파이프라인
여러 개의 레코드를 가져오는 방법 (여러 개의 해시를 가져오는 방법)
두 가지 방법이 있습니다.
1. 반복문을 통해 GETALL과 같은 명령어로 하나씩 다 가져오는 방법
• 요청과 응답이 순차적으로 처리됩니다.
• 네트워크 지연 시간이 요청 수에 비례하여 증가합니다.
• 구현이 직관적이고 간단합니다.2. 파이프라이닝 (추천)
본질적으로 다양한 명령을 하나의 명령으로 만드는 것을 뜻함
하나의 커다란 Batch로 Redis에 요청하는 방법
• 네트워크 왕복 횟수를 줄여 성능을 크게 향상시킵니다.
• 요청 수가 많아질수록 이점이 커집니다.
• 일부 구현에서 코드 작성이 조금 더 복잡할 수 있습니다.node-redis는 동작방식이 다른 라이브러리와 조금 다름
// not node-redis (Python)
client = redis.Redis(..)
pipe = client.pipeline()
pipe.set('foo','bar')
pipe.get('bing')
pipe.execute()// node-redis
const results = await Promis.all([
client.get('color'),
client.get('name')
])// node-redis 응용
const run = async () => {
await client.hSet('car1', {
color: 'red',
year: 1950
});
await client.hSet('car2', {
color: 'green',
year: 1955
});
await client.hSet('car3', {
color: 'blue',
year: 1960
});
const commands = [1, 2, 3].map((id) => {
// hSet, Get 등 다양한 명령어를 사용할 수 있음.
return client.hGetAll('car' + id);
})
// Promis.all을 통해 한번에 배치처맅
const results = await Promise.all(commands);
console.log(results);
};
run();Set
리스트와 마찬가지로 2개이상의 데이터를 관리하는 추상자료형입니다.
| Set | List | |
|---|---|---|
| 순서 | 순서 보장 X | 순서 보장 O |
| 중복 | 중복 허용 X | 중복 허용 O |
특징
- 고유성 보장 : 동일한 값들이 여러 번 저장되지 않음
- 빠른 연산 : O(1) 복잡도
- 집합 연산 지원 : 차집합, 교집합, 합집합과 같은 집합 연산을 지원
사용 예시
- 고유한 값들의 관리 : ex) 특정 사이트에 접근하는 모든 IP들의 목록을 중복 없이 관리
- 관계 표현 : ex) 게시글에 연결된 태그를 저장할 때 활용
- 추천 시스템 : 친구 추천, 관심사 추천 등에 활용가능
명령어
Set의 모든 명령어는 S로 시작SADD : 집합에 추가
SADD key value1 [value2 value3 …] // 한번에 여러 개의 요소를 추가할 수도 있다
SMEMBERS : 집합의 모든 값을 반환
SMEMBERS key
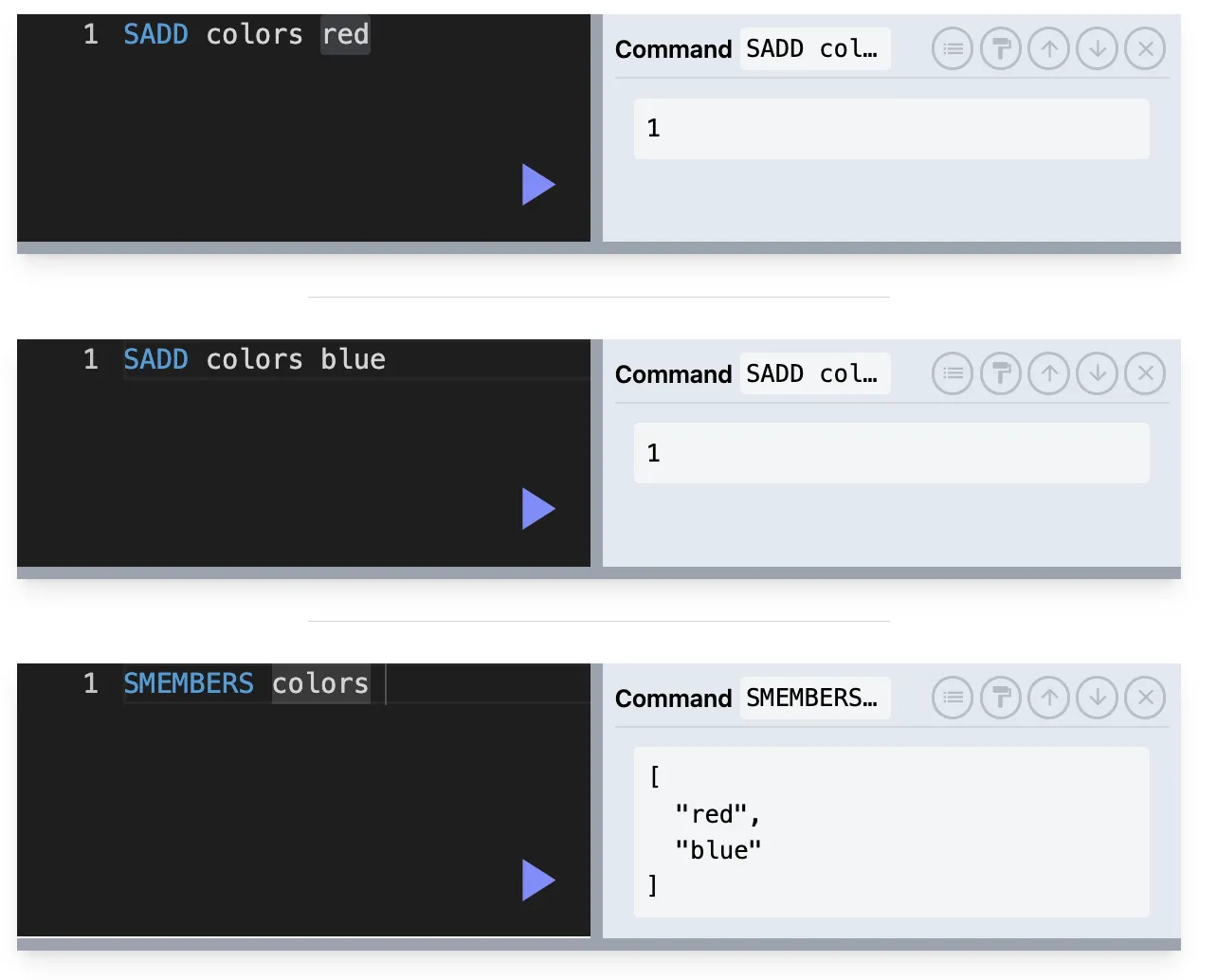
SUNION : 합집합
SUNION key1 key2 key3 …
ex) 모든 게시물에서의 태그를 조회해야할 때
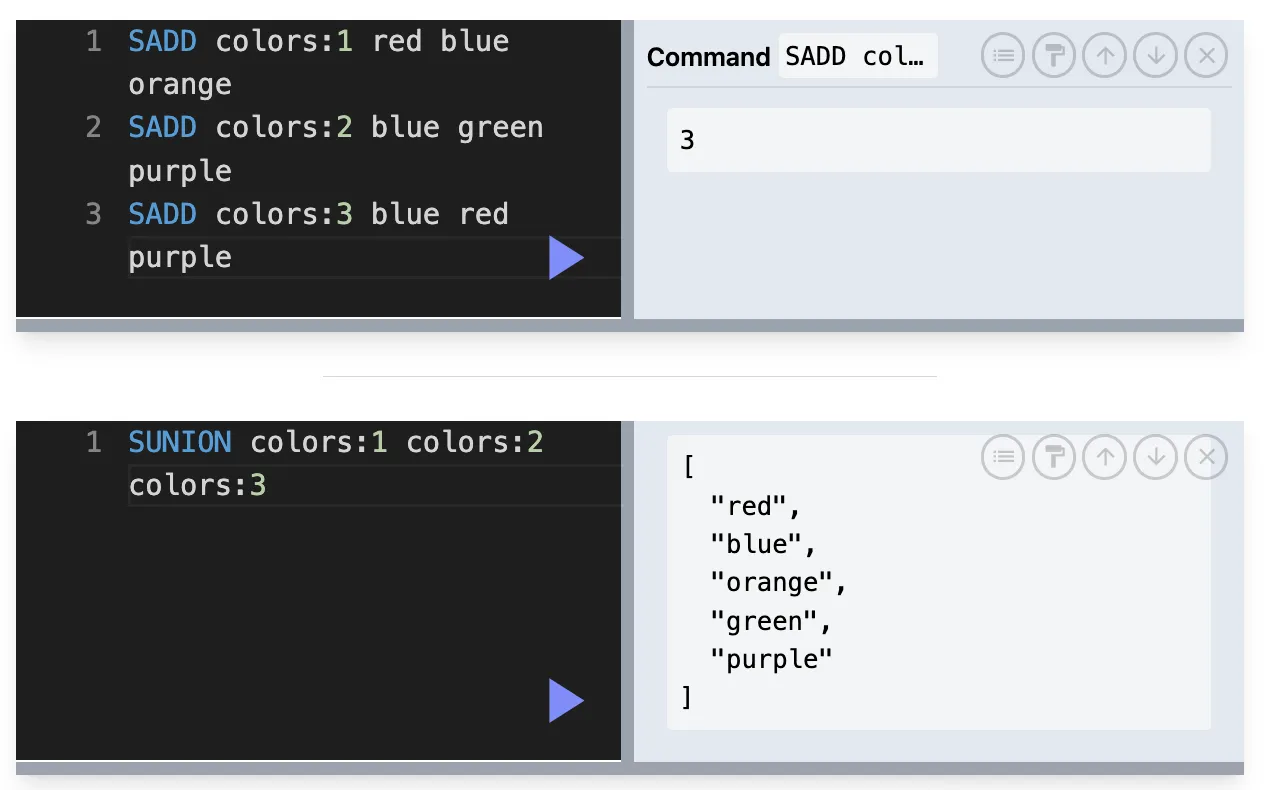
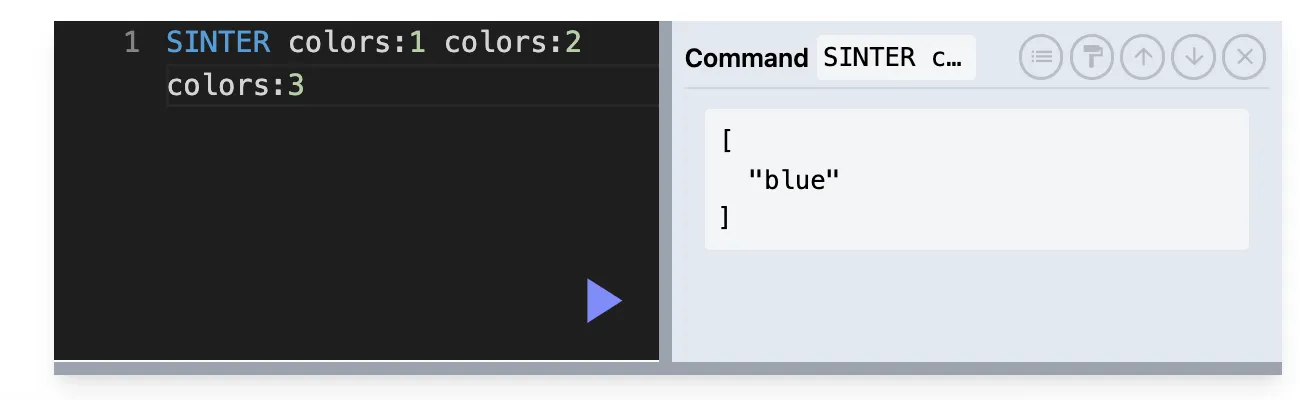
SINTER : 교집합
SINTER key1 key2 key3 …
ex) SNS에서 공통 친구를 찾아야할 때
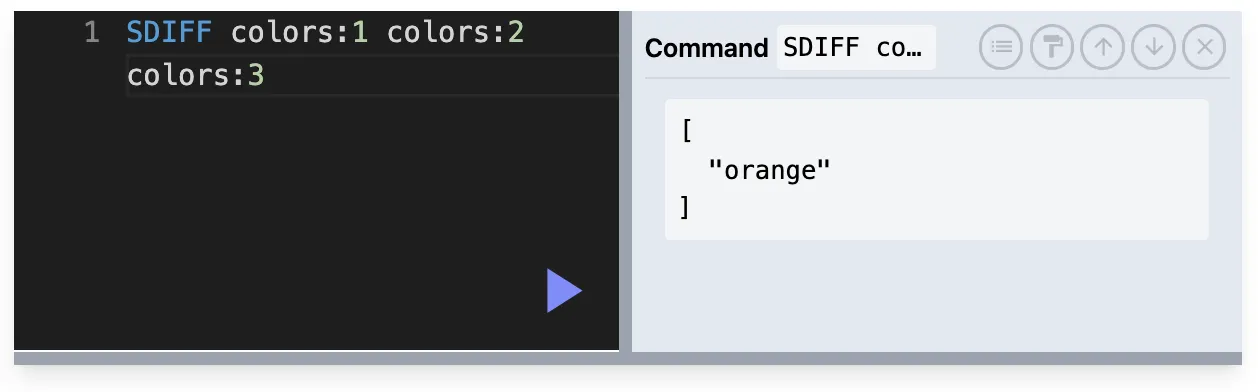
SDIFF : 차집합
SDIFF key1 key2 key3 …
SUNION, SINTER와 다르게 SDIFF는 순서가 중요하다.
첫번 째 key를 기준으로 나머지 key를 참조해 빼는 형식
STORE 연산 : SUNIONSTORE, SDIFFSTORE, SINTERSTORE
SUNIONSTORE resultKey key1 key2 key3 …
SDIFFSTORE resultKey key1 key2 key3 …
SINTERSTORE resultKey key1 key2 key3 …
합집합, 차집합, 교집합의 결과를 새로운 Key에 저장
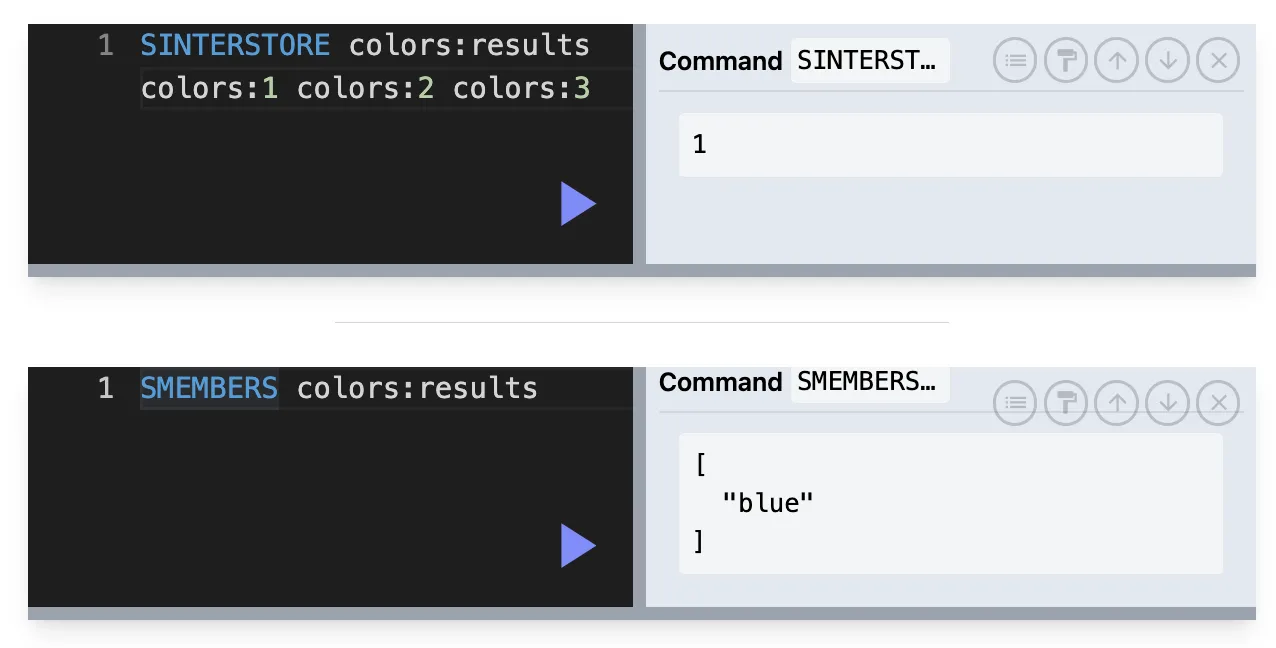
SISMEMBER : SET에 존재하는지 1 or 0
SISMEMBER key value
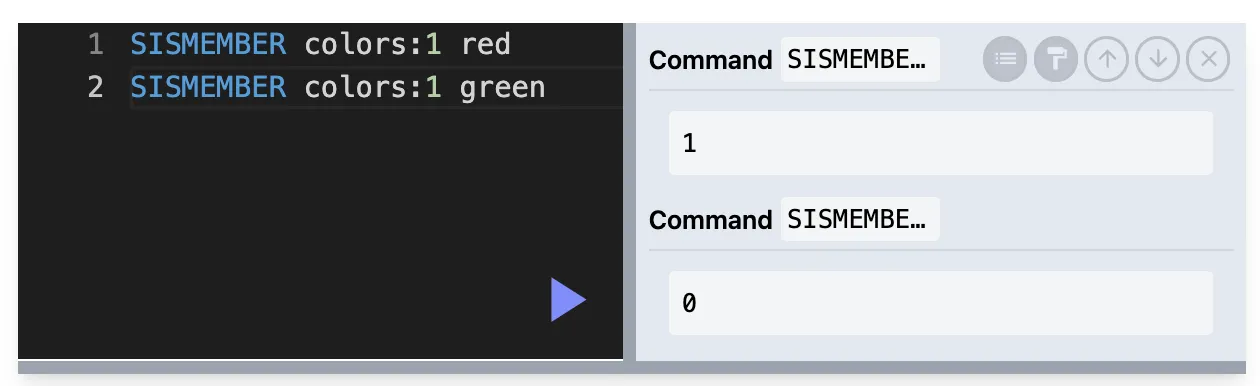
SMISMEMBER : 값들이 존재하는지 배열로 반환
SMISMEMBER key value1 value2 value3 …
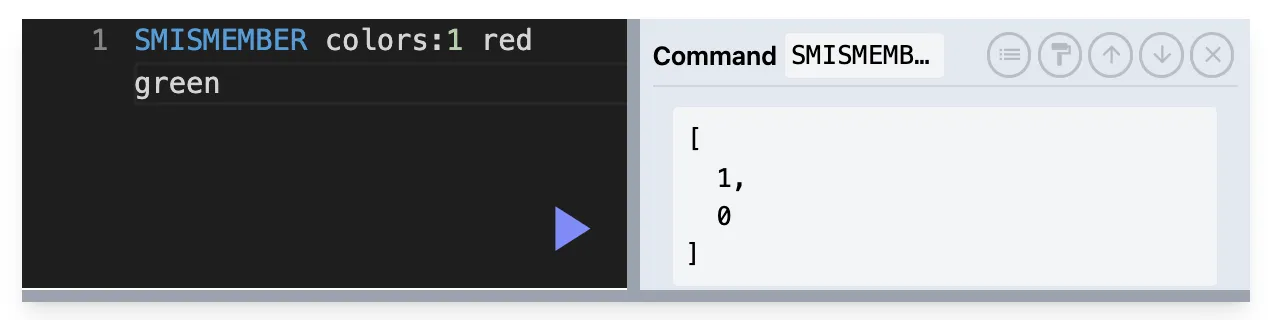
SCARD : SET의 크기 반환
SCARD key
집합의 카디널리티, 즉 크기를 제공
SREM : SET의 특정 값 제거
SREM key value
SSCAN : SET의 데이터를 조회
SSCAN key cursorID count
cursorID : 다음 페이지를 향하는 포인터
일반적으로 대용량 데이터에서 일부분을 가져올 때 사용
SMEMBERS vs SSCAN
| SMEMBERS | SSCAN | |
|---|---|---|
| 사용 목적 | Set의 모든 데이터를 한번에 조회 | Set의 데이터를 반복적으로 나누어 조회 |
| 결과 | 전체 데이터를 한번에 반환 | 커서를 기반으로 일부 데이터를 반환 |
| 대상 데이터 크기 | 작은 규모의 Set에 적합 | 대규모 Set에서도 효율적으로 사용 가능 |
| 필터링 | 지원 X | 지원 O (MATCH 옵션) |
| 메모리 사용량 | 전체 데이터를 메모리에 로드 | 한 번에 일부 데이터만 로드 |
주의사항
SSCAN의 COUNT 옵션은 반환할 요소 수에 대한 엄격한 제한이 아닌 대략적인 힌트로 작동합니다.
따라서 실제 반환되는 요소의 수는 지정한 COUNT 값과 정확히 일치하지 않을 수 있음을 염두에 두고 사용해야 합니다.
