문장의 meaning을 전달하기 위해서는 word도 중요하지만 어떻게 문장을 structure하는지를 생각해봐야 한다.
🔗 Two views of linguistic structure
- Consistuency = phrase structure grammar = context-free grammars (CFGs)
- Dependency structure
Constituency grammar
🔗 Idea
Language에는 더 큰 unit이 있고, 이것을 phrase라고 부른다.
단어가 모여 구를 이루고 구가 모여 더 큰 구를 이룬다.
Dependency structure
🔗 Idea
Dependency structure는 각 word가 어떤 다른 word에 달려있는지, 수식하는지(modify)를 본다. sentences에 dependency structure를 적용한다.
⭐️ 대부분의 NLP에서 이 dependency grammer를 사용한다. Universal dependencies를 따르는 dependency grammer를 사용한다.
✔️ 중요한 point
문장이 있을 때 어떤 구조를 선택하느냐가 해석을 바꾼다. 따라서 listener/natural language understanding program은 어떤 word가 modify하는지 확률론적인 선택을 해야한다. 이 선택이 문장의 해석이 된다.
언어마다 각각 다른 ambiguoty가 있다.
Ambiguity of Languages
🔗 Prepositional phrase attachment ambiguity
- prepositional phase를 가질 때마다 어떻게 해석할지를 선택해야 한다.
- 전에 있는 noun phrase를 modifying
- 전에 있는 verb를 modifying
- prepositional phase가 뒤에 k개가 있으면 Catalan number의 경우의 수가 생긴다. Prepositional phase의 개수의 exponential 수의 가능한 parses가 있다.
🔗 Coordination scope ambiguity
- 특정 word가 modify하는 대상의 범위를 선택해야 한다.
🔗 Adjectival/Adverbial Modifier Ambiguity
- adjective나 adverb modifier가 있으면, 어떤 것을 modifying 할지를 선택해야 한다.
🔗 Verb Phrase (VP) attachment ambiguity
- 하나의 adjectival, adverbial 뿐 아니라 verb phrase가 ambiguity를 가져올 수 있다.
💡 General Idea
문장의 syntatic structure를 아는 것이 semantic interpretation에 도움을 준다.
Dependency Grammar and Dependency Structure
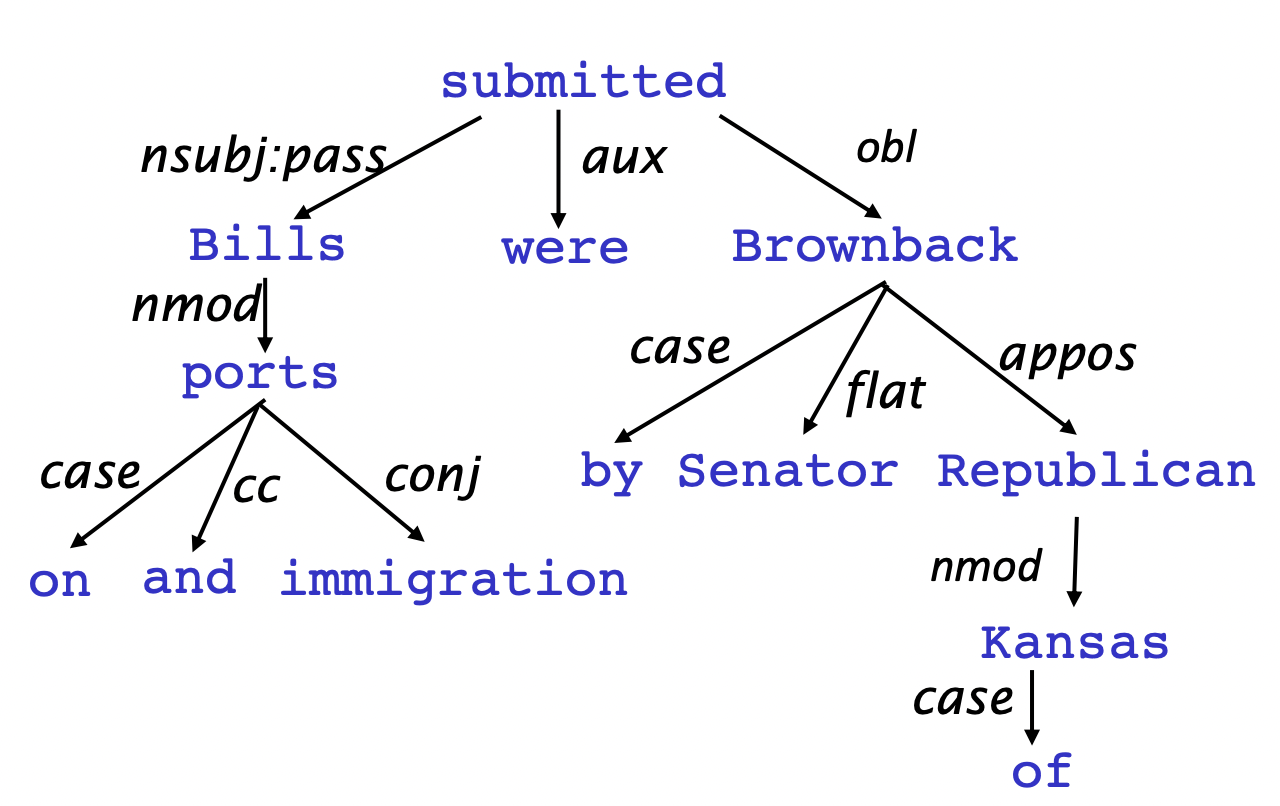
- Dependency syntax에서 syntatic structure는 word 쌍 사이의 relation으로 구성되어있다. 이 relation은 binary asymmetric relation(word 사이에 화살표를 그림)이고 dependencies라고 불린다.
- 화살표에는 grammatical relation의 이름이 적혀있다.
- 화살표는 head(governor, superior, regent)에서 dependent(modifier, inferior, subordinate)로 간다(다른 방식으로 쓰는 경우도 있지만 우리는 이 convention을 따른다).
- 이 dependencies는 보통 tree(a connected, acyclic, single-root graph)를 형성한다.
- 여러 다른 언어에 적용하기에 dependency grammar가 적합하다.
- ROOT를 추가하여 모든 word가 다른 하나의 node에 대해 dependent하도록 한다.
🔗 Treebank
언어학자들을 모아다가 많은 양의 sentences에 대해 hand parse 하여 dependency structure를 만들어 모아놓은 것이다. 여러 다른 언어가 있다.
- 장점
- Reusuability of the labor
- Broad coverage, not just a few intuitions
- Frequencies and distributional information
- A way to evaluate NLP systems : treebank가 등장하면서 evaluation이 가능하게 되어 사람들이 활발하게 성능을 가지고 경쟁할 수 있게 되었다.
🔗 Dependency parsing의 기본 특징
1. Bilexical affinities : Dependencies의 양쪽 끝에 있는 단어의 의미 관계가 중요하다.
2. Dependency distance : 대부분의 dependencies는 거리가 가깝다. 드물게 길다.
3. Intervening matrial : dependencies가 동사나 쉼표에 걸쳐있는 경우가 거의 없다.
4. Valency of heads : head의 양 옆에 보통 어떤 dependents가 오는지 본다.
Dependency Parsing
- 문장은 각각의 word에 대해 어떤 다른 word(ROOT 포함)의 dependent인지 선택함으로써 parsing된다.
- Some constraint
- 오직 하나의 word만이 ROOT의 dependent이다.
- cycle은 없다.
- 이 constraint가 dependencies를 tree로 만든다.
- 마지막 issue는 화살표가 교차할 수 있는가 없는가이다.
Projectivity
🔗 Projective parse
Linear order로 word가 배치될 때, 교차하는 dependency arcs는 없다.
- CFG tree는 projective여야 한다.
- 대부분의 syntatic structure는 projective이지만, dependency theory는 보통 preposition stranding같은 것을 고려하기 위해 non-projective structures도 허용한다. Non-projective dependencies 없이는 이런 특정 construction의 의미를 얻을 수 없다.

Methods of Dependency Parsing
- Dynamic programming
- Graph algorithms
- Constraint Satisfaction
- Transition-based parsing or deterministic dependency parsing
- 좋은 machine learning classifier가 안내하는 greedy choice of attachments
Transition-based parsing
🔗 Idea
Dependency parsing을 하기 위해, shift-reduce parser와 같은 set of transitions를 통해 문장을 parse(구문 분석)할 것이다.
왼쪽에서 오른쪽, 아래에서 위 방향으로 문장을 parse한다.
🔗 Parser가 가지고 있는 것
- a stack σ
- a buffer β
- a set of dependency arcs A
- a set of actions
🔗 동작 과정
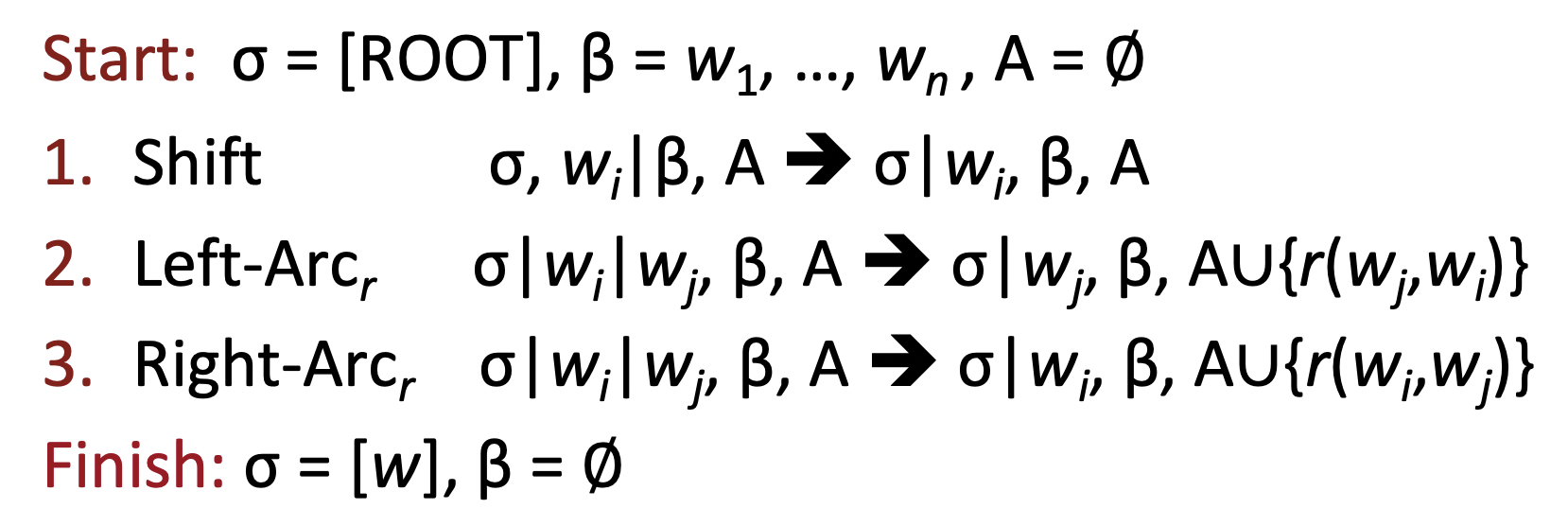
ROOT symbol만 가지고 있는 stack과 sentence를 가지고 있는 buffer로 시작한다.
매 point마다 3개의 action중 하나를 선택하여 행함으로써 a set of dependency arcs를 구축한다.
1. Shift
2. Left-arc reduce
3. Right-arc reduce
- Left-arc reduce나 right-arc reduce를 하고 나면, stack에서 dependent 하나가 없어지고, dependency arc를 arc set에 추가한다. 그리고 보통 grammatical relation도 명시한다.
🔗 Example
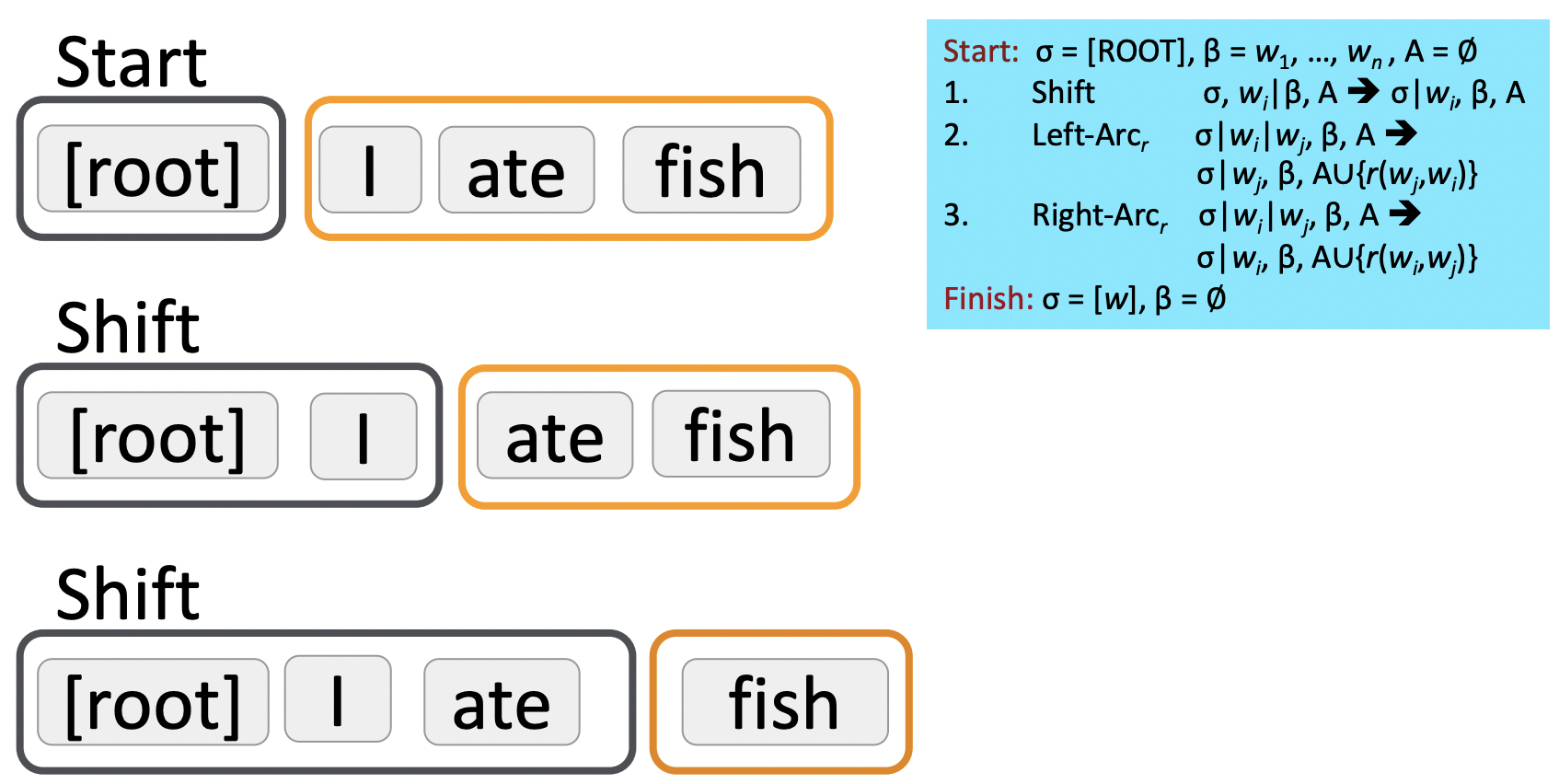
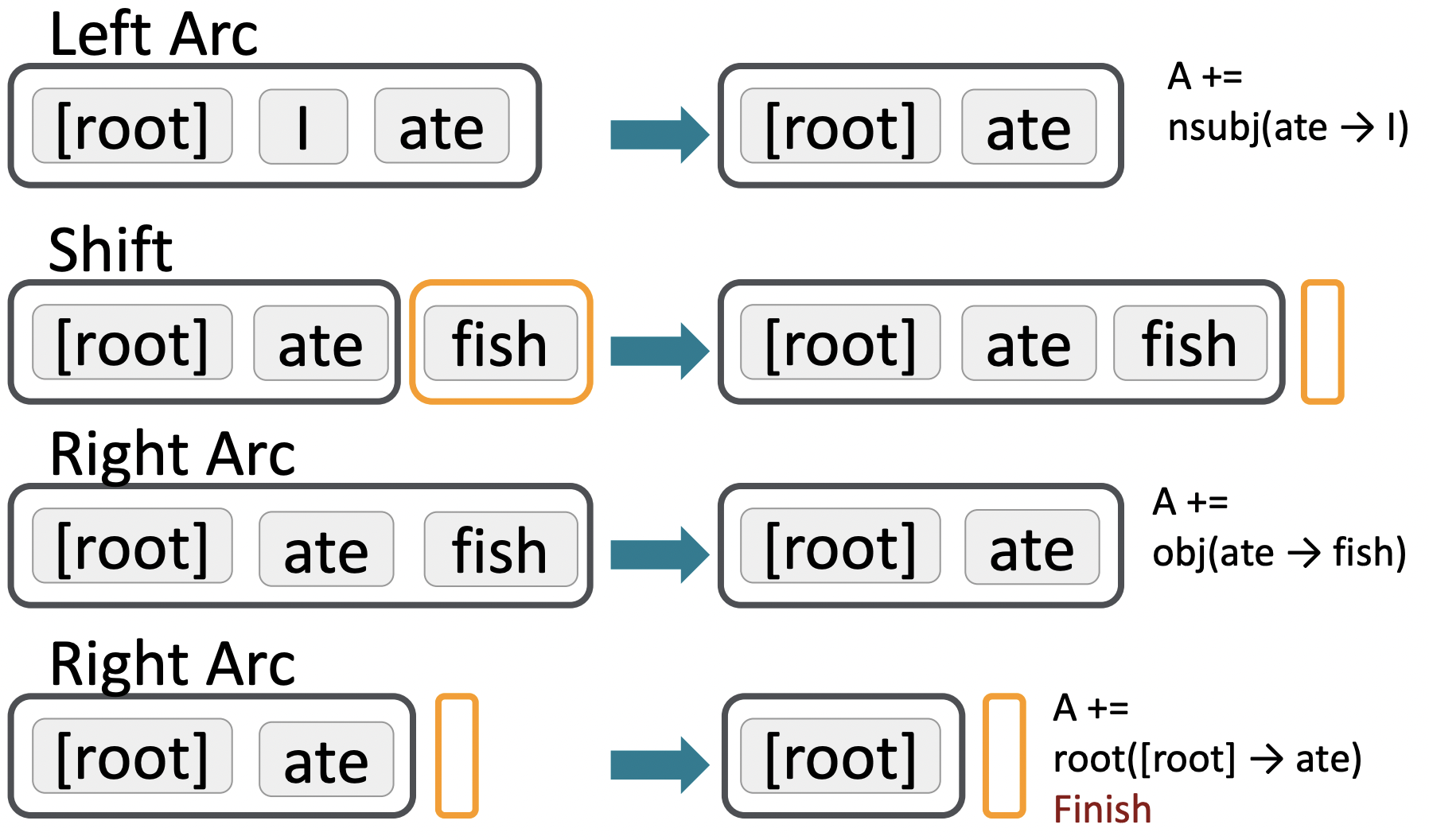
- End condition : buffer가 비어있고, stack에는 ROOT symbol만 있다.
🔗 How to choose the next action
-
각 action은 distriminative classifier(ex. softmax classifier)가 예측한다.
- R개의 relation이 있을 때, |R| * 2 + 1 개의 choice가 있다.
- Features : top of stack word, POS, first in buffer word, POS
-
No search, 매번 greedy하게 선택한다.
- Beam search : 느리지만 결과는 더 좋다. k개의 좋은 parse prefixes를 각 time step마다 keep해놓고 확장한다. 그리고 나중에 어떤 것이 가장 좋은지 evaluate한다.
-
Greedy하기 때문에 매우 빠른 linear time parsing을 높은 정확도에 제공한다. 따라서 많은 양의 parsing을 해야할 때 사용하면 좋다.
🔗 Conventional Feature Representation
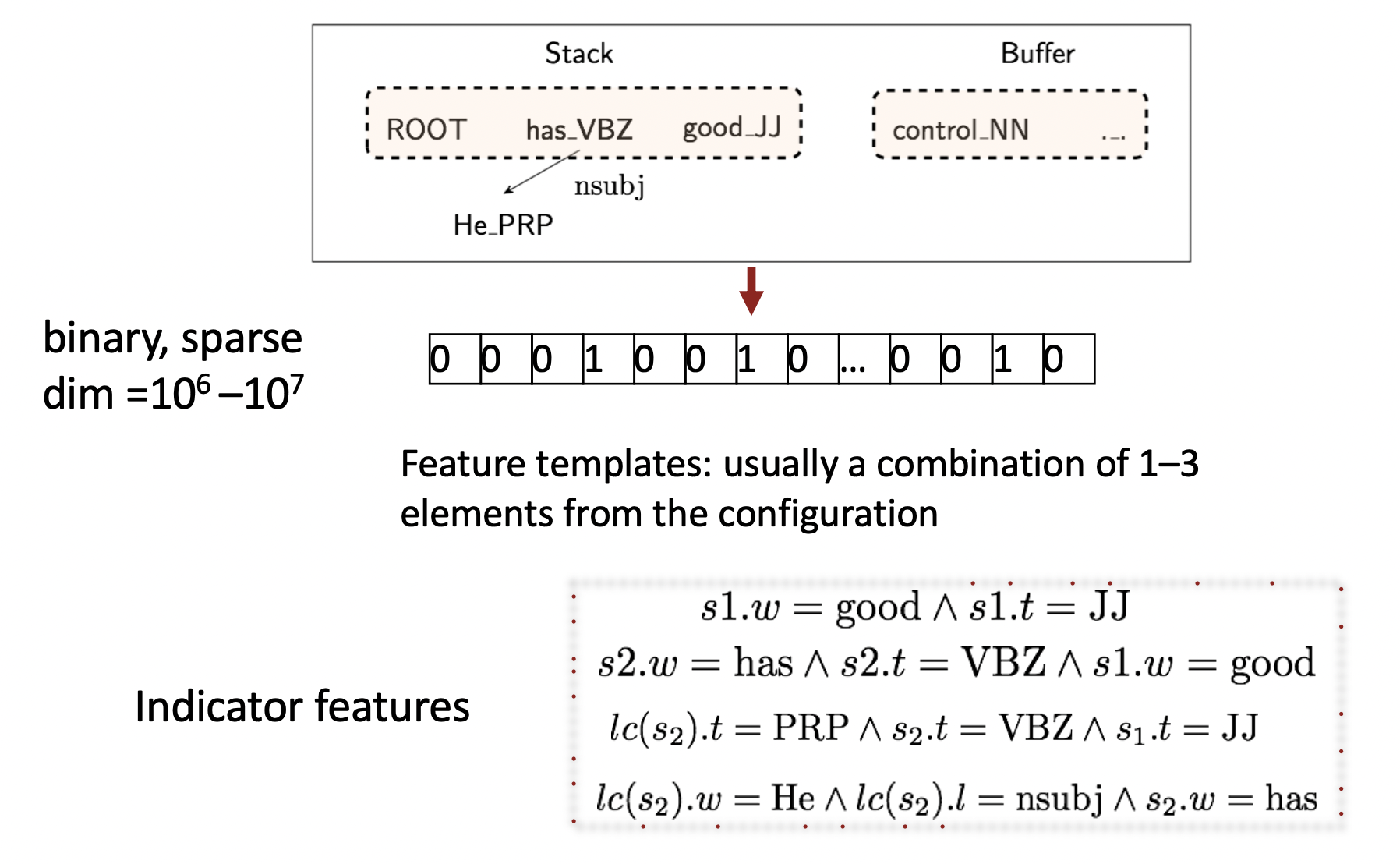
- Machine learning classifier를 build할 때 symbolic feature를 이용했다.
- Indicator feature로 small subset(주로 configuration에서 1~3개의 element)을 pick하였다.
- 오직 1 또는 0의 symbolic feature를 가지는데 보통 parser가 10^6에서 10^7개의 이러한 feature를 가진다.
Evaluation of Dependency Parsing: (labeld) dependency accuracy
- test set은 treebank에서 hand parsed된 것이다.
🔗 두 개의 common metrics
- Unlabeled Accuracy Score(UAS)
- Dependency facts가 일치하는지를 본다.
- Labeled Accuracy Score (LAS)
- Dependency facts와 label된 grammatical relation 둘 다가 일치하는지 본다.
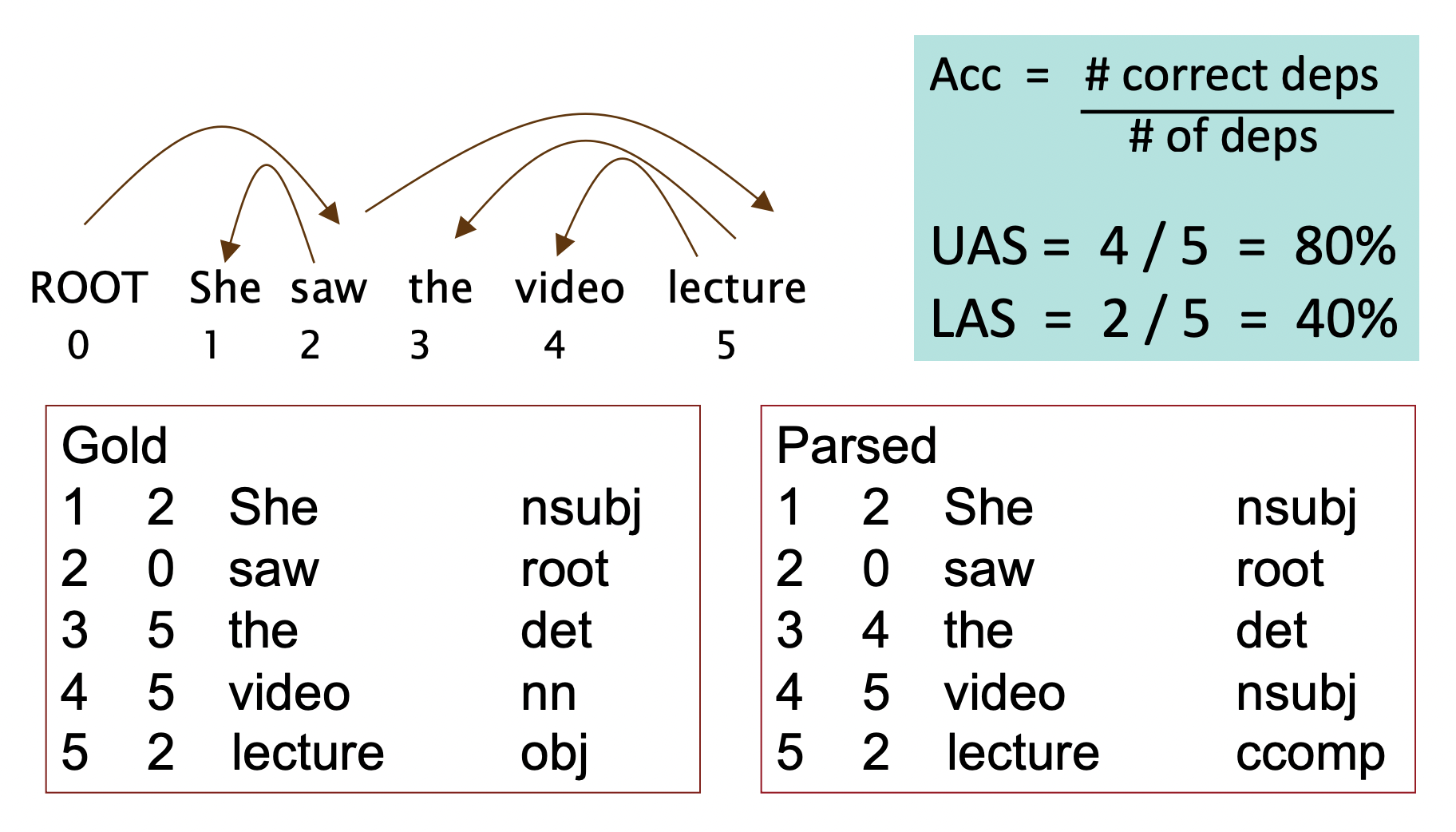
문장에서 한 word당 하나의 dependency를 갖는다.
- Dependency facts와 label된 grammatical relation 둘 다가 일치하는지 본다.
Reference
- CS224n: Natural Language Processing with Deep Learning Lecture at Stanford University
