(test_image_paths, test_image_captions, 'TEST')]:
with h5py.File(os.path.join(output_folder, split + '_IMAGES_' + base_filename + '.hdf5'), 'a') as h:
# Make a note of the number of captions we are sampling per image
h.attrs['captions_per_image'] = captions_per_image
# Create dataset inside HDF5 file to store images
images = h.create_dataset('images', (len(impaths), 3, 256, 256), dtype='uint8')
print("\nReading %s images and captions, storing to file...\n" % split)
enc_captions = []
caplens = []
for i, path in enumerate(tqdm(impaths)):
# Sample captions
if len(imcaps[i]) < captions_per_image:
captions = imcaps[i] + [choice(imcaps[i]) for _ in range(captions_per_image - len(imcaps[i]))]
else:
captions = sample(imcaps[i], k=captions_per_image)
# Sanity check
assert len(captions) == captions_per_image
#print(impaths[i])
# Read images
# code for processing gray-scale image
img = imread(impaths[i])
if len(img.shape) == 2:
img = img[:, :, np.newaxis]
img = np.concatenate([img, img, img], axis=2)
img = resize(img, (256, 256))
img = img.transpose(2, 0, 1)
assert img.shape == (3, 256, 256)
assert np.max(img) <= 255
# Save image to HDF5 file
images[i] = img
for j, c in enumerate(captions):
# Encode captions
enc_c = [vocab['<start>']] + [vocab.get(word, vocab['<unk>']) for word in c] + [
vocab['<end>']] + [vocab['<pad>']] * (max_len - len(c))
# Find caption lengths
c_len = len(c) + 2
enc_captions.append(enc_c)
caplens.append(c_len)
# Sanity check
assert images.shape[0] * captions_per_image == len(enc_captions) == len(caplens)
# Save encoded captions and their lengths to JSON files
with open(os.path.join(output_folder, split + '_CAPTIONS_' + base_filename + '.json'), 'w') as j:
json.dump(enc_captions, j)
with open(os.path.join(output_folder, split + '_CAPLENS_' + base_filename + '.json'), 'w') as j:
json.dump(caplens, j)
create_input_files()2. Define pytorch dataset class
import torch
from torch.utils.data import Dataset
import h5py
import json
import os
class CaptionDataset(Dataset):
def __init__(self, data_folder, data_name, split, transform=None):
self.split = split
assert self.split in {'TRAIN', 'VAL', 'TEST'}
# Open hdf5 file where images are stored
self.h = h5py.File(os.path.join(data_folder, self.split + '_IMAGES_' + data_name + '.hdf5'), 'r')
self.imgs = self.h['images']
# Captions per image
self.cpi = self.h.attrs['captions_per_image']
# Load encoded captions (completely into memory)
with open(os.path.join(data_folder, self.split + '_CAPTIONS_' + data_name + '.json'), 'r') as j:
self.captions = json.load(j)
# Load caption lengths (completely into memory)
with open(os.path.join(data_folder, self.split + '_CAPLENS_' + data_name + '.json'), 'r') as j:
self.caplens = json.load(j)
# PyTorch transformation pipeline for the image (normalizing, etc.)
self.transform = transform
# Total number of datapoints
self.dataset_size = len(self.captions)
def __getitem__(self, i):
# Remember, the Nth caption corresponds to the (N // captions_per_image)th image
img = torch.FloatTensor(self.imgs[i // self.cpi] / 255.)
if self.transform is not None:
img = self.transform(img)
caption = torch.LongTensor(self.captions[i])
caplen = torch.LongTensor([self.caplens[i]])
if self.split is 'TRAIN':
return img, caption, caplen
else:
# For validation of testing, also return all 'captions_per_image' captions to find BLEU-4 score
all_captions = torch.LongTensor(
self.captions[((i // self.cpi) * self.cpi):(((i // self.cpi) * self.cpi) + self.cpi)])
return img, caption, caplen, all_captions
def __len__(self):
return self.dataset_size2. Implement Show, Attend and Tell
2-1. Image encoder
The Encoder encodes the input image with 3 color channels into a smaller image with "learned" channels.

This smaller encoded image is a summary representation of all that's useful in the original image.
Due to the VRAM limitation of colab, we'll use ResNet-101 instead of VGG16.
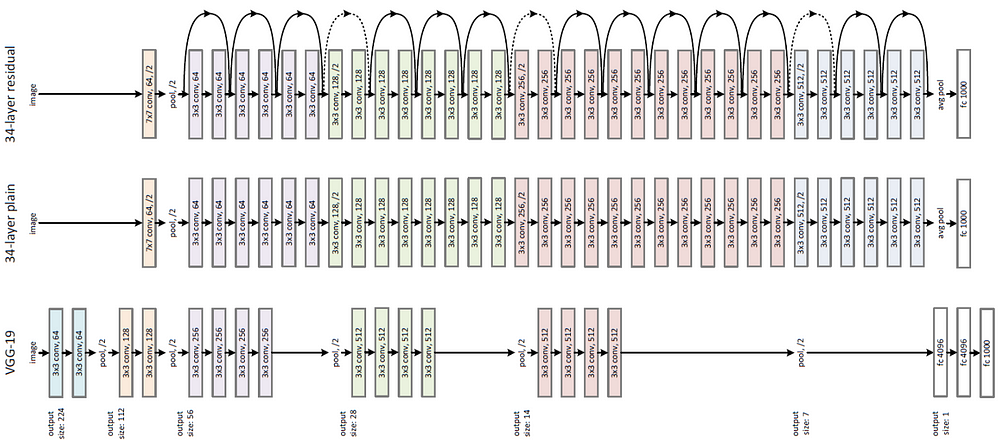
Since the last layer or two of this model are linear layers coupled with softmax activation for classification, we strip them away.
import torch
from torch import nn
import torchvision
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class Encoder(nn.Module):
def __init__(self, encoded_image_size=14):
super(Encoder, self).__init__()
self.enc_image_size = encoded_image_size
# Load pretrained ImageNet ResNet-101
"""
Implement your own code
"""
resnet = torchvision.models.resnet101(pretrained=True, progress=False)
# Remove top-2 layers in model, FC linear and global average pooling layers
modules = list(resnet.children())[:-2] #"Implement your own code"
self.resnet = nn.Sequential(*modules)
# Resize image to fixed size to allow input images of variable size
self.adaptive_pool = nn.AdaptiveAvgPool2d((encoded_image_size, encoded_image_size))
def forward(self, images):
out = self.resnet(images) # (batch_size, 2048, image_size/32, image_size/32)
out = self.adaptive_pool(out) # (batch_size, 2048, encoded_image_size, encoded_image_size)
out = out.permute(0, 2, 3, 1) # (batch_size, encoded_image_size, encoded_image_size, 2048)
return out
def fine_tune(self, fine_tune=True):
# Freeze the encoder paramters
"""
Implement your own code
"""
for p in self.resnet.parameters():
p.requires_grad = False
# If fine-tuning, only fine-tune high level feature encoder
for c in list(self.resnet.children())[5:]:
"""
Implement your own code
"""
for p in c.parameters():
p.requires_grad = fine_tune2-2. Attention network
The Attention network estimate the importance of a certain part of an image.
It considers the sequence generated thus far, and attends to the part of the image that needs describing next.

We will use a soft attention, where the weights of the pixels add up to 1. If there are P pixels in our encoded image, then at each timestep t –
This entire process as computing the probability that a pixel is the place to look to generate the next word.
We'll not going to implement a hard attention in this practice.
class Attention(nn.Module):
"""
Attention Network.
"""
def __init__(self, encoder_dim, decoder_dim, attention_dim):
"""
:param encoder_dim: feature size of encoded images
:param decoder_dim: size of decoder's RNN
:param attention_dim: size of the attention network
"""
super(Attention, self).__init__()
self.encoder_map = nn.Linear(encoder_dim, attention_dim) # linear layer to transform encoded image
self.decoder_map = nn.Linear(decoder_dim, attention_dim) # linear layer to transform decoder's output
self.full_att = nn.Linear(attention_dim, 1) # linear layer to calculate values to be softmax-ed
self.relu = nn.ReLU()
self.softmax = nn.Softmax(dim=1) # softmax layer to calculate weights
def forward(self, encoder_out, decoder_hidden):
"""
Forward propagation.
:param encoder_out: encoded images, a tensor of dimension (batch_size, num_pixels, encoder_dim)
:param decoder_hidden: previous decoder output, a tensor of dimension (batch_size, decoder_dim)
:return: attention weighted encoding, weights
"""
enc_feat = self.encoder_map(encoder_out) # (batch_size, num_pixels, attention_dim)
dec_feat = self.decoder_map(decoder_hidden) # (batch_size, attention_dim)
att = self.full_att(self.relu(enc_feat + dec_feat.unsqueeze(1))).squeeze(2) # (batch_size, num_pixels)
alpha = self.softmax(att) # (batch_size, num_pixels)
attention_weighted_encoding = (encoder_out * alpha.unsqueeze(2)).sum(dim=1) # (batch_size, encoder_dim)
return attention_weighted_encoding, alpha
2-3. Text decoder with attention network
The Decoder's job is to look at the encoded image and generate a caption word by word.
Since it's generating a sequence, so we will use Recurrent Neural Network, especially LSTM.
In a setting with Attention, we want the Decoder to be able to look at different parts of the image at different points in the sequence.

Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word.
One technique to speeding-up RNN is ignoring padding tokens during the recurrence. PyTorch also supports this, pack_padded_sequence
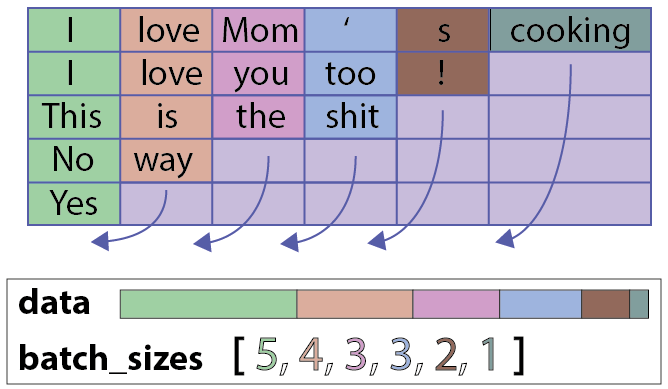
We will manually implement pack_padded_sequence and text decoder with attention in this section.
class DecoderWithAttention(nn.Module):
"""
Decoder.
"""
def __init__(self, attention_dim, embed_dim, decoder_dim, vocab_size, encoder_dim=2048, dropout=0.5):
"""
:param attention_dim: size of attention network
:param embed_dim: embedding size
:param decoder_dim: size of decoder's RNN
:param vocab_size: size of vocabulary
:param encoder_dim: feature size of encoded images
:param dropout: dropout
"""
super(DecoderWithAttention, self).__init__()
self.encoder_dim = encoder_dim
self.attention_dim = attention_dim
self.embed_dim = embed_dim
self.decoder_dim = decoder_dim
self.vocab_size = vocab_size
self.dropout = dropout
self.attention = Attention(encoder_dim, decoder_dim, attention_dim) # attention network
self.embedding = nn.Embedding(vocab_size, embed_dim) # embedding layer
self.dropout = nn.Dropout(p=self.dropout)
self.decode_step = nn.LSTMCell(embed_dim + encoder_dim, decoder_dim, bias=True) # decoding LSTMCell
self.init_h = nn.Linear(encoder_dim, decoder_dim) # linear layer to find initial hidden state of LSTMCell
self.init_c = nn.Linear(encoder_dim, decoder_dim) # linear layer to find initial cell state of LSTMCell
self.f_beta = nn.Linear(decoder_dim, encoder_dim) # linear layer to create a sigmoid-activated gate
self.sigmoid = nn.Sigmoid()
self.fc = nn.Linear(decoder_dim, vocab_size) # linear layer to find scores over vocabulary
self.init_weights() # initialize some layers with the uniform distribution
def init_weights(self):
"""
Initializes some parameters with values from the uniform distribution, for easier convergence.
"""
self.embedding.weight.data.uniform_(-0.1, 0.1)
self.fc.bias.data.fill_(0)
self.fc.weight.data.uniform_(-0.1, 0.1)
def load_pretrained_embeddings(self, embeddings):
"""
Loads embedding layer with pre-trained embeddings.
:param embeddings: pre-trained embeddings
"""
self.embedding.weight = nn.Parameter(embeddings)
def fine_tune_embeddings(self, fine_tune=True):
"""
Allow fine-tuning of embedding layer? (Only makes sense to not-allow if using pre-trained embeddings).
:param fine_tune: Allow?
"""
for p in self.embedding.parameters():
p.requires_grad = fine_tune
def init_hidden_state(self, encoder_out):
"""
Creates the initial hidden and cell states for the decoder's LSTM based on the encoded images.
:param encoder_out: encoded images, a tensor of dimension (batch_size, num_pixels, encoder_dim)
:return: hidden state, cell state
"""
mean_encoder_out = encoder_out.mean(dim=1)
h = self.init_h(mean_encoder_out) # (batch_size, decoder_dim)
c = self.init_c(mean_encoder_out)
return h, c
def forward(self, encoder_out, encoded_captions, caption_lengths):
"""
Forward propagation.
:param encoder_out: encoded images, a tensor of dimension (batch_size, enc_image_size, enc_image_size, encoder_dim)
:param encoded_captions: encoded captions, a tensor of dimension (batch_size, max_caption_length)
:param caption_lengths: caption lengths, a tensor of dimension (batch_size, 1)
:return: scores for vocabulary, sorted encoded captions, decode lengths, weights, sort indices
"""
batch_size = encoder_out.size(0)
encoder_dim = encoder_out.size(-1)
vocab_size = self.vocab_size
# Flatten image
encoder_out = encoder_out.view(batch_size, -1, encoder_dim) # (batch_size, num_pixels, encoder_dim)
num_pixels = encoder_out.size(1)
# Sort input data by decreasing lengths; why? apparent below
caption_lengths, sort_ind = caption_lengths.squeeze(1).sort(dim=0, descending=True)
encoder_out = encoder_out[sort_ind]
encoded_captions = encoded_captions[sort_ind]
# Since we decoded starting with <start>, the targets are all words after <start>, up to <end>
targets = encoded_captions[:,1:]
# Embedding
embeddings = self.embedding(encoded_captions) # (batch_size, max_caption_length, embed_dim)
# Initialize LSTM state
h, c = self.init_hidden_state(encoder_out) # (batch_size, decoder_dim)
# We won't decode at the <end> position, since we've finished generating as soon as we generate <end>
# So, decoding lengths are actual lengths - 1
decode_lengths = (caption_lengths - 1).tolist()
# Create tensors to hold word predicion scores and alphas
predictions = torch.zeros(batch_size, targets.size(1), vocab_size).to(device)
alphas = torch.zeros(batch_size, targets.size(1), num_pixels).to(device)
# At each time-step, decode by
# attention-weighing the encoder's output based on the decoder's previous hidden state output
# then generate a new word in the decoder with the previous word and the attention weighted encoding
for t in range(max(decode_lengths)):
batch_size_t = sum([l > t for l in decode_lengths])
attention_weighted_encoding, alpha = self.attention(encoder_out[:batch_size_t],
h[:batch_size_t])
gate = self.sigmoid(self.f_beta(h[:batch_size_t])) # gating scalar, (batch_size_t, encoder_dim)
attention_weighted_encoding = gate * attention_weighted_encoding
h, c = self.decode_step(
torch.cat([embeddings[:batch_size_t, t, :], attention_weighted_encoding], dim=1),
(h[:batch_size_t], c[:batch_size_t])) # (batch_size_t, decoder_dim)
preds = self.fc(self.dropout(h)) # (batch_size_t, vocab_size)
predictions[:batch_size_t, t, :] = preds
alphas[:batch_size_t, t, :] = alpha
return predictions, targets, decode_lengths, alphas, sort_ind3. Train and Evaluate your model
In this section, we'll train the model and evaluate it's performance with BLEU-4 score.
3.1 Set hyperparameters
Load python libraries and set some hyperparameters.
Here, we will use nltk library to calculate BLEU score.
!pip install torchreidimport time
import torch.backends.cudnn as cudnn
import torch.optim
import torch.utils.data
import torchvision.transforms as transforms
from torch import nn
from torch.nn.utils.rnn import pack_padded_sequence
from nltk.translate.bleu_score import corpus_bleu
from tqdm import tqdm
from torchreid import utils
# Data parameters
data_folder = 'cache_features' # folder with data files saved by create_input_files.py
data_name = 'flickr8k_5_cap_per_img_5_min_word_freq' # base name shared by data files
# Model parameters
emb_dim = 512 # dimension of word embeddings
attention_dim = 512 # dimension of attention linear layers
decoder_dim = 512 # dimension of decoder RNN
dropout = 0.5
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # sets device for model and PyTorch tensors
cudnn.benchmark = True # set to true only if inputs to model are fixed size; otherwise lot of computational overhead
# Training parameters
start_epoch = 0
epochs = 120 # number of epochs to train for (if early stopping is not triggered)
epochs_since_improvement = 0 # keeps track of number of epochs since there's been an improvement in validation BLEU
batch_size = 32
workers = 1 # for data-loading; right now, only 1 works with h5py
encoder_lr = 1e-4 # learning rate for encoder if fine-tuning
decoder_lr = 4e-4 # learning rate for decoder
grad_clip = 5. # clip gradients at an absolute value of
alpha_c = 1. # regularization parameter for 'doubly stochastic attention', as in the paper
best_bleu4 = 0. # BLEU-4 score right now
print_freq = 100 # print training/validation stats every __ batches
fine_tune_encoder = True # fine-tune encoder?
checkpoint = None # path to checkpoint, None if none
# utility class
class AverageMeter(object):
"""Computes and stores the average and current value."""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def clip_gradient(optimizer, grad_clip):
"""
Clips gradients computed during backpropagation to avoid explosion of gradients.
:param optimizer: optimizer with the gradients to be clipped
:param grad_clip: clip value
"""
for group in optimizer.param_groups:
for param in group['params']:
if param.grad is not None:
param.grad.data.clamp_(-grad_clip, grad_clip)
def adjust_learning_rate(optimizer, shrink_factor):
"""
Shrinks learning rate by a specified factor.
:param optimizer: opimizer whose learning rate must be shrunk.
:param shrink_factor: factor in interval (0,1) to multiply learning rate with.
"""
print("\nDECAYING learning rate.")
for param_group in optimizer.param_groups:
param_group['lr'] = param_group['lr'] * shrink_factor
print("The new learning rate is %f\n" % (optimizer.param_groups[0]['lr'],))
def accuracy(scores, targets, k):
"""
Computes top-k accuracy, from predicted and true labels.
:param scores: scores from the model
:param targets: true labels
:param k: k in top-k accuracy
:return: top-k accuracy
"""
batch_size = targets.size(0)
_, ind = scores.topk(k, 1, True, True)
correct = ind.eq(targets.view(-1,1).expand_as(ind))
correct_total = correct.view(-1).float().sum() # 0D tensor
return correct_total.item() * (100.0 / batch_size)
def save_checkpoint(data_name, epoch, epochs_since_improvement, encoder, decoder, encoder_optimizer, decoder_optimizer,
bleu4, is_best):
"""
Saves model checkpoint.
:param data_name: base name of processed dataset
:param epoch: epoch_number
:param epochs_since_improvement: number of epochs since last improvement in BLEU-4 score
:param encoder: encoder model
:param decoder: decoder model
:param encoder_optimizer: optimizer to update encoder's weights, if fine-tuning
:param decoder_optimizer: optimizer to update decoder's weights
:param bleu4: validation BLEU-4 score for this epoch
:param is_best: is this checkpoint the best so far?
"""
state = {'epoch': epoch,
'epochs_since_improvement': epochs_since_improvement,
'bleu4': bleu4,
'encoder': encoder,
'decoder': decoder,
'encoder_optimizer': encoder_optimizer,
'decoder_optimizer': decoder_optimizer}
filename = 'checkpoint_' + data_name + '.pth.tar'
torch.save(state, filename)
# If this checkpoint is the best so far, store a copy so it doesn't get overwritten by a worse checkpoint
if is_best:
torch.save(state, 'BEST_' + filename)
3.2 Train
We will implement the objective function and single training loop in paper.
The objective function is:

def train(train_loader, encoder, decoder, criterion, encoder_optimizer, decoder_optimizer, epoch):
"""
Performs one epoch's training.
:param train_loader: DataLoader for training data
:param encoder: encoder model
:param decoder: decoder model
:param criterion: loss layer
:param encoder_optimizer: optimizer to update encoder's weights (if fine-tuning)
:param decoder_optimizer: optimizer to update decoder's weights
:param epoch: epoch number
"""
decoder.train() # train mode (dropout and batchnorm is used)
encoder.train()
batch_time = AverageMeter() # forward prop. + back prop. time
data_time = AverageMeter() # data loading time
losses = AverageMeter() # loss (per word decoded)
top5accs = AverageMeter() # top5 accuracy
start = time.time()
# Batches
for i, (imgs, caps, caplens) in tqdm(enumerate(train_loader),total=len(train_loader)):
data_time.update(time.time() - start)
# Move to GPU, if available
imgs = imgs.to(device)
caps = caps.to(device)
caplens = caplens.to(device)
# Forward prop.
imgs = encoder(imgs)
scores, targets, decode_lengths, alphas, sort_ind = decoder(imgs, caps, caplens)
# Resize score and targets
scores = scores.reshape(-1,scores.size(2))
targets = targets.reshape(-1)
# Calculate loss
loss = criterion(scores, targets)
# Add doubly stochastic attention regularization
loss += alpha_c * ((1. - alphas.sum(dim=1)) ** 2).mean()
# Back prop.
decoder_optimizer.zero_grad()
if encoder_optimizer is not None:
encoder_optimizer.zero_grad()
loss.backward()
# Clip gradients
if grad_clip is not None:
clip_gradient(decoder_optimizer, grad_clip)
if encoder_optimizer is not None:
clip_gradient(encoder_optimizer, grad_clip)
# Update weights
decoder_optimizer.step()
if encoder_optimizer is not None:
encoder_optimizer.step()
# Keep track of metrics
top5 = accuracy(scores, targets, 5)
losses.update(loss.item(), sum(decode_lengths))
top5accs.update(top5, sum(decode_lengths))
batch_time.update(time.time() - start)
start = time.time()
# Print status
if i % print_freq == 0:
print('\nEpoch: [{0}][{1}/{2}]\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Top-5 Accuracy {top5.val:.3f} ({top5.avg:.3f})'.format(epoch, i, len(train_loader),
loss=losses,
top5=top5accs))3.3 Evaluation
We will evalute the trained model with BLEU-4 score.
def validate(val_loader, encoder, decoder, criterion):
"""
Performs one epoch's validation.
:param val_loader: DataLoader for validation data.
:param encoder: encoder model
:param decoder: decoder model
:param criterion: loss layer
:return: BLEU-4 score
"""
decoder.eval() # eval mode (no dropout or batchnorm)
if encoder is not None:
encoder.eval()
batch_time = AverageMeter()
losses = AverageMeter()
top5accs = AverageMeter()
start = time.time()
references = list() # references (true captions) for calculating BLEU-4 score
hypotheses = list() # hypotheses (predictions)
with torch.no_grad():
# Batches
for i, (imgs, caps, caplens, allcaps) in enumerate(val_loader):
# Move to device, if available
imgs = imgs.to(device)
caps = caps.to(device)
caplens = caplens.to(device)
# Forward prop.
if encoder is not None:
imgs = encoder(imgs)
scores, targets, decode_lengths, alphas, sort_ind = decoder(imgs, caps, caplens)
# Resize score and targets
scores_copy = scores.clone()
scores = scores.reshape(-1,scores.size(2))
targets = targets.reshape(-1)
# Calculate loss
loss = criterion(scores, targets)
# Add doubly stochastic attention regularization
loss += alpha_c * ((1. - alphas.sum(dim=1)) ** 2).mean()
# Keep track of metrics
losses.update(loss.item(), sum(decode_lengths))
top5 = accuracy(scores, targets, 5)
top5accs.update(top5, sum(decode_lengths))
batch_time.update(time.time() - start)
start = time.time()
if i % print_freq == 0:
print('Validation: [{0}/{1}]\t'
'Batch Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Top-5 Accuracy {top5.val:.3f} ({top5.avg:.3f})\t'.format(i, len(val_loader), batch_time=batch_time,
loss=losses, top5=top5accs))
# Store references (true captions), and hypothesis (prediction) for each image
# If for n images, we have n hypotheses, and references a, b, c... for each image, we need -
# references = [[ref1a, ref1b, ref1c], [ref2a, ref2b], ...], hypotheses = [hyp1, hyp2, ...]
allcaps = allcaps.to(device)
sort_ind = sort_ind.to(device)
# References
allcaps = allcaps[sort_ind] # because images were sorted in the decoder
for j in range(allcaps.shape[0]):
img_caps = allcaps[j].tolist()
img_captions = list(
map(lambda c: [w for w in c if w not in {vocab['<start>'], vocab['<pad>']}],
img_caps)) # remove <start> and pads
references.append(img_captions)
# Hypotheses
_, preds = torch.max(scores_copy, dim=2)
preds = preds.tolist()
temp_preds = list()
for j, p in enumerate(preds):
temp_preds.append(preds[j][:decode_lengths[j]]) # remove pads
preds = temp_preds
hypotheses.extend(preds)
assert len(references) == len(hypotheses)
# Calculate BLEU-4 scores
bleu4 = corpus_bleu(references, hypotheses)
print(
'\n * LOSS - {loss.avg:.3f}, TOP-5 ACCURACY - {top5.avg:.3f}, BLEU-4 - {bleu}\n'.format(
loss=losses,
top5=top5accs,
bleu=bleu4))
return bleu43.4 Run training & evaluation code
def main():
"""
Training and validation.
"""
global best_bleu4, epochs_since_improvement, checkpoint, start_epoch, fine_tune_encoder, data_name, vocab
# Read word map
vocab_file = os.path.join(data_folder, 'WORDMAP_' + data_name + '.json')
with open(vocab_file, 'r') as j:
vocab = json.load(j)
# Initialize / load checkpoint
if checkpoint is None:
decoder = DecoderWithAttention(attention_dim=attention_dim,
embed_dim=emb_dim,
decoder_dim=decoder_dim,
vocab_size=len(vocab),
dropout=dropout)
decoder_optimizer = torch.optim.RMSprop(params=filter(lambda p: p.requires_grad, decoder.parameters()),
lr=decoder_lr)
encoder = Encoder()
encoder.fine_tune(fine_tune_encoder)
encoder_optimizer = torch.optim.RMSprop(params=filter(lambda p: p.requires_grad, encoder.parameters()),
lr=encoder_lr) if fine_tune_encoder else None
else:
checkpoint = torch.load(checkpoint)
start_epoch = checkpoint['epoch'] + 1
epochs_since_improvement = checkpoint['epochs_since_improvement']
best_bleu4 = checkpoint['bleu-4']
decoder = checkpoint['decoder']
decoder_optimizer = checkpoint['decoder_optimizer']
encoder = checkpoint['encoder']
encoder_optimizer = checkpoint['encoder_optimizer']
if fine_tune_encoder is True and encoder_optimizer is None:
encoder.fine_tune(fine_tune_encoder)
encoder_optimizer = torch.optim.Adam(params=filter(lambda p: p.requires_grad, encoder.parameters()),
lr=encoder_lr)
# Move to GPU, if available
decoder = decoder.to(device)
encoder = encoder.to(device)
# Loss function
criterion = nn.CrossEntropyLoss(ignore_index=vocab['<pad>']).to(device)
# Custom dataloaders
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
train_loader = torch.utils.data.DataLoader(
CaptionDataset(data_folder, data_name, 'TRAIN', transform=transforms.Compose([normalize])),
batch_size=batch_size, shuffle=True, num_workers=workers, pin_memory=True)
val_loader = torch.utils.data.DataLoader(
CaptionDataset(data_folder, data_name, 'VAL', transform=transforms.Compose([normalize])),
batch_size=batch_size, shuffle=True, num_workers=workers, pin_memory=True)
# Epochs
for epoch in range(start_epoch, epochs):
# Decay learning rate if there is no improvement for 2 consecutive epochs, and terminate training after 5
if epochs_since_improvement == 5:
break
if epochs_since_improvement > 0 and epochs_since_improvement % 2 == 0:
adjust_learning_rate(decoder_optimizer, 0.8)
if fine_tune_encoder:
adjust_learning_rate(encoder_optimizer, 0.8)
# One epoch's training
train(train_loader=train_loader,
encoder=encoder,
decoder=decoder,
criterion=criterion,
encoder_optimizer=encoder_optimizer,
decoder_optimizer=decoder_optimizer,
epoch=epoch)
# One epoch's validation
recent_bleu4 = validate(val_loader=val_loader,
encoder=encoder,
decoder=decoder,
criterion=criterion)
# Check if there was an improvement
is_best = recent_bleu4 > best_bleu4
best_bleu4 = max(recent_bleu4, best_bleu4)
if not is_best:
epochs_since_improvement += 1
print("\nEpochs since last improvement: %d\n" % (epochs_since_improvement,))
else:
epochs_since_improvement = 0
# Save checkpoint
save_checkpoint(data_name, epoch, epochs_since_improvement, encoder, decoder, encoder_optimizer,
decoder_optimizer, recent_bleu4, is_best)
if __name__ == '__main__':
main()4. Generate captions & Visualize attentions
4.1 Generate captions with beam search
The greedy decoding choose the word with the highest score and use it to predict the next word. But this is not optimal because the rest of the sequence hinges on that first word you choose. If that choice isn't the best, everything that follows is sub-optimal. And it's not just the first word – each word in the sequence has consequences for the ones that succeed it.
It would be best if we could somehow not decide until we've finished decoding completely, and choose the sequence that has the highest overall score from a basket of candidate sequences. Beam Search does exactly this.

In this section, we will implement beam search decoding scheme.
import torch
import torch.nn.functional as F
import numpy as np
import json
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import skimage.transform
from skimage import img_as_ubyte
from skimage.io import imread
from PIL import Image
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def caption_image_beam_search(encoder, decoder, image_path, vocab, beam_size=3):
k = beam_size
vocab_size = len(vocab)
# Read image and process
img = imread(image_path)
if len(img.shape) == 2:
img = img[:, :, np.newaxis]
img = np.concatenate([img, img, img], axis=2)
img = img_as_ubyte(skimage.transform.resize(img, (256, 256)))
img = img.transpose(2, 0, 1)
img = img / 255
img = torch.FloatTensor(img).to(device)
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
transform = transforms.Compose([normalize])
image = transform(img) # (3, 256, 256)
# Encode
image = image.unsqueeze(0) # (1, 3, 256, 256)
encoder_out = encoder(image) # (1, enc_image_size, enc_image_size, encoder_dim)
enc_image_size = encoder_out.size(1)
encoder_dim = encoder_out.size(3)
# Flatten encoding
encoder_out = encoder_out.view(1, -1, encoder_dim) # (1, num_pixels, encoder_dim)
num_pixels = encoder_out.size(1)
# We'll treat the problem as having a batch size of k
encoder_out = encoder_out.expand(k, num_pixels, encoder_dim) # (k, num_pixels, encoder_dim)
# Tensor to store top k previous words at each step; now they're just <start>
k_prev_words = torch.LongTensor([[vocab['<start>']]] * k).to(device) # (k, 1)
# Tensor to store top k sequences; now they're just <start>
seqs = k_prev_words # (k, 1)
# Tensor to store top k sequences' scores; now they're just 0
top_k_scores = torch.zeros(k, 1).to(device) # (k, 1)
# Tensor to store top k sequences' alphas; now they're just 1s
seqs_alpha = torch.ones(k, 1, enc_image_size, enc_image_size).to(device) # (k, 1, enc_image_size, enc_image_size)
# Lists to store completed sequences, their alphas and scores
complete_seqs = list()
complete_seqs_alpha = list()
complete_seqs_scores = list()
# Start decoding
step = 1
h, c = decoder.init_hidden_state(encoder_out)
# s is a number less than or equal to k, because sequences are removed from this process once they hit <end>
while True:
embeddings = decoder.embedding(k_prev_words).squeeze(1) # (s, embed_dim)
awe, alpha = decoder.attention(encoder_out, h) # (s, encoder_dim), (s, num_pixels)
alpha = alpha.view(-1, enc_image_size, enc_image_size) # (s, enc_image_size, enc_image_size)
gate = decoder.sigmoid(decoder.f_beta(h)) # gating scalar, (s, encoder_dim)
awe = gate * awe
h, c = decoder.decode_step(torch.cat([embeddings, awe], dim=1), (h, c)) # (s, decoder_dim)
scores = decoder.fc(h) # (s, vocab_size)
scores = F.log_softmax(scores, dim=1)
# Add score to top-k_scores
scores = top_k_scores.expand_as(scores) + scores # (s, vocab_size)
# For the first step, all k points will have the same scores (since same k previous words, h, c)
if step == 1:
top_k_scores, top_k_words = scores[0].topk(k, 0, True, True) # (s)
else:
# Unroll and find top scores, and their unrolled indices
top_k_scores, top_k_words = scores.view(-1).topk(k, 0, True, True) # (s)
# Convert unrolled indices to actual indices of scores
prev_word_inds = (top_k_words / vocab_size).long() # (s)
next_word_inds = top_k_words % vocab_size # (s)
# Add new words to sequences, alphas
seqs = torch.cat([seqs[prev_word_inds], next_word_inds.unsqueeze(1)], dim=1) # (s, step+1)
seqs_alpha = torch.cat([seqs_alpha[prev_word_inds], alpha[prev_word_inds].unsqueeze(1)],
dim=1) # (s, step+1, enc_image_size, enc_image_size)
# Which sequences are incomplete (didn't reach <end>)?
incomplete_inds = [ind for ind, next_word in enumerate(next_word_inds) if
next_word != vocab['<end>']]
complete_inds = list(set(range(len(next_word_inds))) - set(incomplete_inds))
# Set aside complete sequences
if len(complete_inds) > 0:
complete_seqs.extend(seqs[complete_inds].tolist())
complete_seqs_alpha.extend(seqs_alpha[complete_inds].tolist())
complete_seqs_scores.extend(top_k_scores[complete_inds])
k -= len(complete_inds) # reduce beam length accordingly
# Proceed with incomplete sequences
if k == 0:
break
seqs = seqs[incomplete_inds]
seqs_alpha = seqs_alpha[incomplete_inds]
h = h[prev_word_inds[incomplete_inds]]
c = c[prev_word_inds[incomplete_inds]]
encoder_out = encoder_out[prev_word_inds[incomplete_inds]]
top_k_scores = top_k_scores[incomplete_inds].unsqueeze(1)
k_prev_words = next_word_inds[incomplete_inds].unsqueeze(1)
# Break if things have been going on too long
if step > 50:
break
step += 1
i = complete_seqs_scores.index(max(complete_seqs_scores))
seq = complete_seqs[i]
alphas = complete_seqs_alpha[i]
return seq, alphas4.2 Visualize attention
Instead of investigating the "true impact" of attention score on each input images, we'll use some trick to visualize attentions on the input image.
- Resize image to 14*N X 14*N scale
- Expand our 14 X 14 attention score matrix to 14*N X 14*N like below. Expanded attentions matrix are acting like a regional mask on the input image.

- Plot image and attention mask in a single image.
def visualize_att(image_path, seq, alphas, rev_vocab, smooth=True):
"""
Visualizes caption with weights at every word.
Adapted from paper authors' repo: https://github.com/kelvinxu/arctic-captions/blob/master/alpha_visualization.ipynb
:param image_path: path to image that has been captioned
:param seq: caption
:param alphas: weights
:param rev_vocab: reverse word mapping, i.e. ix2word
:param smooth: smooth weights?
"""
image = Image.open(image_path)
image = image.resize([14 * 24, 14 * 24], Image.LANCZOS)
words = [rev_vocab[ind] for ind in seq]
for t in range(len(words)):
if t > 50:
break
plt.subplot(np.ceil(len(words) / 5.), 5, t + 1)
plt.text(0, 1, '%s' % (words[t]), color='black', backgroundcolor='white', fontsize=12)
plt.imshow(image)
current_alpha = alphas[t, :]
if smooth:
alpha = skimage.transform.pyramid_expand(current_alpha.numpy(), upscale=24, sigma=8)
else:
alpha = skimage.transform.resize(current_alpha.numpy(), [14 * 24, 14 * 24])
if t == 0:
plt.imshow(alpha, alpha=0)
else:
plt.imshow(alpha, alpha=0.8)
plt.set_cmap(cm.Greys_r)
plt.axis('off')
plt.show()4.3 Let's check our model really working well!
If you want to check other examples, please change
# IMG_PATH = 'COCO-toy/<image_name>'List of images:
- baseball.jpg
- baseball2.jpg
- bathroom.jpg
- bear.jpg
- birds.jpg
- city.jpg
- dog.jpg
- giraffe.jpg
- laptop.jpg
- man.jpg
- man2.jpg
- manandwoman.jpg
- meal.jpg
- motorcycle.jpg
- people.jpg
- pizza.jpg
- room.jpg
- snowboard.jpg
- wine.jpg
# Change this
IMG_PATH = 'COCO-toy/dog.jpg'
MODEL = 'BEST_checkpoint_coco_5_cap_per_img_5_min_word_freq.pth.tar'
vocab = 'WORDMAP_coco_5_cap_per_img_5_min_word_freq.json'
BEAM_SIZE=3
# Load model
checkpoint = torch.load(MODEL, map_location=str(device))
decoder = checkpoint['decoder']
decoder = decoder.to(device)
decoder.eval()
encoder = checkpoint['encoder']
encoder = encoder.to(device)
encoder.eval()
# Load word map (word2ix)
with open(vocab, 'r') as j:
vocab = json.load(j)
rev_vocab = {v: k for k, v in vocab.items()} # ix2word
# Encode, decode with attention and beam search
seq, alphas = caption_image_beam_search(encoder, decoder, IMG_PATH, vocab, BEAM_SIZE)
alphas = torch.FloatTensor(alphas)
# Visualize caption and attention of best sequence
visualize_att(IMG_PATH, seq, alphas, rev_vocab)5. Supplementary materials
5-1. Evaluation with beam search
We can also test our model with a beam search.
This is just a combination of section 3-3 and 4-1.
import torch.backends.cudnn as cudnn
import torch.optim
import torch.utils.data
import torchvision.transforms as transforms
#from datasets import *
#from utils import *
from nltk.translate.bleu_score import corpus_bleu
import torch.nn.functional as F
from tqdm import tqdm
# Parameters
data_folder = 'cache_features' # folder with data files saved by create_input_files.py
data_name = 'flickr8k_5_cap_per_img_5_min_word_freq' # base name shared by data files
checkpoint = 'BEST_checkpoint_flickr8k_5_cap_per_img_5_min_word_freq.pth.tar' # model checkpoint
vocab_file = 'cache_features/WORDMAP_flickr8k_5_cap_per_img_5_min_word_freq.json' # word map, ensure it's the same the data was encoded with and the model was trained with
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # sets device for model and PyTorch tensors
cudnn.benchmark = True # set to true only if inputs to model are fixed size; otherwise lot of computational overhead
# Load model
checkpoint = torch.load(checkpoint)
decoder = checkpoint['decoder']
decoder = decoder.to(device)
decoder.eval()
encoder = checkpoint['encoder']
encoder = encoder.to(device)
encoder.eval()
# Load word map (word2ix)
with open(vocab_file, 'r') as j:
vocab = json.load(j)
rev_vocab = {v: k for k, v in vocab.items()}
vocab_size = len(vocab)
# Normalization transform
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
def evaluate(beam_size):
"""
Evaluation
:param beam_size: beam size at which to generate captions for evaluation
:return: BLEU-4 score
"""
# DataLoader
loader = torch.utils.data.DataLoader(
CaptionDataset(data_folder, data_name, 'TEST', transform=transforms.Compose([normalize])),
batch_size=1, shuffle=True, num_workers=1, pin_memory=True)
# TODO: Batched Beam Search
# Therefore, do not use a batch_size greater than 1 - IMPORTANT!
# Lists to store references (true captions), and hypothesis (prediction) for each image
# If for n images, we have n hypotheses, and references a, b, c... for each image, we need -
# references = [[ref1a, ref1b, ref1c], [ref2a, ref2b], ...], hypotheses = [hyp1, hyp2, ...]
references = list()
hypotheses = list()
# For each image
for i, (image, caps, caplens, allcaps) in enumerate(
tqdm(loader, desc="EVALUATING AT BEAM SIZE " + str(beam_size))):
k = beam_size
# Move to GPU device, if available
image = image.to(device) # (1, 3, 256, 256)
# Encode
encoder_out = encoder(image) # (1, enc_image_size, enc_image_size, encoder_dim)
enc_image_size = encoder_out.size(1)
encoder_dim = encoder_out.size(3)
# Flatten encoding
encoder_out = encoder_out.view(1, -1, encoder_dim) # (1, num_pixels, encoder_dim)
num_pixels = encoder_out.size(1)
# We'll treat the problem as having a batch size of k
encoder_out = encoder_out.expand(k, num_pixels, encoder_dim) # (k, num_pixels, encoder_dim)
# Tensor to store top k previous words at each step; now they're just <start>
k_prev_words = torch.LongTensor([[vocab['<start>']]] * k).to(device) # (k, 1)
# Tensor to store top k sequences; now they're just <start>
seqs = k_prev_words # (k, 1)
# Tensor to store top k sequences' scores; now they're just 0
top_k_scores = torch.zeros(k, 1).to(device) # (k, 1)
# Lists to store completed sequences and scores
complete_seqs = list()
complete_seqs_scores = list()
# Start decoding
step = 1
h, c = decoder.init_hidden_state(encoder_out)
# s is a number less than or equal to k, because sequences are removed from this process once they hit <end>
while True:
embeddings = decoder.embedding(k_prev_words).squeeze(1) # (s, embed_dim)
awe, _ = decoder.attention(encoder_out, h) # (s, encoder_dim), (s, num_pixels)
gate = decoder.sigmoid(decoder.f_beta(h)) # gating scalar, (s, encoder_dim)
awe = gate * awe
h, c = decoder.decode_step(torch.cat([embeddings, awe], dim=1), (h, c)) # (s, decoder_dim)
scores = decoder.fc(h) # (s, vocab_size)
scores = F.log_softmax(scores, dim=1)
# Add
scores = top_k_scores.expand_as(scores) + scores # (s, vocab_size)
# For the first step, all k points will have the same scores (since same k previous words, h, c)
if step == 1:
top_k_scores, top_k_words = scores[0].topk(k, 0, True, True) # (s)
else:
# Unroll and find top scores, and their unrolled indices
top_k_scores, top_k_words = scores.view(-1).topk(k, 0, True, True) # (s)
# Convert unrolled indices to actual indices of scores
prev_word_inds = (top_k_words / vocab_size).long() # (s)
next_word_inds = top_k_words % vocab_size # (s)
# Add new words to sequences
seqs = torch.cat([seqs[prev_word_inds], next_word_inds.unsqueeze(1)], dim=1) # (s, step+1)
# Which sequences are incomplete (didn't reach <end>)?
incomplete_inds = [ind for ind, next_word in enumerate(next_word_inds) if
next_word != vocab['<end>']]
complete_inds = list(set(range(len(next_word_inds))) - set(incomplete_inds))
# Set aside complete sequences
if len(complete_inds) > 0:
complete_seqs.extend(seqs[complete_inds].tolist())
complete_seqs_scores.extend(top_k_scores[complete_inds])
k -= len(complete_inds) # reduce beam length accordingly
# Proceed with incomplete sequences
if k == 0:
break
seqs = seqs[incomplete_inds]
h = h[prev_word_inds[incomplete_inds]]
c = c[prev_word_inds[incomplete_inds]]
encoder_out = encoder_out[prev_word_inds[incomplete_inds]]
top_k_scores = top_k_scores[incomplete_inds].unsqueeze(1)
k_prev_words = next_word_inds[incomplete_inds].unsqueeze(1)
# Break if things have been going on too long
if step > 50:
break
step += 1
i = complete_seqs_scores.index(max(complete_seqs_scores))
seq = complete_seqs[i]
# References
img_caps = allcaps[0].tolist()
img_captions = list(
map(lambda c: [w for w in c if w not in {vocab['<start>'], vocab['<end>'], vocab['<pad>']}],
img_caps)) # remove <start> and pads
references.append(img_captions)
# Hypotheses
hypotheses.append([w for w in seq if w not in {vocab['<start>'], vocab['<end>'], vocab['<pad>']}])
assert len(references) == len(hypotheses)
# Calculate BLEU-4 scores
bleu4 = corpus_bleu(references, hypotheses)
return bleu4
if __name__ == '__main__':
beam_size = 1
print("\nBLEU-4 score @ beam size of %d is %.4f." % (beam_size, evaluate(beam_size)))Reference
- AI504: Programming for AI Lecture at KAIST AI
