
1. Natural Language Processing (NLP) – A Solution for Knowledge Extraction from Patent Unstructured Data.
Souili, Achille & Cavallucci, Denis & Rousselot, Francois. (2015). Procedia Engineering. 131. 635-643. 10.1016/j.proeng.2015.12.457.
💡 논문 요약
전통적으로 특허 분석은 TRIZ와 TRIZ에서 유래된 IDM (Inventive Design Method)이라는 방법으로 이뤄졌다. IDM에는 특허 전문가들이 특허 문서를 읽고 알아낸 특허를 구성하는 여러 요소들(문제 상황, 해결방법, 변수 등)이 knowlege로 사용된다.
이 논문에서는 NLP와 Text Mining을 적용하여 특허 문서에서 IDM knowledge의 추출을 자동화하는 방법을 제안하였다. 자동화에는 NLP에서 유한 상태 기계(FSM)과 어휘 의미 패턴(LSM)을 이용하였다.
연구 결과로 키워드를 입력하면 키워드에 해당되는 특허 문서를 찾아 그 문서에서 Problems와 Partial Solutions를 찾아내고, Problem graph를 그려내었다. 이는 특허 전문가의 patent mining을 돕는 자동화 방법을 제안한 것이다.
📚 논문과 함께 공부한 배경 이론
1. IDM (Inventive Design Method)
Inventive problem를 풀기 위한 방법으로 네 단계에 걸쳐 이뤄진다.
Step 1 Extract knowledge and Organize it into a graph of Problems and Partial Solutions
Step 2 Formulate a set of contradictions with the graph
Step 3 Solve the contradictions individually
Step 4 Choose the most innovative Solution Concept
IDM의 main concepts는 Problems, Partial Solutions, Action Parameters, Evaluation Parameter 네 가지로, Step 1에서 그래프를 그리기 위해 Problems, Partial Solutions가 필요하고 Step 3에서 contradictions을 해결하기 위해 Action Parameters, Evaluation Parameter가 필요하다.
- 이 논문은 특허 문서에서 IDM의 두 요소 Problems, Partial Solutions을 추출하고, 이를 통해 Problem graph을 그리는 Step 1을 자동화하고자 한다.
어떤 키워드에 대한 Inventive problem을 마주했을 때, 해당 키워드에 대한 다른 특허 문서들의 Problem graph을 그려서 다른 특허에서는 어떻게 문제를 해결하였는지를 확인할 수 있을 것이다.
2. Finite State Machine (Finite State Automata, 유한 상태 기계)
유한 상태 기계 FSM은 컴퓨터 프로그램과 전자 논리 회로를 설계하는 데에 쓰이는 수학적 모델으로, sequential process의 가장 간단한 모델 중 하나이다. FSM은 start state (initial state)와 final state를 포함한 유한 개의 상태와, 상태 사이에서 가능한 이동을 나타내는 전이로 정의되는 추상 기계이다.
FSM이 어떠한 sequence를 accept한다는 것은 start state에서 시작하여 transiton을 거쳐 final state에 도달할 때 생성될 수 있는 sequence라는 의미이다. FSM이 accept하는 sequence의 집합을 해당 FSM의 'Language'라고 한다.
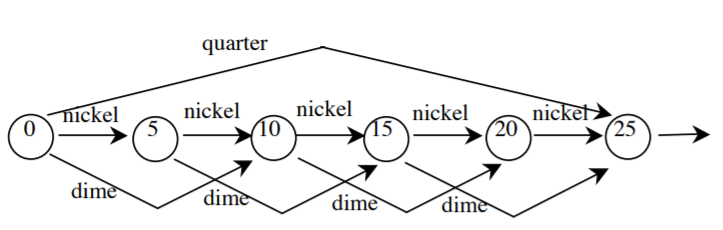
그림은 25센트를 넣을 수 있는 동전 자판기를 모델링한 FSM이다. dime(10), dime(10), nickel(5)는 accept되는 sequence로 이 FSM의 language가 된다.
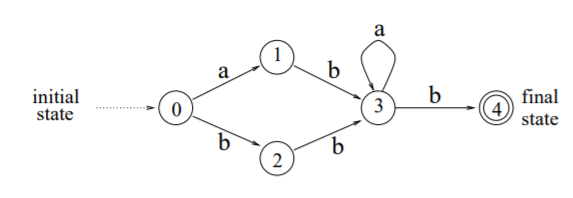
특허 텍스트 전처리에 사용 중인 정규표현식(Regular Expression)에도 FSM이 사용된다. 그림은 정규표현식 (a|b)ba∗b을 식별하는 FSM이다. initial state에서는 a나 b가 들어와야 하고, 결국 b를 거쳐 final state에 도달하며 문자열이 끝나야 한다. initial state에 입력된 문자열이 가능한 전이가 없다면, accept이 아닌 reject가 되고 해당 문자열은 이 FSM의 language가 아니라는 결론이 나온다.
FSM은 특히 자연어 처리 영역에서 굉장히 유용하다고 한다. 자연어는 같은 단어라도 어떤 순서로 배치되는지에 따라 의미가 달라지고 가능한 배치가 제한적인데, FSM은 유한 상태 간의 이동 순서를 결정하기 때문인 것 같다. 아래 그림은 the one old cow는 accept하지만 the very cow는 reject하는 자연어 FSM이다.
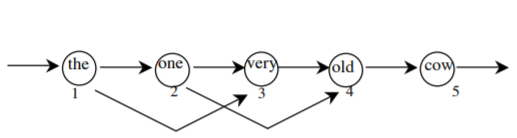
이 외에도 FSM은 튜링 기계를 포함하여 다양한 모델링에 사용될 수 있는데, 공부를 하다보니 Hidden Markov Chain도 FSM과 연결된다고 한다. 신기한 FSM.
- 이 논문에서 언어 현상을 표현한 Finite State Automata를 기반으로 문장을 Problem인지 Partial Solution인지를 매칭했다고 한다. 논문의 이론적 배경에서 S-A-O 기반 접근 (Subject-Action-Object), '동사+명사'와 '형용사+명사'의 이진 관계를 이용한 의미 문장의 유사성 등을 언급한 것으로 보아 주어, 서술어 등의 문장의 요소를 중심으로 본 것 같다. 특허에서 사용되는 문장의 요소들을 분석한 것을 바탕으로, 문장 요소와 가능한 전이로 구성된 FSM을 이용하여 해당 문장이 Problem이나 Partial Solution으로 accept 되는지 파악할 수 있을 것 같다.
3. Lexico-Syntatic Patterns (어휘 의미 패턴)
같은 의미의 문장이 형태는 다양할 수 있지만 중요한 키워드는 결국 비슷한 의미 패턴을 갖는데, 이 때의 의미 패턴을 어휘 의미 패턴 LSP라고 한다. 아래와 같이 문장 내의 형태소를 분석하여 정규화하면 일반적인 자연어 문장을 LSP 형태로 추출할 수 있다.
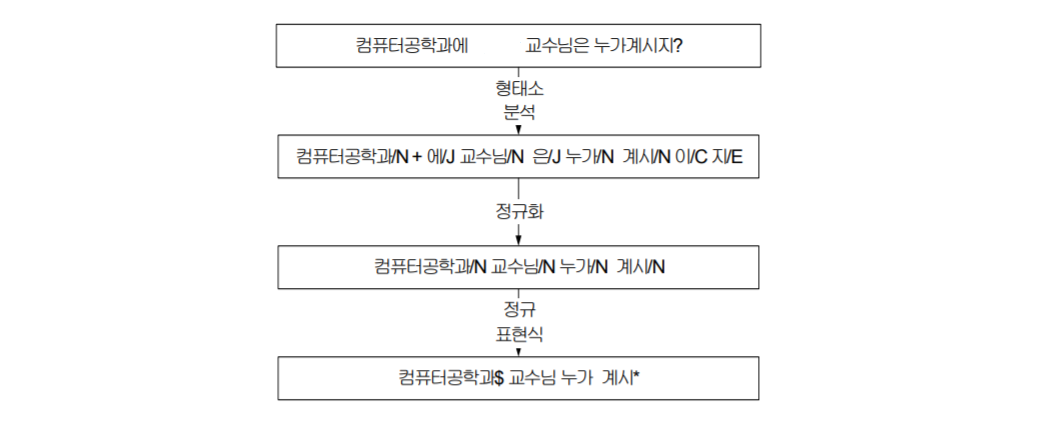
- 이 논문에서 LSP로 Problems과 Partial Solutions을 추출했다고 했는데, 구체적으로 LSP를 어떻게 활용하였는지는 나와있지 않았다.
4. XML 태그
XML은 데이터의 구조를 기술하기 위한 언어인데, 문장에 대한 정보를 시작 태그와 종료 태그를 이용하여 나타낼 수 있다.
- 이 논문에서는 특허 문서 텍스트에 XML 태그를 붙임으로써 찾은 Problems과 Partial Solutions 문장 등을 표시하였다.
📁 논문에서 사용한 데이터
USPTO에서 얻은 특허 문서 100개.
(다양한 분야에서의 특허가 선택되도록 직접 선택)
✍ 논문에서 제안한 Method
Step 1 Selection of relevant patent documents
사용자가 원하는 keyword 2개와 찾고자 하는 텍스트의 영역을 입력하면 관련된 특허 문서를 찾아 선택한다.
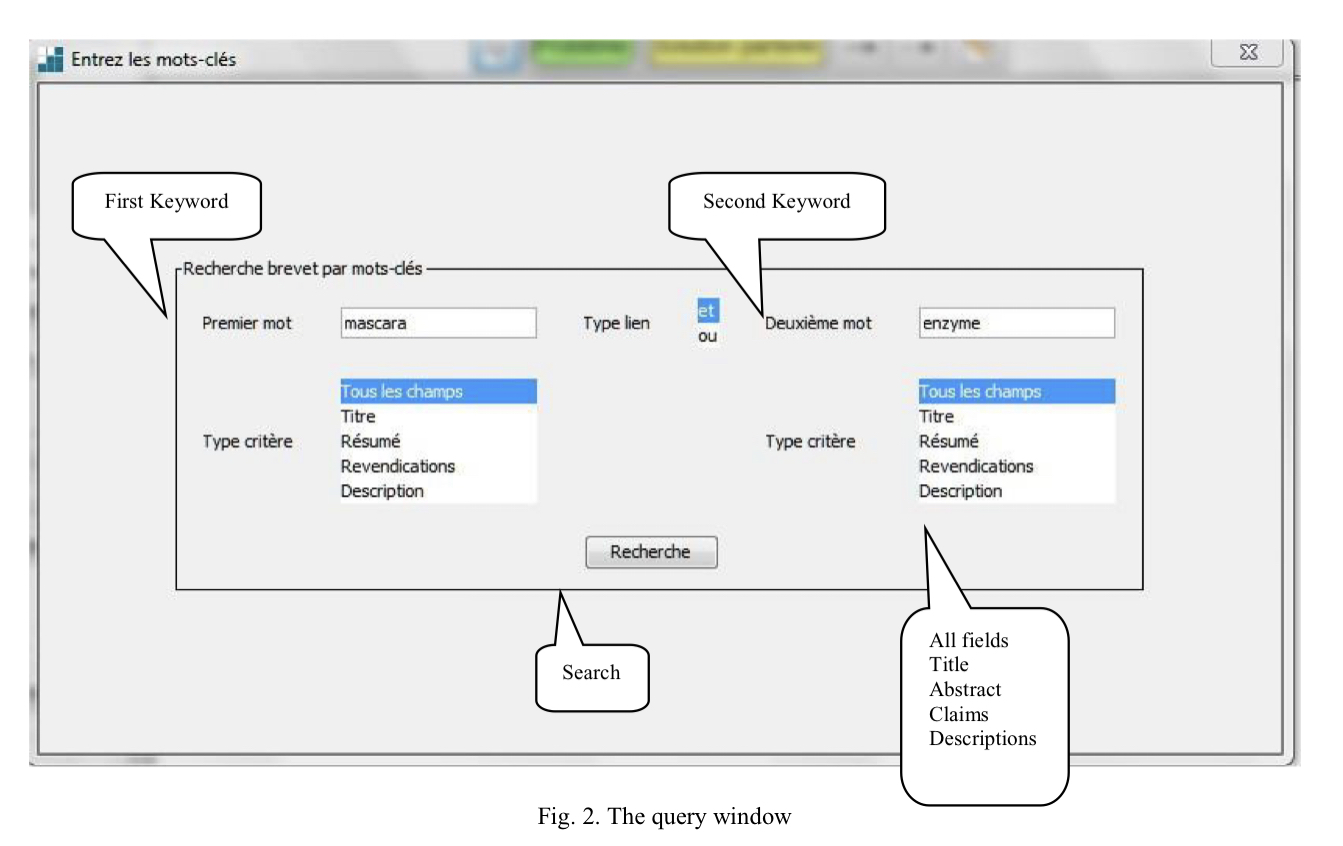

Step 2 Segmentation in paragraphs
Step 3 Matching and tagging of knowledge relevant to IDM
언어 현상을 표현한 FSM을 이용하여, 특허 문서의 문단에서 problem과 partial solution 문장을 찾고 XML 태그를 붙인다.

Step 4 Problem graph generation
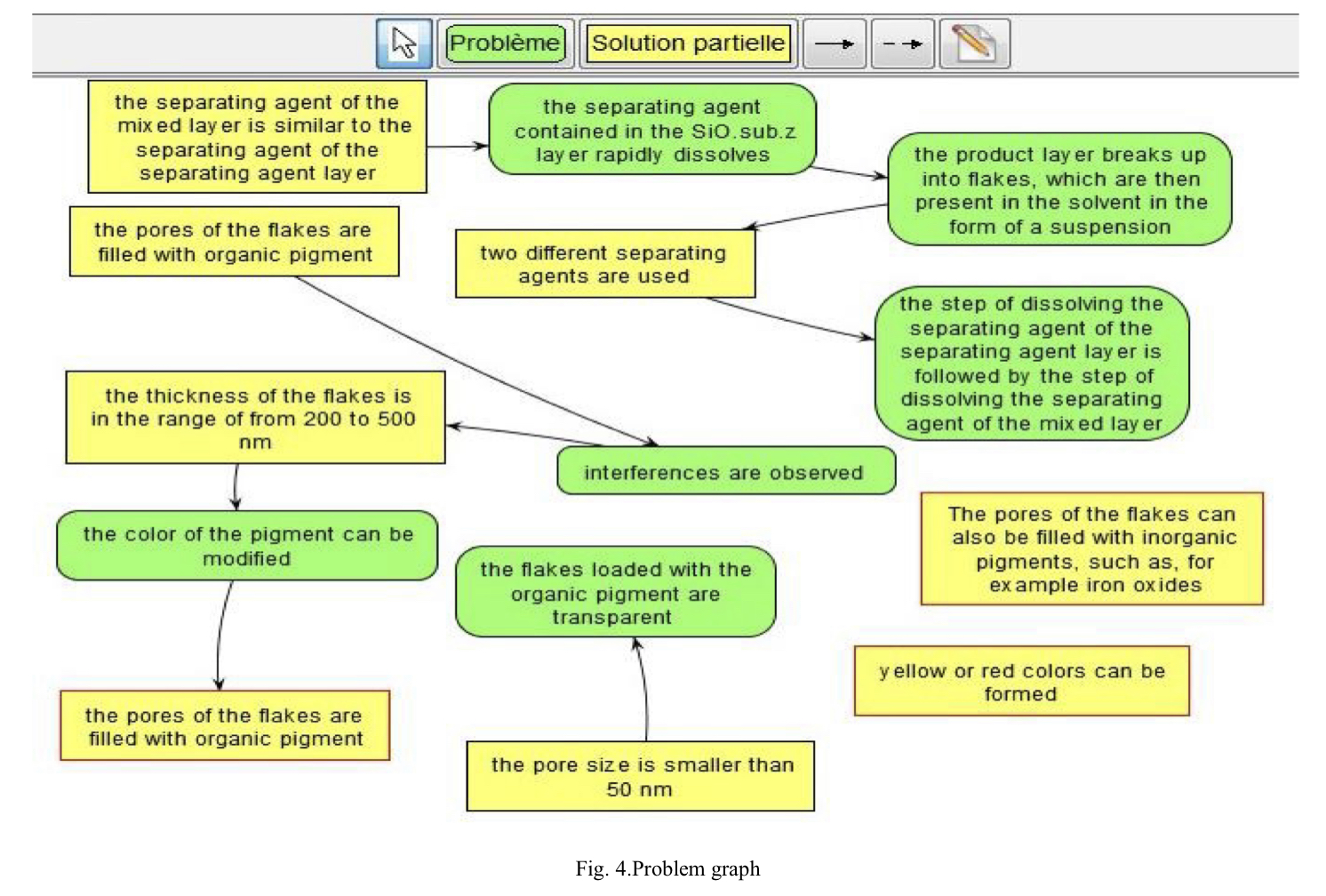
💬 후기
선배님의 말을 빌리자면, NLP에서 나온 기술을 사용하는거지, NLP를 하는 거는 아닌거 같은데. 괜히 제목에 낚였네. 진짜 NLP 연구를 한 논문인줄 알았더니 그냥 특허에서 Knowledge를 추출할 때 NLP 기법을 썼다는 거잖어. 그리고 구체적으로 어떻게 NLP 기법을 사용했는지도 안 나와.
성능 평가도 딱 keywords 두 세트로, recall rate는 안 보고 precision rate만 보고.
이게 모얌.
🛑 논문 1-2, 1-3도 해야 되지롱. 아 다른 게시글에 할까? 그것두 괜찮을 거 같구. 1-2까지만 같이해도 될거같구.
앞으로는 특히 더더더더
Data와 Method를 위주로 적어야지
출처
IDM
https://url.kr/vix793
FSM
https://url.kr/enlw52
https://www.cs.rochester.edu/u/james/CSC248/Lec7.pdf _ Hidden MC
https://homepage.lnu.se//staff/jlnmsi/cc1/lexical.pdf
LSP
https://www.koreascience.or.kr/article/CFKO200725752348593.pdf

나는 당신의 기사를 주셔서 감사합 weaver wordle 니다. 나는 이제 그것에 대해 더 잘 이해했으며 기사의 철저함에 감사합니다. 앞으로 당신의 글을 더 많이 읽고 싶습니다.